Cloud Music v1.0
Download as PPTX, PDF5 likes2,163 views

클라우드 뮤직 공개용 버전





























![[SSA] 03.newsql database (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/03-140225072436-phpapp01-thumbnail.jpg?width=560&fit=bounds)


![[SSA] 04.sql on hadoop(2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/04-140225072610-phpapp01-thumbnail.jpg?width=560&fit=bounds)










![[SSA] 01.bigdata database technology (2014.02.05)](https://cdn.slidesharecdn.com/ss_thumbnails/01-140225072202-phpapp02-thumbnail.jpg?width=560&fit=bounds)












More Related Content
Viewers also liked (10)
Similar to Cloud Music v1.0 (20)







![∞⁄Ïò§Ì¿øÏÜåÏä§Ïª®ÏѧÌåÖ]ΆàÏù¥πÆ¥Î≥ÑÏò§Ì¿øÏÜåÏä§](https://cdn.slidesharecdn.com/ss_thumbnails/random-130509091012-phpapp01-thumbnail.jpg?width=560&fit=bounds)
Cloud Music v1.0
- 2. Contents환경변화클라우드 컴퓨팅PCC클라우드 뮤직아마존 클라우드 플레이어구글 뮤직애플 아이클라우드mSpot Music
- 4. 환경변화 – 1996 vs. 2010
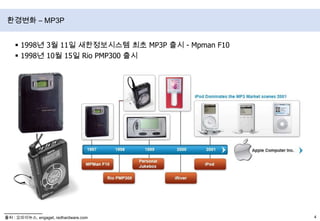
- 5. 1998년 3월 11일 새한정보시스템 최초 MP3P 출시 - Mpman F101998년 10월 15일 Rio PMP300 출시환경변화 – MP3P출처 : 오마이뉴스, engaget, redhardware.com
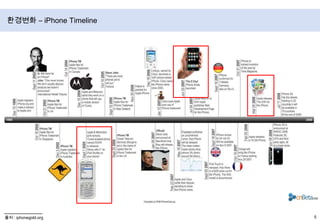
- 6. 환경변화 – iPhone Timeline출처 : iphonegold.org
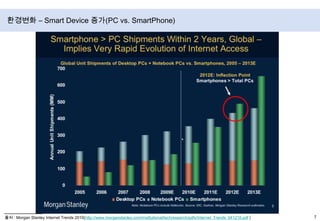
- 7. 환경변화 – Smart Device 증가출처 : Morgan Stanley Internet Trends 2010(http://www.morganstanley.com/institutional/techresearch/pdfs/Internet_Trends_041210.pdf)
- 8. 환경변화 – Smart Device 증가(PC vs. SmartPhone)출처 : Morgan Stanley Internet Trends 2010(http://www.morganstanley.com/institutional/techresearch/pdfs/Internet_Trends_041210.pdf)
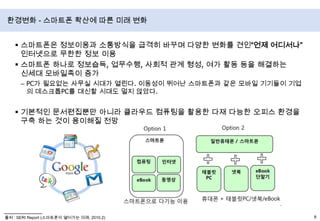
- 9. 스마트폰은정보이용과 소통방식을 급격히 바꾸며 다양한 변화를 견인“언제 어디서나” 인터넷으로 무한한 정보 이용스마트폰 하나로 정보습득, 업무수행, 사회적 관계 형성, 여가 활동 등을 해결하는 신세대 모바일족이증가PC가 필요없는 사무실 시대가 열린다. 이동성이 뛰어난 스마트폰과 같은 모바일기기들이 기업의 데스크톱PC를 대신할 시대도 멀지 않았다.기본적인 문서편집뿐만 아니라 클라우드 컴퓨팅을 활용한 다재 다능한 오피스 환경을 구축 하는 것이 용이해질 전망환경변화 - 스마트폰확산에 따른 미래 변화출처 : SERI Report (스마트폰이 열어가는 미래, 2010.2)
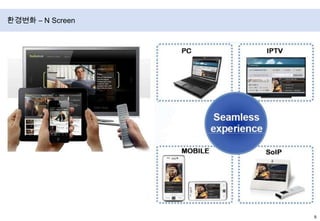
- 10. 환경변화 – N Screen
- 12. 클라우드컴퓨팅 이란?전기를 생각해 보면,출처 : Oracle on AWS(http://www.slideshare.net/ShakilLangha/oracle-on-aws-8071588)
- 13. 클라우드 컴퓨팅 이란?컴퓨터로 바꿔 보면,- 연산파워와 스토리지는 언제든 필요한 만큼 사용이 가능함- 사용에 따른 과금출처 : Oracle on AWS(http://www.slideshare.net/ShakilLangha/oracle-on-aws-8071588)
- 14. 클라우드 컴퓨팅 주요 플레이어출처 : Cisco 2010 Webinar
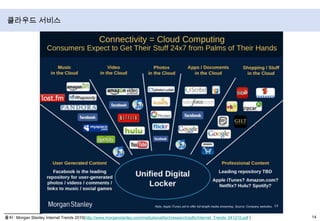
- 15. 클라우드 서비스출처 : Morgan Stanley Internet Trends 2010(http://www.morganstanley.com/institutional/techresearch/pdfs/Internet_Trends_041210.pdf)
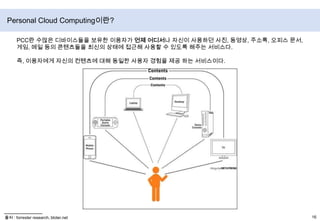
- 17. Personal Cloud Computing이란?PCC란 수많은 디바이스들을 보유한 이용자가 언제 어디서나 자신이 사용하던 사진, 동영상, 주소록, 오피스 문서, 게임, 메일 등의 콘텐츠들을 최신의 상태에 접근해 사용할 수 있도록 해주는 서비스다.즉, 이용자에게 자신의 컨텐츠에 대해 동일한 사용자 경험을 제공하는서비스이다.출처 : forrester research, bloter.net
- 18. 개인형 스토리지Passive 형: Naver N Drive, LG U+ Box, Amazon Cloud Drive, MS Sky DriveActive 형: DropBox, SugarSync , Daum Cloud, KT ucloud, iCloud오피스Google Office, MS Docs.com, Zoho Office, 네이버 오피스, ThinkfreeOffice , MS Office365캘린더Google Calendar, 네이버 캘린더메일 / 주소록Yahoo Mail, Hotmail, Gmail, 네이버메일, 다음 메일사진Picasa, iCloud Photo Stream, ucloud photo, 네이버 포토앨범, 다음 사진메모EverNote, SpringPadPersonal Cloud Service 종류
- 19. Cloud Storage
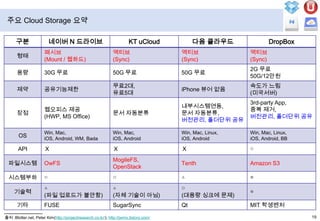
- 20. 주요 Cloud Storage 요약출처 :Blotter.net, Peter Kim(http://projectresearch.co.kr/), http://jwmx.tistory.com/
- 21. 30GB를 1,000만명 에게 제공하면 = 30GB * 10,000,000 = 300,000 TB= 300 PB 필요NAS 스토리지로 구성하는 경우50TB = 1억
- 22. 300,000 TB = 50TB * 6,000개
- 23. 6,000억 소요PC 급 장비로 이용하는 경우1TB = 10만원 (PC급 SATA HDD)
- 24. 서버 1대당 25TB 장착 가능
- 25. 25TB = 1,000만원 (750+250)
- 26. 300,000 TB = 25TB * 12,000 개
- 27. 1,200억 소요왜 자체 분산파일시스템을 사용하나?
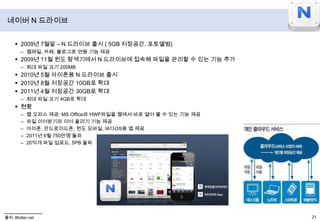
- 28. 네이버N 드라이브2009년 7월말 – N 드라이브 출시 ( 5GB 저장공간, 포토앨범)웹메일, 카페, 블로그로 연동 기능 제공2009년 11월 윈도 탐색기에서 N 드라이브에 접속해 파일을 관리할 수 있는 기능 추가최대 파일 크기 200MB2010년 5월 아이폰용N 드라이브 출시2010년 8월 저장공간 10GB로 확대2011년 4월 저장공간 30GB로 확대최대 파일 크기 4GB로 확대현황웹 오피스 제공: MS Office와 HWP파일을 웹에서 바로 열어 볼 수 있는 기능 제공파일 이어받기와 이어 올리기 기능 제공아이폰, 안드로이드폰, 윈도 모바일, 바다OS용 앱 제공2011년 6월 750만명 돌파20억개 파일 업로드, 5PB 돌파출처 :Blotter.net
- 29. 네이버N 드라이브출처 : http://blog.naver.com/kurugel
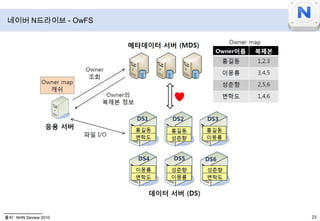
- 30. 네이버N드라이브 - OwFS출처 : NHN Deview 2010
- 31. 2010년 2월말 다음 클라우드 시범서비스저장공간 20GB, 최대 파일 크기 4GB버전관리 기능 제공: 히스토리 보기, 1개월간 문서 작업 내역확인 및 복원기능특정 폴더를 친구와 공유 가능동기화 기능 제공히스토리 관리 기능 제공2010년 5월 아이폰앱 출시2010년 6월 안드로이드앱 출시음악/영상 스트리밍 기능 추가공유폴더에는 음원/동영상 업로드 제한2010년 6월 저장공간 50GB로 확대현황웹 오피스 뷰어 제공: MS Office, HWP파일파일 이어받기와 이어 올리기 기능 제공아이폰, 안드로이드폰앱제공윈도, Mac, Linux용 싱크 매니저 제공 (Qt)2011년 6월 160만명 돌파다음 클라우드출처 :Blotter.net, Daum
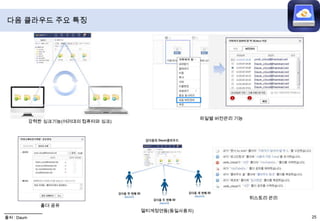
- 32. 다음 클라우드 주요 특징파일별 버전관리 기능강력한 싱크기능(여러대의 컴퓨터와 싱크)히스토리 관리폴더 공유멀티계정연동(동일사용자)출처 : Daum
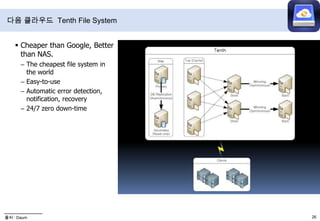
- 33. 다음 클라우드 Tenth File SystemCheaper than Google, Better than NAS.The cheapest file system in the world Easy-to-use Automatic error detection, notification, recovery 24/7 zero down-time출처 : Daum
- 34. 클라우드 뮤직(Music in the Cloud)
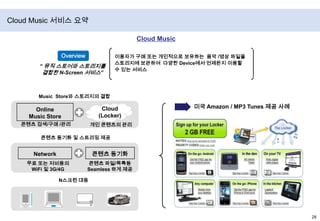
- 35. Cloud Music 서비스 요약Cloud Music이용자가 구매 또는 개인적으로 보유하는 음악 /영상 파일을스토리지에 보관하여 다양한 Device에서 언제든지 이용할수 있는 서비스Overview“ 뮤직스토어와 스토리지를결합한 N-Screen 서비스”Music Store와 스토리지의 결합Online Music StoreCloud(Locker)미국 Amazon / MP3 Tunes 제공 사례콘텐츠 검색/구매 /관리개인 콘텐츠의 관리콘텐츠 동기화 및 스트리밍 제공콘텐츠 동기화Network콘텐츠 파일/목록등Seamless 하게 제공무료 또는 저비용의WiFi및 3G/4GN스크린 대응
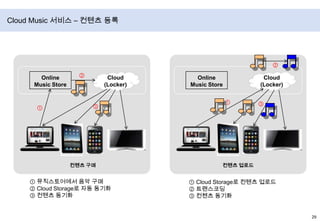
- 36. Cloud Music 서비스 – 컨텐츠 등록②②Online Music StoreOnline Music StoreCloud(Locker)Cloud(Locker)①③③①컨텐츠 구매컨텐츠 업로드① 뮤직스토어에서 음악 구매② Cloud Storage로 자동 동기화③ 컨텐츠 동기화① Cloud Storage로 컨텐츠 업로드② 트랜스코딩③ 컨첸츠 동기화
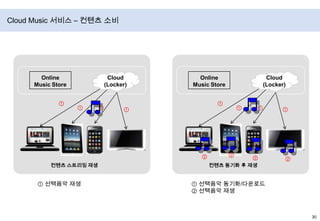
- 37. Cloud Music 서비스 – 컨텐츠 소비Online Music StoreCloud(Locker)Online Music StoreCloud(Locker)①①①①①①①①②②②②컨텐츠 동기화 후 재생컨텐츠스트리밍 재생① 선택음악 재생① 선택음악 동기화/다운로드② 선택음악 재생
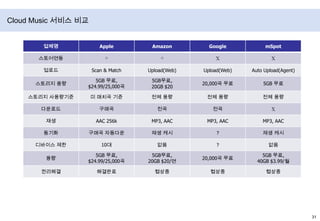
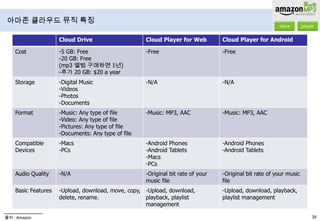
- 38. Cloud Music 서비스 비교
- 39. 아마존
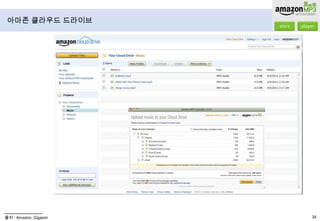
- 40. 아마존 클라우드 뮤직2007년 9월 25일 아마존 MP3 서비스 오픈(뮤직 스토어): 16M곡 보유2008년 12월 3일 영국, 2009년 4월 1일 독일, 2009년 6월 10일 프랑스, 2009년 12월 3일 독일, 호주, 스위스 서비스 오픈2011년 3월 29일 아마존 클라우드 뮤직 서비스 오픈구성클라우드 드라이브 + 클라우드 플레이어로 서비스가 구성됨클라우드 드라이브Web Interface(PC)와 개인 Storage만 제공
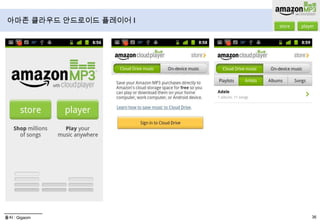
- 41. 자동분류, 메타정보로 Library구성클라우드 플레이어 for AndroidMP3 Store/Cloud Drive 브라우징+구매+저장+재생 기능 통합 제공특징MP3 Store와 결합되어 구매>저장>재생 인터페이스를 all in one으로 제공라이선스: 현재 권리사 협의 중 (수익쉐어 형태)서비스 지역: 미국디바이스: PC 웹, 안드로이드앱수익모델: 저장 용량당 과금5GB 무료, Mp3 앨범 구매시1년간 20GB까지 무료
- 42. 추가 Storage 구매시1년간 20$에 20GB
- 43. Amazon MP3 Store에서 구매한 곡도 Storage사용량에 Count출처 : Amazon, 위키피디아
- 44. 아마존 클라우드 드라이브출처 : Amazon, Gigaom
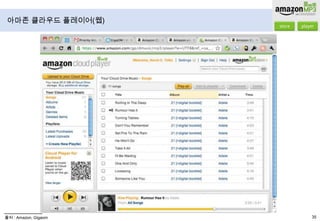
- 45. 아마존 클라우드 플레이어(웹)출처 : Amazon, Gigaom
- 46. 아마존 클라우드 안드로이드 플레이어 I출처 : Gigaom
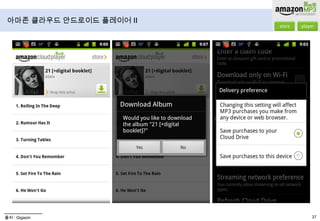
- 47. 아마존 클라우드 안드로이드 플레이어 II출처 : Gigaom
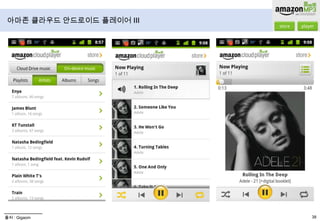
- 48. 아마존 클라우드 안드로이드 플레이어 III출처 : Gigaom
- 49. 아마존 클라우드 뮤직 특징출처 : Amazon
- 50. 구글 뮤직
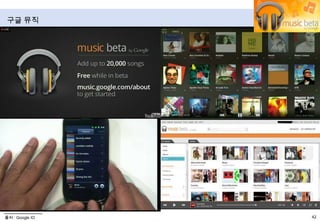
- 51. 뮤직서비스 히스토리2009.10.29:Google OneBox서비스(Music Search) 출시iLike, Lala, Pandora, Rhapsody, imeem과 제휴2010.05.21:Simplify Media 인수아이튠스, 윈도 미디어 플레이어에 보관된 음악 컨텐츠를안드로이드 단말기에서 원격으로 재생2011.04.08:Push Life인수iTunes로 관리하고 있는 음악을 동기화 시키는 SmartSync기술 보유2011.05.11:Google IO 에서 구글 뮤직 Beta 출시특징글라우드 기반 음악 스트리밍 서비스회원가입: 초대기반(베타기간 동안)20,000곡 업로드 무료PC와 스마트폰, 스마트패드 등 여러 기기의 음악 재생 목록들은 자동 동기화서로 어울리는 음악으로 재생 목록을 생성해 주는 즉석 믹싱기능디바이스: PC 웹, 안드로이드앱상황라이선스: 현재 권리사 협의 중스토어: 스포티파이와 제휴논의 중 소문 (2011.4.25)서비스 지역: 미국수익모델: 언급 없음구글 뮤직출처 : Google, 뉴스
- 52. 구글 뮤직출처 : Google IO
- 54. 애플 클라우드 서비스2008.06.09 WWDC 2008에서 모바일미 소개2008.07.30 모바일미 서비스 오픈연락처, 캘린더, 메일동기화(Sync) 기능, 20GB/연간 $99요금안정성문제(접속이 느리고, 데이터 손실문제, 잦은 버그), 비싼 요금으로 사용자에게 외면"모바일미는 충분한 준비 없이 출시됐고 너무 복잡해 애플 스탠더드(표준)에도 맞지 않는다“2011.06.06 WWDC 2011에서 iCloud소개카테고리아이튠스 클라우드
- 56. 포토 스트림
- 57. 앱, 책, 백업
- 58. 연락처, 캘린더, 메일5GB 무료컨텐츠 종류별 전략 채택출처 : Apple
- 59. iTunes in the Cloud히스토리2009.07.06 노스캐롤라이나메이든시에데이터 센터 건립 발표 183acre(약 22만평), $1B 규모2009.11 마이스페이스iLike, imeem인수2009.12.04 애플 Lala.com 인수2010.11.22 애플 iOS 4.2에 AirPlay 출시2011.04.15 MS 데이터센터 본부장 영입2011.06.06 WWDC 2011에서 iTunes in the Cloud 소개2011년말 데이터 센터 완공 예정라이선스 해결을 위해 $150M 선급금 제공(전자신문)특징저장공간: 5GB디바이스: PC iTunes, 아이폰, 아이팟 터치, 아이패드 등 10개 디바이스에 한함iTunes Store구매>iCloud에 보관>연동 Device에 다운로드/스트리밍iTunes Match연간 $24.99 / 25,000곡
- 60. iTunes Scan/Match>iCloud 라이브러리에 추가(매칭 or 업로드)>연동 Device에서 스트리밍
- 61. 구매곡/매치곡은 저장공간 Count에서 제외출처 : Apple
- 62. 애플 데이터 센터노스캐롤라이나주에 있는 애플 데이터 센터 (2009.06 ~ ), 2011년말오픈예정
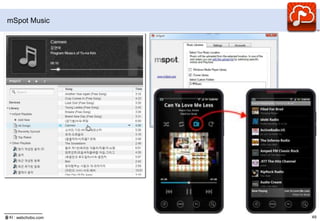
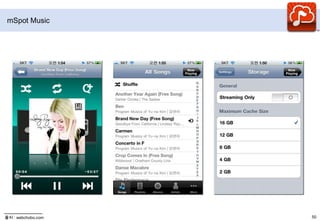
- 63. mSpot Music
- 64. mSpot Music히스토리2004년 Daren Tsui가 VC에서 $250M투자로 설립2009.03.02. mSpot.com 출시2010.06.28 클라우드 뮤직 서비스 출시2GB(1,600여곡) 스토리지 제공
- 65. 권리사와 계약 없이 서비스2011.03.30 5GB로 증가특징저장공간: 5GB 무료, 40GB ($3.99/월)디바이스: PC, 아이폰, 안드로이드, 웹TV하이브리드 클라우드 뮤직서비스: 클라우드 뮤직과 라디오형 서비스를 결합PC iTunes로부터 자동 동기화: Meta, Cover Art, Playlist, 음악을 자동 동기화캐시모드: 안드로이드, 아이폰라디오 기능, Recommendation 기능: 안드로이드, 라디오는 지역 제한출처 : readwriteweb.com,
- 66. mSpot Music출처 : webchobo.com
- 67. mSpot Music출처 : webchobo.com
- 68. Í∞êÏǨ«Í©ÎãàÎã§.