






![データ
● 以下の3つのベンチマークを利用
○ NUS-WIDE:269,648 images from flickr, 1000 tags + 81 tags from human annotator
○ MS COCO: 123,000 images, 80 class
○ PASCAL VOC 2007: 9963 images
● 学習データ時のlabelの入力順序
○ 学習データでの当該 labelの出現頻度順で決定
(簡単な、典型的なlabelから先に予測していく事を意図 )
○ 順番をランダムにしたり、高度な順番付の手法 [28]をつかってみたが、特に効果はなかった …
○ mini batchごとに順番をrandomにしたら、収束せず…](https://image.slidesharecdn.com/cvcvpr2016-161127010908/85/CNN-RNN-A-Unified-Framework-for-Multi-label-Image-Classification-CV-35-CVPR2016-11-320.jpg)





![結果(その他)
● attentionの可視化
○ Deconvolutional network(画像のどこに強く反応したかreconstructする
network[Zeiler et al 2010])を用いてattention を可視化
○ elephant→zebraと予測した時のattentionの変化
18](https://image.slidesharecdn.com/cvcvpr2016-161127010908/85/CNN-RNN-A-Unified-Framework-for-Multi-label-Image-Classification-CV-35-CVPR2016-18-320.jpg)






























More Related Content
Viewers also liked (20)
Similar to CNN-RNN: A Unified Framework for Multi-label Image Classification@CV勉強会35回CVPR2016読み会 (20)








![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=560&fit=bounds)









Recently uploaded (15)















CNN-RNN: A Unified Framework for Multi-label Image Classification@CV勉強会35回CVPR2016読み会
- 1. CNN-RNN: A Unified Framework for Multi-label Image Classification 2016/7/24 @CV勉強会 酒井 俊樹
- 2. 自己紹介 名前:酒井 俊樹(@104kisakai) 所属:NTTドコモ 仕事:画像認識API/サービスの研究開発(NTT) ● 局所特徴量を用いた画像認識 https://www.nttdocomo.co.jp/binary/pdf/corporate/technology/rd/technical_journal/bn/vol23_1/vol23_1_004jp.pdf ● Deep Learningを用いた画像認識 https://www.nttdocomo.co.jp/binary/pdf/corporate/technology/rd/technical_journal/bn/vol24_1/vol24_1_007jp.pdf ● 画像認識API https://dev.smt.docomo.ne.jp 本発表は個人で行うものであり、所属組織とは 関係ありません。
- 3. この論文の概要 CNN-RNN: A Unified Framework for Multi-label Image Classification ● 著者:Jiang Wang et al. ● Baidu researchの研究(著者の何人かはその後転職) 概要 ● CNNとRNNを組み合わせたMulti labelでの画像分類フレームワークを提案 ○ SOTAを上回る精度 ● 各labelが画像上のどこに着目しているか(attention)を可視化
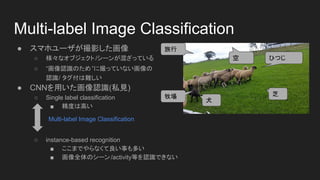
- 4. Multi-label Image Classification ● スマホユーザが撮影した画像 ○ 様々なオブジェクト/シーンが混ざっている ○ “画像認識のため”に撮っていない画像の 認識/ タグ付は難しい ● CNNを用いた画像認識(私見) ○ Single label classification ■ 精度は高い ○ instance-based recognition ■ ここまでやらなくて良い事も多い ■ 画像全体のシーン/activity等を認識できない ひつじ 犬 芝牧場 空 旅行 Multi-label Image Classification
- 5. Multi label classificationの課題 ● labelの共起 (co-ocuurence dependency) ○ 雲と空は共起しやすい ○ 水と車は共起しにくい ○ グラフを用いて表現できるが … labelの数に応じてパラメタが増える ● labelの意味の重複 ● 画像全体 or 局所 ○ 画像全体からしか推定できないタグ ■ 画像のシーン/アクティビティ ○ 画像全体から特徴量を抽出すると、 小さいオブジェクト等が見逃されがち 0.8 0.1 0.2 空 雲 人 ocean; sea; water ship; boat; vessel; craft; vehicle; watercraft
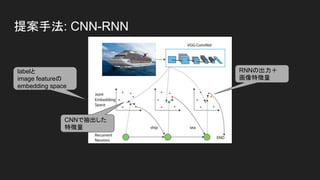
- 6. 提案手法: CNN-RNN ● labelの共起 →RNNを用いて学習 ● 画像全体 or 局所 →RNNによりAttentionをmodel化 →画像中の一部分にattention ● labelの意味の重複 →image/label embedding space で表現 空 雲 空 雲 鳥 ocean sea ship boat watercraft people 船の画像
- 8. 提案手法: CNN-RNN labelの1hot vectorを 行列UIを用いてembedding space 上のvectorに変換 vector sum labelに逆変換
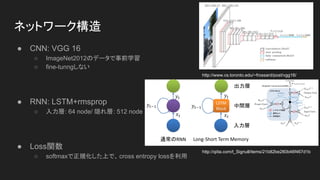
- 9. ネットワーク構造 ● CNN: VGG 16 ○ ImageNet2012のデータで事前学習 ○ fine-tunngしない ● RNN: LSTM+rmsprop ○ 入力層: 64 node/ 隠れ層: 512 node ● Loss関数 ○ softmaxで正規化した上で、cross entropy lossを利用 http://www.cs.toronto.edu/~frossard/post/vgg16/ http://qiita.com/t_Signull/items/21b82be280b46f467d1b
- 10. どの順番でLabelを予測していくのが良いのか Labelの予測する順番に正解はない →Greedyに推測 ● Greedyに予測する際の問題点 ○ 最初の一つの予測を間違えてしまうと、 すべてがダメになってしまう … ○ 各時刻tでtopK個のlabelを予測していき、 beam searchする方法をとることに
- 11. データ ● 以下の3つのベンチマークを利用 ○ NUS-WIDE:269,648 images from flickr, 1000 tags + 81 tags from human annotator ○ MS COCO: 123,000 images, 80 class ○ PASCAL VOC 2007: 9963 images ● 学習データ時のlabelの入力順序 ○ 学習データでの当該 labelの出現頻度順で決定 (簡単な、典型的なlabelから先に予測していく事を意図 ) ○ 順番をランダムにしたり、高度な順番付の手法 [28]をつかってみたが、特に効果はなかった … ○ mini batchごとに順番をrandomにしたら、収束せず…
- 12. 評価指標 ● labelとground truthを比較 ○ 予測されたK番目までのlabelを元にprecison/recall/F1を 算出/平均 ■ precision = 正解数/生成されたlabel数 ■ recall = 正解数/ground truthのlabel数 ■ classごとのprecision/recall/F1の平均(C-P,C-R) ■ 全labelでのprecision/recall(O-P, O-R) ○ mean average precision(MAP)@top N ■ 画像ごとでのprecisionの平均値
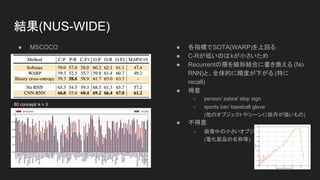
- 13. 結果 ● NUS-WIDE ● MSCOCO
- 14. 結果(NUS-WIDE) ● NUS-WIDE 81 concept/ k = 3 1000 concept/ k = 10 ● 各指標でSOTA(WARP)を上回る ● C-Rが低いのはkが小さいため ● 性別に関係するタグ (actor/actress)は特に 難しかった←学習データがImageNetのた め? 多分筆者のミス
- 15. 結果(NUS-WIDE) ● MSCOCO ● 各指標でSOTA(WARP)を上回る ● C-Rが低いのはkが小さいため ● Recurrentの層を線形結合に書き換える (No RNN)と、全体的に精度が下がる (特に recall) ● 得意 ○ person/ zebra/ stop sign ○ sports bar/ baseball glove (他のオブジェクトやシーンに依存が強いもの) ● 不得意 ○ 画像中の小さいオブジェクトの細かい違い (電化製品の名称等) 80 concept/ k = 3
- 16. 結果(PASCAL VOC 2007) ● 颁濒补蝉蝉ごとの笔谤别肠颈蝉颈辞苍
- 17. 結果(その他) ● 定性的な傾向 ○ 学習されたEmbedding Space ○ embedding space上でkNNを取ると、 classificationで学習するより、より fine-grainedな単語が学習できる 17 CNN-RNNで生成した Embedding Space上 でkNNした結果
- 18. 結果(その他) ● attentionの可視化 ○ Deconvolutional network(画像のどこに強く反応したかreconstructする network[Zeiler et al 2010])を用いてattention を可視化 ○ elephant→zebraと予測した時のattentionの変化 18
- 19. まとめ ● CNNとRNNを組み合わせたMulti labelでの画像分類フレームワークを提案 ○ SOTAを上回る制度 ○ 重複したlabelが出力されにくくなった ○ 注意の可視化も可能に