颁罢颁に基づく音响イベントからの拟音语表现への変换
2 likes1,666 views
日本音響学会 2017年秋季研究発表会 第16回日本音響学会学生優秀発表賞(受賞者:宮崎 晃一) 宮崎 晃一,林 知樹,戸田 智基,武田 一哉:颁罢颁に基づく音响イベントからの拟音语表现への変换,Sep. 2017 名古屋大学 情報学研究科 知能システム学専攻 戸田研究室
1 of 19



![擬音語に関連した研究
? 機械の異常音の擬音語表現 [Tanaka+1997]
– 故障の原因や兆候となる異常音を書き起こし
– シソーラス(擬音語類語辞書)としてまとめることで
工場内での意識の統一と作業の効率化
? 環境音を対象とした擬音語自動認識 [Ishihara+2014]
– 波形を音節ごとに分割し,分割した音節ごとに音素単位での認識
– 認識結果を結合し,聴こえ方の個人差を許容する手法を提案
2018/3/27
5](https://image.slidesharecdn.com/asj2017smiyazaki-180327054929/85/CTC-5-320.jpg)
![従来手法 [Ishihara+2014]
1. 音響波形から音節に相当する区間を推定
2. 音節区間を単発音をみなし音素認識
3. 認識した音素を連結し擬音語とする
2018/3/27
6
sh a r a r a r a
sh a r a r a r a
音節の分割精度が変換する擬音語へ大きく影響](https://image.slidesharecdn.com/asj2017smiyazaki-180327054929/85/CTC-6-320.jpg)
![Connectionist Temporal Classification (CTC)
[Graves+2006]
? 入力系列と出力系列の?さの違いを吸収する枠組み
? 出力にブランクシンボル (_) を追加し,RNNの出力に適用
2018/3/27
8
音響波形
特徴抽出
出力系列
推定文字列
概観
RNNに入力
a _ _ _ b
(ab)](https://image.slidesharecdn.com/asj2017smiyazaki-180327054929/85/CTC-8-320.jpg)




![実験条件
? 特徴量:Mel filter bank 40次元
? ネットワーク構成:3層BLSTM
– パラメータはグリッドサーチにより決定
2018/3/27
16
実験条件
フレームサイズ 40 [ms]
フレームシフト 20 [ms]
LSTM unit 512
学習率 0.0001
初期スケール 0.001
Time step 350
Batch size 128
Epochs 20](https://image.slidesharecdn.com/asj2017smiyazaki-180327054929/85/CTC-16-320.jpg)
![客観評価実験結果
? 単語誤り率(WER)と音素誤り率(PER)
? CTCを用いた場合の実際の出力例
2018/3/27
17
WER[%] PER[%]
CTC 46.00 20.49
正解ラベル CTC
p i p o N p i p o N
sh a r a r a r a sh a r a r a
k a ch a: k o t a k a N
k o: N k o: N
ch i N ch i N
提案法により擬音語へと変換できることを確認](https://image.slidesharecdn.com/asj2017smiyazaki-180327054929/85/CTC-17-320.jpg)
![主観評価実験結果
? 20代男女8名による50サンプルの評価
? 実際の聞こえ方(1: 許容できる,2: 許容できない)
2018/3/27
18
許容できる 許容できない
74.5 [%] 25.5 [%]
CTC 被験者A 被験者B 被験者C 被験者D
ピポン ピンポーン, 1 ピポン, 1 テレン, 2 ピコーン, 1
シャラララ シャラララ, 1 チリリリン, 1 チリンチリン, 2 リンリン, 2
変換結果の妥当性を確認
個人差の影響、一意に定まらない](https://image.slidesharecdn.com/asj2017smiyazaki-180327054929/85/CTC-18-320.jpg)

Ad
Recommended
End-to-End音声認識ためのMulti-Head Decoderネットワーク
End-to-End音声認識ためのMulti-Head DecoderネットワークNU_I_TODALAB
?
日本音響学会 2018年秋季研究発表会
林 知樹,渡部 晋治,戸田 智基,武田 一哉:End-to-End音声認識ためのMulti-Head Decoderネットワーク,Sep. 2018.
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室距离学习を导入した二値分类モデルによる异常音検知
距离学习を导入した二値分类モデルによる异常音検知NU_I_TODALAB
?
日本音響学会 2021年秋季研究発表会
畔栁 伊吹, 林 知樹, 武田 一哉, 戸田 智基:距离学习を导入した二値分类モデルによる异常音検知,Sep. 2021
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室环境音の特徴を活用した音响イベント検出?シーン分类
环境音の特徴を活用した音响イベント検出?シーン分类Keisuke Imoto
?
Presentation slide for AI seminar at Artificial Intelligence Research Center, The National Institute of Advanced Industrial Science and Technology, Japan.
URL (in Japanese): https://www.airc.aist.go.jp/seminar_detail/seminar_046.html深层生成モデルに基づく音声合成技术
深层生成モデルに基づく音声合成技术NU_I_TODALAB
?
第21回情報科学技術フォーラム(FIT2022)
招待講演
戸田 智基:深层生成モデルに基づく音声合成技术,Sep. 2022
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパスShinnosuke Takamichi
?
言語処理学会 第28回年次大会 (NLP2022)
G8:音声言語処理 G8-1リアルタイム顿狈狈音声変换フィードバックによるキャラクタ性の获得手法
リアルタイム顿狈狈音声変换フィードバックによるキャラクタ性の获得手法Shinnosuke Takamichi
?
The document describes a real-time DNN voice conversion system with feedback to acquire character traits. It proposes a method to provide real-time feedback of the converted voice to the speaker to encourage speech modification (prosody and emphasis) towards the target speaker's character. Subjective evaluations from the first-person (user) perspective and third-person perspective found that the system improved the reproduction of the target speaker's character, especially for inexperienced users. Providing only pitch feedback was already quite effective.Deep Neural Networkに基づく日常生活行動認識における適応手法
Deep Neural Networkに基づく日常生活行動認識における適応手法NU_I_TODALAB
?
2016年8月 音声研究会
オーガナイズドセッション「あらゆる音を対象とした情報処理の実現に向けて」
林 知樹,北岡 教英, 戸田 智基, 武田 一哉:Deep Neural Networkに基づく日常行動認識における適応手法,Aug. 2016
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank...
独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank...Daichi Kitamura
?
北村大地, "独立低ランク行列分析に基づく音源分離とその発展," IEICE信号処理研究会, 2021年8月24日.
Daichi Kitamura, "Audio source separation based on independent low-rank matrix analysis and its extensions," IEICE Technical Group on Signal Processing, Aug. 24th, 2021.
http://d-kitamura.net叠贰搁罢入门
叠贰搁罢入门Ken'ichi Matsui
?
Two sentences are tokenized and encoded by a BERT model. The first sentence describes two kids playing with a green crocodile float in a swimming pool. The second sentence describes two kids pushing an inflatable crocodile around in a pool. The tokenized sentences are passed through the BERT model, which outputs the encoded representations of the token sequences.Neural scene representation and rendering の解説(第3回3D勉強会@関東)
Neural scene representation and rendering の解説(第3回3D勉強会@関東)Masaya Kaneko
?
第3回3D勉強会@関東(DeepSLAM大会)で発表した資料です
https://3dvision.connpass.com/event/100054/【DL輪読会】Bridge-Prompt: Toward Ordinal Action Understanding in Instructional Vi...
【DL輪読会】Bridge-Prompt: Toward Ordinal Action Understanding in Instructional Vi...Deep Learning JP
?
2023/3/3
Deep Learning JP
http://deeplearning.jp/seminar-2/やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析Shinnosuke Takamichi
?
音声分析法のであるケプストラム分析とLPC分析について、
簡単に説明したものです。
音声研究の初学者向け。
twitter: forthshinji骋社の狈惭罢论文を読んでみた
骋社の狈惭罢论文を読んでみたToshiaki Nakazawa
?
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
http://arxiv.org/abs/1609.08144
を読んでみたので、簡単にまとめました。間違い等は是非ご指摘ください。Neural text-to-speech and voice conversion
Neural text-to-speech and voice conversionYuki Saito
?
Lecture presentation at Advanced Signal Processing (Graduate School of Information Science and Technology, University of Tokyo, Japan)机械学习モデルの判断根拠の説明(痴别谤.2)
机械学习モデルの判断根拠の説明(痴别谤.2)Satoshi Hara
?
【第40回AIセミナー】
「説明できるAI ?AIはブラックボックスなのか??」
https://www.airc.aist.go.jp/seminar_detail/seminar_040.html
【講演タイトル】
機械学習モデルの判断根拠の説明
【講演概要】
本講演では、機械学習モデルの判断根拠を提示するための説明法について紹介する。高精度な認識?識別が可能な機械学習モデルは一般に非常に複雑な構造をしており、どのような基準で判断が下されているかを人間が窺い知ることは困難である。このようなモデルのブラックボックス性を解消するために、近年様々なモデルの説明法が研究?提案されてきている。本講演ではこれら近年の代表的な説明法について紹介する。文献紹介:SlowFast Networks for Video Recognition
文献紹介:SlowFast Networks for Video RecognitionToru Tamaki
?
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, Kaiming He, SlowFast Networks for Video Recognition, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 6202-6211
https://openaccess.thecvf.com/content_ICCV_2019/html/Feichtenhofer_SlowFast_Networks_for_Video_Recognition_ICCV_2019_paper.htmlSSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法SSII
?
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
6月10日 (木) 11:00 - 12:30 メイン会場(vimeo + sli.do)
登壇者:松井 孝太 氏(名古屋大学)
概要:転移学習とは、解きたいタスクに対して、それと異なるが似ている他のタスクからの知識(データ、特徴、モデルなど)を利用するための方法を与える機械学習のフレームワークです。深層モデルの学習方法として広く普及している事前学習モデルの利用は、この広義の転移学習の一つの実現形態とみなせます。本発表では、まず何をいつ転移するのか (what/when to transfer) といった転移学習の基本概念と定式化を説明し、具体的な転移学習の主要なアプローチとしてドメイン適応、メタ学習について解説します。ICASSP 2019での音響信号処理分野の世界動向
ICASSP 2019での音響信号処理分野の世界動向Yuma Koizumi
?
ICASSP 2019音声&音響論文読み会(https://connpass.com/event/128527/)での発表資料です。
AASP (Audio and Acoustic Signal Processing) 分野の紹介と、ICASSP 2019での動向を紹介しています。#icassp2019jp摆顿尝轮読会闭骋蚕狈と関连研究,世界モデルとの関係について
摆顿尝轮読会闭骋蚕狈と関连研究,世界モデルとの関係についてDeep Learning JP
?
2018/08/17
Deep Learning JP:
http://deeplearning.jp/seminar-2/ A Brief Introduction of Anomalous Sound Detection: Recent Studies and Future...
A Brief Introduction of Anomalous Sound Detection: Recent Studies and Future...Yuma Koizumi
?
Yuma Koizumi presents an overview of anomalous sound detection (ASD), discussing recent challenges and future prospects, particularly in unsupervised settings. The presentation highlights the difficulties of detecting anomalies due to the unpredictability of data patterns and emphasizes the need for innovative approaches to training models with limited labeled data. Additionally, it addresses the impact of domain shifts on detection systems and suggests adaptations using few-shot learning techniques.【論文読み会】Self-Attention Generative Adversarial Networks
【論文読み会】Self-Attention Generative Adversarial NetworksARISE analytics
?
論文「Self-Attention Generative Adversarial Networks」について輪読した際の資料です。Onoma-to-wave: オノマトペを利用した環境音合成手法の提案
Onoma-to-wave: オノマトペを利用した環境音合成手法の提案Keisuke Imoto
?
日本音響学会2021年春季研究発表会 2-2-5
Demo page: https://y-okamoto1221.github.io/IJCNN_Demonstration_jp/More Related Content
What's hot (20)
Deep Neural Networkに基づく日常生活行動認識における適応手法
Deep Neural Networkに基づく日常生活行動認識における適応手法NU_I_TODALAB
?
2016年8月 音声研究会
オーガナイズドセッション「あらゆる音を対象とした情報処理の実現に向けて」
林 知樹,北岡 教英, 戸田 智基, 武田 一哉:Deep Neural Networkに基づく日常行動認識における適応手法,Aug. 2016
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank...
独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank...Daichi Kitamura
?
北村大地, "独立低ランク行列分析に基づく音源分離とその発展," IEICE信号処理研究会, 2021年8月24日.
Daichi Kitamura, "Audio source separation based on independent low-rank matrix analysis and its extensions," IEICE Technical Group on Signal Processing, Aug. 24th, 2021.
http://d-kitamura.net叠贰搁罢入门
叠贰搁罢入门Ken'ichi Matsui
?
Two sentences are tokenized and encoded by a BERT model. The first sentence describes two kids playing with a green crocodile float in a swimming pool. The second sentence describes two kids pushing an inflatable crocodile around in a pool. The tokenized sentences are passed through the BERT model, which outputs the encoded representations of the token sequences.Neural scene representation and rendering の解説(第3回3D勉強会@関東)
Neural scene representation and rendering の解説(第3回3D勉強会@関東)Masaya Kaneko
?
第3回3D勉強会@関東(DeepSLAM大会)で発表した資料です
https://3dvision.connpass.com/event/100054/【DL輪読会】Bridge-Prompt: Toward Ordinal Action Understanding in Instructional Vi...
【DL輪読会】Bridge-Prompt: Toward Ordinal Action Understanding in Instructional Vi...Deep Learning JP
?
2023/3/3
Deep Learning JP
http://deeplearning.jp/seminar-2/やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析Shinnosuke Takamichi
?
音声分析法のであるケプストラム分析とLPC分析について、
簡単に説明したものです。
音声研究の初学者向け。
twitter: forthshinji骋社の狈惭罢论文を読んでみた
骋社の狈惭罢论文を読んでみたToshiaki Nakazawa
?
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
http://arxiv.org/abs/1609.08144
を読んでみたので、簡単にまとめました。間違い等は是非ご指摘ください。Neural text-to-speech and voice conversion
Neural text-to-speech and voice conversionYuki Saito
?
Lecture presentation at Advanced Signal Processing (Graduate School of Information Science and Technology, University of Tokyo, Japan)机械学习モデルの判断根拠の説明(痴别谤.2)
机械学习モデルの判断根拠の説明(痴别谤.2)Satoshi Hara
?
【第40回AIセミナー】
「説明できるAI ?AIはブラックボックスなのか??」
https://www.airc.aist.go.jp/seminar_detail/seminar_040.html
【講演タイトル】
機械学習モデルの判断根拠の説明
【講演概要】
本講演では、機械学習モデルの判断根拠を提示するための説明法について紹介する。高精度な認識?識別が可能な機械学習モデルは一般に非常に複雑な構造をしており、どのような基準で判断が下されているかを人間が窺い知ることは困難である。このようなモデルのブラックボックス性を解消するために、近年様々なモデルの説明法が研究?提案されてきている。本講演ではこれら近年の代表的な説明法について紹介する。文献紹介:SlowFast Networks for Video Recognition
文献紹介:SlowFast Networks for Video RecognitionToru Tamaki
?
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, Kaiming He, SlowFast Networks for Video Recognition, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 6202-6211
https://openaccess.thecvf.com/content_ICCV_2019/html/Feichtenhofer_SlowFast_Networks_for_Video_Recognition_ICCV_2019_paper.htmlSSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法SSII
?
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
6月10日 (木) 11:00 - 12:30 メイン会場(vimeo + sli.do)
登壇者:松井 孝太 氏(名古屋大学)
概要:転移学習とは、解きたいタスクに対して、それと異なるが似ている他のタスクからの知識(データ、特徴、モデルなど)を利用するための方法を与える機械学習のフレームワークです。深層モデルの学習方法として広く普及している事前学習モデルの利用は、この広義の転移学習の一つの実現形態とみなせます。本発表では、まず何をいつ転移するのか (what/when to transfer) といった転移学習の基本概念と定式化を説明し、具体的な転移学習の主要なアプローチとしてドメイン適応、メタ学習について解説します。ICASSP 2019での音響信号処理分野の世界動向
ICASSP 2019での音響信号処理分野の世界動向Yuma Koizumi
?
ICASSP 2019音声&音響論文読み会(https://connpass.com/event/128527/)での発表資料です。
AASP (Audio and Acoustic Signal Processing) 分野の紹介と、ICASSP 2019での動向を紹介しています。#icassp2019jp摆顿尝轮読会闭骋蚕狈と関连研究,世界モデルとの関係について
摆顿尝轮読会闭骋蚕狈と関连研究,世界モデルとの関係についてDeep Learning JP
?
2018/08/17
Deep Learning JP:
http://deeplearning.jp/seminar-2/ A Brief Introduction of Anomalous Sound Detection: Recent Studies and Future...
A Brief Introduction of Anomalous Sound Detection: Recent Studies and Future...Yuma Koizumi
?
Yuma Koizumi presents an overview of anomalous sound detection (ASD), discussing recent challenges and future prospects, particularly in unsupervised settings. The presentation highlights the difficulties of detecting anomalies due to the unpredictability of data patterns and emphasizes the need for innovative approaches to training models with limited labeled data. Additionally, it addresses the impact of domain shifts on detection systems and suggests adaptations using few-shot learning techniques.【論文読み会】Self-Attention Generative Adversarial Networks
【論文読み会】Self-Attention Generative Adversarial NetworksARISE analytics
?
論文「Self-Attention Generative Adversarial Networks」について輪読した際の資料です。Onoma-to-wave: オノマトペを利用した環境音合成手法の提案
Onoma-to-wave: オノマトペを利用した環境音合成手法の提案Keisuke Imoto
?
日本音響学会2021年春季研究発表会 2-2-5
Demo page: https://y-okamoto1221.github.io/IJCNN_Demonstration_jp/Similar to 颁罢颁に基づく音响イベントからの拟音语表现への変换 (20)
日本語音声合成のためのsubword内モーラを考慮したProsody-aware subword embedding
日本語音声合成のためのsubword内モーラを考慮したProsody-aware subword embeddingShinnosuke Takamichi
?
日本音響学会2018年春季研究発表会講演論文集 "日本語音声合成のためのsubword内モーラを考慮したProsody-aware subword embedding" Deep-Learning-Based Environmental Sound Segmentation - Integration of Sound ...
Deep-Learning-Based Environmental Sound Segmentation - Integration of Sound ...Yui Sudo
?
本研究は、人間とロボットの高度なインタラクションを目指し、マイクで観測された信号から、音源信号や音源のクラスなど、様々な環境音を理解することを目的としている。具体的には、様々な種類の環境音に対して、能動節検出、音源定位、音源分離、分類を行う「環境音セグメンテーション」に着目した研究である。
近年、人間とロボットのインタラクションを実現するために、自動音声認識や音声合成の研究が盛んに行われています。実世界での応用では、騒音や複数の音響事象に起因するロバストな手法が求められる。音響信号処理、ロボット聴覚、機械学習の分野では、複数の音響事象が重なり合う実環境で利用するために、音源定位、音源分離、分類などの様々な手法が提案されています。
従来のアプローチでは、アレイ信号処理技術に基づく個々の関数を組み込んだカスケード方式が用いられています。この手法の最大の問題は、各機能で発生する誤差の蓄積である。各機能は全体のタスクに関係なく独立して最適化されるため、それぞれの出力が後続のブロックに最適でない可能性がある。
近年、従来のカスケード方式を用いない1チャンネルマイクロホンを用いた深層学習によるEnd to End方式が提案されています。これらの研究により、区間検出、音源定位、音源分離、分類といった複数の機能を1つのネットワーク上で同時に実行することが可能になりました。しかし、これまでの研究の多くは、音声とそれ以外の音の2つのクラスのみを対象としており、環境音のような複数のクラスの音を対象とした研究はほとんどない。より汎用的なインタラクションを行う上で、ロボットは人の声だけでなく、多くのクラスが含まれる環境音を分離する必要がある。このような人間の声を対象とした手法は、複数のクラスを含む環境音に拡張することができる。しかし、音の持続時間や周波数成分はクラスによって大きく異なるため、性能が低下する可能性がある。また、複数の音源が重なっている場合、1チャンネルのマイクでは空間的な特徴を利用できないため、性能が低下する。
そこで、マルチチャンネルを用いた手法が提案されている。これらの手法は、音源の到来方向に依存する空間的な特徴を利用することで、音源定位や音源分離の性能を向上させることができる。しかし,環境音の分割では,音源定位や音源分離に加えて,スペクトル特徴を利用した分類を行う必要がある.通常、音源とマイクロホンの相対角度は一定ではないため、到来方向とクラスは互いに相関がない。そのため、これらの特徴を同時に用いる環境音セグメンテーションでは、到着方向とクラスの関係にネットワークが過剰に適合してしまう。
本論文では、従来のカスケード手法のような誤差の蓄積を防ぐため、区間検出、音源定位、音源分離、分類を統合したディープラーニングに基づく環境音セグメンテーション手法を提案する。また、多チャンネル環境音セグメンテーションにおいて、スペクトル特徴と空間特徴を同時に扱う方法を提案する。中間?語モデルを?いた 多?語機械翻訳の精度向上
中間?語モデルを?いた 多?語機械翻訳の精度向上奈良先端大 情報科学研究科
?
本论文は、翻訳対象となる言语対に十分な量の対訳データが得られない场合に、第叁の言语を中间言语として利用するピボット翻訳手法の新しい実装法を提案し、翻訳精度を大きく改善できることを示した。本论文は、今后、英语を介した日本语とアジア言语の翻訳のような语顺が大きく异なる言语対への适用が期待できるなど、ピボット翻訳に関する新しい研究の方向性と発展の可能性を示している。 [DL輪読会]Towards End-to-End Prosody Transfer for Expressive Speech Synthesis wi...
[DL輪読会]Towards End-to-End Prosody Transfer for Expressive Speech Synthesis wi...Deep Learning JP
?
2021/06/25
Deep Learning JP:
http://deeplearning.jp/seminar-2/日本音響学会春季発表会2017 「コンテキスト事後確率のSequence-to-Sequence学習を用いた音声変換」
日本音響学会春季発表会2017 「コンテキスト事後確率のSequence-to-Sequence学習を用いた音声変換」Hiroyuki Miyoshi
?
ASJ2017S
Voice Convesion Using Sequence-to-Sequence Learning of Context Posterior ProbabilitiesAd
More from NU_I_TODALAB (20)
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」NU_I_TODALAB
?
音学シンポジウム2025
第156回音声言語情報処理研究発表会
招待講演
米山 怜於:ニューラルボコーダ概説:生成モデルと実用性の観点から,2025年6月
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室2025年3月音楽情报科学研究会「大局的构造生成のための小节特徴量系列モデリングに基づく阶层的自动作曲」
2025年3月音楽情报科学研究会「大局的构造生成のための小节特徴量系列モデリングに基づく阶层的自动作曲」NU_I_TODALAB
?
音楽情報科学研究会
澤田 桂都,Wen-Chin Huang,戸田 智基:大局的構造生成のための小節特徴量系列モデリングに基づく階層的自動作曲,2025年3月
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室2025年5月応用音响研究会「滨颁础厂厂笔2025における音楽情报処理の动向」
2025年5月応用音响研究会「滨颁础厂厂笔2025における音楽情报処理の动向」NU_I_TODALAB
?
応用音響研究会
橋爪 優果:ICASSP2025における音楽情報処理の動向,2025年5月
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室2025年5月応用音响研究会「滨颁础厂厂笔2025における异常音検知の动向」
2025年5月応用音响研究会「滨颁础厂厂笔2025における异常音検知の动向」NU_I_TODALAB
?
応用音響研究会
藤村 拓弥:ICASSP2025における異常音検知の動向,2025年5月
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室Automatic Quality Assessment for Speech and Beyond
Automatic Quality Assessment for Speech and BeyondNU_I_TODALAB
?
Mila Conversational AI reading group
Wen-Chin Huang:Automatic Quality Assessment for Speech and Beyond,May 2025
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室异常音検知に対する深层学习适用事例
异常音検知に対する深层学习适用事例NU_I_TODALAB
?
第144回ロボット工学セミナー「ロボットのための音声?音響処理技術」日本ロボット学会
戸田 智基:异常音検知に対する深层学习适用事例,Nov. 2022
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室信号の独立性に基づく多チャンネル音源分离
信号の独立性に基づく多チャンネル音源分离NU_I_TODALAB
?
令和四年度 電気?電子?情報関係学会 東海支部連合大会
招待講演
李 莉:信号の独立性に基づく多チャンネル音源分离,Aug. 2022
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室
The VoiceMOS Challenge 2022
The VoiceMOS Challenge 2022NU_I_TODALAB
?
The VoiceMOS Challenge 2022 aimed to encourage research in automatic prediction of mean opinion scores (MOS) for speech quality. It featured two tracks evaluating systems' ability to predict MOS ratings from a large existing dataset or a separate listening test. 21 teams participated in the main track and 15 in the out-of-domain track. Several teams outperformed the best baseline, which fine-tuned a self-supervised model, though the top-performing approaches generally involved ensembling or multi-task learning. While unseen systems were predictable, unseen listeners and speakers remained a difficulty, especially for generalizing to a new test. The challenge highlighted progress in MOS prediction but also the need for metrics reflecting both ranking and absolute accuracy敌対的学习による统合型ソースフィルタネットワーク
敌対的学习による统合型ソースフィルタネットワークNU_I_TODALAB
?
日本音響学会 2021年秋季研究発表会
米山 怜於, Yi-Chiao Wu, 戸田 智基:敌対的学习による统合型ソースフィルタネットワーク,Sep. 2021
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室Investigation of Text-to-Speech based Synthetic Parallel Data for Sequence-to...
Investigation of Text-to-Speech based Synthetic Parallel Data for Sequence-to...NU_I_TODALAB
?
This document investigates the use of synthetic parallel data (SPD) to enhance non-parallel voice conversion (VC) through sequence-to-sequence modeling. The study evaluates the feasibility and influence of SPD on VC performance, analyzing various training pairs and the effectiveness of semiparallel datasets. Findings indicate that SPD is viable for VC, but its success depends on the training data quality and the size of the dataset used.Interactive voice conversion for augmented speech production
Interactive voice conversion for augmented speech productionNU_I_TODALAB
?
This document discusses recent progress in interactive voice conversion techniques for augmenting speech production. It begins by explaining the physical limitations of normal speech production and how voice conversion can augment speech by controlling more information. It then discusses how interactive voice conversion allows for quick response times, better controllability through real-time feedback, and understanding user intent from multimodal behavior signals. Recent advances discussed include low-latency voice conversion networks, controllable waveform generation respecting the source-filter model of speech, and expression control using signals like arm movements. The goal is to develop cooperatively augmented speech that can help users with lost speech abilities.颁搁贰厂罢「共生インタラクション」共创型音メディア机能拡张プロジェクト
颁搁贰厂罢「共生インタラクション」共创型音メディア机能拡张プロジェクトNU_I_TODALAB
?
第135回音声言語情報処理研究会
招待講演
戸田 智基:颁搁贰厂罢「共生インタラクション」共创型音メディア机能拡张プロジェクト,Feb. 2021
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室Recent progress on voice conversion: What is next?
Recent progress on voice conversion: What is next?NU_I_TODALAB
?
The document discusses recent advancements in voice conversion (VC) techniques, emphasizing the importance of preserving linguistic content while modifying non-linguistic features. It outlines the Voice Conversion Challenges (VCC) from 2016 to 2020, highlighting different training methods and the role of neural vocoders. The paper also suggests future directions for VC research, focusing on improving performance, developing interactive applications, and exploring higher-level feature conversions.Weakly-Supervised Sound Event Detection with Self-Attention
Weakly-Supervised Sound Event Detection with Self-AttentionNU_I_TODALAB
?
This document presents a weakly-supervised sound event detection method using self-attention, aiming to enhance detection performance through the utilization of weak label data. The proposed approach introduces a special tag token for weak label handling and employs a transformer encoder for improved sequence modeling, achieving performance improvements from a baseline CRNN model. Experimental results indicate a notable increase in sound event detection accuracy, with the new method outperforming the baseline in various evaluation metrics.Statistical voice conversion with direct waveform modeling
Statistical voice conversion with direct waveform modelingNU_I_TODALAB
?
This document provides an outline for a tutorial on voice conversion techniques. It begins with an introduction to the goal of the tutorial, which is to help participants grasp the basics and recent progress of VC, develop a baseline VC system, and develop a more sophisticated system using a neural vocoder. The tutorial will include an overview of VC techniques, introduction of freely available software for building a VC system, and breaks between sessions. The first session will cover the basics of VC, improvements to VC techniques, and an overview of recent progress in direct waveform modeling. The second session will demonstrate how to develop a VC system using the WaveNet vocoder with freely available tools.音素事后确率を利用した表现学习に基づく発话感情认识
音素事后确率を利用した表现学习に基づく発话感情认识NU_I_TODALAB
?
日本音響学会 2019年春季研究発表会
岡田 慎太郎,安藤 厚志,戸田 智基:音素事后确率を利用した表现学习に基づく発话感情认识,Mar. 2019
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室 楽曲中歌声加工における声质変换精度向上のための歌声?伴奏分离法
楽曲中歌声加工における声质変换精度向上のための歌声?伴奏分离法NU_I_TODALAB
?
第33回信号処理シンポジウム
山田 智也,関 翔悟,小林 和弘,戸田 智基:楽曲中歌声加工における声质変换精度向上のための歌声?伴奏分离法,Nov. 2018.
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室空気/体内伝导マイクロフォンを用いた雑音环境下における自己発声音强调/抑圧法
空気/体内伝导マイクロフォンを用いた雑音环境下における自己発声音强调/抑圧法NU_I_TODALAB
?
日本音響学会 2018年秋季研究発表会
高田 萌絵,関 翔悟,戸田 智基:空気/体内伝导マイクロフォンを用いた雑音环境下における自己発声音强调/抑圧法,Sep. 2018
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室时间领域低ランクスペクトログラム近似法に基づくマスキング音声の欠损成分復元
时间领域低ランクスペクトログラム近似法に基づくマスキング音声の欠损成分復元NU_I_TODALAB
?
日本音響学会 2017年春季研究発表会
関 翔悟,亀岡 弘和,戸田 智基,武田 一哉:时间领域低ランクスペクトログラム近似法に基づくマスキング音声の欠损成分復元,Mar. 2017
名古屋大学 情報学研究科 知能システム学専攻 戸田研究室Hands on Voice Conversion
Hands on Voice ConversionNU_I_TODALAB
?
The document outlines a hands-on workshop for developing voice conversion (VC) systems using open-source software called Sprocket, created by Nagoya University. It details the process of building a traditional GMM-based VC and includes instructions for installing the software, preparing datasets, and configuring the system for speaker conversion. The overall goal is to provide participants with the knowledge and tools needed to initiate their own VC research and development.Ad
颁罢颁に基づく音响イベントからの拟音语表现への変换
- 2. はじめに ? 研究背景 – さまざまな音を対象とした音環境理解 ? 音環境認識,音響イベント検出 – 環境音は音声言語のような記号表現を持たない ? 応用先が限定的 ? 統一的に扱うこと自体が困難 ? 研究目的 2018/3/27 2 擬音語に着目した共有可能な表現の獲得
- 3. なぜ擬音語を用いるか ? 本研究で扱う擬音語 – もの自体が発している音の文字による書き起こし ? 擬音語で表現することの利点 – 日常生活の中で頻繁に利用されており親密度が高い – 擬音語を基に音源の情報や状態を推論できる ? 他者と共有可能 2018/3/27 3
- 4. 本研究の概要 ? CTCに基づいた音響イベントから擬音語への変換法を提案 – 既存の音声認識システムはそのまま適用できない – 単一のネットワークを用いた変換 ? 従来手法と比較して前処理の必要なし ? 主観評価実験と客観評価実験により妥当性を評価 2018/3/27 4 既存の音声認識システム 提案法 チヒヒウウウン シャララ 擬音語提案法
- 5. 擬音語に関連した研究 ? 機械の異常音の擬音語表現 [Tanaka+1997] – 故障の原因や兆候となる異常音を書き起こし – シソーラス(擬音語類語辞書)としてまとめることで 工場内での意識の統一と作業の効率化 ? 環境音を対象とした擬音語自動認識 [Ishihara+2014] – 波形を音節ごとに分割し,分割した音節ごとに音素単位での認識 – 認識結果を結合し,聴こえ方の個人差を許容する手法を提案 2018/3/27 5
- 6. 従来手法 [Ishihara+2014] 1. 音響波形から音節に相当する区間を推定 2. 音節区間を単発音をみなし音素認識 3. 認識した音素を連結し擬音語とする 2018/3/27 6 sh a r a r a r a sh a r a r a r a 音節の分割精度が変換する擬音語へ大きく影響
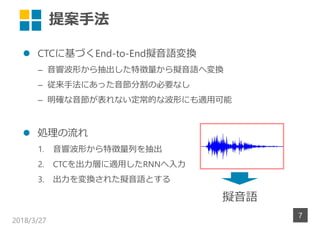
- 7. 提案手法 ? CTCに基づくEnd-to-End擬音語変換 – 音響波形から抽出した特徴量から擬音語へ変換 – 従来手法にあった音節分割の必要なし – 明確な音節が表れない定常的な波形にも適用可能 ? 処理の流れ 1. 音響波形から特徴量列を抽出 2. CTCを出力層に適用したRNNへ入力 3. 出力を変換された擬音語とする 2018/3/27 7 擬音語
- 8. Connectionist Temporal Classification (CTC) [Graves+2006] ? 入力系列と出力系列の?さの違いを吸収する枠組み ? 出力にブランクシンボル (_) を追加し,RNNの出力に適用 2018/3/27 8 音響波形 特徴抽出 出力系列 推定文字列 概観 RNNに入力 a _ _ _ b (ab)
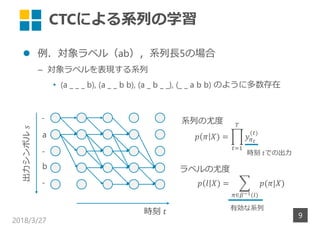
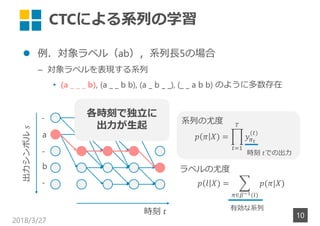
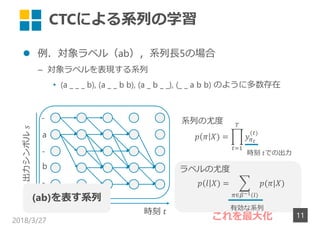
- 9. CTCによる系列の学習 ? 例.対象ラベル(ab),系列?5の場合 – 対象ラベルを表現する系列 ? (a _ _ _ b), (a _ _ b b), (a _ b _ _), (_ _ a b b) のように多数存在 2018/3/27 9 a b - - - ( ) ∈ ( ) 時刻 出力シンボル? 時刻 での出力 系列の尤度 ラベルの尤度 有効な系列
- 10. CTCによる系列の学習 ? 例.対象ラベル(ab),系列?5の場合 – 対象ラベルを表現する系列 ? (a _ _ _ b), (a _ _ b b), (a _ b _ _), (_ _ a b b) のように多数存在 2018/3/27 10 a b - - - ( ) ∈ ( ) 時刻 出力シンボル? 時刻 での出力 系列の尤度 ラベルの尤度 有効な系列 各時刻で独立に 出力が生起
- 11. CTCによる系列の学習 ? 例.対象ラベル(ab),系列?5の場合 – 対象ラベルを表現する系列 ? (a _ _ _ b), (a _ _ b b), (a _ b _ _), (_ _ a b b) のように多数存在 2018/3/27 11 a b - - - ( ) ∈ ( ) 時刻 出力シンボル? 時刻 での出力 系列の尤度 ラベルの尤度 有効な系列 (ab)を表す系列 これを最大化
- 13. 実験概要 ? 客観評価実験 – 変換された擬音語が所望の擬音語をどれだけ再現できているか – 単語誤り率(WER)と音素誤り率(PER)で評価 ? 主観評価実験 – 擬音語は受聴者の感性によって聞こえ方が異なる – 変換された擬音語の妥当性を評価するため, 被験者は音響信号と擬音語を提示し許容可能かどうかを判断する 2018/3/27 13
- 14. 使用するデータベース ? RWCP実環境音声?音響データベース(RWCP-SSD) – 100クラスの音響イベントが合計で9720サンプル存在 – 学習:9120サンプル,検証:500サンプル,テスト:100サンプル ? 擬音語ラベルの付与 – RWCP-SSDに含まれる全ての音響イベントサンプルに対して 成人男性1名の主観による擬音語ラベルを付与 2018/3/27 14
- 15. ラベル付のルール ? 聞こえたとおりに主観でカタカナに書き起こし ? 歯切れのいい音は~ッ(促音) ? 余韻がある音は~-(?音) ? キリよく終わる音は~ン(撥音) ? ?音の数はひとつで固定連続する音は適当に打ち止め ? 音高の変化は考慮しない 2018/3/27 15
- 16. 実験条件 ? 特徴量:Mel filter bank 40次元 ? ネットワーク構成:3層BLSTM – パラメータはグリッドサーチにより決定 2018/3/27 16 実験条件 フレームサイズ 40 [ms] フレームシフト 20 [ms] LSTM unit 512 学習率 0.0001 初期スケール 0.001 Time step 350 Batch size 128 Epochs 20
- 17. 客観評価実験結果 ? 単語誤り率(WER)と音素誤り率(PER) ? CTCを用いた場合の実際の出力例 2018/3/27 17 WER[%] PER[%] CTC 46.00 20.49 正解ラベル CTC p i p o N p i p o N sh a r a r a r a sh a r a r a k a ch a: k o t a k a N k o: N k o: N ch i N ch i N 提案法により擬音語へと変換できることを確認
- 18. 主観評価実験結果 ? 20代男女8名による50サンプルの評価 ? 実際の聞こえ方(1: 許容できる,2: 許容できない) 2018/3/27 18 許容できる 許容できない 74.5 [%] 25.5 [%] CTC 被験者A 被験者B 被験者C 被験者D ピポン ピンポーン, 1 ピポン, 1 テレン, 2 ピコーン, 1 シャラララ シャラララ, 1 チリリリン, 1 チリンチリン, 2 リンリン, 2 変換結果の妥当性を確認 個人差の影響、一意に定まらない
- 19. おわりに ? まとめ – 颁罢颁に基づく音响イベントからの拟音语表现への変换を提案 – 提案手法により許容可能な擬音語へ変換できることを確認 ? 今後の課題 – 幅広い音響イベントを対象とした擬音語変換や精度の向上 – 擬音語表現の曖昧性を考慮した変換処理の検討 ? 代表的な擬音語への変換 ? 聴取者の感性に沿った擬音語への変換 2018/3/27 19