Oracle Big Data Discovery - ludzka twarz Hadoop'a
2 likes1,259 views

Osza┼éamiaj─ģce wizualnie, intuicyjne rozwi─ģzanie, kt├│re pozwala wykorzysta─ć potencja┼é Hadoop i przekszta┼éci─ć surowe dane w nowe odkrycia w ci─ģgu kilku minut, bez potrzeby uczenia si─Ö skomplikowanych rozwi─ģza┼ä przeznaczonych dla w─ģskiego grona specjalist├│w.

















Oracle Big Data Discovery - ludzka twarz Hadoop'a
- 2. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Big Data Discovery... ...ludzka twarz Hadoop'a Oracle Confidential ŌĆō Internal Filip Kaznowski ŌĆō Cloud & Big Data LeadŌĆōECE Region, Consulting Micha┼é Grochowski ŌĆō BI Architect, Pre-sales Data Science Meetup, 12 maja 2015
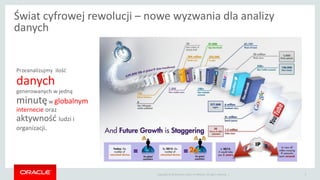
- 3. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | ┼Üwiat cyfrowej rewolucji ŌĆō nowe wyzwania dla analizy danych 3 Przeanalizujmy ilo┼ø─ć danych generowanych w jedn─ģ minut─Öw globalnym internecie oraz aktywno┼ø─ć ludzi i organizacji.
- 4. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Struktura danychŌĆ×on WriteŌĆØ vs ŌĆ×on ReadŌĆØ ŌĆó Tradycyjna struktura danych ŌĆ£on WriteŌĆØ ŌĆō Dane musz─ģ by─ć zidentyfikowane i zamodelowane w okre┼ølonej strukturze ŌĆō W kolejnych krokach dane s─ģ przetwarzane i ┼éadowane w procesie ETL ŌĆō Analiza danych mo┼╝liwa po zako┼äczeniu przetwarzania ŌĆó Struktura danych Big Data ŌĆ£on ReadŌĆØ ŌĆō Dane ┼║r├│d┼éowe bezpo┼ørednio dost─Öpne w narz─Ödziach analitycznych ŌĆō Przetwarzanie danych poprzez algorytmy map/reduce lub rozproszone przetwarzanie w pami─Öci Elastyczno┼ø─ć i szybko┼ø─ć analizy danych
- 5. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Analiza du┼╝ych wolumen├│w danych niestrukturalnych Szczeg├│┼éowa analiza danych niezagregowanych = Odkrycia nowych zwi─ģzk├│w i zale┼╝no┼øci = Skuteczniejsze decyzje
- 6. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | ŌĆó M─Ö┼╝czyzna, urodzony w 1948 ŌĆó Wychowany w Anglii ŌĆó Dwukrotnie ┼╝onaty, dziecko ŌĆó Bogaty celebryta ŌĆó Kocha psy ŌĆó Uwielbia sp─Ödza─ć czas w Alpach Jak dobrze znamy w┼éasnych klient├│w? Oracle Confidential ŌĆō Internal/Restricted/Highly Restricted | #BeyondBigData
- 7. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential ŌĆō Internal/Restricted/Highly Restricted 7 DNA Klienta ’é¦Analiza zachowania i interakcji ’é¦Szczeg├│┼éowe profilowanie ’é¦Analiza danych spo┼éeczno┼øciowych "We donŌĆÖt have better algorithms. We just have more data.ŌĆ£ Peter Norvig, Google's Research Director
- 8. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Czy potrafimy wystarczaj─ģco szybko analizowa─ć strumie┼ä danych? 8 Z┼éo┼╝ono┼ø─ć narz─Ödzi ŌĆó Wi─Ökszo┼ø─ć narz─Ödzi Hadoop wymaga wiedzy eksperckiej ŌĆó Narz─Ödzia BI nie s─ģ dostowane do specyfiki Hadoop ŌĆó Nowe technologie nie s─ģ wystarczaj─ģco wszechstronne Du┼╝e nak┼éady pracy: ocena przydatno┼øci i przygotowanie danych Z┼éo┼╝ono┼ø─ć danych ŌĆó R├│┼╝norodno┼ø─ć i wielko┼ø─ć danych ŌĆó Przydatno┼ø─ć danych trudna do oszacowania ŌĆó Wymagane z┼éo┼╝one transformacje Nieb─Ödne specjalistyczne kompetencje
- 9. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential ŌĆō Internal 9
- 10. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential | Business Analytics Product Group Jakie narz─Ödzia s─ģ wykorzystywane w analizie danych? Source: OŌĆÖReilly: 2013 Data Science Salary Survey
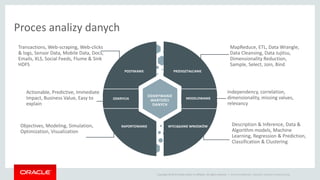
- 11. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential | Business Analytics Product Group Proces analizy danych Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | RAPORTOWANIE POZYSKANIE PRZEKSZTA┼üCANIE WYCI─äGANIE WNIOSK├ōW ODKRYWANIE WARTO┼ÜCI DANYCH Independency, correlation, dimensionality, missing values, relevancy Objectives, Modeling, Simulation, Optimization, Visualization Transactions, Web-scraping, Web-clicks & logs, Sensor Data, Mobile Data, Docs, Emails, XLS, Social Feeds, Flume & Sink HDFS MapReduce, ETL, Data Wrangle, Data Cleansing, Data Jujitsu, Dimensionality Reduction, Sample, Select, Join, Bind MODELOWANIEODKRYCIA Actionable, Predictive, Immediate Impact, Business Value, Easy to explain Description & Inference, Data & Algorithm models, Machine Learning, Regression & Prediction, Classification & Clustering
- 12. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential | Business Analytics Product Group Proces analizy danych ŌĆō w─ģskie gard┼éa Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | RAPORTOWANIE POZYSKANIE PRZEKSZTA┼üCANIE WYCI─äGANIE WNIOSK├ōW ODKRYWANIE WARTO┼ÜCI DANYCH Independency, correlation, dimensionality, missing values, relevancy Transactions, Web-scraping, Web-clicks & logs, Sensor Data, Mobile Data, Docs, Emails, XLS, Social Feeds, Flume & Sink HDFS MapReduce, ETL, Data Wrangle, Data Cleansing, Data Jujitsu, Dim Reduction, Sample, Select, Join, Bind MODELOWANIEODKRYCIA80% czasu jest po┼øwi─Öcone na Przekszta┼écanie, Transformacje, & Modelowanie
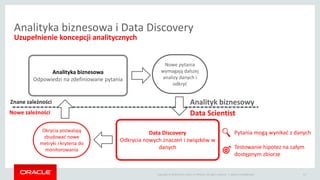
- 13. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Analityka biznesowa i Data Discovery Uzupe┼énienie koncepcji analitycznych Oracle Confidential 13 Znane zale┼╝no┼øci Analityka biznesowa Odpowiedzi na zdefiniowane pytania Nowe pytania wymagaj─ģ dalszej analizy danych i odkry─ć Nowe zale┼╝no┼øci Data Discovery Odkrycia nowych znacze┼ä i zwi─ģzk├│w w danych Okrycia pozwalaj─ģ zbudowa─ć nowe metryki i kryteria do monitorowania Analityk biznesowy Data Scientist Pytania mog─ģ wynika─ć z danych Testowanie hipotez na ca┼éym dost─Öpnym zbiorze
- 14. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Potrzebne s─ģ narz─Ödzia nowej generacji 14 Szybkiego przekszta┼écenia i wzbogacenia danych Dokonywania odkry─ć i udost─Öpniania wniosk├│w dla wielu u┼╝ytkownik├│w Przejrzysty i intuicyjny kokpit do pracy z danymi w celu... ┼üatwej identyfikacji danych i zrozumienia ich potencja┼éu do analizy find explore transform discover share
- 15. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | 15 Big Data Discovery. The Visual Face of Hadoop find explore transform discover share
- 16. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Big Data Discovery. The Visual Face of Hadoop 16 find explore transform discover share Analiza potencja┼éu pozyskanych danych
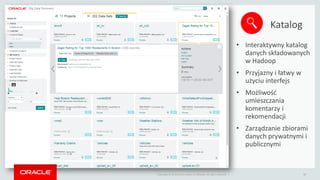
- 17. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Katalog 17 ŌĆó Interaktywny katalog danych sk┼éadowanych w Hadoop ŌĆó Przyjazny i ┼éatwy w u┼╝yciu interfejs ŌĆó Mo┼╝liwo┼ø─ć umieszczania komentarzy i rekomendacji ŌĆó Zarz─ģdzanie zbiorami danych prywatnymi i publicznymi
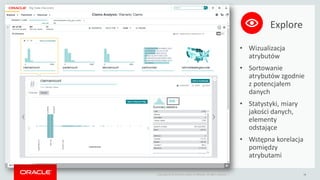
- 18. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Explore 18 ŌĆó Wizualizacja atrybut├│w ŌĆó Sortowanie atrybut├│w zgodnie z potencja┼éem danych ŌĆó Statystyki, miary jako┼øci danych, elementy odstaj─ģce ŌĆó Wst─Öpna korelacja pomi─Ödzy atrybutami
- 19. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Big Data Discovery. The Visual Face of Hadoop 19 find explore transform discover share Szybkie przekszta┼écanie i wzbogacanie danych
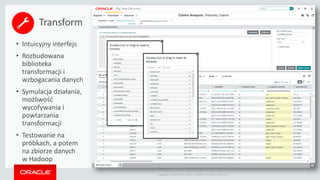
- 20. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | 2020 ŌĆó Intuicyjny interfejs ŌĆó Rozbudowana biblioteka transformacji i wzbogacania danych ŌĆó Symulacja dzia┼éania, mo┼╝liwo┼ø─ć wycofywania i powtarzania transformacji ŌĆó Testowanie na pr├│bkach, a potem na zbiorze danych w Hadoop Transform
- 21. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Big Data Discovery. The Visual Face of Hadoop 21 find explore transform discover share Odkrycia i udost─Öpnianie wniosk├│w
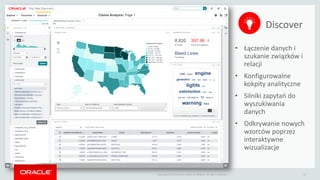
- 22. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | 22 ŌĆó ┼ü─ģczenie danych i szukanie zwi─ģzk├│w i relacji ŌĆó Konfigurowalne kokpity analityczne ŌĆó Silniki zapyta┼ä do wyszukiwania danych ŌĆó Odkrywanie nowych wzorc├│w poprzez interaktywne wizualizacje Discover
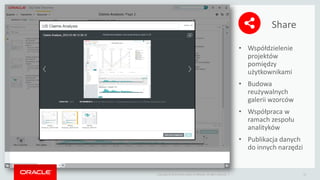
- 23. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | 23 ŌĆó Wsp├│┼édzielenie projekt├│w pomi─Ödzy u┼╝ytkownikami ŌĆó Budowa reu┼╝ywalnych galerii wzorc├│w ŌĆó Wsp├│┼épraca w ramach zespo┼éu analityk├│w ŌĆó Publikacja danych do innych narz─Ödzi Share
- 24. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Efektywne po┼é─ģczenie dw├│ch ┼ørodowisk danych 24 ŌĆó Kompletna platforma analityczna ŌĆó Oszcz─Ödno┼ø─ć czasu na procesach pomocniczych ŌĆó Wydajne przetwarzanie w pami─Öci Data Warehouse Dane operacyjne Dane niestrukturalne Ocean danychHurtownia danych
- 25. Copyright ┬® 2014 Oracle and/or its affiliates. All rights reserved. | Oracle Confidential ŌĆō Internal 25 Je┼╝eli pasjonujesz si─Ö ŌĆ×data scienceŌĆØ, masz praktyczne do┼øwiadczenia z obszarem Big Data, jeste┼ø kreatywny i lubisz wyzwania, serdecznie zapraszamy do kontaktu: Wojciech Wcis┼éo: wojciech.wcislo@oracle.com Rekrutujemy pracownik├│w do regionalnego zespo┼éu Big Data!