Otwarte Miasta
4 likes1,054 views

Prezentacja Kasi MikoĆajczyk (Fundacja Fundament) z 11 spotkania Data Science Warsaw
1 of 13
Downloaded 13 times











Ad
Recommended
ARTRITIS â ENCEFALITIS CAPRINAEdgar Mrtinez
Ìę
La artritis-encefalitis caprina es producida por un retrovirus que infecta principalmente a cabras y ocasionalmente ovejas. Aunque la mayorĂa de las infecciones son asintomĂĄticas, algunos animales desarrollan una enfermedad progresiva e incurable que se manifiesta a travĂ©s de cuadros nerviosos, articulares o pulmonares/mamarios. El diagnĂłstico se realiza mediante pruebas serolĂłgicas y el control incluye la eliminaciĂłn de animales infectados y medidas de higiene.Neptune - narzÄdzie do monitorowania i zarzÄ
dzania eksperymentami Machine Lea...
Neptune - narzÄdzie do monitorowania i zarzÄ
dzania eksperymentami Machine Lea...Data Science Warsaw
Ìę
deepsense.io specializes in deep learning solutions for enterprises, focusing on data science and featuring a team of over 150 professionals, including software engineers and data scientists. The company offers products, services, and workshops centered around Neptune, a high-level API for managing experiments, and invites users to join its early adopters program for exclusive access and influence on product development. Additionally, deepsense.io emphasizes its commitment to ongoing product improvements, including support for multiple programming languages and integration with tools like Git and cloud services.CRISP-DM Agile Approach to Data Mining Projects
CRISP-DM Agile Approach to Data Mining ProjectsData Science Warsaw
Ìę
This document summarizes MichaĆ ĆopuszyĆski's presentation on using an agile approach based on the CRISP-DM methodology for data mining projects. It discusses the key phases of CRISP-DM including business understanding, data understanding, data preparation, modelling, evaluation, and deployment. For each phase, it provides examples of best practices and challenges, with an emphasis on spending sufficient time on data understanding and preparation, developing models with the deployment context in mind, and carefully evaluating results against business objectives.Big Data, Wearable, sztuczna inteligencja i ekonomia wspĂłĆpracy
Big Data, Wearable, sztuczna inteligencja i ekonomia wspĂłĆpracyData Science Warsaw
Ìę
Big Data, Wearable, sztuczna inteligencja i ekonomia wspĂłĆpracy - Sebastian StarzyĆski (Take Task)Geolokalizacja i analizy przestrzenne: trzy wymiary a ile pracy dla analityka!
Geolokalizacja i analizy przestrzenne: trzy wymiary a ile pracy dla analityka!Data Science Warsaw
Ìę
O roli danych geograficznych ich ĆșrĂłdĆach, potencjale oraz metodach analitycznych wykorzystujÄ
cych informacje przestrzenne.
5 spotkanie Data Science Warsaw MeetUp. Warszawa, 12 maja 2015Data science w ubezpieczeniach
Data science w ubezpieczeniachData Science Warsaw
Ìę
Data science w ubezpieczeniach - Agnieszka Zdebiak (Fundacja DataSci)RozwiÄ
zywanie problemĂłw optymalizacyjnych
RozwiÄ
zywanie problemĂłw optymalizacyjnychData Science Warsaw
Ìę
Prezentacja by Wit Jakuczun z WLOG Solutions wygĆoszona na 13tym spotkaniu Data Science Warsaw Meetup, pt. RozwiÄ
zywanie problemĂłw optymalizacyjnych z przykĆadami w GNU R. Wizualne budowanie aplikacji na Sparku przy pomocy narzÄdzia Seahorse
Wizualne budowanie aplikacji na Sparku przy pomocy narzÄdzia SeahorseData Science Warsaw
Ìę
Seahorse is a collaborative platform designed to enhance Apache Spark's accessibility for non-technical users and improve the development of Spark applications. The document outlines its evolution since its first release in February 2016, highlighting features such as R and Scala support, custom cluster connectivity, and reporting capabilities. It also includes information on how to access Seahorse and participate in its feedback process.To siÄ w ram ie nie zmieĆci
To siÄ w ram ie nie zmieĆciData Science Warsaw
Ìę
Prezentacja MichaĆa Brzezicki z 9 spotkania Data Science Warsaw przedstawiajÄ
ca w jaki sposĂłb pobierane i analizowane sÄ
dane w SentiOne. Opowiada o problemach zwiÄ
zanych z crawlowaniem ponad pĂłĆ miliona domen oraz dlaczego Hadoop i ElasticSearch jest fajny i na ilu dyskietkach mieĆci siÄ 5,7 miliarda przeanalizowanych wypowiedzi. Analiza jÄzyka naturalnego
Analiza jÄzyka naturalnegoData Science Warsaw
Ìę
Prezentacja Adama Dancewicza z Applica z 11 spotkania Data Science WarsawNuevos paradigmas e aprendizajesWendy Velasquez Vallejo
Ìę
Este documento discute varios cambios en los paradigmas de aprendizaje. Señala que ahora es posible acceder a informaciĂłn desde cualquier lugar con una computadora y que los jĂłvenes usan frecuentemente Internet para completar tareas escolares sin demostrar comprensiĂłn. TambiĂ©n menciona que los jĂłvenes quieren todo de forma instantĂĄnea pero que el aprendizaje requiere tiempo y esfuerzo. El documento concluye que los docentes deben cambiar sus metodologĂas para adaptarse a cĂłmo aprenden los estudiantes de hoy en dĂa con las nueTed para ticyadiraperea24
Ìę
El documento describe cĂłmo las tecnologĂas en lĂnea estĂĄn cambiando la educaciĂłn al hacerla mĂĄs accesible e interactiva. Organizaciones como EDX ahora ofrecen cursos masivos en lĂnea con videos, ejercicios y debates que permiten a los estudiantes aprender en cualquier lugar y a su propio ritmo, complementando la enseñanza tradicional en el aula. Estos nuevos enfoques buscan hacer la educaciĂłn menos monĂłtona y mĂĄs eficaz para mejorar el desempeño de los estudiantes.ĐșĐŸĐœĐșŃŃŃĐœĐŸĐ” ĐžŃĐżŃŃĐ°ĐœĐžĐ” «ŃŃĐŸĐș»
ĐșĐŸĐœĐșŃŃŃĐœĐŸĐ” ĐžŃĐżŃŃĐ°ĐœĐžĐ” «ŃŃĐŸĐș»dmitriymmz
Ìę
ĐĐŸĐșŃĐŒĐ”ĐœŃ ĐŸĐżĐžŃŃĐČĐ°Đ”Ń ĐșĐ»ŃŃĐ”ĐČŃĐ” Đ°ŃпДĐșŃŃ, ĐșĐŸŃĐŸŃŃĐ” ŃлДЎŃĐ”Ń ŃŃĐžŃŃĐČĐ°ŃŃ ĐżŃĐž ĐŸŃĐłĐ°ĐœĐžĐ·Đ°ŃОО ĐŸŃĐșŃŃŃĐŸĐłĐŸ ŃŃĐŸĐșĐ° ŃŃĐžŃĐ”Đ»Ń Đ°ĐœĐłĐ»ĐžĐčŃĐșĐŸĐłĐŸ ŃĐ·ŃĐșĐ°. УЎДлŃĐ”ŃŃŃ ĐČĐœĐžĐŒĐ°ĐœĐžĐ” ĐŒĐ”ŃĐŸĐŽĐžŃĐ”ŃĐșĐŸĐŒŃ ĐŒĐ°ŃŃĐ”ŃŃŃĐČŃ, ĐŒĐŸŃĐžĐČĐ°ŃОО ŃŃĐ”ĐœĐžĐșĐŸĐČ, ĐŸŃĐ”ĐœĐžĐČĐ°ĐœĐžŃ Đž ĐŸŃĐłĐ°ĐœĐžĐ·Đ°ŃОО ŃŃĐ”Đ±ĐœĐŸĐłĐŸ ĐżŃĐŸŃĐ”ŃŃĐ°. йаĐșжД ŃĐ°ŃŃĐŒĐ°ŃŃĐžĐČĐ°ŃŃŃŃ ĐČĐ°Đ¶ĐœŃĐ” ĐșĐŸĐŒĐżĐŸĐœĐ”ĐœŃŃ, ŃĐ°ĐșОД ĐșĐ°Đș ĐžŃĐżĐŸĐ»ŃĐ·ĐŸĐČĐ°ĐœĐžĐ” ĐžĐœŃĐ”ŃĐ°ĐșŃĐžĐČĐœŃŃ
ĐŒĐ”ŃĐŸĐŽĐŸĐČ, ŃĐ”ŃлДĐșŃĐžŃ Đž ŃĐŸĐ·ĐŽĐ°ĐœĐžĐ” ĐșĐŸĐŒŃĐŸŃŃĐœĐŸĐč ŃŃĐ”Đ±ĐœĐŸĐč ŃŃДЎŃ.Siewicz_LaCH_otwarte publikacje
Siewicz_LaCH_otwarte publikacjePlatforma Otwartej Nauki
Ìę
Warsztaty organizowane przez Laboratorium Cyfrowe Humanistyki UW. ĐžŃĐșŃŃŃŃĐČĐŸ Đ·ĐČŃŃĐ°ŃĐ”ĐłĐŸ ŃĐ»ĐŸĐČĐ°
ĐžŃĐșŃŃŃŃĐČĐŸ Đ·ĐČŃŃĐ°ŃĐ”ĐłĐŸ ŃĐ»ĐŸĐČĐ°dmitriymmz
Ìę
ĐžŃĐșŃŃŃŃĐČĐŸ Đ·ĐČŃŃĐ°ŃĐ”ĐłĐŸ ŃĐ»ĐŸĐČĐ°Listasandrav29
Ìę
La profesora Sandra Velasco enseña InformĂĄtica en el grado 3-A durante el primer periodo. La asistencia de los estudiantes se registra con sus nombres completos y tres notas numĂ©ricas. La clase se imparte en la Escuela Normal Superior del Distrito de Barranquilla.ĐąĐ°ĐžĐœŃŃĐČĐŸ ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ°
ĐąĐ°ĐžĐœŃŃĐČĐŸ ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ° dmitriymmz
Ìę
ĐĐŸĐșŃĐŒĐ”ĐœŃ ŃĐŸĐŽĐ”ŃĐ¶ĐžŃ ĐžĐœŃĐŸŃĐŒĐ°ŃĐžŃ ĐŸ ĐŒŃĐœĐžŃОпалŃĐœĐŸĐŒ ĐșĐŸĐœĐșŃŃŃĐ” ŃĐČĐŸŃŃĐ”ŃĐșĐžŃ
ŃĐ°Đ±ĐŸŃ Â«ĐąĐ°ĐžĐœŃŃĐČĐŸ Đ ĐŸĐ¶ĐŽĐ”ŃŃĐČа» ĐČ ĐŃĐ”Ń
ĐŸĐČĐŸ-ĐŃĐ”ĐČĐŸ Đ·Đ° 2016 ĐłĐŸĐŽ. ĐĐ”ŃĐ”ŃĐžŃĐ»Đ”ĐœŃ ĐżĐŸĐ±Đ”ĐŽĐžŃДлО Đž ĐżŃОзДŃŃ ĐČ ĐŽĐČŃŃ
ĐœĐŸĐŒĐžĐœĐ°ŃĐžŃŃ
: «ŃĐșŃĐ°ŃĐ”ĐœĐžĐ” ĐŽĐ»Ń ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ”ĐœŃĐșĐŸĐč ДлО» Đž «ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ”ĐœŃĐșĐžĐč ŃŃĐČĐ”ĐœĐžŃ». ĐĐ°Đ¶ĐŽĐŸĐŒŃ ŃŃĐ°ŃŃĐœĐžĐșŃ ŃĐșĐ°Đ·Đ°ĐœŃ ĐžŃ
ŃĐ°Đ±ĐŸŃŃ, ŃĐ°ĐŒĐžĐ»ĐžĐž ŃŃĐșĐŸĐČĐŸĐŽĐžŃДлДĐč Đž ĐČĐŸŃпОŃĐ°ŃДлДĐč.Polityka otwartego dostÄpu w Polsce. Rekomendacje MNiSW
Polityka otwartego dostÄpu w Polsce. Rekomendacje MNiSWPlatforma Otwartej Nauki
Ìę
Mateusz GaczyĆski, National Open Access Workshop OpenAIRE, Warsaw 16 November 2016.Otwarte dane badawcze w humanistyce
Otwarte dane badawcze w humanistycePlatforma Otwartej Nauki
Ìę
Warsztaty organizowane przez Laboratorium Cyfrowe HumanistykiPurification of Biogas from Anaerobic Digestion
Purification of Biogas from Anaerobic DigestionKofi Afriyie
Ìę
This document summarizes several methods for purifying biogas produced from anaerobic digestion, including membrane separation, gas-liquid adsorption, adsorption by iron oxide, and biological filtration. Membrane separation uses permeability of different molecules to separate gases like methane, with three-stage membranes producing 90% pure methane. Gas-liquid adsorption uses a hydrophobic membrane interface to dissolve impurities like CO2 and H2S in liquid while collecting pure methane. Adsorption by iron oxide reacts hydrogen sulfide with iron oxide at temperatures between 250-500C to form iron sulfide and water. Biological filtration grows thiobacillus bacteria on a filter bed to oxidize hydrogen sulfide before the biogas entersMaĆe dane, duĆŒy wpĆyw - Dominik Batorski ICM
MaĆe dane, duĆŒy wpĆyw - Dominik Batorski ICMData Science Warsaw
Ìę
MaĆe dane, duĆŒy wpĆyw - Dominik Batorski ICMHow to build your own google
How to build your own googleData Science Warsaw
Ìę
The document discusses how to build your own search engine like Google using Apache Solr and Tika. It explains that Solr uses an inverted index and represents documents as vectors in a common term space to allow fast search across large datasets. Tika is used to extract text from different file formats. The document provides examples of how companies like Netflix use Solr for search capabilities on their websites.Ask Data Anything
Ask Data AnythingData Science Warsaw
Ìę
This document discusses how semantic technologies can be used to gain additional insights from data by defining relationships between data elements. It describes how Ask Data Anything uses ontologies and taxonomies to represent relationships that allow for more complex queries over data than what is contained in the data itself. Examples of queries over sample invoice data are provided, such as summarizing quantities by city and country, or status by vendor. Material subsetting is also discussed as a way to extract meaningful attributes from raw data to assist in building taxonomies.Oracle Big Data Discovery - ludzka twarz Hadoop'a
Oracle Big Data Discovery - ludzka twarz Hadoop'aData Science Warsaw
Ìę
OszaĆamiajÄ
ce wizualnie, intuicyjne rozwiÄ
zanie, ktĂłre pozwala wykorzystaÄ potencjaĆ Hadoop i przeksztaĆciÄ surowe dane w nowe odkrycia w ciÄ
gu kilku minut, bez potrzeby uczenia siÄ skomplikowanych rozwiÄ
zaĆ przeznaczonych dla wÄ
skiego grona specjalistĂłw.AngulosBrĂgida Ferreira
Ìę
Este documento fornece instruçÔes para medir, completar e classificar diferentes tipos de Ăąngulos, incluindo medição de Ăąngulos especĂficos, preenchimento de Ăąngulos com amplitudes corretas e classificação de Ăąngulos como agudos, retos ou obtusos.Dlaczego miasta potrzebujÄ
otwartych danych (opendata)
Dlaczego miasta potrzebujÄ
otwartych danych (opendata)Fundacja ePaĆstwo
Ìę
Prezentacja z warsztatu "dlaczego miasta potrzebujÄ
otwartych danych?" z #PDF20163 lata otwierania danych w GdaĆsku
3 lata otwierania danych w GdaĆskuTomasz Nadolny
Ìę
Prezentacja na trĂłjmiejskim 3campie 4 paĆșdziernika 2016 na temat 3 lat doĆwiadczeĆ w otwieraniu danych w ramach projektu Otwarty GdaĆsk. More Related Content
Viewers also liked (20)
To siÄ w ram ie nie zmieĆci
To siÄ w ram ie nie zmieĆciData Science Warsaw
Ìę
Prezentacja MichaĆa Brzezicki z 9 spotkania Data Science Warsaw przedstawiajÄ
ca w jaki sposĂłb pobierane i analizowane sÄ
dane w SentiOne. Opowiada o problemach zwiÄ
zanych z crawlowaniem ponad pĂłĆ miliona domen oraz dlaczego Hadoop i ElasticSearch jest fajny i na ilu dyskietkach mieĆci siÄ 5,7 miliarda przeanalizowanych wypowiedzi. Analiza jÄzyka naturalnego
Analiza jÄzyka naturalnegoData Science Warsaw
Ìę
Prezentacja Adama Dancewicza z Applica z 11 spotkania Data Science WarsawNuevos paradigmas e aprendizajesWendy Velasquez Vallejo
Ìę
Este documento discute varios cambios en los paradigmas de aprendizaje. Señala que ahora es posible acceder a informaciĂłn desde cualquier lugar con una computadora y que los jĂłvenes usan frecuentemente Internet para completar tareas escolares sin demostrar comprensiĂłn. TambiĂ©n menciona que los jĂłvenes quieren todo de forma instantĂĄnea pero que el aprendizaje requiere tiempo y esfuerzo. El documento concluye que los docentes deben cambiar sus metodologĂas para adaptarse a cĂłmo aprenden los estudiantes de hoy en dĂa con las nueTed para ticyadiraperea24
Ìę
El documento describe cĂłmo las tecnologĂas en lĂnea estĂĄn cambiando la educaciĂłn al hacerla mĂĄs accesible e interactiva. Organizaciones como EDX ahora ofrecen cursos masivos en lĂnea con videos, ejercicios y debates que permiten a los estudiantes aprender en cualquier lugar y a su propio ritmo, complementando la enseñanza tradicional en el aula. Estos nuevos enfoques buscan hacer la educaciĂłn menos monĂłtona y mĂĄs eficaz para mejorar el desempeño de los estudiantes.ĐșĐŸĐœĐșŃŃŃĐœĐŸĐ” ĐžŃĐżŃŃĐ°ĐœĐžĐ” «ŃŃĐŸĐș»
ĐșĐŸĐœĐșŃŃŃĐœĐŸĐ” ĐžŃĐżŃŃĐ°ĐœĐžĐ” «ŃŃĐŸĐș»dmitriymmz
Ìę
ĐĐŸĐșŃĐŒĐ”ĐœŃ ĐŸĐżĐžŃŃĐČĐ°Đ”Ń ĐșĐ»ŃŃĐ”ĐČŃĐ” Đ°ŃпДĐșŃŃ, ĐșĐŸŃĐŸŃŃĐ” ŃлДЎŃĐ”Ń ŃŃĐžŃŃĐČĐ°ŃŃ ĐżŃĐž ĐŸŃĐłĐ°ĐœĐžĐ·Đ°ŃОО ĐŸŃĐșŃŃŃĐŸĐłĐŸ ŃŃĐŸĐșĐ° ŃŃĐžŃĐ”Đ»Ń Đ°ĐœĐłĐ»ĐžĐčŃĐșĐŸĐłĐŸ ŃĐ·ŃĐșĐ°. УЎДлŃĐ”ŃŃŃ ĐČĐœĐžĐŒĐ°ĐœĐžĐ” ĐŒĐ”ŃĐŸĐŽĐžŃĐ”ŃĐșĐŸĐŒŃ ĐŒĐ°ŃŃĐ”ŃŃŃĐČŃ, ĐŒĐŸŃĐžĐČĐ°ŃОО ŃŃĐ”ĐœĐžĐșĐŸĐČ, ĐŸŃĐ”ĐœĐžĐČĐ°ĐœĐžŃ Đž ĐŸŃĐłĐ°ĐœĐžĐ·Đ°ŃОО ŃŃĐ”Đ±ĐœĐŸĐłĐŸ ĐżŃĐŸŃĐ”ŃŃĐ°. йаĐșжД ŃĐ°ŃŃĐŒĐ°ŃŃĐžĐČĐ°ŃŃŃŃ ĐČĐ°Đ¶ĐœŃĐ” ĐșĐŸĐŒĐżĐŸĐœĐ”ĐœŃŃ, ŃĐ°ĐșОД ĐșĐ°Đș ĐžŃĐżĐŸĐ»ŃĐ·ĐŸĐČĐ°ĐœĐžĐ” ĐžĐœŃĐ”ŃĐ°ĐșŃĐžĐČĐœŃŃ
ĐŒĐ”ŃĐŸĐŽĐŸĐČ, ŃĐ”ŃлДĐșŃĐžŃ Đž ŃĐŸĐ·ĐŽĐ°ĐœĐžĐ” ĐșĐŸĐŒŃĐŸŃŃĐœĐŸĐč ŃŃĐ”Đ±ĐœĐŸĐč ŃŃДЎŃ.Siewicz_LaCH_otwarte publikacje
Siewicz_LaCH_otwarte publikacjePlatforma Otwartej Nauki
Ìę
Warsztaty organizowane przez Laboratorium Cyfrowe Humanistyki UW. ĐžŃĐșŃŃŃŃĐČĐŸ Đ·ĐČŃŃĐ°ŃĐ”ĐłĐŸ ŃĐ»ĐŸĐČĐ°
ĐžŃĐșŃŃŃŃĐČĐŸ Đ·ĐČŃŃĐ°ŃĐ”ĐłĐŸ ŃĐ»ĐŸĐČĐ°dmitriymmz
Ìę
ĐžŃĐșŃŃŃŃĐČĐŸ Đ·ĐČŃŃĐ°ŃĐ”ĐłĐŸ ŃĐ»ĐŸĐČĐ°Listasandrav29
Ìę
La profesora Sandra Velasco enseña InformĂĄtica en el grado 3-A durante el primer periodo. La asistencia de los estudiantes se registra con sus nombres completos y tres notas numĂ©ricas. La clase se imparte en la Escuela Normal Superior del Distrito de Barranquilla.ĐąĐ°ĐžĐœŃŃĐČĐŸ ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ°
ĐąĐ°ĐžĐœŃŃĐČĐŸ ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ° dmitriymmz
Ìę
ĐĐŸĐșŃĐŒĐ”ĐœŃ ŃĐŸĐŽĐ”ŃĐ¶ĐžŃ ĐžĐœŃĐŸŃĐŒĐ°ŃĐžŃ ĐŸ ĐŒŃĐœĐžŃОпалŃĐœĐŸĐŒ ĐșĐŸĐœĐșŃŃŃĐ” ŃĐČĐŸŃŃĐ”ŃĐșĐžŃ
ŃĐ°Đ±ĐŸŃ Â«ĐąĐ°ĐžĐœŃŃĐČĐŸ Đ ĐŸĐ¶ĐŽĐ”ŃŃĐČа» ĐČ ĐŃĐ”Ń
ĐŸĐČĐŸ-ĐŃĐ”ĐČĐŸ Đ·Đ° 2016 ĐłĐŸĐŽ. ĐĐ”ŃĐ”ŃĐžŃĐ»Đ”ĐœŃ ĐżĐŸĐ±Đ”ĐŽĐžŃДлО Đž ĐżŃОзДŃŃ ĐČ ĐŽĐČŃŃ
ĐœĐŸĐŒĐžĐœĐ°ŃĐžŃŃ
: «ŃĐșŃĐ°ŃĐ”ĐœĐžĐ” ĐŽĐ»Ń ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ”ĐœŃĐșĐŸĐč ДлО» Đž «ŃĐŸĐ¶ĐŽĐ”ŃŃĐČĐ”ĐœŃĐșĐžĐč ŃŃĐČĐ”ĐœĐžŃ». ĐĐ°Đ¶ĐŽĐŸĐŒŃ ŃŃĐ°ŃŃĐœĐžĐșŃ ŃĐșĐ°Đ·Đ°ĐœŃ ĐžŃ
ŃĐ°Đ±ĐŸŃŃ, ŃĐ°ĐŒĐžĐ»ĐžĐž ŃŃĐșĐŸĐČĐŸĐŽĐžŃДлДĐč Đž ĐČĐŸŃпОŃĐ°ŃДлДĐč.Polityka otwartego dostÄpu w Polsce. Rekomendacje MNiSW
Polityka otwartego dostÄpu w Polsce. Rekomendacje MNiSWPlatforma Otwartej Nauki
Ìę
Mateusz GaczyĆski, National Open Access Workshop OpenAIRE, Warsaw 16 November 2016.Otwarte dane badawcze w humanistyce
Otwarte dane badawcze w humanistycePlatforma Otwartej Nauki
Ìę
Warsztaty organizowane przez Laboratorium Cyfrowe HumanistykiPurification of Biogas from Anaerobic Digestion
Purification of Biogas from Anaerobic DigestionKofi Afriyie
Ìę
This document summarizes several methods for purifying biogas produced from anaerobic digestion, including membrane separation, gas-liquid adsorption, adsorption by iron oxide, and biological filtration. Membrane separation uses permeability of different molecules to separate gases like methane, with three-stage membranes producing 90% pure methane. Gas-liquid adsorption uses a hydrophobic membrane interface to dissolve impurities like CO2 and H2S in liquid while collecting pure methane. Adsorption by iron oxide reacts hydrogen sulfide with iron oxide at temperatures between 250-500C to form iron sulfide and water. Biological filtration grows thiobacillus bacteria on a filter bed to oxidize hydrogen sulfide before the biogas entersMaĆe dane, duĆŒy wpĆyw - Dominik Batorski ICM
MaĆe dane, duĆŒy wpĆyw - Dominik Batorski ICMData Science Warsaw
Ìę
MaĆe dane, duĆŒy wpĆyw - Dominik Batorski ICMHow to build your own google
How to build your own googleData Science Warsaw
Ìę
The document discusses how to build your own search engine like Google using Apache Solr and Tika. It explains that Solr uses an inverted index and represents documents as vectors in a common term space to allow fast search across large datasets. Tika is used to extract text from different file formats. The document provides examples of how companies like Netflix use Solr for search capabilities on their websites.Ask Data Anything
Ask Data AnythingData Science Warsaw
Ìę
This document discusses how semantic technologies can be used to gain additional insights from data by defining relationships between data elements. It describes how Ask Data Anything uses ontologies and taxonomies to represent relationships that allow for more complex queries over data than what is contained in the data itself. Examples of queries over sample invoice data are provided, such as summarizing quantities by city and country, or status by vendor. Material subsetting is also discussed as a way to extract meaningful attributes from raw data to assist in building taxonomies.Oracle Big Data Discovery - ludzka twarz Hadoop'a
Oracle Big Data Discovery - ludzka twarz Hadoop'aData Science Warsaw
Ìę
OszaĆamiajÄ
ce wizualnie, intuicyjne rozwiÄ
zanie, ktĂłre pozwala wykorzystaÄ potencjaĆ Hadoop i przeksztaĆciÄ surowe dane w nowe odkrycia w ciÄ
gu kilku minut, bez potrzeby uczenia siÄ skomplikowanych rozwiÄ
zaĆ przeznaczonych dla wÄ
skiego grona specjalistĂłw.AngulosBrĂgida Ferreira
Ìę
Este documento fornece instruçÔes para medir, completar e classificar diferentes tipos de Ăąngulos, incluindo medição de Ăąngulos especĂficos, preenchimento de Ăąngulos com amplitudes corretas e classificação de Ăąngulos como agudos, retos ou obtusos.Similar to Otwarte Miasta (11)
Dlaczego miasta potrzebujÄ
otwartych danych (opendata)
Dlaczego miasta potrzebujÄ
otwartych danych (opendata)Fundacja ePaĆstwo
Ìę
Prezentacja z warsztatu "dlaczego miasta potrzebujÄ
otwartych danych?" z #PDF20163 lata otwierania danych w GdaĆsku
3 lata otwierania danych w GdaĆskuTomasz Nadolny
Ìę
Prezentacja na trĂłjmiejskim 3campie 4 paĆșdziernika 2016 na temat 3 lat doĆwiadczeĆ w otwieraniu danych w ramach projektu Otwarty GdaĆsk. OMS podstawy prawne waĆŒne w realizacji monitoringu sportu
OMS podstawy prawne waĆŒne w realizacji monitoringu sportuSieÄ Obywatelska Watchdog Polska
Ìę
Prezentacja autorstwa Szymona Osowskiego zaprezentowana w trakcie szkolenia dla uczestnikĂłw i uczestniczek Obywatelskiego Monitoringu Sportu, Konstancin-Jeziorna 14-16 IX 2012Otwarte dane - portale open data | Whiteaster
Otwarte dane - portale open data | WhiteasterPaulina Piechaczek
Ìę
Otwarte dane (Open data) to forma udostÄpnienia danych publicznych w sposĂłb przejrzysty, przydatny i zgodny ze standardami oraz przepisami prawa. Portale Open Data sÄ
powszechnie stosowane na Ćwiecie, stanowiÄ
c szeroko dostÄpny sposĂłb komunikacji ze spoĆeczeĆstwem. W Polsce pionierem w tej dziedzinie jest Ministerstwo Cyfryzacji, korzystajÄ
ce juĆŒ z systemu tego typu (danepubliczne.gov.pl).
WiÄcej na www.otwartedane.com
UdosteÌšpnianie danych finansowych - Katarzyna MikoĆajczyk
UdosteÌšpnianie danych finansowych - Katarzyna MikoĆajczykFundacja ePaĆstwo
Ìę
Katarzyna MikoĆajczyk
Koordynatorka Programu Otwarte Miasta w Fundacji ePaĆstwo
Ćodzka dziaĆaczka, ktĂłra na co dzieĆ koordynuje projekt fundacji ePaĆstwo Otwarte Miasta, umoĆŒliwiajÄ
cy gminom z caĆej Polski sprawnie otwieranie posiadanych baz danych i udostÄpnianie ich mieszkaĆcom. Wychodzi z zaĆoĆŒenia, ĆŒe planowanie (miasta) dla ludzi, wymaga planowania go z ludĆșmi.Open data, public data, Open Gdansk - 3camp Gdansk
Open data, public data, Open Gdansk - 3camp GdanskTomasz Nadolny
Ìę
Prezentacja na 3camp w GdaĆsku 09.02.2015 na temat otwartych danych publicznych i projektu Otwarty GdaĆsk. Fundacja ePaĆstwo i UrzÄ
d Miasta GdaĆskaPo co miasta majÄ
otwieraÄ dane? Przypadek GdaĆska
Po co miasta majÄ
otwieraÄ dane? Przypadek GdaĆskaTomasz Nadolny
Ìę
Moja prezentacja na warsztatach Personal Democracy Forum 2016 w GdaĆsku na temat projektu Otwarty GdaĆsk. WiÄcej informacji na www.otwartygdansk.plAd
More from Data Science Warsaw (9)
Online content popularity prediction
Online content popularity predictionData Science Warsaw
Ìę
The document highlights Tomasz TrzciĆski's work on predicting online content popularity, particularly through the analysis of image features, social network dynamics, and early patterns of viewer engagement. It references various research studies and methodologies, including regression techniques and neural networks, for predicting the virality of content on platforms like Flickr and YouTube. The document also notes that Tooploox is hiring data scientists with expertise in machine learning and data visualization.Ile informacji jest w danych?
Ile informacji jest w danych?Data Science Warsaw
Ìę
Prezentacja z 12 spotkania Data Science Warsaw wspĂłlnie z allegro.techAzure - DuĆŒe zbiory w chmurze
Azure - DuĆŒe zbiory w chmurzeData Science Warsaw
Ìę
DuĆŒe zbiory w chmurze - jak z nich skorzystaÄ i wykorzystaÄAs simple as Apache Spark
As simple as Apache SparkData Science Warsaw
Ìę
The document discusses Apache Spark and its ecosystem. It begins with introducing the speaker who has 5 years of experience in knowledge discovery and has used big data technologies like Hadoop and Spark. It then explains that Spark provides a versatile ecosystem for batch, streaming, SQL, machine learning and graph processing workloads through components like Spark Core, Spark SQL, Spark Streaming, MLLib and GraphX. The document demonstrates Spark's seamless integration through an example that performs SQL queries, trains a machine learning model and performs streaming analysis in one workflow. It encourages attendees to start using Spark by downloading it and experimenting through hands-on coding examples.Data Exchange - the missing link in the big data value chain
Data Exchange - the missing link in the big data value chainData Science Warsaw
Ìę
q.Datum is a data exchange platform that allows data providers and consumers to share and trade various types of raw and aggregate data. It aims to standardize cross-industry data sharing to optimize data use for different applications. The platform consolidates organizational data and lets users share it within their networks. It provides a service across multiple industries like retail, finance, health, and more. Data can be shared for free with partners or sold as a revenue stream. The platform handles privacy/security, payment processing, and allows accessing data through APIs or downloads. It aims to make big data exchange and access easy.Metody logiczne w analizie danych
Metody logiczne w analizie danych Data Science Warsaw
Ìę
This document presents an overview of the Tolerance Rough Set Model (TRSM) and its applications in web intelligence and document clustering. The TRSM uses a tolerance relation instead of an indiscernibility relation to define rough set approximations. This model is used for clustering web search results by enriching document representations with terms from tolerance classes and then applying k-means clustering. An extended TRSM incorporates a thesaurus to further expand document representations. The document concludes by describing SONCA, a search platform that applies these rough set methods along with semantic indexing to perform advanced querying over document collections.Haven 2 0
Haven 2 0 Data Science Warsaw
Ìę
The document discusses HP's HAVEn big data platform. HAVEn integrates HP technologies like Vertica, Autonomy IDOL, and ArcSight to ingest, analyze, and understand both machine and human data at scale. The platform is designed to process both structured and unstructured data from various sources and provide analytics and visualization capabilities. Examples of companies using HAVEn solutions for log analysis, sensor data analysis, and early warning systems are also presented.Ad
Otwarte Miasta
- 2. Jakie dane ma miasto? i jak siÄ dowiedzieÄ tego samego?
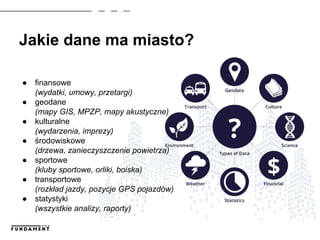
- 3. Jakie dane ma miasto? â finansowe (wydatki, umowy, przetargi) â geodane (mapy GIS, MPZP, mapy akustyczne) â kulturalne (wydarzenia, imprezy) â Ćrodowiskowe (drzewa, zanieczyszczenie powietrza) â sportowe (kluby sportowe, orliki, boiska) â transportowe (rozkĆad jazdy, pozycje GPS pojazdĂłw) â statystyki (wszystkie analizy, raporty)
- 4. Co wie miasto? O sobie â liczba pracownikĂłw, wydatki miasta, dochody miasta, planowane inwestycje, ksztaĆt tych inwestycji a takĆŒe koszty ich utrzymania, O nas â liczba mieszkaĆcĂłw, wnoszone przez nas opĆaty, liczba osĂłb mieszkajÄ cych w danym miejscu (deklaracja âĆmieciowaâ), liczba posiadanych dzieci (program rodzina 500+) i to gdzie chodzÄ do szkoĆy O biznesie â liczba firm, odprowadzany przez nie podatek PIT, liczka i miejsce koncesji na alkohol O przestrzeni â miejscowe plany zagospodarowania przestrzennego... Co moĆŒe dodatkowo wiedzieÄ miasto: KtĂłrÄdy chodzimy i jeĆșdzimy (miejski monitoring i miejski system transportowy)
- 5. Kto udostÄpnia juĆŒ teraz dane? â GdaĆsk (otwartygdansk.pl) â PoznaĆ (poznan.pl/api/) â Warszawa (api.um.warszawa.pl) â WrocĆaw (wroclaw.pl/open-data) â Dane centralne (danepubliczne.gov.pl) â Inne dane (mojepanstwo.pl/api)
- 6. A jeĆli nie ma dedykowanej strony?
- 7. Jest informacja publiczna! âKaĆŒda informacja o sprawach publicznych stanowi informacjÄ publicznÄ w rozumieniu ustawy i podlega udostÄpnieniu i ponownemu wykorzystywaniu na zasadach i w trybie okreĆlonych w niniejszej ustawie.â Art 1.1 ustawy z dnia 6 wrzeĆnia 2001 r. o dostÄpie do informacji publicznej
- 8. Informacja publiczna - kto posiada? 1) organy wĆadzy publicznej; 2) organy samorzÄ dĂłw gospodarczych i zawodowych; 3) podmioty reprezentujÄ ce zgodnie z odrÄbnymi przepisami Skarb PaĆstwa; 4) podmioty reprezentujÄ ce paĆstwowe osoby prawne albo osoby prawne samorzÄ du terytorialnego(...); 5) podmioty reprezentujÄ ce (...), ktĂłre wykonujÄ zadania publiczne lub dysponujÄ majÄ tkiem publicznym, oraz osoby prawne, w ktĂłrych Skarb PaĆstwa, jednostki samorzÄ du terytorialnego lub samorzÄ du gospodarczego albo zawodowego majÄ pozycjÄ dominujÄ cÄ w rozumieniu przepisĂłw o ochronie konkurencjii konsumentĂłw Art 4.1 ustawy z dnia 6 wrzeĆnia 2001 r. o dostÄpie do informacji publicznej
- 9. Informacja publiczna - jak znaleĆșÄ? 1) Biuletyn Informacji Publicznej albo 2) Wniosek o dostÄp do informacji publicznej (np. www.mojepanstwo.pl/pisma, e-mailem, ustnie, pismem) Jakie informacje, w jakim formacie, w jakim celu, jak dostarczona (email, fax, odbiĂłr osobisty, dalekopis, wysyĆka pocztÄ ), imiÄ i nazwisko.
- 10. A jeĆli nie wiemy o co zapytaÄ?
- 11. MoĆŒemy: - przeglÄ daÄ zapytania ofertowe i przetargowe - przeglÄ daÄ wyniki postÄpowaĆ przetargowych - przeglÄ daÄ zarzÄ dzenia - regularnie skĆadaÄ wnioski o wykaz podpisanych umĂłw i jednoczeĆnie wnioskowaÄ oto, aby miasta udostÄpniaĆy takie dane âsame z siebieâ ;-)
- 12. DziÄkujÄ za uwagÄ Katarzyna MikoĆajczyk katarzyna.mikolajczyk@epf.org.pl @kasia_lodz