データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
4 likes3,632 views

クラスメソッド社イベント"Developers.IO 2019 Tokyo"実施セッション https://dev.classmethod.jp/news/developers-io-2019-tokyo/ AWSが提供するサービスは多岐に渡ります。AWS上にデータ分析基盤を構築する場合、どのAWSサービスを組み合わせるか、沢山の選択肢があります。どのAWSサービスがどういう要件に適しているか、弊社で担当した多くの案件を元にお伝えします。






























データ分析基盤、どう作る?システム設計のポイント、教えます - Developers.IO 2019 (20191101)
- 4. 4再掲:セッション概要 AWSが提供するサービスは多岐に渡ります。 AWS上にデータ分析基盤を構築する場合、どのAWS サービスを組み合わせるか、沢山の選択肢があります。 どのAWSサービスがどういう要件に適しているか、弊 社で担当した多くの案件を元にお伝えします。 ? これからデータ分析の環境を作る方に ? AWSでは実際にどのようなモノを作る必要があるのか ? 现実には色々と考虑点がある、という话
- 6. 6「スモールスタート」とは 早く始めたい ? 企画が立って年度内に完成させたい 安く始めたい ? 費用対効果がわからないのでできるだけ… よくある規模感 ? 利用ユーザ数名~数十名 ? データサイズ数十~数百GB ? プロジェクト期間2~6ヶ月 ? プロジェクト予算300~800万円(500万円前後)
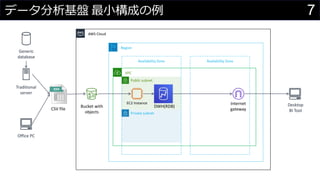
- 7. 7データ分析基盤 最小構成の例 AWS Cloud Region Availability Zone Availability Zone VPC Private subnet Public subnet Desktop BI Tool EC2 Instance Generic database Traditional server DWH(RDB)Bucket with objects Internet gatewayCSV file Office PC
- 8. 8ネットワーク周りの検討 AWSネットワーク設計 ? 最小は1AWSアカウント / 1リージョン / 1AZ / 1VPC ? Public Subnet or (Private Subnet + 踏み台) 専用線接続 or Internet経由 ? 専用線接続の場合 ? DX, VPN設定など相応の期間と予算の確保 ? Internet経由の場合 ? SSL/TLS証明書 + ドメイン名取得
- 9. 9 データ収集
- 10. 10収集データの初歩~AWS基盤に乗せる前に~ 最初はテキストで表現できるデータから ? テキストでないデータ:画像、音声 ? 顧客名簿、注文?売上データ… 機械が吐き出すデータは事前に精度を確認 ? 欠損や明らかな飛び値は発生していないか ? データの不足は加工時点で補うルールづくりと工夫を 分析しやすい形に事前準備 ? アンケートデータからキーワード抽出 ? JSONを王道のCSV, TSVに
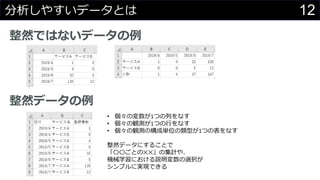
- 11. 11「分析しやすいデータ」とは 整然(Tidy)データ ? データ分析や機械学習などで扱いやすいデータ構造 ? R言語の普及に多大な貢献をしている Hadley Wickham氏が提唱 Wickham, Hadley (2014). "Tidy Data". Journal of Statistical Software. 59 (10). 日本語訳:”整然データとは何か” 整然データの条件 1. 個々の変数が1つの列をなす 2. 個々の観測が1つの行をなす 3. 個々の観測の構成単位の類型が1つの表をなす
- 12. 12分析しやすいデータとは 整然ではないデータの例 整然データの例 ? 個々の変数が1つの列をなす ? 個々の観測が1つの行をなす ? 個々の観測の構成単位の類型が1つの表をなす 整然データにすることで 「〇〇ごとの??」の集計や、 機械学習における説明変数の選択が シンプルに実現できる
- 13. 13AWSへデータ送信 データの送信先(=AWSの入口)の初歩はS3 ? バッチプログラム + awscli ? オンプレ側ETLツール ? S3としては、整然でないデータも置ける 「ボトルネックを作らない」事を心がける ? Redshiftに随時INSERTなどは悪手の極み ? スループットが出せる構成を考える 作り込みができる場合はKinesisやAWS IoTも検討 ? センサーなど、機械からの大量データ収集
- 14. 14 データ加工?蓄積
- 15. 15データレイクとは データ活用の前処理が行える、巨大なデータ蓄積所 ? 生データが基本、一次加工したデータも含む ? 沼(スワンプ)と違い、澄んでいるイメージ AWSでは、データレイクはS3上に構成するイメージ ? 構造化/非構造化データを蓄積 ? AWS Glueのクローラ機能で構造解析、カタログ化 ? テーブルとして直アクセスも可(Athena, Spectrum) ? 新サービス”Lake Formation”でデータレイクの整備を より簡単、確実に行えるように
- 16. 16イベントベースのデータ加工 データレイクの直利用を進める場合に行うと良い操作 ? 規模の大きなプロジェクトで導入 S3に入った生データをより検索に適した形へ加工 ? データクレンジング ? 非構造化データの整然化 ? 列志向データへの変換(CSV → Parquet)など ? 生データバケット → 検索可能バケット S3ファイル格納をイベントにした非同期処理 ? 処理の並列性と確実性を担保する
- 18. 18S3のバケット構造 データファイルはフォルダで階層分けする ? AthenaやRedshift Spectrumなどで検索する事を想定 ? パーティション情報を与える事で検索コスト減 s3://athena-examples/elb/plaintext/2015/01/01/ s3://elasticmapreduce/samples/hive-ads/tables/impressions/ dt=2009-04-12-13-00/ dt=2009-04-12-13-05/ dt=2009-04-12-13-10/ dt=2009-04-12-13-15/ … 引用元:Amzon Athenaユーザーズガイド https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c-spectrum-external-tables.html
- 19. 19データウェアハウス(DWH) 「高速に」データ検索、活用を行うデータ格納領域 ? データレイクから抽出、集計したデータを格納 ? トランザクションテーブル ? マスタテーブル ? マートテーブル ? BIツールや機械学習プログラムが利用する ? 自由(アドホック)検索を必要とする ? 大量なデータを高速に集計する必要がある
- 20. 20DWHに適したAWSサービス 本命はRedshift ? データレイクと合わせてより広大なデータも 扱えるように進化(Redshift Spectrum) 次点で各RDBサービス ? Aurora ? RDS for xxx ? 高速なピンポイント検索には向くが、 集計処理に向かないデータ格納形式 データレイクを直接検索に使用する構成も可能 ? Athena
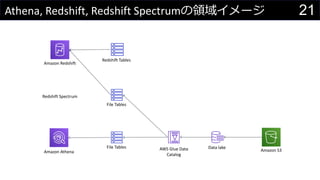
- 21. 21Athena, Redshift, Redshift Spectrumの領域イメージ Data lake Amazon S3Amazon Athena Amazon Redshift AWS Glue Data Catalog Redshift Tables File Tables File Tables Redshift Spectrum
- 22. 22DWHへのデータロード 処理の効率化のため、バルクロードが基本 ? RedshiftへのCOPYコマンドなど ? Kinesis Data Firehoseなども利用可能 Athena, Redshift Spectrum利用の準備 ? Glue Crawlerでファイルの定義情報を検索 ? クローリングの結果を元にテーブルとして定義 ? テーブル情報をAthenaやRedshift Spectrumで利用
- 23. 23ETL vs ELT ETL: S3のファイルを加工しながらDWHへロード ? AWSの場合、Glueジョブフローの作成と実行 ? 主な必要スキル:PySpark ? その他手段としては、市販のETLツール ? 主な必要要素:財力 ? 構成が複雑になる代わりに、DWHへ負担を掛けない ELT: ファイルを先にDWHにロードしてDWH内で加工 ? バルクロード後のデータをSQLで集計 ? 主な必要スキル:SQL ? 構成はシンプルになるが、DWHに負担が掛かる
- 24. 24 データ提供
- 25. 25データ提供方法 基本はBIツールや分析ツール ? Tableau, Looker, SPSS… ? 多くのDWHはODBC, JDBC対応なので、 汎用的なツールはだいたい使える 「人はなぜ BIツールを CSVダウンロードツールにしてしまうのか」 ? BIツールの一部は、帳票表示が苦手 ? 何のためにCSVファイルをエクスポートするのか ? BIで目的が完了できるよう、現在の業務における データの用途を検討して欲しい
- 26. 26ユーザ管理について 最近多い話「ADでユーザ管理したい」 ? DWHのデータベースユーザをADユーザと紐付けるのは 大変難しい ? グループ、権限設定の問題 ? そもそも連携機能がない事が多い、自作のリスク 結論:ユーザ管理はBIツール側に寄せるべき ? BIサーバにはAD連携機能が提供されている ? グループ管理、権限設定も専用の管理画面がある ? データの出し分けは、BIツールの設定で!
- 28. 28AWSではないところで工夫が必要な要素 データカタログ ? システムで使用するデータカタログ(データリポジトリ)は、 AWS Glueデータカタログで実現可能 ? 人間が利用する物理/論理対応表は、別途準備が必要 データリネージ ? ETL/ELT処理フローを把握 ライフサイクル管理 ? データの発生期日 or 賞味期限をデータに付記 ? ETL/ETL処理内で破棄 結論として、「データの番人」は必要
- 29. 29非機能要件:性能 結論:やってみないとわからない ? AWSの弾力性を十分に活かす ? 「必要なら足せばいい」という考え方 ? 予算は余裕を持って確保を… ? 性能に余裕があったので「予算が余ってラッキー☆」 くらいの考え方がありがたい
- 30. 30非機能要件:セキュリティ 基本的にはAWSの監視サービスに寄せる ログ収集の例 ? AWS基盤に対する操作ログ ? CloudTrail ? DWHに対するクエリログ ? RedshiftのログS3出力設定 ? BIツールの利用ログ ? 現実的には連携できないこと多い ? 独自のログ監視機能を利用する
- 32. 32受諾開発 vs 準委任契約 「何を作って欲しいか」が明確にできるか? ? 「いい感じに作って」を受諾契約することは不可能 ? 「いい感じ」とは…?というのが正直なところ ? 開発予算をプールして、「その範囲でできること」を 精一杯設計実装する形が落とし所
- 34. 34