
























































More Related Content
What's hot (20)
Similar to 顿补迟补产谤颈肠办蝉を初めて使う人に向けて.辫辫迟虫 (20)











![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=560&fit=bounds)






顿补迟补产谤颈肠办蝉を初めて使う人に向けて.辫辫迟虫
- 2. 2 Databricksを始めるとき、こんな疑問を抱くことがないでしょうか? クラスター構成の最適解が わからない。 分散処理に使用するワーカー 数ってどのくらいが妥当? Databricks SQLとSpark SQL はどう使い分ける?
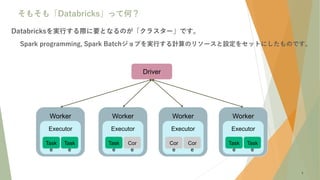
- 5. 5 そもそも「Databricks」って何? Databricksを実行する際に要となるのが「クラスター」です。 Spark programming, Spark Batchジョブを実行する計算のリソースと設定をセットにしたものです。 Driver Worker Worker Worker Worker Executor Executor Executor Executor Cor e Cor e Cor e Cor e Cor e Cor e Cor e Cor e Task Task Task Task Task
- 7. 7 クラスター構成のベストプラクティス ? 構成を決定する際に考慮する点 ? ユーザーの種類 ? ワークロードの種類 ? Service Level Agreement(SLA)の程度 ? 予算の制約 クラスターの構成は、コストとパフォーマンスのバランスを考慮して行います。 コスト: ? クラスターによって消費されるDatabricksユニット ? クラスターの実行に必要な基本リソース ?二次的なコストがはっきりせず、考慮に入れにくいケースもあります。
- 8. 8 クラスター構成のベストプラクティス ? クラスターのサイズ設定 クラスターのサイズを設定する際に考慮すべきポイント ? ワークロードで消費されるデータ量 ? コンピューティングの複雑さ ? データの読み取り元 ? 外部ストレージでのデータのパーティションの方法 ? どの程度の並列処理が必要であるか
- 9. 9 クラスターの構成
- 10. 10 クラスターの構成 ? クラスターを新規作成する際には、以下の項目を選択する ? クラスターポリシー ? マルチノード/シングルノード ? アクセスモード ? Runtimeバージョン ? クラスターノードの型
- 11. 11 クラスターの構成 ? クラスターポリシー 規則に基づいてユーザー?グループの クラスター作成のアクセス許可を制御する。 ? マルチノード / シングルノード 複数のワーカーで分散処理をさせるか単一ワー カーで集中処理させるかを定義する。
- 12. 12 クラスターの構成 ? アクセスモード Unity Catalogで保護されたデータへのアクセス方法を 設定する。 ? Runtimeバージョン クラスターで実行されるコアコンポーネントのセット。 すべてのバージョンにApache Sparkが含まれている。
- 14. 14 【補足】ワーカー数の設定
- 15. 15 ワーカー数の設定 ? 多くすればいいとは限らない 以下の設定をしているクラスターは同じコンピューティングとメモリを持つ ことになる。 ? 2つのワーカー(16コアと112GBのRAM) ? 8つのワーカー(4コアと28GBのRAM) ワーカーの数とワーカー インスタンスタイプのサイズとの間でバランスを考慮 する必要がある。
- 17. 17 クラスター構成の考慮ポイント ? 最適なクラスター構成を目指すうえで考慮すべきこと ? 反復パフォーマンステストによるクラスターサイズの最適化 ? シャッフルの調整 ? データのパーティション分割
- 18. 18 クラスター構成の考慮ポイント ? パフォーマンステストを反復することで最適サイズのクラスターを 構成する 1. 中規模(2~8ノード)のクラスターで開発を行う。 2. 機能要件を満たしたら、CPU、メモリ、およびI/Oを集計レベルで測定し、 より大きなデータに対してテストを行う。 3. クラスターを最適化して、手順2で見つかったボトルネックを取り除く ?ボトルネックが解決されるまで手順2と3を繰り返す。
- 20. 20 クラスター構成まとめ ? データのパーティションによる影響を考慮する 適切なパーティションを設定することでスケーラビリティの向上や競合の 低減、パフォーマンスの最適化へとつながる。 ? 均等にデータが分散されるようなパーティションを設定する ? パーティションあたり数十GB ? データセットが小さい場合は不必要にパーティション分割しない ? 過剰なパーティション分割を行わない
- 22. 22 そもそもDatabricks SQL とは ? Databricks Lakehouse Platformにビルトインされている エンタープライズデータウェアハウス Lakehouseに直接クエリを実行できる。
- 23. 23 そもそもDatabricks SQL とは Databricks SQLではダッシュボードの作成も可能であるため、 SQLクエリやBIツールをメインで使用するデータアナリストなどにとって 直感的に分析を行う環境として用いられる。 ダッシュボードの例
- 24. 24 Databricks SQL と Spark SQLの使い分け 下図のように、データアナリスト?データサイエンティストなどの役割に応じて Databricks SQLとSpark SQLを使い分けることにより、データインフラストラク チャの簡素化、データソースの信頼性を確保することができる。
- 25. 25 まとめ
- 27. 27 参考リンク集 【クラスター構成のベストプラクティス】 https://learn.microsoft.com/ja-jp/azure/databricks/clusters/cluster-config-best-practices 【クラスターポリシー】 https://learn.microsoft.com/ja-jp/azure/databricks/administration-guide/clusters/policies 【アクセスモードとは】 https://learn.microsoft.com/ja-jp/azure/databricks/clusters/cluster-ui-preview#--what-is-cluster-access-mode 【クラスターノードの型】 https://learn.microsoft.com/ja-jp/azure/databricks/clusters/create-cluster#--cluster-node-type 【Runtimeバージョン】 https://learn.microsoft.com/ja-jp/azure/databricks/runtime/?source=recommendations 【クラスターの最適化】 AzureDatabricksBestPractices/toc.md at master · Azure/AzureDatabricksBestPractices · GitHub 【Databricks SQLとは】 Databricks SQLとは何か? - Qiita SQL開発者向けDatabricksのご紹介 - Qiita
- 28. 28 Thank You for Watching.
Editor's Notes
- #3: 疑问解消の一助になれるよう、ベストプラクティスを绍介していきます。
- #9: データ量が多くなるということは、その分Executorで処理する情報量も多くなる 大規模なインスタンスを減らすことにより、シャッフル負荷の高いワークロードの実行中にデータを転送する際のI/Oを削減することが可能。
- #12: クラスターポリシー:クラスターを作成するときに使用できる構成オプションを制限するための一連のルール。規則に基づいてユーザーまたはグループのクラスター作成のアクセス許可を制御する。 クラスターポリシーによってできること ?指定された設定でユーザーがクラスターを作成できるように制限をかける ?ユーザーが特定のクラスターを作成するように制限する ?ユーザーインターフェースを単純化して、多くのユーザーが独自のクラスターを作成できるようにする ?クラスターあたりの最大コストを制御することで全体のコストをコントロールする https://learn.microsoft.com/ja-jp/azure/databricks/administration-guide/clusters/policies マルチノード / シングルノード:スライドの通り。
- #13: アクセスモード:Unity Catalogで保護されたデータへのアクセス方法を設定する。 https://learn.microsoft.com/ja-jp/azure/databricks/clusters/cluster-ui-preview#--what-is-cluster-access-mode シングルユーザーを指定した場合、指定されたユーザーのみがUnity Catalog内のデータにアクセスすることができる。 共有を指定した場合、対象のクラスターを利用できるユーザーがUnity Catalog内のデータにアクセスできる。(サードパーティ製ライブラリ、JARSがサポートされていないなど、制約あり) Runtimeバージョン: https://learn.microsoft.com/ja-jp/azure/databricks/runtime/?source=recommendations
- #14: クラスターノードの型: https://learn.microsoft.com/ja-jp/azure/databricks/clusters/create-cluster#--cluster-node-type ※Sparkジョブを実行する際には、少なくとも1台のワーカーノードが必要。
- #16: データ量が多くなるということは、その分Executorで処理する情報量も多くなる 大規模なインスタンスを減らすことにより、シャッフル負荷の高いワークロードの実行中にデータを転送する際のI/Oを削減することが可能。 ?データ分析:データアナリスト向けのクラスターは多くのシャッフル操作が発生する。シャッフルを実行するために必要なNWおよびディスクI/Oを削減するため、ノード数が少ないクラスターが推奨される。 ?バッチETL(単純):大規模な変換を必要としない場合、コンピューティングに最適化されたクラスターが推奨される。 ?バッチETL(複雑):シャッフルされるデータ量を最小限に抑えることで最適実行される。データ分析同様ノード数を少なくするクラスターが推奨される。 ?機械学習トレーニングモデル:導入初期は小規模なクラスターを使用し、シャッフルの影響を小さくする。安定性が求められる場合はクラスターの規模を大きくする。しかしシャッフルが大量に発生するような構成はおススメされない。
- #18: 中規模(2~8ノード)のクラスターで開発を行う。 機能要件を満たしたら、CPU、メモリ、およびI/Oを集計レベルで測定し、 より大きなデータに対してテストを行う。 クラスターを最適化して、手順2で見つかったボトルネックを取り除く ボトルネックで考えられるのは、 ?CPUバウンド:ノードを追加してコアを追加する ?NWバウンド:使用するSSDベースのマシンの数を減らし、NWサイズを縮小、リモート読み取りパフォーマンスを向上させる ?ディスクI/Oバウンド:ジョブがディスクに流出してしまう場合、より多くのメモリを搭載しているVMを使用する。 これにより、SLAを満たすことができるベースラインクラスターサイズに到達できる。
- #19: ボトルネックで考えられるのは、 ?CPUバウンド:ノードを追加してコアを追加する ?NWバウンド:使用するSSDベースのマシンの数を減らし、NWサイズを縮小、リモート読み取りパフォーマンスを向上させる ?ディスクI/Oバウンド:ジョブがディスクに流出してしまう場合、より多くのメモリを搭載しているVMを使用する。 これにより、SLA(Service Level Agreement)を満たすことができるベースラインクラスターサイズに到達できる。
- #20: シャッフルにおいてキーとなる属性はパーティションの数です。パーティションの最适な数はデータに依存しますが、データサイズはステージごと、クエリーごとに大きく异なるため、数をチューニングすることが困难。
- #21: 抽象的ですが…。
- #22: ペルソナは、Data Science & Data Engineer / Machine Learning / SQLの3つで構成されている。 Data Science & Data Engineer、Machine Learningは名前の通り利用イメージができるかと思う。SQL はSpark SQLがData Science & Data Engineerでも使えるので、どう使えば?となりがち(著者が苦笑)
- #23: Databricks SQLとは何か? - Qiita
- #24: SQL開発者向けDatabricksのご紹介 - Qiita