






![ūĀīĪÎ―ĖĪĘĪ·ÐÎBËØ―âÎö
n?? ūĀīĪÎ―ĖĪĘĪ·ÐÎBËØ―âÎöĪÏ
gÕZ·ÖļîĪÎ
ĪßĪōQĪÃĪÆĪĪĪë
n?? Æ·Ô~ĪÏŋž]ĪĩĪėĪĘĪĪ
2015/04/30 9
Æ·Ô~ĮéóĪŽąØŌŠĪĘĪéĪÐ
eÍū―ĖĪĘĪ·Æ·Ô~ÍÆķĻ?ĘÖ·ĻĪČ
―MĪßšÏĪïĪŧĪëąØŌŠĪŽĪĒĪë](https://image.slidesharecdn.com/dsirnlp7-150430055828-conversion-gate01/85/Dsirnlp-7-9-320.jpg)






![Ėá°ļ?ĘÖ·ĻĪÎ?ÉúģÉĨâĨĮĨë
n?? ëLĪėĨŧĨßĨÞĨëĨģĨÕĨâĨĮĨë
p??ÓQyĪÏ?ÎÄŨÖÁÐÁÐĪÎĪß
p??
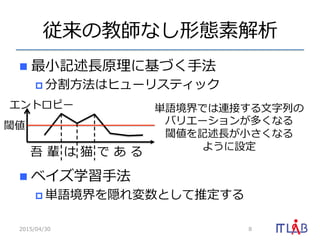
gÕZĪČÆ·Ô~ĪÎI?·―ĪōëLĪėäĘýĪČĪđĪë
p???ÉúÆðī_ÂĘÂĘÂĘĪŽ
gÕZngramĪōŋž]Ī·ĪÆĪĪĪë
2015/04/30 16](https://image.slidesharecdn.com/dsirnlp7-150430055828-conversion-gate01/85/Dsirnlp-7-16-320.jpg)


![Nested Pitman-Yor Language Model
[Mochihashi, 2009]
n?? Ėá°ļ?ĘÖ·ĻĪÎÆ·Ô~ĘýĪō1ĪËĪ·ĪŋÎïĪŽNPYLMĪČ
?ŌŧÖÂĪđĪë
n?? ĪÄĪÞĪęĖá°ļ·ĻĪÏNPYLMĪÎĪËĪĘĪÃĪÆĪĪĪë
n??
gÕZ unigram ĪÎĨđĨāĐ`ĨļĨóĨ°ĪËĪÏ?ÎÄŨÖ ?
ngramĪō?ÓÃĪĪĪÆĪĪĪë
2015/04/30 19](https://image.slidesharecdn.com/dsirnlp7-150430055828-conversion-gate01/85/Dsirnlp-7-19-320.jpg)




![Į°ÏōĪī_ÂĘÂĘÂĘĪÎÓËã
2015/04/30 25
[t][k][z] =
t k
j=1
Z
r=0
P(ct
t k|ct k
t k j+1, z)P(z|r) [t k][j][r]
EOSBOS ÖT ?ÐÐÐÐ o ģĢ ĪÎ í
ÖT?ÐÐÐÐ ?ÐÐÐÐo oģĢ ģĢĪÎ ĪÎí
word length
POS
index
time ÖT?ÐÐÐÐo ?ÐÐÐÐoģĢ oģĢĪÎ ģĢĪÎí
ĶÁ[6][1][1] ĄúĢĻĶÁ[í][1]ĢĐ
ĪÄĪÞĪęÖÜÞxŧŊĪ·ĪÆ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ĪōĮóĪáĪÆĪĪĪë ?P(í, 1)](https://image.slidesharecdn.com/dsirnlp7-150430055828-conversion-gate01/85/Dsirnlp-7-25-320.jpg)









![[DLÝÕiŧá]Reward Augmented Maximum Likelihood for Neural Structured Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0804-170803075139-thumbnail.jpg?width=560&fit=bounds)





























More Related Content
Viewers also liked (20)
Recently uploaded (11)









Dsirnlp#7
- 1. ëLĪėĨŧĨßĨÞĨëĨģĨÕĨâĨĮĨëĪËĪčĪë ―ĖĪĘĪ·ÐÎBËØ―âÎö ĨĮĨóĨ―Đ`ĨĒĨĪĨÆĨĢĐ`ĨéĨÜĨéĨČĨę ÄÚšĢ ?c ?kuchiumi@d-itlab.co.jp VÔ ?ÔĢĘ· ?htsukahara@d-itlab.co.jp ―yÓĘýĀíĀíŅÐūŋËų ģÖō ??īóĩØ ?daichi@ism.ac.jp 2015/04/30 1
- 2. ―ĖĪĘĪ·ÐÎBËØ―âÎö ĢĻĪ·ĪįĪģĪŋĪóĨÖĨíĨ°ĪÎĀýĀýĢĐ n?? ?Čë?ÁĶÁĶ ĨŊĨęĨŠĮÞ?ŨÓĨßĨëĨŊĨÐĨóiĪŊĪÆ(???)??!!ĄĢĪ·ĪčĪĶĪģ ? ĮÞÆðĪĪéĪĪĨÆĨĢĨóĪÏģŊ?Įā?ýýËÆĪđĪĘĪĄĪéĪĪĨÆĨĢĨóĄĒiPad2ĪÎĨģĨĪĨóĨēĐ` ĨāĪōĪļĪÃĪČ?ŌŌĪÄĪáĪÆ?ĘŨĪŦĪ·ĪēĄĒĨģĨĪĨóÂäÂäĪČĪ·ĪËēΞÓĪ·ĪŋwwwwwĪŦĪï ĪæĪđĪĘĢĄĨŪĨķĨŦĨïĨæĨđ ? ËØĮįĪéĪ·ĪĪĨŊĨŠĨęĨÆĨĢĪÎĨĻĨŊĨđĨÆ(Đb?Đb)(Đb?Đb)(Đb?Đb )Đ`Đ`Đ`ĢĄĢĄĢĄĪ·ĪĪĨÞĨęĨđŌ°?ŋÚĪĩĪÞĪĒĪęĪŽĪČĪĶĪīĪķĪĪĪÞĪđ n?? ģö?ÁĶÁĶ ĨŊĨęĨŠĮÞ?ŨÓ/ĨßĨëĨŊĨÐĨó/iĪŊĪÆ/(???)/??!!/ĄĢĪ·ĪčĪĶĪģ ? ĮÞÆðĪ/ĪéĪĪĨÆĨĢĨó/ĪÏ/ģŊ/?Įā?ýýËÆ/ĪđĪĘĪĄ/ĪéĪĪĨÆĨĢĨó/ĄĒ/iPad/2/ ĪÎ/ĨģĨĪĨóĨēĐ`Ĩā/Īō/ĪļĪÃĪČ/?ŌŌĪÄĪá/ĪÆ/?ĘŨ/ĪŦĪ·Īē/ĄĒ/ĨģĨĪĨó/ÂäÂäĪČ Ī·/ĪË/ēΞÓ/Ī·/Īŋ/wwwww/ĪŦĪïĪæ/ĪđĪĘ/ĢĄ/ĨŪĨķĨŦĨïĨæĨđ ? ËØĮįĪéĪ·ĪĪ/ĨŊĨŠĨęĨÆĨĢ/ĪÎ/ĨĻĨŊĨđĨÆ/(Đb?Đb)/(Đb?Đb)/(Đb?Đb) /Đ`Đ`Đ`/ĢĄĢĄĢĄ/Ī·ĪĪ/ĨÞĨęĨđ/Ō°?ŋÚ/ĪĩĪÞ/ĪĒĪęĪŽĪČĪĶ/ĪīĪķĪĪĪÞĪđ 2015/04/30 2
- 3. ÐÎBËØ―âÎöĪČĪÏ n?? ?ŨÔČŧ?ŅÔÕZIĀíĀíĪÎŧųĩAžžÐg n?? ?ÎÄÕÂĪōÐÎBËØĪØ·ÖļîĪđĪë p?? ÐÎBËØĢšŌâÎķĪÎĪĒĪëŨî?ÐĄĪÎ gÎŧ 2015/04/30 3 ĄļÎáÝ ĪÏÃĻĪĮĪĒĪëĄĢĄđĪÎÐÎBËØ―âÎö―YĢĻMeCabĢĐ ÎŌÝ ĨïĨŽĨÏĨĪ īúÃûÔ~ ĪÏ Ĩï ÖúÔ~-ÏĩÖúÔ~ ÃĻ ĨÍĨģ ÃûÔ~-ÆÕÍĻÃûÔ~-?Ōŧ°ã ĪĮ ĨĮ ÖúÓÔ~-ĨĀ ĪĒĪë ĨĒĨë ÓÔ~-?·Į?ŨÔ?ÁĒÁĒŋÉÄÜ ĄĢ ĄĢ ŅaÖúÓšÅ-ūäūäĩã EOS
- 4. ―ĖĪĒĪęÐÎBËØ―âÎö 2015/04/30 4 ?Čë?ÁĶÁĶ?ÎÄĢšÎŌÝ ĪÏÃĻĪĮĪĒĪë ?ÎÄî^ ÎŌ Ý ÎŌÝ ĪÏ ÃĻ ĪĮ ĪĒĪë ĪĮĪĒĪë ?ÎÄÄĐ ÐÎBËØīĮøĪōŌýĪĪĪÆĢŽ?ŌŌĪÄĪŦĪÃĪŋÐÎBËØĪĮĨéĨÆĨĢĨđĪōŨũĪë ÐÎBËØīĮøĢŦ 0.3 0.3 0.3 0.1 0.1 0.2 ?Ōŧ·Žī_ÂĘÂĘÂĘĪÎ?ļßĪĪ―U··Īō?ŌŌĪÄĪąĪë
- 5. ?ÉúÆðī_ÂĘÂĘÂĘĪČßwŌÆī_ÂĘÂĘÂĘ 2015/04/30 5 ?ÎÄî^ ÎŌ Ý ÎŌÝ 0.3 0.3 0.3 0.1 0.2 P(ÃûÔ~ | ÃûÔ~) = 0.2 P(ÎŌÝ | ÃûÔ~) = 0.1 ßwŌÆī_ÂĘÂĘÂĘ ?ÉúÆðī_ÂĘÂĘÂĘ
- 6. ī_ÂĘÂĘÂĘĪÎÓËã 2015/04/30 6 ÎŌĄĐ ? ? ? ?ÃûÔ~ ĪČ ? ? ? ? ? ?ÖúÔ~ Ī·ĪÆ ? ? ? ?ÓÔ~ ĪÏ ? ? ? ? ? ?ÖúÔ~ ĪÞĪĀ ? ? ? ?ļąÔ~ ÏĢÍû ? ? ? ?ÃûÔ~ ĪÏ ? ? ? ? ? ?ÖúÔ~ ÎĪÆĪÆ ? ?ÓÔ~ ĪĪ ? ? ? ? ? ?―ÓÎēīĮ ĪĘĪĪ ? ? ? ?―ÓÎēīĮ ?ĄĢ ? ? ? ? ? ?ĖØĘâ Õý―âĨĮĐ`ĨŋĢĻ?ČË?ĘÖĢĐ P(ÃûÔ~ | ÃûÔ~) = ÃûÔ~ĪČÃûÔ~ĪÎßB―ÓŧØĘý ÃûÔ~ĪÎģöŽFŧØĘý n?? ßwŌÆī_ÂĘÂĘÂĘ n?? ?ÉúÆðī_ÂĘÂĘÂĘ P(ÎŌÝ | ÃûÔ~) = ÃûÔ~ĪČÎŌÝ ĪÎđēÆðŧØĘý ÃûÔ~ĪÎģöŽFŧØĘý
- 7. Õý―âĨĮĐ`ĨŋĪÎŨũģÉĪäīĮøĪÎĨáĨóĨÆ n?? ?ČË?ĘÖĪÏ?ÐÁĪĪ 2015/04/30 7 ĨŊĨęĨŠĮÞ?ŨÓĨßĨëĨŊĨÐĨóiĪŊĪÆ(???)??!!ĄĢĪ·ĪčĪĶĪģ ? ĮÞÆðĪĪéĪĪĨÆĨĢĨóĪÏģŊ?Įā?ýýËÆĪđĪĘĪĄĪéĪĪĨÆĨĢĨóĄĒiPad2ĪÎĨģ ĨĪĨóĨēĐ`ĨāĪōĪļĪÃĪČ?ŌŌĪÄĪáĪÆ?ĘŨĪŦĪ·ĪēĄĒĨģĨĪĨóÂäÂäĪČĪ·ĪËēÎžÓ Ī·ĪŋwwwwwĪŦĪïĪæĪđĪĘĢĄĨŪĨķĨŦĨïĨæĨđ ? ËØĮįĪéĪ·ĪĪĨŊĨŠĨęĨÆĨĢĪÎĨĻĨŊĨđĨÆ(Đb?Đb)(Đb?Đb)(Đb?Đb )Đ`Đ`Đ`ĢĄĢĄĢĄĪ·ĪĪĨÞĨęĨđŌ°?ŋÚĪĩĪÞĪĒĪęĪŽĪČĪĶĪīĪķĪĪĪÞĪđ ―ĖĪĘĪ·ÐÎBËØ―âÎöĪŽÍûĪÞĪėĪë ĢĻīĮøĪĘĪ·ĢŽÕý―âĪÎļķÓëĪĘĪ·ĢĐ
- 8. ūĀīĪÎ―ĖĪĘĪ·ÐÎBËØ―âÎö n?? Ũî?ÐĄÓĘö??éLÔĀíĀíĪËŧųĪÅĪŊ?ĘÖ·Ļ p??·Öļî?·―·ĻĪÏĨŌĨåĐ`ĨęĨđĨÆĨĢĨÃĨŊ n?? ĨŲĨĪĨšŅ§Á?ĘÖ·Ļ p?? gÕZūģ―įĪōëLĪėäĘýĪČĪ·ĪÆÍÆķĻĪđĪë 2015/04/30 8 Îá ?Ý ?ĪÏ ?ÃĻ ?ĪĮ ?ĪĒ ?Īë gÕZūģ―įĪĮĪÏßB―ÓĪđĪë?ÎÄŨÖÁÐÁÐĪÎ ĨÐĨęĨĻĐ`Ĩ·ĨįĨóĪŽķāĪŊĪĘĪë éĪōÓĘö??éLĪŽ?ÐĄĪĩĪŊĪĘĪë ĪčĪĶĪËÔOķĻ ĨĻĨóĨČĨíĨÔĐ` é
- 9. ūĀīĪÎ―ĖĪĘĪ·ÐÎBËØ―âÎö n?? ūĀīĪÎ―ĖĪĘĪ·ÐÎBËØ―âÎöĪÏ gÕZ·ÖļîĪÎ ĪßĪōQĪÃĪÆĪĪĪë n?? Æ·Ô~ĪÏŋž]ĪĩĪėĪĘĪĪ 2015/04/30 9 Æ·Ô~ĮéóĪŽąØŌŠĪĘĪéĪÐ eÍū―ĖĪĘĪ·Æ·Ô~ÍÆķĻ?ĘÖ·ĻĪČ ―MĪßšÏĪïĪŧĪëąØŌŠĪŽĪĒĪë
- 10. ―ĖĪĘĪ·Æ·Ô~ÍÆķĻ n?? ŧųąūĩÄĪË Hidden Markov Model ĪĮ?ÐÐÐÐĪĶ p??ĘÂĮ°·ÖēžĪäÍÆķĻ?·―·ĻĪŽĪĪĪíĪĪĪí n?? gÕZ·ÖļîĪŽÓëĪĻĪéĪėĪÆĪĪĪëĪģĪČĪŽĮ°Ėá 2015/04/30 10 x i - 1 xi xi + 1 y i - 1 yi yi+1 y: Æ·Ô~ x: gÕZ
- 11. gÕZ·ÖļîūŦķČķČĪËÆ·Ô~ĪÏÓ°íĪđĪëĢŋ n?? ŌÔÏÂĪÎĀýĀý?ÎÄĪōŋžĪĻĪë n?? ?ÎÄ·ĻĩÄĪĘÖŠŨRŨRĪĘĪ·ĪĮ―âÎöĪđĪëöšÏ n?? ÃûÔ~ĪŦĪéĪÏÓÔ~?―ÓÎēĪËĪÏ―ÓūAĪ·ĪËĪŊĪĪ ĪČĪĪĪĶÖŠŨRŨR p???ÎÄ·ĻĩÄĪËĄąĪĪÎĪģ/ĪėĪ륹ĪÏģöĪËĪŊĪĪĪČ·ÖĪŦĪë 2015/04/30 11 ĄļĪģĪÎÏČ?ÉúĪĪÎĪģĪėĪëĪÎĪŦĢŋĄđ ĪģĪÎ/ÏČ?Éú/ĪĪÎĪģ/ĪėĪë/ĪÎ/ĪŦ/Ģŋ ĪģĪÎ/ÏČ/?ÉúĪ/ĪÎĪģĪėĪë/ĪÎ/ĪŦ/Ģŋ (MeCabĪÎ―âÎö―Yđû)
- 13. ÐÎBËØ―âÎöĪÎķĻĘ―ŧŊ n?? ÐÎBËØ―âÎö: n?? ?ĄĄ?ĄĄĢš gÕZĢŽ ? ? ?ĢšÆ·Ô~ĢŽ ? ?Ģš?ÎÄŨÖĢŽ ? ?Ģš?ÎÄ n?? ī_ÂĘÂĘÂĘ ? ? ? ? ? ? ? ? ? ? ? ? ?ĪōŨî?īóŧŊĪđĪëĪčĪĶĪĘ w ĪōÍÆ ķĻĪđĪëî} ? ? ? ? ? ? ?w = argmax w p(w|s) s : c1, c2, . . . , cN p(w|s) wn cn szn 13 w = {w1, w2, . . . , wM , z1, z2, . . . , zM }
- 14. ēŋ·Öî}ĪË·Öļî n?? ÐÎBËØ―âÎö w ĪÎī_ÂĘÂĘÂĘĪōŌÔÏÂĪČĪŠĪŊ n?? ŌÔÏÂĪÎĪčĪĶĪËäÐÎ 2015/04/30 14 P(w|s) = M i=1 P(wi, zi|hi 1) hi = {w1, w2, . . . , wi, z1, z2, . . . , zi} P(wi, zi|hi 1) = P(wi|zi, hi 1)P(zi|hi 1) P(wi|zi, hi 1) = P(wi|wi 1 i N+1, zi) P(zi|hi 1) = P(zi|zi 1 i N+1) Æ·Ô~°ĪÎ gÕZngram Æ·Ô~ngram
- 15. ngramĨâĨĮĨë 2015/04/30 15 ?ÎÄî^ ÎŌ Ý ÎŌÝ ĪÏ ÃĻ ĪĮ ĪĒĪë ĪĮĪĒĪë ?ÎÄÄĐ 0.1 0.2 P(ÎŌÝ | ÎÄî^, ÃûÔ~) P(ÃûÔ~ | ÃûÔ~) Æ·Ô~ bigram gÕZ bigram
- 17. ĨžĨíîlķČķČî} n?? ?ŌŌĪŋĪģĪČĪÎoĪĪngramĪÎī_ÂĘÂĘÂĘĪŽ0ĪËĪĘĪë 2015/04/30 17 ?ÎÄî^ ÎŌ Ý ÎŌÝ ĪÏ ÃĻ ĪĮ ĪĒĪë ĪĮĪĒĪë ?ÎÄÄĐ P(ÃĻ | ĪÏ, ÃûÔ~) = c(ÃĻ | ĪÏ, ÃûÔ~) c(ĪÏ, ÃûÔ~) = 0 P(ÎŌÝ , ĪÏ, ÃĻ, ĪĮ, ĪĒĪë) = 0 ÓQyĪĩĪėĪÆĪĘĪĪ ?ngram ĪËĪâßmĮÐĮÐĪĘī_ÂĘÂĘÂĘĪōÓëĪĻĪëąØŌŠĪŽĪĒĪë ―ĖĪĘĪ·Ņ§ÁĪĀĪČŨîģõĪÏ gÕZĪŽ·ÖĪŦĪÃĪÆĪĘĪĪĪÎĪĮīųĪÉĨžĨíîlķČķČ
- 18. gÕZ/Æ·Ô~ngramī_ÂĘÂĘÂĘ n?? ëAÓPitman-Yor?ŅÔÕZĨâĨĮĨëĪō?ÓÃĪĪĪë 2015/04/30 18 P(w|h) = c(w|h) d ĄĪ thw + c(h) + + d ĄĪ thĄĪ + c(h) P(w|h ) N-1 gram ĪÎī_ÂĘÂĘÂĘĪĮūÐÎŅaÍę ĢĻÔŲĒĩÄĪË?ÐÐÐÐĪïĪėĪëĢĐ N-gram ĪÎī_ÂĘÂĘÂĘ (îlķČķČĪōĨĮĨĢĨđĨŦĨĶĨóĨČ) ĨđĨāĐ`ĨļĨóĨ° ĨđĨāĐ`ĨļĨóĨ°ĪÏūĀīĨŌĨåĐ`ĨęĨđĨÆĨĢĨÃĨŊĪĘ?ĘÖ·ĻĪŽķāĪĪ HPYLMĪÏÁžÁžĪŊ?ÓÃĪĪĪéĪėĪë Interpolated Kneser-ney Īō ĨŲĨĪĨšĩÄĪĘ―MĪßĪĮŨ―ĪĻÖąĪ·ĪŋĪâĪÎ
- 19. Nested Pitman-Yor Language Model [Mochihashi, 2009] n?? Ėá°ļ?ĘÖ·ĻĪÎÆ·Ô~ĘýĪō1ĪËĪ·ĪŋÎïĪŽNPYLMĪČ ?ŌŧÖÂĪđĪë n?? ĪÄĪÞĪęĖá°ļ·ĻĪÏNPYLMĪÎĪËĪĘĪÃĪÆĪĪĪë n?? gÕZ unigram ĪÎĨđĨāĐ`ĨļĨóĨ°ĪËĪÏ?ÎÄŨÖ ? ngramĪō?ÓÃĪĪĪÆĪĪĪë 2015/04/30 19
- 20. ĨŅĨéĨáĐ`ĨŋÍÆķĻ n?? ÓĩÄÓŧ·ĻĪČMCMCĪō―MĪßšÏĪïĪŧĪŋ?ĘÖ·Ļ p??blocked Gibbs sampling n?? ?ĄĄ?ĄĄ?ĄĄ?ĄĄ?ĄĄ?ĄĄ?ĄĄ?ĄĄĪōÍÆķĻĪđĪë 2015/04/30 20 : gÕZ ?ngram ?ŅÔÕZĨâĨĮĨë : Æ·Ô~ ?ngram ĨâĨĮĨëĪÎĨŅĨéĨáĐ`Ĩŋ z P(w|s; z, )
- 21. Ņ§ÁĨĒĨëĨīĨęĨšĨā 1.? ļũ?ÎÄĪËĨéĨóĨĀĨāĪËÆ·Ô~ĪōļîĩąĪÆĪë 2.? ?ÎÄĪō gÕZĪČ?ŌŌĪĘĪ·ĢŽ gÕZ/Æ·Ô~HPYLMĪōļüļüР3.? §ĘøĪđĪëĪÞĪĮŌÔÏÂĪōĀRĪę·ĩĪđ 1.? ĨéĨóĨĀĨāĪË?ÎÄsĪōßxkĪ·ĢŽsĪÎÐÎBËØ―âÎö―Yđûw(s)Īō ĨŅĨéĨáĐ`ĨŋĪŦĪéģýČĨ 2.? ģýČĨááĪÎĨŅĨéĨáĐ`ĨŋĪō?ÓÃĪĪĪÆÐÎBËØ―âÎö―YđûĪōĨĩĨó ĨŨĨęĨóĨ° 3.? wĄŊ(s)Īō?ÓÃĪĪĪÆĨŅĨéĨáĐ`ĨŋĪōļüļüР2015/04/30 21 w (s) P(w|s; z, ) Ąų?ŅÔÕZĨâĨĮĨëĪÎļüļüÐÂĪÏŌÔÏÂĪōēÎÕÕ Y. W. Teh. A Bayesian Interpretation of In- terpolated Kneser-Ney. Technical Report TRA2/06, School of Computing, NUS.
- 22. ÐÎBËØ―âÎöĪÎĨĩĨóĨŨĨęĨóĨ° n?? ?Čë?ÁĶÁĶĢšĄļÖT?ÐÐÐÐoģĢĪÎíĄđ n?? ÐÎBËØ―âÎöĪÎī_ÂĘÂĘÂĘĪËūĪÃĪÆ1ĪÄĨĩĨóĨŨĨëĪđ Īë 2015/04/30 22 P(ÖTÐÐ, oģĢ, ĪÎ, í, 1, 1, 2, 1) = 0.1 P(ÖT, ÐÐ, oģĢ, ĪÎí, 1, 1, 1, 2) = 0.01 ? ? ? ―MšÏĪŧĪŽÅō?īóĪĘĪÎĪĮŋÂĘÂĘÂĘĪŽĪĪ ÓĩÄÓŧ·ĻĪĮŋÂĘÂĘÂĘĩÄĪË―âĪŊ
- 23. ÐÎBËØ―âÎöĪÎĨĩĨóĨŨĨęĨóĨ° n?? ļũ gÕZšōŅaĪČÆ·Ô~ĪÎÍŽrī_ÂĘÂĘÂĘĪōÓËã 2015/04/30 23 ÖÜÞxŧŊ P(ÖT, ÐÐ, o, ģĢ, ĪÎ,í, 1, 1, 1, 1, 2, 1) +P(ÖTÐÐ, oģĢ, ĪÎ,í, 1, 1, 2, 1) +P(ÖTÐÐoģĢ, ĪÎ,í, 1, 2, 1) + ĄĪ ĄĪ ĄĪ = P(í, 1)
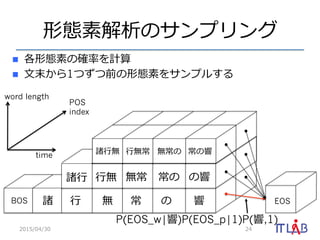
- 24. ÐÎBËØ―âÎöĪÎĨĩĨóĨŨĨęĨóĨ° n?? ļũÐÎBËØĪÎī_ÂĘÂĘÂĘĪōÓËã n?? ?ÎÄÄĐĪŦĪé1ĪÄĪšĪÄĮ°ĪÎÐÎBËØĪōĨĩĨóĨŨĨëĪđĪë 2015/04/30 24 EOSBOS ÖT ?ÐÐÐÐ o ģĢ ĪÎ í ÖT?ÐÐÐÐ ?ÐÐÐÐo oģĢ ģĢĪÎ ĪÎí word length POS index time ÖT?ÐÐÐÐo ?ÐÐÐÐoģĢ oģĢĪÎ ģĢĪÎí P(EOS_w|í)P(EOS_p|1)P(í,1)
- 25. Į°ÏōĪī_ÂĘÂĘÂĘĪÎÓËã 2015/04/30 25 [t][k][z] = t k j=1 Z r=0 P(ct t k|ct k t k j+1, z)P(z|r) [t k][j][r] EOSBOS ÖT ?ÐÐÐÐ o ģĢ ĪÎ í ÖT?ÐÐÐÐ ?ÐÐÐÐo oģĢ ģĢĪÎ ĪÎí word length POS index time ÖT?ÐÐÐÐo ?ÐÐÐÐoģĢ oģĢĪÎ ģĢĪÎí ĶÁ[6][1][1] ĄúĢĻĶÁ[í][1]ĢĐ ĪÄĪÞĪęÖÜÞxŧŊĪ·ĪÆ ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ĪōĮóĪáĪÆĪĪĪë ?P(í, 1)
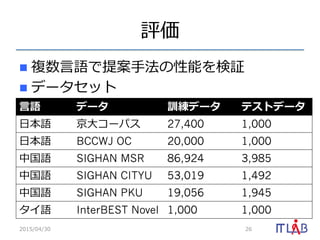
- 26. Ôuý n?? Ņ}Ęý?ŅÔÕZĪĮĖá°ļ?ĘÖ·ĻĪÎÐÔÄÜĪōĘÔ^ n?? ĨĮĐ`ĨŋĨŧĨÃĨČ 2015/04/30 26 ?ŅÔÕZ ĨĮĐ`Ĩŋ ÓūĨĮĐ`Ĩŋ ĨÆĨđĨČĨĮĐ`Ĩŋ ?ČÕąūÕZ ūĐ?īóĨģĐ`ĨŅĨđ 27,400 1,000 ?ČÕąūÕZ BCCWJ OC 20,000 1,000 ÖÐđúÕZ SIGHAN MSR 86,924 3,985 ÖÐđúÕZ SIGHAN CITYU 53,019 1,492 ÖÐđúÕZ SIGHAN PKU 19,056 1,945 ĨŋĨĪÕZ InterBEST Novel 1,000 1,000
- 27. gōYÔOķĻ1 n?? ―ĖĪĘĪ·Ņ§Á p?? ÓūĨĮĐ`ĨŋĪËļķÓëĪĩĪėĪÆĪĪĪë gÕZūģ―įĪÎĮéóĪÏČŦ ĪÆÏũģý p?? ÓËãĪÎŋÂĘÂĘÂĘŧŊĪÎĪŋĪáĪËŨî?īó gÕZ??éLĪō?ŅÔÕZ°ĪËÔOķĻ v?? ?ČÕąūÕZĢš?ÎÄŨÖ·N°ĪËÔOķĻĢĻhŨÖ8ĢŽĨŦĨŋĨŦĨĘ21ĢŽetc.ĢĐ v?? ÖÐđúÕZĢš4?ÎÄŨÖ v?? ĨŋĨĪÕZĢš6?ÎÄŨÖ p?? ĮąÔÚĨŊĨéĨđĪÎĘý v?? ūĐ?īóĨģĐ`ĨŅĨđĢš20 v?? BCCWJ OCĢš30 v?? SIGHANĢš10 v?? BESTĢš10 2015/04/30 27
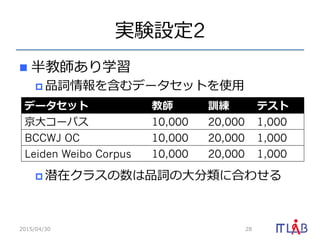
- 28. gōYÔOķĻ2 n?? °ë―ĖĪĒĪęŅ§Á p??Æ·Ô~ĮéóĪōšŽĪāĨĮĐ`ĨŋĨŧĨÃĨČĪōĘđ?Óà p??ĮąÔÚĨŊĨéĨđĪÎĘýĪÏÆ·Ô~ĪÎ?īó·ÖîĪËšÏĪïĪŧĪë 2015/04/30 28 ĨĮĐ`ĨŋĨŧĨÃĨČ ―Ė Óū ĨÆĨđĨČ ūĐ?īóĨģĐ`ĨŅĨđ 10,000 20,000 1,000 BCCWJ OC 10,000 20,000 1,000 Leiden Weibo Corpus 10,000 20,000 1,000
- 29. ÔuýģßķČķČ n?? gÕZ·ÖļîĪÎÔuý p?? gÕZĪÎé_ĘžÎŧÖÃĪČ―KÁËÁËÎŧÖÃĪŽ―ĖĨĮĐ`ĨŋĪČ?ŌŧÖÂĪ· ĪŋrĪÎĪßÕý―âĪČĪđĪë p?? ÔuýģßķČķČĪËĪÏFĪō?ÓÃĪĪĪŋ n?? Æ·Ô~ÍÆķĻĪÎÔuý p?? ÕýĪ·ĪŊ·ÖļîĪĮĪĪŋ gÕZĪËĪÄĪĪĪÆĪÎÆ·Ô~ūŦķČķČĪō?ÓÃĪĪ Īë p?? ―ĖĨĮĐ`ĨŋĪČĮąÔÚĨŊĨéĨđĪÎęĪÏĢŽĮąÔÚĨŊĨéĨđĪī ĪČĪËđēÆðĪ·ĪŋÆ·Ô~ĨéĨŲĨëĪÎîlķČķČĪōĮóĪáĢŽŨîĪâķāĪŊ đēÆðĪ·ĪŋÆ·Ô~ĪČĮąÔÚĨŊĨéĨđĪōęļķĪąĪŋ 2015/04/30 29
- 30. ―ĖĪĘĪ· gÕZ·ÖļîĪÎÔuý 2015/04/30 30 ĨĮĐ`Ĩŋ PYHSMM NPYLM BE+MDL HDP+HMM ūĐ?īóĨģĐ`ĨŅĨđ 0.715 0.621 0.713 - BCCWJ 0.705 - - - MSR 0.829 0.802 0.782 0.817 CITYU 0.817 0.824 0.787 - PKU 0.816 - 0.808 0.811 BEST 0.821 - 0.821 -
- 31. ―ĖĪĘĪ·Æ·Ô~ÍÆķĻĪÎÔuý n?? ÕýĪ·ĪĪ gÕZ·ÖļîĪōÓëĪĻĪŋöšÏĪčĪęĪâÁžÁžĪĪ―Yđû 2015/04/30 31 ĨĮĐ`Ĩŋ PYHSMM NPYLM+BHMM Õý―â·Öļî+BHMM ūĐ?īóĨģĐ`ĨŅĨđ 0.574 0.538 0.495 BCCWJ 0.502 0.441 0.442 LWC 0.330 0.309 0.329 ĄųLWCĪÎÕý―âĪÏžČīæĪÎÖÐđúÕZĪÎÐÎBËØ―âÎöÆũĪĮļķÓëĪĩĪėĪŋĪâĪÎ ?ĄĄĪĒĪŊĪÞĪĮēÎŋžĘý
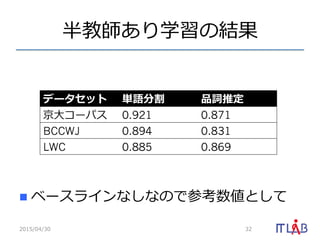
- 32. °ë―ĖĪĒĪęŅ§ÁĪÎ―Yđû n?? ĨŲĐ`ĨđĨéĨĪĨóĪĘĪ·ĪĘĪÎĪĮēÎŋžĘýĪČĪ·ĪÆ 2015/04/30 32 ĨĮĐ`ĨŋĨŧĨÃĨČ gÕZ·Öļî Æ·Ô~ÍÆķĻ ūĐ?īóĨģĐ`ĨŅĨđ 0.921 0.871 BCCWJ 0.894 0.831 LWC 0.885 0.869
- 33. ―âÎö―YđûĪÎĀýĀý n?? ČýšÓÛÍĪÎĀýĀýĢĻKĢ―ĢĩĢ°ĢĐ ĨĶĨ§Đ`ĨÖĨđĨŋĨļĨĒĨā/34 ØŨ?đČ/28 ĪË/2 FC/1 ØŨ?đČ/28 ĪÎ/2 Ô ?šÏ/ 31 Īō/2 ÓQ/35 ĪË/2 ?ÐÐÐÐ/27 ĪÃĪÆ/40 Īß/35 ĪęĪó/3 ĨÕĨĐĨíĨÐ/17 ĪĒĪęĪŽĪČ/19 ĪīĪķĪĪĪÞĪđ/19 ! /2 ĪčĪíĪ·ĪŊ/19 îm ?Īā/35 ĪÎĪó/ 3 ĄĢ/10 ĪģĪė/20 ĪŪĪ·/37 Ī·ĪŦ/37 ĪĘĪĪ/12 ĪĀ/12 ĪŦĪó/3 ? /10 ĪĒĪąĪŠ Īá/19 ĪĀ/12 ĪūĪó/3 !! /10 ―ņÄęÄę/18 Īâ/2 ĪčĪíĪ·ĪŊ ?/19 îmĪā/35 ĪūĪó/3 !! /10 ĪŠĪÞ/13 Đ`/5 ĪÎ/2 î^/25 ĄĒ/2 ĪÁĪóĪļĪåĪĶ/35 ĪĀĪÎĪó/3 !! /8 w/ 8 Ī°Īí/36 ĪČ/24 Īâ/2 ?ŅÔ/15 ĪĶ/12 ĪÎĪó/3 !! /8 ĪČĪÁĪóĪģĪĮ/35 ―Y ĪóĪĮ/19 ĪÞĪÃĪŋĪâĪó/12 ĪĮ/12 ĄĒ/2 ĪČ/37 Īė ?/12 Īä/45 ĪŧĪó/ 13 ĪË/13 Đ`/5 (^_^;)/10 ĪÎĪóĪÛĪĪ/12 ĪÏ/2 ČôČôĪĪ/24 ?ČË/20 ĪÏ/2 ĪĒĪóĪÞĪ·/30 Ęđ/15 Īï ? Īó/12 ĪūĪó/3 !/10 ĪļĪĪĪĩĪó/24 ĄĒ/2 ĪÐĪĒĪĩĪó/37 ĘĀīú/25 ĪÎ ?/ 2 ?ŅÔČ~Č~/27 ĪĀ/12 ĪÎĪó/3 ! /8 /6 2015/04/30 33
- 37. ēÎŋž?ÎÄÏŨ n?? Miaohong Chen, et al. 2014. A Joint Model for Unsupervised Chinese Word Segmentation. In EMNLP 2014, pages 854ĻC1 863. n?? Sharon Goldwater, et al. A Fully Bayesian Approach to Unsupervised Part-of-Speech Tagging. In Proceedings of ACL 2007, pages 744ĻC 751. n?? Sharon Goldwater, et al. Contextual Dependencies in Un- supervised Word Segmentation. In Proceedings of ACL/COLING 2006, pages 673ĻC680. n?? Matthew J. Johnson et al. Bayesian Nonparametric Hidden Semi-Markov Models. Journal of Machine Learning Research, 14:673ĻC701. n?? Pierre Magistry et al. Can MDL Improve Unsupervised Chinese Word Segmenta- tion? In Proceedings of the Seventh SIGHAN Work- shop on Chinese Language Processing, pages 2ĻC10. n?? Daichi Mochihashi, et al. Bayesian Unsupervised Word Seg- mentation with Nested Pitman-Yor Language Mod- eling. In Proceedings of ACL-IJCNLP 2009, pages 100ĻC108. n?? Yee Whye Teh. A Bayesian Interpretation of In- terpolated Kneser-Ney. Technical Report TRA2/06, School of Computing, NUS. n?? Valentin Zhikov, et al. An Efficient Algorithm for Unsuper- vised Word Segmentation with Branching Entropy and MDL. In EMNLP 2010, pages 832ĻC842. 2015/04/30 37