Expert Systems: Definition, Functioning, and Development Approach - [Part: 2]
0 likes25 views

Expert Systems: Definition, Functioning, and Development Approach - [Part: 2]
![Artificial Intelligence
Expert Systems: Definition, Functioning, and
Development Approach - [Part: 2]
Dr. DEGHA Houssem Eddine
March 17, 2025
Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 1/17](https://image.slidesharecdn.com/ai-part-4compressed-250325210427-f643e6f6/85/Expert-Systems-Definition-Functioning-and-Development-Approach-Part-2-1-320.jpg)













































More Related Content
Similar to Expert Systems: Definition, Functioning, and Development Approach - [Part: 2] (20)
Recently uploaded (20)


















Expert Systems: Definition, Functioning, and Development Approach - [Part: 2]
- 1. Artificial Intelligence Expert Systems: Definition, Functioning, and Development Approach - [Part: 2] Dr. DEGHA Houssem Eddine March 17, 2025 Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 1/17
- 3. Backward Chaining: A Goal-Driven Approach ─Ä Definition: ŌĆó f Backward Chaining is an inference method used in logical reasoning and artificial intelligence. ŌĆó ┬▒ It starts with a goal (hypothesis) and works backward to determine if known facts support it. ŌĆó ├É Commonly used in diagnostic systems, AI, and expert systems where the desired conclusion is known. ŌĆó ┼ā Ensures e’¼Ćicient problem-solving by focusing only on relevant conditions. Example: ─Å A doctor diagnosing a disease by analyzing symptoms and tracing back to possible causes. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 3/17
- 4. Backward Chaining: Thinking in Reverse How it Works: ŌĆó Starts with a goal: Verifies its validity by analyzing prior conditions. ŌĆó Used in AI: Applied in decision support systems and logical reasoning. ŌĆó E’¼Ćicient Processing: Focuses only on relevant information to reach conclusions. Example Scenario: AI diagnosing a network issue by tracing root causes step by step. Key Benefit: Increases e’¼Ćiciency by avoiding unnecessary data exploration. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 4/17
- 5. How Does Backward Chaining Work? Ŏ Step-by-Step Process: 1. İ Start with a clearly defined goal or hypothesis. 2. f Check existing facts and rules that may lead to the goal. 3. ± Work backward by analyzing dependencies and conditions. 4. ¬ Confirm or reject the hypothesis based on available data. Example: A security system determining if an unauthorized access attempt was made by checking log anomalies and system events. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 5/17
- 6. Data and Relationships Papers and Topics: ŌĆó Paper A: ŌĆØDeep Learning in NLPŌĆØ ŌĆó Paper B: ŌĆØNeural Network BasicsŌĆØ ŌĆó Paper C: ŌĆØAdvanced NLP ModelsŌĆØ ŌĆó Paper D: ŌĆØAttention MechanismsŌĆØ ŌĆó Paper E: ŌĆØTransformer NetworksŌĆØ ŌĆó Paper F: ŌĆØRenewable Energy SystemsŌĆØ ŌĆó Paper G: ŌĆØSolar Power InnovationsŌĆØ ŌĆó Paper H: ŌĆØWind Energy OptimizationŌĆØ Known Relationships: ŌĆó cites(PaperA, PaperB) ŌĆó cites(PaperA, PaperC) ŌĆó cites(PaperB, PaperD) ŌĆó coCited(PaperC, PaperD) ŌĆó coCited(PaperD, PaperE) ŌĆó cites(PaperE, PaperF) ŌĆó coCited(PaperF, PaperG) ŌĆó cites(PaperG, PaperH) Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 6/17
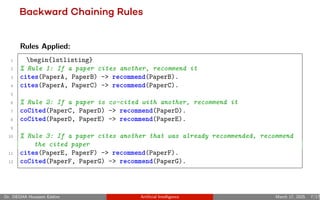
- 7. Backward Chaining Rules Rules Applied: 1 begin{lstlisting} 2 % Rule 1: If a paper cites another, recommend it 3 cites(PaperA, PaperB) -> recommend(PaperB). 4 cites(PaperA, PaperC) -> recommend(PaperC). 5 6 % Rule 2: If a paper is co-cited with another, recommend it 7 coCited(PaperC, PaperD) -> recommend(PaperD). 8 coCited(PaperD, PaperE) -> recommend(PaperE). 9 10 % Rule 3: If a paper cites another that was already recommended, recommend the cited paper 11 cites(PaperE, PaperF) -> recommend(PaperF). 12 coCited(PaperF, PaperG) -> recommend(PaperG). Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 7/17
- 8. Backward Chaining for Citation Recommendation Goal: Determine if a paper should be recommended. ŌĆó We work backward from the goal. ŌĆó We verify conditions step by step. Step Goal/Input Rule Used Output/Conclusion 1 Define Goal: recommend(PaperG) N/A Goal is set 2 Check relevant rules coCited(PaperF, PaperG) ŌåÆ recommend(PaperG) Identify condition 3 Verify condition Need to verify recommend(PaperF) Proceed to next step 4 Check relevant rules cites(PaperE, PaperF) ŌåÆ recommend(PaperF) Identify condition 5 Verify condition Need to verify recommend(PaperE) Proceed to next step 6 Check relevant rules coCited(PaperD, PaperE) ŌåÆ recommend(PaperE) Identify condition 7 Verify condition Need to verify recommend(PaperD) Proceed to next step 8 Check relevant rules coCited(PaperC, PaperD) ŌåÆ recommend(PaperD) Identify condition 9 Verify condition coCited(PaperC, PaperD) holds true recommend(PaperD) is true 10 Conclusion recommend(PaperE) is true recommend(PaperF) is true 11 Conclusion recommend(PaperG) is true ’┐Į Goal achieved Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 8/17
- 10. Abductive Reasoning ─Ä Definition: ŌĆó f Abductive reasoning finds the most plausible explanation for observed facts. ŌĆó ─Š Used when data is incomplete or uncertain. ŌĆó ═ō Applied in research recommendations, medical diagnosis, and AI predictions. Example Context: ŌĆĪ Recommending research papers based on citation relationships. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 10/17
- 11. Data and Relationships Ųü Papers and Topics: ŌĆó Paper A: ŌĆØDeep Learning in NLPŌĆØ ŌĆó Paper B: ŌĆØNeural Network BasicsŌĆØ ŌĆó Paper C: ŌĆØAdvanced NLP ModelsŌĆØ ŌĆó Paper D: ŌĆØAttention MechanismsŌĆØ ŌĆó Paper E: ŌĆØTransformer NetworksŌĆØ ŌĆó Paper F: ŌĆØRenewable Energy SystemsŌĆØ ŌĆó Paper G: ŌĆØSolar Power InnovationsŌĆØ ŌĆó Paper H: ŌĆØWind Energy OptimizationŌĆØ Known Relationships: ŌĆó cites(PaperA, PaperB), cites(PaperA, PaperC) ŌĆó cites(PaperB, PaperD), coCited(PaperC, PaperD) ŌĆó coCited(PaperD, PaperE), cites(PaperE, PaperF) ŌĆó coCited(PaperF, PaperG), cites(PaperG, PaperH) Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 11/17
- 12. Rules for Paper Recommendation { Applied Rules: ŌĆó Rule 1: If a paper cites another, recommend it: ŌĆó cites(PaperA, PaperB) ŌåÆ recommend(PaperB) ŌĆó cites(PaperA, PaperC) ŌåÆ recommend(PaperC) ŌĆó Rule 2: If a paper is co-cited with another, recommend it: ŌĆó coCited(PaperC, PaperD) ŌåÆ recommend(PaperD) ŌĆó coCited(PaperD, PaperE) ŌåÆ recommend(PaperE) ŌĆó Rule 3: If a paper cites another already recommended paper, recommend it: ŌĆó cites(PaperE, PaperF) ŌåÆ recommend(PaperF) ŌĆó coCited(PaperF, PaperG) ŌåÆ recommend(PaperG) Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 12/17
- 13. Abductive Reasoning Process ─Ä Step Observation (Fact) Abductive Hypothesis (Best Explanation) Rule Applied Output (Conclusion) 1 Paper F appears in recommendations Hypothesis: Paper F is relevant ŌĆö Need to verify why Pa- per F is relevant 2 Paper E cites Paper F Paper E is likely relevant Rule 3: Citation Paper E is added as a relevant paper 3 Paper D is co-cited with Paper E Paper D might be rele- vant Rule 2: Co-citation Paper D is added as a relevant paper 4 Paper C is co-cited with Paper D Paper C might be rele- vant Rule 2: Co-citation Paper C is added as a relevant paper 5 Paper A cites Paper C Paper A is likely relevant Rule 1: Citation Paper A is added as a relevant paper 6 Paper A is an NLP- related paper NLP relevance explains Paper FŌĆÖs connection Background Knowl- edge Paper F is justified as relevant Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 13/17
- 15. ─ÄInductive Reasoning: Concept Definition: Inductive reasoning generalizes from specific observations to broader principles or rules. It is useful when patterns or trends are observed in the data, leading to predictions. Key Characteristics: ŌĆó fUsed for pattern recognition and trend analysis. ŌĆó ├ÉHelps in forming hypotheses and theories. ŌĆó ├ŹApplied in AI, machine learning, and scientific research. Example: If multiple papers show a correlation between Transformer Networks and high NLP performance, we can generalize that Transformers are effective for NLP tasks. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 15/17
- 16. ├╗Inductive Reasoning Process Step Observation (Fact) Inductive Pattern Generalization (Conclusion) 1 Paper A (Deep Learning in NLP) uses Transform- ers Transformers improve NLP tasks Hypothesis: Transformers en- hance NLP 2 Paper B (Neural Net- works) compares RNNs vs. Transformers Transformers outperform RNNs in benchmarks Transformers are more effective for NLP 3 Paper C (Advanced NLP Models) applies Trans- formers to language tasks Transformer-based models achieve high accuracy Transformers are state-of-the-art for NLP 4 Paper D (Attention Mechanisms) finds that attention boosts perfor- mance Attention mechanism is key to Transformers Transformer models generalize well Final Con- clusion Transformers are highly effective for NLP and should be the preferred architecture. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 16/17
- 17. ┬¼Benefits of Inductive Reasoning Why Use Inductive Reasoning? ŌĆó ═ōDiscovers hidden patterns in large datasets. ŌĆó ŲźPredicts future trends based on past data. ŌĆó ─ÄForms general theories from real-world observations. ŌĆó ├ÉApplies to AI and machine learning for model training. Example: The discovery of TransformersŌĆÖ success in NLP led to their widespread adoption in AI applications. Dr. DEGHA Houssem Eddine Artificial Intelligence March 17, 2025 17/17