1 of 16
Download to read offline




![Twitter Finagle
Finagle[fin©”igl] - ????
extensible asynchronous (reactive) RPC for the JVM
uniform client and server APIs for several protocols
high performance and concurrency
written in Scala](https://image.slidesharecdn.com/finagle-140927211149-phpapp01/85/Finagle-7-320.jpg)



Ad
Recommended
??, ??, ???????
??, ??, ???????jbugkorea
?
2015 JBUG Korea meetup ????? ??? ?????. ??? ?? ????? ????? ???????? ?? ???????.┼┼Čė┼┼Čė--░ņ▓╣┤┌░ņ▓╣
┼┼Čė┼┼Čė--░ņ▓╣┤┌░ņ▓╣chernbb
?
░Ł▓╣┤┌░ņ▓╣╩Ūę╗Ė÷Ęų▓╝╩ĮĄ─╚šųŠ╠ßĮ╗Ę■╬±Ż¼Ųį┤ė┌│óŠ▒▓į░ņ▒╗Õ▒§▓įŻ¼╩╣ė├│¦│”▓╣▒¶▓╣╩ĄŽųĪŻ╦³ū„╬¬Ž¹ŽóČė┴ąŻ¼Š▀ėąĖ▀Ė║įž║═┐╔║ߎ“└®š╣ąįŻ¼▓╔ė├ĘųŪ°║═ČÓĖ▒▒Š┤µ┤ó╗·ųŲŻ¼ę└┐┐┤▄┤Ū┤Ū░ņ▒▒▒Ķ▒░∙Į°ąą╝»╚║╣▄└ĒĪŻ╔·▓·š▀═©╣²═Ų╦═Ž¹ŽóĄĮĄ■░∙┤Ū░ņ▒░∙Ż¼Ž¹Ęčš▀┤ėĄ■░∙┤Ū░ņ▒░∙└Ł╚ĪŽ¹ŽóŻ¼ų¦│ųČÓųųŽ¹Ęč─Ż╩Į║═╚▌įų╠žąįĪŻAvro
AvroEric Turcotte
?
Avro is a data serialization system that provides dynamic typing, a schema-based design, and efficient encoding. It supports serialization, RPC, and has implementations in many languages with first-class support for Hadoop. The project aims to make data serialization tools more useful and "sexy" for distributed systems.Microservices in the Enterprise
Microservices in the Enterprise Jesus Rodriguez
?
This document provides an overview of microservices in the enterprise. It discusses factors driving the rise of microservices like SOA fatigue and the need for faster innovation. Examples of microservice architectures from companies like Netflix, Twitter and Gilt are presented. Key capabilities for building enterprise-ready microservices are described, including service discovery, description, deployment isolation using containers, data/verb partitioning, lightweight middleware, API gateways and observability. Open source technologies that support implementing these capabilities are also outlined. The document concludes that microservices are the future of distributed systems and enterprises should implement solutions from first principles using inspiration from internet companies.RPC protocols
RPC protocols?? ?
?
RPC protocols like SOAP, XML-RPC, JSON-RPC, and Thrift allow for remote procedure calls between a client and server. RPC works by having a client call an RPC function, which then calls the service and executes the request. The service returns a reply and the program continues. Interface layers can be high-level existing API calls, middle-level custom API calls generated by a compiler, or low-level direct RPC API calls. Popular data formats used include XML, JSON, HTTP, and TCP/IP. Thrift is an open-source protocol developed by Facebook that supports many programming languages. It generates stubs for easy client-server communication. Avro and Protocol Buffers also generate stubs and are supported by languages likeAvro - More Than Just a Serialization Framework - CHUG - 20120416
Avro - More Than Just a Serialization Framework - CHUG - 20120416Chicago Hadoop Users Group
?
The document discusses Apache Avro, a data serialization framework. It provides an overview of Avro's history and capabilities. Key points include that Avro supports schema evolution, multiple languages, and interoperability with other formats like Protobuf and Thrift. The document also covers implementing Avro, including using the generic, specific and reflect data types, and examples of writing and reading data. Performance is addressed, finding that Avro size is competitive while speed is in the top half.Protobuf & Code Generation + Go-Kit
Protobuf & Code Generation + Go-KitManfred Touron
?
The document discusses using protocol buffers (Protobuf) and code generation to reduce boilerplate code when developing microservices with the Go kit framework. It provides an example of defining a service in Protobuf and generating Go code for the service endpoints, transports, and registration functions using a custom code generation tool called protoc-gen-gotemplate. The tool reads Protobuf service definitions and template files to generate standardized, up-to-date Go code that implements the services while avoiding much of the repetitive code normally required.OpenFest 2016 - Open Microservice Architecture
OpenFest 2016 - Open Microservice ArchitectureNikolay Stoitsev
?
This document discusses open microservice architecture with an emphasis on loosely coupled service-oriented architecture and its components, including users, products, and payments. It highlights various technologies and tools for deployment, communication, load balancing, and monitoring such as Docker, Kubernetes, and Kafka. Key metrics to monitor include success rates, error rates, and resource usage, among others.3 avro hug-2010-07-21
3 avro hug-2010-07-21Hadoop User Group
?
Avro is a data serialization system that provides data interchange and interoperability between systems. It allows for efficient encoding of data and schema evolution. Avro defines data using JSON schemas and provides dynamic typing which allows data to be read without code generation. It includes a file format and supports MapReduce workflows. Avro aims to become the standard data format for Hadoop applications by providing rich data types, interoperability between languages, and compatibility between versions.G rpc lection1
G rpc lection1eleksdev
?
This document provides instructions for creating a gRPC Hello World sample in C# using .NET Core. It describes creating client and server projects with protobuf definition files. The server project implements a Greeter service that returns a greeting message. The client project calls the SayHello method to get a response from the server. Running the projects demonstrates a basic gRPC communication.RPC: Remote procedure call
RPC: Remote procedure callSunita Sahu
?
RPC allows a program to call a subroutine that resides on a remote machine. When a call is made, the calling process is suspended and execution takes place on the remote machine. The results are then returned. This makes the remote call appear local to the programmer. RPC uses message passing to transmit information between machines and allows communication between processes on different machines or the same machine. It provides a simple interface like local procedure calls but involves more overhead due to network communication.HTTP2 and gRPC
HTTP2 and gRPCGuo Jing
?
gRPC is a modern open source RPC framework that enables client and server applications to communicate transparently. It is based on HTTP/2 for its transport mechanism and Protocol Buffers as its interface definition language. Some benefits of gRPC include being fast due to its use of HTTP/2, supporting multiple programming languages, and enabling server push capabilities. However, it also has some downsides such as potential issues with load balancing of persistent connections and requiring external services for service discovery.??? ???? (Apache Thrift)
??? ???? (Apache Thrift) Jin wook
?
Scalable Cross-Language Services? ?? ??? ???? (Apache Thrift) ? ?? ??? ????Building High Performance APIs In Go Using gRPC And Protocol Buffers
Building High Performance APIs In Go Using gRPC And Protocol BuffersShiju Varghese
?
The document discusses building high performance APIs in Go using gRPC and Protocol Buffers. It describes how gRPC is a high performance, open-source RPC framework that uses Protocol Buffers for serialization. It provides an overview of building APIs with gRPC by defining services and messages with Protobuf, generating code, implementing servers and clients. The workflow allows building APIs that are efficient, strongly typed and work across languages.Druid @ branch
Druid @ branch Biswajit Das
?
The document summarizes Druid, an open source data analytics platform, and how it has enhanced the data platform for a company to enable better business decisions. Key features of Druid include sub-second aggregate queries, real-time analytics dashboards, and live queries for unique users. Druid has helped scale to several hundred terabytes of data with thousands of queries per second while supporting new analytics applications, ad hoc reporting, and exploratory analysis. Future plans include improving the query service and migrating components to technologies like Spark, Flink, Mesos and Docker.Introduction to Remote Procedure Call
Introduction to Remote Procedure CallAbdelrahman Al-Ogail
?
This document provides an introduction and overview of Remote Procedure Call (RPC). It discusses what RPC is, why it is used, how RPC operates, how it is implemented in Windows, provides a practical example of implementing RPC, and discusses how RPC is used in QFS. Key points include that RPC allows a process to call a procedure in a different address space, possibly on a different machine, and hides the remote interaction. It operates by marshaling parameters for transmission over the network and making function calls to send the request and receive the response.3 apache-avro
3 apache-avrozafargilani
?
Apache Avro is a data serialization system and RPC framework that provides rich data structures and compact, fast binary data formats. It uses JSON for schemas and relies on schemas stored with data to allow serialization without per-value overhead. Avro supports Java, C, C++, C#, Python and Ruby and is commonly used in Hadoop for data persistence and communication between nodes. It compares similarly to Protobuf and Thrift but with some differences in implementation, error handling and extensibility.Hawkular overview
Hawkular overviewjbugkorea
?
Hawkular is an open source monitoring project that is the successor to JBoss ON (RHQ). It provides REST services for collecting and storing metrics and triggering alerts. Some key features include storing metrics in a Time Series database based on Cassandra, providing alerting on metrics, and integrating with projects like ManageIQ and Kubernetes. Hawkular has several sub-projects including Hawkular Services for base functionality, Hawkular Metrics for metrics storage, and Hawkular APM which is now deprecated in favor of adopting CNCF's Jaeger for distributed tracing.???? ????? ???? ???
???? ????? ???? ???jbugkorea
?
This document discusses the role of a middleware engineer and their experience transitioning to cloud development. It summarizes the engineer's background as a J2EE developer who was initially confused by cloud concepts like IaaS, PaaS, and SaaS. It then covers their journey learning Linux skills while working at a open source company, discovering tools like Docker and Kubernetes for automating middleware provisioning, and recognizing the value of Platform as a Service for simplifying development environments.More Related Content
Viewers also liked (20)
Microservices in the Enterprise
Microservices in the Enterprise Jesus Rodriguez
?
This document provides an overview of microservices in the enterprise. It discusses factors driving the rise of microservices like SOA fatigue and the need for faster innovation. Examples of microservice architectures from companies like Netflix, Twitter and Gilt are presented. Key capabilities for building enterprise-ready microservices are described, including service discovery, description, deployment isolation using containers, data/verb partitioning, lightweight middleware, API gateways and observability. Open source technologies that support implementing these capabilities are also outlined. The document concludes that microservices are the future of distributed systems and enterprises should implement solutions from first principles using inspiration from internet companies.RPC protocols
RPC protocols?? ?
?
RPC protocols like SOAP, XML-RPC, JSON-RPC, and Thrift allow for remote procedure calls between a client and server. RPC works by having a client call an RPC function, which then calls the service and executes the request. The service returns a reply and the program continues. Interface layers can be high-level existing API calls, middle-level custom API calls generated by a compiler, or low-level direct RPC API calls. Popular data formats used include XML, JSON, HTTP, and TCP/IP. Thrift is an open-source protocol developed by Facebook that supports many programming languages. It generates stubs for easy client-server communication. Avro and Protocol Buffers also generate stubs and are supported by languages likeAvro - More Than Just a Serialization Framework - CHUG - 20120416
Avro - More Than Just a Serialization Framework - CHUG - 20120416Chicago Hadoop Users Group
?
The document discusses Apache Avro, a data serialization framework. It provides an overview of Avro's history and capabilities. Key points include that Avro supports schema evolution, multiple languages, and interoperability with other formats like Protobuf and Thrift. The document also covers implementing Avro, including using the generic, specific and reflect data types, and examples of writing and reading data. Performance is addressed, finding that Avro size is competitive while speed is in the top half.Protobuf & Code Generation + Go-Kit
Protobuf & Code Generation + Go-KitManfred Touron
?
The document discusses using protocol buffers (Protobuf) and code generation to reduce boilerplate code when developing microservices with the Go kit framework. It provides an example of defining a service in Protobuf and generating Go code for the service endpoints, transports, and registration functions using a custom code generation tool called protoc-gen-gotemplate. The tool reads Protobuf service definitions and template files to generate standardized, up-to-date Go code that implements the services while avoiding much of the repetitive code normally required.OpenFest 2016 - Open Microservice Architecture
OpenFest 2016 - Open Microservice ArchitectureNikolay Stoitsev
?
This document discusses open microservice architecture with an emphasis on loosely coupled service-oriented architecture and its components, including users, products, and payments. It highlights various technologies and tools for deployment, communication, load balancing, and monitoring such as Docker, Kubernetes, and Kafka. Key metrics to monitor include success rates, error rates, and resource usage, among others.3 avro hug-2010-07-21
3 avro hug-2010-07-21Hadoop User Group
?
Avro is a data serialization system that provides data interchange and interoperability between systems. It allows for efficient encoding of data and schema evolution. Avro defines data using JSON schemas and provides dynamic typing which allows data to be read without code generation. It includes a file format and supports MapReduce workflows. Avro aims to become the standard data format for Hadoop applications by providing rich data types, interoperability between languages, and compatibility between versions.G rpc lection1
G rpc lection1eleksdev
?
This document provides instructions for creating a gRPC Hello World sample in C# using .NET Core. It describes creating client and server projects with protobuf definition files. The server project implements a Greeter service that returns a greeting message. The client project calls the SayHello method to get a response from the server. Running the projects demonstrates a basic gRPC communication.RPC: Remote procedure call
RPC: Remote procedure callSunita Sahu
?
RPC allows a program to call a subroutine that resides on a remote machine. When a call is made, the calling process is suspended and execution takes place on the remote machine. The results are then returned. This makes the remote call appear local to the programmer. RPC uses message passing to transmit information between machines and allows communication between processes on different machines or the same machine. It provides a simple interface like local procedure calls but involves more overhead due to network communication.HTTP2 and gRPC
HTTP2 and gRPCGuo Jing
?
gRPC is a modern open source RPC framework that enables client and server applications to communicate transparently. It is based on HTTP/2 for its transport mechanism and Protocol Buffers as its interface definition language. Some benefits of gRPC include being fast due to its use of HTTP/2, supporting multiple programming languages, and enabling server push capabilities. However, it also has some downsides such as potential issues with load balancing of persistent connections and requiring external services for service discovery.??? ???? (Apache Thrift)
??? ???? (Apache Thrift) Jin wook
?
Scalable Cross-Language Services? ?? ??? ???? (Apache Thrift) ? ?? ??? ????Building High Performance APIs In Go Using gRPC And Protocol Buffers
Building High Performance APIs In Go Using gRPC And Protocol BuffersShiju Varghese
?
The document discusses building high performance APIs in Go using gRPC and Protocol Buffers. It describes how gRPC is a high performance, open-source RPC framework that uses Protocol Buffers for serialization. It provides an overview of building APIs with gRPC by defining services and messages with Protobuf, generating code, implementing servers and clients. The workflow allows building APIs that are efficient, strongly typed and work across languages.Druid @ branch
Druid @ branch Biswajit Das
?
The document summarizes Druid, an open source data analytics platform, and how it has enhanced the data platform for a company to enable better business decisions. Key features of Druid include sub-second aggregate queries, real-time analytics dashboards, and live queries for unique users. Druid has helped scale to several hundred terabytes of data with thousands of queries per second while supporting new analytics applications, ad hoc reporting, and exploratory analysis. Future plans include improving the query service and migrating components to technologies like Spark, Flink, Mesos and Docker.Introduction to Remote Procedure Call
Introduction to Remote Procedure CallAbdelrahman Al-Ogail
?
This document provides an introduction and overview of Remote Procedure Call (RPC). It discusses what RPC is, why it is used, how RPC operates, how it is implemented in Windows, provides a practical example of implementing RPC, and discusses how RPC is used in QFS. Key points include that RPC allows a process to call a procedure in a different address space, possibly on a different machine, and hides the remote interaction. It operates by marshaling parameters for transmission over the network and making function calls to send the request and receive the response.3 apache-avro
3 apache-avrozafargilani
?
Apache Avro is a data serialization system and RPC framework that provides rich data structures and compact, fast binary data formats. It uses JSON for schemas and relies on schemas stored with data to allow serialization without per-value overhead. Avro supports Java, C, C++, C#, Python and Ruby and is commonly used in Hadoop for data persistence and communication between nodes. It compares similarly to Protobuf and Thrift but with some differences in implementation, error handling and extensibility.More from jbugkorea (17)
Hawkular overview
Hawkular overviewjbugkorea
?
Hawkular is an open source monitoring project that is the successor to JBoss ON (RHQ). It provides REST services for collecting and storing metrics and triggering alerts. Some key features include storing metrics in a Time Series database based on Cassandra, providing alerting on metrics, and integrating with projects like ManageIQ and Kubernetes. Hawkular has several sub-projects including Hawkular Services for base functionality, Hawkular Metrics for metrics storage, and Hawkular APM which is now deprecated in favor of adopting CNCF's Jaeger for distributed tracing.???? ????? ???? ???
???? ????? ???? ???jbugkorea
?
This document discusses the role of a middleware engineer and their experience transitioning to cloud development. It summarizes the engineer's background as a J2EE developer who was initially confused by cloud concepts like IaaS, PaaS, and SaaS. It then covers their journey learning Linux skills while working at a open source company, discovering tools like Docker and Kubernetes for automating middleware provisioning, and recognizing the value of Platform as a Service for simplifying development environments.???? ???? ???? - RHQ? ??? Legacy System ????
???? ???? ???? - RHQ? ??? Legacy System ????jbugkorea
?
2015 JBUG Korea meetup ????? ??? ?????. ??? ?? ????? RHQ ??? ?? ???????.Micro Service Architecture ???
Micro Service Architecture ???jbugkorea
?
The document discusses reasons for adopting a microservices architecture (MSA). It notes that MSA can help simplify software structure, enable faster development and deployment to meet time-to-market goals. The document also lists nine key characteristics of MSA, including decomposing applications into independently deployable services, organizing around business capabilities rather than projects, decentralized governance and data management, and designing for failure.INFINISPAN non-clustering Spring4 WEB/MOBILE APP ??
INFINISPAN non-clustering Spring4 WEB/MOBILE APP ??jbugkorea
?
2015 JBUG KOREA MEETUP
?? ? ??? ???? ??? ??? Infinispan? ???? Clustering ?? ???? ??? ??? Spring4 ??? ?/??? ?? ??????? ???? ???? Arquillian? ??? Real Object ???
??? ???? ???? Arquillian? ??? Real Object ???jbugkorea
?
The document discusses Arquillian, a testing framework that allows integration tests to be written and run similarly to unit tests. It can package components into deployable archives, launch tests inside a container, and support running tests from an IDE. Benefits include being able to run integration tests incrementally like unit tests without needing to rebuild between test runs.Undertow ???????
Undertow ???????jbugkorea
?
This document provides an overview of Undertow, an embeddable web server for Java applications. It discusses Undertow's lightweight and high performance architecture based on small reusable handlers. Key features mentioned include support for Servlet 3.1, web sockets, and acting as a reverse proxy. The document also briefly outlines Undertow's handler-based approach and some built-in handlers like path matching, virtual hosts, and error handling.JBoss Community Introduction
JBoss Community Introductionjbugkorea
?
The document introduces the JBoss Community, which was started in 1999 by Marc Fluery with a focus on middleware. It grew popular as the EJB container when Java grew and now has over 100 open source projects focused on Java standards and middleware development. Red Hat acquired JBoss Community in 2006 and supports enterprise middleware subscriptions. The community's principles are standards-driven innovation and rapid technology adoption seen in technologies like parallel loading in JBoss 7. Major projects include Hibernate and Drools.JBoss AS 7 ????
JBoss AS 7 ????jbugkorea
?
The document discusses JBoss Application Server 7 and compares it to other application servers like WildFly and Tomcat. It introduces WildFly as the new name for JBoss Application Server to reduce confusion. It then provides an overview of new features in JBoss AS 7 like support for Spring 3.x, MyBatis 3.x, and domain mode configuration.Infinispan Data Grid Platform
Infinispan Data Grid Platformjbugkorea
?
The document introduces the Infinispan data grid platform. It discusses how Infinispan can be used as a distributed in-memory cache both as a library and server. Key features of Infinispan are clustering, persistence, transactions, querying, and map-reduce capabilities. Examples of using Infinispan for session clustering and as a state store for Storm processing are provided.Java 8 - A step closer to Parallelism
Java 8 - A step closer to Parallelismjbugkorea
?
Java 8 introduces several new features that help modernize the Java platform and move it closer to parallelism. These include lambda expressions, which allow treating code as data, and default methods in interfaces, which allow interfaces to evolve while maintaining compatibility. Streams and bulk operations on collections enable a more functional, parallel style of programming. The invokedynamic bytecode instruction is enhanced to allow lambda expressions to be compiled to anonymous methods and executed efficiently by the JVM.JBoss Community's Application Monitoring Platform
JBoss Community's Application Monitoring Platformjbugkorea
?
This document introduces two open source projects, RHQ and Byteman, that can help software engineers broaden the scope of their development activities. RHQ is a platform for monitoring JBoss applications, while Byteman allows testing and debugging of applications. The presentation aims to share stories about these tools in order to help developers expand their work.Ad
?????? ???? Finagle?????
- 1. ?? ?? Finagle??? Jeff Lee
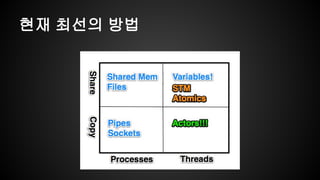
- 2. ???? ?? ?? ???? CPU ?? ??? ?? ???? ScaleUp? ?? ???? ??? ???
- 3. ?? ??? ??
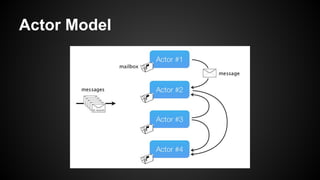
- 4. Actor Model ?? ??? ??? ??? ???? ?? ? ??. ??? ??? ??? ??? ? ? ??. ?? ??? ?? ???? ??? ??(behavior)? ?? ? ? ??. ?? ??? ????? ????? ?? ?? ??? ??? ? ?. - ? ???(1973)
- 5. Actor Model ??? ??(??)? ???? ???? ???. - ??? ??? ?? ??? ?????? ????. - ??? ??, ??, ?????? ?? Message passing No shared memory
- 6. Actor Model
- 7. Twitter Finagle Finagle[fin©”igl] - ???? extensible asynchronous (reactive) RPC for the JVM uniform client and server APIs for several protocols high performance and concurrency written in Scala
- 8. Multiple protocols HTTP Memcached Redis Protobuf Thrift MySQL mDNS...
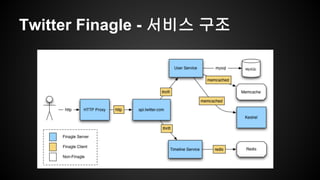
- 9. Twitter Finagle - ??? ??
- 10. Apache Thrift framework, for scalable cross-language services development code generation engine C++, Java, Python, PHP, Ruby, Erlang,Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml,Delphi ĪŁ Developed by Facebook, opensourced in April 2007
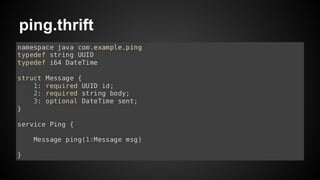
- 11. ping.thrift
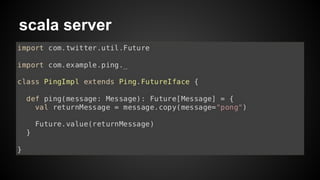
- 12. scala server
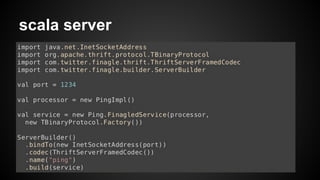
- 13. scala server
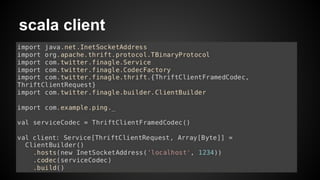
- 14. scala client
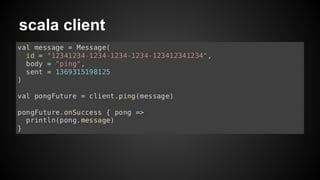
- 15. scala client
- 16. ????. Finagle GitHub https://github.com/twitter/finagle Finagle Guide http://twitter.github.io/finagle/guide/index.html Scala School - ????(Finagle) ?? https://twitter.github.io/scala_school/ko/finagle.html SOA with Thrift and Finagle http://www.slideshare.net/bancek/soa-with-thrift-and-finagle