The Sidekick Pattern: Strata talk by Abe Gong
5 likes1,626 views

The document discusses the 'sidekick pattern' in data science, emphasizing how small, curated datasets can enhance the value of large datasets. It provides examples such as hieroglyph translation and sleep context, detailing when and how to apply the sidekick pattern. Key points include separating data cleaning from scaling and bootstrapping new data products to leverage variety against volume.
1 of 46
Download to read offline














![[DATA ART EXAMPLE]
SUB-TITLE
Wednesday, February 12, 14](https://image.slidesharecdn.com/gong-strata-sidekick-pattern-140214151219-phpapp01/85/The-Sidekick-Pattern-Strata-talk-by-Abe-Gong-18-320.jpg)


















Ad
Recommended
The Edison Moment for the Internet of You
The Edison Moment for the Internet of YouAbe Gong
╠²
Abe Gong introduces himself as formerly working for Jawbone in internet of things and having recently left to start his own company. He is excited to discuss the Edison Moment for internet of things.Building for resilience
Building for resilienceAbe Gong
╠²
The document suggests going home and breaking something to relieve stress. It also recommends learning from mistakes by iterating designs in smartware. All units are said to learn from every mistake made.Building for resilience (with speaking notes)
Building for resilience (with speaking notes)Abe Gong
╠²
Abe Gong from Jawbone gave a talk about building resilient systems. He defined resilience as combining flexibility and toughness. To build resilient products, companies need to extensively test products to destruction beyond standard tests, and get "creative about destruction". They also need diverse and redundant systems to avoid single points of failure, as well as the ability to quickly learn from mistakes and iterate on both hardware and software. Companies should hire people comfortable with failure and breaking things, and ensure that when problems do occur, all parts of the organization can work together to solve the issue.How to ride, eat, tame, etc. your personal elephant
How to ride, eat, tame, etc. your personal elephantAbe Gong
╠²
This document is a talk given by Abe Gong at a local congregation event about effectively managing time and productivity. The talk uses the analogy of the mind as an elephant rider to explain how to align conscious and subconscious minds. Key recommendations include making detailed plans, breaking large tasks into smaller pieces, limiting the number of active projects, frequently measuring progress, setting deadlines but being willing to adjust them, eliminating distractions, and finding ways to keep tasks enjoyable such as through creativity or gamification. The overall message is that willpower is best used by understanding one's mental processes and setting up systems and habits to work with one's natural tendencies.Picking programming packages
Picking programming packagesAbe Gong
╠²
The document discusses considerations for choosing programming packages and tools. It notes that the decision matters and is one that programmers face regularly. It analogizes the decision to choosing clothes, considering factors like whether the software works with other tools, is popular with active support communities, is well-documented and easy to use, and fits the intended purpose. The document lists tools the author uses including Python, R, Hadoop, and web development packages, and notes other tools they would consider or avoid using.Gong info heist
Gong info heistAbe Gong
╠²
The document discusses planning a heist by analyzing information flow between individuals. It outlines four phases of a heist: the mark, the team, the plan, and the takedown. For analyzing information flow, it discusses challenges like hidden networks and subtle signals. It proposes using graphical causal models, mutual information theory, and large datasets to study when information flow can be inferred, the direction of flow, and the quantity of flow. The goal is to develop a framework for testable theories of information spread.An Automated Snowball Census of the Political Web - JITP 2011
An Automated Snowball Census of the Political Web - JITP 2011Abe Gong
╠²
The document discusses an automated snowball census of political bloggers, highlighting the need for a representative sample to understand political participation better. It outlines the methodology for collecting data from political blogs and presents findings from a census that included over 1.8 million sites, with a significant portion identified as political. The conclusions stress the importance of combining various research tools, careful sampling, and the value of complementary data in political science research.2024 Trend Updates: What Really Works In SEO & Content Marketing
2024 Trend Updates: What Really Works In SEO & Content MarketingSearch Engine Journal
╠²
The document outlines key SEO and content marketing trends for 2024, emphasizing the impact of AI, the importance of E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), and a shift towards user-centric content strategies. It advises against focusing on outdated trends like voice search and stresses the need for creating value-driven, authoritative content. Additionally, it highlights the need to leverage AI as a supportive tool rather than relying solely on it for content creation.CapCut Pro Crack For PC Latest Version {Fully Unlocked} 2025
CapCut Pro Crack For PC Latest Version {Fully Unlocked} 2025pcprocore
╠²
¤æēØŚĪØŚ╝ØśüØŚ▓:ØŚ¢ØŚ╝ØŚĮØśå ØŚ╣ØŚČØŚ╗ØŚĖ & ØŚĮØŚ«ØśĆØśüØŚ▓ ØŚČØŚ╗ØśüØŚ╝ ØŚÜØŚ╝ØŚ╝ØŚ┤ØŚ╣ØŚ▓ ØŚ╗ØŚ▓Øśä ØśüØŚ«ØŚ»> https://pcprocore.com/ ¤æłŌŚĆ
CapCut Pro Crack is a powerful tool that has taken the digital world by storm, offering users a fully unlocked experience that unleashes their creativity. With its user-friendly interface and advanced features, itŌĆÖs no wonder why aspiring videographers are turning to this software for their projects.You are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante
╠²
We live in an ever evolving landscape for cyber threats creating security risk for your production systems. Mitigating these risks requires participation throughout all stages from development through production delivery - and by every role including architects, developers QA and DevOps engineers, product owners and leadership. No one is excused! This session will cover examples of common mistakes or missed opportunities that can lead to vulnerabilities in production - and ways to do better throughout the development lifecycle.Enhance GitHub Copilot using MCP - Enterprise version.pdf
Enhance GitHub Copilot using MCP - Enterprise version.pdfNilesh Gule
╠²
║▌║▌▀Ż deck related to the GitHub Copilot Bootcamp in Melbourne on 17 June 2025OpenACC and Open Hackathons Monthly Highlights June 2025
OpenACC and Open Hackathons Monthly Highlights June 2025OpenACC
╠²
The OpenACC organization focuses on enhancing parallel computing skills and advancing interoperability in scientific applications through hackathons and training. The upcoming 2025 Open Accelerated Computing Summit (OACS) aims to explore the convergence of AI and HPC in scientific computing and foster knowledge sharing. This year's OACS welcomes talk submissions from a variety of topics, from Using Standard Language Parallelism to Computer Vision Applications. The document also highlights several open hackathons, a call to apply for NVIDIA Academic Grant Program and resources for optimizing scientific applications using OpenACC directives.UserCon Belgium: Honey, VMware increased my bill
UserCon Belgium: Honey, VMware increased my billstijn40
╠²
VMwareŌĆÖs pricing changes have forced organizations to rethink their datacenter cost management strategies. While FinOps is commonly associated with cloud environments, the FinOps Foundation has recently expanded its framework to include ScopesŌĆöand Datacenter is now officially part of the equation. In this session, weŌĆÖll map the FinOps Framework to a VMware-based datacenter, focusing on cost visibility, optimization, and automation. YouŌĆÖll learn how to track costs more effectively, rightsize workloads, optimize licensing, and drive efficiencyŌĆöall without migrating to the cloud. WeŌĆÖll also explore how to align IT teams, finance, and leadership around cost-aware decision-making for on-prem environments. If your VMware bill keeps increasing and you need a new approach to cost management, this session is for you!ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOpt...
ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOpt...Edge AI and Vision Alliance
╠²
For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/key-requirements-to-successfully-implement-generative-ai-in-edge-devices-optimized-mapping-to-the-enhanced-npx6-neural-processing-unit-ip-a-presentation-from-synopsys/
Gordon Cooper, Principal Product Manager at Synopsys, presents the ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOptimized Mapping to the Enhanced NPX6 Neural Processing Unit IPŌĆØ tutorial at the May 2025 Embedded Vision Summit.
In this talk, Cooper discusses emerging trends in generative AI for edge devices and the key role of transformer-based neural networks. He reviews the distinct attributes of transformers, their advantages over conventional convolutional neural networks and how they enable generative AI.
Cooper then covers key requirements that must be met for neural processing units (NPU) to support transformers and generative AI in edge device applications. He uses transformer-based generative AI examples to illustrate the efficient mapping of these workloads onto the enhanced Synopsys ARC NPX NPU IP family.FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce.pptx
FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce.pptxFIDO Alliance
╠²
FIDO Seminar: Targeting Trust: The Future of Identity in the WorkforceFIDO Seminar: New Data: Passkey Adoption in the Workforce.pptx
FIDO Seminar: New Data: Passkey Adoption in the Workforce.pptxFIDO Alliance
╠²
FIDO Seminar: New Data: Passkey Adoption in the WorkforceTech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdf
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdfcaoyixuan2019
╠²
A presentation at Internetware 2025.10 Key Challenges for AI within the EU Data Protection Framework.pdf
10 Key Challenges for AI within the EU Data Protection Framework.pdfPriyanka Aash
╠²
10 Key Challenges for AI within the EU Data Protection FrameworkImproving Data Integrity: Synchronization between EAM and ArcGIS Utility Netw...
Improving Data Integrity: Synchronization between EAM and ArcGIS Utility Netw...Safe Software
╠²
Utilities and water companies play a key role in the creation of clean drinking water. The creation and maintenance of clean drinking water is becoming a critical problem due to pollution and pressure on the environment. A lot of data is necessary to create clean drinking water. For fieldworkers, two types of data are key: Asset data in an asset management system (EAM for example) and Geographic data in a GIS (ArcGIS Utility Network ). Keeping this type of data up to date and in sync is a challenge for many organizations, leading to duplicating data and creating a bulk of extra attributes and data to keep everything in sync. Using FME, it is possible to synchronize Enterprise Asset Management (EAM) data with the ArcGIS Utility Network in real time. Changes (creation, modification, deletion) in ArcGIS Pro are relayed to EAM via FME, and vice versa. This ensures continuous synchronization of both systems without daily bulk updates, minimizes risks, and seamlessly integrates with ArcGIS Utility Network services. This presentation focuses on the use of FME at a Dutch water company, to create a sync between the asset management and GIS.From Manual to Auto Searching- FME in the Driver's Seat
From Manual to Auto Searching- FME in the Driver's SeatSafe Software
╠²
Finding a specific car online can be a time-consuming task, especially when checking multiple dealer websites. A few years ago, I faced this exact problem while searching for a particular vehicle in New Zealand. The local classified platform, Trade Me (similar to eBay), wasnŌĆÖt yielding any results, so I expanded my search to second-hand dealer sitesŌĆöonly to realise that periodically checking each one was going to be tedious. ThatŌĆÖs when I noticed something interesting: many of these websites used the same platform to manage their inventories. Recognising this, I reverse-engineered the platformŌĆÖs structure and built an FME workspace that automated the search process for me. By integrating API calls and setting up periodic checks, I received real-time email alerts when matching cars were listed. In this presentation, IŌĆÖll walk through how I used FME to save hours of manual searching by creating a custom car-finding automation system. While FME canŌĆÖt buy a car for youŌĆöyetŌĆöit can certainly help you find the one youŌĆÖre after!Security Tips for Enterprise Azure Solutions
Security Tips for Enterprise Azure SolutionsMichele Leroux Bustamante
╠²
Delivering solutions to Azure may involve a variety of architecture patterns involving your applications, APIs data and associated Azure resources that comprise the solution. This session will use reference architectures to illustrate the security considerations to protect your Azure resources and data, how to achieve Zero Trust, and why it matters. Topics covered will include specific security recommendations for types Azure resources and related network security practices. The goal is to give you a breadth of understanding as to typical security requirements to meet compliance and security controls in an enterprise solution.Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdf
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdfICT Frame Magazine Pvt. Ltd.
╠²
Artificial Intelligence (AI) is rapidly changing the face of cybersecurity across the globe. In Nepal, the shift is already underway. Vice President of the Information Security Response Team Nepal (npCERT) and Information Security Consultant at One Cover Pvt. Ltd., Sudan Jha, recently presented an in-depth workshop on how AI can strengthen national security and digital defenses.Raman Bhaumik - Passionate Tech Enthusiast
Raman Bhaumik - Passionate Tech EnthusiastRaman Bhaumik
╠²
A Junior Software Developer with a flair for innovation, Raman Bhaumik excels in delivering scalable web solutions. With three years of experience and a solid foundation in Java, Python, JavaScript, and SQL, she has streamlined task tracking by 20% and improved application stability.OWASP Barcelona 2025 Threat Model Library
OWASP Barcelona 2025 Threat Model LibraryPetraVukmirovic
╠²
Threat Model Library Launch at OWASP Barcelona 2025
https://owasp.org/www-project-threat-model-library/MuleSoft for AgentForce : Topic Center and API Catalog
MuleSoft for AgentForce : Topic Center and API Catalogshyamraj55
╠²
This presentation dives into how MuleSoft empowers AgentForce with organized API discovery and streamlined integration using Topic Center and the API Catalog. Learn how these tools help structure APIs around business needs, improve reusability, and simplify collaboration across teams. Ideal for developers, architects, and business stakeholders looking to build a connected and scalable API ecosystem within AgentForce.PyCon SG 25 - Firecracker Made Easy with Python.pdf
PyCon SG 25 - Firecracker Made Easy with Python.pdfMuhammad Yuga Nugraha
╠²
Explore the ease of managing Firecracker microVM with the firecracker-python. In this session, I will introduce the basics of Firecracker microVM and demonstrate how this custom SDK facilitates microVM operations easily. We will delve into the design and development process behind the SDK, providing a behind-the-scenes look at its creation and features. While traditional Firecracker SDKs were primarily available in Go, this module brings a simplicity of Python to the table.Techniques for Automatic Device Identification and Network Assignment.pdf
Techniques for Automatic Device Identification and Network Assignment.pdfPriyanka Aash
╠²
Techniques for Automatic Device Identification and Network AssignmentFIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptx
FIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptxFIDO Alliance
╠²
FIDO Seminar: Perspectives on Passkeys & Consumer AdoptionStorytelling For The Web: Integrate Storytelling in your Design Process
Storytelling For The Web: Integrate Storytelling in your Design ProcessChiara Aliotta
╠²
The document outlines a livestream presentation by Chiara Aliotta on integrating storytelling into web design to enhance user experiences. It covers the storytelling process for designers, emphasizing aspects such as understanding the audience, structuring narratives, and creating emotional connections. The presentation also includes case studies and practical examples to demonstrate effective storytelling in UX/UI design.Artificial Intelligence, Data and Competition ŌĆō SCHREPEL ŌĆō June 2024 OECD dis...
Artificial Intelligence, Data and Competition ŌĆō SCHREPEL ŌĆō June 2024 OECD dis...OECD Directorate for Financial and Enterprise Affairs
╠²
This presentation by Thibault Schrepel, Associate Professor of Law at Vrije Universiteit Amsterdam University, was made during the discussion ŌĆ£Artificial Intelligence, Data and CompetitionŌĆØ held at the 143rd meeting of the OECD Competition Committee on 12 June 2024. More papers and presentations on the topic can be found at oe.cd/aicomp.
This presentation was uploaded with the authorŌĆÖs consent.
More Related Content
Recently uploaded (20)
CapCut Pro Crack For PC Latest Version {Fully Unlocked} 2025
CapCut Pro Crack For PC Latest Version {Fully Unlocked} 2025pcprocore
╠²
¤æēØŚĪØŚ╝ØśüØŚ▓:ØŚ¢ØŚ╝ØŚĮØśå ØŚ╣ØŚČØŚ╗ØŚĖ & ØŚĮØŚ«ØśĆØśüØŚ▓ ØŚČØŚ╗ØśüØŚ╝ ØŚÜØŚ╝ØŚ╝ØŚ┤ØŚ╣ØŚ▓ ØŚ╗ØŚ▓Øśä ØśüØŚ«ØŚ»> https://pcprocore.com/ ¤æłŌŚĆ
CapCut Pro Crack is a powerful tool that has taken the digital world by storm, offering users a fully unlocked experience that unleashes their creativity. With its user-friendly interface and advanced features, itŌĆÖs no wonder why aspiring videographers are turning to this software for their projects.You are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante
╠²
We live in an ever evolving landscape for cyber threats creating security risk for your production systems. Mitigating these risks requires participation throughout all stages from development through production delivery - and by every role including architects, developers QA and DevOps engineers, product owners and leadership. No one is excused! This session will cover examples of common mistakes or missed opportunities that can lead to vulnerabilities in production - and ways to do better throughout the development lifecycle.Enhance GitHub Copilot using MCP - Enterprise version.pdf
Enhance GitHub Copilot using MCP - Enterprise version.pdfNilesh Gule
╠²
║▌║▌▀Ż deck related to the GitHub Copilot Bootcamp in Melbourne on 17 June 2025OpenACC and Open Hackathons Monthly Highlights June 2025
OpenACC and Open Hackathons Monthly Highlights June 2025OpenACC
╠²
The OpenACC organization focuses on enhancing parallel computing skills and advancing interoperability in scientific applications through hackathons and training. The upcoming 2025 Open Accelerated Computing Summit (OACS) aims to explore the convergence of AI and HPC in scientific computing and foster knowledge sharing. This year's OACS welcomes talk submissions from a variety of topics, from Using Standard Language Parallelism to Computer Vision Applications. The document also highlights several open hackathons, a call to apply for NVIDIA Academic Grant Program and resources for optimizing scientific applications using OpenACC directives.UserCon Belgium: Honey, VMware increased my bill
UserCon Belgium: Honey, VMware increased my billstijn40
╠²
VMwareŌĆÖs pricing changes have forced organizations to rethink their datacenter cost management strategies. While FinOps is commonly associated with cloud environments, the FinOps Foundation has recently expanded its framework to include ScopesŌĆöand Datacenter is now officially part of the equation. In this session, weŌĆÖll map the FinOps Framework to a VMware-based datacenter, focusing on cost visibility, optimization, and automation. YouŌĆÖll learn how to track costs more effectively, rightsize workloads, optimize licensing, and drive efficiencyŌĆöall without migrating to the cloud. WeŌĆÖll also explore how to align IT teams, finance, and leadership around cost-aware decision-making for on-prem environments. If your VMware bill keeps increasing and you need a new approach to cost management, this session is for you!ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOpt...
ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOpt...Edge AI and Vision Alliance
╠²
For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/key-requirements-to-successfully-implement-generative-ai-in-edge-devices-optimized-mapping-to-the-enhanced-npx6-neural-processing-unit-ip-a-presentation-from-synopsys/
Gordon Cooper, Principal Product Manager at Synopsys, presents the ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOptimized Mapping to the Enhanced NPX6 Neural Processing Unit IPŌĆØ tutorial at the May 2025 Embedded Vision Summit.
In this talk, Cooper discusses emerging trends in generative AI for edge devices and the key role of transformer-based neural networks. He reviews the distinct attributes of transformers, their advantages over conventional convolutional neural networks and how they enable generative AI.
Cooper then covers key requirements that must be met for neural processing units (NPU) to support transformers and generative AI in edge device applications. He uses transformer-based generative AI examples to illustrate the efficient mapping of these workloads onto the enhanced Synopsys ARC NPX NPU IP family.FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce.pptx
FIDO Seminar: Targeting Trust: The Future of Identity in the Workforce.pptxFIDO Alliance
╠²
FIDO Seminar: Targeting Trust: The Future of Identity in the WorkforceFIDO Seminar: New Data: Passkey Adoption in the Workforce.pptx
FIDO Seminar: New Data: Passkey Adoption in the Workforce.pptxFIDO Alliance
╠²
FIDO Seminar: New Data: Passkey Adoption in the WorkforceTech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdf
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdfcaoyixuan2019
╠²
A presentation at Internetware 2025.10 Key Challenges for AI within the EU Data Protection Framework.pdf
10 Key Challenges for AI within the EU Data Protection Framework.pdfPriyanka Aash
╠²
10 Key Challenges for AI within the EU Data Protection FrameworkImproving Data Integrity: Synchronization between EAM and ArcGIS Utility Netw...
Improving Data Integrity: Synchronization between EAM and ArcGIS Utility Netw...Safe Software
╠²
Utilities and water companies play a key role in the creation of clean drinking water. The creation and maintenance of clean drinking water is becoming a critical problem due to pollution and pressure on the environment. A lot of data is necessary to create clean drinking water. For fieldworkers, two types of data are key: Asset data in an asset management system (EAM for example) and Geographic data in a GIS (ArcGIS Utility Network ). Keeping this type of data up to date and in sync is a challenge for many organizations, leading to duplicating data and creating a bulk of extra attributes and data to keep everything in sync. Using FME, it is possible to synchronize Enterprise Asset Management (EAM) data with the ArcGIS Utility Network in real time. Changes (creation, modification, deletion) in ArcGIS Pro are relayed to EAM via FME, and vice versa. This ensures continuous synchronization of both systems without daily bulk updates, minimizes risks, and seamlessly integrates with ArcGIS Utility Network services. This presentation focuses on the use of FME at a Dutch water company, to create a sync between the asset management and GIS.From Manual to Auto Searching- FME in the Driver's Seat
From Manual to Auto Searching- FME in the Driver's SeatSafe Software
╠²
Finding a specific car online can be a time-consuming task, especially when checking multiple dealer websites. A few years ago, I faced this exact problem while searching for a particular vehicle in New Zealand. The local classified platform, Trade Me (similar to eBay), wasnŌĆÖt yielding any results, so I expanded my search to second-hand dealer sitesŌĆöonly to realise that periodically checking each one was going to be tedious. ThatŌĆÖs when I noticed something interesting: many of these websites used the same platform to manage their inventories. Recognising this, I reverse-engineered the platformŌĆÖs structure and built an FME workspace that automated the search process for me. By integrating API calls and setting up periodic checks, I received real-time email alerts when matching cars were listed. In this presentation, IŌĆÖll walk through how I used FME to save hours of manual searching by creating a custom car-finding automation system. While FME canŌĆÖt buy a car for youŌĆöyetŌĆöit can certainly help you find the one youŌĆÖre after!Security Tips for Enterprise Azure Solutions
Security Tips for Enterprise Azure SolutionsMichele Leroux Bustamante
╠²
Delivering solutions to Azure may involve a variety of architecture patterns involving your applications, APIs data and associated Azure resources that comprise the solution. This session will use reference architectures to illustrate the security considerations to protect your Azure resources and data, how to achieve Zero Trust, and why it matters. Topics covered will include specific security recommendations for types Azure resources and related network security practices. The goal is to give you a breadth of understanding as to typical security requirements to meet compliance and security controls in an enterprise solution.Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdf
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdfICT Frame Magazine Pvt. Ltd.
╠²
Artificial Intelligence (AI) is rapidly changing the face of cybersecurity across the globe. In Nepal, the shift is already underway. Vice President of the Information Security Response Team Nepal (npCERT) and Information Security Consultant at One Cover Pvt. Ltd., Sudan Jha, recently presented an in-depth workshop on how AI can strengthen national security and digital defenses.Raman Bhaumik - Passionate Tech Enthusiast
Raman Bhaumik - Passionate Tech EnthusiastRaman Bhaumik
╠²
A Junior Software Developer with a flair for innovation, Raman Bhaumik excels in delivering scalable web solutions. With three years of experience and a solid foundation in Java, Python, JavaScript, and SQL, she has streamlined task tracking by 20% and improved application stability.OWASP Barcelona 2025 Threat Model Library
OWASP Barcelona 2025 Threat Model LibraryPetraVukmirovic
╠²
Threat Model Library Launch at OWASP Barcelona 2025
https://owasp.org/www-project-threat-model-library/MuleSoft for AgentForce : Topic Center and API Catalog
MuleSoft for AgentForce : Topic Center and API Catalogshyamraj55
╠²
This presentation dives into how MuleSoft empowers AgentForce with organized API discovery and streamlined integration using Topic Center and the API Catalog. Learn how these tools help structure APIs around business needs, improve reusability, and simplify collaboration across teams. Ideal for developers, architects, and business stakeholders looking to build a connected and scalable API ecosystem within AgentForce.PyCon SG 25 - Firecracker Made Easy with Python.pdf
PyCon SG 25 - Firecracker Made Easy with Python.pdfMuhammad Yuga Nugraha
╠²
Explore the ease of managing Firecracker microVM with the firecracker-python. In this session, I will introduce the basics of Firecracker microVM and demonstrate how this custom SDK facilitates microVM operations easily. We will delve into the design and development process behind the SDK, providing a behind-the-scenes look at its creation and features. While traditional Firecracker SDKs were primarily available in Go, this module brings a simplicity of Python to the table.Techniques for Automatic Device Identification and Network Assignment.pdf
Techniques for Automatic Device Identification and Network Assignment.pdfPriyanka Aash
╠²
Techniques for Automatic Device Identification and Network AssignmentFIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptx
FIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptxFIDO Alliance
╠²
FIDO Seminar: Perspectives on Passkeys & Consumer AdoptionYou are not excused! How to avoid security blind spots on the way to production
You are not excused! How to avoid security blind spots on the way to productionMichele Leroux Bustamante
╠²
ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOpt...
ŌĆ£Key Requirements to Successfully Implement Generative AI in Edge DevicesŌĆöOpt...Edge AI and Vision Alliance
╠²
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdf
Information Security Response Team Nepal_npCERT_Vice_President_Sudan_Jha.pdfICT Frame Magazine Pvt. Ltd.
╠²
Featured (20)
Storytelling For The Web: Integrate Storytelling in your Design Process
Storytelling For The Web: Integrate Storytelling in your Design ProcessChiara Aliotta
╠²
The document outlines a livestream presentation by Chiara Aliotta on integrating storytelling into web design to enhance user experiences. It covers the storytelling process for designers, emphasizing aspects such as understanding the audience, structuring narratives, and creating emotional connections. The presentation also includes case studies and practical examples to demonstrate effective storytelling in UX/UI design.Artificial Intelligence, Data and Competition ŌĆō SCHREPEL ŌĆō June 2024 OECD dis...
Artificial Intelligence, Data and Competition ŌĆō SCHREPEL ŌĆō June 2024 OECD dis...OECD Directorate for Financial and Enterprise Affairs
╠²
This presentation by Thibault Schrepel, Associate Professor of Law at Vrije Universiteit Amsterdam University, was made during the discussion ŌĆ£Artificial Intelligence, Data and CompetitionŌĆØ held at the 143rd meeting of the OECD Competition Committee on 12 June 2024. More papers and presentations on the topic can be found at oe.cd/aicomp.
This presentation was uploaded with the authorŌĆÖs consent.
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...SocialHRCamp
╠²
The document discusses leveraging AI to enhance employee wellness through data analytics, automating tasks, and personalized wellness apps, emphasizing the shared responsibility of employee well-being between leaders and organizations. It outlines best practices for using AI in wellness strategies, including ensuring data privacy and security, understanding employee needs, and promoting inclusivity. Lydia Di Francesco, a wellness specialist, shares insights to optimize workplace wellness strategy using AI-driven data analytics and encourages collaboration and transparency.2024 State of Marketing Report ŌĆō by Hubspot
2024 State of Marketing Report ŌĆō by HubspotMarius Sescu
╠²
The State of Marketing 2024 report highlights the transformative impact of AI and automation, emphasizing the importance of personalization and engagement to drive growth in a competitive landscape. Marketers are focusing on optimizing budgets, leveraging social media for brand awareness, and utilizing AI tools to enhance efficiency across tasks. Key trends for 2024 include the rise of experiential marketing, content creation that meets user needs, and strengthened connections through personalized customer experiences.Everything You Need To Know About ChatGPT
Everything You Need To Know About ChatGPTExpeed Software
╠²
ChatGPT is an AI chatbot developed by OpenAI, built on advanced language models to facilitate human-like conversational interactions. Launched in November 2022, it utilizes a transformer architecture to understand and generate text, with applications ranging from content creation to customer service. Despite its capabilities, there are concerns about potential misuse and biases in its responses, which OpenAI aims to mitigate through moderation and user feedback.Product Design Trends in 2024 | Teenage Engineerings
Product Design Trends in 2024 | Teenage EngineeringsPixeldarts
╠²
The realm of product design is a constantly changing environment where technology and style intersect. Every year introduces fresh challenges and exciting trends that mold the future of this captivating art form. In this piece, we delve into the significant trends set to influence the look and functionality of product design in the year 2024.How Race, Age and Gender Shape Attitudes Towards Mental Health
How Race, Age and Gender Shape Attitudes Towards Mental HealthThinkNow
╠²
The November 2023 mental health report indicates that 70% of respondents rate their mental health as 'good' or 'excellent,' with higher diagnoses reported among African Americans and non-Hispanic whites compared to Hispanics and Asians. Younger generations, particularly Gen Z and millennials, are more likely to experience mental health challenges, seek information online, and report that their mental health impacts their work and relationships. Half of the respondents feel comfortable discussing their mental health with professionals, although Gen Z shows the least comfort in this area.AI Trends in Creative Operations 2024 by Artwork Flow.pdf
AI Trends in Creative Operations 2024 by Artwork Flow.pdfmarketingartwork
╠²
Creative operations teams expect increased AI use in 2024. Currently, over half of tasks are not AI-enabled, but this is expected to decrease in the coming year. ChatGPT is the most popular AI tool currently. Business leaders are more actively exploring AI benefits than individual contributors. Most respondents do not believe AI will impact workforce size in 2024. However, some inhibitions still exist around AI accuracy and lack of understanding. Creatives primarily want to use AI to save time on mundane tasks and boost productivity.Skeleton Culture Code
Skeleton Culture CodeSkeleton Technologies
╠²
Organizational culture includes values, norms, systems, symbols, language, assumptions, beliefs, and habits that influence employee behaviors and how people interpret those behaviors. It is important because culture can help or hinder a company's success. Some key aspects of Netflix's culture that help it achieve results include hiring smartly so every position has stars, focusing on attitude over just aptitude, and having a strict policy against peacocks, whiners, and jerks.PEPSICO Presentation to CAGNY Conference Feb 2024
PEPSICO Presentation to CAGNY Conference Feb 2024Neil Kimberley
╠²
PepsiCo provided a safe harbor statement noting that any forward-looking statements are based on currently available information and are subject to risks and uncertainties. It also provided information on non-GAAP measures and directing readers to its website for disclosure and reconciliation. The document then discussed PepsiCo's business overview, including that it is a global beverage and convenient food company with iconic brands, $91 billion in net revenue in 2023, and nearly $14 billion in core operating profit. It operates through a divisional structure with a focus on local consumers.Content Methodology: A Best Practices Report (Webinar)
Content Methodology: A Best Practices Report (Webinar)contently
╠²
This document provides an overview of content methodology best practices. It defines content methodology as establishing objectives, KPIs, and a culture of continuous learning and iteration. An effective methodology focuses on connecting with audiences, creating optimal content, and optimizing processes. It also discusses why a methodology is needed due to the competitive landscape, proliferation of channels, and opportunities for improvement. Components of an effective methodology include defining objectives and KPIs, audience analysis, identifying opportunities, and evaluating resources. The document concludes with recommendations around creating a content plan, testing and optimizing content over 90 days.How to Prepare For a Successful Job Search for 2024
How to Prepare For a Successful Job Search for 2024Albert Qian
╠²
The document provides guidance on preparing a job search for 2024. It discusses the state of the job market, focusing on growth in AI and healthcare but also continued layoffs. It recommends figuring out what you want to do by researching interests and skills, then conducting informational interviews. The job search should involve building a personal brand on LinkedIn, actively applying to jobs, tailoring resumes and interviews, maintaining job hunting as a habit, and continuing self-improvement. Once hired, the document advises setting new goals and keeping skills and networking active in case of future opportunities.Social Media Marketing Trends 2024 // The Global Indie Insights
Social Media Marketing Trends 2024 // The Global Indie InsightsKurio // The Social Media Age(ncy)
╠²
The 2024 social media marketing trends report highlights significant shifts influenced by generative AI, including the emergence of personalized content, the rise of virtual influencers, and a stronger focus on user-generated content. Insights were gathered from 33 experts across 23 leading independent agencies, providing a perspective that emphasizes creativity and authenticity in marketing strategies. Key trends also include the blending of B2B and B2C approaches, reflecting changes in consumer behavior and the evolving landscape of social media engagement.Trends In Paid Search: Navigating The Digital Landscape In 2024
Trends In Paid Search: Navigating The Digital Landscape In 2024Search Engine Journal
╠²
The document discusses trends in paid search for 2024, highlighting changes in user behavior, the implications for financial services, and privacy challenges. It emphasizes the importance of adapting search strategies, utilizing AI-driven tools like performance max and smart bidding, and leveraging first-party data for better marketing efficacy. Key takeaways include holistic SEO and SEM approaches, monitoring shifting user intents, and the need for continuous performance evaluation.5 Public speaking tips from TED - Visualized summary
5 Public speaking tips from TED - Visualized summarySpeakerHub
╠²
The document outlines five public speaking tips from Chris Anderson, TED Talks curator, emphasizing the importance of eye contact, vulnerability, humor, humility, and storytelling. These skills are presented as essential for engaging audiences effectively and are increasingly valuable in today's economy. The article posits that mastering these techniques can enhance speakers' ability to communicate ideas powerfully.ChatGPT and the Future of Work - Clark Boyd
ChatGPT and the Future of Work - Clark Boyd Clark Boyd
╠²
The document provides an overview of generative AI, particularly focusing on ChatGPT and its implications for business and the job market. It discusses the rapid growth of generative AI, its applications in marketing, and the skills needed for the AI era while addressing potential job displacement and the need for adaptation. The agenda includes a Q&A session and emphasizes rethinking work in collaboration with AI technology.Getting into the tech field. what next
Getting into the tech field. what next Tessa Mero
╠²
The document provides career advice for getting into the tech field, including:
- Doing projects and internships in college to build a portfolio.
- Learning about different roles and technologies through industry research.
- Contributing to open source projects to build experience and network.
- Developing a personal brand through a website and social media presence.
- Networking through events, communities, and finding a mentor.
- Practicing interviews through mock interviews and whiteboarding coding questions.Google's Just Not That Into You: Understanding Core Updates & Search Intent
Google's Just Not That Into You: Understanding Core Updates & Search IntentLily Ray
╠²
1. Core updates from Google periodically change how its algorithms assess and rank websites and pages. This can impact rankings through shifts in user intent, site quality issues being caught up to, world events influencing queries, and overhauls to search like the E-A-T framework.
2. There are many possible user intents beyond just transactional, navigational and informational. Identifying intent shifts is important during core updates. Sites may need to optimize for new intents through different content types and sections.
3. Responding effectively to core updates requires analyzing "before and after" data to understand changes, identifying new intents or page types, and ensuring content matches appropriate intents across video, images, knowledge graphs and more.How to have difficult conversations
How to have difficult conversations Rajiv Jayarajah, MAppComm, ACC
╠²
The document provides essential tips on how to handle difficult conversations in a workplace setting, emphasizing the importance of preparation, environment, and timing. It highlights that many employees dread such conversations, often leading to avoidance and worsening situations. Ultimately, the guide aims to promote positive outcomes while maintaining professional relationships.Introduction to Data Science
Introduction to Data ScienceChristy Abraham Joy
╠²
The document discusses the rise and importance of data science and machine learning, highlighting the growing demand for data scientists and the challenges they face. It explains machine learning concepts such as supervised and unsupervised learning, along with various real-world applications and the necessary steps involved in a machine learning workflow. Additionally, the document emphasizes the iterative process of model improvement and feature engineering used to enhance machine learning outcomes.Artificial Intelligence, Data and Competition ŌĆō SCHREPEL ŌĆō June 2024 OECD dis...
Artificial Intelligence, Data and Competition ŌĆō SCHREPEL ŌĆō June 2024 OECD dis...OECD Directorate for Financial and Enterprise Affairs
╠²
Ad
The Sidekick Pattern: Strata talk by Abe Gong
- 1. THE SIDEKICK PATTERN: USING SMALL DATA TO MULTIPLY THE VALUE OF BIG DATA @AbeGong Data Scientist, Jawbone Strata - February 2014 Wednesday, February 12, 14
- 2. Wednesday, February 12, 14
- 3. Wednesday, February 12, 14
- 4. Wednesday, February 12, 14
- 5. Wednesday, February 12, 14
- 6. Wednesday, February 12, 14
- 7. Wednesday, February 12, 14
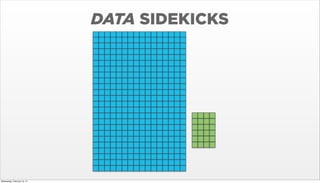
- 8. DATA SIDEKICKS Wednesday, February 12, 14
- 12. EX: CAMPAIGN TARGETING Wednesday, February 12, 14
- 13. EX: CAMPAIGN TARGETING Wednesday, February 12, 14
- 14. EX: CAMPAIGN TARGETING Wednesday, February 12, 14
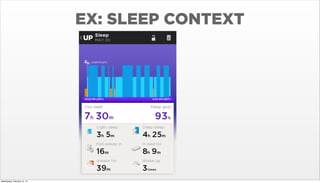
- 15. EX: SLEEP CONTEXT Wednesday, February 12, 14
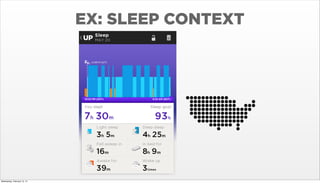
- 16. EX: SLEEP CONTEXT Wednesday, February 12, 14
- 17. EX: SLEEP CONTEXT Wednesday, February 12, 14
- 18. [DATA ART EXAMPLE] SUB-TITLE Wednesday, February 12, 14
- 19. Wednesday, February 12, 14
- 20. EXAMPLES, PLEASE: WHICH DATA STREAMS GET BIG? (...AND BESIDES SIZE, WHAT ELSE DO THEY HAVE IN COMMON?) Wednesday, February 12, 14
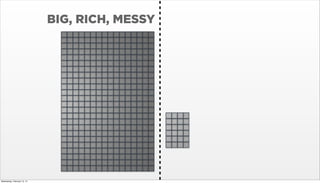
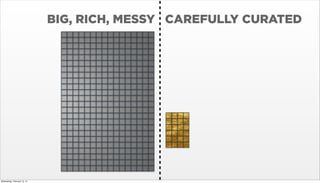
- 21. BIG, RICH, MESSY Wednesday, February 12, 14
- 22. BIG, RICH, MESSY CAREFULLY CURATED Wednesday, February 12, 14
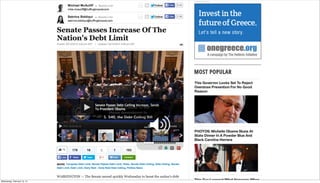
- 24. EX: HUFFPO MODERATION Wednesday, February 12, 14
- 25. Wednesday, February 12, 14
- 26. Wednesday, February 12, 14
- 27. EX: HUFFPO MODERATION Wednesday, February 12, 14
- 28. EX: HUFFPO MODERATION Wednesday, February 12, 14
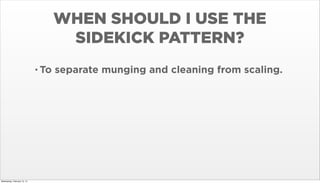
- 29. WHEN SHOULD I USE THE SIDEKICK PATTERN? Wednesday, February 12, 14
- 30. WHEN SHOULD I USE THE SIDEKICK PATTERN? ŌĆó To Wednesday, February 12, 14 separate munging and cleaning from scaling.
- 31. WHEN SHOULD I USE THE SIDEKICK PATTERN? ŌĆó To ŌĆó To Wednesday, February 12, 14 separate munging and cleaning from scaling. bootstrap new data products.
- 32. WHEN SHOULD I USE THE SIDEKICK PATTERN? ŌĆó To ŌĆó To bootstrap new data products. ŌĆó To Wednesday, February 12, 14 separate munging and cleaning from scaling. leverage variety against volume.
- 33. EX: SLEEP RECOVERY Wednesday, February 12, 14
- 34. EX: SLEEP RECOVERY Wednesday, February 12, 14
- 35. EX: SLEEP RECOVERY Wednesday, February 12, 14
- 36. EX: SLEEP RECOVERY Wednesday, February 12, 14
- 37. Wednesday, February 12, 14
- 38. Wednesday, February 12, 14
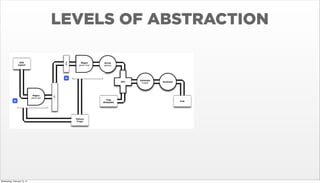
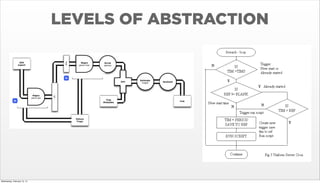
- 39. LEVELS OF ABSTRACTION Wednesday, February 12, 14
- 40. LEVELS OF ABSTRACTION Wednesday, February 12, 14
- 41. LEVELS OF ABSTRACTION Wednesday, February 12, 14
- 42. QUESTIONS? COMMENTS? @AbeGong Data Scientist, Jawbone Strata - February 2014 Wednesday, February 12, 14
- 43. Wednesday, February 12, 14
- 44. Big Rich Messy Sensory User experience External-facing Abstract Business logic Internal-facing ŌĆ£QualitativeŌĆØ Story-making Wednesday, February 12, 14 Small Focused Curated ŌĆ£QuantitativeŌĆØ Science-making
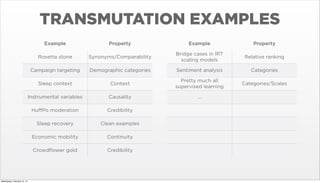
- 45. TRANSMUTATION EXAMPLES Example Example Property Rosetta stone Synonyms/Comparability Bridge cases in IRT scaling models Relative ranking Campaign targeting Demographic categories Sentiment analysis Categories Sleep context Context Pretty much all supervised learning Categories/Scales Instrumental variables Causality ... Hu’¼ĆPo moderation Credibility Sleep recovery Clean examples Economic mobility Continuity Crowd’¼éower gold Wednesday, February 12, 14 Property Credibility
- 46. RECOMMENDED READING ŌĆó ŌĆó Paco Nathan: http://www.slideshare.net/pacoid/using-cascalog-to-build-an-appbased-on-city-of-palo-alto-open-data ŌĆó Jay Kreps: http://engineering.linkedin.com/distributed-systems/log-what-everysoftware-engineer-should-know-about-real-time-datas-unifying ŌĆó Joseph Turian: http://’¼üles.meetup.com/1542972/20120202-more-data-samemodels-STUDY-SLIDES.pdf ŌĆó Wednesday, February 12, 14 Pete Skomoroch: http://www.slideshare.net/pskomoroch/strataendorsements-16939466 Me: http://blog.abegong.com/2014/02/wanted-good-examples-of-datasidekicks.html