? ?? ?? ??: HTTP/2
367 likes33,785 views

10? 17? ????? ?? ?? ? 20?? ?????? ??? "? ?? ?? ??: HTTP/2" ???????.
















































? ?? ?? ??: HTTP/2
- 1. HTTP/2 ? ?? ?? ?? 14? 10? 21? ???
- 2. ??? ?? ? ??? ? NAVER LABS?? ????? ? ?????? ??? ? ? HTTP: The Definitive Guide ??? 14? 10? 21? ???
- 3. ?? ???? ? ? HTTP/2? ? ? ???? ? ? ??? 14? 10? 21? ???
- 4. ? ???? 14? 10? 21? ???
- 5. ? ???? ? HTTP/1? ?? ??? 14? 10? 21? ???
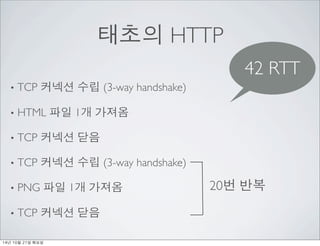
- 6. HTTP/1? ? ??? ? HTTP/1? ??: ? ?????? ??? ??? ???. ? ??? ??????? ?? ?? ??? ???. ? ???? ???? round trip ??? ??? 14? 10? 21? ???
- 7. HTTP/1? ? ??? ? ??? ??? ??? ????? ??? ?? ? ?? <=> ??: 8ms ? ?? <=> ??: 35ms ? ?? <=> ??: 200ms ? ?? <=> ??: 8? ~ 48? 14? 10? 21? ???
- 8. ??? HTTP HTML x 1 PNG x 20 14? 10? 21? ???
- 9. ??? HTTP ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? TCP ??? ?? ? TCP ??? ?? (3-way handshake) ? PNG ?? 1? ??? ? TCP ??? ?? 20? ?? 14? 10? 21? ???
- 10. ??? HTTP ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? TCP ??? ?? ? TCP ??? ?? (3-way handshake) ? PNG ?? 1? ??? ? TCP ??? ?? 42 RTT 20? ?? 14? 10? 21? ???
- 11. HTTP/1.0+ (KEEP-ALIVE) ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? PNG ?? 1? ??? (20? ??) 14? 10? 21? ???
- 12. HTTP/1.0+ (KEEP-ALIVE) ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? PNG ?? 1? ??? (20? ??) 22 RTT 14? 10? 21? ???
- 13. PARALLEL CONNECTIONS ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? TCP ??? 7? ? ?? (3-way handshake) ? PNG ?? 8? ??? ? PNG ?? 8? ? ??? ? PNG ?? 4? ? ??? 14? 10? 21? ???
- 14. PARALLEL CONNECTIONS ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? TCP ??? 7? ? ?? (3-way handshake) ? PNG ?? 8? ??? ? PNG ?? 8? ? ??? ? PNG ?? 4? ? ??? 6 RTT 14? 10? 21? ???
- 15. PIPELINING ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? PNG ?? 20? ??? 14? 10? 21? ???
- 16. PIPELINING ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? PNG ?? 20? ??? 3 RTT 14? 10? 21? ???
- 17. PIPELINING ? TCP ??? ?? (3-way handshake) ? HTML ?? 1? ??? ? PNG ?? 20? ??? ??? ???? ? ??! 14? 10? 21? ???
- 18. HTTP/1? ? ??? 2 ? ??? ?? ? (?? ??) 14? 10? 21? ???
- 19. ?? ??? ?? ?? ??? ? HTTP-NG ???? (1997) ? Roy Fielding? WAKA ?? ? S+M(Speedy+Mobility, ???????) ? SPDY (??, 2009) 14? 10? 21? ???
- 20. HTTP/2 ? HTTP ????? SPDY? ???? HTTP/2 ?? ?? (2012? 10?) 14? 10? 21? ???
- 21. HTTP/2? ? ??? ?Header Compression ?Multiplexed Streams ?Server Push ?Stream Priority 14? 10? 21? ???
- 22. HEADER COMPRESSION ?Huffman Coding ?Header Tables 14? 10? 21? ???
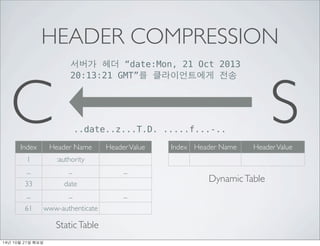
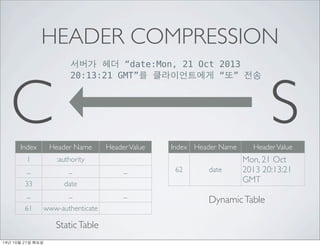
- 23. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 20:13:21 GMTĪ▒? ??????? ?? date:Mon, 21 Oct 2013 20:13:21 GMT C S 14? 10? 21? ???
- 24. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 20:13:21 GMTĪ▒? ??????? ?? C S ..date..z...T.D. .....f...-.. ???? Huffman Coding ??: 34 => 29 14? 10? 21? ???
- 25. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 C 20:13:21 GMTĪ▒? ??????? ?? S ..date..z...T.D. .....f...-.. Index Header Name Header Value 1 :authority ... ... ... 33 date ... ... ... 61 www-authenticate Static Table Index Header Name Header Value Dynamic Table 14? 10? 21? ???
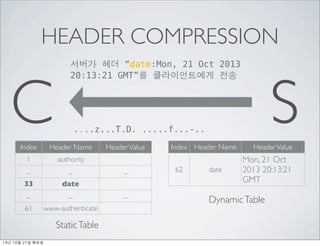
- 26. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 C 20:13:21 GMTĪ▒? ??????? ?? S ....z...T.D. .....f...-.. Index Header Name Header Value 1 :authority ... ... ... 33 date ... ... ... 61 www-authenticate Static Table Index Header Name Header Value Dynamic Table ?? ??? Static Table ???? ??: 29 => 24 14? 10? 21? ???
- 27. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 C 20:13:21 GMTĪ▒? ??????? ?? S ....z...T.D. .....f...-.. Index Header Name Header Value 1 :authority ... ... ... 33 date ... ... ... 61 www-authenticate Static Table Index Header Name Header Value 62 date Mon, 21 Oct 2013 20:13:21 GMT Dynamic Table 14? 10? 21? ???
- 28. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 C 20:13:21 GMTĪ▒? ??????? Ī░?Ī▒ ?? S Index Header Name Header Value 1 :authority ... ... ... 33 date ... ... ... 61 www-authenticate Static Table Index Header Name Header Value 62 date Mon, 21 Oct 2013 20:13:21 GMT Dynamic Table 14? 10? 21? ???
- 29. HEADER COMPRESSION ??? ?? Ī░date:Mon, 21 Oct 2013 C 20:13:21 GMTĪ▒? ??????? Ī░?Ī▒ ?? S Index Header Name Header Value 1 :authority ... ... ... 33 date ... ... ... 61 www-authenticate Static Table Index Header Name Header Value 62 date Mon, 21 Oct 2013 20:13:21 GMT Dynamic Table . ?? ??? Dynamic Table ???? ??: 24 => 1 14? 10? 21? ???
- 30. MULTIPLEXED STREAMS ? ????? ??? ?? ???? ?? ?? ? ?? 14? 10? 21? ???
- 31. MULTIPLEXED STREAMS HTML x 1 PNG x 20 Max Connections: 8 14? 10? 21? ???
- 32. MULTIPLEXED STREAMS ? HTTP/1.1 ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? TCP ??? 7?? ? ?? ? PNG ?? 8?? ???? ?? ? PNG ?? 8?? ? ???? ?? ? PNG ?? 4?? ? ???? ?? 14? 10? 21? ???
- 33. MULTIPLEXED STREAMS ? HTTP/1.1 ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? TCP ??? 7?? ? ?? ? PNG ?? 8?? ???? ?? ? PNG ?? 8?? ? ???? ?? ? PNG ?? 4?? ? ???? ?? ? HTTP/2 ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? PNG ?? 20?? ???? ?? 14? 10? 21? ???
- 34. MULTIPLEXED STREAMS C S 14? 10? 21? ???
- 35. MULTIPLEXED STREAMS GET /a.png GET /b.png GET /c.png ... C S 14? 10? 21? ???
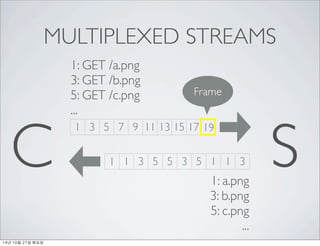
- 36. MULTIPLEXED STREAMS 1: GET /a.png 3: GET /b.png 5: GET /c.png ... C 1 3 5 7 9 11 13 15 17 19 S 14? 10? 21? ???
- 37. MULTIPLEXED STREAMS 1: GET /a.png 3: GET /b.png 5: GET /c.png Frame ... C 1 3 5 7 9 11 13 15 17 19 S 14? 10? 21? ???
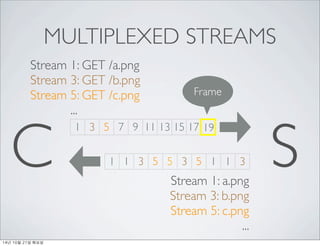
- 38. MULTIPLEXED STREAMS C 1 3 5 7 9 11 13 15 17 19 S 1 1 3 5 5 3 5 1 1 3 1: a.png 3: b.png 5: c.png ... Frame 1: GET /a.png 3: GET /b.png 5: GET /c.png ... 14? 10? 21? ???
- 39. MULTIPLEXED STREAMS Stream 1: GET /a.png Stream 3: GET /b.png Stream 5: GET /c.png ... C 1 3 5 7 9 11 13 15 17 19 S 1 1 3 5 5 3 5 1 1 3 Stream 1: a.png Stream 3: b.png Stream 5: c.png ... Frame 14? 10? 21? ???
- 40. SERVER PUSH ??? ??? ?? ???? ??? ???? ?? 14? 10? 21? ???
- 41. SERVER PUSH HTML x 1 PNG x 2 14? 10? 21? ???
- 42. SERVER PUSH ? Server Push ???: ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? ?? ?? 2?? ???? ?? 14? 10? 21? ???
- 43. SERVER PUSH ? Server Push ???: ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? ?? ?? 2?? ???? ?? ? Server Push ??: ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ?? 2?? ?? ?? 14? 10? 21? ???
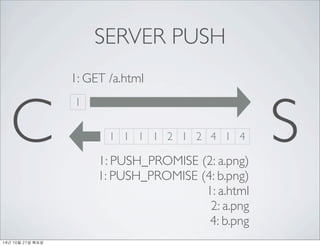
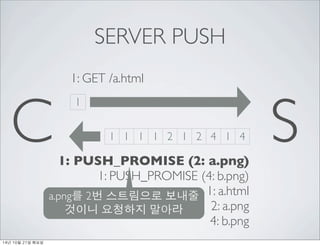
- 44. SERVER PUSH C 1 S 1 1 1 1 2 1 2 4 1 4 1: PUSH_PROMISE (2: a.png) 1: PUSH_PROMISE (4: b.png) 1: a.html 2: a.png 4: b.png 1: GET /a.html 14? 10? 21? ???
- 45. SERVER PUSH C 1 S 1 1 1 1 2 1 2 4 1 4 1: PUSH_PROMISE (2: a.png) 1: PUSH_PROMISE (4: b.png) 1: a.html 2: a.png 4: b.png 1: GET /a.html a.png? 2? ????? ??? ??? ???? ??? 14? 10? 21? ???
- 46. STREAM PRIORITY ??? ??? ??? ??? ? ?? 14? 10? 21? ???
- 47. STREAM PRIORITY HTML x 1 CSS x 1 PNG x 2 14? 10? 21? ???
- 48. STREAM PRIORITY ? ??? ?? ???: ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? CSS ?? 1?? ?? ?? 2?? ???? ?? ? CSS ??? ?? ?? ???? ??? 14? 10? 21? ???
- 49. STREAM PRIORITY ? ??? ?? ???: ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? CSS ?? 1?? ?? ?? 2?? ???? ?? ? CSS ??? ?? ?? ???? ??? ? ??? ????: ? TCP ??? 1?? ?? ? HTML ?? 1?? ???? ?? ? CSS ?? 1?? ?? ?? 2?? ???? ??. ?? ??? CSS ? ???? ??? ???. ? CSS ??? ?? ?? ???? ??? 14? 10? 21? ???
- 50. STREAM PRIORITY C 7 5 3 S 3 3 3 3 7 5 5 7 7 5 3: a.css 5: 1.png 7: 2.png 3: GET /a.css 5: GET /1.png (3? ??) 7: GET /2.png (3? ??) 14? 10? 21? ???
- 51. STREAM PRIORITY C 7 5 3 S 3 3 3 3 7 5 5 7 7 5 3: a.css 5: 1.png 7: 2.png 3: GET /a.css 5: GET /1.png (3? ??) 7: GET /2.png (3? ??) ??? ??? ?????? ?? ??? ?? ?? 14? 10? 21? ???
- 52. FAQ 14? 10? 21? ???
- 53. HTTP/1?? ??? ? ? HTTP ??? ?? ? HTTP ??? ???? ? Connection ?? ??? ? chunked ??? ?? ?? 14? 10? 21? ???
- 54. ??? ?? ? ? Ī░HTTP's existing semantics remain unchanged.Ī▒ ? RFC 7231, 7232, 7233, 7234, 7235 ??? ??? 14? 10? 21? ???
- 55. SPDY? ?? ? ?? ?? SPDY HTTP/2 zlib HPACK 14? 10? 21? ???
- 56. SPDY? ?? ? ?? ?? SPDY HTTP/2 zlib HPACK CRIME ??? 14? 10? 21? ???
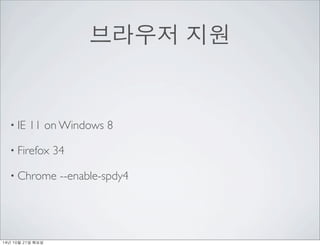
- 57. ???? ?? ? IE 11 on Windows 8 ? Firefox 34 ? Chrome --enable-spdy4 14? 10? 21? ???
- 58. ?? HTTP/2 ???? ?Working Group Last Call (??? ??) ? 2015? 2? RFC? ??? Ī░??Ī▒ 14? 10? 21? ???
- 59. HTTP/2? ????? ? HTTP/2 ?? HPACK ??? ??, ? ietf-http-wg@w3.org ? ??? ????. ? ?? ?? ?? ?? https://github.com/http2/http2-spec ? PullRequest? ??? ????. 14? 10? 21? ???