±Ź°ł“Ē³¾±š³Ł³ó±š³Ü²õČėĆŤ«¤éŌĖÓƤŽ¤Ē³¹µ×½āÕh
Download as PPTX, PDF50 likes35,210 views

Tech Festa 2017¤ĒµĒƤ·¤æ”ø±Ź°ł“Ē³¾±š³Ł³ó±š³Ü²õČėĆŤ«¤éŌĖÓƤŽ¤Ē³¹µ×½āÕh”¹¤Ī„¹„鄤„ɤĒ¤¹









![„Æ„Ø„źŹ½
? „Æ„Ø„ź¤ņgŠŠ¤¹¤ė¤Č„Ł„Æ„æÄŚ¤Ē×īŠĀ¤Ī¤ņ¤ā¤ÄŠŠ¤¬·µ
¤µ¤ģ¤ė
? ĘŚég¤ņÖø¶Ø¤¹¤ė¤³¤Č¤¬¤Ē¤¤ė
Borgman¤ČĶ¬¤ĪŹĖ
{var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west} 10
{var=http_requests,job=webserver,instance=host1:80,service=web,zone=us-west} 9
{var=http_requests,job=webserver,instance=host2:80,service=web,zone=us-west} 11
{var=http_requests,job=webserver,instance=host3:80,service=web,zone=us-west} 0
{var=http_requests,job=webserver,instance=host4:80,service=web,zone=us-west} 10
{var=http_requests,job=webserver,service=web,zone=us-west}[10m]
{var=http_requests,job=webserver,instance=host0:80, ...} 0 1 2 3 4 5 6 7 8 9 10](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-13-320.jpg)






![ŌO¶Ø£ŗPrometheus.yml
? Service Discovery¤ņĄūÓƤ¹¤ė
? EC2¤ņTarget¤Ė¤·¤Ę¤ß¤ė
? localhost¤āĻó¤Ė¤·¤Ę¤ß¤ė
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
ec2_sd_configs:
- region: ap-northeast-1
access_key:
secret_key:
port: 9100
relabel_configs:
- source_labels: [__meta_ec2_tag_Name]
target_label: instance](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-24-320.jpg)



![ŹÖÓ¤ĒtaargetŌO¶Ø¤¹¤ė
? ŠĀ¤·¤¤„µ©`„Š©`×·¼Ó¤¹¤ė¤ČConfigøüŠĀ¤¬±ŲŅŖ
? „Š©`„ø„ē„ó„ß„¹„Ž„Ć„Į
? „µ©`„Š©`¤ĪŹŹ§ scrape_configs:
- job_name: microservice1
target_groups:
- targets: [Өserver1:8003Ӯ]
- targets: [Өserver2:8003Ӯ]
- targets: [Өserver3:8003Ӯ]
- targets: [Өserver4:8003Ӯ]
- job_name: otherjob
target_groups:
- targets: [Өserver3:8086Ӯ]
- targets: [Өserver4:8087Ӯ]](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-30-320.jpg)




![relabeling ¤Č¤Ļ£æ
½Y¹ū”¢¤³¤ó¤Ź¶ØĮx¤Ė¤·¤ĘEC2¤Ī„æ„°Ćū¤ņoŹĀČ”µĆ
scrape_configs:
- job_name: 'node'
ec2_sd_configs:
- region: ap-northeast-1
access_key:
secret_key:
port: 9100
relabel_configs:
- source_labels: [__meta_ec2_tag_Name]
target_label: instance](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-39-320.jpg)

![Ļó¤Īßxk
? ÄæµÄ¤Ī„Ē©`„æ¤ņßxk¤¹¤ė·½·Ø
? Ōģ¤¬ÉŁ¤Ź¤¤öŗĻ¤Ļ”¢ÕżŅ±ķ¬F
relabel_configs:
- source_labels: ["__meta_consul_tags"]
regex: ".*,production,.*”±
action: keep](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-42-320.jpg)
![¾S³Ö[keep]¤ČĘĘ[drop]
? ¤ā¤Ć¤Č¤ā
g¼¤Źrelabelling¤Ī²Ł×÷
? keep¤Čdrop
? Keep
? ÕżŅ±ķ¬F¤ĖŗĻÖĀ¤¹¤ė¤Č”¢²Ł×÷¤ņ¾@¾A¤·¤Ž¤¹
? ŗĻÖĀ¤·¤Ź¤¤öŗĻ¤Ļ”¢IĄķ¤ņ½KĮĖ¤·”¢“Ī¤ĪĻó¤ĖŅʤź¤Ž¤¹
? Drop
? ÕżŅ±ķ¬F¤ĖŗĻÖĀ¤¹¤ė¤ČIĄķ¤ņ½KĮĖ¤·”¢“Ī¤ĪĻó¤ĖŅʤź¤Ž¤¹](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-43-320.jpg)


![EC2¤ĪName„æ„°¤ņ„ø„ē„ÖĆū¤Ė¤¹¤ėĄż
relabel_configs:
- source_labels: ["__meta_ec2_tag_Name"]
regex: "(.*)”±
action: replace
replacement: "${1}”±
target_label: "job"](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-47-320.jpg)
![„Ē„Õ„©„ė„ȤĪ¤ā¤Ī¤Ļ¤ā¤Ć¤Č„·„ó„ׄė¤Ėų¤±¤ė
relabel_configs:
- source_labels: ["__meta_ec2_tag_Name"]
target_label: "job"](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-48-320.jpg)




![node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ
irate(node_load1{instance=~".*-blue"}[1m])
Ź¹¤¤Ź¼¤į¤°¤é¤¤¤Ē”¢¤³¤¦¤¤¤¦„Æ„Ø„ź¤ņŅ¤Ę
„Õ„£©`„ź„ó„°¤Ē„Æ„Ø„ź¤ņų¤Ź¼¤į¤Ę¤·¤Ž¤Ø¤ė”£¤¢¤é”¢ĖŲ³”£
„Æ„Ø„źų¤¤¤Ę¤Ę”¢¤¢¤ģ£æ¤Ę¤Ź¤Ć¤Ę”¢¤½©`¤¤¤Ø¤Š[1m]¤Ī½Y¹ū¤ĘŗĪ¤¬·µ¤Ć¤Ę¤ė£æ£æ](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-53-320.jpg)
![node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ
Range vector ¤Ć¤Ę£æ
https://prometheus.io/docs/querying/basics/#range-vector-selectors
¬FŌŚ¤«¤é[ ]¤ĒÖø¶Ø¤·¤ærégĒ°¤Ž¤Ē¤Ī
¹ ģÄŚ¤Ī¤ņ
¤¹¤Ł¤Ę·µ¤¹½Y¹ū„»„Ć„Č
[5m]¤Ź¤éß^Č„5·Öég
[1h]¤Ź¤éß^Č„£±rég
¤ĪÓåhČ«¤Ę¤ņ·µ¤¹¤Č¤¤¤¦ŅāĪ¶](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-54-320.jpg)
![node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ
Range vector ¤Ć¤Ę£æ
https://prometheus.io/docs/querying/basics/#range-vector-selectors
¬FŌŚ¤«¤é[ ]¤ĒÖø¶Ø¤·¤ærégĒ°¤Ž¤Ē¤Ī
¹ ģÄŚ¤Ī¤ņ
¤¹¤Ł¤Ę·µ¤¹½Y¹ū„»„Ć„Č
[5m]¤Ź¤éß^Č„5·Öég
[1h]¤Ź¤éß^Č„£±rég
¤ĪÓåhČ«¤Ę¤ņ·µ¤¹¤Č¤¤¤¦ŅāĪ¶
£µĆėégøō¤Ē
§¼Æ¤·¤Ę¤¤¤ė¤Č”¢1·Ö¹ ģ¤Ė¤¹¤ė¤Č¼s12½Y¹ū„»„ƄȤ¬·µ¤Ć¤Ę¤Æ¤ė](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-55-320.jpg)
![node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ
Range vector ¤Ć¤Ę£æ
https://prometheus.io/docs/querying/basics/#range-vector-selectors
¬FŌŚ¤«¤é[ ]¤ĒÖø¶Ø¤·¤ærégĒ°¤Ž¤Ē¤Ī¹ ģÄŚ
„Ē©`„æ
§¼Æ„¤„ó„æ©`„Š©`„ė¤ĪÖø¶Ørég¤¬10Ćė¤Ė¤·¤Ę¤ė¤Č¤¤Ė
[9s]¤Č¤¹¤ė¤Č½Y¹ū„»„ƄȤ¬1¤Ä”¢2¤Ä¤Č¤Š¤é¤±¤ė](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-56-320.jpg)
![PromQL
SQL:
SELECT job, instance, method, status, path, rate(value, 5m)
FROM api_http_requests_total
PromQL:
rate(api_http_requests_total[5m])](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-57-320.jpg)

![PromQL
SQL:
SELECT errors.job, errors.instance, [”more labels”],
errors.value / total.value
FROM errors, total
WHERE errors.job=”±foo”± AND total.job=”±foo”± JOIN
[”some more complicated stuff here”]
PromQL:
errors{job=”±foo”±} / total{job=”±foo”±}](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-59-320.jpg)






![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534
餬½~
„µ©`„Ó„¹¤Ī³ÉéL¤Ė°é¤¤é¤ĪÕ{Õū¤¬±ŲŅŖ¤Ė¤Ź¤ė](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-75-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-76-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-77-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m])) > 500
{} 534](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-78-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m]) /
sum rate(requests_total[5m]) * 100 > 1
{} 1.8354](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-79-320.jpg)
![ALERT HighErrorRate
IF sum rate(request_errors_total[5m]) /
sum rate(requests_total[5m]) * 100 > 1
{} 1.8354
øß„Ø„é©`/µĶ„Č„é„Õ„£„Ć„Æ
µĶ„Ø„é©`/øß„Č„é„Õ„£„Ć„Æ
ŗĻÓ](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-80-320.jpg)
![ALERT HighErrorRate
IF sum by(instance, path) rate(request_errors_total[5m]) /
sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01
{instance=”±web-2”±, path=”±/api/comments”±} 2.435
{instance=”±web-1”±, path=”±/api/comments”±} 1.0055
{instance=”±web-2”±, path=”±/api/profile”±} 34.124
„¢„é©`„Č°k»š](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-81-320.jpg)
![ALERT HighErrorRate
IF sum by(instance, path) rate(request_errors_total[5m]) /
sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01
{instance=”±web-2”±, path=”±/api/v1/comments”±} 2.435
„¢„é©`„Č°k»š
„¤„󄹄æ„ó„¹£±
„¤„󄹄æ„ó„¹2~100](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-82-320.jpg)
![ALERT HighErrorRate
IF sum without(instance) rate(request_errors_total[5m]) /
sum without(instance) rate(requests_total[5m]) * 100 > 1
{method=”±GET”±, path=”±/api/v1/comments”±} 2.435
{method=”±POST”±, path=”±/api/v1/comments”±} 1.0055
{method=”±POST”±, path=”±/api/v1/profile”±} 34.124
„¢„é©`„Č°k»š](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-83-320.jpg)


![Alertmanager¤Ī„¢„é©`„ČČŗ
route:
receiver: infra # default receiver
group_by: ['alertname', 'Service', 'Stage', 'Role']
group_wait: 30s # wait for aggregating alert
group_interval: 5m # wait for alert (next time)
repeat_interval: 3h # wait for alert (re-sending same one)
Ķ¬¤ø„¢„é©`„Č”¢
Ķ¬¤ø„µ©`„Ó„¹”¢
Ķ¬¤ø„¹„Ę©`„ø”¢
Ķ¬¤ø„ķ©`„ė
¤¬30ĆėŅŌÄŚ¤ĖĄ“¤æ¤é”¢Ķ¬¤ø„¢„é©`„ȤȤߤŹ¤¹
5·Ö°¤Ė„¢„é©`„Č°k³h¤¹¤ė
“Ī»ŲĖĶŠÅ¤µ¤ģ¤ė¤Ī¤Ļ”¢3régįį](https://image.slidesharecdn.com/random-170827032332/85/Prometheus-88-320.jpg)



































More Related Content
What's hot (20)
Viewers also liked (14)












Similar to ±Ź°ł“Ē³¾±š³Ł³ó±š³Ü²õČėĆŤ«¤éŌĖÓƤŽ¤Ē³¹µ×½āÕh (20)









![[Japan Tech summit 2017] DEP 005](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfdep005-171116035106-thumbnail.jpg?width=560&fit=bounds)
![[Cloud OnAir] ×īŠĀ„¢„ƄׄĒ©`„Č Google Cloud „Ē©`„æévßB„½„ź„å©`„·„ē„ó 2020Äź5ŌĀ14ČÕ ·ÅĖĶ](https://cdn.slidesharecdn.com/ss_thumbnails/0514-200514080330-thumbnail.jpg?width=560&fit=bounds)









Recently uploaded (11)











±Ź°ł“Ē³¾±š³Ł³ó±š³Ü²õČėĆŤ«¤éŌĖÓƤŽ¤Ē³¹µ×½āÕh
- 1. Prometheus ČėéT¤«¤éß\ÓƤŽ¤ĒŲµ×½āÕh ÖźŹ½»įÉē„Ū„ļ„¤„Č„×„é„¹ „·„¹„Ę„ąé_°kG„Ž„Ķ„ø„ć©` “óŗĶĪŻŁFČŹ July Tech Festa 2017 google„Ø„ó„ø„Ė„¢¤¬×÷¤Ć¤æ±OŅ„·„¹„Ę„ą
- 2. “óŗĶĪŻŁFČŹ ÖźŹ½»įÉē„Ū„ļ„¤„Č„×„é„¹ „·„¹„Ę„ąé_°kG „Ž„Ķ„ø„ć©` Microsoft MVP for Azure£Ø2011-2018 Qiita : @t_Yamatoya http://sqlazure.jp/r
- 6. Prometheus¤Ļ”¢ĢŲ¤Ė„ė©`„ėŃŌÕZ¤ĖBorgmon¤Č¶ą¤Æ¤Ī īĖʵ椬¤¢¤ź¤Ž¤¹”£ ŅĄČ»¤Č¤·¤ĘBorgmon¤ĻGoogleÄŚ²æ¤Ī¤ā¤Ī¤Ē¤¹¤¬”¢„¢ „é©`„Ȥņ°k¤¹¤ė¤æ¤į¤Ī„Ē©`„愽©`„¹¤Č¤·¤ĘrĻµĮŠ„Ē©` „æ¤ņQ¤¦¤Č¤¤¤¦°kĻė¤Ļ”¢½ńČÕ¤Ē¤ĻPrometheus”¢ Riemann”¢Heka”¢Bosun¤Č¤¤¤Ć¤æ„Ŗ©`„ׄ󄽩`„¹¤Ī „Ä©`„ė¤ņĶؤø¤ĘŚ¤ÆŹÜ¤±Čė¤ģ¤é¤ģ¤Ę¤Ŗ¤ź” Prometheus ¤Č google SRE „µ„¤„Č„ź„鄤„¢„Ó„ź„Ę„£„Ø„ó„ø„Ė„¢„ź„ó„° ØDØDGoogle¤ĪŠÅīmŠŌ¤ņÖ§¤Ø¤ė„Ø„ó„ø„Ė„¢„ź„ó„°„Į©`„ą
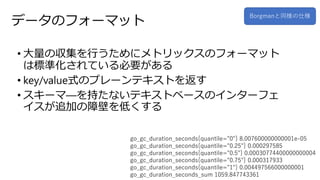
- 8. „Ē©`„æ¤Ī„Õ„©©`„Ž„Ć„Č ? “óĮæ¤Ī §¼Æ¤ņŠŠ¤¦¤æ¤į¤Ė„į„Č„ź„Ć„Æ„¹¤Ī„Õ„©©`„Ž„Ć„Č ¤ĻĖŹ»Æ¤µ¤ģ¤Ę¤¤¤ė±ŲŅŖ¤¬¤¢¤ė ? key/valueŹ½¤Ī„ׄģ©`„ó„Ę„„¹„Ȥņ·µ¤¹ ? „¹„©`„ŽØD¤ņ³Ö¤æ¤Ź¤¤„Ę„„¹„Č„Ł©`„¹¤Ī„¤„ó„æ©`„Õ„§ „¤„¹¤¬×·¼Ó¤ĪÕĻ±Ś¤ņµĶ¤Æ¤¹¤ė go_gc_duration_seconds{quantile="0"} 8.007600000000001e-05 go_gc_duration_seconds{quantile="0.25"} 0.000297585 go_gc_duration_seconds{quantile="0.5"} 0.00030774400000000004 go_gc_duration_seconds{quantile="0.75"} 0.000317933 go_gc_duration_seconds{quantile="1"} 0.004497566000000001 go_gc_duration_seconds_sum 1059.847743361 Borgman¤ČĶ¬¤ĪŹĖ
- 9. „æ©`„²„ƄȤĪ°kŅ ? „Ē©`„æ §¼Æ¤ņ¤¹¤ėĻó¤ņ×ŌÓ¤ĒŹ³ö¤¹¤ė ? „µ©`„Ó„¹„Ē„£„¹„«„Š„ź£ØService Discovery£©¤ņĄūÓƤ¹¤ė¤³¤Č ¤Ē„ź„¹„ȤĪ„į„ó„Ę„Ź„󄹄³„¹„ȤņĻĀ¤²¤ė Borgman¤ČĶ¬¤ĪŹĖ
- 10. „Ē©`„æ¤Ī §¼Æ ? Öø¶Ø¤µ¤ģ¤æégøō¤Ē„æ©`„²„ƄȤĪURI¤«¤é„Õ„§„Ć„Į¤¹¤ė ? HTTP½UÓɤĒ„æ©`„²„ƄȤņ„¹„Æ„ģ„¤„Ō„ó„°¤¹¤ė ? „Õ„§„Ć„Įr¤ĖŗĻ³É䏿¤āÓåh¤¹¤ė ? „Ū„¹„ČĆū¤Č„Ż©`„Č·¬ŗŤĖ½āQ¤Ē¤¤ė¤« ? „ģ„¹„Ż„󄹤ņ·µ¤·¤æ¤« ? §¼Æ¤¬ĶźĮĖ¤·¤æræĢ Borgman¤ČĶ¬¤ĪŹĖ % curl http://webserver:80/varz http_requests 37 errors_total 12
- 11. rĻµĮŠ„Ē©`„æ„Ł©`„¹ ? „Ē©`„æ¤ņ„¤„ó„į„ā„ź„Ē©`„æ„Ł©`„¹¤Ėøń¼{¤·”¢¶ØĘŚµÄ¤Ė „Į„§„Ć„Æ„Ż„¤„ó„ȤĒrĻµĮŠ„Ē©`„æ„Ł©`„¹£Ø„Ē„£„¹„Æ£© ¤Ėų¤³ö¤¹ ? timestamp¤ČvalueŠĪŹ½¤Ē”¢rĻµĮŠ„Ē©`„æ¤ĖŃŲ¤Ć¤Ęøń¼{ ¤¹¤ė Borgman¤ČĶ¬¤ĪŹĖ http_requests_total{status="200",method="GET"}@1434317560938 ? 94355 http_requests_total{status="200",method="GET"}@1434317561287 ? 94934 http_requests_total{status="200",method="GET"}@1434317562344 ? 96483 http_requests_total{status="404",method="GET"}@1434317560938 ? 38473 http_requests_total{status="404",method="GET"}@1434317561249 ? 38544 http_requests_total{status="404",method="GET"}@1434317562588 ? 38663 http_requests_total{status="200",method="POST"}@1434317560885 ? 4748
- 13. „Æ„Ø„źŹ½ ? „Æ„Ø„ź¤ņgŠŠ¤¹¤ė¤Č„Ł„Æ„æÄŚ¤Ē×īŠĀ¤Ī¤ņ¤ā¤ÄŠŠ¤¬·µ ¤µ¤ģ¤ė ? ĘŚég¤ņÖø¶Ø¤¹¤ė¤³¤Č¤¬¤Ē¤¤ė Borgman¤ČĶ¬¤ĪŹĖ {var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west} 10 {var=http_requests,job=webserver,instance=host1:80,service=web,zone=us-west} 9 {var=http_requests,job=webserver,instance=host2:80,service=web,zone=us-west} 11 {var=http_requests,job=webserver,instance=host3:80,service=web,zone=us-west} 0 {var=http_requests,job=webserver,instance=host4:80,service=web,zone=us-west} 10 {var=http_requests,job=webserver,service=web,zone=us-west}[10m] {var=http_requests,job=webserver,instance=host0:80, ...} 0 1 2 3 4 5 6 7 8 9 10
- 14. „¢„é©`„Č/Alertmanager ? ÕęĪ¤ĒÅŠ¶Ļ¤·”¢Õę¤Ė¤Ź¤ė¤Č„¢„é©`„Č°kŠŠ ? „¢„é©`„ȤĖ¤ĻŹ½¤¬Ź¹¤Ø”¢Ė²égµÄ¤ŹéŌ½¤Ø¤Ų¤ĪI¤¬ČŻŅ× ? Altermanager¤ĻĶØÖŖĻȤŲ¤Ī„¢„é©`„ČÜĖĶ¤ņµ£µ±¤¹¤ė ? „¢„Æ„Ę„£„Ö¤Ė¤Ź¤Ć¤Ę¤¤¤ė„¢„é©`„ȤĖź¤ø¤æĖū¤Ī„¢„é©`„ČŅÖÖĘ ? īĖʤ·¤æ„é„Ł„ė„»„ƄȤņ³Ö¤ÄŃ}Źż¤Ī„¢„é©`„Ȥ¬°kÉś¤·¤æėH¤Ī¼Æ¼s Borgman¤ČĶ¬¤ĪŹĖ
- 15. Borgman¤ČPrometheus¤ĪīĖʵ椎¤Č¤į ? „Ē©`„æ„Õ„©©`„Ž„Ć„Č£ŗ„ׄģ©`„ó„Ę„„¹„ȤĪkey/value ? Target Discovery ? „Ē©`„æ¤Ī §¼Æ·½·Ø£ŗURL„Õ„§„Ć„Į”¢„¹„Æ„ģ„¤„Ō„ó„° ? rĻµĮŠ„Ē©`„æ„Ł©`„¹ ? „é„Ł„ė ? „Æ„Ø„źŹ½ ? „¢„é©`„Č
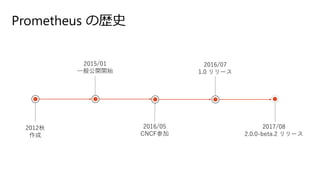
- 16. Prometheus ¤ĪsŹ· 2012Ēļ ×÷³É 2016/05 CNCF²Ī¼Ó 2015/01 Ņ»°ć¹«é_é_Ź¼ 2016/07 1.0 „ź„ź©`„¹ 2017/08 2.0.0-beta.2 „ź„ź©`„¹
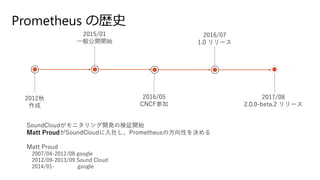
- 17. Prometheus ¤ĪsŹ· 2012Ēļ ×÷³É 2016/05 CNCF²Ī¼Ó 2015/01 Ņ»°ć¹«é_é_Ź¼ 2016/07 1.0 „ź„ź©`„¹ 2017/08 2.0.0-beta.2 „ź„ź©`„¹ SoundCloud¤¬„ā„Ė„æ„ź„ó„°é_°k¤ĪŹŌ^é_Ź¼ Matt Proud¤¬SoundCloud¤ĖČėÉē¤·”¢Prometheus¤Ī·½ĻņŠŌ¤ņQ¤į¤ė Matt Proud 2007/04-2012/08 google 2012/09-2013/09 Sound Cloud 2014/01- google
- 18. Prometheus¤ĪCÄÜ ? „ā„Ė„æ„ź„ó„°„·„¹„Ę„ą¤ČrĻµĮŠDB ? y¶Ø ? „į„Č„ź„Ć„Æ„¹ §¼Æ¤Č±£“ę ? ±£“ꤷ¤æ„į„Č„ź„Ć„Æ„¹¤Ė¤¹¤ė„Æ„Ø„ź ? „¢„é©`„Č ? „Ą„Ć„·„å„Ü©`„É ? ×¢Į¦ ? OS„ā„Ė„æ„ź„ó„° ? ӵĄƄ鄦„Éh¾³
- 19. Prometheus¤¬¤·¤Ź¤¤¤³¤Č ? Éś„ķ„°?„¤„Ł„ó„Č„Ē©`„æ¤Ī §¼Æ ? „ź„Æ„Ø„¹„Č„Č„ģ©`„¹ ? ĄżĶā°kŅ ? éLĘŚ±£“ę„¹„Č„ģ©`„ø ? ×ŌÓĖ®Ę½„¹„±©`„ė ? „ę©`„¶©`/ÕJŌ^¹ÜĄķ
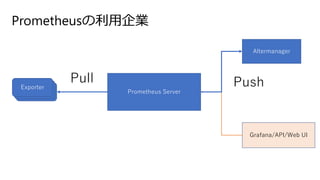
- 20. Prometheus¤ĪĄūÓĆĘóI ? AbemaTV / Cyberagent ? Line ? Yahoo!Japan ? Freee ? „Ū„ļ„¤„Č„×„é„¹
- 21. Prometheus ČėéT
- 23. Prometheus¤ĪŗB ? ŗB¤Ļ gŅ»„Š„¤„Ź„ź¤ņÓ¤«¤¹¤Ą¤±¤ĒOK ? „ׄź„³„ó„Ń„¤„ė¤µ¤ģ¤æ„Š„¤„Ź„ź¤ņ„Ą„¦„ó„ķ©`„ɤ·¤ĘgŠŠ ? Source¤«¤émake ? Docker„³„ó„Ę„Ź©` docker run -p 9090:9090 -v /prometheus-data prom/prometheus -config.file=/prometheus-data/prometheus.yml
- 24. ŌO¶Ø£ŗPrometheus.yml ? Service Discovery¤ņĄūÓƤ¹¤ė ? EC2¤ņTarget¤Ė¤·¤Ę¤ß¤ė ? localhost¤āĻó¤Ė¤·¤Ę¤ß¤ė global: scrape_interval: 5s scrape_configs: - job_name: 'prometheus' scrape_interval: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'node' ec2_sd_configs: - region: ap-northeast-1 access_key: secret_key: port: 9100 relabel_configs: - source_labels: [__meta_ec2_tag_Name] target_label: instance
- 25. exporter¤ņÓ¤«¤¹ ? ±OŅĻó¤Ēexporter¤ņÓ¤«¤·¤Ž¤¹ ? node_exporter: *NIX„«©`„Ķ„ėÓƤĪ„Ļ©`„É„¦„§„¢¤ČOS¤Ī„į„Č „ź„Ć„Æ„¹ §¼Æ”£ node_exporter -- collectors.enabled="conntrack,diskstats,entropy,filefd,filesystem,loadavg,mdadm,meminfo,netdev,netstat, stat,textfile,time,vmstat" >/dev/null 2>&1 &
- 27. „Ó„ø„å„¢„鄤„ŗ±ķŹ¾ ? ĖŹ¤Ē¤ā„°„é„ÕCÄܤĻ¤¢¤ė ? ¤±¤É”¢„Ą„Ć„·„å„Ü©`„ɤŹ¤É¤Ī„Ó„ø„å„¢„鄤„ŗ¤ĻGrafana¤Ź¤É¤Ī „Ó„ø„å„¢„鄤„ŗ„Ä©`„ė¤ĖĪÆČĪ¤¹¤ė·½į ? Prometheus¤Ė„¢„Æ„»„¹¤Ē¤¤ėNWh¾³¤ĖGrafana¤ņ„¤„ó „¹„Č©`„ė ? Docker¤ĒÓĆŅā¤¹¤ė¤Ī¤¬ŗ g # create /var/lib/grafana as persistent volume storage docker run -d -v /var/lib/grafana --name grafana-storage busybox:latest # start grafana docker run -d -p 3000:3000 --name=grafana --volumes-from grafana-storage grafana/grafana
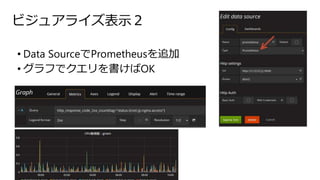
- 28. „Ó„ø„å„¢„鄤„ŗ±ķŹ¾£² ? Data Source¤ĒPrometheus¤ņ×·¼Ó ? „°„é„Õ¤Ē„Æ„Ø„ź¤ņŹé¤±¤Š°æ°
- 30. ŹÖÓ¤ĒtaargetŌO¶Ø¤¹¤ė ? ŠĀ¤·¤¤„µ©`„Š©`×·¼Ó¤¹¤ė¤ČConfigøüŠĀ¤¬±ŲŅŖ ? „Š©`„ø„ē„ó„ß„¹„Ž„Ć„Į ? „µ©`„Š©`¤ĪŹŹ§ scrape_configs: - job_name: microservice1 target_groups: - targets: [”®server1:8003”Æ] - targets: [”®server2:8003”Æ] - targets: [”®server3:8003”Æ] - targets: [”®server4:8003”Æ] - job_name: otherjob target_groups: - targets: [”®server3:8086”Æ] - targets: [”®server4:8087”Æ]
- 31. Service Discovery ? DNS ? Consul / Azure / ec2 ? „Õ„”„¤„ė - job_name: pandora-exporter_nbg1 target_groups: dns_sd_configs: consul_sd_configs: - server: 127.0.0.1:8500 datacenter: nbg1 services: - pandora-exporter - job_name: service2-exporter_fra1 target_groups: dns_sd_configs: consul_sd_configs: - server: 127.0.0.1:8500 datacenter: fra1 services: - service2-exporter
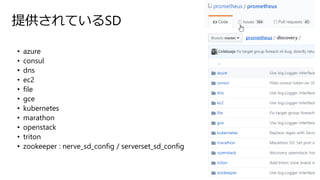
- 32. Ģį¹©¤µ¤ģ¤Ę¤¤¤ėSD ? azure ? consul ? dns ? ec2 ? file ? gce ? kubernetes ? marathon ? openstack ? triton ? zookeeper : nerve_sd_config / serverset_sd_config
- 33. relabelling
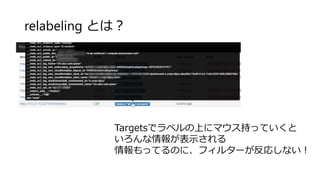
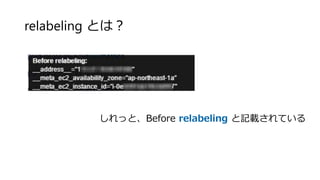
- 36. relabeling ¤Č¤Ļ£æ ¤·¤ģ¤Ć¤Č”¢Before relabeling ¤Č¼ĒŌŲ¤µ¤ģ¤Ę¤¤¤ė
- 39. relabeling ¤Č¤Ļ£æ ½Y¹ū”¢¤³¤ó¤Ź¶ØĮx¤Ė¤·¤ĘEC2¤Ī„æ„°Ćū¤ņoŹĀČ”µĆ scrape_configs: - job_name: 'node' ec2_sd_configs: - region: ap-northeast-1 access_key: secret_key: port: 9100 relabel_configs: - source_labels: [__meta_ec2_tag_Name] target_label: instance
- 40. Relabelling¤Č¤Ļ ? Target¤Ī„į„æ„Ē©`„æ¤ņČ”¤źŽz¤ß”¢ §¼Æ¤¹¤ėĻó¤ņßxk ? ßxk¤¹¤ė¤ČŹ¹ÓƤĒ¤¤ė ? ¼Č¶Ø ? __address__„é„Ł„ė ? instance„é„Ł„ė
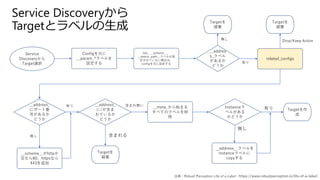
- 41. Service Discovery¤«¤é Targetßxk Config¤ņŌŖ¤Ė __param_*„é„Ł„ė¤ņ ŌO¶Ø¤¹¤ė Job”¢__scheme__”¢ __metric_path__„é„Ł„ė¤¬ŌO ¶Ø¤µ¤ģ¤Ę¤¤¤Ź¤¤öŗĻ¤Ļ”¢ config¤ņŌŖ¤ĖŌO¶Ø¤¹¤ė __addres s_„é„Ł„ė ¤¬¤¢¤ė¤« ¤É¤¦¤« Target¤ņ ĘĘ relabel_configs Target¤ņ ĘĘ __address_ ¤Ė„Ż©`„Č·¬ ŗŤ¬¤¢¤ė¤« ¤É¤¦¤« __scheme__¤¬http¤« æÕ¤Ź¤é80”¢https¤Ź¤é 443¤ņ×·¼Ó __address_ ¤Ė/¤¬ŗ¬¤Ž ¤ģ¤Ę¤¤¤ė¤« ¤É¤¦¤« __meta_¤«¤éŹ¼¤Ž¤ė ¤¹¤Ł¤Ę¤Ī„é„Ł„ė¤ņĻ÷ ³ż Instance„é „Ł„ė¤¬¤¢¤ė ¤«¤É¤¦¤« __address__„é„Ł„ė¤ņ instance„é„Ł„ė¤Ė copy¤¹¤ė Target¤ņ ĘĘ Target¤ņ×÷ ³É o¤· ÓŠ¤ź ŗ¬¤Ž¤ģ¤ė ŗ¬¤Ž¤ģo¤¤ ÓŠ¤ź o¤· Drop/Keep Actiono¤· ÓŠ¤ź ³öµä£ŗRobust Perception Life of a Label : https://www.robustperception.io/life-of-a-label/ Service Discovery¤«¤é Target¤Č„é„Ł„ė¤ĪÉś³É
- 42. Ļó¤Īßxk ? ÄæµÄ¤Ī„Ē©`„æ¤ņßxk¤¹¤ė·½·Ø ? Ōģ¤¬ÉŁ¤Ź¤¤öŗĻ¤Ļ”¢ÕżŅ±ķ¬F relabel_configs: - source_labels: ["__meta_consul_tags"] regex: ".*,production,.*”± action: keep
- 43. ¾S³Ö[keep]¤ČĘĘ[drop] ? ¤ā¤Ć¤Č¤ā g¼¤Źrelabelling¤Ī²Ł×÷ ? keep¤Čdrop ? Keep ? ÕżŅ±ķ¬F¤ĖŗĻÖĀ¤¹¤ė¤Č”¢²Ł×÷¤ņ¾@¾A¤·¤Ž¤¹ ? ŗĻÖĀ¤·¤Ź¤¤öŗĻ¤Ļ”¢IĄķ¤ņ½KĮĖ¤·”¢“Ī¤ĪĻó¤ĖŅʤź¤Ž¤¹ ? Drop ? ÕżŅ±ķ¬F¤ĖŗĻÖĀ¤¹¤ė¤ČIĄķ¤ņ½KĮĖ¤·”¢“Ī¤ĪĻó¤ĖŅʤź¤Ž¤¹
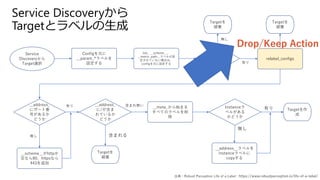
- 44. Service Discovery¤«¤é Targetßxk Config¤ņŌŖ¤Ė __param_*„é„Ł„ė¤ņ ŌO¶Ø¤¹¤ė Job”¢__scheme__”¢ __metric_path__„é„Ł„ė¤¬ŌO ¶Ø¤µ¤ģ¤Ę¤¤¤Ź¤¤öŗĻ¤Ļ”¢ config¤ņŌŖ¤ĖŌO¶Ø¤¹¤ė __addres s_„é„Ł„ė ¤¬¤¢¤ė¤« ¤É¤¦¤« Target¤ņ ĘĘ relabel_configs Target¤ņ ĘĘ __address_ ¤Ė„Ż©`„Č·¬ ŗŤ¬¤¢¤ė¤« ¤É¤¦¤« __scheme__¤¬http¤« æÕ¤Ź¤é80”¢https¤Ź¤é 443¤ņ×·¼Ó __address_ ¤Ė/¤¬ŗ¬¤Ž ¤ģ¤Ę¤¤¤ė¤« ¤É¤¦¤« __meta_¤«¤éŹ¼¤Ž¤ė ¤¹¤Ł¤Ę¤Ī„é„Ł„ė¤ņĻ÷ ³ż Instance„é „Ł„ė¤¬¤¢¤ė ¤«¤É¤¦¤« __address__„é„Ł„ė¤ņ instance„é„Ł„ė¤Ė copy¤¹¤ė Target¤ņ ĘĘ Target¤ņ×÷ ³É o¤· ÓŠ¤ź ŗ¬¤Ž¤ģ¤ė ŗ¬¤Ž¤ģo¤¤ ÓŠ¤ź o¤· Drop/Keep Action o¤· ÓŠ¤ź ³öµä£ŗRobust Perception Life of a Label : https://www.robustperception.io/life-of-a-label/ Service Discovery¤«¤é Target¤Č„é„Ł„ė¤ĪÉś³É
- 45. 2¤Ä¤Ī„é„Ł„ė¤ĖŗĻÖĀ¤µ¤»¤æ¤¤öŗĻ ? source_labels ? „ź„¹„ȤĒŗƤ¤Ź¤č¤¦¤ĖŃ}Źż¤Ī„é„Ł„ė¤ņÖø¶Ø¤Ē¤¤ė ? ½Y¹ū ? „»„ß„³„ķ„ó¤Ē·Öøī¤µ¤ģ¤ĘßB½Y ? separator ? „»„Ń„ģ„æ©`¤ņäøü¤Ē¤¤Ž¤¹ ? Ē·Ā䤷¤Ę¤¤¤ė„é„Ł„ė¤Ė¤ĻæÕĪÄ×ÖĮŠ¤¬ŌO¶Ø¤µ¤ģ¤ė ? relabel_configs ? „ź„¹„ȤĒ”¢ŗƤ¤Ź¤č¤¦¤ĖŃ}Źż¤Īaction¤ņŌO¶Ø¤Ē¤¤ė ? drop¤«keep¤ĒIĄķ¤¬ĶźĮĖ¤¹¤ė¤Ž¤Ē”¢„¢„Æ„·„ē„ó¤¬ßmÓƤµ¤ģ¤ė
- 46. „é„Ł„ė¤Īäøü ? Relabelling¤Ī„į„¤„óCÄܤĻ”¢ÖĆQ¤Ē¤¹ ? Source_lables¤Ėregex¤ņßmÓƤ·”¢ŗĻÖĀ¤·¤æ¤ā¤Ī¤ņ replacement¤ĒÖƤQ¤Ø”¢target_label¤Ė½Y¹ū¤ņų¤Žz¤ß ¤Ž¤¹ ? æÕ„é„Ł„ė¤Ļ„é„Ł„ė¤¬Ļ÷³ż¤µ¤ģ¤æ¤³¤Č¤ņ±ķ¤·¤Ž¤¹ ? __meta„é„Ł„ė¤Ļrelabelling¤Īįį”¢Ļ÷³ż¤µ¤ģ¤Ž¤¹
- 47. EC2¤ĪName„æ„°¤ņ„ø„ē„ÖĆū¤Ė¤¹¤ėĄż relabel_configs: - source_labels: ["__meta_ec2_tag_Name"] regex: "(.*)”± action: replace replacement: "${1}”± target_label: "job"
- 49. „¤„󄹄æ„ó„¹„é„Ł„ė ? „µ©`„Ó„¹„Ē„£„¹„«„Š„ź©` ? __address__¤Ėhost:port ¤ņøń¼{ ? relabelling¤Ī½KĮĖ¤Ž¤Ē¤Ė”¢instance„é„Ł„ė¤¬¤Ź¤¤öŗĻ ? „Ē„Õ„©„ė„ȤĒ”¢__address__¤Ī¤ņŌO¶Ø ? EC2„¤„󄹄æ„ó„¹ID¤äZookeeper¤Ī„Ń„¹¤ņŌO¶ØæÉÄÜ ? Ėū¤Ī„é„Ł„ė¤ņÕi¤ß¤ä¤¹¤¤„¤„󄹄æ„ó„¹Ćū¤Č¤·¤Ę×·¼Ó¤Ļ ±Ü¤±¤ė
- 50. ¤½¤ĪĖū¤Ī„é„Ł„ė ? schema”¢metrics_path”¢params¤Ļ„Ē„Õ„©„ė„Č ? http/https¤«¤ņ“_ÕJ¤Ē¤¤Ž¤¹ ? __param_* „é„Ł„ė ? ø÷URL„Ń„é„į©`„æ©`¤Ī×ī³õ¤Ī¤¬ŗ¬¤Ž¤ģ¤ė ? ×ī³õ¤Ī¤ņrelabel¤Ē¤¤ė
- 51. Query
- 52. „é„Ł„ė {instance=”°example1-com-green",job="node"} 0.005 {instance=”°example2-com-green",job="node"} 0.005 {instance=”°example3-com-green",job="node"} 0.005 node_load1{instance=~"(-hokan-jp|-batch|wh-plus-com|futon-jp|kutsu-jp|-jp)-green"} / count by(job, instance)(count by(job, instance, cpu) (node_cpu{instance=~"(-hokan-jp|-batch|wh-plus-com |futon-jp|kutsu-jp|-jp)-green"})) „Æ„Ø„ź
- 54. node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ Range vector ¤Ć¤Ę£æ https://prometheus.io/docs/querying/basics/#range-vector-selectors ¬FŌŚ¤«¤é[ ]¤ĒÖø¶Ø¤·¤ærégĒ°¤Ž¤Ē¤Ī ¹ ģÄŚ¤Ī¤ņ ¤¹¤Ł¤Ę·µ¤¹½Y¹ū„»„Ć„Č [5m]¤Ź¤éß^Č„5·Öég [1h]¤Ź¤éß^Č„£±rég ¤ĪÓåhČ«¤Ę¤ņ·µ¤¹¤Č¤¤¤¦ŅāĪ¶
- 55. node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ Range vector ¤Ć¤Ę£æ https://prometheus.io/docs/querying/basics/#range-vector-selectors ¬FŌŚ¤«¤é[ ]¤ĒÖø¶Ø¤·¤ærégĒ°¤Ž¤Ē¤Ī ¹ ģÄŚ¤Ī¤ņ ¤¹¤Ł¤Ę·µ¤¹½Y¹ū„»„Ć„Č [5m]¤Ź¤éß^Č„5·Öég [1h]¤Ź¤éß^Č„£±rég ¤ĪÓåhČ«¤Ę¤ņ·µ¤¹¤Č¤¤¤¦ŅāĪ¶ £µĆėégøō¤Ē §¼Æ¤·¤Ę¤¤¤ė¤Č”¢1·Ö¹ ģ¤Ė¤¹¤ė¤Č¼s12½Y¹ū„»„ƄȤ¬·µ¤Ć¤Ę¤Æ¤ė
- 56. node_load1[1m]¤Ī[1m]¤ĘŗĪ£æ Range vector ¤Ć¤Ę£æ https://prometheus.io/docs/querying/basics/#range-vector-selectors ¬FŌŚ¤«¤é[ ]¤ĒÖø¶Ø¤·¤ærégĒ°¤Ž¤Ē¤Ī¹ ģÄŚ „Ē©`„æ §¼Æ„¤„ó„æ©`„Š©`„ė¤ĪÖø¶Ørég¤¬10Ćė¤Ė¤·¤Ę¤ė¤Č¤¤Ė [9s]¤Č¤¹¤ė¤Č½Y¹ū„»„ƄȤ¬1¤Ä”¢2¤Ä¤Č¤Š¤é¤±¤ė
- 57. PromQL SQL: SELECT job, instance, method, status, path, rate(value, 5m) FROM api_http_requests_total PromQL: rate(api_http_requests_total[5m])
- 58. PromQL SQL: SELECT city, AVG(value) FROM temperature_Celsius WHERE country=”±germany”± GROUP BY city PromQL: avg by(city) (temperature_celsius{country=”±germany”±})
- 59. PromQL SQL: SELECT errors.job, errors.instance, [”more labels”], errors.value / total.value FROM errors, total WHERE errors.job=”±foo”± AND total.job=”±foo”± JOIN [”some more complicated stuff here”] PromQL: errors{job=”±foo”±} / total{job=”±foo”±}
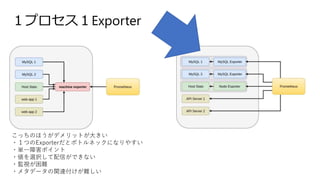
- 60. Exporter
- 63. exporter¤Ī·Nī https://prometheus.io/docs/instrumenting/exporters/ ¤Ė100ŅŌÉĻ„ź„¹„Č„¢„Ƅפµ¤ģ¤Ę¤¤¤Ž¤¹
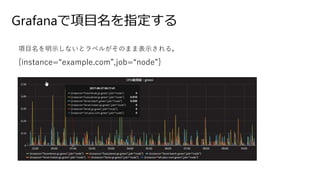
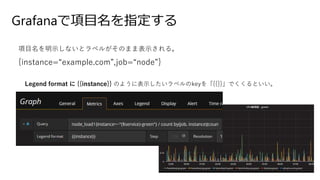
- 68. Grafana¤ĒķÄæĆū¤ņÖø¶Ø¤¹¤ė ķÄæĆū¤ņĆ÷Ź¾¤·¤Ź¤¤¤Č„é„Ł„ė¤¬¤½¤Ī¤Ž¤Ž±ķŹ¾¤µ¤ģ¤ė”£ {instance=”°example.com”±,job=”°node”±} Legend format ¤Ė {{instance}} ¤Ī¤č¤¦¤Ė±ķŹ¾¤·¤æ¤¤„é„Ł„ė¤Īkey¤ņ”ø{{}}”¹¤Ē¤Æ¤Æ¤ė¤Č¤¤¤¤”£
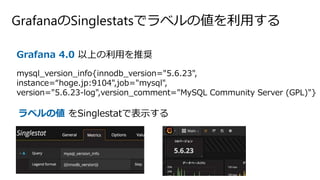
- 69. Grafana¤ĪSinglestats¤Ē„é„Ł„ė¤Ī¤ņĄūÓƤ¹¤ė Grafana 4.0 ŅŌÉĻ¤ĪĄūÓƤņĶĘX mysql_version_info{innodb_version="5.6.23", instance=”°hoge.jp:9104",job="mysql", version="5.6.23-log",version_comment="MySQL Community Server (GPL)"} „é„Ł„ė¤Ī ¤ņSinglestat¤Ē±ķŹ¾¤¹¤ė
- 72. Alerts
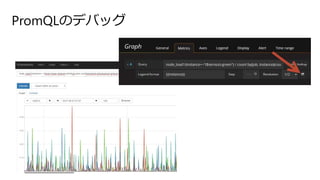
- 73. ALERT <alert name> IF <PromQL vector expression> FOR <duration> LABELS { ... } ANNOTATIONS { ... } <elem1> <val1> <elem2> <val2> <elem3> <val3> ... ½Y¹ū°¤ĖŅ»¤Ä¤Ī„¢„é©`„Č
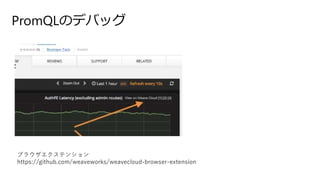
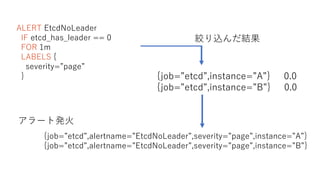
- 74. ALERT EtcdNoLeader IF etcd_has_leader == 0 FOR 1m LABELS { severity=”±page”± } {job=”±etcd”±,alertname=”±EtcdNoLeader”±,severity=”±page”±,instance=”±A”±} {job=”±etcd”±,alertname=”±EtcdNoLeader”±,severity=”±page”±,instance=”±B”±} {job=”±etcd”±,instance=”±A”±} 0.0 {job=”±etcd”±,instance=”±B”±} 0.0 ½g¤źŽz¤ó¤Ą½Y¹ū „¢„é©`„Č°k»š
- 75. ALERT HighErrorRate IF sum rate(request_errors_total[5m])) > 500 {} 534 餬½~ „µ©`„Ó„¹¤Ī³ÉéL¤Ė°é¤¤é¤ĪÕ{Õū¤¬±ŲŅŖ¤Ė¤Ź¤ė
- 76. ALERT HighErrorRate IF sum rate(request_errors_total[5m])) > 500 {} 534
- 77. ALERT HighErrorRate IF sum rate(request_errors_total[5m])) > 500 {} 534
- 78. ALERT HighErrorRate IF sum rate(request_errors_total[5m])) > 500 {} 534
- 79. ALERT HighErrorRate IF sum rate(request_errors_total[5m]) / sum rate(requests_total[5m]) * 100 > 1 {} 1.8354
- 80. ALERT HighErrorRate IF sum rate(request_errors_total[5m]) / sum rate(requests_total[5m]) * 100 > 1 {} 1.8354 øß„Ø„é©`/µĶ„Č„é„Õ„£„Ć„Æ µĶ„Ø„é©`/øß„Č„é„Õ„£„Ć„Æ ŗĻÓ
- 81. ALERT HighErrorRate IF sum by(instance, path) rate(request_errors_total[5m]) / sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01 {instance=”±web-2”±, path=”±/api/comments”±} 2.435 {instance=”±web-1”±, path=”±/api/comments”±} 1.0055 {instance=”±web-2”±, path=”±/api/profile”±} 34.124 „¢„é©`„Č°k»š
- 82. ALERT HighErrorRate IF sum by(instance, path) rate(request_errors_total[5m]) / sum by(instance, path) rate(requests_total[5m]) * 100 > 0.01 {instance=”±web-2”±, path=”±/api/v1/comments”±} 2.435 „¢„é©`„Č°k»š „¤„󄹄æ„ó„¹£± „¤„󄹄æ„ó„¹2~100
- 83. ALERT HighErrorRate IF sum without(instance) rate(request_errors_total[5m]) / sum without(instance) rate(requests_total[5m]) * 100 > 1 {method=”±GET”±, path=”±/api/v1/comments”±} 2.435 {method=”±POST”±, path=”±/api/v1/comments”±} 1.0055 {method=”±POST”±, path=”±/api/v1/profile”±} 34.124 „¢„é©`„Č°k»š
- 84. Alertmanager
- 85. Alertmanager¤ĪCÄÜ ? Ķ¬¤ø„¢„é©`„ČČŗ¤ņ¤Ž¤Č¤į¤ė ? Õl¤ĖĖĶ¤ė¤«„ė©`„Ę„£„ó„°¤¹¤ė ? ŌŁĖĶ¤ä„Æ„ķ©`„ŗ¤Ī„³„ó„Č„ķ©`„ė
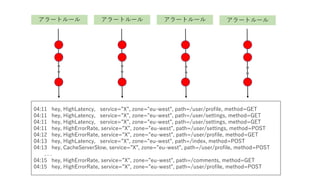
- 86. „¢„é©`„Č„ė©`„ė „¢„é©`„Č„ė©`„ė „¢„é©`„Č„ė©`„ė „¢„é©`„Č„ė©`„ė 04:11 hey, HighLatency, service=”±X”±, zone=”±eu-west”±, path=/user/profile, method=GET 04:11 hey, HighLatency, service=”±X”±, zone=”±eu-west”±, path=/user/settings, method=GET 04:11 hey, HighLatency, service=”±X”±, zone=”±eu-west”±, path=/user/settings, method=GET 04:11 hey, HighErrorRate, service=”±X”±, zone=”±eu-west”±, path=/user/settings, method=POST 04:12 hey, HighErrorRate, service=”±X”±, zone=”±eu-west”±, path=/user/profile, method=GET 04:13 hey, HighLatency, service=”±X”±, zone=”±eu-west”±, path=/index, method=POST 04:13 hey, CacheServerSlow, service=”±X”±, zone=”±eu-west”±, path=/user/profile, method=POST . . . 04:15 hey, HighErrorRate, service=”±X”±, zone=”±eu-west”±, path=/comments, method=GET 04:15 hey, HighErrorRate, service=”±X”±, zone=”±eu-west”±, path=/user/profile, method=POST
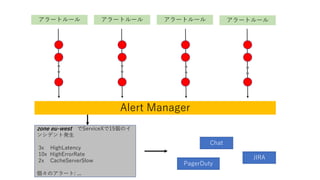
- 87. „¢„é©`„Č„ė©`„ė „¢„é©`„Č„ė©`„ė „¢„é©`„Č„ė©`„ė „¢„é©`„Č„ė©`„ė Alert Manager zone eu-west ¤ĒServiceX¤Ē15¤Ī„¤ „ó„·„Ē„ó„Č°kÉś 3x HighLatency 10x HighErrorRate 2x CacheServerSlow ”©¤Ī„¢„é©`„Č: ... Chat JIRA PagerDuty
- 88. Alertmanager¤Ī„¢„é©`„ČČŗ route: receiver: infra # default receiver group_by: ['alertname', 'Service', 'Stage', 'Role'] group_wait: 30s # wait for aggregating alert group_interval: 5m # wait for alert (next time) repeat_interval: 3h # wait for alert (re-sending same one) Ķ¬¤ø„¢„é©`„Č”¢ Ķ¬¤ø„µ©`„Ó„¹”¢ Ķ¬¤ø„¹„Ę©`„ø”¢ Ķ¬¤ø„ķ©`„ė ¤¬30ĆėŅŌÄŚ¤ĖĄ“¤æ¤é”¢Ķ¬¤ø„¢„é©`„ȤȤߤŹ¤¹ 5·Ö°¤Ė„¢„é©`„Č°k³h¤¹¤ė “Ī»ŲĖĶŠÅ¤µ¤ģ¤ė¤Ī¤Ļ”¢3régįį
- 90. {alertname=”±DatacenterOnFire”±, severity=”±huge-page”±, zone=”±eu-west”±} {alertname=”±LatencyHigh”±, severity=”±page”±, ..., zone=”±eu-west”±} ... {alertname=”±LatencyHigh”±, severity=”±page”±, ..., zone=”±eu-west”±} {alertname=”±ErrorsHigh”±, severity=”±page”±, ..., zone=”±eu-west”±} ... {alertname=”±ServiceDown”±, severity=”±page”±, ..., zone=”±eu-west”±} „¢„Æ„Ę„£„Ö¤Ė¤Ź¤Ć¤æ¤é”¢ Ķ¬Ņ»„ź©`„ø„ē„ó¤Ī¤¹¤Ł¤Ę¤Ī„¢„é©`„Ȥņ„ß„å©`„ȤĖ¤¹¤ė