IBM Watson Assistant ?? ?? ?? ?? ?? (2019.11.18)
4 likes706 views

IBM Watson Assistant ?? ?? ?? ?? ?? (2019.11.18)










































![Chat Flow ???
150
2nd function - Prepare for Telegram
<Source Code>
msg.payload = {
chatId : msg.chatId,
type : "message",
content : msg.payload.output.text[0]
};
return msg;](https://image.slidesharecdn.com/kyoyoonchatbotpresentationfinal-191117114452/85/IBM-Watson-Assistant-2019-11-18-150-320.jpg)





















![Skill?? Entity ?? - @account
235
accountNames / Patterns / @([A-Za-z0-9_]+)](https://image.slidesharecdn.com/kyoyoonchatbotpresentationfinal-191117114452/85/IBM-Watson-Assistant-2019-11-18-235-320.jpg)


![ˇ°Account Specifiedˇ± Node?
Web Hook ???? ??
252
1. Web Hook ??? ????? ??? ??
Last Tweets for $account:<br> - <? $webhook_result_1.response.result.message[0] ?> <br> - <?
$webhook_result_1.response.result.message[1] ?><br> - <? $webhook_result_1.response.result.message[2] ?>
2. Web Hook ??? ???? ??
I couldn't find the account - please try again with e.g. @blackmirror @stranger_things](https://image.slidesharecdn.com/kyoyoonchatbotpresentationfinal-191117114452/85/IBM-Watson-Assistant-2019-11-18-252-320.jpg)





IBM Watson Assistant ?? ?? ?? ?? ?? (2019.11.18)
- 1. Chatbot ?? ??? ?? ?? ? IBM Watson Assistant ?? Chatbot ??? 2019.11.18 ???: ??? 1
- 2. ?? ? Chatbot ? ?? ? ?? ?? ? Chatbot ? ?? ?? ? Chatbot ? ?? ? ?? ? Chatbot ?? ???? ? Chatbot ?? ? ??? ?? ?? (Hands-On) 2
- 3. Chatbot ? ?? ? ?? ?? 3
- 4. Chatbot (??) ??? ? ???? ??? ??? ???, Chatbot ? ??? ? ???? ????. ? ˇ°A computer program designed to simulate conversation with human users, especially over the Internet.ˇ± ? ? ? ????? ????, Chatbot ? ? ???, ?????? ?? ???? ?? ? (????, ????, ???? ?)? ? ?? ?? ???? ??? ???? ?? ??? ???? ???? ????? ?? ?? ? ??? ??? ? ??? ???? ????? ??? ????. ? ??? Chatbot? ????? ??? ?? ???? ?????? ??? ? ??. 4
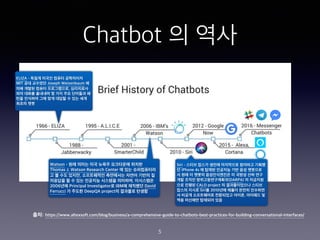
- 5. Chatbot ? ?? 5 ??: https://www.altexsoft.com/blog/business/a-comprehensive-guide-to-chatbots-best-practices-for-building-conversational-interfaces/ ELIZA - ??? ??? ??? ????? MIT ?? ???? Joseph Weizenbaum ? ?? ??? ??? ??????, ????? ?? ??? ???? ? ?? ?? ???? ? ?? ???? ?? ?? ??? ? ?? ?? ??? ?? Watson - ?? ??? ?? ??? ????? ??? Thomas J. Watson Research Center ? ?? ?????? ? ? ?? ???, ?????? ????? ??? ??? ? ???? ? ? ?? ???? ???? ????, ????? 2006?? Principal Investigator? IBM? ???? David Ferrucci ? ??? DeepQA project? ???? ??? Siri - ??? ??? ??? ????? ???? ??? ? iPhone 4s ? ??? ???? ?? ?? ???? ? ?? ? ??? ??????? ? ??? ?? ?? ?? ??? ?????????(DARPA) ? ???? ?? ??? CALO project ? ??????? ??? ??? ??? Siri? 2010?? ??? ??? ???? ? ??? ?????? ????? ???, ???? ? ?? ???? ???? ??
- 6. Chatbot ? ? ????? ? Chatbot ? ???? ?????? ??? ?? ?? ? ??? ????? ??? ???? ?? ?? ??? ? ?? ???? ??? ?????? ????? ??? ? ???? ??????? ????. ? ?? ??? Chatbot ? ??? ??? ??? ???? ? ???? ?? ??? ????? ?? ??? ?? ?? ? ?? ??? ??? ?? ??? ???? ?? ? ?? ?? ???? ????? ??? ?? ??? ??. 6
- 7. ??? ? Chatbot ? ?????? ? 2017? 11?? ?? ?4? ??? ?? ?? ????? ? ??? ?? ???? ???? Chatbot ? ??? ? ?????? ?? ? ?? ??? ???? ??. ? ????? ???, ???? Chatbot? ????? ?????? ? ?? ??? ??? ??. ? ??? ?? - Chatbot? ??? ??? ????? ? ?? ? ??? ????. ? ?????? ?? - Chatbot? ????? ??? ? ? ???? ???? ?? ??? ???? ? ?? ? ? ? ???? ?? ????. ? ?? ? ?? ?? - Chatbot? ???? ???? ? ? ? ??? ???? ??? ??? ?? ???? ? ? ??? ? ?? ?? ??? ??? ? ??? ??? ?. ? ??? ?? - Chatbot ?? ?? ??? ???? ?? ??. ?, ???? Chatbot? ??? ?? ??? ?? ?? ???? ??? ?? ????? ????. 7
- 8. Chatbot ? ?? ?? 8
- 9. ¨CChristina Milian ˇ°I think chatbots are the future of engagement between a fan and a brand or celebrity.ˇ± 9
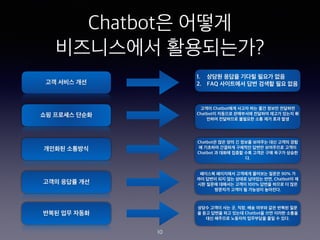
- 10. Chatbot? ??? ?????? ?????? ?? ??? ?? ?? ???? ??? ???? ???? ??? ??? ?? ??? ?? ??? 10 1. ??? ??? ??? ??? ?? 2. FAQ ????? ?? ??? ?? ?? ??? Chatbot?? ??? ?? ?? ??? ???? Chatbot? ???? ????? ???? ??? ??? ? ??? ????? ???? ?? ?? ?? ?? Chatbot? ?? ?? ? ??? ???? ?? ??? ?? ? ???? ???? ???? ??? ????? ??? Chatbot ? ??? ??? ?? ??? ?? ??? ??? ?. ???? ????? ???? ???? ??? 90% ? ?? ??? ?? ?? ??? ???? ??, Chatbot? ? ?? ??? ???? ??? 100% ??? ??? ? ?? ???? ??? ? ???? ????. ??? ??? ?? ?, ??, ?? ??? ?? ??? ?? ? ?? ??? ?? ??? Chatbot? ?? ??? ??? ?? ???? ???? ????? ?? ? ??.
- 11. Chatbot ? ?? ? ?? 11
- 12. ?? ??? Chatbot? ???? ? Chatbot ? ??? ?? ?? ??? ?? ????? ??? ??? ??? ?? ????? ?? ? ??? ??? ??? ? ?? ?? (Lead Generation)?? ????? ??? ??? ??? ? ? ?? ??? Chatbot? ?? ??? ?? ???? ??. ?? ???? ????? ????? Chatbot? ?? 5?? ??? ??? ? ??. ? FAQ assistants - ??? ??? ?? ?? ?? ??? ??? ?? ???? ????? ?? ? Navigation Bots - ??? ??? ??? ?? ???? ?? ?? ???? ?? ????? ??? ? Lead generation and retention bots - ?? ???? ???? ? ??? ???? ? ??? ?? ?? ???? ?? ??? ??? ???? ???? ?? ??? ?? ? Transaction bots - ?? ?? Chatbot? ?? ?? ?????? ??? ?? ??? ???? ?? ?? ?? ???? ??? ? ??? ???? ?? ? Internal assistant chatbots - ?? ?? ???? ???? ???? ?? ?? ? ???? ??? ? ??? ??? ???? ?? ?? Chatbot? ??? ????? ?? (?: ?? ? ??? ??? ? ???? ?? ?? ?? ?? ?? ??) 12
- 13. ?? ?? - ??? ? Hotel Search Chatbot Demo - GoHero.AI ? ??: https://www.youtube.com/watch?v=7LWY8rwpTnI 13
- 14. ?? ?? - ??? ?? ? Table booking chatbot - ADEO WEB ? ??: https://www.youtube.com/watch?v=Y84M_7AiJto 14
- 15. ?? ?? - ???? ?? ? Healthcare Chatbot Demo - Avaya Messaging Automation ? ??: https://www.youtube.com/watch?v=nvOJQ4JttP0 15
- 16. ?? ?? - ?? ? ?? ?? ? Retailer & Brand Chatbot offers to consumers powered by AI - TrendBrew ? ??: https://www.youtube.com/watch?v=74JEJlpX9w4 16
- 17. ?? ?? - Google Duplex ? Google Duplex A.I. - How Does it Work? - ColdFusion ? ??: https://www.youtube.com/watch?v=IuIpgArEZig 17
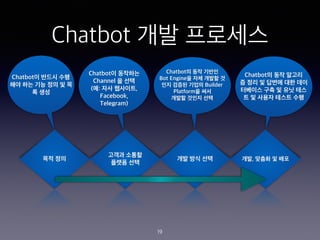
- 19. Chatbot ?? ???? ?? ?? ??? ??? ??? ?? ?? ?? ?? ??, ??? ? ?? Chatbot? ??? ?? ?? ?? ?? ?? ? ? ? ?? Chatbot? ???? Channel ? ?? (?: ?? ????, Facebook, Telegram) Chatbot? ?? ??? Bot Engine? ?? ??? ? ?? ??? ??? Builder Platform? ?? ??? ??? ?? Chatbot? ?? ??? ? ?? ? ??? ?? ?? ???? ?? ? ?? ?? ? ? ??? ??? ?? 19
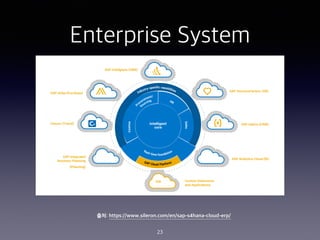
- 20. Chatbot ??? ?? ?? 20 ??: https://wiprodigital.com/2019/07/11/conversational-ai-and-chatbots-the-new-digital-frontier/ Channels Bot Engine Enterprise System
- 21. Channels 21
- 24. Chatbot ?? ?? ?? ?? 24 ??: https://www.cleveroad.com/blog/how-to-create-a-chatbot-for-business--step-by-step-guide-with-an-estimation
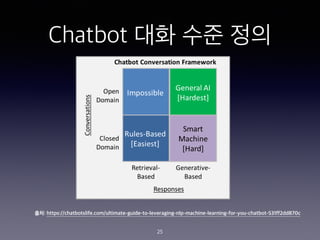
- 25. Chatbot ?? ?? ?? 25 ??: https://chatbotslife.com/ultimate-guide-to-leveraging-nlp-machine-learning-for-you-chatbot-531ff2dd870c
- 26. Chatbot ?? ?? ?? ? Intents: to convey purpose or goal ? Entities: make logical decisions based on user input ? Dialogs: design a conversation ? Slots: collect important information to fulfill an intent ? Digressions and Handlers: handle unexpected conversations. 26
- 27. Chatbot ?? ? ??? ? ? ?? (Hands-On) 27
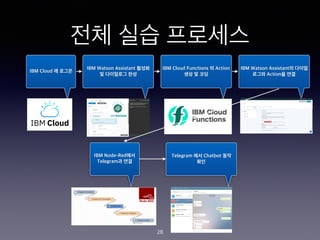
- 28. ?? ?? ???? IBM Cloud ? ??? IBM Watson Assistant ??? ? ????? ?? IBM Cloud Functions ? Action ?? ? ?? IBM Watson Assistant? ??? ??? Action? ?? IBM Node-Red?? Telegram? ?? Telegram ?? Chatbot ?? ?? 28
- 29. ?? ?? GitHub Repository 29 https://github.com/KyoYoon/ibm_watson_chatbot_lecture_basic
- 30. ??? ???? ??.. ? Chrome ???? ?? ? Gmail ?? ?? ? Google Colab ?? ? Telegram ???? ? ?? ? Bot ?? ? Open API ?? ? IBM ?? ?? ? IBM Cloud ?? ? ??? 30
- 32. Gmail ?? ?? 32
- 33. Google Colab ?? (1) 33
- 34. Google Colab ?? (2) 34
- 35. Telegram ???? ? ?? 35
- 36. Telegram ?? ? ??? 36
- 37. Telegram Bot ??? (1) 1. @BotFather ?? ? ?? 2. ???? ? BotFather ?? 37
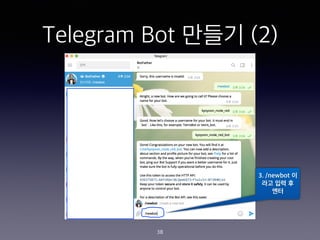
- 38. Telegram Bot ??? (2) 3. /newbot ? ?? ?? ? ?? 38
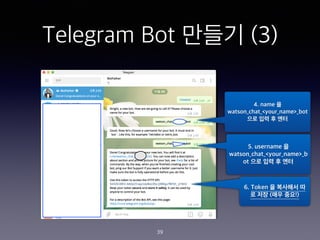
- 39. Telegram Bot ??? (3) 4. name ? watson_chat_<your_name>_bot ?? ?? ? ?? 5. username ? watson_chat_<your_name>_b ot ?? ?? ? ?? 6. Token ? ???? ? ? ?? (?? ??!) 39
- 40. Telegram Bot ??? (4) 7. @watson_chat_<your_name>_bot ?? ? ??? ? ??? ??? Bot ?? 40
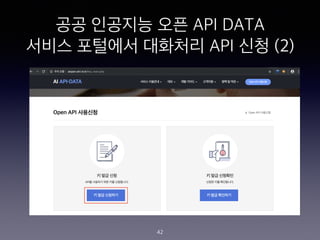
- 41. ?? ???? ?? API DATA ??? ???? ???? API ?? (1) 41
- 42. ?? ???? ?? API DATA ??? ???? ???? API ?? (2) 42
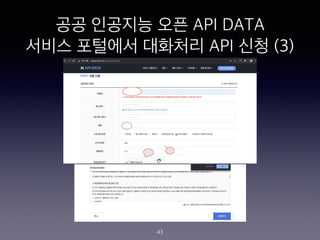
- 43. ?? ???? ?? API DATA ??? ???? ???? API ?? (3) 43
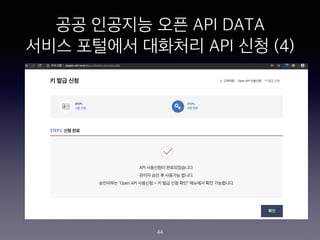
- 44. ?? ???? ?? API DATA ??? ???? ???? API ?? (4) 44
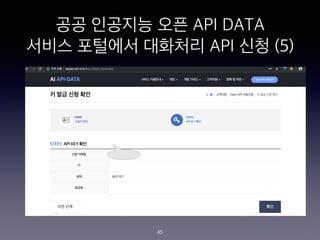
- 45. ?? ???? ?? API DATA ??? ???? ???? API ?? (5) 45
- 46. ?? ???? ?? API DATA ??? ???? ???? API ?? (6) ??? ?? ?????? ??? ?? ??? ??? ???? ?? ?? ? ?? ?? ???? ?? ? ??? ???? ?? ? ?? ? ???? ? 46
- 47. ?? ???? ?? API DATA ??? ???? ???? API ?? (7) 47
- 48. IBM ?? ?? (1) 48 https://www.ibm.com/kr-ko
- 49. IBM ?? ?? (2) 49
- 50. IBM ?? ?? (3) 50
- 51. IBM ?? ?? (4) 51
- 52. IBM ?? ?? (5) 52
- 53. IBM ?? ?? (6) 53
- 54. IBM ?? ?? (7) 54
- 55. IBM Cloud ??? ? ??? 1.?????? ??? ????? ?? ?? ? ?? ?? ?? IBM Cloud ?? ? ???? ???? IBM?? ???? ????? ?? ?? ????? ???? ?? ?? ? -> ??? ?? ? ??? ??? ?? ???? 55 https://cloud.ibm.com/
- 56. IBM Cloud ??? ? ??? 56 https://cloud.ibm.com/
- 57. IBM Cloud ??? ? ??? 57
- 58. IBM Cloud ??? ? ??? 58
- 59. IBM Cloud ??? ? ??? 59
- 60. IBM Cloud ??? ? ??? 60
- 61. IBM Cloud ??? ? ??? 61
- 62. IBM Cloud ??? ? ??? 62
- 63. IBM Cloud ??? ?? (??) 63
- 64. IBM Cloud ??? ?? (??) 64
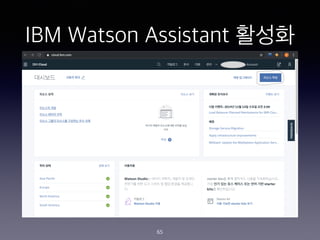
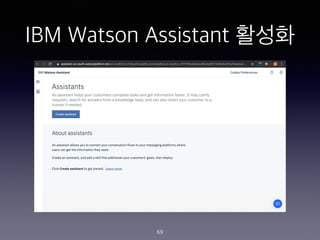
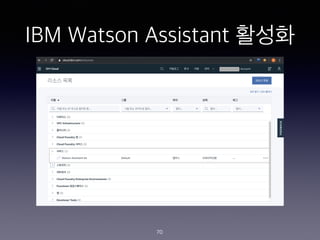
- 65. IBM Watson Assistant ??? 65
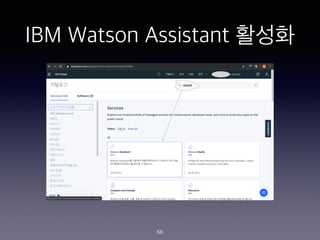
- 66. IBM Watson Assistant ??? 66
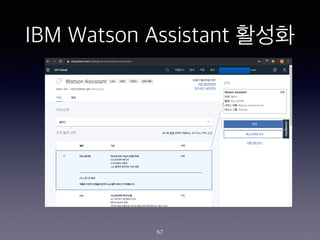
- 67. IBM Watson Assistant ??? 67
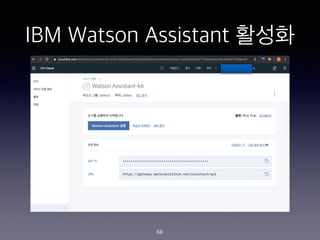
- 68. IBM Watson Assistant ??? 68
- 69. IBM Watson Assistant ??? 69
- 70. IBM Watson Assistant ??? 70
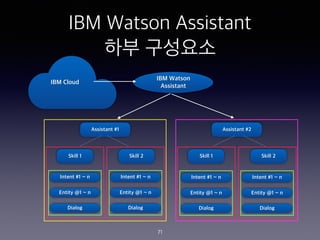
- 71. IBM Watson Assistant ?? ???? 71 IBM Watson Assistant IBM Cloud Assistant #1 Assistant #2 Skill 1 Skill 2 Skill 1 Skill 2 Intent #1 ~ n Entity @1 ~ n Dialog Intent #1 ~ n Entity @1 ~ n Dialog Intent #1 ~ n Entity @1 ~ n Dialog Intent #1 ~ n Entity @1 ~ n Dialog
- 72. ?? #1 72
- 73. ???? ?? ?? (??) 73 ???? ???? ?? ???? ?? ?? ? ????? ??? ?? ? 2?? ??? ??? ???? ??? ??
- 74. ???? ?? ?? (??) 74 ???? ??? ?? ?? ??? ???? ??, ??, ? ?? ?? ?? #1 ???? ?? ??? ??? ?? ??? ?? ?? #2 ˇ°??ˇ±??? ??? ??? ?? ??? ?? ?? #3 ˇ°??7?ˇ± ?? ??? ??? ?? ??? ?? ?? #4 ˇ°3?ˇ±? ?? ??? ??? ?? ?? ?? ??
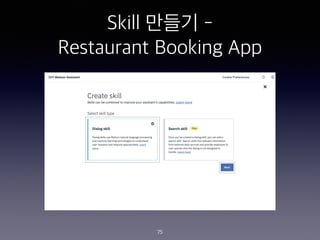
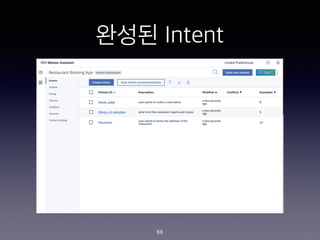
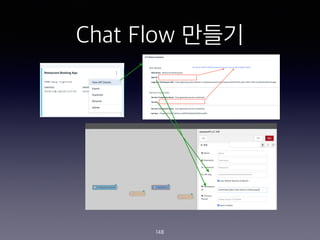
- 75. Skill ??? - Restaurant Booking App 75
- 76. Skill ??? - Restaurant Booking App 76
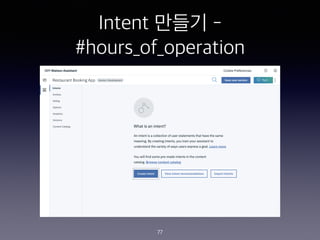
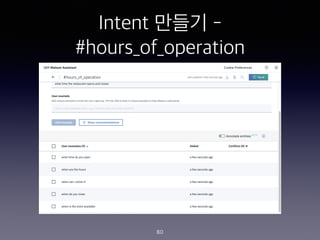
- 78. Intent ??? - #hours_of_operation 78 User examples what time do you open when are the hours when can I come in when do you close when is the store available
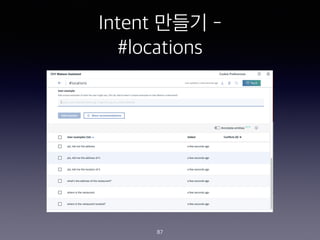
- 82. Intent ??? - #book_table 82 User examples Can I book a table for 4 people, at 7pm? can i book a table? Can I reserve a table for 10 people at 8pm? can I reserve a table? I'd like to book a table I'd like to book a table for 3 people, at 10am I'd like to reserve a table I'd like to reserve a table for 7 people, at 6pm
- 85. Intent ??? - #locations 85 User examples can you tell me where it is? can you tell me where the restaurant is? how can i get there? please, let me know the address of the restaurant please, let me know the location of the restaurant please, tell me the address of the restaurant please, tell me the location of the restaurant plz, let me know the address of it Where is the store at
- 86. Intent ??? - #locations 86 User examples plz, let me know the location plz, let me know the location of it plz, tell me the address plz, tell me the address of it plz, tell me the location of it what's the address of the restaurant? where is the restaurant where is the restaurant located? where is it
- 88. ??? Intent 88
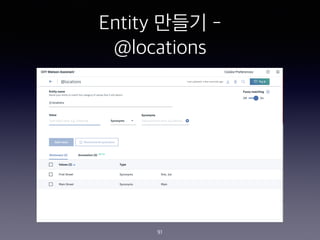
- 92. Entity ??? - System Entity 92
- 93. Dialog ??? ??ˇ 93 ??: https://cloud.ibm.com/docs/services/assistant?topic=assistant-dialog-overview#dialog-overview-variety
- 94. Dialog ??? (?? ??) 94
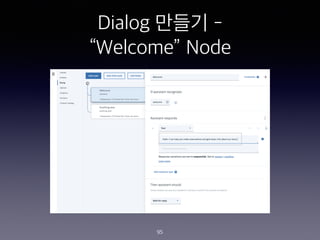
- 95. Dialog ??? - ˇ°Welcomeˇ± Node 95
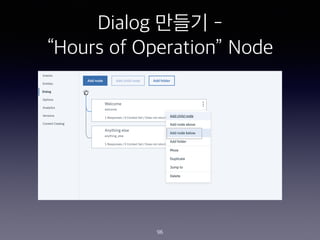
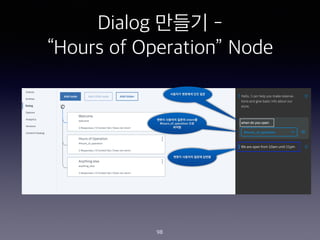
- 96. Dialog ??? - ˇ°Hours of Operationˇ± Node 96
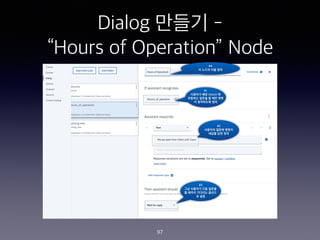
- 97. Dialog ??? - ˇ°Hours of Operationˇ± Node 97 #3 ?? ???? ?? ??? ? ??? ???? ??? ? ?? #1 ???? ?? Intent ? ???? ??? ? ?? ?? ? ????? ?? #2 ???? ??? ??? ??? ?? ?? #4 ? ??? ?? ??
- 98. Dialog ??? - ˇ°Hours of Operationˇ± Node 98 ???? ???? ?? ?? ??? ???? ??? ??? ??? ???? ??? intent? #hours_of_operation ?? ???
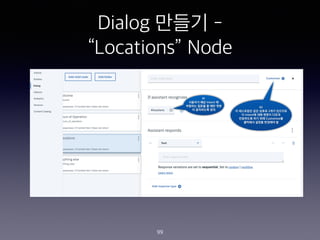
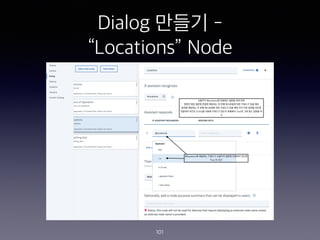
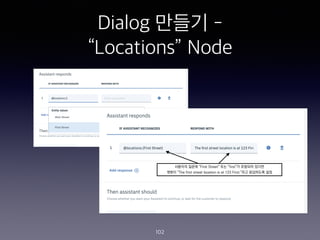
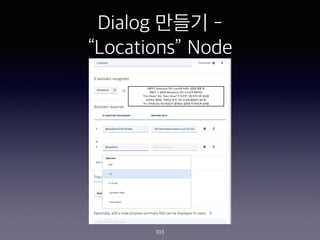
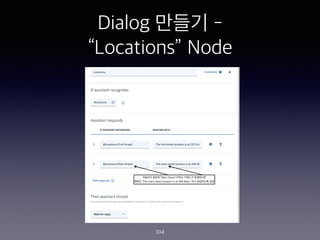
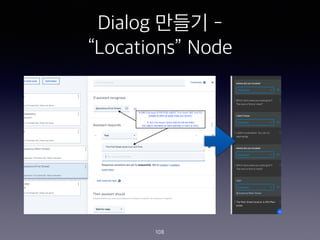
- 99. Dialog ??? - ˇ°Locationsˇ± Node 99 #1 ???? ?? Intent ? ???? ??? ? ?? ?? ? ????? ?? #2 ? ????? ?? ??? 2?? ???? ? Intent? ?? ??? ??? ????? ?? ?? Customize? ???? ??? ???? ?
- 100. Dialog ??? - ˇ°Locationsˇ± Node 100
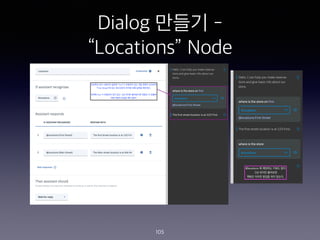
- 101. Dialog ??? - ˇ°Locationsˇ± Node 101
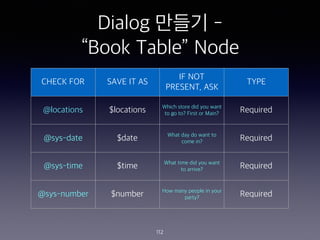
- 102. Dialog ??? - ˇ°Locationsˇ± Node 102
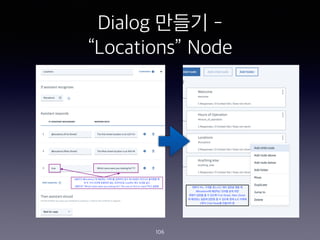
- 103. Dialog ??? - ˇ°Locationsˇ± Node 103
- 104. Dialog ??? - ˇ°Locationsˇ± Node 104
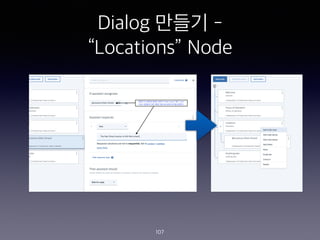
- 105. Dialog ??? - ˇ°Locationsˇ± Node 105
- 106. Dialog ??? - ˇ°Locationsˇ± Node 106
- 107. Dialog ??? - ˇ°Locationsˇ± Node 107
- 108. Dialog ??? - ˇ°Locationsˇ± Node 108
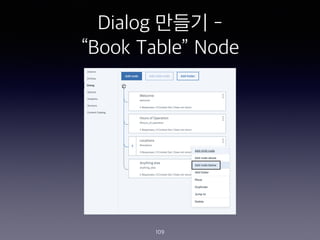
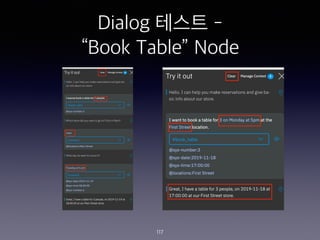
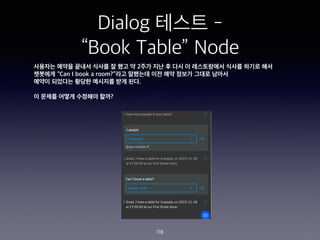
- 109. Dialog ??? - ˇ°Book Tableˇ± Node 109
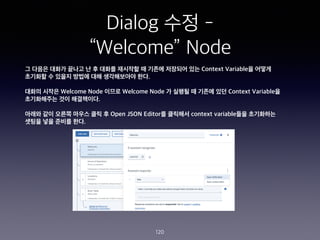
- 110. Dialog ??? - ˇ°Book Tableˇ± Node 110
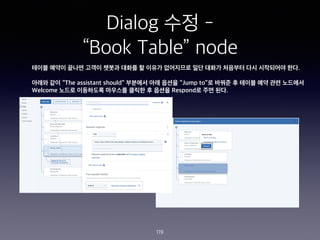
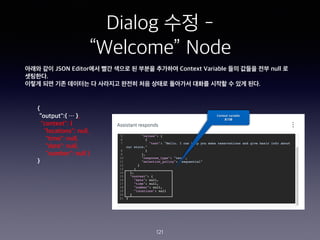
- 111. Dialog ??? - ˇ°Book Tableˇ± Node 111
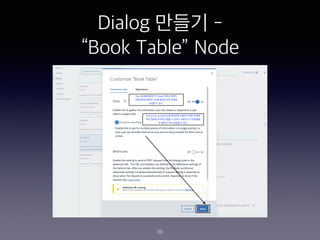
- 112. Dialog ??? - ˇ°Book Tableˇ± Node 112 CHECK FOR SAVE IT AS IF NOT PRESENT, ASK TYPE @locations $locations Which store did you want to go to? First or Main? Required @sys-date $date What day do want to come in? Required @sys-time $time What time did you want to arrive? Required @sys-number $number How many people in your party? Required
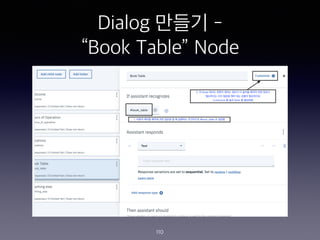
- 113. Dialog ??? - ˇ°Book Tableˇ± Node 113
- 114. Dialog ??? - ˇ°Book Tableˇ± Node 114
- 115. Dialog ??? - ˇ°Book Tableˇ± Node 115
- 116. Dialog ??? - ˇ°Book Tableˇ± Node 116
- 117. Dialog ??? - ˇ°Book Tableˇ± Node 117
- 118. Dialog ??? - ˇ°Book Tableˇ± Node 118 ???? ??? ??? ??? ? ?? ? 2?? ?? ? ?? ? ?????? ??? ??? ?? ???? ˇ°Can I book a room?ˇ±?? ???? ?? ?? ??? ??? ??? ??? ???? ??? ???? ?? ??. ? ??? ??? ???? ???
- 119. Dialog ?? - ˇ°Book Tableˇ± node 119 ??? ??? ??? ??? ??? ??? ? ??? ????? ?? ??? ???? ?? ????? ??. ??? ?? ˇ°The assistant shouldˇ± ???? ?? ??? ˇ°Jump toˇ±? ??? ? ??? ?? ?? ???? Welcome ??? ????? ???? ??? ? ??? Respond? ?? ??.
- 120. Dialog ?? - ˇ°Welcomeˇ± Node 120 ? ??? ??? ??? ? ? ??? ???? ? ??? ???? ?? Context Variable? ??? ???? ? ??? ??? ?? ?????? ??. ??? ??? Welcome Node ??? Welcome Node ? ??? ? ??? ?? Context Variable? ?????? ?? ?????. ??? ?? ??? ??? ?? ? Open JSON Editor? ???? context variable?? ????? ??? ?? ??? ??.
- 121. Dialog ?? - ˇ°Welcomeˇ± Node 121 { ˇ°output":{ ˇ }, "context": { "locations": null, "time": null, "date": null, "number": null } } ??? ?? JSON Editor?? ?? ??? ? ??? ???? Context Variable ?? ??? ?? null ? ????. ??? ?? ?? ???? ? ???? ??? ?? ??? ???? ??? ??? ? ?? ??. Context variable ???
- 122. Dialog ?? - ˇ°Welcomeˇ± Node 122 ??? ???? ? ??? ?? ??? ?? ??? Context Variable? ?? ?? null ? ??? ??.
- 123. Dialog ??? - ˇ°Book Tableˇ± Node 123 ??? ? ? ? ?? ???? ?? ?? ??? ?? ??? ???? ? ??? ??? ???? ? ?????? ?? ?? ??? ?? ?? ??? ??? ?? ?? ??? ??? ?? ??? ??? ???? ??.
- 124. Dialog ?? - ˇ°Welcomeˇ± Node 124 ??, Intent, Entity, Dialog ?? ????? ???? ?????? Node-Red? ?? ???? ???? ??? ????. ? ?? Welcome ??? ???? ??? ? ??? ????? ??? ??? ??? ˇ°/startˇ±?? ??? ????? ?? Watson Assistant ? ??? ???. ???, ?? ??? Entity? ?? ??? ? Entity? Welcome Node ? ?????? ??.
- 125. Dialog ?? - ˇ°Welcomeˇ± Node 125 ??? ?? telegram_start ?? ???? Entity? ?? ??? ??? ??? /start ? ?? ????.
- 126. Dialog ?? - ˇ°Welcomeˇ± Node 126 ??? ?? @telegram_start ? Welcome Node? ˇ°If assistant recognizesˇ± ??? or ???? ???? ????.
- 127. Node-Red ? ????? 127 IBM Cloud ??? ?? ?? ???????? ???? ???? ??? ?? ????? ??? ?? ?????? ?? ?? ???????? ? ? ??? ??? ????? ? https://nodered.org/
- 128. IBM Node-Red Starter Kit ?? 128
- 129. IBM Node-Red Starter Kit ?? 129
- 130. IBM Node-Red Starter Kit ?? 130
- 131. IBM Node-Red Starter Kit ?? 131
- 132. IBM Node-Red Starter Kit ?? 132
- 133. IBM Node-Red Starter Kit ?? 133
- 134. IBM Node-Red Starter Kit ?? 134
- 135. IBM Node-Red Starter Kit ?? 135
- 136. IBM Node-Red Starter Kit ?? 136
- 137. IBM Node-Red Starter Kit ?? 137
- 138. IBM Node-Red Starter Kit ?? 138
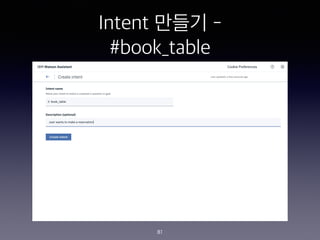
- 139. IBM Node-Red Starter Kit ?? 139
- 140. IBM Node-Red ??? 140
- 141. Node-Red ??? Node-Red: an open source logic engine that allows programmers of any level to easily write code that can connect to APIs, hardware, IoT devices or online services 141
- 142. Node-Red ??? 142
- 143. IBM Node-Red ? Telegram connector ?? 143
- 144. IBM Node-Red ? Telegram connector ?? 144
- 145. IBM Node-Red ? Telegram connector ???? 145
- 146. Chat Flow ??? 146
- 147. Chat Flow ??? 147
- 148. Chat Flow ??? 148
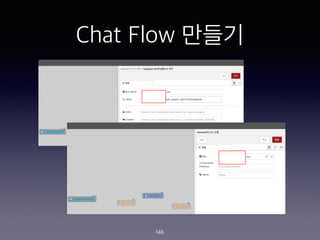
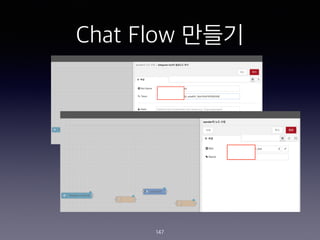
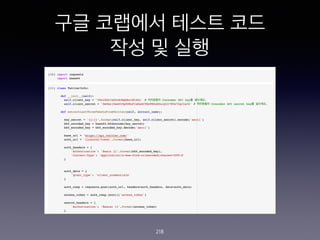
- 149. Chat Flow ??? 149 1st function - Prepare for Conversation <Source Code> msg.chatId = msg.payload.chatId; msg.payload = msg.payload.content; return msg;
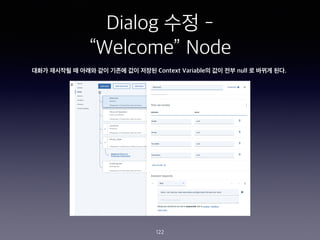
- 150. Chat Flow ??? 150 2nd function - Prepare for Telegram <Source Code> msg.payload = { chatId : msg.chatId, type : "message", content : msg.payload.output.text[0] }; return msg;
- 151. Chat Flow ?? 151
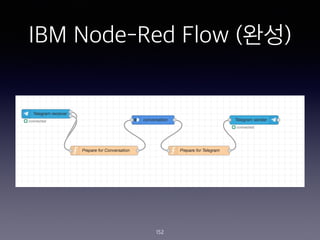
- 152. IBM Node-Red Flow (??) 152
- 153. Telegram ?? ?? ?? 153
- 154. IBM Cloud ??? ?? ?? 154
- 155. ?? #2 155
- 156. ?? QnA ?? (???) 156 ??? ??? ???? 605.2 km ????? ???? ???? 3? ?? ?? ?? ???? ?????(??? ?: Charles ˇ
- 157. ?? QnA ?? ???? ??.. ? ?? ?? ?????? ??? ?? ?? ???? ?? API DATA ??? ???? ??? API Key ? ?? ??? ?????? ?? ? ?? ???? ?? API DATA ??? ???? API ?? ?? ??? ???? ?? ? ?? (??? ? API? ??? ???) ? Google Colab(?? ??)?? ??? ? ??? ??? ?? ?? ? ?? ??? ?? ??? ??? ?? ???? ?? ? ?? API? ??? ? ?? ??? ?? ??? ???? ?? (Gmail ??? ????, ????? ??? JSON ???? ? ????? ??? ???? ??? Key? ???? Value? ?? ? ??? ????? ??? ??? ???? ????? ??? ? ??? ?) ? Cloud(????)? ???? ? ?? ???? ?? ??? ?? (??? IT ???? ???? ?? ????? ?? ?? ? ??? Auto Scailing ? ???? ??? ??? ??? ??) ? Web Hook ? Serverless Function ??? ?? ?? (??? ???? ??? ??? ? ? Watson Assistant? ??? ?? ?? ?? ???? ???? ??? ?? ????, IBM ???? ??? Serverless Function? ??? Action? ?? ? ?? Action?? ?? ???? ???? ???? ?? ? ?? Action? URL? Watson Assistant ?? ?? ?? Skill ? Web Hook?? ????? ??? ????? ???) 157
- 158. ?? ???? API Key ?? 158
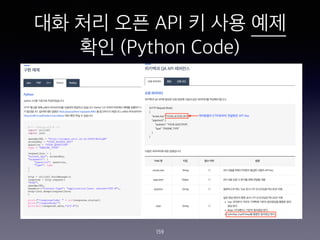
- 159. ?? ?? ?? API ? ?? ?? ?? (Python Code) 159
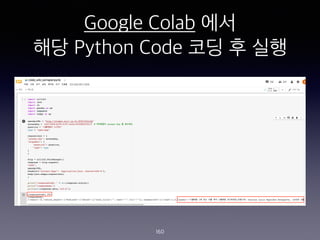
- 160. Google Colab ?? ?? Python Code ?? ? ?? 160
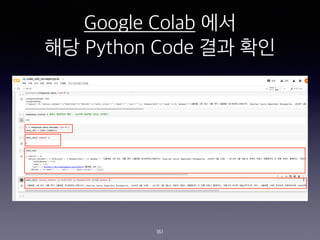
- 161. Google Colab ?? ?? Python Code ?? ?? 161
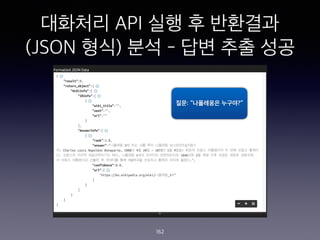
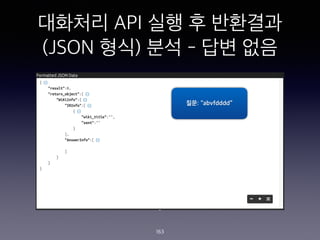
- 162. ???? API ?? ? ???? (JSON ??) ?? - ?? ?? ?? 162 ??: ˇ°????? ????ˇ±
- 163. ???? API ?? ? ???? (JSON ??) ?? - ?? ?? 163 ??: ˇ°abvfddddˇ±
- 164. ???? API ?? ? ???? (JSON ??) ?? - ?? ?? 164 ??: ˇ°#@!!! ????ˇ±
- 165. ???? API ?? ? ???? (JSON ??) ?? - ??? ?? 165 ??: ˇ°?? ????ˇ±
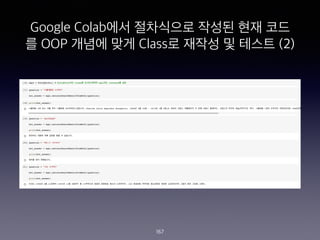
- 166. Google Colab?? ????? ??? ?? ?? ? OOP ??? ?? Class? ??? ? ??? (1) 166
- 167. Google Colab?? ????? ??? ?? ?? ? OOP ??? ?? Class? ??? ? ??? (2) 167
- 168. Cloud ? ?? 168 Cloud? ????, ?? ??? ?? ???? ?? ???? ???? ?? ???? ??? ? ??? ??? ??? ??? ?? ????, ?? ?? ??? ?? ??? ??? ??? ?? ???? ??? ???? ?? ? ??? ?? ??? ????. Cloud ??? ?? ??? ???? ???? IT ???, ??? ? ?????? ??? ??? ?? ?? ??? ? ?? ?? ?? ??? ? ? ??? ?? ??? ???? ????. Cloud? ????? ??? ???? ???? Cloud ??? ?? ??? ?? ? ??? ????? ??, ???? ???? ??? ????? ???? ??? ?? ??? ?? ???? ??? ???? ????? ?? ???? ?? ??, OS, Software?? ??? ? ??. ??: http://ccr.sigcomm.org/online/files/p50-v39n1l-vaqueroA.pdf
- 169. Cloud ? ?? 169 ??: https://www.journaldev.com/25061/cloud-computing
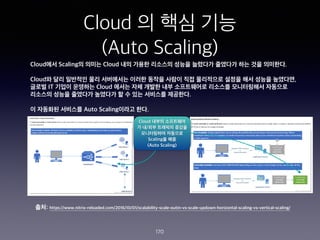
- 170. Cloud ? ?? ?? (Auto Scaling) 170 Cloud?? Scaling? ??? Cloud ?? ??? ???? ??? ???? ???? ?? ?? ????. Cloud? ?? ???? ?? ????? ??? ??? ??? ?? ????? ??? ?? ??? ????, ??? IT ??? ???? Cloud ??? ?? ??? ?? ?????? ???? ?????? ???? ???? ??? ???? ???? ? ? ?? ???? ????. ? ???? ???? Auto Scaling??? ??. Cloud ??? ????? ? ?/?? ???? ??? ?????? ???? Scaling? ?? (Auto Scaling) ??: https://www.nitrix-reloaded.com/2016/10/01/scalability-scale-outin-vs-scale-updown-horizontal-scaling-vs-vertical-scaling/
- 171. Web Hook & Serverless Function in Chatbot 171 Webhook? ???? ??? ??? ?? ??? ? ?? ??? ?????? HTTP POST? ??? ????, Webhook? ??? ? ???????, ?? ??? ??? ? URL? ?? POST???? ??? ????. ?? ???? ?? ??? ??? ???? ???? ??? ???? Webhook? ??? ??????? URL? ??? ? ??? ?? ?? IBM Cloud ?? Skill ?? Webhook URL? ??? ? ?? Node ?? Webhook? ????? Webhook? ?? ?? ???? ???? ???? ??? ? ??? ?? ??. Serverless Function ? ?? ????? ??? ??? ?? Function? ??? ? ?? ???? ??? ??? Function? ??? ? ???? ???? ???? ??? ???? ?? Function? ??? ? ???? ??? ? ??? ??? ??? ???? ??? ??? ????? ????? ?? ??? ??? ???? ??? ?? ??? ? ??? ?? ???? ??. IBM Cloud ??? IBM Cloud Function ??? ???? Serverless Function? ???? ????? ?? ?? ?? ??? ?? ???? ????? ???? ??? ??? ?? ??? API? ?? ???? ???? ??? ? ?? ? ??? ??? ?? ???? ???? ?? IBM Cloud Function??. IBM Cloud Function ??? ?? ??? ???? ??? Action??? ?? ? Action ??? ????? ??? ?? ?? ??? ?? ??? ?? ? ?? ? Action ??? URL? ??? ??? ?? IBM Watson Assistant ? Skill ?? Webhook ? ? URL? ??? ?? ??? ?? ??? ?? ?? Action? ???? ? ??.
- 172. IBM Cloud Function ?? Action ??? 172
- 173. IBM Cloud Function ?? Action ??? 173
- 174. IBM Cloud Function ?? Action ??? 174
- 175. IBM Cloud Function ?? Action ??? 175
- 176. IBM Cloud Function ?? Action ??? 176
- 177. IBM Cloud Function ?? Action ??? 177
- 178. IBM Cloud Function ?? Action ??? 178
- 179. IBM Cloud Function ?? Action ??? 179
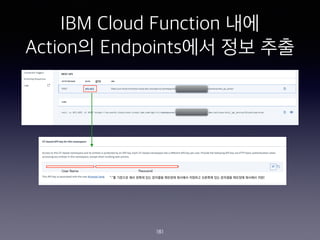
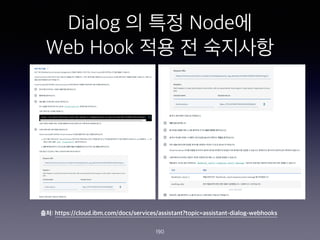
- 180. IBM Cloud Function ?? Action? Endpoints?? ?? ?? 180
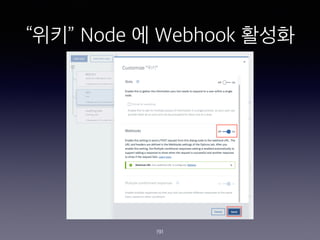
- 181. IBM Cloud Function ?? Action? Endpoints?? ?? ?? 181
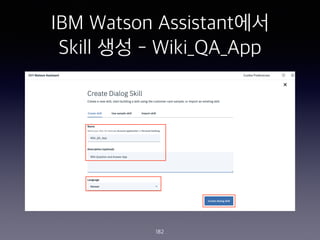
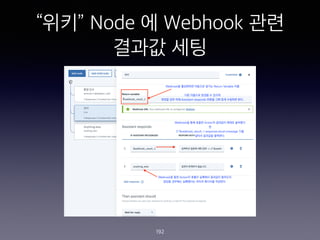
- 182. IBM Watson Assistant?? Skill ?? - Wiki_QA_App 182
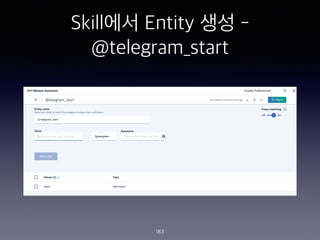
- 183. Skill?? Entity ?? - @telegram_start 183
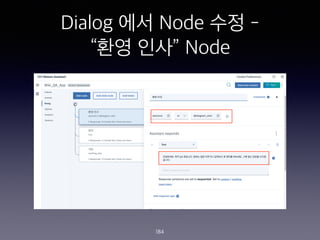
- 184. Dialog ?? Node ?? - ˇ°?? ??ˇ± Node 184
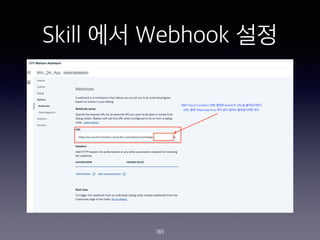
- 185. Skill ?? Webhook ?? 185
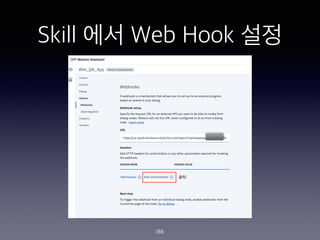
- 186. Skill ?? Web Hook ?? 186
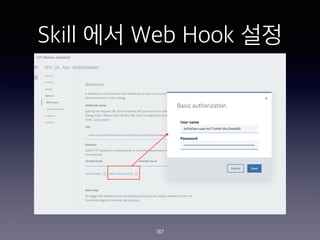
- 187. Skill ?? Web Hook ?? 187
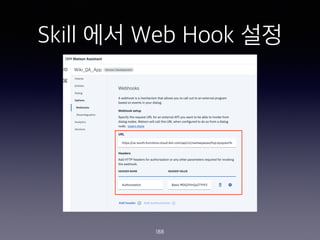
- 188. Skill ?? Web Hook ?? 188
- 189. Dialog ?? Node ?? - ˇ°??ˇ± Node ? ?? ???? ?? 189
- 190. Dialog ? ?? Node? Web Hook ?? ? ???? 190 ??: https://cloud.ibm.com/docs/services/assistant?topic=assistant-dialog-webhooks
- 191. ˇ°??ˇ± Node ? Webhook ??? 191
- 192. ˇ°??ˇ± Node ? Webhook ?? ??? ?? 192
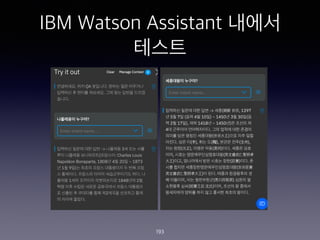
- 193. IBM Watson Assistant ??? ??? 193
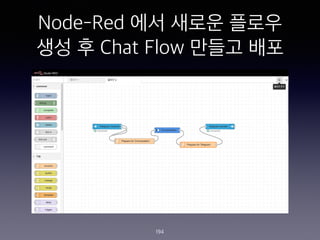
- 194. Node-Red ?? ??? ??? ?? ? Chat Flow ??? ?? 194
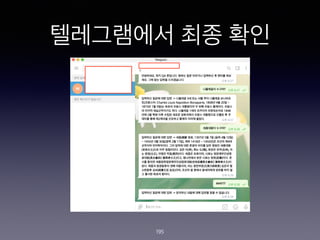
- 195. ?????? ?? ?? 195
- 196. ?? #3 196
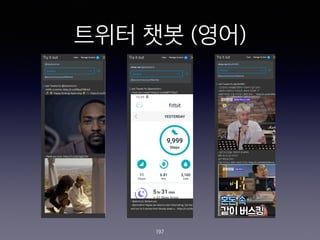
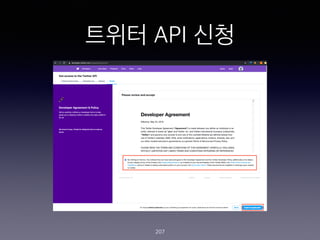
- 197. ??? ?? (??) 197
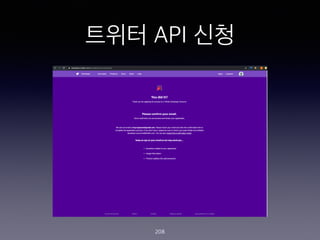
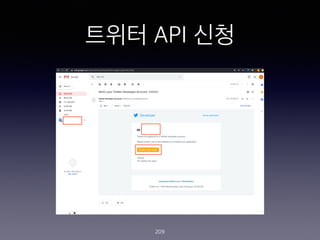
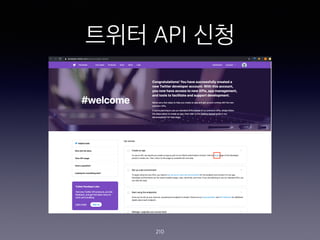
- 198. ??? ?? ???? ??.. ? ?? ??? (https://twitter.com/ )? ???? ???? ?? ? (??? ??? ????? ?? ???? ?) ? ??? API? ???? ?? ??? ??? ???(https:// developer.twitter.com/en/apply-for-access.html )? ???? ??? ???? ???? ? ??? ?? ?? ??? ???? ??? ? ? ??? ??? ??? ?? ??? ? ??? ??? ?? ? ??? ?? ? ?? Consumer key (API key), Consumer Secret (API Secret), Access Token, and Access Token Secret ? 4?? ?? ? ? ?? ? ??? ?? ? ?? ???? ???? ?? ??? ???? ? ?? ???? ? ??? ??? ??? ??? ? ???? ??? ?? ? ????? ?? 198
- 199. ??? ???? 199
- 200. ??? ???? 200
- 201. ??? ??? ??? ?? 201
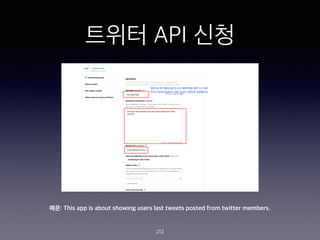
- 202. ??? API ?? 202
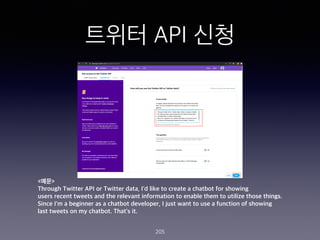
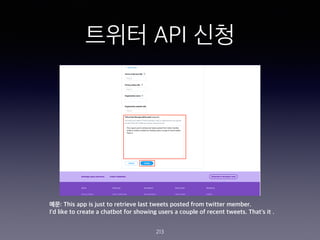
- 203. ??? API ?? 203
- 204. ??? API ?? 204
- 205. ??? API ?? 205 <??> Through Twitter API or Twitter data, I'd like to create a chatbot for showing users recent tweets and the relevant information to enable them to utilize those things. Since I'm a beginner as a chatbot developer, I just want to use a function of showing last tweets on my chatbot. That's it.
- 206. ??? API ?? 206
- 207. ??? API ?? 207
- 208. ??? API ?? 208
- 209. ??? API ?? 209
- 210. ??? API ?? 210
- 211. ??? API ?? 211
- 212. ??? API ?? 212 ??: This app is about showing users last tweets posted from twitter members.
- 213. ??? API ?? 213 ??: This app is just to retrieve last tweets posted from twitter member. I'd like to create a chatbot for showing users a couple of recent tweets. That's it .
- 214. ??? API ?? 214
- 215. ??? API ?? 215
- 216. ??? API ?? 216
- 217. ??? API ?? 217
- 218. ?? ???? ??? ?? ?? ? ?? 218
- 219. ?? ???? ??? ?? ?? ? ?? 219
- 220. IBM Cloud Function ?? Action ??? 220
- 221. IBM Cloud Function ?? Action ??? 221
- 222. IBM Cloud Function ?? Action ??? 222
- 223. IBM Cloud Function ?? Action ??? 223
- 224. IBM Cloud Function ?? Action ??? 224
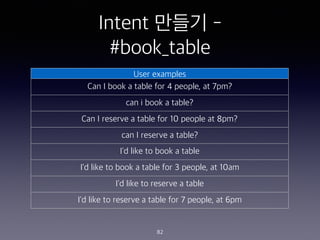
- 225. IBM Cloud Function ?? Action ??? 225
- 226. IBM Cloud Function ?? Action ??? 226
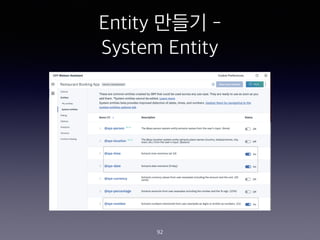
- 227. IBM Cloud Function ?? Action ??? 227 Parameter Name: account Parameter Value: ˇ°@withMBCˇ±
- 228. IBM Cloud Function ?? Action ??? 228
- 229. IBM Watson Assistant?? Skill ?? - Show_Last_Three_Tweets_App 229
- 230. Skill?? Intent ?? - #twitter 230
- 231. Skill?? Intent ?? - #twitter 231
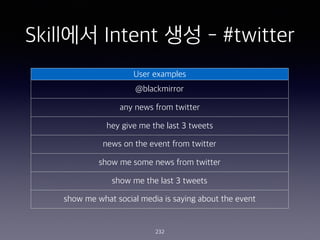
- 232. Skill?? Intent ?? - #twitter 232 User examples @blackmirror any news from twitter hey give me the last 3 tweets news on the event from twitter show me some news from twitter show me the last 3 tweets show me what social media is saying about the event
- 233. Skill?? Intent ?? - #twitter 233 User examples some tweets twitter @account twitter messages twitts please what people is saying about the show what people is saying on twitter what the social media is telling about the event ?
- 234. Skill?? Intent ?? - #twitter 234
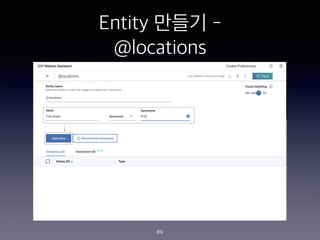
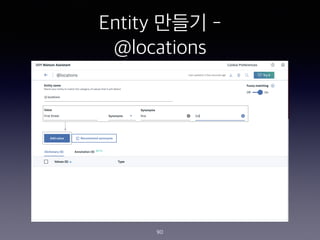
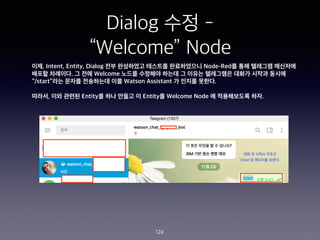
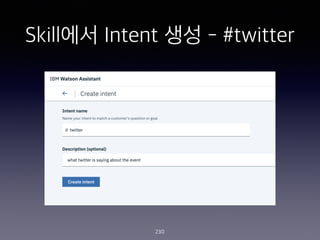
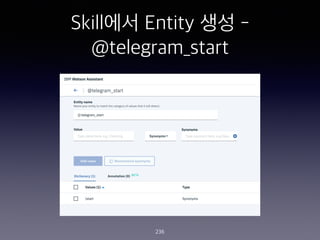
- 235. Skill?? Entity ?? - @account 235 accountNames / Patterns / @([A-Za-z0-9_]+)
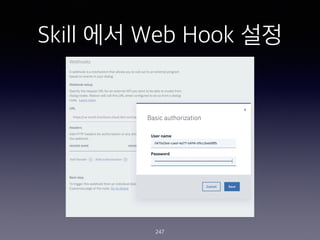
- 236. Skill?? Entity ?? - @telegram_start 236
- 237. Skill?? System Entity ?? 237
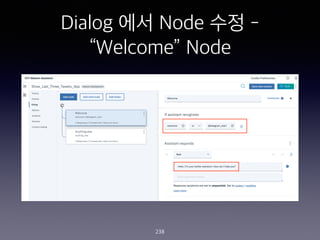
- 238. Dialog ?? Node ?? - ˇ°Welcomeˇ± Node 238
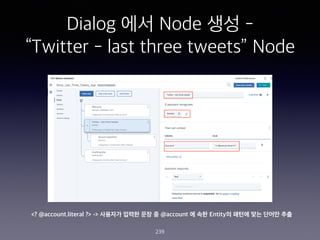
- 239. Dialog ?? Node ?? - ˇ°Twitter - last three tweetsˇ± Node 239 <? @account.literal ?> -> ???? ??? ?? ? @account ? ?? Entity? ??? ?? ??? ??
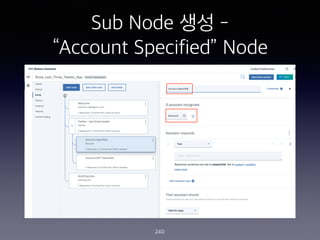
- 240. Sub Node ?? - ˇ°Account Specifiedˇ± Node 240
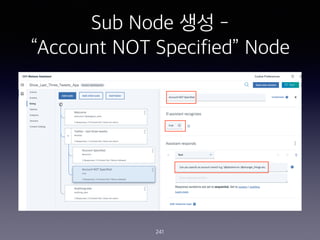
- 241. Sub Node ?? - ˇ°Account NOT Specifiedˇ± Node 241
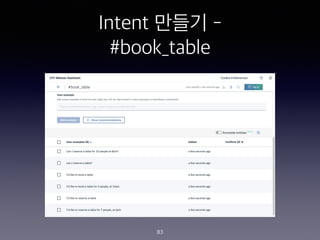
- 242. ˇ°Twitter - last three tweetsˇ± Node ?? 242
- 243. ˇ°Twitter - last three tweetsˇ± Node ???? 243
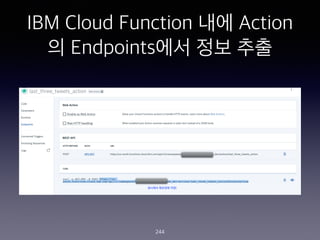
- 244. IBM Cloud Function ?? Action ? Endpoints?? ?? ?? 244
- 245. IBM Cloud Function ?? Action ? Endpoints?? ?? ?? 245
- 246. Skill ?? Web Hook ?? 246
- 247. Skill ?? Web Hook ?? 247
- 248. Skill ?? Web Hook ???? 248
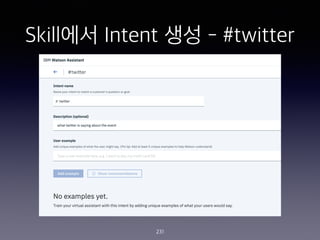
- 249. ˇ°Account Specifiedˇ± Node? Web Hook ??? 249
- 250. ˇ°Account Specifiedˇ± Node?? Web Hook? ?? ???? ?? 250
- 251. Skill Refresh ? Webhook ??? ?? 251
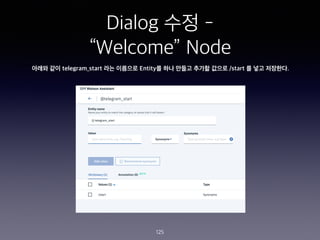
- 252. ˇ°Account Specifiedˇ± Node? Web Hook ???? ?? 252 1. Web Hook ??? ????? ??? ?? Last Tweets for $account:<br> - <? $webhook_result_1.response.result.message[0] ?> <br> - <? $webhook_result_1.response.result.message[1] ?><br> - <? $webhook_result_1.response.result.message[2] ?> 2. Web Hook ??? ???? ?? I couldn't find the account - please try again with e.g. @blackmirror @stranger_things
- 253. ?? ?? ?? ?? 253
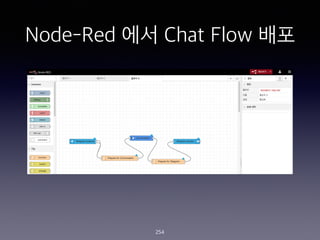
- 254. Node-Red ?? Chat Flow ?? 254
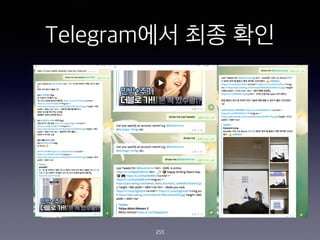
- 255. Telegram?? ?? ?? 255
- 256. Reference (1) ? https://medium.com/swlh/what-is-a-chatbot-and-how-to-use- it-for-your-business-976ec2e0a99f ? https://www.digitaldoughnut.com/articles/2019/april/the-five- types-of-chatbot-use-for-businesses ? https://developer.ibm.com/recipes/tutorials/how-to-create-a- watson-chatbot-on-nodered/ ? https://medium.com/ibm-watson/chatting-with-watson-to- hook-any-tweets-webhook-tutorial-bf0fac67d604 ? https://www.entrepreneur.com/article/337430 256
- 257. Reference (2) ? https://medium.com/ibm-garage/designing-a-chatbot- with-ibm-watson-assistant-7e11b94c2b3d ? https://developer.ibm.com/events/how-to-build-your- own-chatbot/ ? https://medium.com/deep-math-machine-learning-ai/ chapter-11-chatbots-to-question-answer-systems- e06c648ac22a ? https://chatbotslife.com/ultimate-guide-to-leveraging- nlp-machine-learning-for-you-chatbot-531ff2dd870c 257
- 258. Reference (3) ? https://brunch.co.kr/@dol74/142 ? /alexglee/ai-chatbot-191433017? fbclid=IwAR2CsBwwaqN- K1Tg7S_NtGBaJEkMouRoKvNXE0KHWDr0KPepFgpgM3askaE ? https://medium.com/landbot-io/creating-conversational-experiences-ii-build- and-design-20ac88d7ee72 ? https://developer.ibm.com/kr/watson/2017/01/13/watsonchatbot-1-watson- conversation/ ? https://developer.ibm.com/kr/watson/watson-service/2017/02/26/watson- conversation-ui-%ed%88%b4-%ec%82%ac%ec%9a%a9%eb%b2%95/ ? https://cloud.ibm.com/docs/services/assistant?topic=assistant-dialog- overview#dialog-overview-variety 258
- 259. Reference (4) ? https://www.youtube.com/watch?v=OPdOCUPGMIQ ? https://www.youtube.com/watch?v=o-uhdw6bIyI ? https://www.youtube.com/watch?v=XkhAMe9gSFU ? https://developer.ibm.com/answers/questions/390108/how-can-i- restart-a-conversation-which-clears-all/ ? https://discourse.nodered.org/t/node-red-telegram-polling-error/ 16765/8 ? http://blog.drakejin.me/Serverless-1/ ? https://union.parti.xyz/posts/22676 259
- 260. Thank You! 260