Inspection of CloudML Hyper Parameter Tuning
12 likes2,366 views

GCPUG Fukuoka 5th ?Machine Learning ╝└? ż╬░k▒Ē┘Y┴Ž
1 of 55
Downloaded 13 times












![īg“Y1
? Hyper Parameter
? 1ēõ╩²(x), 2ēõ╩²(x, y)
? ╣ĀćņżŽ╚½żŲ [-1, 1]
? ūŅ?éÄż“Ū¾żßżļ
? ╠Į╦„╗ž╩²(N)żŽ
? 1ēõ╩² Ī· N=10 or 15
? 2ēõ╩² Ī· N=30](https://image.slidesharecdn.com/inspectionofcloudmlhyperparametertuning-170128080952/85/Inspection-of-CloudML-Hyper-Parameter-Tuning-25-320.jpg)







![īg“Y2
? īg“Y1ż╚═¼żĖF(x)ż╦īØżĘżŲ Bayesian Optimization
? ūŅ│§ż╬3ĄŃżŽīg“Y1ż╬(Cloud MLż╬)ĮY╣¹ż“┴„??
(Bayesian Optimization żŽ│§Ų┌║╬ĄŃż½żŽźķź¾ź└źÓ╠Į╦„)
? Pythonż╬BayesianOptimizationźčź├ź▒®`źĖż“└¹??
[https://github.com/fmfn/BayesianOptimization]
? Acquisition function ż╦żŽ GP-UCB, kappa=0.5 ż“▀xÆk](https://image.slidesharecdn.com/inspectionofcloudmlhyperparametertuning-170128080952/85/Inspection-of-CloudML-Hyper-Parameter-Tuning-44-320.jpg)


Ad
Recommended
ż▄ż»ż╬īgū░żĘż┐ūŅ╚§ż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░
ż▄ż»ż╬īgū░żĘż┐ūŅ╚§ż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░ż╩ż¬żŁ żŁżĘż└
?
ūŅĮ³┴„ąąż╬źŪźŻ®`źūźķ®`ź╦ź¾ź░ż“īgū░żĘżŲ╗ŁŽ±╚Ž╩ȿʿĶż”ż╚żĘż┐ż▒ż╔ż╩ż½ż╩ż½ż”ż▐ż»č¦Ž░żĘżŲż»żņż╩żż╗░ż“żĘżĶż”ż╚╦╝ż├ż┐ż╬ż└ż▒ż╔Īóż╔ż”żõżķż”ż▐ż»żżżŁ╩╝żßż┐żĶż”żŪż╣ĪŻąį─▄£yČ©Ą└ īg╝∙ŠÄ
ąį─▄£yČ©Ą└ īg╝∙ŠÄYuto Hayamizu
?
2014/2/1ż╦ķ_┤▀żĄżņż┐╚š▒ŠPostgreSQLźµ®`źČ╗ß Ą┌27╗žżĘż»ż▀Ż½źóźūźĻź▒®`źĘźńź¾├ŃÅŖ╗ßżŪż╬ųvč▌żŪż╣ĪŻ
http://www.postgresql.jp/wg/shikumi/shikumi28╚š▒Š╔±ĮU╗ž┬Ęč¦╗ßź╗ź▀ź╩®`ĪĖČ┘▒▒▒Ķ│ó▒▓╣░∙▓įŠ▒▓į▓Ąż“╩╣ż├żŲż▀żĶż”ŻĪĪ╣ū╩┴Ž
╚š▒Š╔±ĮU╗ž┬Ęč¦╗ßź╗ź▀ź╩®`ĪĖČ┘▒▒▒Ķ│ó▒▓╣░∙▓įŠ▒▓į▓Ąż“╩╣ż├żŲż▀żĶż”ŻĪĪ╣ū╩┴ŽKenta Oono
?
╚š▒Š╔±ĮU╗ž┬Ęč¦╗ßź╗ź▀ź╩®`ĪĖČ┘▒▒▒Ķ│ó▒▓╣░∙▓įŠ▒▓į▓Ąż“╩╣ż├żŲż▀żĶż”ŻĪĪ╣ż╬┤¾ż╬ĄŻĄ▒Ęųż╬ū╩┴ŽżŪż╣ĪŻ2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├
2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├ Kenta Oono
?
GTC Japan 2015żŪż╬░k▒Ē┘Y┴Ž (Session ID:2015 - 1014)ChainerżŪDeep Learningż“įćż╣ż┐żßż╦▒žę¬ż╩ż│ż╚
ChainerżŪDeep Learningż“įćż╣ż┐żßż╦▒žę¬ż╩ż│ż╚Retrieva inc.
?
2016/12/21 dots.DeepLearning▓┐ĪĖ╩²╩Įż¼ż’ż½żķż╩ż»ż┐ż├żŲDeep Learningżõż├żŲż▀ż┐żżŻĪ╚╦╝»║Ž- dots. DeepLearning▓┐ ░kūŃŻĪĪ╣żŪųvč▌żĘż┐┘Y┴ŽżŪż╣ĪŻąį─▄£yČ©Ą└ ╩┬╩╝żßŠÄ
ąį─▄£yČ©Ą└ ╩┬╩╝żßŠÄYuto Hayamizu
?
2013/10/05ż╦ķ_┤▀żĄżņż┐╚š▒ŠPostgreSQLźµ®`źČ╗ß Ą┌27╗žżĘż»ż▀Ż½źóźūźĻź▒®`źĘźńź¾├ŃÅŖ╗ßżŪż╬ųvč▌żŪż╣ĪŻ
http://www.postgresql.jp/wg/shikumi/shikumi27
----
ź│ź¾źįźÕ®`ź┐źĘź╣źŲźÓż╦ż¬ż▒żļąį─▄£yČ©ż╚żŽĪó╝╝▄┐żŪż╣ĪŻ
ąį─▄£yČ©ż╚żżż”ż╚Īóģgż╦£yČ©ź─®`źļż“īgąąż╣żļż└ż▒ż╬ū„śIż└ż╚┐╝ż©żķżņż¼ż┴żŪż╣ĪŻżĘż½żĘīgļHż╦żŽĪó║╬ż╬ż┐żßż╦£yČ©ż“ż╣żļż╬ż½ĪóżĮż╬ż┐żßż╦║╬ż“£yČ©ż╣żļż┘żŁż½ĪóżĮżĘżŲ║╬ż“╩╣ż├żŲ£yČ©ż╣żļż┘żŁż½ż“└ĒĮŌżĘż┐╔ŽżŪąąż’ż╩ż▒żņżą╚½ż»ęŌ╬Čż“│╔żĄż╩żżĪó╔Ņż▀ż╬żóżļ╝╝▄┐ż╬╩└ĮńżŪż╣ĪŻ
ųvč▌š▀ż╬╦∙╩¶ż╣żļ蹊┐╩ężŪżŽķL─Ļż╦ż’ż┐żĻźŪ®`ź┐ź┘®`ź╣źĘź╣źŲźÓż╬蹊┐?ķ_░kż“ąąż├żŲżŁż▐żĘż┐ĪŻżĮż╬▀^│╠żŪ┼Óż’żņż┐ąį─▄£yČ©ż╬╝╝▄┐ż╦ż─żżżŲĪóūŅĮ³ż╬īg└²żŌĮ╗ż©ż─ż─żĮż╬┐╝ż©ĘĮż“ż┤ĮBĮķżĘż┐żżż╚╦╝żżż▐ż╣ĪŻźŪźŻ®`źūźķ®`ź╦ź¾ź░ūŅĮ³ż╬░kš╣ż╚źėźĖź═ź╣ÅĻė├żžż╬┐╬╠Ō
źŪźŻ®`źūźķ®`ź╦ź¾ź░ūŅĮ³ż╬░kš╣ż╚źėźĖź═ź╣ÅĻė├żžż╬┐╬╠ŌKenta Oono
?
2015─Ļ5į┬26╚šĪóź©ź╠źėźŪźŻźóśöų„┤▀ĪĖźŪźŻ®`źūźķ®`ź╦ź¾ź░źšź®®`źķźÓ2015Ī╣żŪż╬Preferred Networksż╬ųvč▌┘Y┴ŽżŪż╣
http://www.gdep.jp/page/view/412░Ł▓╣▓Ą▓Ą▒¶▒ż╬źŲź»ź╦ź├ź»
░Ł▓╣▓Ą▓Ą▒¶▒ż╬źŲź»ź╦ź├ź»Yasunori Ozaki
?
░Ł▓╣▓Ą▓Ą▒¶▒ż╬żóżļź│ź¾źŲź¾ź╣ź╚ż╬ė┼╩żš▀ż¼ū„ż├ż┐źŌźŪźļż“ź▒®`ź╣ź╣ź┐źŪźŻż╚żĘżŲĪó░ņ▓╣▓Ą▓Ą▒¶▒źŲź»ź╦ź├ź»ż“ĮŌšhżĘż▐ż╣ĪŻ╠žż╦│¦│┘▓╣│”░ņŠ▒▓į▓Ąż“ųąą─ż╦ĮŌšhżĘżŲżżż▐ż╣ĪŻ░õ▒Ę▒Ęż╦żŽżóż©żŲ┤źżņż▐ż╗ż¾żŪżĘż┐ĪŻż▐ż┐Īó│┘-│¦▒ĘĘĪżõ│µ▓Ą▓·┤Ū┤Ū▓§│┘ż╬Ė┼┬įż╦żŌ┤źżņż▐żĘż┐ĪŻMicrosoft Malware Classification Challenge ╔Ž╬╗╩ųĘ©ż╬ĮBĮķ (in Kaggle Study Meetup)
Microsoft Malware Classification Challenge ╔Ž╬╗╩ųĘ©ż╬ĮBĮķ (in Kaggle Study Meetup)Shotaro Sano
?
2015─Ļż╦ķ_┤▀żĄżņż┐ÖCąĄč¦┴Ģź│ź¾ź┌źŲźŻźĘźńź¾Ż©Microsoft Malware Classification ChallengeŻ®ż╦ż¬ż▒żļ╔Ž╬╗╩ųĘ©żõā×ä┘źŌźŪźļż╦ż─żżżŲż╬ĮŌšhĪŻż│ż┴żķż╬ź▀®`ź╚źóź├źūżŪ░k▒ĒżĄż╗żŲżżż┐ż└żŁż▐żĘż┐Ż║ http://connpass.com/event/25007/ Chainer ż╬ Trainer ĮŌšhż╚ NStepLSTM ż╦ż─żżżŲ
Chainer ż╬ Trainer ĮŌšhż╚ NStepLSTM ż╦ż─żżżŲRetrieva inc.
?
źņź╚źĻźąź╗ź▀ź╩®` 2017/03/15
Movie: https://www.youtube.com/watch?v=ok_bvPKAEaMKaggle▓╬╝ėł¾Ėµ: Champs Predicting Molecular Properties
Kaggle▓╬╝ėł¾Ėµ: Champs Predicting Molecular PropertiesKazuki Fujikawa
?
Kaggleź│ź¾ź┌źŲźŻźĘźńź¾ĪĖPredicting Molecular PropertiesĪ╣żŪ13╬╗ż╦ż╩ż├ż┐Ģrż╬ĮŌĘ©ż╬ĮBĮķż╚Īó╔Ž╬╗źĮźĻźÕ®`źĘźńź¾ż╬ĮBĮķżŪż╣ĪŻ░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├
░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├Seiya Tokui
?
Ą┌10╗ž NLP╚¶╩ųż╬╗ߟʟ¾ź▌źĖź”źÓ (YANS) ż╬ź┴źÕ®`ź╚źĻźóźļź╣źķźżź╔żŪż╣ĪŻź╦źÕ®`źķźļź═ź├ź╚ż╬Ż©źóźļź┤źĻź║źÓż╚żĘżŲż╬Ż®ż¬żĄżķżżż╚ĪóChainer v1.3.0ż╬╩╣żżĘĮż“ĮBĮķżĘżŲżżż▐ż╣ĪŻĄ┌3╗ž╗·ąĄč¦Ž░├ŃŪ┐╗ßĪĖ╔½Ī®ż╩▒Ę▒Ęźšźņ®`źÓź’®`ź»ż“Č»ż½żĘżŲż▀żĶż”Ī╣-░Ł▒░∙▓╣▓§▒Ó-
Ą┌3╗ž╗·ąĄč¦Ž░├ŃŪ┐╗ßĪĖ╔½Ī®ż╩▒Ę▒Ęźšźņ®`źÓź’®`ź»ż“Č»ż½żĘżŲż▀żĶż”Ī╣-░Ł▒░∙▓╣▓§▒Ó-Yasuyuki Sugai
?
2016─Ļ6į┬Ų┌AITCź¬®`źūź¾źķź▄
Ą┌3╗ž ÖCąĄč¦┴Ģ├ŃÅŖ╗ß ĪĖ╔½Ī®ż╩ź╦źÕ®`źķźļ?ź═ź├ź╚ź’®`ź»ż╬źšźņ®`źÓź’®`ź»ż“äėż½żĘżŲż▀żĶż”ŻĪĪ╣ KerasŠÄ┘Y┴Ž2015-11-17 żŁż┴ż¾ż╚ų¬żĻż┐żżApache Spark Ī½ÖCąĄč¦┴Ģż╚żĄż▐żČż▐ż╩ÖC─▄╚║
2015-11-17 żŁż┴ż¾ż╚ų¬żĻż┐żżApache Spark Ī½ÖCąĄč¦┴Ģż╚żĄż▐żČż▐ż╩ÖC─▄╚║Yu Ishikawa
?
2015-11-17 żŁż┴ż¾ż╚ų¬żĻż┐żżApache Spark Ī½ÖCąĄč¦┴Ģż╚żĄż▐żČż▐ż╩ÖC─▄╚║źóź╔źŲź»Ī┴│¦│”▓╣▒¶▓╣Ī┴źčźšź®®`ź▐ź¾ź╣ź┴źÕ®`ź╦ź¾ź░
źóź╔źŲź»Ī┴│¦│”▓╣▒¶▓╣Ī┴źčźšź®®`ź▐ź¾ź╣ź┴źÕ®`ź╦ź¾ź░Yosuke Mizutani
?
źóź╔źŲź»Ī┴Scala meetup 2014-11-20
http://connpass.com/event/8384/2018─Ļ01į┬27╚š TensorFlowż╬ėŗ╦Ńź░źķźšż╬└ĒĮŌ
2018─Ļ01į┬27╚š TensorFlowż╬ėŗ╦Ńź░źķźšż╬└ĒĮŌaitc_jp
?
░k▒Ē╚šŻ║2018─Ļ01į┬27╚š
źżź┘ź¾ź╚├¹Ż║ AITCź¬®`źūź¾źķź▄ TensorFlow├ŃÅŖ╗ߟʟĻ®`ź║Ż▓ │╔╣¹ł¾Ėµ╗ß
źżź┘ź¾ź╚URLŻ║http://aitc.jp/events/20180127-OpenLab/info.html
ź┐źżź╚źļŻ║TensorFlowż╬ėŗ╦Ńź░źķźšż╬└ĒĮŌ
░k▒Ēš▀Ż║╝¬╠’ įŻų«╩Ž
TensorFlowż╦żĶżļź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╬īgū░żŽĪóĪĖėŗ╦Ńź░źķźšĪ╣ż“śŗ║B
ż╣żļź│®`ź╔ż╬ėø╩÷ż╦ż╩żĻż▐ż╣ĪŻ
▒Š░k▒ĒżŪżŽĪóTensorFlow└¹ė├ż╬╗∙ĄAų¬ūRż╚żĘżŲĪóėŗ╦Ńź░źķźšż╬┐╝ż©ĘĮż╚╩╦ĮM
ż▀ż“ĮŌšhżĘż▐ż╣ĪŻ
źĻźóźļź┐źżźÓäI└Ēź©ź¾źĖź¾
Gearpumpż╬ĮBĮķ
źĻźóźļź┐źżźÓäI└Ēź©ź¾źĖź¾
Gearpumpż╬ĮBĮķSotaro Kimura
?
#ScalaMatsuri ż╬źķź¾ź┴LTė├źĻźóźļź┐źżźÓäI└Ēź©ź¾źĖź¾Gearpumpż╬ĮBĮķź╣źķźżź╔żŪż╣ĪŻ
PCšŽ║”żŪ╩╣ż’ż║ż╦ĮBĮķżĘżŲż▐żĘż┐ż¼╣®Bż╬ż┐żßźóź├źūżĘżŲż¬żŁż▐ż╣ĪŻ[DL▌åši╗ß]Parallel WaveNet: Fast High-Fidelity Speech Synthesis
[DL▌åši╗ß]Parallel WaveNet: Fast High-Fidelity Speech SynthesisDeep Learning JP
?
2018/1/5
Deep Learning JP:
http://deeplearning.jp/seminar-2/▒▒┤¾š{║═ŽĄ DLź╝ź▀ A3C
▒▒┤¾š{║═ŽĄ DLź╝ź▀ A3CTomoya Oda
?
ź©źįźĮ®`ź╔ż╬źĄź¾źūźĻź¾ź░?č¦┴Ģż¼ĘŪ═¼Ų┌ + Actor-Criticż╩╩ųĘ©ż╬╠ß░ĖĪŻĖ³ż╦GPUżŪżŽż╩ż»CPUż╬ż▀żŪDQNżĶżĻč¦┴ĢĢrķgż“Ž„żļż│ż╚ż╦│╔╣”ĪŻż▐ż┐ĪóDQNż¼┐Ó╩ųż╩ąąäė┐šķgż¼▀BŠAż╩ł÷║Žż╬┐╔─▄ąįżŌ╩ŠżĘż┐ĪŻ
żĘż½żĘĪó¼Fį┌żŪżŽA2CŻ©═¼Ų┌Ż®ż╬ĘĮż¼ąį─▄ż¼┴╝żżż╚żĄżņżŲżżżļĪŻ├©żŪżŌĘųż½żļVariational AutoEncoder
├©żŪżŌĘųż½żļVariational AutoEncoderSho Tatsuno
?
╔·│╔źŌźŪźļż╚ż½ż“żóż▐żĻų¬żķż╩żż╚╦ż╦żŌż╩żļż┘ż»Ęųż½żĻżõż╣żżšh├„ż“ą─ż¼ż▒ż┐Variational AutoEncoderż╬ź╣źķźżź╔
īgū░ż╚║åģgż╩čaūŃżŽęįŽ┬ż“▓╬šš
http://sh-tatsuno.com/blog/index.php/2016/07/30/variationalautoencoder/ūįĘųż┐ż┴żŪż─ż»ż├ż┐&▒ń│▄┤Ū│┘;▒½│▌ź¼źżź╔źķźżź¾&▒ń│▄┤Ū│┘;ż“Ų¼╩ųż╦Ī󟻟ķź”ź╔ź’®`ź»ź╣ż“ū„żĻēõż©żļĪŻ
ūįĘųż┐ż┴żŪż─ż»ż├ż┐&▒ń│▄┤Ū│┘;▒½│▌ź¼źżź╔źķźżź¾&▒ń│▄┤Ū│┘;ż“Ų¼╩ųż╦Ī󟻟ķź”ź╔ź’®`ź»ź╣ż“ū„żĻēõż©żļĪŻkazuma ueda
?
UX JAM #14 żŪ░k▒ĒżĘż┐┘Y┴ŽżŪż╣ĪŻ
Ī∙ę╗▓┐ż╬Ūķł¾ż“ą▐š²żĘżŲ╣½ķ_żĘżŲżżż▐ż╣ĪŻŪ┐╗»č¦Ž░░¬▒╩▓ŌČ┘▓╣│┘▓╣.░š┤Ū░ņ▓Ō┤Ū
Ū┐╗»č¦Ž░░¬▒╩▓ŌČ┘▓╣│┘▓╣.░š┤Ū░ņ▓Ō┤ŪNaoto Yoshida
?
PyData.Tokyo Meetup #12 żŪż╬ÅŖ╗»č¦┴Ģż╦ķvż╣żļųvč▌ź╣źķźżź╔żŪż╣Ż«
https://pydatatokyo.connpass.com/event/48563/More Related Content
What's hot (20)
ąį─▄£yČ©Ą└ ╩┬╩╝żßŠÄ
ąį─▄£yČ©Ą└ ╩┬╩╝żßŠÄYuto Hayamizu
?
2013/10/05ż╦ķ_┤▀żĄżņż┐╚š▒ŠPostgreSQLźµ®`źČ╗ß Ą┌27╗žżĘż»ż▀Ż½źóźūźĻź▒®`źĘźńź¾├ŃÅŖ╗ßżŪż╬ųvč▌żŪż╣ĪŻ
http://www.postgresql.jp/wg/shikumi/shikumi27
----
ź│ź¾źįźÕ®`ź┐źĘź╣źŲźÓż╦ż¬ż▒żļąį─▄£yČ©ż╚żŽĪó╝╝▄┐żŪż╣ĪŻ
ąį─▄£yČ©ż╚żżż”ż╚Īóģgż╦£yČ©ź─®`źļż“īgąąż╣żļż└ż▒ż╬ū„śIż└ż╚┐╝ż©żķżņż¼ż┴żŪż╣ĪŻżĘż½żĘīgļHż╦żŽĪó║╬ż╬ż┐żßż╦£yČ©ż“ż╣żļż╬ż½ĪóżĮż╬ż┐żßż╦║╬ż“£yČ©ż╣żļż┘żŁż½ĪóżĮżĘżŲ║╬ż“╩╣ż├żŲ£yČ©ż╣żļż┘żŁż½ż“└ĒĮŌżĘż┐╔ŽżŪąąż’ż╩ż▒żņżą╚½ż»ęŌ╬Čż“│╔żĄż╩żżĪó╔Ņż▀ż╬żóżļ╝╝▄┐ż╬╩└ĮńżŪż╣ĪŻ
ųvč▌š▀ż╬╦∙╩¶ż╣żļ蹊┐╩ężŪżŽķL─Ļż╦ż’ż┐żĻźŪ®`ź┐ź┘®`ź╣źĘź╣źŲźÓż╬蹊┐?ķ_░kż“ąąż├żŲżŁż▐żĘż┐ĪŻżĮż╬▀^│╠żŪ┼Óż’żņż┐ąį─▄£yČ©ż╬╝╝▄┐ż╦ż─żżżŲĪóūŅĮ³ż╬īg└²żŌĮ╗ż©ż─ż─żĮż╬┐╝ż©ĘĮż“ż┤ĮBĮķżĘż┐żżż╚╦╝żżż▐ż╣ĪŻźŪźŻ®`źūźķ®`ź╦ź¾ź░ūŅĮ³ż╬░kš╣ż╚źėźĖź═ź╣ÅĻė├żžż╬┐╬╠Ō
źŪźŻ®`źūźķ®`ź╦ź¾ź░ūŅĮ³ż╬░kš╣ż╚źėźĖź═ź╣ÅĻė├żžż╬┐╬╠ŌKenta Oono
?
2015─Ļ5į┬26╚šĪóź©ź╠źėźŪźŻźóśöų„┤▀ĪĖźŪźŻ®`źūźķ®`ź╦ź¾ź░źšź®®`źķźÓ2015Ī╣żŪż╬Preferred Networksż╬ųvč▌┘Y┴ŽżŪż╣
http://www.gdep.jp/page/view/412░Ł▓╣▓Ą▓Ą▒¶▒ż╬źŲź»ź╦ź├ź»
░Ł▓╣▓Ą▓Ą▒¶▒ż╬źŲź»ź╦ź├ź»Yasunori Ozaki
?
░Ł▓╣▓Ą▓Ą▒¶▒ż╬żóżļź│ź¾źŲź¾ź╣ź╚ż╬ė┼╩żš▀ż¼ū„ż├ż┐źŌźŪźļż“ź▒®`ź╣ź╣ź┐źŪźŻż╚żĘżŲĪó░ņ▓╣▓Ą▓Ą▒¶▒źŲź»ź╦ź├ź»ż“ĮŌšhżĘż▐ż╣ĪŻ╠žż╦│¦│┘▓╣│”░ņŠ▒▓į▓Ąż“ųąą─ż╦ĮŌšhżĘżŲżżż▐ż╣ĪŻ░õ▒Ę▒Ęż╦żŽżóż©żŲ┤źżņż▐ż╗ż¾żŪżĘż┐ĪŻż▐ż┐Īó│┘-│¦▒ĘĘĪżõ│µ▓Ą▓·┤Ū┤Ū▓§│┘ż╬Ė┼┬įż╦żŌ┤źżņż▐żĘż┐ĪŻMicrosoft Malware Classification Challenge ╔Ž╬╗╩ųĘ©ż╬ĮBĮķ (in Kaggle Study Meetup)
Microsoft Malware Classification Challenge ╔Ž╬╗╩ųĘ©ż╬ĮBĮķ (in Kaggle Study Meetup)Shotaro Sano
?
2015─Ļż╦ķ_┤▀żĄżņż┐ÖCąĄč¦┴Ģź│ź¾ź┌źŲźŻźĘźńź¾Ż©Microsoft Malware Classification ChallengeŻ®ż╦ż¬ż▒żļ╔Ž╬╗╩ųĘ©żõā×ä┘źŌźŪźļż╦ż─żżżŲż╬ĮŌšhĪŻż│ż┴żķż╬ź▀®`ź╚źóź├źūżŪ░k▒ĒżĄż╗żŲżżż┐ż└żŁż▐żĘż┐Ż║ http://connpass.com/event/25007/ Chainer ż╬ Trainer ĮŌšhż╚ NStepLSTM ż╦ż─żżżŲ
Chainer ż╬ Trainer ĮŌšhż╚ NStepLSTM ż╦ż─żżżŲRetrieva inc.
?
źņź╚źĻźąź╗ź▀ź╩®` 2017/03/15
Movie: https://www.youtube.com/watch?v=ok_bvPKAEaMKaggle▓╬╝ėł¾Ėµ: Champs Predicting Molecular Properties
Kaggle▓╬╝ėł¾Ėµ: Champs Predicting Molecular PropertiesKazuki Fujikawa
?
Kaggleź│ź¾ź┌źŲźŻźĘźńź¾ĪĖPredicting Molecular PropertiesĪ╣żŪ13╬╗ż╦ż╩ż├ż┐Ģrż╬ĮŌĘ©ż╬ĮBĮķż╚Īó╔Ž╬╗źĮźĻźÕ®`źĘźńź¾ż╬ĮBĮķżŪż╣ĪŻ░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├
░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├Seiya Tokui
?
Ą┌10╗ž NLP╚¶╩ųż╬╗ߟʟ¾ź▌źĖź”źÓ (YANS) ż╬ź┴źÕ®`ź╚źĻźóźļź╣źķźżź╔żŪż╣ĪŻź╦źÕ®`źķźļź═ź├ź╚ż╬Ż©źóźļź┤źĻź║źÓż╚żĘżŲż╬Ż®ż¬żĄżķżżż╚ĪóChainer v1.3.0ż╬╩╣żżĘĮż“ĮBĮķżĘżŲżżż▐ż╣ĪŻĄ┌3╗ž╗·ąĄč¦Ž░├ŃŪ┐╗ßĪĖ╔½Ī®ż╩▒Ę▒Ęźšźņ®`źÓź’®`ź»ż“Č»ż½żĘżŲż▀żĶż”Ī╣-░Ł▒░∙▓╣▓§▒Ó-
Ą┌3╗ž╗·ąĄč¦Ž░├ŃŪ┐╗ßĪĖ╔½Ī®ż╩▒Ę▒Ęźšźņ®`źÓź’®`ź»ż“Č»ż½żĘżŲż▀żĶż”Ī╣-░Ł▒░∙▓╣▓§▒Ó-Yasuyuki Sugai
?
2016─Ļ6į┬Ų┌AITCź¬®`źūź¾źķź▄
Ą┌3╗ž ÖCąĄč¦┴Ģ├ŃÅŖ╗ß ĪĖ╔½Ī®ż╩ź╦źÕ®`źķźļ?ź═ź├ź╚ź’®`ź»ż╬źšźņ®`źÓź’®`ź»ż“äėż½żĘżŲż▀żĶż”ŻĪĪ╣ KerasŠÄ┘Y┴Ž2015-11-17 żŁż┴ż¾ż╚ų¬żĻż┐żżApache Spark Ī½ÖCąĄč¦┴Ģż╚żĄż▐żČż▐ż╩ÖC─▄╚║
2015-11-17 żŁż┴ż¾ż╚ų¬żĻż┐żżApache Spark Ī½ÖCąĄč¦┴Ģż╚żĄż▐żČż▐ż╩ÖC─▄╚║Yu Ishikawa
?
2015-11-17 żŁż┴ż¾ż╚ų¬żĻż┐żżApache Spark Ī½ÖCąĄč¦┴Ģż╚żĄż▐żČż▐ż╩ÖC─▄╚║źóź╔źŲź»Ī┴│¦│”▓╣▒¶▓╣Ī┴źčźšź®®`ź▐ź¾ź╣ź┴źÕ®`ź╦ź¾ź░
źóź╔źŲź»Ī┴│¦│”▓╣▒¶▓╣Ī┴źčźšź®®`ź▐ź¾ź╣ź┴źÕ®`ź╦ź¾ź░Yosuke Mizutani
?
źóź╔źŲź»Ī┴Scala meetup 2014-11-20
http://connpass.com/event/8384/2018─Ļ01į┬27╚š TensorFlowż╬ėŗ╦Ńź░źķźšż╬└ĒĮŌ
2018─Ļ01į┬27╚š TensorFlowż╬ėŗ╦Ńź░źķźšż╬└ĒĮŌaitc_jp
?
░k▒Ē╚šŻ║2018─Ļ01į┬27╚š
źżź┘ź¾ź╚├¹Ż║ AITCź¬®`źūź¾źķź▄ TensorFlow├ŃÅŖ╗ߟʟĻ®`ź║Ż▓ │╔╣¹ł¾Ėµ╗ß
źżź┘ź¾ź╚URLŻ║http://aitc.jp/events/20180127-OpenLab/info.html
ź┐źżź╚źļŻ║TensorFlowż╬ėŗ╦Ńź░źķźšż╬└ĒĮŌ
░k▒Ēš▀Ż║╝¬╠’ įŻų«╩Ž
TensorFlowż╦żĶżļź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»ż╬īgū░żŽĪóĪĖėŗ╦Ńź░źķźšĪ╣ż“śŗ║B
ż╣żļź│®`ź╔ż╬ėø╩÷ż╦ż╩żĻż▐ż╣ĪŻ
▒Š░k▒ĒżŪżŽĪóTensorFlow└¹ė├ż╬╗∙ĄAų¬ūRż╚żĘżŲĪóėŗ╦Ńź░źķźšż╬┐╝ż©ĘĮż╚╩╦ĮM
ż▀ż“ĮŌšhżĘż▐ż╣ĪŻ
źĻźóźļź┐źżźÓäI└Ēź©ź¾źĖź¾
Gearpumpż╬ĮBĮķ
źĻźóźļź┐źżźÓäI└Ēź©ź¾źĖź¾
Gearpumpż╬ĮBĮķSotaro Kimura
?
#ScalaMatsuri ż╬źķź¾ź┴LTė├źĻźóźļź┐źżźÓäI└Ēź©ź¾źĖź¾Gearpumpż╬ĮBĮķź╣źķźżź╔żŪż╣ĪŻ
PCšŽ║”żŪ╩╣ż’ż║ż╦ĮBĮķżĘżŲż▐żĘż┐ż¼╣®Bż╬ż┐żßźóź├źūżĘżŲż¬żŁż▐ż╣ĪŻ[DL▌åši╗ß]Parallel WaveNet: Fast High-Fidelity Speech Synthesis
[DL▌åši╗ß]Parallel WaveNet: Fast High-Fidelity Speech SynthesisDeep Learning JP
?
2018/1/5
Deep Learning JP:
http://deeplearning.jp/seminar-2/▒▒┤¾š{║═ŽĄ DLź╝ź▀ A3C
▒▒┤¾š{║═ŽĄ DLź╝ź▀ A3CTomoya Oda
?
ź©źįźĮ®`ź╔ż╬źĄź¾źūźĻź¾ź░?č¦┴Ģż¼ĘŪ═¼Ų┌ + Actor-Criticż╩╩ųĘ©ż╬╠ß░ĖĪŻĖ³ż╦GPUżŪżŽż╩ż»CPUż╬ż▀żŪDQNżĶżĻč¦┴ĢĢrķgż“Ž„żļż│ż╚ż╦│╔╣”ĪŻż▐ż┐ĪóDQNż¼┐Ó╩ųż╩ąąäė┐šķgż¼▀BŠAż╩ł÷║Žż╬┐╔─▄ąįżŌ╩ŠżĘż┐ĪŻ
żĘż½żĘĪó¼Fį┌żŪżŽA2CŻ©═¼Ų┌Ż®ż╬ĘĮż¼ąį─▄ż¼┴╝żżż╚żĄżņżŲżżżļĪŻ├©żŪżŌĘųż½żļVariational AutoEncoder
├©żŪżŌĘųż½żļVariational AutoEncoderSho Tatsuno
?
╔·│╔źŌźŪźļż╚ż½ż“żóż▐żĻų¬żķż╩żż╚╦ż╦żŌż╩żļż┘ż»Ęųż½żĻżõż╣żżšh├„ż“ą─ż¼ż▒ż┐Variational AutoEncoderż╬ź╣źķźżź╔
īgū░ż╚║åģgż╩čaūŃżŽęįŽ┬ż“▓╬šš
http://sh-tatsuno.com/blog/index.php/2016/07/30/variationalautoencoder/Viewers also liked (20)
ūįĘųż┐ż┴żŪż─ż»ż├ż┐&▒ń│▄┤Ū│┘;▒½│▌ź¼źżź╔źķźżź¾&▒ń│▄┤Ū│┘;ż“Ų¼╩ųż╦Ī󟻟ķź”ź╔ź’®`ź»ź╣ż“ū„żĻēõż©żļĪŻ
ūįĘųż┐ż┴żŪż─ż»ż├ż┐&▒ń│▄┤Ū│┘;▒½│▌ź¼źżź╔źķźżź¾&▒ń│▄┤Ū│┘;ż“Ų¼╩ųż╦Ī󟻟ķź”ź╔ź’®`ź»ź╣ż“ū„żĻēõż©żļĪŻkazuma ueda
?
UX JAM #14 żŪ░k▒ĒżĘż┐┘Y┴ŽżŪż╣ĪŻ
Ī∙ę╗▓┐ż╬Ūķł¾ż“ą▐š²żĘżŲ╣½ķ_żĘżŲżżż▐ż╣ĪŻŪ┐╗»č¦Ž░░¬▒╩▓ŌČ┘▓╣│┘▓╣.░š┤Ū░ņ▓Ō┤Ū
Ū┐╗»č¦Ž░░¬▒╩▓ŌČ┘▓╣│┘▓╣.░š┤Ū░ņ▓Ō┤ŪNaoto Yoshida
?
PyData.Tokyo Meetup #12 żŪż╬ÅŖ╗»č¦┴Ģż╦ķvż╣żļųvč▌ź╣źķźżź╔żŪż╣Ż«
https://pydatatokyo.connpass.com/event/48563/Convolutional Neural Netwoks żŪūį╚╗čįšZäI└Ēż“ż╣żļ
Convolutional Neural Netwoks żŪūį╚╗čįšZäI└Ēż“ż╣żļDaiki Shimada
?
╚½├Śźó®`źŁźŲź»ź┴źŃ╚¶╩ųż╬╗ߥ┌20╗žź½źĖźÕźóźļź╚®`ź»░k▒Ēū╩┴Žaiconf2017okanohara
aiconf2017okanoharaPreferred Networks
?
Aiź½ź¾źšźĪźņź¾ź╣ 2017@źėź├ź░źĄźżź╚żŪż╬ųvč▌┘Y┴ŽżŪż╣ĪŻūįäė▄ćĪóźĒź▄ź├ź╚Īóźąźżź¬źžźļź╣ź▒źóżŪż╬ÅĻė├╩┬└²Ī󿬿ĶżėĮ±ßßż╬šnŅ}ż╦ż─żżżŲĢ°żżżŲżóżĻż▐ż╣ĪŻDistributed Deep Q-Learning
Distributed Deep Q-LearningLyft
?
The document discusses a distributed deep Q-learning algorithm developed to enhance reinforcement learning efficiency by utilizing neural networks for high-dimensional sensory inputs. It outlines serial and distributed algorithms, highlights the importance of experience replay for stability, and presents numerical experiments demonstrating the method's effectiveness. The implementation enables significant scaling through data parallelism, resulting in faster training and improved performance in various gaming environments.źŪ®`ź┐źņźżź»ż“╗∙┼╠ż╚żĘż┐┤Ī░┬│¦╔ŽżŪż╬╗·ąĄč¦Ž░źĄ®`źėź╣╣╣ų■
źŪ®`ź┐źņźżź»ż“╗∙┼╠ż╚żĘż┐┤Ī░┬│¦╔ŽżŪż╬╗·ąĄč¦Ž░źĄ®`źėź╣╣╣ų■Amazon Web Services Japan
?
2016/12/17ķ_┤▀ĪĖĮ±─ĻżŌżõżļżĶŻĪźėź├ź░źŪ®`ź┐ź¬®`źļź╣ź┐®`ź║ -╚š▒Šż“┤·▒Ēż╣żļźėź├ź░źŪ®`ź┐ź©ź¾źĖź╦źó?ź▐®`ź▒ź┐®`ż¼┤¾╝»ĮYŻĪ- Ī╣żŪż╬░k▒Ē┘Y┴ŽĪĖźŪ®`ź┐źņźżź»ż“╗∙┼╠ż╚żĘż┐┤Ī░┬│¦╔ŽżŪż╬╗·ąĄč¦Ž░źĄ®`źėź╣╣╣ų■Ī╣żŪż╣Deep learningż╬Ė┼ꬿ╚ź╔źßźżź¾źŌźŪźļż╬ēõ▀w
Deep learningż╬Ė┼ꬿ╚ź╔źßźżź¾źŌźŪźļż╬ēõ▀wTaiga Nomi
?
Deep Learningż╬Ė┼ę¬ĪóūŅĮ³ż╬│╔╣¹ż╚Īóźšźņ®`źÓź’®`ź»īgū░š▀ż╬ęĢĄŃżŪęŖż┐ź╔źßźżź¾źŌźŪźļż╬ēõ▀wż╦ż─żżżŲĪŻHype vs. Reality: The AI Explainer
Hype vs. Reality: The AI ExplainerLuminary Labs
?
The document discusses the current state and future potential of artificial intelligence (AI) in business, separating hype from reality. It emphasizes that AI will change job roles rather than eliminate them, and suggests five practical steps businesses can take to integrate AI in a meaningful way. Key points include starting with specific business problems, fostering empathy in the workforce, and ensuring a clear understanding of AI capabilities.A Reintroduction To Ruby M17 N
A Reintroduction To Ruby M17 NYui NARUSE
?
¢|Š®RubyKaigi03 │╔×üż╬░k▒Ē
ĪĖA reintroduction to Ruby M17NĪ╣
http://nalsh.jp/pub/A%20reintroduction%20to%20Ruby%20M17N.pptxMachine Learning Methods for Parameter Acquisition in a Human ...
Machine Learning Methods for Parameter Acquisition in a Human ...butest
?
The document discusses using machine learning approaches to automate the acquisition of parameters and network structures for computational models of human decision making. It aims to semi-automate the process of building and tuning cognitive models to reduce costs and speed up development. Parameter acquisition and network topology induction are challenging problems that require novel machine learning algorithms to infer the internal representations and decision processes of human operators under cognitive plausibility constraints. Direct elicitation of information from users may be the most promising approach.MALT: Distributed Data-Parallelism for Existing ML Applications (Distributed ...
MALT: Distributed Data-Parallelism for Existing ML Applications (Distributed ...asimkadav
?
The document discusses MALT, a machine learning toolset that enables efficient data-parallel training of existing machine learning applications across distributed systems. It highlights the challenges of model training, such as the large data sizes and the need for real-time model updates, and provides a peer-to-peer communication approach for model updates without a central server. MALT integrates with C++ and Lua applications, demonstrating improved speed and fault tolerance in model training through advanced communication techniques.Spark Summit EU talk by Rolf Jagerman
Spark Summit EU talk by Rolf JagermanSpark Summit
?
This document discusses an asynchronous parameter server called Glint for Spark. It was created to address the problem of machine learning models exceeding the memory of a single machine. Glint distributes models over multiple machines and allows two operations - pulling and pushing model parameters. It was tested on topic modeling of a 27TB dataset using 1,000 topics, significantly outperforming MLLib in terms of quality, runtime, and scalability. Future work may include improved fault tolerance, custom aggregation functions, and implementing additional algorithms like deep learning.tofu - COOKPAD's image system
tofu - COOKPAD's image systemIssei Naruta
?
Tofu is an image processing system developed by COOKPAD that generates thumbnail images on demand from original images stored in S3. Previously, COOKPAD would generate all thumbnail sizes upfront, using significant storage. Tofu addresses this by using a Apache module called mod_tofu that generates thumbnails from original images only when requested. This on-demand approach is faster, more scalable, and saves storage by not pre-generating all sizes. Tofu leverages the scalability of AWS to process large volumes of image resizing with high performance.Japanese Rubyists you have not met yet
Japanese Rubyists you have not met yetmasayoshi takahashi
?
This document introduces two important Japanese Rubyists, Yugui and Itojun. Yugui was the release manager for Ruby 1.9 and wrote a Japanese edition book on learning Ruby. Itojun contributed the IPv6 protocol stack for Ruby and helped with the early development and release of Ruby by providing mailing lists and FTP access to Matz. Unfortunately, Itojun passed away in 2007 but his contributions to Ruby and as a free software evangelist in Japan remain important. The document concludes that while some Rubyists may not be met in person, their work can still be experienced through projects like Ruby and that the open nature of free software allows developers and communities to form around the world.How to Begin to Develop Ruby Core
How to Begin to Develop Ruby CoreHiroshi SHIBATA
?
The document discusses how to contribute code to the Ruby programming language. It provides instructions for obtaining the Ruby source code, running tests on the Ruby codebase, and submitting patches to the Ruby bug tracking system. The tests include language tests, framework tests, and extension tests. The goal is to help developers get started testing and contributing to the Ruby core.How To Select Best Transmission For Your Vehicle
How To Select Best Transmission For Your VehicleDreamcars Auto Repair
?
The document discusses various types of vehicle transmission systems, including conventional automatic, dual-clutch, and continuously variable transmissions (CVT). CVTs are highlighted for their efficiency due to the use of belts for smooth transitions, resulting in up to 10% better fuel economy compared to other transmission types. Overall, the document emphasizes the performance and operational advantages of modern transmission technologies.ūįĘųż┐ż┴żŪż─ż»ż├ż┐&▒ń│▄┤Ū│┘;▒½│▌ź¼źżź╔źķźżź¾&▒ń│▄┤Ū│┘;ż“Ų¼╩ųż╦Ī󟻟ķź”ź╔ź’®`ź»ź╣ż“ū„żĻēõż©żļĪŻ
ūįĘųż┐ż┴żŪż─ż»ż├ż┐&▒ń│▄┤Ū│┘;▒½│▌ź¼źżź╔źķźżź¾&▒ń│▄┤Ū│┘;ż“Ų¼╩ųż╦Ī󟻟ķź”ź╔ź’®`ź»ź╣ż“ū„żĻēõż©żļĪŻkazuma ueda
?
Ad
Similar to Inspection of CloudML Hyper Parameter Tuning (20)
├„ų╬┤¾č¦ųvč▌┘Y┴ŽĪĖÖCąĄč¦┴Ģż╚ūįäėźŽźżźč®`źčźķźßź┐ūŅ▀m╗»Ī╣ ū¶ę░š²╠½└╔
├„ų╬┤¾č¦ųvč▌┘Y┴ŽĪĖÖCąĄč¦┴Ģż╚ūįäėźŽźżźč®`źčźķźßź┐ūŅ▀m╗»Ī╣ ū¶ę░š²╠½└╔Preferred Networks
?
2019─Ļ6į┬28╚šż╬├„ų╬┤¾č¦żŪż╬ųv┴x┘Y┴ŽżŪż╣ĪŻ
żŪżŁżļż└ż▒╩²╩Įż“╩╣ż’ż║ż╦Ī║ÖCąĄč¦┴Ģż╬ż¬żĄżķżżĪ╗Ī║ūįäėźŽźżźč®`źčźķźßź┐ūŅ▀m╗»Ī╗Ī║Optuna ż╬╩╣żżĘĮĪ╗Ī║ź┘źżź║ūŅ▀m╗»ż╬ÅĻė├╩┬└²Ī╗ż╦ż─żżżŲšh├„żĘżŲżżż▐ż╣ĪŻ
Ī±Optuna : https://github.com/pfnet/optuna20210427 grass roots_ml_design_patterns_hyperparameter_tuning
20210427 grass roots_ml_design_patterns_hyperparameter_tuninghitoshim
?
Machine Learning Design Patterns šiĢ°╗ß #3
https://grass-roots-ml.connpass.com/event/211119/presentation/
żŪ░k▒ĒżĘż┐┘Y┴ŽżŪż╣ĪŻPractical recommendations for gradient-based training of deep architectures
Practical recommendations for gradient-based training of deep architecturesKoji Matsuda
?
Yoshua Bengio, Practical recommendations for gradient-based training of deep architectures, arXiv:1206.5533v2, 2012 ż╬ĮŌšhÖCąĄč¦┴ĢźūźĒźĖź¦ź»ź╚ż╦ż¬ż▒żļ Cloud AI Platform ż╬╩╣żżĘĮ (2018-11-19)
ÖCąĄč¦┴ĢźūźĒźĖź¦ź»ź╚ż╦ż¬ż▒żļ Cloud AI Platform ż╬╩╣żżĘĮ (2018-11-19)Yaboo Oyabu
?
Google Cloud Platform (GCP) ż╬╔ŽżŪĪóä┐┬╩Ą─ż╦ÖCąĄč¦┴ĢźŌźŪźļż“ķ_░kż╣żļĘĮĘ©ĪóÖCąĄč¦┴ĢźūźĒźĖź¦ź»ź╚ż“▀\ė├ż╣żļĘĮĘ©ż╦ż─żżżŲšh├„żĘż▐ż╣[DL▌åši╗ß]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
[DL▌åši╗ß]EfficientNet: Rethinking Model Scaling for Convolutional Neural NetworksDeep Learning JP
?
2019/06/21
Deep Learning JP:
http://deeplearning.jp/seminar-2/ źŪźŻ®`źūźķ®`ź╦ź¾ź░╚ļķT Ī½ ╗ŁŽ±äI└Ē?ūį╚╗čįšZäI└Ēż╦ż─żżżŲ Ī½
źŪźŻ®`źūźķ®`ź╦ź¾ź░╚ļķT Ī½ ╗ŁŽ±äI└Ē?ūį╚╗čįšZäI└Ēż╦ż─żżżŲ Ī½Kensuke Otsuki
?
ż│żņż½żķźŪźŻ®`źūźķ®`ź╦ź¾ź░ż“覿ųĘĮż╬ż┐żßż╬ū╩┴Žż“ū„żĻż▐żĘż┐ĪŻÅĻė├Ž╚ż╚żĘżŲżŽ╗ŁŽ±äI└Ē?ūį╚╗čįė’äI└Ēż╦Į╩ż├żŲĮŌšhż“ąąż├żŲżżż▐ż╣ĪŻź┘źżź║ūŅ╩╩╗»ż╦żĶżļźŽźżźčźķ®`źčźķźß®`ź┐╠Į╦„
ź┘źżź║ūŅ╩╩╗»ż╦żĶżļźŽźżźčźķ®`źčźķźß®`ź┐╠Į╦„╬„ī∙ ┘tę╗└╔
?
ź┘źżź║ūŅ▀m╗»ż╦żĶżļźŽźżźč®`źčźķźß®`ź┐╠Į╦„ż╦ż─żżżŲżČż├ż»żĻż╚ĮŌšhżĘż▐żĘż┐ĪŻ
Į±╗žĮBĮķż╣żļ─┌╚▌ż╬į¬ż╚ż╩ż├ż┐šō╬─
Bergstra, James, et al. "Algorithms for hyper-parameter optimization." 25th annual conference on neural information processing systems (NIPS 2011). Vol. 24. Neural Information Processing Systems Foundation, 2011.
https://hal.inria.fr/hal-00642998/
TensorFlow User Group #1
TensorFlow User Group #1Ļ¢ŲĮ ╔Į┐┌
?
TensorFlow żŪÜ░│»╠Õ▓┘ż“┘tż»żĘż┐įÆżŪż╣ĪŻ╔┘żĘŪ░ż╦ GCPUG Sapporo vol.2 ML Night żŪįÆżĘż┐ż│ż╚ż╚═¼żĖżŪż╣ĪŻ╔┘żĘĘųż½żĻżõż╣ż»š`ĮŌż¼╔┘ż╩ż»ż╩ż├żŲżżż▐ż╣ĪŻ
TensorFlow żŪč¦┴ĢżĘż┐źŌźŪźļż“źŌźąźżźļż╩ż╔żŪäėż½ż╣ł÷║Žż╦▓╬┐╝ż╦ż╩żļż╚╦╝żżż▐ż╣ĪŻAzure Machine Learning Services Ė┼ę¬ - 2019─Ļ3į┬░µ
Azure Machine Learning Services Ė┼ę¬ - 2019─Ļ3į┬░µDaiyu Hatakeyama
?
Azure Machine Learning Services ż╬Ė┼ꬿŪż╣ĪŻ
źŪ®`ź┐ż╬£╩éõĪóč¦┴ĢźĖźńźųĪóźŌźŪźļż╬š╣ķ_ĪóAutomated Machine LearningĪóHyperparameter ExplorerĪóONNIXĪóWindowsMLż╩ż╔ż¼║¼ż▐żņżŲżżż▐ż╣ĪŻ[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...Deep Learning JP
?
2019/06/10
Deep Learning JP:
http://deeplearning.jp/hacks/ Journal club dec24 2015 splice site prediction using artificial neural netw...
Journal club dec24 2015 splice site prediction using artificial neural netw...Hiroya Morimoto
?
Brief introduction to artificial neural networks and the application to bioinformatics fields. And show how to utilize neural networks to predict splice sites in genome/gene sequences. ▒ß▓Ō▒Ķ▒░∙┤Ū▒Ķ│┘ż╚żĮż╬ų▄▐xż╦ż─żżżŲ
▒ß▓Ō▒Ķ▒░∙┤Ū▒Ķ│┘ż╚żĮż╬ų▄▐xż╦ż─żżżŲKeisuke Hosaka
?
Hyperoptż╬įŁšō╬─ż“šiż¾żŪHyperoptż“ĮŌšhżĘż┐┘Y┴ŽżŪż╣ĪŻ
Ė┼ꬿ└ż▒żŪż╩ż»╝Üż½żżż╚ż│żĒżŌżŪżŁżļż└ż▒šh├„ż╣żļżĶż”ż╦żĘżŲżżż▐ż╣ĪŻGCPUG Sapporo vol.2 ML Night
GCPUG Sapporo vol.2 ML NightĻ¢ŲĮ ╔Į┐┌
?
└┤Ų▄┤©ļŖ╦Ńż╦ż¬ż▒żļÖCąĄč¦┴Ģ╗Ņė├╩┬└²żŪż╣ĪŻĮ±╗žżŽĪóÜ░│»╠Õ▓┘ż╬ƱĄŃź©ź¾źĖź¾ż“╔Ņīėč¦┴Ģż╦ŪążĻ╠µż©ż┐įÆżŪż╣ĪŻTensorFlow żŌ╩╣ż├żŲżżż▐ż╣ĪŻ╔Ņīėč¦┴Ģż“źŌźąźżźļż╦ĮMż▀▐zżÓļHż╦▓╬┐╝ż╦ż╩żļż½żŌżĘżņż▐ż╗ż¾ĪŻ
TensorFlow ż“╗∙▒Pż╚ż╣żļź©ź│źĘź╣źŲźÓż“ū„żĒż”ż╚żĘżŲżżżļż╬żŪĪó┼d╬Čż¼żóżļĘĮżŽż¬╔∙ż¼ż▒ż»ż└żĄżżĪŻ
šō╬─ĮBĮķ:Practical bayesian optimization of machine learning algorithms(nips2012)
šō╬─ĮBĮķ:Practical bayesian optimization of machine learning algorithms(nips2012)Keisuke Uto
?
Practical Bayesian Optimization of Machine Learning Algorithms(NIPS2012)ż╬šō╬─ĮBĮķżŪż╣ĪŻ
Gaussian Process ż╬ų▒ĖąĄ─ż╩źżźß®`źĖż╚ĪóżĮż╬╩╣ż’żņĘĮż“ĮŌšhżĘż▐żĘż┐ĪŻAI Business Challenge Day 20170316
AI Business Challenge Day 20170316Ļ¢ŲĮ ╔Į┐┌
?
SOFTOPIA JAPANų„┤▀ AI Business Challenge DayĪĖĄ┌1╗ž ÖCąĄč¦┴Ģīg╝∙├ŃÅŖ╗ßĪ╣żŪįÆż╣ļHż╦╩╣ż”┘Y┴ŽżŪż╣ĪŻ
Ü░│»╠Õ▓┘ż╬AIż╦ķvż╣żļįÆż¼ųąą─żŪż╣ż¼ĪóūŅĮ³ż╬╚ĪżĻĮMż▀ż╦ż─żżżŲż╬ź┌®`źĖż¼ēłż©żŲżżż▐ż╣ĪŻ├µ░ūżż│╔╣¹ż¼żŪżŲżżżļż╬żŪĪóż╝żęęŖżŲż»ż└żĄżżĪŻAd
More from nagachika t (13)
Make Ruby Differentiable
Make Ruby Differentiablenagachika t
?
The document discusses making Ruby differentiable by introducing automatic differentiation capabilities. It presents a differentiation gem that allows making Ruby methods, procs, numbers and matrices differentiable. This allows defining and computing gradients of functions. It demonstrates this on a multilayer perceptron neural network model solving XOR. The goal is to make Ruby differentiable in order to apply automatic differentiation to Ruby programs.All bugfixes are incompatibilities
All bugfixes are incompatibilitiesnagachika t
?
This document summarizes lessons learned from failures in backporting bug fixes to Ruby stable branches:
- Don't backport performance improvements or fixes for imaginary use cases as they can introduce regressions.
- Be careful backporting fixes related to parsing, constants/method search, and refinements as they are complex and prone to causing new bugs.
- Some long-standing bugs may not need fixing if no real applications are affected. It's better to avoid regressions.
- Consider an application's needs before backporting - don't backport fixes if no one requested or needs them. Be practical.Functional Music Composition
Functional Music Compositionnagachika t
?
This document discusses functional programming and audio programming. It introduces LazyK, a purely functional and stream-based programming language based on SKI combinator calculus. It also introduces RazyK, a LazyK interpreter implemented in Ruby that allows stepping through reduction steps and includes a browser interface and audio stream mode to evaluate LazyK programs that generate music.BigQuery case study in Groovenauts & Dive into the DataflowJavaSDK
BigQuery case study in Groovenauts & Dive into the DataflowJavaSDKnagachika t
?
This document summarizes a presentation about using BigQuery and the Dataflow Java SDK. It discusses how Groovenauts uses BigQuery to analyze data from their MAGELLAN container hosting service, including resource monitoring, developer activity logs, application logs, and end-user access logs. It then provides an overview of the Dataflow Java SDK, including the key concepts of PCollections, coders, PTransforms, composite transforms, ParDo and DoFn, and windowing.Magellan on Google Cloud Platform
Magellan on Google Cloud Platformnagachika t
?
The document outlines the capabilities of Tomoyuki Chikanaga's Groovenauts, Inc. regarding their mobile application platform and various functionalities associated with Google Cloud services. It highlights features like high availability, quick deployment, and interoperability through the use of Google Compute Engine, BigQuery, and other tools. Additionally, it emphasizes the cost performance and scalable querying of BigQuery for resource usage and activity analysis.CRuby Committers Who's Who in 2013
CRuby Committers Who's Who in 2013nagachika t
?
This document summarizes recent trends in CRuby development and introduces some of the key committers to the CRuby project in 2013. It notes that development speed has increased, with over 12 commits per day on average. It profiles several top committers like matz, nobu, ko1, akr, usa, naruse, kosaki, nari, shugo, svn, and nagachika, highlighting their main contributions and an example commit. The document promotes external resources like ruby-trunk-changes for tracking CRuby changes.CRuby_Committers_Whos_Who_in_2014
CRuby_Committers_Whos_Who_in_2014nagachika t
?
The document provides an overview of key contributors to the cruby project in 2014, listing active committers, their roles, and notable speakers at the conference. It highlights the contributions of various individuals, including the creator of Ruby, Yukihiro Matsumoto, and other committers from notable companies. Additionally, it mentions new projects and updates related to the Ruby programming language and its features.ĄĪČĶż╩Ėķ│▄▓·▓ŌŠ▒▓§│┘żžż╬Ą└ fukuoka rubykaigi01
ĄĪČĶż╩Ėķ│▄▓·▓ŌŠ▒▓§│┘żžż╬Ą└ fukuoka rubykaigi01nagachika t
?
ĖŻī∙Ruby╗ßūh01 żŪ░k▒ĒżĘż┐ź╣źķźżź╔ż“╣½ķ_ė├ż╦PDF ż╦ēõōQżĘż┐żŌż╬żŪż╣ĪŻźóź╦źß®`źĘźńź¾żõźŪźŌäė╗ŁżŽź╣źķźżź╔ż╦ų├żŁōQż©żŲżżż▐ż╣ĪŻRuby on azure żŪ game server service
Ruby on azure żŪ game server servicenagachika t
?
10į┬16╚šż╦ķ_┤▀żĄżņż┐Windows Azure ź╗ź▀ź╩®`żŪ░k▒ĒżĘż┐ĪĖRuby on Azure żŪ GameServer ServiceĪ╣ż╬░k▒Ē┘Y┴ŽĪŻ
ź└ź”ź¾źĒ®`ź╔żŪ PowerPoint źšźĪźżźļż“ź╣źķźżź╔źĘźń®`▒Ē╩Šż╣żļż╚źóź╦źß®`źĘźńź¾żŌį┘╔·żŪżŁż▐ż╣ĪŻRuby trunk changes Įyėŗ░µ
Ruby trunk changes Įyėŗ░µnagachika t
?
The document provides statistics about commits to the CRuby repository over time. It breaks down commit categories by percentage, finding that 22% were for bug fixes, 20% for refactoring, 11% for enhancements, 11% for tests, 10% for documentation, 8% for the build process, 8% for Windows support, 3% introduced new bugs, 3% fixed typos, 10% updated version.h, and 6% were trivial. It concludes by reviewing top commit categories and a degrader ranking.Pd Kai#2 Object Model
Pd Kai#2 Object Modelnagachika t
?
The document describes Pure Data's object-oriented programming model, where all elements like boxes, objects, classes and inlets/outlets are represented as objects, with classes defining common behaviors and properties of objects, and objects being instances of classes that can receive and send messages through inlets and outlets. Key elements include the class struct that defines methods like initialization and message handling, the t_object base class, and fundamental data types like symbols, atoms, and inlet/outlet objects that allow communication between objects.Inspection of CloudML Hyper Parameter Tuning
- 1. Inspection of Cloud Machine Leaning Hyper Parameter Tuning nagachika GCPUG Fukuoka
- 2. Agenda ? Hyper Parameter Tuning ż╚żŽ? ? Hyper Parameter Tuning ż╬ąį─▄ż“īg“Y ? Hyper Parameter Tuning ż╬╠Į╦„?Ę©ż“═Ų£y
- 3. About me ? nagachika ? Ruby committer, Stable branch maintainer ? Fukuoka.rb organizer ? GCPUG ? TFUG (TensorFlow User Group) ? TensorFlow contributor Ī¹ NEW
- 4. Pull Requests to TensorFlow
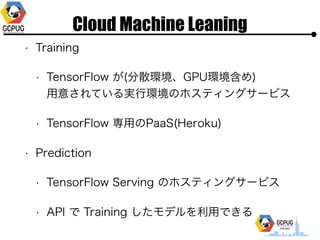
- 6. Cloud Machine Leaning ? Training ? TensorFlow ż¼(Ęų╔óŁhŠ│ĪóGPUŁhŠ│║¼żß)? ?ęŌżĄżņżŲżżżļīg?ŁhŠ│ż╬ź█ź╣źŲźŻź¾ź░źĄ®`źėź╣ ? TensorFlow ī¤?ż╬PaaS(Heroku) ? Prediction ? TensorFlow Serving ż╬ź█ź╣źŲźŻź¾ź░źĄ®`źėź╣ ? API żŪ Training żĘż┐źŌźŪźļż“└¹?żŪżŁżļ
- 8. Hyper Parameter Tuning ? Hyper Parameter ż╚żŽ? ? źŌźŪźļ(SVM, Random Forest, MLP, CNN Ą╚Ī®ż╩ż¾żŪżóżņ)ż╬č¦┴Ģż╦? Ž╚?ż├żŲøQČ©żĘż╩żżż╚żżż▒ż╩żżźčźķźß®`ź┐ ? źŌźŪźļż╬Š½Č╚ż╦ė░Ēæż╣żļ ? żĶżĻ┴╝żż Hyper Parameter ż╬╠Į╦„ż¼═¹ż▐żĘżż
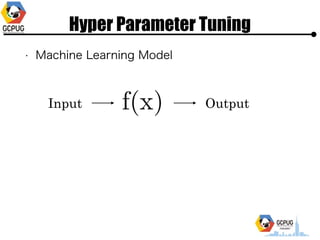
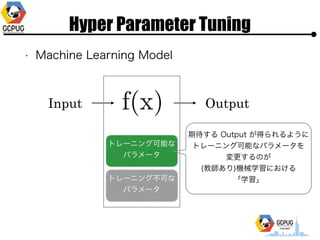
- 9. Hyper Parameter Tuning ? Machine Learning Model Input Output
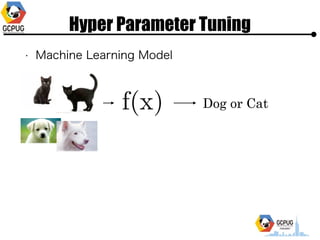
- 10. Hyper Parameter Tuning ? Machine Learning Model Dog or Cat
- 11. Hyper Parameter Tuning ? Machine Learning Model Input Output ź╚źņ®`ź╦ź¾ź░┐╔─▄ż╩ źčźķźß®`ź┐ ź╚źņ®`ź╦ź¾ź░▓╗┐╔ż╩ źčźķźß®`ź┐ Ų┌┤²ż╣żļ Output ż¼Ą├żķżņżļżĶż”ż╦? ź╚źņ®`ź╦ź¾ź░┐╔─▄ż╩źčźķźß®`ź┐ż“? ēõĖ³ż╣żļż╬ż¼? (Į╠ĤżóżĻ)ÖCąĄč¦┴Ģż╦ż¬ż▒żļ? ĪĖč¦┴ĢĪ╣
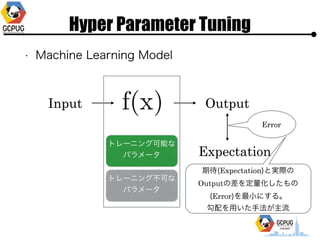
- 12. Hyper Parameter Tuning ? Machine Learning Model Input Output ź╚źņ®`ź╦ź¾ź░┐╔─▄ż╩ źčźķźß®`ź┐ ź╚źņ®`ź╦ź¾ź░▓╗┐╔ż╩ źčźķźß®`ź┐ Expectation Error Ų┌┤²(Expectation)ż╚īgļHż╬ Outputż╬▓Ņż“Č©┴┐╗»żĘż┐żŌż╬ (Error)ż“ūŅ?ż╦ż╣żļĪŻ? ╣┤┼õż“?żżż┐?Ę©ż¼ų„┴„
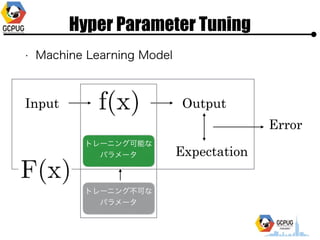
- 13. Hyper Parameter Tuning ? Machine Learning Model Input Output ź╚źņ®`ź╦ź¾ź░┐╔─▄ż╩ źčźķźß®`ź┐ ź╚źņ®`ź╦ź¾ź░▓╗┐╔ż╩ źčźķźß®`ź┐ Expectation Error
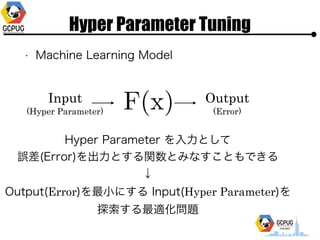
- 14. Hyper Parameter Tuning ? Machine Learning Model Input (Hyper Parameter) Output? (Error) Hyper Parameter ż“??ż╚żĘżŲ? š`▓Ņ(Error)ż“│÷?ż╚ż╣żļķv╩²ż╚ż▀ż╩ż╣ż│ż╚żŌżŪżŁżļ? Ī² Output(Error)ż“ūŅ?ż╦ż╣żļ Input(Hyper Parameter)ż“? ╠Į╦„ż╣żļūŅ▀m╗»å¢Ņ}
- 15. Hyper Parameter Tuning ? Machine Learning Model Input (Hyper Parameter) Output? (Error) ż┐ż└żĘĪó?░ŃĄ─ż╦ ? ╣┤┼õżŽż’ż½żķż╩żż(żĮżŌżĮżŌInputż¼ŠÓļxż╬Ė┼─Ņż¼żóżļ┐šķgż╚Ž▐żķż╩żż) ? F(x) ż╬įuü²ż╦żŽĢrķgż¼ż½ż½żļ
- 16. Hyper Parameter Tuning ? Derivative-free optimization? (╣┤┼õż╦żĶżķż╩żżūŅ▀m╗»?Ę©) ? Simulated Annealing(¤åżŁż╩ż▐żĘĘ©) ? Genetic Algorithm(▀zü╗Ą─źóźļź┤źĻź║źÓ) Ī· ?┴┐ż╬įć?ż¼▒žę¬żŪīg?ź│ź╣ź╚ż¼?żŁżż
- 17. Hyper Parameter Tuning ? Scikit learn ? Grid Search(ź░źĻź├ź╔źĄ®`ź┴) ? źčźķźß®`ź┐Ü░ż╦ėąŽ▐ż╬║“čaż╬ĮMż▀║Žż’ż╗įć? ? Random Search(źķź¾ź└źÓ╠Į╦„) Ī· źĘź¾źūźļż└ż▒ż╔żżż▐żżż┴┘tż»ż╩żż
- 18. Hyper Parameter Tuning Cloud Machine Learning ż╬? Hyper Parameter Tuning żŽ? ż╔ż¾ż╩?Ę©żŪ╠Į╦„ż“? żĘżŲżżżļż╬ż└żĒż”ż½?
- 19. Motivation
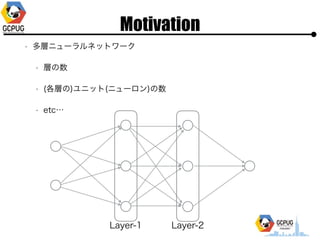
- 20. Motivation ? ČÓīėź╦źÕ®`źķźļź═ź├ź╚ź’®`ź» ? īėż╬╩² ? (Ė„īėż╬)źµź╦ź├ź╚(ź╦źÕ®`źĒź¾)ż╬╩² ? etcĪŁ Layer-1 Layer-2
- 21. Motivation ? īėż╬╩² ? (Ė„īėż╬)źµź╦ź├ź╚(ź╦źÕ®`źĒź¾)ż╬╩² ? 1ż─ż╬źčźķźß®`ź┐żŪ▒Ē¼FżĘż┐żżż╩ ? śOČ╚ż╦ČÓĘÕĄ─ż╩ķv╩²ż╦ż╩żĻżĮż”ĪŁ
- 22. Motivation ? ČÓĘÕąįķv╩²Ī·ūŅ▀m╗»ż¼└¦ļyż╩ąį┘| ? Cloud Machine Learning żŽż│ż¾ż╩ķv╩²ż╦īØżĘżŲ? ż╔ż╬ż»żķżż┘tż»ūŅ▀m╗»żĘżŲż»żņżļż¾ż└żĒż”? ģgĘÕąįķv╩² ČÓĘÕąįķv╩²
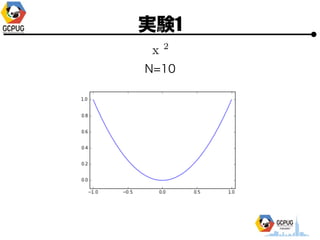
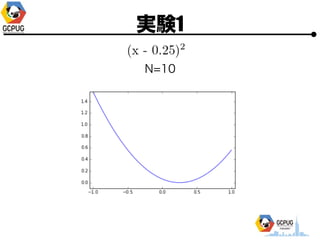
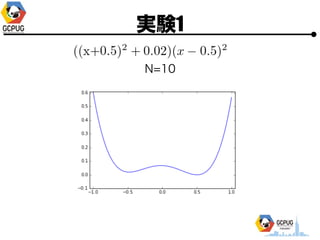
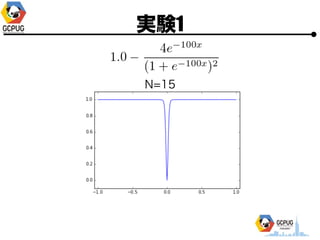
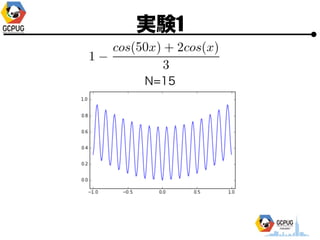
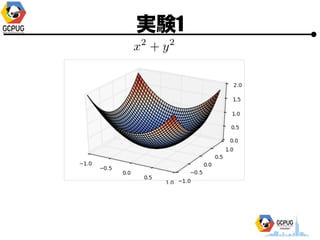
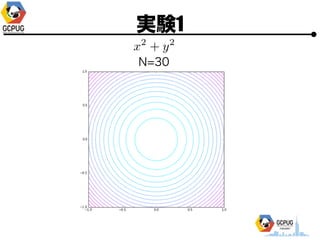
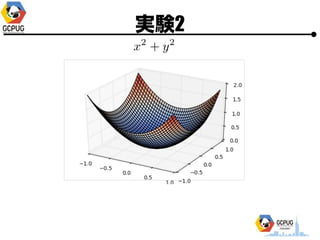
- 23. īg“Y1
- 24. īg“Y1 ? Cloud Machine Learning ż╦ Hyper Parameter Tuning żŪ ╝╚ų¬ż╬ķv╩²ż╬ūŅ▀m╗»ż“żĄż╗żļ ? F(x) ż“├„?Ą─ż╦╩Įż╚żĘżŲėļż©żļ ? Hyper Parameter ż“╩▄ż▒╚Īż├żŲ F(x) ż“ėŗ╦ŃżĘ żŲł¾Ėµż╣żļż└ż▒ż╬ Python źŌźĖźÕ®`źļż“ū„│╔
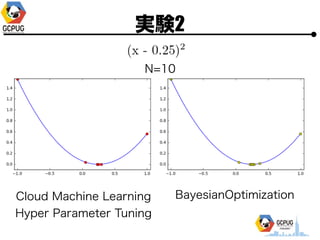
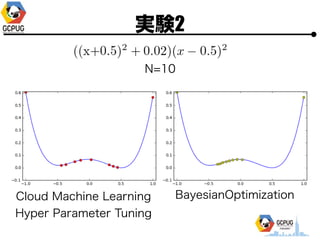
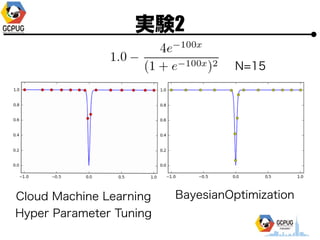
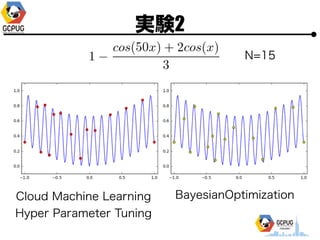
- 25. īg“Y1 ? Hyper Parameter ? 1ēõ╩²(x), 2ēõ╩²(x, y) ? ╣ĀćņżŽ╚½żŲ [-1, 1] ? ūŅ?éÄż“Ū¾żßżļ ? ╠Į╦„╗ž╩²(N)żŽ ? 1ēõ╩² Ī· N=10 or 15 ? 2ēõ╩² Ī· N=30
- 26. īg“Y1 N=10
- 27. īg“Y1 N=10
- 28. īg“Y1 N=10
- 29. īg“Y1 N=15
- 30. īg“Y1 N=15
- 31. īg“Y1
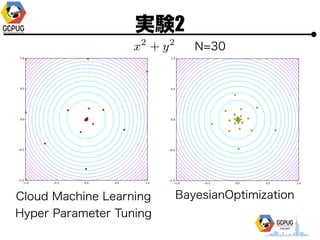
- 32. īg“Y1 N=30
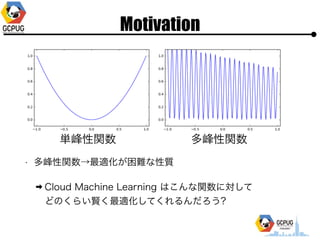
- 35. īg“Y1 ? żóżŁżķż½ż╦ Grid Search żŪżŽż╩żż ? Ą═┤╬į¬ż╬ČÓĒŚ╩Į(?)ż»żķżżż└ż╚ż½ż╩żĻ┘tżż? (╔┘ż╩żżįć?╗ž╩²żŪūŅ▀méÄż╬Į³ż»ż“Ą▒żŲżļ) ? ļyżĘżżą╬ū┤ż╬ķv╩²żŌżĮżņż╩żĻż╦? (?ė“╠Į╦„żĘżŲżżżļ? Šų╦∙ĮŌż╦┬õż┴ż┐żĻżŽż╩żĄżĮż”) ? ż╔ż”żõż├żŲżļż¾ż└żĒż”???
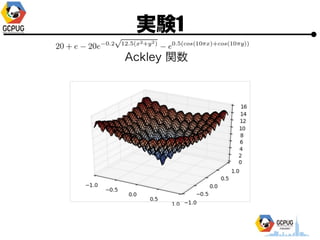
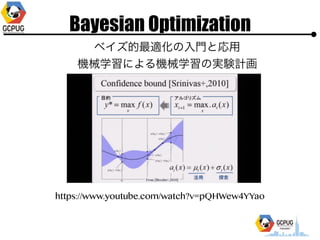
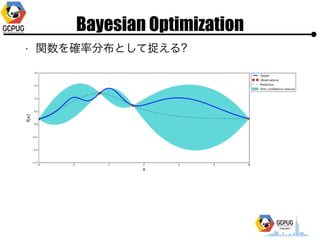
- 39. Bayesian Optimization ż¬ż¬żČż├żčż╩└ĒĮŌżŪżŽ ? ╝╚ż╦Ą├ż┐??ż╬ĮY╣¹ż“į¬ż╦═Ų£yżĘż─ż─ ? ż▐ż└š{ż┘żŲż╩żżżóż┐żĻżŌš{ż┘żļżĶż”ż╦żĘż─ż─ żżżżĖążĖż╦╠Į╦„ż╣żļż┐żßż╦Īó? ūŅ▀m╗»żĘż┐żżķv╩²ż╬ą╬ū┤ż“(Ė„??ż╦īØż╣żļ)? ┤_┬╩Ęų▓╝ż╚żĘżŲūĮż©żļĪŻ
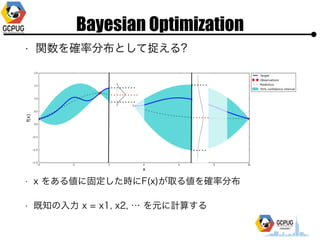
- 41. Bayesian Optimization ? ķv╩²ż“┤_┬╩Ęų▓╝ż╚żĘżŲūĮż©żļ? ? x ż“żóżļéÄż╦╣╠Č©żĘż┐Ģrż╦F(x)ż¼╚ĪżļéÄż“┤_┬╩Ęų▓╝ ? ╝╚ų¬ż╬?? x = x1, x2, ĪŁ ż“į¬ż╦ėŗ╦Ńż╣żļ
- 42. Bayesian Optimization ? Acquisition function ? ┤╬ż╦źŲź╣ź╚ż╣ż┘żŁĄŃż“øQżßżļż┐żßż╬? ĪĖųžę¬Č╚Ī╣ż▀ż┐żżż╩ż╬ż“øQżßżļķv╩² ? GP-UCB ŲĮŠ∙ Ęų╔ó = ╗Ņ? = ╠Į╦„
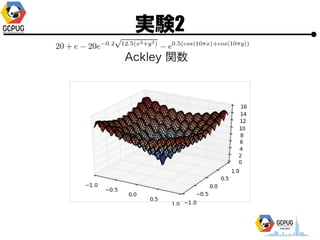
- 43. īg“Y2
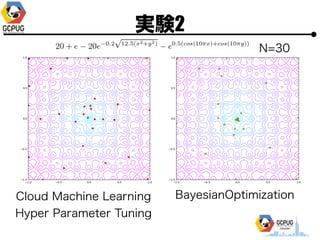
- 44. īg“Y2 ? īg“Y1ż╚═¼żĖF(x)ż╦īØżĘżŲ Bayesian Optimization ? ūŅ│§ż╬3ĄŃżŽīg“Y1ż╬(Cloud MLż╬)ĮY╣¹ż“┴„?? (Bayesian Optimization żŽ│§Ų┌║╬ĄŃż½żŽźķź¾ź└źÓ╠Į╦„) ? Pythonż╬BayesianOptimizationźčź├ź▒®`źĖż“└¹?? [https://github.com/fmfn/BayesianOptimization] ? Acquisition function ż╦żŽ GP-UCB, kappa=0.5 ż“▀xÆk
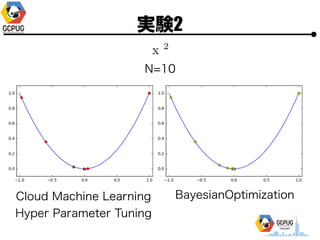
- 45. īg“Y2 N=10 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 46. īg“Y2 N=10 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 47. īg“Y2 N=10 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 48. īg“Y2 N=15 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 49. īg“Y2 N=15 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 50. īg“Y2
- 51. īg“Y2 N=30 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 53. īg“Y2 N=30 Cloud Machine Learning Hyper Parameter Tuning BayesianOptimization
- 54. īg“Y2 ? Bayesian Optimization > Grid Search ? Cloud Machine Learning ż╬ Hyper Parameter Tuning ż╚╦ŲżŲżżżļż╚żżż©ż╩ż»żŌż╩żż? ? Bayesian Optimization?╠Õż╦żŌ? Hyper Parameterż¼żóżļ(acquisition function ż╬▀xÆk, żĮż╬źčźķźß®`ź┐ etc..)
- 55. Summary ? Cloud Machine Learning ż╬Hyper Parameter Tuning żŽż½żĘż│ż»żŲ▒Ń└¹ ? Hyper Parameter ż╦īØżĘżŲč}ļjż╩ķv╩²ż╦ż╩żļĢrżŽ? ČÓżßż╦įć?╗ž╩²ż“╚ĪżĒż” ? Hyper Parameter Tuning ż╬čYé╚żŽ? Bayesian Optimization? ? ???? Cloud Machine Learning ż╬śŗ║BżŌē¶żŪżŽ ż╩żż!?