















![1. R で文字列処理
> alice <- readLines(“alice.txt”)
> #readLines() で1行ずつ読み込み
> head(alice, 50) #50行目までを表示
> grep(“THE END”, alice) #grep() で検索
> alice[3365:3375] #3370前後を表示して確認
> alice2 <- alice[41:3370] #本文のみを代入
> head(alice2) #念のため確認
19Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-16-320.jpg)
![1. R で文字列処理
> alice.words <- unlist (strsplit (alice2, split =
”[[:space:]]+|[[:punct:]]+”))
> #空白類?ピリオド?カンマなどが1つ以上続
く部分を区切りとして文字列を切り出し
> length(alice.words)
> #句読点を省いた単語数を抽出
20Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-17-320.jpg)
![1. R で文字列処理
> head(alice.words)
> sum(alice.words ==“”)
> #句読点とスペースが連続して並んだ場合,
区切った際にそこは無(空)となる
> alice.words2 <- alice.words[alice.words !=“”]
> # 区切った結果空となる場合を除いて,新た
な変数を作って再代入
> length(alice.words2)
21Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-18-320.jpg)
![1. R で文字列処理
> sum (alice.words2 ==“the”)
> #“the”の頻度を求める
> alice.freq <- as.data.frame (table (alice.words2))
> #頻度表の作成
> alice.sorted <- alice.freq [ order (alice.freq$Freq,
decreasing = TRUE), ]
> # order() 関数で頻度の高い順に並び替え
> nrow(alice.sorted) #行数が語彙(type)数
22Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-19-320.jpg)






![4) 数値を求める
> length(nns_unlist)
[1] 70220 # Token
> nns_all <- table(nns_unlist)
# 単語一覧表の作成
> nns_type <- length(uniq_nns)
> nns_type
[1] 7579 # Type
31Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-28-320.jpg)







![> length(grep("^And,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 175
> length(grep("^But,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 178
> length(grep("^and,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 1479
> length(grep("^but,?", nns_unlist, fixed = FALSE, value=TRUE))
[1] 260
R による and と but の検索
41Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-38-320.jpg)





![> install.packages(“Snowball”) #インスール
> library(Snowball) #読み込み
> alice.sn <- SnowballStemmer(tolower(alice.words))
> #小文字に変換後,stemming を実行(し,結果を代入)
> alice.sn.freq <- as.data.frame(table(alice.sn))
> # 横並びの表を縦並びに
> alice.sn.sorted <- alice.sn.freq[order(alice.sn.freq
$alice.sn),]
> #alice.sn.freq 内のalice.sn 列で並び替え(アルファベット順)
>head(alice.sn.sorted)
実演: Snowball package
48Sunday, October 6, 13](https://image.slidesharecdn.com/jaecs2013sendaiday2-131005233249-phpapp01/85/R-45-320.jpg)














统计解析环境搁による言语データの分析
- 1. 2013-10-06 JAECS2013@Tohoku Univ. 統計解析環境 による言語データの分析 1Sunday, October 6, 13
- 7. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 10Sunday, October 6, 13
- 8. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 11Sunday, October 6, 13
- 9. 1. R で文字列処理 つなげて数える (頻度表作成) 12Sunday, October 6, 13
- 10. pp.87-100 を真似てみる 13Sunday, October 6, 13
- 11. 1. R で文字列処理 > sample <-“DONE IS BETTER THAN PERFECT” > length(sample) #要素数 > nchar(sample) #文字数(空白類含む) > x <- c(“ABC”,“efg”) #2つの文字列 > length(x) #要素数 > nchar(x) #文字数(各要素に対して) 14Sunday, October 6, 13
- 12. 1. R で文字列処理 > tolower(sample) #大文字を小文字に変換 > toupper(x) #小文字を大文字に変換 > toupper(tolower(sample)) #連続処理1 > tolower(toupper(tolower(sample))) #連続処理2 > #丸括弧の数に注意 15Sunday, October 6, 13
- 13. 1. R で文字列処理 > steve <- c(“No one wants to die.”,“Even people who want to go to heaven don't want to die to get there.”) > length(steve) # 要素数 > nchar(steve) # 文字数 > strsplit(steve,““) #文字列を空白で切り分け http://news.stanford.edu/news/2005/june15/jobs-061505.html 16Sunday, October 6, 13
- 14. 1. R で文字列処理 > steve2 <- unlist(strsplit(steve,““)) > #リスト内の要素を結合し1つのベクトルに > steve2 > length(steve2) > table(steve2) #頻度表を作成 > as.data.frame(table(steve2)) #表を縦に http://news.stanford.edu/news/2005/june15/jobs-061505.html 17Sunday, October 6, 13
- 16. 1. R で文字列処理 > alice <- readLines(“alice.txt”) > #readLines() で1行ずつ読み込み > head(alice, 50) #50行目までを表示 > grep(“THE END”, alice) #grep() で検索 > alice[3365:3375] #3370前後を表示して確認 > alice2 <- alice[41:3370] #本文のみを代入 > head(alice2) #念のため確認 19Sunday, October 6, 13
- 17. 1. R で文字列処理 > alice.words <- unlist (strsplit (alice2, split = ”[[:space:]]+|[[:punct:]]+”)) > #空白類?ピリオド?カンマなどが1つ以上続 く部分を区切りとして文字列を切り出し > length(alice.words) > #句読点を省いた単語数を抽出 20Sunday, October 6, 13
- 18. 1. R で文字列処理 > head(alice.words) > sum(alice.words ==“”) > #句読点とスペースが連続して並んだ場合, 区切った際にそこは無(空)となる > alice.words2 <- alice.words[alice.words !=“”] > # 区切った結果空となる場合を除いて,新た な変数を作って再代入 > length(alice.words2) 21Sunday, October 6, 13
- 19. 1. R で文字列処理 > sum (alice.words2 ==“the”) > #“the”の頻度を求める > alice.freq <- as.data.frame (table (alice.words2)) > #頻度表の作成 > alice.sorted <- alice.freq [ order (alice.freq$Freq, decreasing = TRUE), ] > # order() 関数で頻度の高い順に並び替え > nrow(alice.sorted) #行数が語彙(type)数 22Sunday, October 6, 13
- 20. 1. R で文字列処理 ? つなげる?区切る?置換するが基本 ? 処理手順?方法は1つに限らない ? まだレマ化が必要 ? Snowballパッケージで対応可能 23Sunday, October 6, 13
- 21. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 24Sunday, October 6, 13
- 22. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 25Sunday, October 6, 13
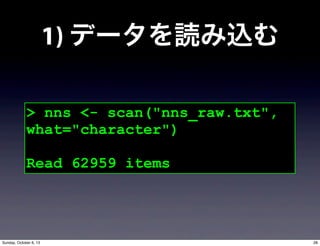
- 24. 2. 言語データ処理の流れ 1) データを読み込む 2) データを分解する 3) データを える 4) 数値を求める 5) データを保存する 27Sunday, October 6, 13
- 25. 1) データを読み込む > nns <- scan("nns_raw.txt", what="character") Read 62959 items 28Sunday, October 6, 13
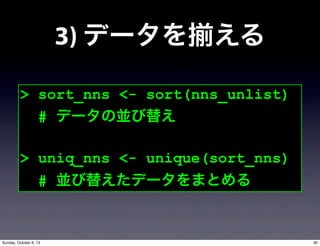
- 26. 2) データを分解する > nns_list <- strsplit(nns, " ") # スペースでデータをリスト化 # 干し柿状態(?) > nns_unlist <- unlist(nns_list) # リストされたデータをバラバラに分解 29Sunday, October 6, 13
- 27. 3) データを える > sort_nns <- sort(nns_unlist) # データの並び替え > uniq_nns <- unique(sort_nns) # 並び替えたデータをまとめる 30Sunday, October 6, 13
- 28. 4) 数値を求める > length(nns_unlist) [1] 70220 # Token > nns_all <- table(nns_unlist) # 単語一覧表の作成 > nns_type <- length(uniq_nns) > nns_type [1] 7579 # Type 31Sunday, October 6, 13
- 29. 5) データを保存する > write.table(nns_all, file="freq.txt", sep="t") # freq.txt という名で列をタブ区切りにして保存 32Sunday, October 6, 13
- 30. ? どんな言語?ソフトでも裏でこうした 処理(特に 1)~3))をしている ? その過程で<穴>がないか用心したい ? やはりレマ化はしていないので注意 2. 言語データ処理の流れ 33Sunday, October 6, 13
- 31. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 34Sunday, October 6, 13
- 32. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 35Sunday, October 6, 13
- 33. 実習 36Sunday, October 6, 13
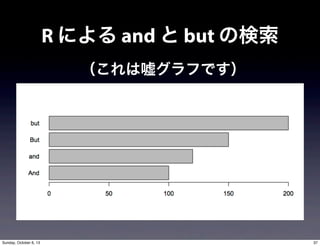
- 34. R による and と but の検索 (これは嘘グラフです) 37Sunday, October 6, 13
- 35. R による and と but の検索 ? And/and, But/but の検索結果を棒グラフで可視化 ? nns_raw.txt を加工し単語に切り分ける ? 切り分けたものから検索をかける(正規表現) ? 処理に使う関数(データ読み込みもお忘れなく) ? strsplit(), unlist(), grep(), length(), barplot() ? 変数の中身を随時確認する ? R は一度初期化して(保存せず)取り組みましょう 38Sunday, October 6, 13
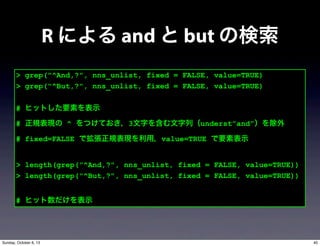
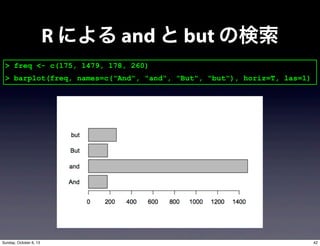
- 37. > grep("^And,?", nns_unlist, fixed = FALSE, value=TRUE) > grep("^But,?", nns_unlist, fixed = FALSE, value=TRUE) # ヒットした要素を表示 # 正規表現の ^ をつけておき,3文字を含む文字列(underst”and”)を除外 # fixed=FALSE で拡張正規表現を利用,value=TRUE で要素表示 > length(grep("^And,?", nns_unlist, fixed = FALSE, value=TRUE)) > length(grep("^But,?", nns_unlist, fixed = FALSE, value=TRUE)) # ヒット数だけを表示 R による and と but の検索 40Sunday, October 6, 13
- 38. > length(grep("^And,?", nns_unlist, fixed = FALSE, value=TRUE)) [1] 175 > length(grep("^But,?", nns_unlist, fixed = FALSE, value=TRUE)) [1] 178 > length(grep("^and,?", nns_unlist, fixed = FALSE, value=TRUE)) [1] 1479 > length(grep("^but,?", nns_unlist, fixed = FALSE, value=TRUE)) [1] 260 R による and と but の検索 41Sunday, October 6, 13
- 39. > freq <- c(175, 1479, 178, 260) > barplot(freq, names=c("And", "and", "But", "but"), horiz=T, las=1) R による and と but の検索 42Sunday, October 6, 13
- 40. ? R で基本的な検索?分析ならば... 1) データを strsplit() + unlist() して 2) grep() と length() でカウント 3) barplot() などで視覚化 4) chisq.test() などで検定 R による and と but の検索 43Sunday, October 6, 13
- 41. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 44Sunday, October 6, 13
- 42. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 45Sunday, October 6, 13
- 43. Packageとは? ? ある処理?機能に特化したプログラム ? base(基本パッケージ)だけでも 1,000 以上 ? 特殊な処理を行う際は,別の package を追加 ? 言語処理に特化したものもある(ex. RMeCab) 46Sunday, October 6, 13
- 44. 実演: Snowball package ? 活用形を原形をまとめる機能 ? stemming と呼ばれる(cf. lemmatization) ? 辞書情報と照合し変換するような処理 ? 実際はより高度な処理(ですがそこはお任せ) 47Sunday, October 6, 13
- 45. > install.packages(“Snowball”) #インスール > library(Snowball) #読み込み > alice.sn <- SnowballStemmer(tolower(alice.words)) > #小文字に変換後,stemming を実行(し,結果を代入) > alice.sn.freq <- as.data.frame(table(alice.sn)) > # 横並びの表を縦並びに > alice.sn.sorted <- alice.sn.freq[order(alice.sn.freq $alice.sn),] > #alice.sn.freq 内のalice.sn 列で並び替え(アルファベット順) >head(alice.sn.sorted) 実演: Snowball package 48Sunday, October 6, 13
- 46. i) tm: Text Mining Package ? http://tm.r-forge.r-project.org/ ? http://cran.r-project.org/web/packages/tm/tm.pdf ii) corpora ? http://www.stefan-evert.de/SIGIL/sigil_R/ ? http://cran.r-project.org/web/packages/corpora/corpora.pdf iii) LanguageR ? http://www.ualberta.ca/~baayen/software.html ? http://cran.r-project.org/web/packages/languageR/languageR.pdf 言語処理に特化した packages 49Sunday, October 6, 13
- 48. RMeCabとは ? 石田 基広氏が開発したパッケージ ? R から MeCab を呼び出して日本語 のテキストを解析させる ? 解析結果をも R で出力してくれる 素晴らしいプログラム 51Sunday, October 6, 13
- 49. デモ一覧 ?RMeCabText() : ファイル解析 ?RMeCabFreq() : 頻度集計 ?Ngram() : N-gram 解析 ?collocate() : 共起関係の分析 52Sunday, October 6, 13
- 50. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 53Sunday, October 6, 13
- 51. Agenda 1. R で文字列処理 2. 言語データ処理の流れ 3. R による and と but の検索 4. パッケージ利用によるデータ処理 5. おわりに 54Sunday, October 6, 13
- 54. のススメ 57Sunday, October 6, 13
- 55. ? すべての処理?分析が R のみで完結 ? <-> Concordancer + Editor + Excel (+ UNIX) + R ? プログラミングの基礎養成に有効 ? --> Python, Perl, ... どこでも使える ? 作図が美しい(+Mac ならフォントも) ? Excel の作図はオモチャ のススメ 58Sunday, October 6, 13
- 56. 参考文献 61Sunday, October 6, 13
- 57. 参考文献(続) 63Sunday, October 6, 13
- 58. 参考文献(続) 64Sunday, October 6, 13
- 59. Enjoy ! twitter: @sakaue e-mail: tsakaue<AT>hiroshima-u.ac.jp 65Sunday, October 6, 13