






























kubernetes : From beginner to Advanced
- 1. Copyright ┬® 2017, Oracle and/or its affiliates. All rights reserved. | Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 1 th Ļ░ĢņØĖĒśĖ inho.kang@oracle.com Kubernetes : from Beginner to Advanced 2019.03.16 9th Oracle Developer Meetup
- 2. Copyright ┬® 2017, Oracle and/or its affiliates. All rights reserved. | Safe Harbor Statement The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into any contract. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described for OracleŌĆÖs products remains at the sole discretion of Oracle. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 2
- 3. ┬¦ .Net Developer ┬¦ CBD, SOA Methodology Consulting ┬¦ ITA/EA, ISP Consulting ┬¦ Oracle Corp. ┬¦ Middleware ┬¦ Cloud Native Application, Container Native ┬¦ Emerging Technology Team ┬¦ k8s korea user group innoshom@gamil.com
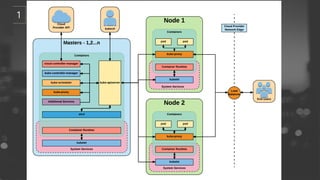
- 4. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 4 Kubernetes Concept
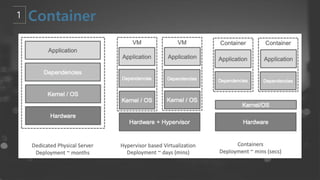
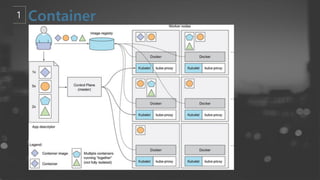
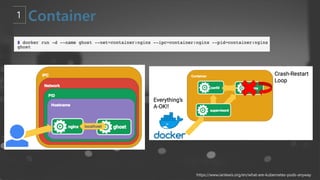
- 6. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 6 Kubernetes Concept - Container
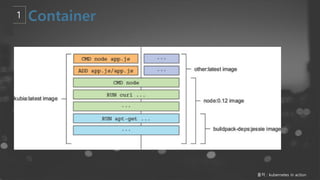
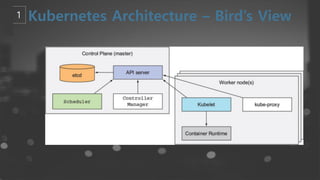
- 8. ņČ£ņ▓ś : kubernetes in action
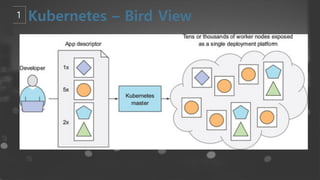
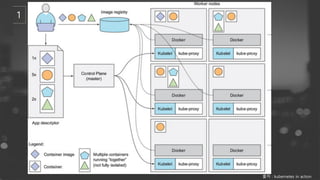
- 13. ņČ£ņ▓ś : kubernetes in action
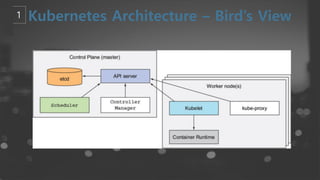
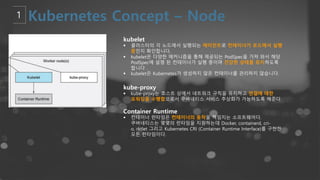
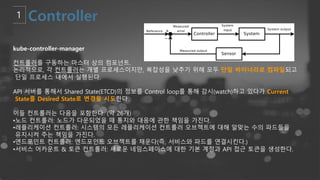
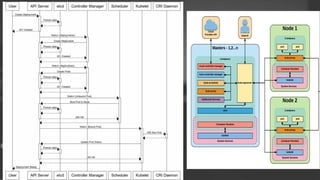
- 15. kube-apiserver ┬¦ ņ┐Āļ▓äļäżĒŗ░ņŖż APIļź╝ ļģĖņČ£ĒĢśļŖö ļ¦łņŖżĒä░ ņāüņØś ņ╗┤ĒżļäīĒŖĖ. ņ┐Āļ▓äļäżĒŗ░ņŖż ņ╗©ĒŖĖļĪż ĒöīļĀłņØĖņŚÉ ļīĆĒĢ£ ĒöäļĪĀĒŖĖņŚöļō£ņØ┤ļŗż. ┬¦ ņłśĒÅēņĀü ņŖżņ╝ĆņØ╝(ņ”ē, ļŹö ļ¦ÄņØĆ ņØĖņŖżĒä┤ņŖżļź╝ ļööĒöīļĪ£ņØ┤ĒĢśļŖö ņŖżņ╝ĆņØ╝)ņØä ņ£äĒĢ┤ ņäżĻ│äļÉśņŚłļŗż. etcd ┬¦ ļ¬©ļōĀ Ēü┤ļ¤¼ņŖżĒä░ ļŹ░ņØ┤Ēä░ļź╝ ļŗ┤ļŖö ņ┐Āļ▓äļäżĒŗ░ņŖż ļÆĘļŗ©ņØś ņĀĆņןņåīļĪ£ ņé¼ņÜ®ļÉśļŖö ņØ╝Ļ┤Ćņä▒┬ĘĻ│ĀĻ░ĆņÜ®ņä▒ Ēéż-Ļ░Æ ņĀĆņןņåī. ┬¦ ņ┐Āļ▓äļäżĒŗ░ņŖż Ēü┤ļ¤¼ņŖżĒä░ ņĀĢļ│┤ļź╝ ļŗ┤Ļ│Ā ņ׳ļŖö etcd ļŹ░ņØ┤Ēä░ņŚÉ ļīĆĒĢ£ ļ░▒ņŚģ Ļ│äĒÜŹņØĆ ĒĢäņłśņØ┤ļŗż. kube-scheduler ┬¦ ļģĖļō£Ļ░Ć ļ░░ņĀĢļÉśņ¦Ć ņĢŖņØĆ ņāłļĪ£ ņāØņä▒ļÉ£ Ēīīļō£ļź╝ Ļ░Éņ¦ĆĒĢśĻ│Ā ĻĘĖĻ▓āņØ┤ ĻĄ¼ļÅÖļÉĀ ļģĖļō£ļź╝ ņäĀĒāØĒĢśļŖö ļ¦łņŖżĒä░ ņāüņØś ņ╗┤ĒżļäīĒŖĖ. ┬¦ ņŖżņ╝Ćņżäļ¦ü Ļ▓░ņĀĢņØä ņ£äĒĢ£ ņ¢┤ņ╣┤ņÜ┤ĒŖĖ ļé┤ ņÜöņåīļōżļĪ£ļŖö Ļ░£ļ│ä ļ░Å Ļ│ĄļÅÖņØś ļ”¼ņåīņŖż ņÜöĻ▒┤, ĒĢśļō£ņø©ņ¢┤/ņåīĒöäĒŖĖņø©ņ¢┤/ņĀĢņ▒ģ ņĀ£ņĢĮ, ņ╣£ļ░Ć ļ░Å ļ░░Ļ▓® ļ¬ģņäĖ, ļŹ░ņØ┤Ēä░ ņ¦ĆņŚŁņä▒, ņøīĒü¼ļĪ£ļō£-Ļ░ä Ļ░äņäŁ, ļŹ░ļō£ļØ╝ņØĖļōżņØ┤ ĒżĒĢ©ļÉ£ļŗż. kube-controller-manager ┬¦ ņ╗©ĒŖĖļĪżļ¤¼ļź╝ ĻĄ¼ļÅÖĒĢśļŖö ļ¦łņŖżĒä░ ņāüņØś ņ╗┤ĒżļäīĒŖĖ. ┬¦ ļģ╝ļ”¼ņĀüņ£╝ļĪ£, Ļ░ü ņ╗©ĒŖĖļĪżļ¤¼ļŖö Ļ░£ļ│ä ĒöäļĪ£ņäĖņŖżņØ┤ņ¦Ćļ¦ī, ļ│Ąņ×Īņä▒ņØä ļé«ņČöĻĖ░ ņ£äĒĢ┤ ļ¬©ļæÉ ļŗ©ņØ╝ ļ░öņØ┤ļäłļ”¼ļĪ£ ņ╗┤ĒīīņØ╝ļÉśĻ│Ā ļŗ©ņØ╝ ĒöäļĪ£ņäĖņŖż ļé┤ņŚÉņä£ ņŗżĒ¢ēļÉ£ļŗż. ┬¦ ļģĖļō£ ņ╗©ĒŖĖļĪżļ¤¼: ļģĖļō£Ļ░Ć ļŗżņÜ┤ļÉśņŚłņØä ļĢī ĒåĄņ¦ĆņÖĆ ļīĆņØæņŚÉ Ļ┤ĆĒĢ£ ņ▒ģņ×äņØä Ļ░Ćņ¦äļŗż. ┬¦ ļĀłĒöīļ”¼ņ╝ĆņØ┤ņģś ņ╗©ĒŖĖļĪżļ¤¼: ņĢīļ¦×ļŖö ņłśņØś Ēīīļō£ļōżņØä ņ£Āņ¦Ćņŗ£ņ╝£ ņŻ╝ļŖö ņ▒ģņ×äņØä Ļ░Ćņ¦äļŗż. ┬¦ ņŚöļō£ĒżņØĖĒŖĖ ņ╗©ĒŖĖļĪżļ¤¼: ņä£ļ╣äņŖżņÖĆ Ēīīļō£ļź╝ ņŚ░Ļ▓░ņŗ£Ēé©ļŗż
- 16. kubelet ┬¦ Ēü┤ļ¤¼ņŖżĒä░ņØś Ļ░ü ļģĖļō£ņŚÉņä£ ņŗżĒ¢ēļÉśļŖö ņŚÉņØ┤ņĀäĒŖĖļĪ£ ņ╗©ĒģīņØ┤ļäłĻ░Ć Ēżļō£ņŚÉņä£ ņŗżĒ¢ē ņżæņØĖņ¦Ć ĒÖĢņØĖĒĢ®ļŗłļŗż. ┬¦ kubeletņØĆ ļŗżņ¢æĒĢ£ ļ®öņ╗żļŗłņ”śņØä ĒåĄĒĢ┤ ņĀ£Ļ│ĄļÉśļŖö PodSpecņØä Ļ░ĆņĀĖ ņÖĆņä£ ĒĢ┤ļŗ╣ PodSpecņŚÉ ņäżļ¬ģ ļÉ£ ņ╗©ĒģīņØ┤ļäłĻ░Ć ņŗżĒ¢ē ņżæņØ┤ļ®░ Ļ▒┤Ļ░ĢĒĢ£ ņāüĒā£ļź╝ ņ£Āņ¦ĆĒĢśļÅäļĪØ ĒĢ®ļŗłļŗż . ┬¦ kubeletņØĆ KubernetesĻ░Ć ņāØņä▒ĒĢśņ¦Ć ņĢŖņØĆ ņ╗©ĒģīņØ┤ļäłļź╝ Ļ┤Ćļ”¼ĒĢśņ¦Ć ņĢŖņŖĄļŗłļŗż. kube-proxy ┬¦ kube-proxyļŖö ĒśĖņŖżĒŖĖ ņāüņŚÉņä£ ļäżĒŖĖņøīĒü¼ ĻĘ£ņ╣ÖņØä ņ£Āņ¦ĆĒĢśĻ│Ā ņŚ░Ļ▓░ņŚÉ ļīĆĒĢ£ Ēżņøīļö®ņØä ņłśĒ¢ēĒĢ©ņ£╝ļĪ£ņä£ ņ┐Āļ▓äļäżĒŗ░ņŖż ņä£ļ╣äņŖż ņČöņāüĒÖöĻ░Ć Ļ░ĆļŖźĒĢśļÅäļĪØ ĒĢ┤ņżĆļŗż. Container Runtime ┬¦ ņ╗©ĒģīņØ┤ļäł ļ¤░ĒāĆņ×äņØĆ ņ╗©ĒģīņØ┤ļäłņØś ļÅÖņ×æņØä ņ▒ģņ×äņ¦ĆļŖö ņåīĒöäĒŖĖņø©ņ¢┤ļŗż. ņ┐Āļ▓äļäżĒŗ░ņŖżļŖö ļ¬ćļ¬ćņØś ļ¤░ĒāĆņ×äņØä ņ¦ĆņøÉĒĢśļŖöļŹ░ Docker, containerd, cri- o, rktlet ĻĘĖļ”¼Ļ│Ā Kubernetes CRI (Container Runtime Interface)ļź╝ ĻĄ¼ĒśäĒĢ£ ļ¬©ļōĀ ļ¤░ĒāĆņ×äņØ┤ļŗż.
- 17. OCI ?
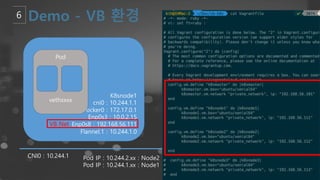
- 18. Pod IP : 10.244.2.xx : Node2 Pod IP : 10.244.1.xx : Node1 K8snode1 cni0 : 10.244.1.1 Docker0 : 172.17.0.1 Enp0s3 : 10.0.2.15 Enp0s8 : 192.168.56.111 Flannel.1 : 10.244.1.0 Pod vethxxxx CNI0 : 10.244.1 VB Net
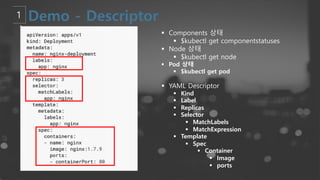
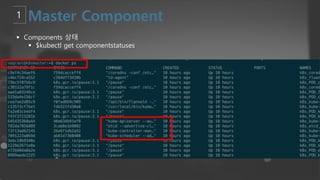
- 19. ┬¦ Components ņāüĒā£ ┬¦ $kubectl get componentstatuses ┬¦ Node ņāüĒā£ ┬¦ $kubectl get node ┬¦ Pod ņāüĒā£ ┬¦ $kubectl get pod
- 20. ┬¦ YAML Descriptor ┬¦ Kind ┬¦ Label ┬¦ Replicas ┬¦ Selector ┬¦ MatchLabels ┬¦ MatchExpression ┬¦ Template ┬¦ Spec ┬¦ Container ┬¦ Image ┬¦ ports ┬¦ Components ņāüĒā£ ┬¦ $kubectl get componentstatuses ┬¦ Node ņāüĒā£ ┬¦ $kubectl get node ┬¦ Pod ņāüĒā£ ┬¦ $kubectl get pod
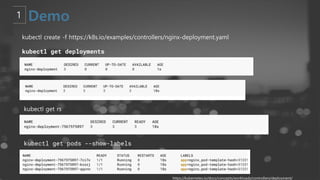
- 21. kubectl create -f https://k8s.io/examples/controllers/nginx-deployment.yaml kubectl get rs kubectl get deployments kubectl get pods --show-labels https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
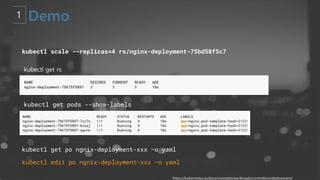
- 22. kubectl get rs kubectl scale --replicas=4 rs/nginx-deployment-75bd58f5c7 kubectl get pods --show-labels https://kubernetes.io/docs/concepts/workloads/controllers/deployment/ kubectl get po ngnix-deployment-xxx ŌĆōo yaml kubectl edit po ngnix-deployment-xxx ŌĆōo yaml
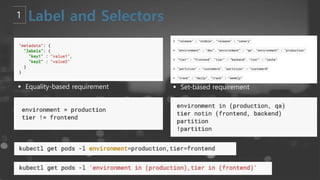
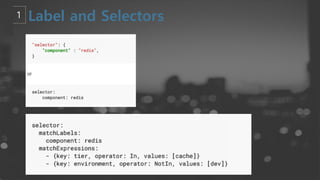
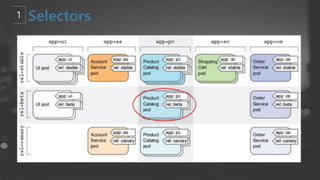
- 23. ┬¦ Equality-based requirement ┬¦ Set-based requirement
- 27. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 27 Dive into Kubernetes Internal
- 29. ┬¦ Deployment -> ReplicatSet -> ┬¦ Pods
- 30. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 30 Dive into Kubernetes Internal - Pod
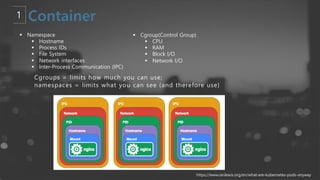
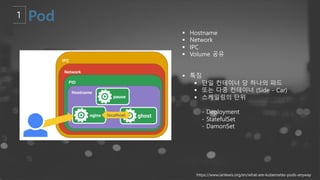
- 33. ┬¦ Namespace ┬¦ Hostname ┬¦ Process IDs ┬¦ File System ┬¦ Network interfaces ┬¦ Inter-Process Communication (IPC) ┬¦ Cgroup(Control Group) ┬¦ CPU ┬¦ RAM ┬¦ Block I/O ┬¦ Network I/O Cgroups = limits how much you can use; namespaces = limits what you can see (and therefore use) https://www.ianlewis.org/en/what-are-kubernetes-pods-anyway
- 35. ┬¦ Hostname ┬¦ Network ┬¦ IPC ┬¦ Volume Ļ│Ąņ£Ā ┬¦ ĒŖ╣ņ¦Ģ ┬¦ ļŗ©ņØ╝ ņ╗©ĒģīņØ┤ļäł ļŗ╣ ĒĢśļéśņØś Ēīīļō£ ┬¦ ļśÉļŖö ļŗżņżæ ņ╗©ĒģīņØ┤ļäł (Side - Car) ┬¦ ņŖżņ╝ĆņØ╝ļ¦üņØś ļŗ©ņ£ä - Deployment - StatefulSet - DamonSet https://www.ianlewis.org/en/what-are-kubernetes-pods-anyway
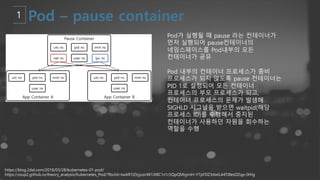
- 36. https://blog.2dal.com/2018/03/28/kubernetes-01-pod/ https://ssup2.github.io/theory_analysis/Kubernetes_Pod/?fbclid=IwAR1IZtyjusnW1iX8C1s1c5QpQMigmiH-Y7pFDZ3dwtL44TJ8esDZqp-lXHg PodĻ░Ć ņŗżĒ¢ēļÉĀ ļĢī pause ļØ╝ļŖö ņ╗©ĒģīņØ┤ļäłĻ░Ć ļ©╝ņĀĆ ņŗżĒ¢ēļÉśņ¢┤ pauseņ╗©ĒģīņØ┤ļäłņØś ļäżņ×äņŖżĒÄśņØ┤ņŖżļź╝ Podļé┤ļČĆņØś ļ¬©ļōĀ ņ╗©ĒģīņØ┤ļäłĻ░Ć Ļ│Ąņ£Ā Pod ļé┤ļČĆņØś ņ╗©ĒģīņØ┤ļäł ĒöäļĪ£ņäĖņŖżĻ░Ć ņóĆļ╣ä ĒöäļĪ£ņäĖņŖżĻ░Ć ļÉśņ¦Ć ņĢŖļÅäļĪØ pause ņ╗©ĒģīņØ┤ļäłļŖö PID 1ļĪ£ ņäżņĀĢļÉśņ¢┤ ļ¬©ļōĀ ņ╗©ĒģīņØ┤ļäł ĒöäļĪ£ņäĖņŖżņØś ļČĆļ¬© ĒöäļĪ£ņäĖņŖżĻ░Ć ļÉśĻ│Ā, ņ╗©ĒģīņØ┤ļäł ĒöäļĪ£ņäĖņŖżņØś ļ¼ĖņĀ£Ļ░Ć ļ░£ņāØĒĢ┤ SIGHLD ņŗ£ĻĘĖļäÉņØä ļ░øņ£╝ļ®┤ waitpid(ĒĢ┤ļŗ╣ ĒöäļĪ£ņäĖņŖż ID)ļź╝ ņłśĒ¢ēĒĢ┤ņä£ ņżæņ¦ĆļÉ£ ņ╗©ĒģīņØ┤ļäłĻ░Ć ņé¼ņÜ®ĒĢśļŹś ņ×ÉņøÉņØä ĒÜīņłśĒĢśļŖö ņŚŁĒĢĀņØä ņłśĒ¢ē
- 37. ┬¦ Liveness probe ┬¦ Readyness probe ŌĆō p 152
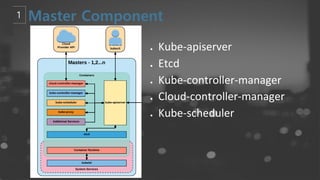
- 38. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 38 Master Component
- 39. ŌŚÅ Kube-apiserver ŌŚÅ Etcd ŌŚÅ Kube-controller-manager ŌŚÅ Cloud-controller-manager ŌŚÅ Kube-scheduler
- 40. ┬¦ Components ņāüĒā£ ┬¦ $kubectl get componentstatuses
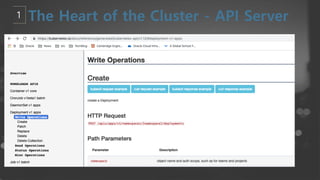
- 41. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 41 Master Component - API Server
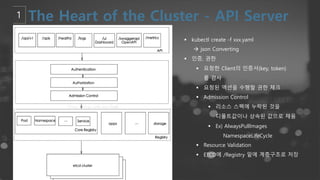
- 42. ┬¦ RESTful APIļź╝ ĒåĄĒĢ┤ņä£ kubectlņÖĆ Ļ░ÖņØĆ Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖņÖĆ ĒåĄņŗĀ ┬¦ RESTful APIļź╝ ĒåĄĒĢ┤ņä£ Ēü┤ļ¤¼ņŖżĒä░ ņāüĒā£ļź╝ ņ┐╝ļ”¼ ļ░Å ņłśņĀĢ(CRUD)ĒĢśĻ│Ā ┬¦ ĻĘĖņĀĢļ│┤ļź╝ etcdņŚÉ ņĀĆņןĒĢ£ļŗż. ┬¦ ļ¬©ļōĀ Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖņÖĆ ņ╗┤ĒżļäīĒŖĖļŖö ņśżņ¦ü API ņä£ļ▓äļź╝ ĒåĄĒĢ┤ņä£ļ¦ī ņāüĒśĖņ×æņÜ®ĒĢ£ļŗż. ┬¦ Ēü┤ļ¤¼ņŖżĒä░ņŚÉ ļīĆĒĢ£ Gatekeeper ņŚŁĒĢĀņØä ĒĢśļ®░, ņØĖņ”Ø(Authen), ĻČīĒĢ£(Authoriz), Ļ░Øņ▓┤ņØś ņ£ĀĒÜ©ņä▒ Ļ▓Ćņé¼(Validation) and admission control ┬¦ JSON ĻĖ░ļ░śņØś HTTP API Ļ░Ć ĻĖ░ļ│ĖņØ┤ņ¦Ćļ¦ī, Ēü┤ļ¤¼ņŖżĒä░ ļé┤ļČĆ ĒåĄņŗĀņØĆ Protocol Buffer ļÅä ņ¦ĆņøÉ
- 43. ┬¦ API ļ▓äņĀä ĻĘ£ņ╣Ö ┬¦ ļ”¼ņåīņŖżļéś ĒĢäļō£ ņłśņżĆļ│┤ļŗżļŖö API ļĀłļ▓©ņŚÉņä£ ļ▓äņĀäņØä ņäĀĒāØĒ¢łļŖöļŹ░, APIĻ░Ć ļ¬ģļŻīĒĢśĻ│Ā, ņŗ£ņŖżĒģ£ ļ”¼ņåīņŖżņÖĆ Ē¢ēņ£ä Ļ┤ĆņĀÉņŚÉņä£ ņØ╝Ļ┤Ćņä▒ņ׳ņ£╝ļ®░, ļŹö ņØ┤ņāü ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖļŖö APIļéś ņŗżĒŚśņĀüņØĖ APIņŚÉ ņĀæĻĘ╝ņØä ņĀ£ņ¢┤ĒĢĀ ņłś ņ׳ļÅäļĪØ ĒĢśĻĖ░ ņ£äĒĢ©ņØ┤ļŗż. ┬¦ Alpha(ex: v1alpha1) ┬¦ ļ▓äĻĘĖĻ░Ć ņ׳ņØä ņłś ņ׳Ļ│Ā, ĻĖ░ļŖźņØä ĒÖ£ņä▒ĒÖöĒĢśļ®┤ ļ▓äĻĘĖĻ░Ć ļģĖņČ£ļÉĀ ņłś ņ׳ļŗż. ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ ļ╣äĒÖ£ņä▒ĒÖö ┬¦ Beta (ex: v2beta3) ┬¦ ņĮöļō£Ļ░Ć ņל ĒģīņŖżĒŖĖļÉśņŚłĻ│Ā, ņĢłņĀĢĒĢśļŗż. ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ ĒÖ£ņä▒ĒÖö ┬¦ Stable(ex: v2) ┬¦ ņĢłņĀĢĒÖöļ▓äņĀä
- 44. ┬¦ ņ┐Āļ▓äļäżĒŗ░ņŖż APIļź╝ ļ│┤ļŗż ņēĮĻ▓ī ĒÖĢņןĒĢśĻĖ░ ņ£äĒĢ┤ņä£, API ĻĘĖļŻ╣ņØä ĻĄ¼ĒśäĒ¢łļŗż. API ĻĘĖļŻ╣ņØĆ REST Ļ▓ĮļĪ£ņÖĆ ņ¦üļĀ¼ĒÖöļÉ£ Ļ░Øņ▓┤ņØś apiVersion ĒĢäļō£ņŚÉ ļ¬ģņŗ£ļÉ£ļŗż. ┬¦ Ēśäņ×¼ ļŗżņ¢æĒĢ£ API ĻĘĖļŻ╣ņØ┤ ņé¼ņÜ®ļÉśĻ│Ā ņ׳ļŗż. ┬¦ ĒĢĄņŗ¼ ĻĘĖļŻ╣ ļśÉļŖö ļĀłĻ▒░ņŗ£ ĻĘĖļŻ╣ ņØ┤ļØ╝Ļ│Ā ĒĢśļŖö ĻĘĖļŻ╣ņØĆ REST Ļ▓ĮļĪ£ /api/v1ņŚÉņä£ apiVersion: v1ņØä ņé¼ņÜ®ĒĢ£ļŗż. ┬¦ ņØ┤ļ”äņØ┤ ņ׳ļŖö ĻĘĖļŻ╣ņØĆ REST Ļ▓ĮļĪ£ /apis/$GROUP_NAME/$VERSIONņŚÉ ņ׳ņ£╝ļ®░ apiVersion: $GROUP_NAME/$VERSIONņØä ņé¼ņÜ®ĒĢ£ļŗż (ņśł: apiVersion: batch/v1). ņ¦ĆņøÉļÉśļŖö API ĻĘĖļŻ╣ ņĀäņ▓┤ņØś ļ¬®ļĪØņØĆ Kubernetes API referenceņŚÉņä£ ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗż.
- 46. ┬¦ kubectl create -f xxx.yaml ├Ā json Converting ┬¦ ņØĖņ”Ø, ĻČīĒĢ£ ┬¦ ņÜöņ▓ŁĒĢ£ ClientņØś ņØĖņ”Øņä£(key, token) ļź╝ Ļ▓Ćņé¼ ┬¦ ņÜöņ▓ŁļÉ£ ņĢĪņģśņØä ņłśĒ¢ēĒĢĀ ĻČīĒĢ£ ņ▓┤Ēü¼ ┬¦ Admission Control ┬¦ ļ”¼ņåīņŖż ņŖżĒÄÖņŚÉ ļłäļØĮļÉ£ Ļ▓āņØä ļööĒÅ┤ĒŖĖĻ░ÆņØ┤ļéś ņāüņåŹļÉ£ Ļ░Æņ£╝ļĪ£ ņ▒äņøĆ ┬¦ Ex) AlwaysPullImages NamespaceLifeCycle ┬¦ Resource Validation ┬¦ ETCDņŚÉ /Registry ļ░æņŚÉ Ļ│äņĖĄĻĄ¼ņĪ░ļĪ£ ņĀĆņן
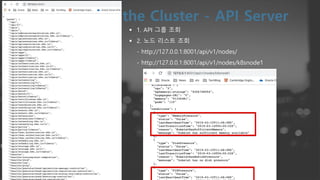
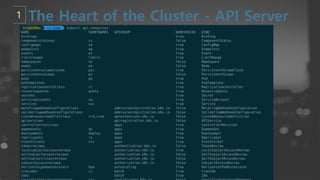
- 47. ┬¦ 1. API ĻĘĖļŻ╣ ņĪ░ĒÜī ┬¦ 2. ļģĖļō£ ļ”¼ņŖżĒŖĖ ņĪ░ĒÜī - http://127.0.0.1:8001/api/v1/nodes/ - http://127.0.0.1:8001/api/v1/nodes/k8snode1
- 49. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 50 Master Component - Controller
- 50. kube-controller-manager ņ╗©ĒŖĖļĪżļ¤¼ļź╝ ĻĄ¼ļÅÖĒĢśļŖö ļ¦łņŖżĒä░ ņāüņØś ņ╗┤ĒżļäīĒŖĖ. ļģ╝ļ”¼ņĀüņ£╝ļĪ£, Ļ░ü ņ╗©ĒŖĖļĪżļ¤¼ļŖö Ļ░£ļ│ä ĒöäļĪ£ņäĖņŖżņØ┤ņ¦Ćļ¦ī, ļ│Ąņ×Īņä▒ņØä ļé«ņČöĻĖ░ ņ£äĒĢ┤ ļ¬©ļæÉ ļŗ©ņØ╝ ļ░öņØ┤ļäłļ”¼ļĪ£ ņ╗┤ĒīīņØ╝ļÉśĻ│Ā ļŗ©ņØ╝ ĒöäļĪ£ņäĖņŖż ļé┤ņŚÉņä£ ņŗżĒ¢ēļÉ£ļŗż. API ņä£ļ▓äļź╝ ĒåĄĒĢ┤ņä£ Shared State(ETCD)ņØś ņĀĢļ│┤ļź╝ Control loopļź╝ ĒåĄĒĢ┤ Ļ░Éņŗ£(watch)ĒĢśĻ│Ā ņ׳ļŗżĻ░Ć Current Stateļź╝ Desired StateļĪ£ ļ│ĆĻ▓ĮņØä ņŗ£ļÅäĒĢ£ļŗż. ņØ┤ļōż ņ╗©ĒŖĖļĪżļ¤¼ļŖö ļŗżņØīņØä ĒżĒĢ©ĒĢ£ļŗż. (ņĢĮ 26Ļ░£) ŌĆóļģĖļō£ ņ╗©ĒŖĖļĪżļ¤¼: ļģĖļō£Ļ░Ć ļŗżņÜ┤ļÉśņŚłņØä ļĢī ĒåĄņ¦ĆņÖĆ ļīĆņØæņŚÉ Ļ┤ĆĒĢ£ ņ▒ģņ×äņØä Ļ░Ćņ¦äļŗż. ŌĆóļĀłĒöīļ”¼ņ╝ĆņØ┤ņģś ņ╗©ĒŖĖļĪżļ¤¼: ņŗ£ņŖżĒģ£ņØś ļ¬©ļōĀ ļĀłĒöīļ”¼ņ╝ĆņØ┤ņģś ņ╗©ĒŖĖļĪżļ¤¼ ņśżļĖīņĀØĒŖĖņŚÉ ļīĆĒĢ┤ ņĢīļ¦×ļŖö ņłśņØś Ēīīļō£ļōżņØä ņ£Āņ¦Ćņŗ£ņ╝£ ņŻ╝ļŖö ņ▒ģņ×äņØä Ļ░Ćņ¦äļŗż. ŌĆóņŚöļō£ĒżņØĖĒŖĖ ņ╗©ĒŖĖļĪżļ¤¼: ņŚöļō£ĒżņØĖĒŖĖ ņśżļĖīņĀØĒŖĖļź╝ ņ▒äņÜ┤ļŗż(ņ”ē, ņä£ļ╣äņŖżņÖĆ Ēīīļō£ļź╝ ņŚ░Ļ▓░ņŗ£Ēé©ļŗż.) ŌĆóņä£ļ╣äņŖż ņ¢┤ņ╣┤ņÜ┤ĒŖĖ & ĒåĀĒü░ ņ╗©ĒŖĖļĪżļ¤¼: ņāłļĪ£ņÜ┤ ļäżņ×äņŖżĒÄśņØ┤ņŖżņŚÉ ļīĆĒĢ£ ĻĖ░ļ│Ė Ļ│äņĀĢĻ│╝ API ņĀæĻĘ╝ ĒåĀĒü░ņØä ņāØņä▒ĒĢ£ļŗż.
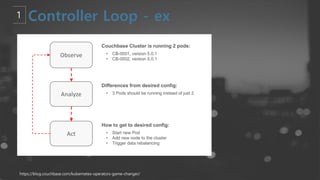
- 51. https://engineering.bitnami.com/articles/a-deep-dive-into-kubernetes-controllers.html ļŗ©ņł£ĒÖöĒĢ£ Controller Loop - ControllerņØś Ļ░Ćņן ņżæņÜöĒĢ£ ņŚŁĒĢĀņØä ObjectņØś current stateņÖĆ desired stateļź╝ watch(Ļ░Éņŗ£) - ņØ┤ļź╝ ņ£äĒĢ┤ API ServerņŚÉ Ļ░ÆņØä ņĪ░ĒÜīĒĢśļŖöļŹ░ ļ¦żļ▓ł ņĪ░ĒÖöĒĢśļŖö Ļ▓āņØä ņśżļ▓äĒŚżļō£Ļ░Ć ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ eventņØä ņĀäļŗ¼ĒĢ┤ņŻ╝ļŖö client-go libraryņØś ŌĆ£Listwatcher interfaceŌĆØ ņé¼ņÜ®
- 53. ļ¬©ļōĀ ņ╗©ĒŖĖļĪżļ¤¼ļŖö API ņä£ļ▓äļź╝ ĒåĄĒĢ┤ API ņśżļĖīņĀØĒŖĖļź╝ Ļ░Ćņ¦ĆĻ│Ā ļÅÖņ×æĒĢ£ļŗż. ņ╗©ĒŖĖļĪżļ¤¼ļŖö KubeletņÖĆ ņ¦üņĀæ ĒåĄņŗĀĒĢśĻ▒░ļéś ņ¢┤ļ¢ż ņóģļźśņØś ļ¬ģļĀ╣ļÅä ļé┤ļ”¼ņ¦Ć ņĢŖļŖöļŗż. ņé¼ņŗż kubeletņØś ņĪ┤ņ×¼ĒĢśļŖöņ¦Ć ņĪ░ņ░© ņĢīņ¦Ć ļ¬╗ĒĢ£ļŗż. ņ╗©ĒŖĖļĪżļ¤¼Ļ░Ć API ņä£ļ▓äņŚÉņä£ ļ”¼ņåīņŖżļź╝ ņŚģļŹ░ņØ┤ļō£ĒĢ£ ņØ┤ĒøäļĪ£ KubeletsņÖĆ ņ┐Āļ▓äļäżĒŗ░ņŖż ņä£ļ╣äņŖż ĒöäļĪØņŗ£ļŖö ņ╗©ĒŖĖļĪżļ¤¼ņØś ņĪ┤ņ×¼ļź╝ ņĢīņ¦Ć ļ¬╗ĒĢ£ļŗż. ĻĘĖļ”¼Ļ│Ā Ēżļō£ņØś ņ╗©ĒģīņØ┤ļäłļź╝ ĒÜīņĀäņŗ£ĒéżĻ│Ā ļäżĒŖĖņøīĒü¼ ņŖżĒåĀļ”¼ņ¦ĆņŚÉ ņŚ░Ļ▓░ĒĢśĻ▒░ļéś Ēżļō£ņØś ņŗżņĀ£ ļĪ£ļō£ ļ░Ėļ¤░ņŗ▒ņØä ņäżņĀĢĒĢ£ļŗż. ņ╗©ĒŖĖļĪż ĒöīļĀłņØĖņØĆ ņĀäņ▓┤ ņŗ£ņŖżĒģ£ ļÅÖņ×æņØś ĒĢ£ ļČĆļČäņØä ņ▓śļ”¼ĒĢśļ»ĆļĪ£, ņØ┤ļ¤░ ļÅÖņ×æņØ┤ ņ┐Āļ▓äļäżĒŗ░ņŖż Ēü┤ļ¤¼ņŖżĒä░ņŚÉņä£ ņ¢┤ļ¢╗Ļ▓ī ĒÄ╝ņ│Éņ¦ĆļŖöņ¦Ć ņÖäņĀäĒ׳ ņØ┤ĒĢ┤ĒĢśļĀżļ®┤ kubeletĻ│╝ ņä£ļ╣äņŖż ĒöäļĪØņŗ£Ļ░Ć ĒĢśļŖö ņØ╝ņØä ņØ┤ĒĢ┤ĒĢĀ ĒĢäņÜöĻ░Ć ņ׳ļŗż.
- 54. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 55 Master Component - Scheduler
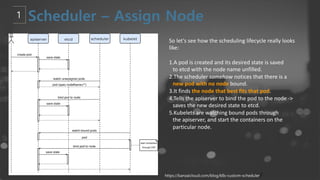
- 55. So letŌĆÖs see how the scheduling lifecycle really looks like: 1.A pod is created and its desired state is saved to etcd with the node name unfilled. 2.The scheduler somehow notices that there is a new pod with no node bound. 3.It finds the node that best fits that pod. 4.Tells the apiserver to bind the pod to the node -> saves the new desired state to etcd. 5.Kubelets are watching bound pods through the apiserver, and start the containers on the particular node. https://banzaicloud.com/blog/k8s-custom-scheduler/
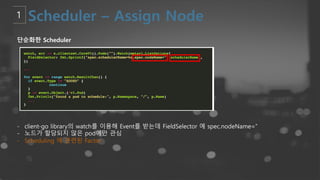
- 56. ļŗ©ņł£ĒÖöĒĢ£ Scheduler - client-go libraryņØś watchļź╝ ņØ┤ņÜ®ĒĢ┤ Eventļź╝ ļ░øļŖöļŹ░ FieldSelector ņŚÉ spec.nodeName=ŌĆÖŌĆÖ - ļģĖļō£Ļ░Ć ĒĢĀļŗ╣ļÉśņ¦Ć ņĢŖņØĆ podņŚÉļ¦ī Ļ┤Ćņŗ¼ - Scheduling ņŚÉ Ļ┤ĆļĀ©ļÉ£ Factor
- 57. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 58 Node Component - ETCD
- 58. ┬¦ ņ┐Āļ▓äļäżĒŗ░ņŖż Ēü┤ļ¤¼ņŖżĒä░ņØś ņĀĆņןņåī ┬¦ ļ╣Āļź┤Ļ│Ā, ļČäņé░ļÉśļ®░, ņØ╝Ļ┤ĆļÉ£ Key-Value Store ┬¦ Raft Consensus algorithm ┬¦ Ēü┤ļ¤¼ņŖżĒä░ļŖö fault-tolerantļź╝ ņ£äĒĢ┤ 3,5,7 Ļ│╝ Ļ░ÖņØĆ ĒÖĆņłśĻ░£ļĪ£ ņÜ┤ņśü ┬¦ ņĀĢņĪ▒ņłś(quorum)
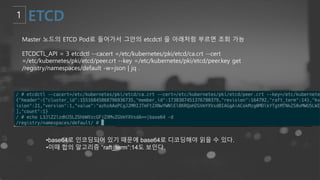
- 59. Master ļģĖļō£ņØś ETCD PodļĪ£ ļōżņ¢┤Ļ░Ćņä£ ĻĘĖņĢłņØś etcdctl ņØä ņĢäļלņ▓śļ¤╝ ļČĆļź┤ļ®┤ ņĪ░ĒÜī Ļ░ĆļŖź ETCDCTL_API = 3 etcdctl --cacert =/etc/kubernetes/pki/etcd/ca.crt --cert =/etc/kubernetes/pki/etcd/peer.crt --key =/etc/kubernetes/pki/etcd/peer.key get /registry/namespaces/default -w=json | jq . ŌĆóbase64ļĪ£ ņØĖņĮöļö®ļÉśņ¢┤ ņ׳ĻĖ░ ļĢīļ¼ĖņŚÉ base64ļĪ£ ļööņĮöļö®ĒĢ┤ņĢ╝ ņØĮņØä ņłś ņ׳ļŗż. ŌĆóņØ┤ļĢī ĒĢ®ņØś ņĢīĻ│Āļ”¼ņ”ś ŌĆ£raft_termŌĆØ:14ļÅä ļ│┤ņØĖļŗż.
- 60. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 61 Node Component - Kubelet
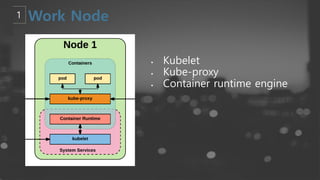
- 61. ┬¦ Kubelet ┬¦ Kube-proxy ┬¦ Container runtime engine
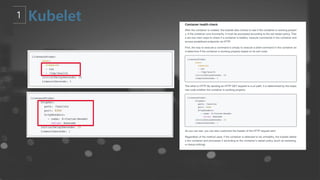
- 62. NodeņŚÉņä£ Agent ņŚŁĒĢĀņØä ĒĢśļ®░ ĒĢśļ®░ PodņØś Lifecycle ņØä Ļ┤Ćļ”¼ĒĢ£ļŗż. ņ¦ĆņåŹņĀüņ£╝ļĪ£ ņŗżĒ¢ēņżæņØĖ ņ╗©ĒģīņØ┤ļäłļź╝ ļ¬©ļŗłĒä░ļ¦üĒĢśĻ│Ā ņāüĒā£ņÖĆ ņØ┤ļ▓żĒŖĖ, ļ”¼ņåīņŖżļō▒ņØä API ņä£ļ▓äņŚÉ ļ│┤Ļ│Ā ĒĢ£ļŗż. 1) Pod Management 2) Contiainer Health Check 3) Contiainer Monitoring - Resouce Usage from cAdvisor ┬¦ File path ┬¦ URL HTTP Endpoint ┬¦ API Server
- 63. kubeletņØś ĻĄ¼ņä▒ ņÜöņåī ┬¦ Kubelet ServerļŖö kube-apiserver ļ░Å metrics-serverņÖĆ Ļ░ÖņØĆ ņä£ļ╣äņŖż ĒśĖņČ£ņØäņ£äĒĢ£ APIļź╝ ņĀ£Ļ│ĄĒĢ®ļŗłļŗż. ņśłļź╝ ļōżņ¢┤, kubectl execļŖö Kubelet API / exec / {token}ņØä ĒåĄĒĢ┤ ņ╗©ĒģīņØ┤ļäłņÖĆ ņāüĒśĖ ņ×æņÜ®ĒĢ┤ņĢ╝ĒĢ®ļŗłļŗż. Read Only API
- 65. kubeletņØś ĻĄ¼ņä▒ ņÜöņåī ┬¦ ņ╗©ĒģīņØ┤ļäł Ļ┤Ćļ”¼ņ×ÉļŖö CGroups, QoS, cpuset, device ļō▒Ļ│╝ Ļ░ÖņØĆ ņ╗©ĒģīņØ┤ļäłņØś ļŗżņ¢æĒĢ£ ņ×ÉņøÉņØä Ļ┤Ćļ”¼ĒĢ®ļŗłļŗż. ┬¦ ļ│╝ļź© Ļ┤Ćļ”¼ņ×ÉļŖö ļööņŖżĒü¼ņØś Ēżļ¦Ę, ļģĖļō£ ļĪ£ņ╗¼ņŚÉ ļ¦łņÜ┤ĒŖĖ, ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ ļ¦łņÜ┤ĒŖĖ Ļ▓ĮļĪ£ļź╝ ņ╗©ĒģīņØ┤ļäłņŚÉ ņĀäļŗ¼ĒĢśļŖö Ļ▓āĻ│╝ Ļ░ÖņØ┤ ņ╗©ĒģīņØ┤ļäłņØś ņŖżĒåĀļ”¼ņ¦Ć ļ│╝ļź©ņØä Ļ┤Ćļ”¼ĒĢ®ļŗłļŗż. ┬¦ Eviction Ļ┤Ćļ”¼ņ×É ļŖö ņ×ÉņøÉņØ┤ ņČ®ļČäĒĢśņ¦Ć ņĢŖņØä ļĢī ņÜ░ņäĀ ņł£ņ£äĻ░Ć ļé«ņØĆ ņ╗©ĒģīņØ┤ļäłņØś Ēć┤ņČ£ ņŗ£ĒéżļŖö Ļ▓āĻ│╝ Ļ░ÖņØ┤ ņÜ░ņäĀ ņł£ņ£äĻ░Ć ļåÆņØĆ ņ╗©ĒģīņØ┤ļäłņØś ņÜ┤ņśüņØä ļ│┤ņןĒĢśĻĖ░ ņ£äĒĢ┤ ņ╗©ĒģīņØ┤ļäł Ēć┤Ļ▒░ļź╝ ļŗ┤ļŗ╣ĒĢ®ļŗłļŗż. ┬¦ cAdvisorļŖö ņ╗©ĒģīņØ┤ļäłņŚÉ Metricsļź╝ ņĀ£Ļ│ĄĒĢ®ļŗłļŗż. ┬¦ ļ®öĒŖĖļ”Ł ļ░Å ĒåĄĻ│äļŖö ļ®öĒŖĖļ”ŁĻ│╝ Ļ░ÖņØĆ ņ╗©ĒģīņØ┤ļäł ļ░Å ļģĖļō£ņŚÉ ļīĆĒĢ£ ļ®öĒŖĖļ”ŁņØä ņĀ£Ļ│ĄĒĢ®ļŗłļŗż. / stats / summaryļź╝ ĒåĄĒĢ┤ ņČöņČ£ ļÉ£ ņä£ļ▓ä ļ®öĒŖĖļ”ŁņØĆ HPAņØś ņ×ÉļÅÖ ĒÖĢņןņØäņ£äĒĢ£ ĻĖ░ļ│Ė ņÜöņåīņ×ģļŗłļŗż. ┬¦ ņØ╝ļ░ś ļ¤░ĒāĆņ×ä Ļ┤Ćļ”¼ņ×ÉļŖö CRI ņāüĒśĖ ņ×æņÜ® ļ░Å ņ╗©ĒģīņØ┤ļäł ļ░Å ļ»Ėļ¤¼ļ¦ü Ļ┤Ćļ”¼ļź╝ ļŗ┤ļŗ╣ĒĢśļŖö ņ╗©ĒģīņØ┤ļäł ļ¤░ĒāĆņ×ä Ļ┤Ćļ”¼ņ×Éņ×ģļŗłļŗż.
- 66. Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 67 Summary
- 68. ŌĆó Introduction to k8s workshop : https://docs.google.com/presentation/d/1zrfVlE5r61ZNQrmX Kx5gJmBcXnoa_WerHEnTxu5SMco/edit?usp=sharing ŌĆó K8s comprehensive Overview: https://docs.google.com/presentation/d/1_xwLGM6U6EDK59s9Zny- zWGGAbQk47cZPuBblU3Upus/edit#slide=id.g2c3848b8cd_0_158 ŌĆó Kubernetes in Action ŌĆó A Crash Course on Container Orchestration & k8s : https://speakerd.s3.amazonaws.com/presentations/cb7394a1868b479eb6723d120995f259/C ontainer_Orchestration_-_Interop_ITX__17.pdf ŌĆó Pod :https://ssup2.github.io/theory_analysis/Kubernetes_Pod/?fbclid=IwAR1IZtyjusnW1iX8C1 s1c5QpQMigmiH-Y7pFDZ3dwtL44TJ8esDZqp-lXHg ŌĆó Pod : https://www.ianlewis.org/en/what-are-kubernetes-pods-anyway ŌĆó Pod : https://blog.2dal.com/2018/03/28/kubernetes-01-pod/
- 69. Copyright ┬® 2017, Oracle and/or its affiliates. All rights reserved. | Confidential ŌĆō Oracle Internal/Restricted/Highly Restricted 70