Lß╗▒a chß╗Źn thuß╗Öc t├Łnh v├Ā Khai ph├Ī luß║Łt kß║┐t hß╗Żp tr├¬n WEKA
1 like9,872 views

B├Īo c├Īo n├Āy sß║Į hŲ░ß╗øng dß║½n: lß╗▒a chß╗Źn thuß╗Öc t├Łnh v├Ā Khai ph├Ī luß║Łt kß║┐t hß╗Żp tr├¬n WEKA. Chi tiß║┐t th├¬m vß╗ü dataset xin mß╗Øi truy cß║Łp blog cß╗¦a ch├║ng t├┤i tß║Īi: http://bit.ly/weka-luat-ket-hop








































































More Related Content
What's hot (20)
Similar to Lß╗▒a chß╗Źn thuß╗Öc t├Łnh v├Ā Khai ph├Ī luß║Łt kß║┐t hß╗Żp tr├¬n WEKA (20)




![[Cntt] all java](https://cdn.slidesharecdn.com/ss_thumbnails/cnttalljava-160829131208-thumbnail.jpg?width=560&fit=bounds)










![[Cntt] b├Āi giß║Żng java khtn hcm](https://cdn.slidesharecdn.com/ss_thumbnails/cnttbigingjava-khtnhcm-160829131334-thumbnail.jpg?width=560&fit=bounds)


More from Ho Quang Thanh (17)

















Lß╗▒a chß╗Źn thuß╗Öc t├Łnh v├Ā Khai ph├Ī luß║Łt kß║┐t hß╗Żp tr├¬n WEKA
- 1. Lß╗░A CHß╗īN THUß╗śC T├ŹNH & KHAI PH├ü LUß║¼T Kß║ŠT Hß╗óP TR├ŖN WEKA THß╗░C HIß╗åN Lß╗░A CHß╗īN THUß╗śC T├ŹNH, L├ĆM Sß║ĀCH Dß╗« LIß╗åU V├Ć KHAI PH├ü LUß║¼T Kß║ŠT Hß╗óP DATA MINING 1
- 2. Mß╗żC Lß╗żC 1. GIß╗ÜI THIß╗åU Vß╗Ć B├ĆI TO├üN 2. CHUß║©N Bß╗Ŗ Dß╗« LIß╗åU 3. DATA CLEANING ŌĆō L├ĆM Sß║ĀCH Dß╗« LIß╗åU 4. ASSOCIATION RULE MINNING ŌĆō KHAI PH├ü LUß║¼T Kß║ŠT Hß╗óP 5. ATTRIBUTE SELECTION ŌĆō Lß╗░A CHß╗īN THUß╗śC T├ŹNH DATA MINING 2
- 3. 1. Giß╗øi thiß╗ću vß╗ü WEKA v├Ā dß╗» liß╗ću WEKA - Waikato Enviroment for Knowledge Analysis ŌĆō l├Ā mß╗Öt tß║Łp hß╗Żp c├Īc giß║Żi thuß║Łt hß╗Źc m├Īy v├Ā c├Īc c├┤ng cß╗ź xß╗Ł l├Į dß╗» liß╗ću. Ng├┤n ngß╗»: Java, ph├ón phß╗æi dŲ░ß╗øi giß║źy ph├®p GNU General Public H├¼nh 1. Logo cß╗¦a Weka khi chŲ░ŲĪng tr├¼nh ─æŲ░ß╗Żc khß╗¤i ─æß╗Öng DATA MINING 3
- 4. M├┤ tß║Ż dß╗» liß╗ću bank-data Dß╗» liß╗ću bank-data tß╗½ DePaul University, ─æ├óy l├Ā dß╗» liß╗ću v├Ł dß╗ź m├┤ phß╗Ång tß╗½ dß╗» liß╗ću ng├ón h├Āng Trong thß╗▒c tß║┐ dß╗» liß╗ću - dß╗» liß╗ću bank-data - ─æŲ░ß╗Żc tß║Łp hß╗Żp tß╗½ c├Īc ─æŲĪn ─æ─āng k├Į cß╗¦a c├Īc kh├Īch h├Āng ─æß║┐n mß╗¤ dß╗ŗch vß╗ź v├Ā thß╗▒c hiß╗ćn ─æ─āng k├Į online cß╗¦a 1 ng├ón h├Āng DATA MINING 4
- 5. id Sß╗æ ─æß╗ŗnh danh (mß╗Śi t├Āi khoß║Żn 1 thß╗® tß╗▒) age Sß╗æ tuß╗Ģi cß╗¦a kh├Īch h├Āng (t├Łnh bß║▒ng n─ām, dß║Īng sß╗æ) sex 2 gi├Ī trß╗ŗ giß╗øi t├Łnh: MALE/FEMALE region 4 gi├Ī trß╗ŗ vß╗ü khu vß╗▒c: inner_city/rural/suburban/town income Thu nhß║Łp cß╗¦a kh├Īch h├Āng (dß║Īng sß╗æ) married Kh├Īch h├Āng ─æ├Ż kß║┐t h├┤n hay chŲ░a, 2 gi├Ī trß╗ŗ: YES/NO children Sß╗æ lŲ░ß╗Żng con c├Īi cß╗¦a kh├Īch h├Āng (dß╗» liß╗ću dß║Īng sß╗æ) car Kh├Īch h├Āng c├│ xe hŲĪi hay kh├┤ng: YES/NO save_acct Kh├Īch h├Āng c├│ t├Āi khoß║Żn (TK) tiß║┐t kiß╗ćm hay kh├┤ng: YES/NO current_acc Kh├Īch h├Āng c├│ TK v├Żng lai hay kh├┤ng: YES/NO mortgage Kh├Īch h├Āng c├│ t├Āi sß║Żn thß║┐ chß║źp hay kh├┤ng: YES/NO pep Kh├Īch h├Āng c├│ mua PEP (Personal Equity Plan) sau lß║¦n li├¬n lß║Īc gß║¦n nhß║źt: YES/NO DATA MINING 5
- 6. 2. CHUß║©N Bß╗Ŗ Dß╗« LIß╗åU TR├ŖN WEKA Chuyß╗ān file CSV > ARFF: dß╗» liß╗ću dß║Īng Attribute- Relation File Format (ARFF) l├Ā dß╗» liß╗ću ─æŲ░ß╗Żc Weka chß║źp nhß║Łn, trong khi dß╗» liß╗ću ch├║ng ta thŲ░ß╗Øng c├│ ß╗¤ dß║Īng csv hoß║Ęc tsv DATA MINING 6
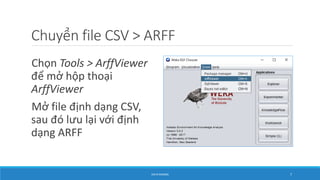
- 7. Chuyß╗ān file CSV > ARFF Chß╗Źn Tools > ArffViewer ─æß╗ā mß╗¤ hß╗Öp thoß║Īi ArffViewer Mß╗¤ file ─æß╗ŗnh dß║Īng CSV, sau ─æ├│ lŲ░u lß║Īi vß╗øi ─æß╗ŗnh dß║Īng ARFF DATA MINING 7
- 8. LŲ░u ├Į Chß╗Źn Invoke options dialog l├Ā v├¼ c├Īc giß║Żi thuß║Łt khai ph├Ī luß║Łt kß║┐t hß╗Żp nhŲ░ Apriori, FPGrowth y├¬u cß║¦u thuß╗Öc t├Łnh dß║Īng Nominal attributes (dß╗» liß╗ću ph├ón loß║Īi DATA MINING 8 ’üĖ
- 10. 3. DATA CLEANING ŌĆō L├ĆM Sß║ĀCH Dß╗« LIß╗åU Mß╗źc ─æ├Łch: T├¼m, sß╗Ła ─æß╗Ģi hoß║Ęc loß║Īi bß╗Å c├Īc record dß╗» liß╗ću kh├┤ng ho├Ān thiß╗ćn, kh├┤ng ch├Łnh x├Īc hoß║Ęc kh├┤ng li├¬n quan ─æß║┐n dß╗» liß╗ću hiß╗ćn c├│ Data Cleansing l├Ā 1 phß║¦n trong qu├Ī tr├¼nh Tiß╗ün xß╗Ł l├Į dß╗» liß╗ću DATA MINING 10
- 11. DATA MINING 11 Tß║Īi sao cß║¦n l├Ām sß║Īch dß╗» liß╗ću?
- 12. Thß╗▒c hiß╗ćn data cleaning bß║▒ng weka Vß╗øi c├Īc gi├Ī trß╗ŗ bß╗ŗ mß║źt ŌŚ”Weka sß║Į ─æŲ░a ra tß╗ē lß╗ć % dß╗» liß╗ću bß╗ŗ mß║źt ŌŚ”D├╣ng bß╗Ö lß╗Źc: ReplaceMissingValues Vß╗øi dß╗» liß╗ću nhiß╗ģu ŌŚ”Weka sß║Į b├Īo c├Īo vß╗ü c├Īc dß╗» liß╗ću c├Ī biß╗ćt ŌŚ”C├Īc bß╗Ö lß╗Źc c├│ thß╗ā sß╗Ł dß╗źng: RemoveMisclassified, MergeTwoValues DATA MINING 12
- 13. Thß╗▒c hiß╗ćn l├Ām sß║Īch dß╗» liß╗ću bank-data DATA MINING 13 Theo b├Īo c├Īo tr├¬n th├¼ dß╗» liß╗ću bank-data kh├┤ng bß╗ŗ mß║źt dß╗» liß╗ću v├Ā c┼®ng kh├┤ng c├│ dß╗» liß╗ću ngoß║Īi lai
- 14. L├Ām sß║Īch dß╗» liß╗ću bß║¦u cß╗Ł: vote Dß╗» liß╗ću c├│ sß╗æ record bß╗ŗ mß║źt l├Ā 12 chiß║┐m 3% v├Ā kh├┤ng c├│ dß╗» liß╗ću ngoß║Īi lai DATA MINING 14
- 15. Xß╗Ł l├Į dß╗» liß╗ću bß╗ŗ mß║źt DATA MINING 15
- 16. C├Īc ├┤ bß╗ŗ mß║źt sß║Į ─æŲ░ß╗Żc t├┤ ─æß║Łm DATA MINING 16
- 17. DATA MINING 17
- 18. L├Ām sß║Īch dß╗» liß╗ću segment-test ß╗× ─æ├óy dß╗» liß╗ću segment-test kh├┤ng c├│ dß╗» liß╗ću bß╗ŗ mß║źt, v├Ā c├│ sß╗æ lŲ░ß╗Żng dß╗» liß╗ću ngoß║Īi lai: 34, chiß║┐m 4% DATA MINING 18
- 19. Xß╗Ł l├Į dß╗» liß╗ću ngoß║Īi lai DATA MINING 19 RemoveMisclassified MergeTwoValues
- 22. 5. KHAI PH├ü LUß║¼T Kß║ŠT Hß╗óP Mß╗źc ─æ├Łch: cß╗¦a luß║Łt kß║┐t hß╗Żp (Association Rule - AR) l├Ā t├¼m ra c├Īc mß╗æi kß║┐t hß╗Żp (association) hay tŲ░ŲĪng quan (correlation) giß╗»a c├Īc ─æß╗æi tŲ░ß╗Żng trong khß╗æi lŲ░ß╗Żng lß╗øn dß╗» liß╗ću. DATA MINING 22
- 23. ß╗©ng dß╗źng: trong nhiß╗üu l─®nh vß╗▒c, nhß║źt l├Ā trong kinh doanh nhŲ░ Market Basket Analysis: Cross selling ŌĆō b├Īn h├Āng ch├®o, Product placement ŌĆō sß║»p xß║┐p sß║Żn phß║®m, Affinity promotion ŌĆō quß║Żng c├Īo li├¬n kß║┐t, Customer behavior Analysis ŌĆō ph├ón t├Łch h├Ānh vi kh├Īch h├Āng. DATA MINING 23
- 24. Mß╗Öt sß╗æ kh├Īi niß╗ćm thŲ░ß╗Øng gß║Ęp khi khai ph├Ī luß║Łt kß║┐t hß╗Żp vß╗øi weka: ŌĆóItem: phß║¦n tß╗Ł ŌĆóItemSet: tß║Łp phß║¦n tß╗Ł ŌĆóTransaction: giao dß╗ŗch ŌĆóAssociation: sß╗▒ kß║┐t hß╗Żp ŌĆóAssociation rule: luß║Łt kß║┐t hß╗Żp ŌĆóSupport: ─æß╗Ö hß╗Ś trß╗Ż ŌĆóConfidence: ─æß╗Ö tin cß║Ły DATA MINING 24
- 25. ŌĆóFrequent itemset: tß║Łp phß║¦n tß╗Ł phß╗Ģ biß║┐n ŌĆóStrong association rule: luß║Łt kß║┐t hß╗Żp mß║Īnh ŌĆóMinimum support threshold: ngŲ░ß╗Īng hß╗Ś trß╗Ż tß╗æi thiß╗āu ŌĆóMinimum confidence threshold: ngŲ░ß╗Īng tin cß║Ły tß╗æi thiß╗āu DATA MINING 25
- 26. Thß╗▒c hiß╗ćn khai ph├Ī luß║Łt kß║┐t hß╗Żp vß╗øi giß║Żi thuß║Łt Apriori: Mß╗źc ti├¬u khai ph├Ī ─æŲ░ß╗Żc mß╗æi quan hß╗ć cß╗¦a c├Īc thuß╗Öc t├Łnh thu thß║Łp ─æŲ░ß╗Żc tß╗½ kh├Īch h├Āng DATA MINING 26
- 27. DATA MINING 27
- 28. DATA MINING 28 ŌĆó car: khai ph├Ī luß║Łt kß║┐t hß╗Żp ph├ón lß╗øp ŌĆó classindex: -1 ß╗¤ ─æ├óy l├Ā lß║źy lß╗øp cuß╗æi c├╣ng ŌĆó lowerBoundMinSupport: cß║Łn dŲ░ß╗øi ─æß╗Ö hß╗Ś trß╗Ż tß╗æi thiß╗āu ŌĆó metricType: dß║Īng thang ─æo ─æß╗Ö tin cß║Ły cß╗¦a giß║Żi - ß╗¤ trŲ░ß╗Øng hß╗Żp n├Āy: Confidence ŌĆó minMetric: sß╗æ ─æiß╗ām tß╗æi thiß╗āu chß║źp nhß║Łn ─æŲ░ß╗Żc cß╗¦a thang ─æo ŌĆó numRules: sß╗æ rules cß║¦n t├¼m ŌĆó outputItemSets: hiß╗ān thß╗ŗ tß║Łp dß╗» liß╗ću ŌĆó removeAllMissingCols: loß║Īi bß╗Å c├Īc cß╗Öt kh├┤ng chß╗®a gi├Ī trß╗ŗ ŌĆó significanceLevel: mß╗®c ├Į ngh─®a, chß╗ē hoß║Īt ─æß╗Öng vß╗øi metric type l├Ā Confidence ŌĆó treatZeroAsMissing: loß║Īi bß╗Å gi├Ī trß╗ŗ ─æß║¦u ti├¬n mß╗Śi row ŌĆó upperBoundMinSupport: cß║Łn tr├¬n ─æß╗Ö hß╗Ś trß╗Ż tß╗æi thiß╗āu ŌĆó verbose: chß║Īy chß║┐ ─æß╗Ö hiß╗ān thß╗ŗ chi tiß║┐t qu├Ī tr├¼nh Mß╗Öt sß╗æ th├┤ng sß╗æ lŲ░u ├Į:
- 29. Chi tiß║┐t c├Īc th├┤ng sß╗æ ŌĆó car: khai ph├Ī luß║Łt kß║┐t hß╗Żp ph├ón lß╗øp ŌĆó classindex: index cß╗¦a lß╗øp d├╣ng trong trŲ░ß╗Øng hß╗Żp "car=true", -1 ß╗¤ ─æ├óy l├Ā lß║źy lß╗øp cuß╗æi c├╣ng ŌĆó lowerBoundMinSupport: cß║Łn dŲ░ß╗øi ─æß╗Ö hß╗Ś trß╗Ż tß╗æi thiß╗āu ŌĆó metricType: dß║Īng thang ─æo ─æß╗Ö tin cß║Ły cß╗¦a giß║Żi thuß║Łt khai ph├Ī luß║Łt kß║┐t hß╗Żp, ß╗¤ ─æ├óy l├Ā dß║Īng Confidence ŌĆó minMetric: sß╗æ ─æiß╗ām tß╗æi thiß╗āu chß║źp nhß║Łn ─æŲ░ß╗Żc cß╗¦a thang ─æo ŌĆó numRules: sß╗æ rules cß║¦n t├¼m ŌĆó outputItemSets: hiß╗ān thß╗ŗ tß║Łp dß╗» liß╗ću ŌĆó removeAllMissingCols: loß║Īi bß╗Å c├Īc cß╗Öt kh├┤ng chß╗®a gi├Ī trß╗ŗ ŌĆó significanceLevel: mß╗®c ├Į ngh─®a, chß╗ē hoß║Īt ─æß╗Öng vß╗øi metric type l├Ā Confidence ŌĆó treatZeroAsMissing: loß║Īi bß╗Å gi├Ī trß╗ŗ ─æß║¦u ti├¬n mß╗Śi row ŌĆó upperBoundMinSupport: cß║Łn tr├¬n ─æß╗Ö hß╗Ś trß╗Ż tß╗æi thiß╗āu ŌĆó verbose: chß║Īy chß║┐ ─æß╗Ö hiß╗ān thß╗ŗ chi tiß║┐t qu├Ī tr├¼nh DATA MINING 29
- 30. 5. ATTRIBUTE SELECTION Dß╗» liß╗ću ph├ón t├Łch thŲ░ß╗Øng chß╗®a nhiß╗üu rß║źt nhiß╗üu thuß╗Öc t├Łnh, nhŲ░ng kh├┤ng phß║Żi tß║źt cß║Ż ch├║ng ─æß╗üu cß║¦n thiß║┐t ─æß╗ā khai ph├Ī tri thß╗®c. DATA MINING 30
- 31. Lß╗▒a chß╗Źn thuß╗Öc t├Łnh trong Weka ─Éß╗ā chß╗Źn lß╗▒a thuß╗Öc t├Łnh trong weka bß║Īn cß║¦n x├Īc ─æß╗ŗnh attribute evaluator v├Ā serch method, sau ─æ├│ n├│ sß║Į t├¼m kiß║┐m trong kh├┤ng gian c├Īc thuß╗Öc t├Łnh con, v├Ā ─æ├Īnh gi├Ī tß╗½ng tß║Łp con mß╗Öt. Mß╗Śi attribute evaluator ─æŲ░ß╗Żc sß╗Ł dß╗źng vß╗øi mß╗Öt phŲ░ŲĪng ph├Īp t├¼m kiß║┐m tŲ░ŲĪng ß╗®ng 31
- 32. Attribute Subset Evaluators Subset Evaluators sß║Į lß║źy mß╗Öt tß║Łp thuß╗Öc t├Łnh con v├Ā trß║Ż ra mß╗Öt gi├Ī trß╗ŗ ─æß╗ā t├¼m kiß║┐m. 32
- 33. "Wrapper" method ─É├Īnh gi├Ī tß║Łp thuß╗Öc t├Łnh bß║▒ng mß╗Öt giß║Żi thuß║Łt hß╗Źc. ─Éß╗Ö ch├Łnh x├Īc cß╗¦a giß║Żi thuß║Łt hß╗Źc tr├¬n tß║Łp thuß╗Öc t├Łnh n├Āy ─æŲ░ß╗Żc xß║źp xß╗ē nhß╗Ø cross-validation. 33
- 34. "Wrapper" method ŌĆóAttribute evaluator chß╗Źn WrapperSubsetEval, chß╗Źn J48, 10 fold cross-validation ŌĆóSearch method: BestFirst, chß╗Źn backward. ŌĆó├üp dß╗źng vß╗øi bank-data, ta ─æŲ░ß╗Żc tß║Łp thuß╗Öc t├Łnh l├Ā income, married, children, save_act, mortgage c├│ merit = 0.863 ŌĆóTß╗Ģng sß╗æ tß║Łp ─æŲ░ß╗Żc ─æ├Īnh gi├Ī: 72 vß╗øi search termination l├Ā 5 34
- 35. ŌĆó Tß║Łp thuß╗Öc t├Łnh bß║»t ─æß║¦u: (1,2,3,4,5,6,7,8), backward search, v├Ā search termination = 1, ta ─æŲ░ß╗Żc (1,2,3,4,5,6,7). Nß║┐u termination = 5 ta ─æŲ░ß╗Żc (4,5,6). ŌĆó Nß║┐u d├╣ng forward search vß╗øi tß║Łp bß║»t ─æß║¦u (1,2,3) ta sß║Į lß║źy to├Ān bß╗Ö thuß╗Öc t├Łnh. ŌĆó Nß║┐u d├╣ng bi-directional vß╗øi tß║Łp (1,2,3) ta c├│ ─æŲ░ß╗Żc (4,5,6,8,10) vß╗øi merit = 0.863 Ch├║ ├Į: tß╗æi Ų░u cß╗źc bß╗Ö vs tß╗æi Ų░u to├Ān cß╗źc ŌĆó search termination > 1 sß║Į gi├║p bß║Īn vŲ░ß╗Żt qua ─æŲ░ß╗Żc thung l┼®ng. ŌĆó Vß╗øi c├Īc ─æiß╗ām bß║»t ─æß║¦u kh├Īc nhau, ch├║ng ta sß║Į tß╗øi ─æŲ░ß╗Żc ─æiß╗ām tß╗æi Ų░u kh├Īc nhau. ŌĆó Greedy searching chß╗ē t├¼m ─æŲ░ß╗Żc tß╗æi Ų░u cß╗źc bß╗Ö trong kh├┤ng gian t├¼m kiß║┐m. 35
- 36. Scheme-Indepedent attribute selection Wrapper ─æŲĪn giß║Żn, trß╗▒c tiß║┐p nhŲ░ng rß║źt chß║Łm. Ch├║ng ta ch├║ ├Į: 1. Sß╗Ł dß╗źng single-attribute evaluator vß╗øi ranking. - Gi├║p loß║Īi bß╗Å nhß╗»ng thuß╗Öc t├Łnh kh├┤ng th├Łch hß╗Żp 2. Sß╗Ł dß╗źng attribute subset evaluator c├╣ng vß╗øi search method. - Gi├║p loß║Īi bß╗Å nhß╗»ng thuß╗Öc t├Łnh dŲ░ thß╗½a. Attribute subset evaluator: - wrapper method l├Ā scheme-dependent subset evaluators - C├▓n c├│ scheme-independent subset evaluators 36
- 37. Scheme-Indepedent attribute selection CfsSubsetEval: l├Ā mß╗Öt scheme-independent subset evaluators Theo CfsSubsetEval th├¼ mß╗Öt tß║Łp thuß╗Öc t├Łnh tß╗æt phß║Żi thß╗Åa m├Żn: - C├│ tŲ░ŲĪng quan cao vß╗øi thuß╗Öc t├Łnh ph├ón lß╗øp (class attribute). - TŲ░ŲĪng quan yß║┐u vß╗øi c├Īc thuß╗Öc t├Łnh trong c├╣ng tß║Łp. N├│ ─æŲ░ß╗Żc thß╗ā hiß╗ćn qua c├┤ng thß╗®c sau: C l├Ā h├Ām ─æ├Īnh gi├Ī tŲ░ŲĪng quan giß╗»a 2 thuß╗Öc t├Łnh 37
- 39. Attribute Selected classifier AttributeSelectedClassifier chß╗Źn lß╗▒a thuß╗Öc t├Łnh chß╗ē dß╗▒a tr├¬n tß║Łp huß║źn luyß╗ćn, thß║Łm ch├Ł khi ─æŲ░ß╗Żc ─æ├Īnh gi├Ī bß║▒ng cross- validation. ─É├óy l├Ā c├Īch l├Ām ─æ├║ng. N├│ cho kß║┐t quß║Ż t├┤t nß║┐u chß╗Źn bß╗Ö ph├ón loß║Īi c├╣ng loß║Īi thuß╗Öc wrapper. 39
- 40. Attribute Selected classifier So s├Īnh CfsSubsetEval vß╗øi Wrapper tr├¬n bank-data.arff Naive Bayes J48 IBK No attribute selection 70.33% 85% 75.33% Attribute selection sß╗Ł dß╗źng AttributeSelectedClassifier CfsSubsetEval (rß║źt nhanh) 69.83% 79% 77.66% Wrapper selection (kh├Ī chß║Łm) 72% 85.5% 85.16% GainRatioAttributeEval (cß╗▒c nhanh) 71% 79.16% 77.83% (giß╗» lß║Īi 4 thuß╗Öc t├Łnh) Trong nhiß╗üu trŲ░ß╗Øng hß╗Żp th├¼ CfsSubsetEval tß╗æt gß║¦n bß║▒ng Wrapper selection nhŲ░ng nhanh hŲĪn nhiß╗üu. 40
- 41. Fast attribute selection sß╗Ł dß╗źng ranking Single-attribute evaluator: c├│ thß╗ā loß║Īi bß╗Å nhß╗»ng thuß╗Öc t├Łnh kh├┤ng th├Łch hß╗Żp, nhŲ░ng thuß╗Öc t├Łnh dŲ░ thß╗½a th├¼ kh├┤ng. - Sß╗Ł dß╗źng vß╗øi ranker search, n├│ d├╣ng ─æß╗ā sß║»p xß║┐p thuß╗Öc t├Łnh theo gi├Ī trß╗ŗ ─æ├Īnh gi├Ī. - Single-attribute evaluator ─æ├Īnh gi├Ī mß╗æi tŲ░ŲĪng quan cß╗¦a tß╗½ng thuß╗Öc t├Łnh vß╗øi vß╗øi thuß╗Öc t├Łnh ph├ón lß╗øp. Mß╗Śi phŲ░ŲĪng ph├Īp th├¼ c├│ c├┤ng thß╗®c ri├¬ng. VD: InfoGainAttributeEval sß╗Ł dß╗źng information gain, hay GainRatioAttributeEval sß╗Ł dß╗źng c├┤ng thß╗®c gain ratio. 41
- 42. Ranker method c├│ c├Īc tham sß╗æ: sß╗æ lŲ░ß╗Żng tham sß╗æ cß║¦n giß╗», ngŲ░ß╗Īng cß║¦n chß╗Źn. Do ─æ├│ Single-attribute evaluation tuy nhanh nhŲ░ng kh├│ x├Īc ─æß╗ŗnh sß╗æ lŲ░ß╗Żng tham sß╗æ cß║¦n giß╗» lß║Īi. Kh├┤ng loß║Īi ─æŲ░ß╗Żc thuß╗Öc t├Łnh dŲ░ 42
- 43. Th├Ānh vi├¬n ─æ├│ng g├│p T├¬n Nguyß╗ģn Tuß║źn V┼® Nguyß╗ģn Anh Viß╗ćt Hß╗ō Quang Thanh ─Éo├Ān VŲ░ŲĪng B├Łnh T├║ V┼® V─ān Thß╗æng Nguyß╗ģn TŲ░ß╗Øng Vi DATA MINING 43