![この資料は「第3回 IEEE SIGHT ハックチャレンジ 」のために作
られました。 別の目的での使用には、下記の引用が必要です:
Tejero-de-Pablos A. (2018). 机械学习の基础 [PowerPoint slides].
Retrieved from
/AntonioTejerodePablo/machine-learning-
fundamentals-ieee
This material was originally created for the “3rd IEEE SIGHT Hack
Challenge” event. If used for a different purpose, the following
citation is necessary:
Tejero-de-Pablos A. (2018). 机械学习の基础 [PowerPoint slides].
Retrieved from
/AntonioTejerodePablo/machine-learning-
fundamentals-ieee](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-1-320.jpg)





![機械学習のフレームワーク
? タスク: スパム検出
? 事例: 一個メール
? ラベル: スパム/NOTスパム
? 特徴:単語数、送信者など
? モデル: スパム検出器
スパム
検出器
Eメール [256, 0 … 3]
スパム
NOTスパム
7](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-8-320.jpg)
![学習 vs. テスト
? 学習モード: モデル更新(繰り返し)
? テスト?推論モード: モデル固定 (更新無し)
スパム
検出器
EメールA
スパム?
NOTスパム?
NOTスパム
[256, 0 … 3] NOTスパム
更新 (誤差)
スパム
検出器
EメールB
スパム?
NOTスパム?
[89, 1 … 3]
誤差
9](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-10-320.jpg)



![学習ループ
? 初期値:
? linear regression なら初期値は何でもよい(乱数でOK)
? Iteration(繰り返し) 1, 2, 3, …
? 入力事例 x ? 予測 y’ ? ロスの計算 ? モデル w 更新
? 学習の終了(収束判定):
? w がほとんど更新されないor全くされない (0 loss)
スパム
検出器
EメールA
スパム?
NOTスパム?
NOTスパム
[256, 0 … 3] NOTスパム
更新 (ロス)
ロス
15](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-16-320.jpg)

![TensorFlowでregressorを学習しよう
features,labels = read_data() # 特徴量を読み込む
features = feature_normalize(features) # 正規化
rnd_indices = np.random.rand(len(features)) < 0.80
train_x = features[rnd_indices] # データを分ける
train_y = labels[rnd_indices]
test_x = features[~rnd_indices]
test_y = labels[~rnd_indices]
learning_rate = 0.01 # 学習変数の初期化
training_iterations = 1000
loss_history = np.empty(shape=[1],dtype=float)
18](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-19-320.jpg)
![TensorFlowでregressorを学習しよう
n_dim = features.shape[1] # TensorFlowの変数コンテナ
X = tf.placeholder(tf.float32,[None,n_dim])
Y = tf.placeholder(tf.float32,[None,1])
W = tf.Variable(tf.ones([n_dim,1]))
init = tf.initialize_all_variables() # 学習変数の初期化
y_ = tf.matmul(X, W) # 学習関数の宣言
loss = tf.reduce_mean(tf.square(y_ - Y))
training_step =
tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
19](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-20-320.jpg)




![特徴抽出
生データと特徴量のマッピング
? 数値: 直接マッピング
? IDなどの非数値データは?
生データ
email:
? 単語数: 129
? 受信数: 12
? 送信者: s2@mail.com
? …
特徴量
x:
? 129.0
? 12.0
? 2?
? …
特徴抽出
3人の送信者: s0@mail.com, s1@mail.com, s2@mail.com
生データ
email:
? 送信者: s2@mail.com
特徴量
x:
? [0, 0, 1]
特徴抽出
25](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-26-320.jpg)
![特徴抽出:データの精査
? 正規化 (例 [100~900] ? [-1~1]):
? 学習の収束を高速化
? Be careful with:
? 外れ値
? 欠損値
? データの重複
? ラベル誤り
? Analyze your data
? 最大値 / 最小値
? 平均 / 中央値
? 標準偏差
頻度
患者の年齢
患者の年齢を予測する
ためのデータセット
26](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-27-320.jpg)





![TensorFlowでMLPを学習しよう
42
dataset.load() # データセットの読み込み
data_size = dataset.size
#===== ネットワークの作成 =====
x = tf.placeholder(tf.float32, [None,(data_size)]) # 入力
fc1 = fullyconnected_layer(name=‘fc1’, input_tensor=x,
num_output=256) # 中間層 (ニューロン数: 256)
act1 = activation_function_layer(name=‘act1’, input_tensor=fc1,
act_func=‘sigmoid’) # 中間層(活性化関数: シグモイド関数)
fc2 = fullyconnected_layer(name=‘fc2’, input_tensor=act1,
num_output=10) # 出力層 (ニューロン数: 10)
y_ = tf.nn.softmax(fc2, name=‘tf_softmax’) # 出力層(softmax)](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-43-320.jpg)
![TensorFlowでMLPを学習しよう
43
y = tf.placeholder(tf.float32, [None, 10]) # ラベル(正解データ)
#===== 学習の設定 =====
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(y_),
reduction_indices=[1])) # ロス関数 (交差エントロピー)
train_step =
tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize
(cross_entropy) # 学習方法の設定(学習率とロス関数を指定)
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 変数の初期化](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-44-320.jpg)

![TensorFlowでMLPを学習しよう
45
#==== レイヤ記述用の関数 ====
def fullyconnected_layer(name, input_tensor, num_output):
with tf.variable_scope(name):
nInput = input_tensor.shape[1] # 入力xの次元数
weight_matrix = tf.get_variable(name=‘weight’,
shape=(nInput, num_output)) # 重みW (nInput×num_output行列)
bias_vector = tf.get_variable(name=‘bias’,
initializer=tf.zeros(shape=(num_output))) # バイアスb
layer = tf.matmul(input_tensor, weight_matrix)# Wx
layer = tf.nn.bias_add(layer, bias_vector) # Wx+b
return layer
def activation_function_layer(name, input_tensor, act_func):
with tf.variable_scope(name):
if act_func is 'relu’: # ReLU関数
layer = tf.nn.relu(input_tensor, name='ReLU’)
elif act_func is ‘sigmoid’: # シグモイド関数
layer = tf.nn.sigmoid(input_tensor, name='Sigmoid’)
...](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-46-320.jpg)


![ディープネットワーク
? 層の多い MLP: 学習は同じコンセプト
? ResNet: 有名な画像認識モデル
………入力層 出力層
[He et al., 2016] https://arxiv.org/abs/1512.03385
49
(36 layers)](https://image.slidesharecdn.com/lectureshare-180709102808/85/Machine-Learning-Fundamentals-IEEE-50-320.jpg)








Machine Learning Fundamentals IEEE
- 1. この資料は「第3回 IEEE SIGHT ハックチャレンジ 」のために作 られました。 別の目的での使用には、下記の引用が必要です: Tejero-de-Pablos A. (2018). 机械学习の基础 [PowerPoint slides]. Retrieved from /AntonioTejerodePablo/machine-learning- fundamentals-ieee This material was originally created for the “3rd IEEE SIGHT Hack Challenge” event. If used for a different purpose, the following citation is necessary: Tejero-de-Pablos A. (2018). 机械学习の基础 [PowerPoint slides]. Retrieved from /AntonioTejerodePablo/machine-learning- fundamentals-ieee
- 3. 人工知能とは? ? 人工知能:機械が知的行動できる ? 機械学習:機械にデータを与えたら自動学習 ? ディープラーニング:機械はより汎用的な理解 を取得 https://blogs.nvidia.com 2
- 4. なぜ機械学習? ? 実用面で ? 開発時間の加速 ? 人がルールを考える → 機械がデータからルールを学習 ? 人が解けない問題も機械が解ける ? 拡張性の高さand generalizable ? For philosophical reasons ? Efficient problem solving ? Think as an engineer ? Think as a scientist 3
- 5. Agenda ? 機械学習のフレームワーク ? 学習 ? 特徴抽出 ? 识别 ? ニューラルネットワーク ? ディープラーニング ? まとめ 4
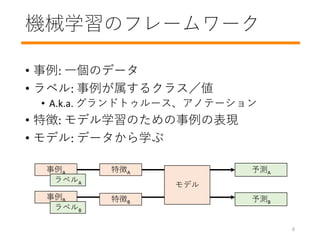
- 7. 機械学習のフレームワーク ? 事例: 一個のデータ ? ラベル: 事例が属するクラス/値 ? A.k.a. グランドトゥルース、アノテーション ? 特徴: モデル学習のための事例の表現 ? モデル: データから学ぶ モデル 事例A 予測A ラベルA 予測B 事例B ラベルB 特徴A 特徴B 6
- 8. 機械学習のフレームワーク ? タスク: スパム検出 ? 事例: 一個メール ? ラベル: スパム/NOTスパム ? 特徴:単語数、送信者など ? モデル: スパム検出器 スパム 検出器 Eメール [256, 0 … 3] スパム NOTスパム 7
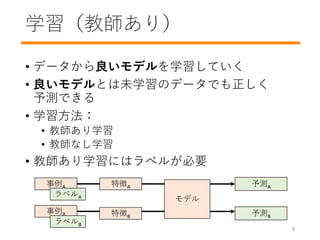
- 9. 学習(教師あり) ? データから良いモデルを学習していく ? 良いモデルとは未学習のデータでも正しく 予測できる ? 学習方法: ? 教師あり学習 ? 教師なし学習 ? 教師あり学習にはラベルが必要 モデル 事例A 予測A ラベルA 予測B 事例B ラベルB 特徴A 特徴B 8
- 10. 学習 vs. テスト ? 学習モード: モデル更新(繰り返し) ? テスト?推論モード: モデル固定 (更新無し) スパム 検出器 EメールA スパム? NOTスパム? NOTスパム [256, 0 … 3] NOTスパム 更新 (誤差) スパム 検出器 EメールB スパム? NOTスパム? [89, 1 … 3] 誤差 9
- 11. 识别 vs. regression (回帰) 教師あり学習によってできるタスクは二つある ? 识别: 予測値は事例のクラス種類 ? 例: 犬、猫、バナナ ? Regression: 予測値はクラスではなく連続値 ? 例: 温度予測 10
- 12. 学習 (Regression)
- 13. 教師あり学習 ? データ (x) から“ロス”の最小化により良いモデ ル (W) を学習していく ? 良いモデルは見たことのないデータに対して 正しく予測 (y’) を出力できる ? 教師あり学習にはラベル (y) が必要 W = {w0, w1 … wn} xA y’A yA y’B xB yB {x1 … xn}A {x1 … xn}B 12
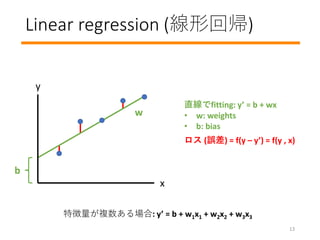
- 14. Linear regression (線形回帰) ロス (誤差) = f(y – y’) = f(y , x) 直線でfitting: y’ = b + wx ? w: weights ? b: bias 特徴量が複数ある場合: y’ = b + w1x1 + w2x2 + w3x3 x y b 13 w
- 15. ロス ? モデルが出した予測がどれくらい悪かったか ? 低ければ低いほど良い ? 2乗誤差(Squared loss 、L2ロス): (y – y’)2 ? 各データ毎の誤差 ? 学習: データセット全体に対するロスを減らす ? 平均2乗誤差(Mean square error、MSE): ? データセット全体の誤差 ? ??? = 1 ? ?,? ∈?(? ? ?′(?))2 ? N: 事例数、D: Dataset 14
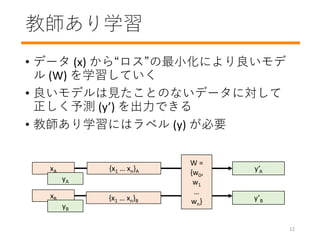
- 16. 学習ループ ? 初期値: ? linear regression なら初期値は何でもよい(乱数でOK) ? Iteration(繰り返し) 1, 2, 3, … ? 入力事例 x ? 予測 y’ ? ロスの計算 ? モデル w 更新 ? 学習の終了(収束判定): ? w がほとんど更新されないor全くされない (0 loss) スパム 検出器 EメールA スパム? NOTスパム? NOTスパム [256, 0 … 3] NOTスパム 更新 (ロス) ロス 15
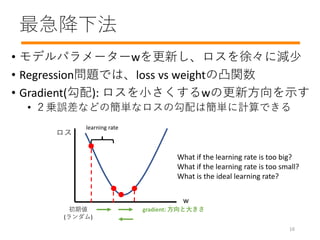
- 17. 最急降下法 ? モデルパラメーターwを更新し、ロスを徐々に減少 ? Regression問題では、loss vs weightの凸関数 ? Gradient(勾配): ロスを小さくするwの更新方向を示す ? 2乗誤差などの簡単なロスの勾配は簡単に計算できる w ロス 初期値 (ランダム) gradient: 方向と大きさ learning rate What if the learning rate is too big? What if the learning rate is too small? What is the ideal learning rate? 16
- 18. データの分割: 学習/テスト 学習したモデルの精度はどれくらい良いか モデルを評価するためにテストデータを用意 ? 統計的に充分な数 ? データセット全体を代表 一般的な分け方(学習/テスト): ? 80%/20% ? 66%/33% Test set Train set 17
- 19. TensorFlowでregressorを学習しよう features,labels = read_data() # 特徴量を読み込む features = feature_normalize(features) # 正規化 rnd_indices = np.random.rand(len(features)) < 0.80 train_x = features[rnd_indices] # データを分ける train_y = labels[rnd_indices] test_x = features[~rnd_indices] test_y = labels[~rnd_indices] learning_rate = 0.01 # 学習変数の初期化 training_iterations = 1000 loss_history = np.empty(shape=[1],dtype=float) 18
- 20. TensorFlowでregressorを学習しよう n_dim = features.shape[1] # TensorFlowの変数コンテナ X = tf.placeholder(tf.float32,[None,n_dim]) Y = tf.placeholder(tf.float32,[None,1]) W = tf.Variable(tf.ones([n_dim,1])) init = tf.initialize_all_variables() # 学習変数の初期化 y_ = tf.matmul(X, W) # 学習関数の宣言 loss = tf.reduce_mean(tf.square(y_ - Y)) training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) 19
- 21. sess = tf.Session() sess.run(init) for iteration in range(training_iterations): # 学習モード sess.run(training_step,feed_dict={X:train_x,Y:train_y}) loss_history = sess.run(loss,feed_dict={X: train_x,Y: train_y}) pred_y = sess.run(y_, feed_dict={X: test_x}) # テストモード sess.close() 20 TensorFlowでregressorを学習しよう
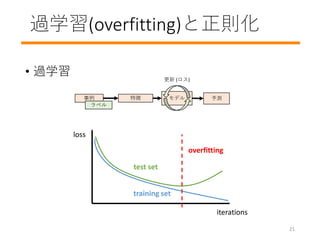
- 22. 過学習(overfitting)と正則化 ? 過学習 モデル事例 予測 ラベル 特徴 更新 (ロス) iterations loss test set training set overfitting 21
- 23. 過学習(overfitting)と正則化 ? 正則化 ? λ大: モデルがシンプルになり過ぎて不十分な学 習 ? 低い精度 ? λ小: モデルが複雑になり過ぎて過学習 ? 未学 習データに弱い ? 理想的なλは?データに依存 ? 試行錯誤して! 22 minimize(loss(x, y) + ???????????(?))
- 24. データ: Validation モデル調整のために学習データを更に分割 Training setで モデルを学習 Validation setで モデルを評価 モデルを調整: ? Hyperparameters ? 特徴量 ? … validation setを一番 良く予測したモデル をTest setで評価 iterations loss validation set training set overfitting Test set Train set Val set 23
- 25. 特徴抽出
- 26. 特徴抽出 生データと特徴量のマッピング ? 数値: 直接マッピング ? IDなどの非数値データは? 生データ email: ? 単語数: 129 ? 受信数: 12 ? 送信者: s2@mail.com ? … 特徴量 x: ? 129.0 ? 12.0 ? 2? ? … 特徴抽出 3人の送信者: s0@mail.com, s1@mail.com, s2@mail.com 生データ email: ? 送信者: s2@mail.com 特徴量 x: ? [0, 0, 1] 特徴抽出 25
- 27. 特徴抽出:データの精査 ? 正規化 (例 [100~900] ? [-1~1]): ? 学習の収束を高速化 ? Be careful with: ? 外れ値 ? 欠損値 ? データの重複 ? ラベル誤り ? Analyze your data ? 最大値 / 最小値 ? 平均 / 中央値 ? 標準偏差 頻度 患者の年齢 患者の年齢を予測する ためのデータセット 26
- 29. 识别
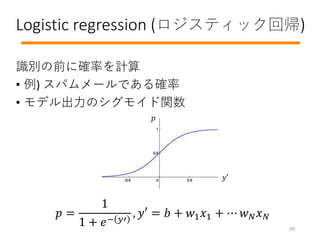
- 30. Logistic regression (ロジスティック回帰) 识别の前に確率を計算 ? 例) スパムメールである確率 ? モデル出力のシグモイド関数 ? = 1 1 + ?? ?′ , ?′ = ? + ?1 ?1 + ? ? ? ? ? ? ?′ 29
- 31. Logistic regression: 演習 Logistic regression モデル: ? b = 1 ? w1 = 2 ? w2 = -1 ? w3 = 5 確率pの値は? 特徴量: ? x1 = 0 ? x2 = 10 ? x3 = 2 p = 73% 30
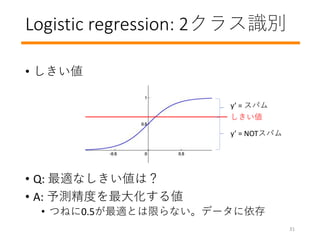
- 32. Logistic regression: 2クラス识别 ? しきい値 ? Q: 最適なしきい値は? ? A: 予測精度を最大化する値 ? つねに0.5が最適とは限らない。データに依存 y’ = スパム y’ = NOTスパム しきい値 31
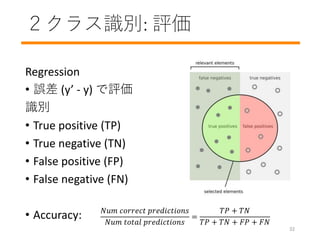
- 33. 2クラス识别: 評価 Regression ? 誤差 (y’ - y) で評価 识别 ? True positive (TP) ? True negative (TN) ? False positive (FP) ? False negative (FN) ? Accuracy: ??? ??????? ??????????? ??? ????? ??????????? = ?? + ?? ?? + ?? + ?? + ?? 32
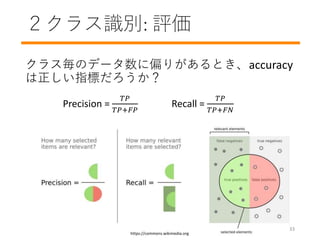
- 34. 2クラス识别: 評価 クラス毎のデータ数に偏りがあるとき、accuracy は正しい指標だろうか? https://commons.wikimedia.org Precision = ?? ??+?? Recall = ?? ??+?? 33
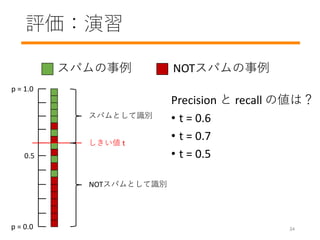
- 35. 評価:演習 スパムの事例 NOTスパムの事例 スパムとして识别 NOTスパムとして识别 しきい値 t p = 1.0 p = 0.0 0.5 Precision と recall の値は? ? t = 0.6 ? t = 0.7 ? t = 0.5 34
- 36. ニューラル ネットワーク
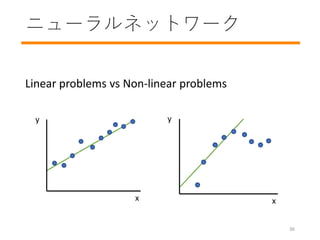
- 37. ニューラルネットワーク Linear problems vs Non-linear problems x y x y 36
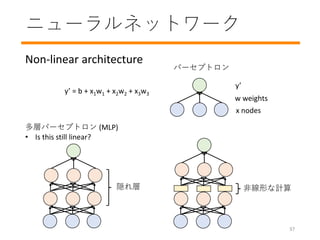
- 38. ニューラルネットワーク Non-linear architecture y’ = b + x1w1 + x2w2 + x3w3 非線形な計算 y’ w weights x nodes 隠れ層 多層パーセプトロン (MLP) ? Is this still linear? パーセプトロン 37
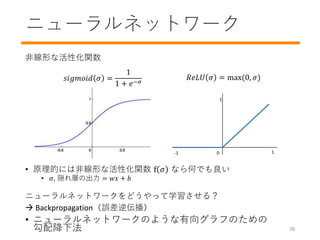
- 39. ニューラルネットワーク 非線形な活性化関数 ? 原理的には非線形な活性化関数 f ? なら何でも良い ? ?, 隠れ層の出力 = ?? + ? ニューラルネットワークをどうやって学習させる? ? Backpropagation(誤差逆伝播) ? ニューラルネットワークのような有向グラフのための 勾配降下法 1 -1 10 ??????? ? = 1 1 + ??? ???? ? = max(0, ?) 38
- 40. ニューラルネットワークのまとめ ニューラルネットワークの要素: ? Nodes (ニューロン) ? Weights (レイヤー間接続) と biases ? 活性化関数 ニューラルネットワークは “Backpropagation”で学習 39
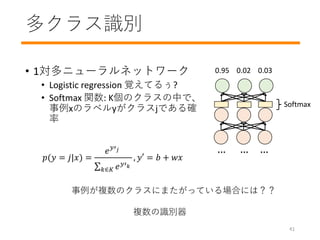
- 42. ? 1対多ニューラルネットワーク ? Logistic regression 覚えてるぅ? ? Softmax 関数: K個のクラスの中で、 事例xのラベルyがクラスjである確 率 … … … Softmax 0.95 0.02 0.03 ?(? = ?|?) = ? ?′ ? ?∈? ? ?′ ? , ?′ = ? + ?? 事例が複数のクラスにまたがっている場合には?? 複数の识别器 41 多クラス识别
- 43. TensorFlowでMLPを学習しよう 42 dataset.load() # データセットの読み込み data_size = dataset.size #===== ネットワークの作成 ===== x = tf.placeholder(tf.float32, [None,(data_size)]) # 入力 fc1 = fullyconnected_layer(name=‘fc1’, input_tensor=x, num_output=256) # 中間層 (ニューロン数: 256) act1 = activation_function_layer(name=‘act1’, input_tensor=fc1, act_func=‘sigmoid’) # 中間層(活性化関数: シグモイド関数) fc2 = fullyconnected_layer(name=‘fc2’, input_tensor=act1, num_output=10) # 出力層 (ニューロン数: 10) y_ = tf.nn.softmax(fc2, name=‘tf_softmax’) # 出力層(softmax)
- 44. TensorFlowでMLPを学習しよう 43 y = tf.placeholder(tf.float32, [None, 10]) # ラベル(正解データ) #===== 学習の設定 ===== cross_entropy = tf.reduce_mean(-tf.reduce_sum(y * tf.log(y_), reduction_indices=[1])) # ロス関数 (交差エントロピー) train_step = tf.train.GradientDescentOptimizer(learning_rate=0.5).minimize (cross_entropy) # 学習方法の設定(学習率とロス関数を指定) sess = tf.Session() sess.run(tf.global_variables_initializer()) # 変数の初期化
- 45. TensorFlowでMLPを学習しよう 44 dataset.set_train_minibatch_size(128) # 128枚ごとに学習 #==== 学習ループ ===== num_iteration = 50 for iteration in range(num_iteration): train_data, train_label = dataset.read_train_batch() sess.run(train_step, feed_dict={x: train_data, y: train_label}) # 学習データ(128枚ずつ)を読み込み、重みを更新 #==== テスト(推論) Accuracyを計算 ===== test_data, test_label = dataset.read_test_batch() accuracy = sess.run(accuracy, feed_dict={x: test_data, y: test_label})
- 46. TensorFlowでMLPを学習しよう 45 #==== レイヤ記述用の関数 ==== def fullyconnected_layer(name, input_tensor, num_output): with tf.variable_scope(name): nInput = input_tensor.shape[1] # 入力xの次元数 weight_matrix = tf.get_variable(name=‘weight’, shape=(nInput, num_output)) # 重みW (nInput×num_output行列) bias_vector = tf.get_variable(name=‘bias’, initializer=tf.zeros(shape=(num_output))) # バイアスb layer = tf.matmul(input_tensor, weight_matrix)# Wx layer = tf.nn.bias_add(layer, bias_vector) # Wx+b return layer def activation_function_layer(name, input_tensor, act_func): with tf.variable_scope(name): if act_func is 'relu’: # ReLU関数 layer = tf.nn.relu(input_tensor, name='ReLU’) elif act_func is ‘sigmoid’: # シグモイド関数 layer = tf.nn.sigmoid(input_tensor, name='Sigmoid’) ...
- 47. ディープラーニング
- 48. ディープラーニング ? 多数の層から構成されるニューラルネット ワークがベース ? 十分な学習データを与え学習させることで 複雑な問題を解くことが可能 ? 複雑な問題って例えば? ? 人間のような認識能力 ? 十分な学習データって何個ぐらい? ? 例 Imagenetなど 47
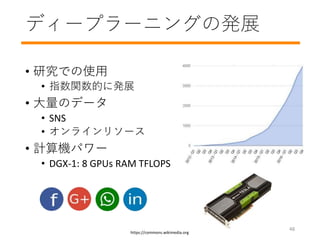
- 49. ディープラーニングの発展 ? 研究での使用 ? 指数関数的に発展 ? 大量のデータ ? SNS ? オンラインリソース ? 計算機パワー ? DGX-1: 8 GPUs RAM TFLOPS https://commons.wikimedia.org 48
- 50. ディープネットワーク ? 層の多い MLP: 学習は同じコンセプト ? ResNet: 有名な画像認識モデル ………入力層 出力層 [He et al., 2016] https://arxiv.org/abs/1512.03385 49 (36 layers)
- 51. ? ツール ディープラーニングプラットフォーム アプリケーション 画像認識、自動翻訳、等 開発ツール PyTorch、Chainer、等 HW Middleware CUDA、OpenMP、等 ハードウェア GPU、Cluster、Amazon Web Services、等 50
- 52. 畳み込みニューラルネットワーク ? 人の手による特徴抽出は困難な場合がある ? 顔認識のための特徴量は? ? 目の数: 2 ? 鼻の下に口がある?: Yes ? … ? https://commons.wikimedia.org 51
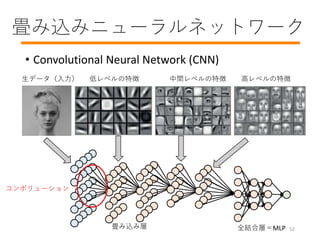
- 53. 畳み込みニューラルネットワーク ? Convolutional Neural Network (CNN) 生データ(入力) 低レベルの特徴 中間レベルの特徴 高レベルの特徴 全結合層=MLP畳み込み層 コンボリューション 52
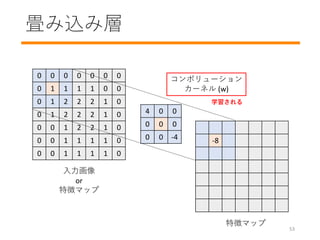
- 54. 畳み込み層 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 1 2 2 2 1 0 0 1 2 2 2 1 0 0 0 1 2 2 1 0 0 0 1 1 1 1 0 0 0 1 1 1 1 0 4 0 0 0 0 0 0 0 -4 -8 入力画像 or 特徴マップ コンボリューション カーネル (w) 特徴マップ 学習される 53
- 55. 画像データセット ? MNIST ? CIFAR-10 ? ImageNet ? 学習:120万枚 ? テスト: 10万枚 ? クラス数:1000 ? 学習:5万枚 ? テスト: 1万枚 ? クラス数:10 ? 学習:6万枚 ? テスト: 1万枚 ? クラス数:10 https://commons.wikimedia.org 54
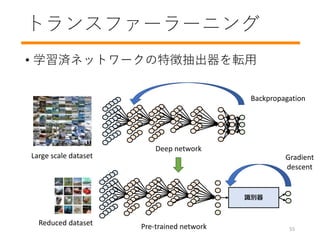
- 56. トランスファーラーニング ? 学習済ネットワークの特徴抽出器を転用 Large scale dataset Deep network Backpropagation Reduced dataset Pre-trained network 识别器 Gradient descent 55
- 57. もっと勉強したい人へ ? 実際にやってみよう! ? 2クラス识别問題 ? 画像の多クラス识别問題 ? ディープラーニングを動かす数式も学ぼう ? Test your skills! https://www.kaggle.com 56
- 58. まとめ
- 59. まとめ ? 事例、特徴、モデル、予測 ? 学習:ロス、gradient descent ? オーバフィテッイング:Train, test, validation ? Regression, logistic regression, classification, multi- class classification ? 評価: Accuracy, precision, recall ? ニューラルネットワーク (non-linearity) ? MLP、backpropagation ? ディープラーニング ? 畳み込み層 58
- 60. まとめ ? 機械学習がデータへの理解をより深くする ? ディープラーニング: ? 表現力の高いモデルを学習 ? 複雑なタスクでも高いパフォーマンス ? 大量の学習データが必要 ? 機械学習において、アルゴリズムはエンジンで データは燃料 ? 機械学習を開発するツールは多く存在する 社会 59
- 61. 参考文献 本 ? 機械学習 ? C. Bishop, “Pattern Recognition and Machine Learning” ? ディープラーニング ? I. Goodfellow, “Deep learning” ? コンピュータビジョン ? 原田達也, “画像認識” オンラインコース ? Google ? https://developers.google.com/machine-learning/crash-course/ ? Coursera ? https://www.coursera.org/learn/machine-learning 60
Editor's Notes
- #4: ?Artificial Intelligence is the broader concept of machines being able to carry out tasks in a way that we would consider “smart”. ?Machine Learning is a current application of AI based around the idea that we should really just be able to give machines access to data and let them learn for themselves. ?Deep learning: The machine is able to understand a broader set of cases. Greater generalization.
- #5: Deciding if a mail is a spam or not Not solvable by people: Predicting the stock market Generalizable: Same model can distinguish, “dogs from cats” and “birds from flowers” Think as a scientist: Think the fundamentals of the problem instead of the implementation
- #10: Predicting learned data is 当たり前 In this lecture, we will focus on supervised learning
- #12: For example: predicting the cost of a house would be classification or regression? Predicting if a movie will be successful or not? 学習のプロセスを詳しく見てみましょう
- #14: How do you train a model? How do you decide these w values?
- #17: Shuusoku
- #19: Data is the fuel (nenryou) to our machine learning model Getting 100% accuracy with 3 instances is not meaningful You cannot keep low values only in your training set and try to predict high values
- #21: sengen
- #23: Learning English from a teenager
- #24: Seizokuka Doing trial and error (chousei) with the test data is not good
- #27: Suuchi
- #28: Seikika By knowing your data you can strategize better: Is the dataset imbalanced? Should I normalize?
- #29: Hint: This is a non-linear problem
- #35: Katayori ga aru
- #36: The lower the threshold, the better the recall. The higher the threshold, the better the precision ? Tradeoff
- #40: Kasseika kansuu
- #42: From binary to multiclass
- #44: What is the size of the input for fc1?
- #45: Gradient descent strategy for updating our model. What algorithm is used for learning? Backpropagation
- #51: Do you know what it is called deep?
- #53: Konnan
- #55: Kernel varies in sizes and jumps
- #56: Well-known datasets allow researchers to compare their methods fairly
- #61: Nenryou