







































More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to Model regresi-non-linear (20)




















Model regresi-non-linear
- 1. MODEL REGRESI NON LINEAR DAN UJI DETEKSI HUBUNGAN NONLINEAR Azwar Rhosyied1 â 1305 100 054 Saudi Imam Besari2 â 1306 100 046 Arisman Wijaya3 â 1306 100 042 1 rhosyied54@gmail.com, 2e_saudi@ymail.com , 3arin_mathlover@yahoo.co.id Abstract In our living, there are many data doesnât has linear pattern. So it is fit to using non linear model to solving it. The purpose of this research is applying non linear regression model for three cases using SPSS, SAS and R software. The best model for the first case is adalah Yt = 81,84 + 102,40 exp(ât/203,19) + Δ . 29,4v + Δ is the model for the second case. All software has the same w â 2,22 result in estimating parameter for this model. For the third case, we use the newest model, Nelson Siegel (N-S) and Nelson Siegel Svensson (N-S-S) model with yield curve data. The result for each model is YTM = 0.133 - 0.031* exp( - TTM / 2.265) â 0.014*exp((TTM /2.265) * exp( - TTM / 2.265)) expecially for N-S model, YTM = 0.647 + 0.4*exp( -TTM / 0.601) â 0.087* ((TTM / 0.601) * exp(TTM /0.601)) + 0.004 * (( -TTM / 0.545) * exp( - TTM / 0.545)) expecially for N-S-S model. T = Keywords : Nelson Siegel, stormer viscometer, model non linear, yield curve 1. Pendahuluan Peristiwa di sekitar sering merupakan kejadian yang dapat dimodelkan dengan persamaan regresi. Berdasarkan hubungan kelinearan antar parameter dalam persamaan regresi, model regresi mempunyai dua bentuk hubungan kelinearan yaitu regresi linear dan regresi nonlinear. Seringkali kejadian dalam kehidupan sehari-hari lebih sering merupakan pola model regresi nonlinear. Untuk itu dalam makalah ini akan dibahas mengenai model regresi nonlinear. Beberapa penelitian yang menggunakan regresi non-linear diantaranya oleh Miconnet, Geeraerd, Impe, Roso, dan Cornu (2005) yaitu memodelkan produksi padi dengan least square non-linear dalam permodelan kurva pertumbuhan dalam produksi. Dalam makalah ini sebagai studi kasus adalah data tentang program penurunan berat badan yang diikuti oleh seorang pasien laki-laki. Data kedua adalah data the stromer viscometer dan data tentang yield curve. Proses untuk mendapatkan model nonlinear pada penelitian ini digunakan software SPSS, SAS dan R, sehingga dapat membandingkan hasil output dari ketiga software tersebut. 2. Tinjauan Pustaka Pada bagian ini dibahas mengenai metode dan beberapa teori yang mendukung untuk pengerjaan analisis hubungan non-linear. 1
- 2. 2.1 Uji Deteksi Non-linear dengan Uji Ramseyâs RESET, Uji White dan Uji Terasvirta Uji Ramseyâs RESET, Uji White dan Uji Terasvirta untuk mendeteksi apakah suatu model mengikuti pola linear atau non-linear tersedia dalam software R. Statistik uji Ramseyâs RESET adalah (Lihat pembahasan lengkap di Gujarati, 1996). F= 2 2 (Rnew â Rold ) / p 2 (1 â Rnew ) / (n â k) (1) dengan p jumlah variabel independen baru, k jumlah parameter pada model baru, n jumlah data. Kesimpulanya Ho ditolak bila F > F(α,p,n-k) Uji White adalah uji deteksi non-linearitas yang dikembangkan dari model neural network yang ditemukan oleh White (1989). Uji white menggunakan statistik Ï2 dan F. Prosedur yang digunakan untuk Ï2 adalah : a. Meregresikan yt pada 1, x1, x2, âŠ, xp dan menghitung nilai-nilai residual ut . Ë b. Meregresikan u t pada 1, x1, x2, âŠ, xp dan m prediktor tambahan dan kemudian hitung koefisien determinasi dari regresi R2. Dalam uji ini, m ' prediktor tambahan ini adalah nilai-nilai dari hasil dari Ï(Îł j wt ) hasil dari suatu transformasi komponen utama. c. Hitung Ï2 =nR2, dimana n adalah jumlah pengamatan yang digunakan. 2 Dengan hipotesis linearitas, Ï2 mendekati distribusi Ï( m ) atau tolak Ho jika P-value < α. Uji Terasvirta adalah uji deteksi non-linearitas yang juga dikembangkan dari model neural network dan termasuk dalam kelompok uji tipe Lagrange Multiplier (LM) yang dikembangkan dengan ekspansi Taylor (Terasvirta, 1993). Pengambilan kesimpulan ketiga uji tersebut dapat dilihat melalui nilai P-value, yaitu tolak Ho jika kurang dari α . 2.2 Model Regresi Non-linear Parametrik Berdasarkan kelinearan antar parameter pada model regresi, maka suatu model regresi dapat diklasifikasikan menjadi dua macam yaitu model linear dan non-linear. Model regresi dikatakan linear jika dapat dinyatakan dalam model : y = ÎČ0 + ÎČ1 x1+ÎČ2 x2 + ÎČ3 x3 + ... + ÎČk xk + Δ (2) Apabila model tidak dapat dinyatakan dalam model tersebut maka model yang diperoleh adalah model non-linear. Secara umum model regresi non-linear parametrik dengan sebagai variabel respon pada replikasi sebanyak dan setiap nilai merupakan variabel independen.dapat dinyatakan dalam persamaan (Ripley, 2002) : (3) Yij = f ( xi , Ξ) +Δij dengan f adalah fungsi regresi dengan parameter Ξ yang harus diduga dan adalah galat dengan sifat N(0,α). Salah satu metode pendugaan parameter dalam sistem non-linear adalah jalan tengah Marquardt (Marquadtâs compromise). Metode Marquardt merupakan kompromi atau jalan tengah antara metode linearisasi atau deret Taylor dengan metode steepest descent (Draper & Smith, 1996). 2
- 3. 2.3 Model Nelson Siegel (N-S) dan Nelson Siegel Svensson (N-S-S) Tahun 1987, Nelson dan Siegel menunjukkan yield curve dari model yang terletak pada bentuk range yang sama. Model N-S dan N-S-S merupakan pendekatan untuk mendapatkan model yield curve. Model N-S dinyatakan dalam persamaan sebagai berikut ïŁźïŁ« m ïŁ¶ ïŁ« mïŁ¶ ïŁ« m ïŁ¶ïŁč ÎłË ( m ) = ÎČ 0 + ÎČ1 expïŁŹ â ïŁ· + ÎČ 2 exp ïŁŻïŁŹ ïŁ· expïŁŹ â ïŁ·ïŁș (4) ïŁ Ï ïŁž ïŁ Ï ïŁžïŁ» ïŁ°ïŁ Ï ïŁž ï© dengan Îł ( m ) adalah nilai yield to maturity (YTM yang )merupakan yield dengan pendekatan forward rate pada maturitas m atau time to maturity (TTM). Sedangkan parameter Ï merupaka konstanta waktu dari belokan kurva dan parameter ÎČ 0 menunjukkan nilai asimtotik atau konstanta, serta ÎČ dan ÎČ2 merupakan 1 parameter yang menunjukkan arah lengkungan dari kurva. Sedangkan model N-S-S berikut merupakan pengembangan dari model N-S dengan penambahan parameter ÎČ dan Ï3 yang digunakan untuk menambah 3 fleksibilitas kurva (Amoako et al, 2005). ïŁźïŁ« m ïŁ¶ ïŁźïŁ« m ïŁ¶ ïŁ« mïŁ¶ ïŁ« m ïŁ¶ïŁč ïŁ« m ïŁ¶ïŁč ÎłË ( m ) = ÎČ 0 + ÎČ1 expïŁŹ â ïŁ· + ÎČ 2 exp ïŁŻïŁŹ ïŁ· expïŁŹ â ïŁ·ïŁș + ÎČ 3 ïŁŻïŁŹ ïŁ· expïŁŹ â ïŁ·ïŁș (5) ïŁŹ Ï ïŁ· ïŁŹÏ ïŁ· ïŁŹ Ï ïŁ· ïŁŹÏ ïŁ· ïŁŹ Ï ïŁ· ïŁ 1ïŁž ïŁ 1 ïŁžïŁ» ïŁ 2 ïŁžïŁ» ïŁ°ïŁ 1 ïŁž ïŁ°ïŁ 2 ïŁž 3. Metodologi Penelitian Dalam penelitian ini digunakan tiga jenis data. Masalah pertama adalah data mengenai program penurunan berat badan yang diikuti oleh pasien laki-laki dengan variabel prediktor adalah hari (t) dan berat badan dalam kg (yt) sebagai variabel respon. Data kedua mengenai The Stormer Viscometer dengan viscosity (v) dan berat fluida (w) sebagai variabel prediktor dan waktu (T) sebagai variabel respon. Ketiga adalah data mengenai transaksi perdagangan obligasi pemerintah pada periode 6 April 2009 dengan variabel prediktor adalah time to maturity (TTM) dan variabel respon adalah yield to maturity (YTM). Proses penglahan data digunakan software SPSS, SAS dan R dengan langkah-langkah sebagai berikut : 1. Melakukan identifikasi hubungan non-linear dengan Uji Ramseyâs RESET, Uji White dan Uji Terasvirta pada software R. Untuk kasus pertama sintak uji linearitas adalah sebagai berikut. >library(lmtest) > resettest(y.t. ~ t , power=2, type="regressor", data=kasus1) > library(tseries) > t<- kasus1$t > y.t.<-kasus1$y.t. > white.test(t, y.t.) > terasvirta.test(t, y.t.) 3
- 4. kasus kedua sintak R adalah sebagai berikut : > library(lmtest) > resettest(t ~ v+w , power=2, type="regressor", data=kasus2) > library(tseries) > t <- kasus2$t > v <-kasus2$v > w <-kasus2$w > x.all <- cbind(v,w) > white.test(x.all, t) sedangkan untuk kasus ketiga sintak yang digunakan adalah sebagai berikut, >library(lmtest) > resettest(ytm ~ ttm , power=2, type="regressor", data=kasus3) > library(tseries) > y<- kasus3$ytm > x<-kasus3$ttm > white.test(x,y) 3. Memodelkan data kasus 1 dengan pemodelan non-linear, kuadratik dan kubik. Model non-linear yang diberikan adalah (Ripley, 2002) : Yt = ÎČ0 + ÎČ1 exp(ât/Ξ) + Δ Identifikasi awal penaksiran parameter ÎČ00, ÎČ10, dan Ξ0 yaitu : a. Melakukan regresi kuadratik antara variabel hari (t) sebagai prediktor dan berat dalam kg (Yt) sebagai respon. Sehingga didapatkan nilai fitted Ë value yi . Model kuadratik tersebut : Yt = ÎČ0* + ÎČ1*t + ÎČ2*t2 + Δ b. Memilih tiga data secara berurutan xo, x1, x2 dari n data yang memiliki Ë Ë Ë selisih sama ( ÎŽ ). Sehingga didapatkan y 0 , y1 , dan y 2 . Ξ dengan rumus : c. Menentukan nilai 0 Ξ0 = ÎŽ Ë Ë ïŁ« y â y1 ïŁ¶ logïŁŹ o ïŁŹy ây ïŁ· ïŁ· ïŁ Ë1 Ë 2 ïŁž d. Menentukan ÎČ00 dan ÎČ10 dengan meregresikan Yt sebagai respon dengan exp(-t/ Ξ ) sebagai prediktor. 0 4
- 5. Makro penaksiran parameter dengan SAS : title 'Non linear regression'; data kasus1; input t y; datalines; 0 185 ï ï 249 111; proc model data=kasus1; y = bo+b1*exp(-t/teta); fit y start=(bo -67.501 b1 246.022 teta 729.464)/out=resid outall; run; proc print kasus1=resid; run; Makro penaksiran parameter dengan R : kasus1<-nls(y.t.~beta0+beta1*(exp(-t/teta)),data=kasus1, start=list(beta0= -67.51, beta1= 246.022, teta= 729.5), trace=TRUE) Menghitung eksplorasi data dengan t>250 yaitu dimulai dari t=251 hingga t=356. Setelah itu membadingkan antar model non-linear, kuadratik maupun kubik. 4. Melakukan permodelan data studi kasus kedua dengan permodelan regresi non-linear. Model non-linear adalah : T= ÎČ 1v +Δ w â ÎČ2 Identifikasi awal penaksiran parameter ÎČ10 dan ÎČ20 dengan melakukan pembentukan model baru dari model tersebut, sehingga menjadi : wT = ÎČ10 v + ÎČ20T + ( w â ÎČ20 )Δ Makro SPSS untuk mendapatkan nilai awal REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA /CRITERIA=PIN(.05) POUT(.10) /ORIGIN /DEPENDENT wT /METHOD=ENTER v T . 5
- 6. Makro SPSS mendapatkan penaksiran parameter * NonLinear Regression. MODEL PROGRAM b1=28.876 b2=2.844 . COMPUTE PRED_ = b1 * v / (w - b2). NLR T /OUTFILE='C:DOCUME~1X2LOCALS~1Tempspss2360SPSSFNLR.TM P' /PRED PRED_ /SAVE PRED Makro penaksiran parameter dengan SAS data kasus2; input w v T; label w='weight' v='viscosity' T='Time'; datalines; 20 14.7 35.6 20 27.5 54.3 ï ï ï 100 161.1 45.1 100 298.3 89 100 298.3 86.5 ; proc nlin data=kasus2 method=MARQUARDT; parms b10=28.9 b20=2.84; model T=b10*v/(w-b20); run; Makro Penaksiran parameter dengan R > fm <- nls(T~ b1*v/(w-b2), start=list(b1=28.9, b2=2.84), data=kasus2, trace=TRUE) > summary(kasus2) 5. Melakukan permodelan data studi kasus keetiga dengan permodelan nonlinear Nelson Siegel (N-S) dan Nelson Siegel Svensson (N-S-S) dengan tahapan sebgai berikut. a. Penentuan nilai awal berdasarkan penelitian oleh Amoako (2002), b0=7.41 b1=-5.41 b2=-5.03 b3=-4.43 t1=0.44 dan t2=1.38. b. Membagi data training dan testing masing-masing sebanyak 100 dan 32 data sampel dan memodelkan NS dan NSS berdasarkan nilai awal. c. Menghitung nilai RMSE untuk masing-masing data training dan testing. d. Memodelkan keseluruhan data dengan model NS dan NSS berdasarkan nilai awal yang sudah ada. 6
- 7. Makro SAS dalam penentuan nilai parameter model N-S data kasus3; input X Y; label X='TTM' Y='YTM'; datalines; 0.0833 0.075 0.1918 0.1056 ï ï 18.874 0.1275; proc nlin data=kasus3 method=MARQUARDT; parms b0=7.41 b1=-5.41 b2=-5.03 t1=0.44; model Y=b0 + b1 * EXP( - X / t1) + b2 *EXP((X /t1) * EXP( - X / t1)); run; Makro SAS dala, penentuan penaksiran parameter model N-S-S data kasus3; input X Y; label X='TTM' Y='YTM'; datalines; 0.0833 0.075 0.1918 0.1056 ï ï 18.874 0.1275; proc nlin data=kasus3 method=MARQUARDT; parms b0=7.41 b1=-5.41 b2=-5.03 b3=-4.43 t1=0.44 t2=1.38; model Y= b0 + b1*exp(-X/t1)+b2*((X/t1)*exp(X/t1))+ b3*((-X/t2)*exp(-X/t2)); run; 4. Hasil analisa data dan pembahasan Hasil analisis pengujian deteksi hubungan non-linear dan regresi non-linear adalah sebagai berikut : 4.1 Pengujian Deteksi Hubungan Non-linear Pengujian hubungan non-linear dengan uji Ramseyâs RESET, uji White dan uji Terasvirta (dengan uji Chi-Square) pada software R yaitu : Tabel 1 Pengujian Deteksi Hubungan Non-linear Data Studi Kasus 1 2 3 Ramseyâs RESET 714.1839 2.2e-16* 7.6107 0,0004* 42.3412 1.544e-09* Keterangan : (*) nilai P-value 7 White 199.7347 2.2e-16* 11.2577 0,0036* 55.1889 1.037e-12* Terasvirta 210.1889 2.2e-16* 91.3249 2.2e-16* 53.9386 1.938e-12*
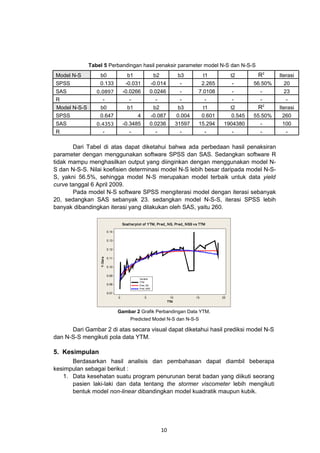
- 8. Dari Tabel 1 di atas dapat diketahui bahwa uji Ramseyâs RESET, Ehite dan Terasvirta menunjukkan hasil bahwa semua data untuk tiap kasus mengikuti bentuk model non-linear . 4.2Model Non-linear Studi Kasus Pertama Pembentukan model non-linear dimulai dengan penaksiran awal parameter yang akan digunakan. Dari persamaan kuadratik Yt = 183.3 â 0.454t + 0.001t 2 + Δ diperoleh tiga data secara berurutan dengan ÎŽ =3 : Ë xo=27 , y 0 = 171.51 Ë x1=30 , y1 = 170.26 Ë x2 =33, y 2 .= 169.03 Sehingga didapatkan Ξ = 428.27, ÎČ00 = 17.97 dan ÎČ10 = 162.13. Kemudian 00 dilanjutkan dengan pembentukan model non-linear dengan software SPSS, R dan SAS dengan parameter awal ÎČ0 = 17.97 dan ÎČ1 = 162.13. Software SPSS R SAS Tabel 2 Model Non-linear pada SPSS, R dan SAS Model R2 Yt = 81,84 + 102,40 exp(ât/203,19) + Δ 99,8 % Δ Yt = 81,84 + 102,40 exp(ât/203,19) + Yt = 81,84 + 102,40 exp(ât/203,19) + Δ 99,8 % Dengan Tabel 2 di atas dapat diketahui bahwa model dan koefisien determinasi (R2) yang diperoleh sama. Dengan estimasi parameter ÎČ0 = 81,84, ÎČ1 = 102,4 dan Ξ = 278,783. Parameter hari(t) tersebut terbukti signifikan berpengaruh 0 dalam model karena P-value kurang dari α = 0,05. Koefisien determinasi yang tinggi sebesar 99,8 % menunjukkan bahwa variabel hari mampu menerangkan penurunan berat badan yang diikuti seorang pasien laki-laki tersebut sebesar 99,8 % yang berarti waktu (hari) sangat berpengaruh terhadap penurunan berat badan. Bila menggunakan metode regresi polinomial kuadratik maka diperoleh persamaan seperti pada pembentukan awal parameter, yaitu Yt = 183,3 - 0,4542t + 0,000684t2 + Δ dengan koefisien determinasi 99,7 %. Dan regresi polynomial kubik yaitu Yt = 184.5 â 0,5133t + 0,001281t 2 â 0,000002t3 dengan koefisien determinansi 99,8 %. Berikut adalah perbandingan fitted value pada model non-linear, kuadratik dan kubik. Scat t er pl ot of yhat _ quad, yhat _ cub, yhat _ non v s t 180 Y- Dat a 160 140 120 Variable y hat_quad y hat_cub y hat_non 100 0 50 100 150 t 200 250 Gambar 1 Plot Ekstrapolasi Data 8 300
- 9. Dari Gambar 1 di atas disimpulkan bahwa model non-linear adalah pilihan model terbaik, karena memperlihatkan hubungan hari dan berat badan yang sama dengan data pembentukan modelnya yaitu semakin besar hari maka berat badan akan semakin menurun. Hal ini juga didukung oleh nilai koefisien determinansi 99,8 % yang besar. 4.3Model Non-linear Studi Kasus Kedua Studi kasus kedua tentang the stormer viscometer untuk mendapatkan model hubungan viscositas(v) dan berat fluida(w) terhadap waktu(T). Pembentukan identifikasiawal penaksiran parameter melalui model wT = 28,9v + 2,84 + ( w â ÎČ 2 )Δ . Kemudian dilanjutkan dengan pembentukan model non-linear dengan software SPSS, R dan SAS dengan parameter awal ÎČ1 = 28,9 dan ÎČ2 = 2,84. Tabel 3 Model Non-linear dengan SPSS, R dan SAS Software SPSS Model 29,4v T = +Δ w â 2,22 R2 99,17 % R T = 29,4v +Δ w â 2,22 - SAS T = 29,4v +Δ w â 2,22 99,17 % Dari Tabel 2 di atas nilai penaksir parameter dan koefisien determinasi keluaran SPSS, R dan SAS sama, dengan estimasi parameter ÎČ1=29,4 dan ÎČ2=2,22 dan R2 = 99.17%. Koefisien determinasi yang tinggi menunjukkan bahwa variabel viskositas dan berat fluida sangat berpengaruh terhadap waktu. 4.4Model Non-linear Nelson Siegel (N-S) dan Nelson Siegel Svensson (N-S-S) Untuk mendapatkan hasil model yang terbaik maka perlu dilakukan validasi dengan membagi data in sampel dan out sample kemudian menghitung nilai RMSE dan membandingkannya. Tabel 4 RMSE in sample dan out sample Model N-S N-S-S RMSE In sample Out sample 0.0029 0.0107 0.0029 0.0108 Dari Tabel 4 di atas dapat diketahui nilai RMSE terkecil adalah pada data in sample untuk model N-S maupun N-S-S, yaitu 0.0029. Berikut adalah perbandingan hasil pemodelan dengan menggunakan data secara keseluruhan. 9
- 10. Tabel 5 Perbandingan hasil penaksir parameter model N-S dan N-S-S Model N-S SPSS SAS R Model N-S-S SPSS SAS R b0 0.133 b1 -0.031 -0.0266 b1 4 -0.3485 - 0.0897 b0 0.647 0.4353 - b2 -0.014 0.0246 b2 -0.087 0.0236 - b3 b3 0.004 31597 - t1 2.265 7.0108 t1 0.601 15.294 - t2 t2 0.545 1904380 - R2 56.50% - R2 55.50% - Dari Tabel di atas dapat diketahui bahwa ada perbedaan hasil penaksiran parameter dengan menggunakan software SPSS dan SAS. Sedangkan software R tidak mampu menghasilkan output yang diinginkan dengan menggunakan model NS dan N-S-S. Nilai koefisien determinasi model N-S lebih besar daripada model N-SS, yakni 56.5%, sehingga model N-S merupakan model terbaik untuk data yield curve tanggal 6 April 2009. Pada model N-S software SPSS mengiterasi model dengan iterasi sebanyak 20, sedangkan SAS sebanyak 23. sedangkan model N-S-S, iterasi SPSS lebih banyak dibandingkan iterasi yang dilakukan oleh SAS, yaitu 260. Scat t er pl ot of YTM, Pr ed_ NS, Pr ed_ NSS v s TTM 0.14 0.13 Y- Dat a 0.12 0.11 0.10 0.09 Variable YTM Pred_NS Pred_NSS 0.08 0.07 0 5 10 TTM 15 20 Gambar 2 Grafik Perbandingan Data YTM, Predicted Model N-S dan N-S-S Dari Gambar 2 di atas secara visual dapat diketahui hasil prediksi model N-S dan N-S-S mengikuti pola data YTM. 5. Kesimpulan Berdasarkan hasil analisis dan pembahasan dapat diambil beberapa kesimpulan sebagai berikut : 1. Data kesehatan suatu program penurunan berat badan yang diikuti seorang pasien laki-laki dan data tentang the stormer viscometer lebih mengikuti bentuk model non-linear dibandingkan model kuadratik maupun kubik. 10 Iterasi 20 23 Iterasi 260 100 -
- 11. 2. Model terbaik pada studi kasus pertama adalah model non-linear Yt = 81,84 + 102,40 exp(ât/203,19) + Δ dengan koefisien determinansi 99,8 %. 3. Model non-linear studi kasus kedua adalah T = 29,4v +Δ w â 2,22 dengan koefisien determinansi (R2) 99,17 %. 4. Software SPSS dan SAS memberikan hasil berbeda dalam menaksir parameter model N-S dan N-S-S, sedangkan software R tidak bisa menghitung taksiran parameter model N-S dan N-S-S Daftar Pustaka Gujarati, D.N. (1996). Basic Econometrics. 5th edition, McGraw Hill International, New York. White, H. 1989.An additional hidden unit test for neglected nonlinearity in multilayer feedforward networks. In Proceedings of The International Joint Conference on Neural Networks, Washington, DC (pp. 451â455). San Diego, CA: SOS Printing. Terasvirta, T., Lin, C.F.,&Granger, C.W.J.1993.Power of the neural network linearity test. Journal of Time Series Analysis, 14, 159â171. Drapper, N.,R.,& Smith, H.1996. Applied Regression Analysis, 2nd edition. New York: John Wiley & Sons. Chapman and Hall. Venables, W., & Ripley, B. 2002. Modern Applied Statistics with S (4th ed.). New York: Springer. 11