Mongo db &_spark
Download as PPTX, PDF5 likes1,363 views

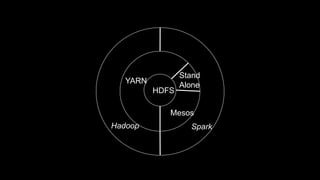
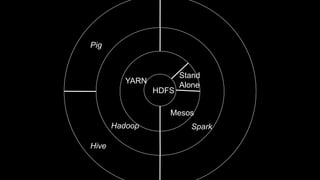
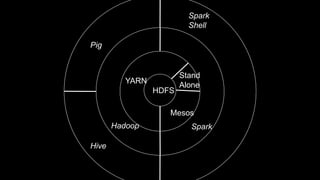
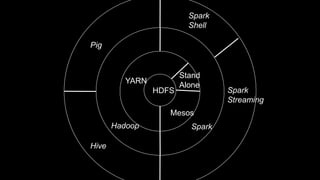
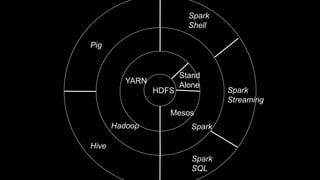
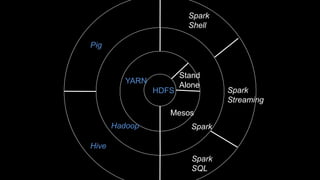
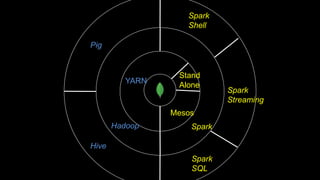
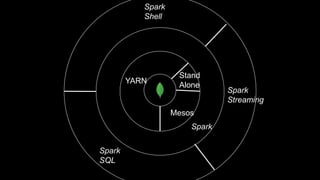
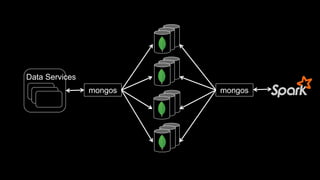
The document describes Spark and how it relates to other big data technologies like HDFS, YARN, and Mesos. It shows how Spark can be used both with these technologies or on its own. Key Spark concepts discussed include Resilient Distributed Datasets (RDDs), transformations, actions, and lineage. It also provides examples of using Spark with MongoDB to read data from a MongoDB collection into an RDD.






























































More Related Content
What's hot (11)
Viewers also liked (11)




Similar to Mongo db &_spark (11)











More from Bryan Reinero (6)






Recently uploaded (20)






![ESET Smart Security Crack + Activation Key 2025 [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/bagc0125seedtechmaizeppt-250402180805-04ae8272-250402193656-b12a103b-thumbnail.jpg?width=560&fit=bounds)





![Windows 8.1 Pro Activator Crack Version [April-2025]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture9-250228130043-bd676d0e-250401141425-60508047-250401150607-9cd2b2bd-thumbnail.jpg?width=560&fit=bounds)




![[Roundtable] Choreo - The AI-Native Internal Developer Platform as a Service](https://cdn.slidesharecdn.com/ss_thumbnails/choreo-deck-250328074645-511dded7-thumbnail.jpg?width=560&fit=bounds)


Mongo db &_spark
- 1. & Spark
- 2. & Spark
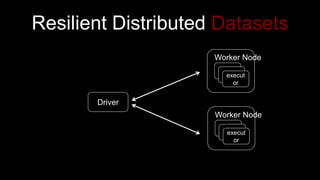
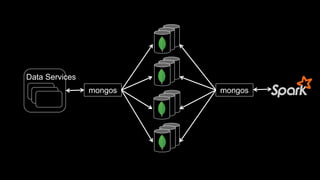
- 28. execut or Worker Node execut or Worker Node Driver Resilient Distributed Datasets
- 29. Resilient Distributed Datasets f(xˇŻˇŻ) = yParellelize = xt(x) = xˇŻt(xˇŻ) = xˇŻˇŻ
- 30. t(x) = xˇŻt(xˇŻ) = xˇŻˇŻf(xˇŻˇŻ) = xˇŻˇŻˇŻParellelize = x Parallelization
- 31. t(x) = xˇŻt(xˇŻ) = xˇŻˇŻf(xˇŻˇŻ) = xˇŻˇŻˇŻParellelize = x Transformations
- 32. Tranformations filter( func ) union( func ) intersection( set ) distinct( n ) map( function )
- 33. t(x) = xˇŻt(xˇŻ) = xˇŻˇŻf(xˇŻˇŻ) = xˇŻˇŻˇŻParellelize = x Action
- 34. Actions collect() count() first() take( n ) reduce( function )
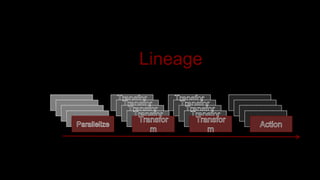
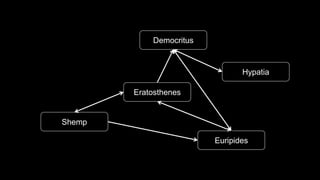
- 35. f(x) = xˇŻf(xˇŻ) = xˇŻˇŻt(xˇŻˇŻ) = xˇŻˇŻˇŻParellelize = x Lineage
- 36. Lineage
- 37. Lineage
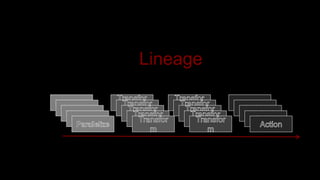
- 38. Lineage
- 39. Lineage
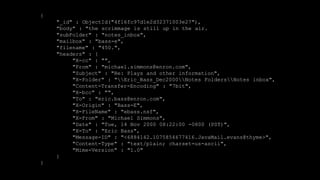
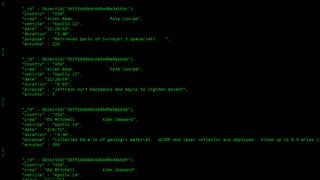
- 41. { "_id" : ObjectId("4f16fc97d1e2d32371003e27"), "body" : "the scrimmage is still up in the air. "subFolder" : "notes_inbox", "mailbox" : "bass-e", "filename" : "450.", "headers" : { "X-cc" : "", "From" : "michael.simmons@enron.com", "Subject" : "Re: Plays and other information", "X-Folder" : "Eric_Bass_Dec2000Notes FoldersNotes inbox", "Content-Transfer-Encoding" : "7bit", "X-bcc" : "", "To" : "eric.bass@enron.com", "X-Origin" : "Bass-E", "X-FileName" : "ebass.nsf", "X-From" : "Michael Simmons", "Date" : "Tue, 14 Nov 2000 08:22:00 -0800 (PST)", "X-To" : "Eric Bass", "Message-ID" : "<6884142.1075854677416.JavaMail.evans@thyme>", "Content-Type" : "text/plain; charset=us-ascii", "Mime-Version" : "1.0" } }
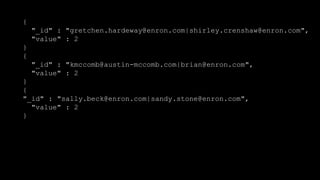
- 42. { "_id" : "gretchen.hardeway@enron.com|shirley.crenshaw@enron.com", "value" : 2 } { "_id" : "kmccomb@austin-mccomb.com|brian@enron.com", "value" : 2 } { "_id" : "sally.beck@enron.com|sandy.stone@enron.com", "value" : 2 }
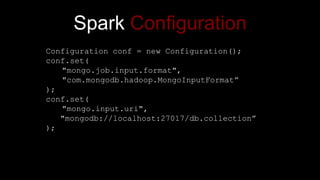
- 44. Spark Configuration Configuration conf = new Configuration(); conf.set( "mongo.job.input.format", "com.mongodb.hadoop.MongoInputFormatˇ± ); conf.set( "mongo.input.uri", "mongodb://localhost:27017/db.collectionˇ± );
- 45. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 46. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 47. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 48. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
- 49. Spark Context JavaPairRDD<Object, BSONObject> documents = context.newAPIHadoopRDD( conf, MongoInputFormat.class, Object.class, BSONObject.class );
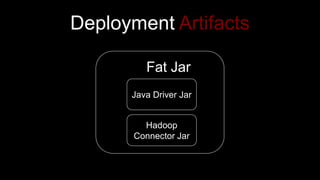
- 51. Deployment Artifacts Hadoop Connector Jar Fat Jar Java Driver Jar
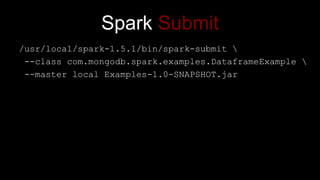
- 52. Spark Submit /usr/local/spark-1.5.1/bin/spark-submit --class com.mongodb.spark.examples.DataframeExample --master local Examples-1.0-SNAPSHOT.jar
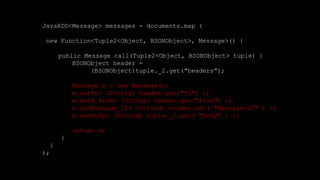
- 54. JavaRDD<Message> messages = documents.map ( new Function<Tuple2<Object, BSONObject>, Message>() { public Message call(Tuple2<Object, BSONObject> tuple) { BSONObject header = (BSONObject)tuple._2.get("headers"); Message m = new Message(); m.setTo( (String) header.get("To") ); m.setX_From( (String) header.get("From") ); m.setMessage_ID( (String) header.get( "Message-ID" ) ); m.setBody( (String) tuple._2.get( "body" ) ); return m; } } );
- 55. & Spack DEMO
- 62. THANK S!{ Name: ˇ®Bryan ReineroˇŻ, Title: ˇ®Developer AdvocateˇŻ, Twitter: ˇ®@blimpyachtˇŻ, Email: ˇ®bryan@mongdb.comˇŻ }
Editor's Notes
- #29: A fault-tolerant collection of elements operated on in parallel best suited for batch applications
- #45: MongoInputFormat allows us to read from a live MongoDB instance. We could also use BSONFileInputFormat to read BSON snapshots.
- #46: JavaPamongodbConfig
- #47: JavaPamongodbConfig
- #48: JavaPamongodbConfig
- #49: JavaPamongodbConfig
- #50: JavaPamongodbConfig