MySQL Cluster ą┬ÖC─▄ĮŌšh 7.5 and beyond
3 likes6,320 views

db tech showcase 2017 tokyożŪ╩╣ż├ż┐┘Y┴ŽżŪż╣ĪŻ













![żĮż╬╦¹ż╬ź¬źūźŲźŻź▐źżźČķv▀Bż╬
ą┬ÖC─▄
Ī±
EXPLAIN FOR CONNECTION
Ī±
ą┬żĘżżź│ź╣ź╚źŌźŪźļ
Ī± ź¬źūźŲźŻź▐źżźČźęź¾ź╚
Ī±
źŪźŻź╣ź»ź┘®`ź╣ż╬źŲź¾ź▌źķźĻźŲ®`źųźļż“ InnoDB ╗»
Ī±
UNION ALL ż¼źŲź¾ź▌źķźĻźŲ®`źųźļ▓╗ꬿ╦
Ī±
ź│ź╣ź╚ż╦ WHERE Šõż╦żĶżļĮgżĻ▐zż▀ż“┐╝æ]
Ī±
GROUP BY ż╬äėū„ż“ SQL ś╦£╩£╩Æćż╦
Ī±
FROM Šõż╬źĄźųź»ź©źĻżŪźŲź¾ź▌źķźĻźŲ®`źųźļż¼▓╗ꬿ╩ł÷║Ž
ū„│╔żĘż╩żżżĶż”ż╦
etc etc](https://image.slidesharecdn.com/mysql-cluster-75-and-beyond-170907022234/85/MySQL-Cluster-7-5-and-beyond-14-320.jpg)
































![źĘź╣źŲźÓ├¹ż╚żŽ
Ī± ź»źķź╣ź┐ż“ūRäeż╣żļż┐żßż╬ź┐ź░ż╬żĶż”ż╩żŌż╬
Ī± config.ini ─┌żŪųĖČ©
[System]
Name = system_name
Ī±
SHOW GLOBAL STATUS LIKE Ī«Ndb_system_nameĪ» żŪ
▓╬šš](https://image.slidesharecdn.com/mysql-cluster-75-and-beyond-170907022234/85/MySQL-Cluster-7-5-and-beyond-53-320.jpg)









![[db tech showcase Tokyo 2017] D21: ż─żżż╦ Red Hat Enterprise LinuxżŪ SQL Serverż¼╩╣...](https://cdn.slidesharecdn.com/ss_thumbnails/d21-170912022444-thumbnail.jpg?width=560&fit=bounds)

![[C21] MySQL ClusterÅžĄū╗Ņė├ąg by Mikiya Okuno](https://cdn.slidesharecdn.com/ss_thumbnails/c21mysql-cluster-techniques-rev3-131206023325-phpapp02-thumbnail.jpg?width=560&fit=bounds)

![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by źóź▐źŠź¾ źŪ®`ź┐ źĄ®`źėź╣ źĖźŃ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)







![[db tech showcase Tokyo 2017] E26: ĘÖżŽķ_ż½żņż┐! SQL Server on Linux żŪÆłż¼żļ┐╔─▄ąį by ╚š▒Šź▐...](https://cdn.slidesharecdn.com/ss_thumbnails/e26-170912024421-thumbnail.jpg?width=560&fit=bounds)
![[db tech showcase Tokyo 2014] C34:[śS╠ņ] įöšh śS╠ņż╬źŪ®`ź┐ź┘®`ź╣źó®`źŁźŲź»ź┴źŃ╩Ę -źĘź¾ź░źļź╬®`ź╔ż½żķüóŽļ╗»źšźķź├źĘ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c34hardware-141211191008-conversion-gate01-thumbnail.jpg?width=560&fit=bounds)












More Related Content
What's hot (20)
Viewers also liked (20)








![[ICLR2017šiż▀╗ß @ DeNA] ICLR2017ĮBĮķ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2017denaiclr2017-170616173153-thumbnail.jpg?width=560&fit=bounds)









Similar to MySQL Cluster ą┬ÖC─▄ĮŌšh 7.5 and beyond (20)




















More from Mikiya Okuno (20)




















MySQL Cluster ą┬ÖC─▄ĮŌšh 7.5 and beyond
- 1. MySQL ClusterMySQL Cluster ą┬ÖC─▄ĮŌšhą┬ÖC─▄ĮŌšh 7.5 and beyond7.5 and beyond ░┬ę░ Äųę▓ Twitter: @nippondanji mikiya (dot) okuno (at) gmail (dot) com @DBTS-Tokyo 2017
- 3. ūį╝║ĮBĮķ Ī± MySQL źĄź▌®`ź╚ź©ź¾źĖź╦źó ©C ╚šĪ®ż╬żĘż┤ż╚ Ī± ź╚źķźųźļźĘźÕ®`źŲźŻź¾ź░╚½░Ń Ī± Q&A ╗ž┤ Ī± źčźšź®®`ź▐ź¾ź╣ź┴źÕ®`ź╦ź¾ź░ ż╩ż╔ Ī± źķźżźšź’®`ź» ©C ūįė╔ż╩źĮźšź╚ź”ź¦źóż╬Ųš╝░ ©C ╚ż╬ČżŽźĻź½ź¾ź┘ź¾ź╚ż╦ü\żļż│ż╚ Ī± ūŅĮ³żŽł╠╣Pż╚ūėė²żŲż╬╚šĪ®??? Ī± źųźĒź░ ©C Øhż╬ź│ź¾źįźÕ®`ź┐Ą└ ©C http://nippondanji.blogspot.com/
- 5. MySQL Ī░NDBĪ▒ Cluster Ī± ź▐ź╦źÕźóźļ╔ŽżŪż╬▒Ēėøż¼ēõĖ³ ©C MySQL Cluster MySQLĪ· NDB Cluster ©C https://dev.mysql.com/doc/refman/en/mysql-cluster.html Ī± MySQL InnoDB Cluster ż╚ż╬├„┤_╗» Ī± čuŲĘ├¹ż╚żĘżŲż╬ēõĖ³żŽŻ©Į±ż╬ż╚ż│żĒŻ®ź╩źĘ ©C MySQL Cluster Carrier Grade Edition ©C https://www.mysql.com/products/cluster/ ©C żõżõż│żĘżõ? ▒Šź╗ź├źĘźńź¾żŪżŽ MySQL NDB Cluster ż╦Įyę╗
- 6. MySQL NDB Cluster 7.5 ą┬╗·─▄Ė┼ę¬
- 7. MySQL NDB Cluster 7.5 ą┬╗·─▄Ė┼ę¬ Ī± MySQL 5.7 ż╚ż╬Įy║Ž Ī± źżź¾źŪź├ź»ź╣ĮyėŗŪķł¾ż╬Ė─┴╝ Ī± ndbinfo ż╬Æł│õ Ī± źąź├ź»źóź├źūźņźūźĻź½ż½żķż╬▓╬šš Ī± ╚½źŪ®`ź┐ź╬®`ź╔żžż╬źņźūźĻź½ Ī± źŲ®`źųźļż╬╚▌┴┐ųŲŽ▐Ė─╔Ų Ī± ndb_restore ź│ź▐ź¾ź╔ż╬ SQL │÷┴” 2016 ─Ļ 10 į┬źĻźĻ®`ź╣
- 9. MySQL 5.7 ż╚ż╬Įy║Ž Ī± MySQL źĄ®`źą®`ż╬ūŅą┬░µ ©C 2015 ─Ļ 10 į┬źĻźĻ®`ź╣ ©C 175 ż“│¼ż©żļą┬ÖC─▄┤Ņ▌d Ī± SQL ź╬®`ź╔ŻĮ NDB ź╣ź╚źņ®`źĖź©ź¾źĖź¾ż─żŁ MySQL źĄ®` źą®` ©C ź╣ź╚źņ®`źĖź©ź¾źĖź¾ż“ēõĖ³ż╣żļż└ż▒żŪ═¼żĖ SQL żŪźóź»ź╗ź╣ ┐╔─▄ ©C MySQL NDB Cluster żŪżŌźßźĻź├ź╚ż╬ŽĒ╩▄ż¼┐╔─▄ Ī± MySQL NDB Cluster 7.5 MySQL 5.7Ī· Ī± MySQL NDB Cluster 7.3, 7.4 MySQL 5.6Ī· Ī± MySQL NDB Cluster 7.2 MySQL 5.5Ī·
- 10. MySQL 5.7 ż╬ÖC─▄ Ī± źņźūźĻź▒®`źĘźńź¾ķv▀B Ī± InnoDB ķv▀B Ī± ź¬źūźŲźŻź▐źżźČ®`ķv▀B Ī± ź╗źŁźÕźĻźŲźŻķv▀B Ī± źčźšź®®`ź▐ź¾ź╣ź╣źŁ®`ź▐ķv▀B Ī± GIS ķv▀B Ī± JSON ķv▀B Ī± etc etc...
- 11. įöĮŌ MySQL 5.7 ų╣ż▐żķż╠▀M╗»ż╦ü\żĻ▀Wżņż╩żżż┐żßż╬źŲź»ź╦ź½źļź¼źżź╔ Ī± MySQL 5.7 ż╬ą┬ÖC─▄ż“ŠW┴_Ą─ż╦ĮŌšh ©C 175 ż╬ą┬ÖC─▄ ©C WorkLog/Bug Id ż─żŁ ©C ź│ź¾ź╗źūź╚Īó╩╦ĮMż▀Īó╩╣żżĘĮ Ī± ą┬ÖC─▄ż╬└ĒĮŌż╦▒žę¬ż╩Ū░╠ßų¬ūR ©C ╣┼żżźą®`źĖźńź¾żŪżŌ▀mė├┐╔─▄ ©C źó®`źŁźŲź»ź┴źŃż“└ĒĮŌż╣żļż│ż╚żŪ ▒Š╬’ż╬└ĒĮŌż“
- 13. Records-per-key ūŅ▀m╗» Ī± ź¬źūźŲźŻź▐źżźČż¼ JOIN ż╬ż╚żŁż╦▓╬ššż╣żļŪķł¾ Ī± ═Ō▓┐▒Ēż╬ 1 ąąż╦īØżĘżŲĪó─┌▓┐▒Ēż½żķŲĮŠ∙║╬ąąż¼ź▐ź├ź┴ż╣żļ ż½ ©C ź╣ź╚źņ®`źĖź©ź¾źĖź¾ż¼éÄż“ĘĄż╣ ©C MySQL 5.7 ż╦ż¬żżżŲźŪ®`ź┐ą═ż¼ INT ż½żķ FLOAT ż╦ēõĖ³ Ī± żĶżĻš²┤_ż╩ JOIN ż╬ź│ź╣ź╚ęŖĘeż¼┐╔─▄ż╦ Ī± MySQL NDB Cluster 7.5 żŌ FLOAT ż╦īØÅĻ
- 14. żĮż╬╦¹ż╬ź¬źūźŲźŻź▐źżźČķv▀Bż╬ ą┬ÖC─▄ Ī± EXPLAIN FOR CONNECTION Ī± ą┬żĘżżź│ź╣ź╚źŌźŪźļ Ī± ź¬źūźŲźŻź▐źżźČźęź¾ź╚ Ī± źŪźŻź╣ź»ź┘®`ź╣ż╬źŲź¾ź▌źķźĻźŲ®`źųźļż“ InnoDB ╗» Ī± UNION ALL ż¼źŲź¾ź▌źķźĻźŲ®`źųźļ▓╗ꬿ╦ Ī± ź│ź╣ź╚ż╦ WHERE Šõż╦żĶżļĮgżĻ▐zż▀ż“┐╝æ] Ī± GROUP BY ż╬äėū„ż“ SQL ś╦£╩£╩Æćż╦ Ī± FROM Šõż╬źĄźųź»ź©źĻżŪźŲź¾ź▌źķźĻźŲ®`źųźļż¼▓╗ꬿ╩ł÷║Ž ū„│╔żĘż╩żżżĶż”ż╦ etc etc
- 15. źčźšź®®`ź▐ź¾ź╣ź╣źŁ®`ź▐ż╚ sys ź╣źŁ®`ź▐ Ī± źčźšź®®`ź▐ź¾ź╣?ź╣źŁ®`ź▐ ©C ĘNĪ®ż╬ĮyėŗŪķł¾ż“╚ĪĄ├ ©C ų„ż╦źčźšź®®`ź▐ź¾ź╣ĮŌ╬÷ż╦└¹ė├ ©C Ūķł¾ż╬ĘNŅÉż¼ČÓż╣ż«żŲ╩╣żżż│ż╩ż╣ż╬ż¼ļyżĘżżż╬ż¼ļyĄŃ ©C źą®`źĖźńź¾ż¼╔Žż¼żļż┤ż╚ż╦Ūķł¾ż╬ĘNŅÉż¼ēł╝ė Ī± sys ź╣źŁ®`ź▐ ©C źčźšź®®`ź▐ź¾ź╣?ź╣źŁ®`ź▐ż╚Ūķł¾ź╣źŁ®`ź▐ż“║ßČŽĄ─ż╦źóź» ź╗ź╣ż╣żļźėźÕ®`ż╬ź│źņź»źĘźńź¾ ©C źčźšź®®`ź▐ź¾ź╣?ź╣źŁ®`ź▐żĶżĻżŌų▒ĖąĄ─ż╦└¹ė├┐╔─▄ ©C MySQL 5.7 żŪūĘ╝ė Ī± į¬Ī®żŽČ└┴óżĘż┐źūźĒźĖź¦ź»ź╚ż└ż├ż┐ Ī± MySQL 5.6 ė├żŌżóżĻ
- 16. MySQL NDB Cluster ż╚żŽ ¤oķvéSż╬ MySQL 5.7 ż╬ēõĖ³ĄŃ Ī± InnoDB ╚½░Ń ©C SQL ź╬®`ź╔╔ŽżŪüŃė├ż╣żļł÷║ŽżŽ└¹ĄŃżóżĻ ©C źŪźŻź╣ź»╔Žż╬źŲź¾ź▌źķźĻźŲ®`źųźļż¼ InnoDB ż╦ż╩ż├ż┐ĄŃżŽ źßźĻź├ź╚żóżĻ Ī± źņźūźĻź▒®`źĘźńź¾ż╬źĄź▌®`ź╚żĄżņżŲżżż╩żżÖC─▄ ©C GTID ©C £╩═¼Ų┌źņźūźĻź▒®`źĘźńź¾ ©C ź▐źļź┴ź╣źņź├ź╔ź╣źņ®`źų ©C ź▐źļź┴źĮ®`ź╣źņźūźĻź▒®`źĘźńź¾ Ī± MySQL NDB Cluster ż╦żŽ¤ożżÖC─▄ ©C ┐šķgźżź¾źŪź├ź»ź╣ ©C źšźļźŲźŁź╣ź╚źżź¾źŪź├ź»ź╣
- 17. ndbinfo ż╬Æł│õ
- 18. ndbinfo ż╚żŽ Ī± MySQL NDB Cluster ė├ż╬Ūķł¾╚ĪĄ├ź─®`źļ Ī± ndbinfo ź╣źŁ®`ź▐ż╦Ė„ĘNźŲ®`źųźļż¼żóżļ Ī± źŪ®`ź┐ź╬®`ź╔ż½żķźßź┐źŪ®`ź┐żõĮyėŗŪķł¾ż“╚ĪĄ├
- 19. MySQL NDB Cluster 7.5 ż╦ż¬ż▒żļĖ─┴╝ĄŃ Ī± config_paramsĪŁ źčźķźß®`ź┐®`ż╬šh├„żõźŪźšź®źļź╚éÄĪó źŪ®`ź┐ą═ż╩ż╔ż¼ūĘ╝ė Ī± config_valuesĪŁ ¼Fį┌ż╬źčźķźß®`ź┐®`ż╬įOČ©éÄż“Ė±╝{ĪŻ Ī± dict_obj_info... Ė„ĘNźŪ®`ź┐ź┘®`ź╣ź¬źųźĖź¦ź»ź╚ż╬Ūķł¾ĪŻ Ī± table_distribution_status... źŲ®`źųźļż╬ LCP ū┤ørĄ╚ Ī± table_fragments... źŲ®`źųźļż┤ż╚ż╬źšźķź░źßź¾ź╚ż╬ū┤æB Ī± table_info... źŲ®`źųźļż╬Ė„ĘNŪķł¾ Ī± table_replicas... źņźūźĻź½ż╬ū┤æB
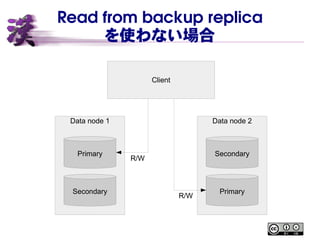
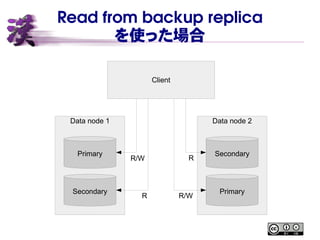
- 21. Read from backup replica Ī± ż│żņż▐żŪżŽźūźķźżź▐źĻ®`źņźūźĻź½ż╬ż▀ R/W ┐╔─▄ Ī± źūźķźżź▐źĻ®`źņźūźĻź½ż“Ė„źŪ®`ź┐ź╬®`ź╔ż╦Ęų╔󿥿╗żļż│ż╚żŪĪó žō║╔żŌĘų╔ó Ī± MySQL NDB Cluster 7.5 żĶżĻĪóźąź├ź»źóź├źūźņźūźĻź½ż½żķż╬ ▓╬ššż¼┐╔─▄ż╦ ©C ż┐ż└żĘźŪźšź®źļź╚żŪżŽż│żņż▐żŪ═©żĻźūźķźżź▐źĻ®`ż╬ż▀ż╦źóź» ź╗ź╣┐╔─▄ ©C źŲ®`źųźļū„│╔Ģrż╦ųĖČ©żĘż┐ł÷║Žż╬ż▀
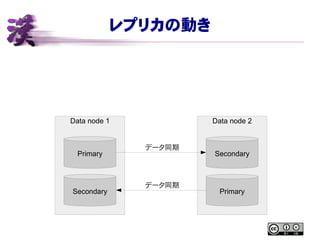
- 22. źņźūźĻź½ż╬äėżŁ Data node 1 Data node 2 Primary Secondary Primary Secondary źŪ®`ź┐═¼Ų┌ źŪ®`ź┐═¼Ų┌
- 23. Read from backup replica ż“╩╣ż’ż╩żżł÷║Ž Data node 1 Data node 2 Primary Secondary Primary Secondary Client R/W R/W
- 24. Read from backup replica ż“╩╣ż├ż┐ł÷║Ž Data node 1 Data node 2 Primary Secondary Primary Secondary Client R/W R/W R R
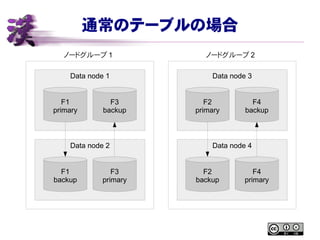
- 26. ═©│Żż╬źŲ®`źųźļż╬ł÷║Ž ź╬®`ź╔ź░źļ®`źū 1 ź╬®`ź╔ź░źļ®`źū 2 Data node 1 Data node 2 Data node 3 Data node 4 F1 primary F3 backup F1 backup F3 primary F2 backup F4 primary F2 primary F4 backup
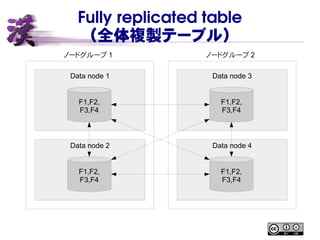
- 27. Fully replicated table Ż©╚½╠Õč}čuźŲ®`źųźļŻ® ź╬®`ź╔ź░źļ®`źū 1 ź╬®`ź╔ź░źļ®`źū 2 Data node 1 Data node 2 Data node 3 Data node 4 F1,F2, F3,F4 F1,F2, F3,F4 F1,F2, F3,F4 F1,F2, F3,F4
- 29. źŲ®`źųźļźĄźżź║ż╬ųŲŽ▐ Ī± MySQL NDB Cluster 7.4 ż▐żŪ ©C FIXED źšź®®`ź▐ź├ź╚▓┐ĘųżŽźšźķź░źßź¾ź╚żóż┐żĻ 16GB ż▐żŪ ©C źšźķź░źßź¾ź╚╩²żŽźŪ®`ź┐ź╬®`ź╔╩²ż╚═¼żĖ Ī± MySQL NDB Cluster 7.5 ©C FIXED źšź®®`ź▐ź├ź╚▓┐Ęųż╬źŪ®`ź┐źĄźżź║żŽ 128TB ż▐żŪ ©C ż┐ż└żĘźŪ®`ź┐ź╬®`ź╔ż┤ż╚ż╬ DataMemory ż╬╔ŽŽ▐ż¼ 1TB Ī± źŪ®`ź┐ź╬®`ź╔żŽ 48 ź╬®`ź╔ż╩ż╬żŪĪóīg┘|Ą─ż╩╔ŽŽ▐żŽ 48TB Ī± źņźūźĻź½╩²Ż▓ż╩żķ 24TB
- 31. ndb_restore ź│ź▐ź¾ź╔ż╬ SQL │÷┴” Ī± ndb_restore żŽĪóź═źżźŲźŻźųźąź├ź»źóź├źūż“źĻź╣ź╚źóż╣żļź─®` źļ ©C źŪ®`ź┐ź╬®`ź╔żžź»źķźżźóź¾ź╚ż╚żĘżŲĮėŠAżĘżŲźĻź╣ź╚źó ©C źąź├ź»źóź├źūżŽźßź┐źŪ®`ź┐ĪóźŪ®`ź┐ĪóźĒź░ż½żķśŗ│╔żĄżņżļ ©C źŪ®`ź┐▓┐Ęųż“ CSV żŪĪóźĒź░ż“źŲźŁź╣ź╚żŪ│÷┴”ż╣żļÖC─▄ż¼ żóż├ż┐ Ī± MySQL NDB Cluster 7.5 ż╦ż¬żżżŲĪóźĒź░ż╬│÷┴”ż¼ SQL īØ ÅĻ ©C InnoDB ż╩ż╔Īó╦¹ż╬ź╣ź╚źņ®`źĖź©ź¾źĖź¾żžż╬źŪ®`ź┐ęŲąąż╦ ©C InnoDB żžż╬źņźūźĻź▒®`źĘźńź¾ż╬ź╗ź├ź╚źóź├źū
- 33. MySQL Cluster 7.6 DRM ĄŪł÷ Ī± MySQL Cluster 7.6 Development Milestone Release ż╚żŽŻ┐ ©C Release Candidate ż╦ż╩żļŪ░ż╬źą®`źĖźńź¾ ©C ÖC─▄ż╬ūĘ╝ė?Ž„│²ż¼ėĶĖµż╩ż»ēõĖ³żĄżņżļł÷║ŽėążĻ Ī± £╩éõż¼š¹ż├ż┐ÖC─▄ż½żķĒśĘ¼ż╦Įy║ŽżĄżņżļ ©C źŁźŃź¾ź╗źļżĄżņżļł÷║ŽżŌżóżĻ Ī± MySQL Cluster 7.6.3 dmr ©C 2017 ─Ļ 7 į┬ 5 ╚šźĻźĻ®`ź╣ Ī± š²╩Į░µżŪżŽżóżĻż▐ż╗ż¾ŻĪ ©C https://lists.mysql.com/announce/1185
- 34. MySQL NDB Cluster 7.6 ż╬ Ż©ėĶČ©żĄżņż┐Ż®ą┬╗·─▄Ė┼ę¬ Ī± źŪźŻź╣ź»ą═źŲ®`źųźļż╬ą┬źšź®®`ź▐ź├ź╚ Ī± źßźŌźĻĖŅżĻĄ▒żŲįOČ©ż╬Ė─╔Ų Ī± ndbinfo ż╬Æł│õ Ī± CSV źŪ®`ź┐ż╬źżź¾ź▌®`ź╚ź─®`źļ Ī± ą┬żĘżżźŌź╦ź┐źĻź¾ź░ź─®`źļ Ī± LCP ż╬ź╣źļ®`źūź├ź╚░▓Č©╗» Ī± SPJ ż╬Ė─┴╝ Ī± źĘź╣źŲźÓ├¹ż╬ųĖČ©
- 36. źŪźŻź╣ź»ą═źŲ®`źųźļż╬ ą┬źšź®®`ź▐ź├ź╚ Ī± ź┌®`źĖź┴ź¦ź├ź»źĄźÓż╬ūĘ╝ė Ī± CREATE TABLE SCHEMA VERSION ID ż╬ī¦╚ļ ©C DROP/CREATE ż╦żĶżĻĪó Table ID ż¼į┘└¹ė├żĄżņżŲżĘż▐ż” ©C ═¼żĖ Table ID ż“│ųż├ż┐ź©ź»ź╣źŲź¾ź╚ż¼ CREATE ßßż╬źŲ®` źųźļż╬żŌż╬ż└ż╚š`ż├żŲ┼ąČ©żĄżņżŲżĘż▐ż” Ī± źżź╦źĘźŃźļźĒ®`źĻź¾ź░źĻź╣ź┐®`ź╚ż╦żĶżĻą┬żĘżżźšź®®`ź▐ź├ź╚żžēõ Ė³ ©C ╣┼żżźšź®®`ź▐ź├ź╚ż“│ųż─źą®`źĖźńź¾ż╦żŽź└ź”ź¾ź░źņ®`ź╔żŪżŁ ż╩żż
- 38. IndexMemory ż╬ijų╣ Ī± DataMemory ż½żķäėĄ─ż╦ĖŅżĻĄ▒żŲ ©C ▒žę¬ż╩Ęųż└ż▒ż¼ĖŅżĻĄ▒żŲżķżņżļżĶż”ż╦ ©C ¤o±jż¼ż╩żż ©C įOČ©ż¼ż┴żńż├ż╚ż└ż▒źĘź¾źūźļż╦ Ī± DataMemory ż└ż▒źĄźżźĖź¾ź░ż╣żņżą OK
- 39. DataMemory ż½żķ SharedGlobalMemory żž Ī± źßźŌźĻĖŅżĻĄ▒żŲŽ╚ż╬ēõĖ³ Ī± DataMemory ©C źŪ®`ź┐ż╬Ė±╝{ż╦ķvż╣żļ▓┐Ęųż╦╠ž╗» Ī± SharedGlobalMemory ©C ź╚źķź¾źČź»źĘźńź¾äI└Ēż╦ķvż╣żļźßźŌźĻżŽż│ż┴żķż½żķĖŅżĻĄ▒żŲ ©C ęįŪ░żĶżĻČÓż»▒žę¬ż╦ż╩żļż½żŌ Ī± ēõĖ³żĄżņż┐żŌż╬ż╬└² ©C źņźūźĻź▒®`źĘźńź¾ė├źżź┘ź¾ź╚źąź├źšźĪ ©C źšźĪźżźļż╬│§Ų┌╗»äI└Ēė├źąź├źšźĪ ©C ź¬źšźķźżź¾ż╬źżź¾źŪź├ź»ź╣ū„│╔ė├źąź├źšźĪ etc storage/ndb/src/kernel/blocks/record_types.hpp
- 40. ndbinfo ż╬Æł│õ
- 41. ndbinfo ż╦Ż▓ż─ż╬źŲ®`źųźļż¼ūĘ╝ė Ī± config_nodes ©C config.ini ─┌żŪČ©┴xżĄżņż┐ź╬®`ź╔ż╬ę╗ėE Ī± processes ©C ¼Fį┌ĮėŠAųąż╬źūźĒź╗ź╣Ż©ź╬®`ź╔Ż®ę╗ėE ndb_mgm -e SHOW ż╬┤·ż’żĻż╦╩╣ż”ż╚▒Ń└¹
- 43. ndb_import Ī± LOAD DATA INFILE ż╬żĶż”ż╦ CSV źŪ®`ź┐ż“źŲ®`źųźļż╦╚Ī żĻ▐zżÓź─®`źļ Ī± źŪ®`ź┐ź╬®`ź╔żžų▒ĮėĮėŠA ©C Ė▀╦┘ŻĪ ©C API ź╬®`ź╔ż╬żęż╚ż─ż╚żĘżŲäėū„ ©C źŪ®`ź┐ź╬®`ź╔żžż╬ĮėŠA╩²ĪóĮėŠAżóż┐żĻż╬ź╣źņź├ź╔╩²ż“ųĖČ© ┐╔─▄ ndb_import -c connectstring db_name table_name.csv
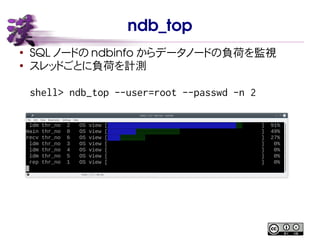
- 45. ndb_top Ī± SQL ź╬®`ź╔ż╬ ndbinfo ż½żķźŪ®`ź┐ź╬®`ź╔ż╬žō║╔ż“▒OęĢ Ī± ź╣źņź├ź╔ż┤ż╚ż╦žō║╔ż“ėŗ£y shell> ndb_top --user=root --passwd -n 2
- 47. LCP ż╚żŽ Ī± Local checkpoint ż╬┬į Ī± źŪ®`ź┐ź╬®`ź╔żŽČ©Ų┌Ą─ż╦ DataMemory ╔Žż╬źŪ®`ź┐ż“ĪóźšźĪ źżźļżžĢ°żŁ│÷żĘżŲżżżļ ©C ╚½╠Õż“Ēś┤╬ź╣źŁźŃź¾ ©C 2 ╩└┤·Ęųż╬źŪ®`ź┐ż¼źšźĪźżźļż╦▒Ż┤µ ©C ż½ż╩żĻż╬ I/O ż¼░k╔·ż╣żļ Ī± GCP Ż© Global checkpoint Ż®ż╚ź╗ź├ź╚żŪźŪ®`ź┐ż“Å═į¬ ©C GCP = Redo logging
- 48. LCP ż╬ź╣źļ®`źūź├ź╚░▓Č©╗» Ī± LCP żŽ I/O ż¼▀Wżżż╚ūįäėĄ─ż╦ź╣źļ®`źūź├ź╚ż“š{š¹ż╣żļÖC─▄ ż¼żóżļ Ī± 7.5 ż▐żŪż╬źą®`źĖźńź¾żŪżŽĪó LDM ź╣źņź├ź╔ż┤ż╚ż╦ I/O ▀Wčėż“ źŌź╦ź┐źĻź¾ź░żĘĪóź╣źļ®`źūź├ź╚ż“š{š¹żĘżŲżżż┐ ©C ╦¹ż╬ LDM ź╣źņź├ź╔żŽź╣źļ®`źūź├ź╚ż“š{š¹żĘż╩żżż½żŌų¬żņ ż╩żż ©C LDM = Local Data Manager Ī± 7.6 żŪżŽ I/O ▀Wčėż╬źŌź╦ź┐źĻź¾ź░ż“źŪ®`ź┐ź╬®`ź╔╚½╠ÕżŪĮyę╗ żĘżŲąąż”żĶż”ż╦ż╩ż├ż┐ ©C żĶżĻš²┤_ż╦źĄ®`źą®`╚½╠Õż╬ I/O ż╬ū┤ørż“Ę┤ė│ż╣żļżĶż”ż╦ ż╩ż├ż┐ĪŻ
- 49. SPJ ż╬Ė─┴╝
- 50. SPJ ż╚żŽ Ī± Select-Project-Join ż╬┬į ©C äe├¹ Pushdown Join Ī± źŪ®`ź┐ź╬®`ź╔╔ŽżŪ JOIN ż“īgąążĘĪóĮY╣¹ż“ SQL ź╬®`ź╔żžĘĄż╣ ©C ĘŪ│Żż╦Ė▀╦┘ŻĪ ©C źŪ®`ź┐ź╬®`ź╔? SQL ź╬®`ź╔ķgż╬źķź”ź¾ź╔ź╚źĻź├źūż“╩Ī┬į ©C č}╩²ż╬źŪ®`ź┐ź╬®`ź╔╔ŽżŪ JOIN ż“üK┴ąīgąą
- 51. Pushdown Join ż¼ä┐┬╩╗» Ī± DBSPJ ź½®`ź═źļźųźĒź├ź»ż╬źĘź░ź╩źļų▄żĻż╬Ė─┴╝ ©C ėÓĘųż╩źĘź░ź╩źļż¼╦═ą┼żĄżņż╩żżżĶż”ż╦ ©C źĘź░ź╩źļźšź®®`ź▐ź├ź╚ż“ź│ź¾źčź»ź╚ż╦ Ī± źĒ®`ź╔źąźķź¾ź╣ż╬Ė─╔Ų ©C LDM ź╣źņź├ź╔╩²ż¼Īó TC ź╣źņź├ź╔╩²żŪĖŅżĻŪążņż╩żżł÷ ║ŽĪó DBSPJ ż╬žō║╔ż╦Ų½żĻż¼╔·żĖżŲżżż┐ ©C żĮż╬ł÷║ŽĪó DBSPJ źųźĒź├ź»ż“źķź”ź¾ź╔źĒźėź¾żŪ╩╣ż”żĶż”ż╦ż╣ żļż│ż╚żŪĪóź╣źņź├ź╔ż┤ż╚ż╬žō║╔ż“ŲĮ╠╣╗»
- 53. źĘź╣źŲźÓ├¹ż╚żŽ Ī± ź»źķź╣ź┐ż“ūRäeż╣żļż┐żßż╬ź┐ź░ż╬żĶż”ż╩żŌż╬ Ī± config.ini ─┌żŪųĖČ© [System] Name = system_name Ī± SHOW GLOBAL STATUS LIKE Ī«Ndb_system_nameĪ» żŪ ▓╬šš
- 54. ż▐ż╚żß
- 55. MySQL Ī░NDBĪ▒ Cluster żŽ ū┼Ī®ż╚▀M╗»ųąŻĪŻĪ Ī± MySQL NDB Cluster 7.5 Īó 7.6DMR żŪū┼īgż╩▀M╗» ©C ┼╔╩ųż╩ēõĖ³żŽ¤ożżż¼Īóę█┴óż─ą┬ÖC─▄ż¼ČÓ╩² Ī± ÖC─▄├µ ©C MySQL 5.7 ż╚ż╬Įy║Žż╦żĶżĻ│õīg ©C ndb_top Īó ndb_import ż╩ż╔ż╬ą┬żĘżżź─®`źļ Ī± ąį─▄├µ ©C ź¬źūźŲźŻź▐źżźČż╬Ė─╔Ųż╦żĶżĻĪó SQL īgąąż¼Ė▀╦┘╗» ©C LCP ź╣źļ®`źūź├ź╚ż╬░▓Č© ©C źąź├ź»źóź├źūźņźūźĻź½żķż½żķż╬▓╬šš ©C DBSPJ ż╬Ė─┴╝ Ī± ▀\ė├├µ ©C ndbinfo ż╦żĶżļ▒OęĢż╬│õīg ©C źĘź╣źŲźÓ├¹ż╦żĶżļūRäe
- 56. ą¹ü╗Ż║Ģ°╝«ż¼│÷ż▐ż╣ŻĪ Pro MySQL NDB Cluster Ī± Pro MySQL NDB Cluster / Apress Media ©C MySQL NDB Cluster 7.5 ż╬ĮŌšhĢ° ©C ═¼┴┼ż╬ Jesper ż╚ż╬╣▓ų° ©C ėóšZżŪż╣ĪŻ ©C ż¬éÄČ╬żŽ $49.99
- 58. ą¹ü╗Ż║źĄź▌®`ź╚ź©ź¾źĖź╦źó─╝╝»ųąŻĪŻĪ Ī± MySQL źĄź▌®`ź╚ź┴®`źÓżŪę╗Šwż╦āPżżżŲż▀ż▐ż╗ż¾ż½Ż┐ŻĪ Ī± ╝╝ąg┴”ż¼╬’ż“čįż”ź▌źĖźĘźńź¾żŪż╣ŻĪ ©C ╝╝ąg┴”ż╦ūįą┼ż╬żóżļĘĮĪó╝╝ągż“─źżŁż┐żżĘĮÜZėŁ ©C L1 ż½żķ L3 ż▐żŪż╬å¢żż║Žż’ż╗ż“ż╣ż┘żŲ╩▄ż▒│ųż┴ Ī± ź»ź©źĻż╬ź┴źÕ®`ź╦ź¾ź░ż╩ż╔żŌąążżż▐ż╣ Ī± ź¬®`źūź¾źĮ®`ź╣ż╩ż╬żŪźĮ®`ź╣ź│®`ź╔ęŖĘ┼Ņ}ŻĪŻĪ ©C ėóšZżĶżĻ╝╝ąg┴”ųžęĢ Ī± ŲšČ╬ż╬śIäšżŽ╚š▒ŠšZź¬ź¾źĻ®`żŪż╣ĪŻ Ī± ╚š▒Šż╬ŅÖ┐═ż¼ź┐®`ź▓ź├ź╚żŪż╣ĪŻ Ī± ╔Ž╦ŠżŽ║Ż═Ō ©C żõżĻż╚żĻżŽėóšZż╬ż▀ ©C TOEIC 700 │╠Č╚ż¼─┐░▓ Ī± į┌š¼Ū┌äš┐╔─▄