


![言语判定とは
? 入力テキストの記述言語を推定
– Time fries like arrow → 英語
– Buona sera! → イタリア語
? 多くの言語処理での前提タスク
– 言語モデルは言語ごとに構築
– 検索、分類、抽出、翻訳、……
? 十分長い&低ノイズなテキストに対して99%以上
の精度で判定可能 [Cavnar+ 94]
– 多くの手法が 3-gram モデルを採用
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-4-320.jpg)


![twitter言语判定は難しい? (1)
? テキスト長が短い
– twitter は最大140字
– 実際は十数~数十字のものも多い
– 3-gram ではわずかな素性しか取り出せない
? LIGA [Tromp+ 11]
– 3-gram をベースにグラフ化した素性
? 長距離の素性を追加して増やす
– twitter 言语判定で95~98%(6言語)
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-8-320.jpg)


![全ての部分文字列を考虑した文书分类
[岡野原+ 08]
? 全部分文字列を素性とする多クラスロジ
スティック回帰を線形時間で構築
– 「極大部分文字列」を用いて同値なモデル
? 拡張 Suffix Array を使って線形時間で抽出
? 素性を TRIE に格納、予測(判定)も高速に
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-13-320.jpg)




![文字の連続表現を正規化
? coooooooollllll, OMGGG! のような表現
? 対応案1: [Brody+ 2011] で正規化辞書を作る
– cooooooooollllllll => cool
– 辞書にない単語に対応できない
? 対応案2: 3文字以上の連続を2文字に縮める
– 正書法の範囲で、同じラテン文字が3個以上続く言語
はない
知ってる範囲で
? 現在は案2のみ対応
– 案1 も組み合わせるのがおそらくベスト
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-19-320.jpg)






![データ形式
? 訓練データ?テストデータ共通
– [正解ラベル]?t[メタデータ]?t[テキスト]
en u should just enjoy ur vacation sadly
en :D i'm online but you arent RT that much
en im gettin attacked for a tweet LOOOOOOOOOOOOOOOOL
ca [ステータスID] [日時] [ユーザID] [UIの言語] @xxx xDDD no
m'extranya... Tal volta haguera segut millor per a la humanitat
que no l'haguera vist... you know.. xDD
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-27-320.jpg)

![Language Detection with Infinity-Gram
(ldig)
? ラテン文字ツイートの言语判定器
– https://github.com/shuyo/ldig
? MIT license
? 学習済みモデルも同 URL にて配布
– ∞-gram 多クラスLR(極大部分文字列) [岡野原+ 08]
– L1 SGD (Cumulative Penalty) [Tsuruoka+ 09]
– Double Array
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-29-320.jpg)
![LIGA dataset で评価
? LIGA[Tromp+ 11] が公開している
6言語 9066件のデータセットで评価
– http://www.win.tue.nl/~mpechen/projects/smm/
言語 size detect correct precision recall
de ドイツ語 1479 1476 1469 99.5 99.3
en 英語 1505 1502 1490 99.2 99.0
es スペイン語 1562 1548 1541 99.6 98.7
fr フランス語 1551 1549 1540 99.4 99.3
it イタリア語 1539 1531 1528 99.8 99.3
nl オランダ語 1430 1429 1424 99.7 99.6
計 9066 8992 99.2
19言語モデルで评価
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-31-320.jpg)

![References
? [岡野原+ 08] 全ての部分文字列を考虑した文书分类
? ニューエクスプレスシリーズ(白水社)
– スウェーデン語、ノルウェー語、デンマーク語、ポーランド語、ハン
ガリー語、ルーマニア語、チェコ語、リトアニア語、スペイン語、カ
タルーニャ語、ベトナム語、トルコ語、ドイツ語、オランダ語、スワ
ヒリ語
? [Brody+ 11] Cooooooooooooooollllllllllllll!!!!!!!!!!!!!! Using
Word Lengthening to Detect Sentiment in Microblogs
? [Cavnar+ 94] N-Gram-Based Text Categorization
? [Tsuruoka+ 09] Stochastic Gradient Descent Training for L1-
regularized Log-linear Models with Cumulative Penalty
極大部分文字列を使った twitter 言语判定 (NLP2012)](https://image.slidesharecdn.com/nlp2012twitterlanguagedetectionslide-120319064147-phpapp02/85/twitter-33-320.jpg)
極大部分文字列を使った twitter 言语判定
- 1. 極大部分文字列を使った twitter 言语判定 2012/03/15 言語処理学会第18回年次大会 中谷 秀洋 @ サイボウズ?ラボ株式会社
- 2. アジェンダ ? 言语判定について ? 提案手法 (極大部分文字列) ? コーパス作成 ? 実装と评価 ? まとめ 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 3. 言语判定 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 4. 言语判定とは ? 入力テキストの記述言語を推定 – Time fries like arrow → 英語 – Buona sera! → イタリア語 ? 多くの言語処理での前提タスク – 言語モデルは言語ごとに構築 – 検索、分類、抽出、翻訳、…… ? 十分長い&低ノイズなテキストに対して99%以上 の精度で判定可能 [Cavnar+ 94] – 多くの手法が 3-gram モデルを採用 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 5. language-detection(langdetect) (中谷 2010) ? 言语判定 Java ライブラリ – http://code.google.com/p/language-detection/ – Apache License 2.0 ? 53言語について 99% 以上の精度で判定 – アジア圏の言語にも広く対応 ? Apache Solr などに採用 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 6. 極大部分文字列を使った twitter 言语判定 (NLP2012)
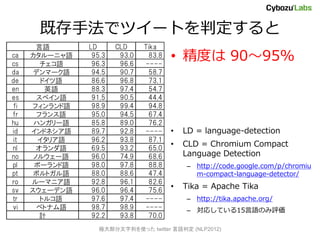
- 7. 既存手法でツイートを判定すると 言語 LD CLD Tika ca cs カタルーニャ語 チェコ語 95.3 96.3 93.0 96.6 83.8 ---- ? 精度は 90~95% da デンマーク語 94.5 90.7 58.7 de ドイツ語 86.6 96.8 73.1 en 英語 88.3 97.4 54.7 es スペイン語 91.5 90.5 44.4 fi フィンランド語 98.9 99.4 94.8 fr フランス語 95.0 94.5 67.4 hu ハンガリー語 85.8 89.0 76.2 id インドネシア語 89.7 92.8 ---- ? LD = language-detection it イタリア語 96.2 93.8 87.1 nl オランダ語 69.5 93.2 65.0 ? CLD = Chromium Compact no ノルウェー語 96.0 74.9 68.6 Language Detection pl ポーランド語 98.0 97.8 88.8 – http://code.google.com/p/chromiu pt ポルトガル語 88.0 88.6 47.4 m-compact-language-detector/ ro ルーマニア語 92.8 96.1 82.6 sv スウェーデン語 96.0 96.4 75.6 ? Tika = Apache Tika tr トルコ語 97.6 97.4 ---- – http://tika.apache.org/ vi ベトナム語 98.7 98.9 ---- – 対応している15言語のみ评価 計 92.2 93.8 70.0 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 8. twitter言语判定は難しい? (1) ? テキスト長が短い – twitter は最大140字 – 実際は十数~数十字のものも多い – 3-gram ではわずかな素性しか取り出せない ? LIGA [Tromp+ 11] – 3-gram をベースにグラフ化した素性 ? 長距離の素性を追加して増やす – twitter 言语判定で95~98%(6言語) 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 9. twitter言语判定は難しい? (2) ? ノイズが多い – 正書法から外れた表現が頻出 – 省略語、短縮語、繰り返し (Cooooolll など) ? 通常の言語モデルでは尤度が小さくなる OMG Oh My God u you LOL Laughing Out Loud ur your イタリア語は k を使わない LMAO Laughing My Ass Out 4 for F4F Follow for Follow i0u I love you MDR Mort de Rire (仏) k che (伊) TKT Ne t‘Inquiète Pas(仏) anke anche(伊) 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 10. 考察と方針 ? 高精度の twitter 言语判定には – 短いテキストから十分な素性を抽出可能なモデル – twitter向け言語モデル あるいは、その構築に必要なコーパス ? 本研究は19言語を精度99%以上で言语判定 – 極大部分文字列モデル (∞-gram 多クラスロジスティック回帰) – 70万件の言語ラベル付き twitter コーパス 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 11. 提案手法(极大部分文字列) 極大部分文字列を使った twitter 言语判定 (NLP2012)
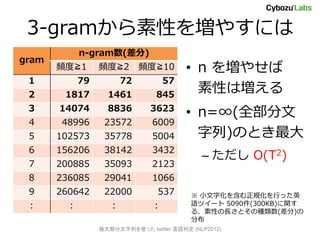
- 12. 3-驳谤补尘から素性を増やすには n-gram数(差分) gram 頻度≧1 頻度≧2 頻度≧10 ? n を増やせば 1 79 72 57 2 1817 1461 845 素性は増える 3 14074 8836 3623 ? n=∞(全部分文 4 48996 23572 6009 5 102573 35778 5004 字列)のとき最大 6 156206 38142 3432 – ただし O(T2) 7 200885 35093 2123 8 236085 29041 1066 9 260642 22000 537 ※ 小文字化を含む正規化を行った英 : : : : 語ツイート 5090件(300KB)に関す る、素性の長さとその種類数(差分)の 分布 極大部分文字列を使った twitter 言语判定 (NLP2012)
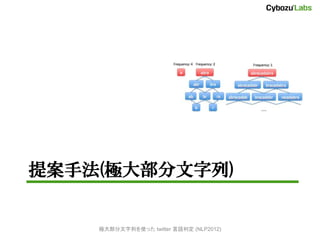
- 13. 全ての部分文字列を考虑した文书分类 [岡野原+ 08] ? 全部分文字列を素性とする多クラスロジ スティック回帰を線形時間で構築 – 「極大部分文字列」を用いて同値なモデル ? 拡張 Suffix Array を使って線形時間で抽出 ? 素性を TRIE に格納、予測(判定)も高速に 極大部分文字列を使った twitter 言语判定 (NLP2012)
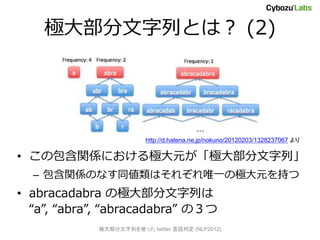
- 14. 極大部分文字列とは? (1) ? 空でない部分文字列の間に、ある種の 「包含関係」(半順序)を入れる abracadabra – “ra” ? “bra“ ? 全ての ”ra” は “bra” の 部分文字列として現れる – “a” ? “ra“ ? “a” は “ra“ だけではなく “ca” にも現れる ※厳密には部分文字列内での出現位置も考慮して定義する 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 15. 極大部分文字列とは? (2) http://d.hatena.ne.jp/nokuno/20120203/1328237067 より ? この包含関係における極大元が「極大部分文字列」 – 包含関係のなす同値類はそれぞれ唯一の極大元を持つ ? abracadabra の極大部分文字列は “a”, “abra”, “abracadabra” の3つ 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 16. 極大部分文字列と∞-gram モデル ? 包含関係を持つ部分文字列同士の出現頻度 (あるいは有無)は常に一致する ? 特徴量を線形結合するモデルなら、包含関係 のある特徴量同士をくくり出せる ? 「極大部分文字列ロジスティック回帰」は 「∞-gramロジスティック回帰」と同値 ※訓練集合外の文字列では一般にモデルの同値性は崩れるが, 訓練集合を十分大きくとることで近似できるとする 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 17. 極大部分文字列による言语判定 ? 言语判定=ラベル付き分類問題 – 極大部分文字列モデルで予測 – ∞-gram を線形時間で構築 ? これだけでは精度は 98% にとどまる ? ? ノイズ対策として、正規化を行う 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 18. Twitter 向け正規化 ? 単純に除去 – URL – mention, ハッシュタグ – RT – 顔文字 ? ラテン文字入りの XD, :p などは特に – via, live on ? URL除去後の末尾にあるもの 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 19. 文字の連続表現を正規化 ? coooooooollllll, OMGGG! のような表現 ? 対応案1: [Brody+ 2011] で正規化辞書を作る – cooooooooollllllll => cool – 辞書にない単語に対応できない ? 対応案2: 3文字以上の連続を2文字に縮める – 正書法の範囲で、同じラテン文字が3個以上続く言語 はない 知ってる範囲で ? 現在は案2のみ対応 – 案1 も組み合わせるのがおそらくベスト 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 20. 「笑い」の正規化 ? 笑い方も言語によっていろいろ – HOW MUCH??? HHAHAHAHAHAAAH – Hihihihi. :) Habe ich regul?r 2x die Woche! – Tafil con eso...!!! Jajajajajajaja – Malo?? Jejejeje XP – kekeke ch? ?ó làm áo ???c ko em? ? ? 2回に縮める(hahaha...ha → haha) – 言語の特徴も出ているので、削らず残す 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 21. トルコ语を考虑した小文字化 大文字 小文字 トルコ語以外 I (U+0049) i (U+0069) I (U+0049) ? (U+0131) トルコ語 ? (U+0130) i (U+0069) ? 小文字化してコーパスを節約 – しない場合、現状のコーパス量では平均精度が1%低下 ? トルコ語は I (U+0049) の小文字が異なる – ? I を除外して小文字化 – I も小文字化すると、いくつかの言語の精度が0.5%低下 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 22. ルーマニア語文字の正規化 ? ルーマニア語の ?, ? は2種類の文字を混用 – U+0218-B : カンマ下付き s/t (正書法) – U+015E-F, 62-3 : セディーユ付き s/t (代用字) ? 代用字の方が広く多く使われている – U+0218-B が一般に利用可能に なったのが2007年頃(Win Vista) ? ? U+0219 U+015F ? ? ? ? 同一視する正規化を行う 極大部分文字列を使った twitter 言语判定 (NLP2012) U+021B U+0163
- 23. ベトナム語文字の正規化 ? 一般の文書でも「声調記号」を付ける – 声調記号は全ての母音に付く – 12 母音 × 6 声調 = 72 文字 ? 声調記号付き文字の表現 1. U+1ea0~U+1eff を使う 2. ダイアクリティカルマークとの合字 ? ? = U+1eb5 = U+0103 U+0303 – ニュースやツイートでは半々 ? ? 2. を 1. に正規化 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 24. コーパス作成 極大部分文字列を使った twitter 言语判定 (NLP2012)
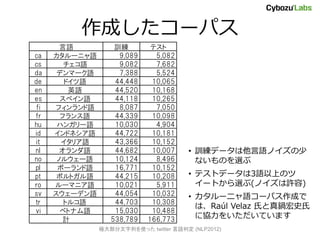
- 25. コーパスの作り方 ? ラテン文字言語を対象 – 混合テキストは文字種で分割すればよい – 最も難易度が高い文字種 (話者 500万人以上の言語が 25 以上) ? twitter Streaming API の sample メソッドでツイート収集 – 全ツイートの 1%程度 (約200万件/日)をサンプリング – ラテン文字の言語は6割程度 ? 収集したツイートに言語ラベルを振る – ツイートをユーザのタイムゾーンごとに分類 ? フランス語ツイートは 1% 程度。Paris タイムゾーンに限れば 50% ? ただし全体の2割はタイムゾーン未設定 – langdetect で仮ラベルを振り、手作業で修正 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 26. 作成したコーパス 言語 訓練 テスト ca カタルーニャ語 9,089 5,082 cs チェコ語 9,082 7,682 da デンマーク語 7,388 5,524 de ドイツ語 44,448 10,065 en 英語 44,520 10,168 es スペイン語 44,118 10,265 fi フィンランド語 8,087 7,050 fr フランス語 44,339 10,098 hu ハンガリー語 10,030 4,904 id インドネシア語 44,722 10,181 it イタリア語 43,366 10,152 nl オランダ語 44,682 10,007 ? 訓練データは他言語ノイズの少 no ノルウェー語 10,124 8,496 ないものを選ぶ pl ポーランド語 16,771 10,152 pt ポルトガル語 44,215 10,208 ? テストデータは3語以上のツ ro ルーマニア語 10,021 5,911 イートから選ぶ(ノイズは許容) sv スウェーデン語 44,054 10,032 ? カタルーニャ語コーパス作成で tr トルコ語 44,703 10,308 は、Raúl Velaz 氏と真鍋宏史氏 vi ベトナム語 15,030 10,488 計 538,789 166,773 に協力をいただいています 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 27. データ形式 ? 訓練データ?テストデータ共通 – [正解ラベル]?t[メタデータ]?t[テキスト] en u should just enjoy ur vacation sadly en :D i'm online but you arent RT that much en im gettin attacked for a tweet LOOOOOOOOOOOOOOOOL ca [ステータスID] [日時] [ユーザID] [UIの言語] @xxx xDDD no m'extranya... Tal volta haguera segut millor per a la humanitat que no l'haguera vist... you know.. xDD 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 28. ブカレスト市内の看板(ルーマニア語) 実装と评価 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 29. Language Detection with Infinity-Gram (ldig) ? ラテン文字ツイートの言语判定器 – https://github.com/shuyo/ldig ? MIT license ? 学習済みモデルも同 URL にて配布 – ∞-gram 多クラスLR(極大部分文字列) [岡野原+ 08] – L1 SGD (Cumulative Penalty) [Tsuruoka+ 09] – Double Array 極大部分文字列を使った twitter 言语判定 (NLP2012)
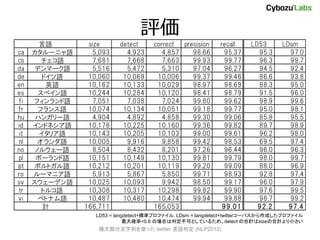
- 30. 评価 言語 size detect correct precision recall LD53 LDsm ca カタルーニャ語 5,093 4,923 4,857 98.66 95.37 95.3 97.0 cs チェコ語 7,681 7,668 7,663 99.93 99.77 96.3 99.7 da デンマーク語 5,516 5,472 5,310 97.04 96.27 94.5 92.4 de ドイツ語 10,060 10,069 10,006 99.37 99.46 86.6 93.8 en 英語 10,162 10,133 10,029 98.97 98.69 88.3 95.0 es スペイン語 10,244 10,284 10,120 98.41 98.79 91.5 96.0 fi フィンランド語 7,051 7,038 7,024 99.80 99.62 98.9 99.6 fr フランス語 10,074 10,134 10,051 99.18 99.77 95.0 98.1 hu ハンガリー語 4,904 4,892 4,858 99.30 99.06 85.8 95.5 id インドネシア語 10,178 10,225 10,160 99.36 99.82 89.7 98.9 it イタリア語 10,143 10,205 10,103 99.00 99.61 96.2 98.0 nl オランダ語 10,005 9,916 9,858 99.42 98.53 69.5 97.4 no ノルウェー語 8,504 8,432 8,201 97.26 96.44 96.0 96.3 pl ポーランド語 10,151 10,149 10,130 99.81 99.79 98.0 99.7 pt ポルトガル語 10,212 10,201 10,119 99.20 99.09 88.0 96.9 ro ルーマニア語 5,913 5,867 5,850 99.71 98.93 92.8 97.4 sv スウェーデン語 10,025 10,093 9,942 98.50 99.17 96.0 97.9 tr トルコ語 10,308 10,317 10,298 99.82 99.90 97.6 99.5 vi ベトナム語 10,487 10,480 10,474 99.94 99.88 98.7 99.2 計 166,711 165,053 99.01 92.2 97.4 LD53 = langdetect+標準プロファイル, LDsm = langdetect+twitterコーパスから作成したプロファイル 最大確率<0.6 の場合は判定不可としているため、detect の合計はsizeの合計より小さい 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 31. LIGA dataset で评価 ? LIGA[Tromp+ 11] が公開している 6言語 9066件のデータセットで评価 – http://www.win.tue.nl/~mpechen/projects/smm/ 言語 size detect correct precision recall de ドイツ語 1479 1476 1469 99.5 99.3 en 英語 1505 1502 1490 99.2 99.0 es スペイン語 1562 1548 1541 99.6 98.7 fr フランス語 1551 1549 1540 99.4 99.3 it イタリア語 1539 1531 1528 99.8 99.3 nl オランダ語 1430 1429 1424 99.7 99.6 計 9066 8992 99.2 19言語モデルで评価 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 32. まとめ&課題 ? 極大部分文字列を用いた言语判定器 – 19 言語を精度 99% で判定 – langdetect + ツイートコーパスも精度97% ? コーパスを整備すれば、精度はまだ上がる – 感覚的には 5000件で 98%、40000件で 99% – 間違いもまだ少なくない(特に da と no) ? メタデータも素性に入れれば、精度はまだ上がる – 低コストでメタデータを追加&学習するには? ? 精度を落とさずモデルをスリム化したい 極大部分文字列を使った twitter 言语判定 (NLP2012)
- 33. References ? [岡野原+ 08] 全ての部分文字列を考虑した文书分类 ? ニューエクスプレスシリーズ(白水社) – スウェーデン語、ノルウェー語、デンマーク語、ポーランド語、ハン ガリー語、ルーマニア語、チェコ語、リトアニア語、スペイン語、カ タルーニャ語、ベトナム語、トルコ語、ドイツ語、オランダ語、スワ ヒリ語 ? [Brody+ 11] Cooooooooooooooollllllllllllll!!!!!!!!!!!!!! Using Word Lengthening to Detect Sentiment in Microblogs ? [Cavnar+ 94] N-Gram-Based Text Categorization ? [Tsuruoka+ 09] Stochastic Gradient Descent Training for L1- regularized Log-linear Models with Cumulative Penalty 極大部分文字列を使った twitter 言语判定 (NLP2012)