
![Linux-HA Japan Project 2
本日のメニュー
[前菜]
① Pacemakerって何?
② PG-REXって何?
[メインディッシュ]
③ PG-REXのF.O短縮
③-1 分析編
③-2 改善編 (高速版PG-REXの誕生)
④ 高速版PG-REXの使用方法
[デザート]
⑤ Linux-HA Japan について](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-2-320.jpg)








![Linux-HA Japan Project 15
故障発生からの経過時間[秒]
? PG-REXでF.O時間を実測してみた。
F.Oに90秒近くかかる(DB負荷なし)
故障パターンとF.O時間[秒]
No. 故障 対処
1 ?????????VIP故障
(A)????再起動
2 ?????????NW断
3
Master側
?????用NW断
(B)通常F.O
4
Master側
Pacemaker故障 (C)STONITH後
F.O
5
Master側
DB 停止失敗
hp DL360p Gen8
CPU Xeon E5-2640 2.5GHz (6core)×1
メモリ 16GB
HDD SAS,10krpm,300GB×6(RAID1+0)
RAID?????? Smart Array P420i/1GB FBWC
種別 名称 バージョン
OS Red Hat Enterprise Linux 6.4 (x86_64)
DBMS PostgreSQL 9.2.4-1PGDG.rhel6.x86_64
クラスタ Pacemaker 1.0.13-1.1.el6.x86_64
ハードソフト
目標値](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-15-320.jpg)
![Linux-HA Japan Project 16
? DBに負荷をかけてみた。
No. 故障 対処
5
Master側
DB 停止失敗
(DB負荷あり)
(C)STONITH後
F.O
負荷条件
?OSDL配布のDBT-2の負荷(ただし負荷ツールは少し改造)
http://sourceforge.net/apps/mediawiki/osdldbt/index.php?title=Main_Page#dbt2
?DB規模は200WH※(約24GB) ※WH(ウェアハウス)はDBT-2で定義されるDB規模の単位。
1WH あたり 約120MB のDBが生成される。
故障発生からの経過時間[秒]
目標値
DB負荷ありだとDBのpromote処理でさらに時間がかかる???orz
分析?改善を実施](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-16-320.jpg)
![No. 故障 対処
5
Master側
DB 停止失敗
(DB負荷あり)
(C)STONITH後
F.O
故障発生からの経過時間[秒]
Linux-HA Japan Project 17
? 分析してみた。
それぞれ何の時間?
①故障を検知し、STONITHの実行が必要と判断するまでの時間。
→Pacemakerが一生懸命がんばっているのでまぁしかたないか???
②SlaveがSTONITH実行を待つ時間。
→? 短くできるかも????
③STONITHを実行し、次に何をすべきかPacemakerが考える時間。
→Pacemakerが一生懸命がんばっているのでまぁしかたないか???
④SlaveがSTONITH実行を待つ時間。
→? 短くできるかも????
(再掲)
① ② ③ ④ ⑤
⑤PostgreSQLがMasterに昇格(promote)する処理。
→? PostgreSQL専門家に聞いてみよう???
怪しい待ち時間を
発見
さらに分析する
凡例](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-17-320.jpg)
![Linux-HA Japan Project 18
? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [1/4]
→まずは、「スプリットブレイン」について復習
出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」
相手が
停止したな...
相手が
停止したな... Pacemaker通信用の
LANが切れ、互いに
相手の状態を確認で
きない。
HAクラスタにとって
最もやばい状況!
PG-REXの場合共有
ディスクは無いが、
両系でDB(Master)が
起動しデータに不整
合が生じる!](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-18-320.jpg)
![Linux-HA Japan Project 19
? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [2/4]
出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」
→次に「STONITH」について復習
「状態が確認できな
い」または「リソース
の停止に失敗」した
ノードの電源を強制
的に切る機能。
スプリットブレイン対
策のひとつ。
「Shoot-The-Other-
Node-In-The-Head」
の略。](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-19-320.jpg)
![Linux-HA Japan Project 20
? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [3/4]
→もしたまたま同時にSTONITHしたら????
出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」
相手が
停止したな...
相手が
停止したな...
両系マウント?データ
破壊は防げるが、
なるべくならサービス
継続したい!!](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-20-320.jpg)
![Linux-HA Japan Project 21
? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [4/4]
出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」
→で、登場するのが「stonith-helper」と「待ち時間」
PG-REXでも
この機能を使用。
自分がSlaveなら
STONITH実行を待つ。
(??????25秒)](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-21-320.jpg)
![Linux-HA Japan Project 22
? ②と④の待ち時間について再考
→stonith-helperのロジックを、2回待たなくていいように改善!(改善1)
→よく考えたら、PG-REXではもう少し短くできる!(改善2)
それぞれ対処しました!!
No. 故障 対処
5
Master側
DB 停止失敗
(DB負荷あり)
(C)STONITH後
F.O
故障発生からの経過時間[秒]
(再掲)
② ④
こんな疑問が浮かびますよね???
? そもそも25秒も待つ必要あるの?
? なんで、②④の2回も待つの?
「DB停止失敗」なのでSTONITHするしかないはず???
→ 解析の結果、本来不要な待ち時間であるが stonith-helperのロジックの
都合上、2回実行していたことがわかった。
→25秒はstonith-helperのデフォルト待ち時間。パラメタで設定可能。](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-22-320.jpg)




![Linux-HA Japan Project 34
3) 設定変更の詳細(pm_crmgen使用の場合)
#表 5-5-1 クラスタ設定 … Primitiveリソース (id=prmStonith2-1)
PRIMITIVE
P
#
A type
# パラメータ種別
params
O type
# オペレーション
start
monitor
stop
自身がSlaveのときにSTONITH実行を待つ時間[秒]
standby_check_command /usr/sbin/crm_resource -r master-group -W | grep -q `hostname` Masterノード判定コマンド
standby_wait_time 10
60s 0s
60s 10s
60s 0s
タイムアウト値 監視間隔 on_fail(障害時の動作) 起動前処理
run_online_check yes standby_wait待ちを、可能な場合にスキップするか。
timeout interval on-fail start-delay
備考
id class provider type
リソースID class provider type
prmStonith2-1 stonith external/stonith-helper
項目 設定内容 概要
hostlist
priority 1
name value
stonith-timeout 40s
dead_check_target 172.20.144.44 192.168.0.12 192.168.2.2 192.168.1.2 192.168.3.2
STONITH実行優先順位
stonith-helperプラグインのタイムアウト値
概要
stonith-helperプラグイン(STONITHプラグイン)
STONITH対象ノードの全てのIPアドレス(運用LAN、インター
pg-rex02 STONITH対象ノードのホスト名
stonith-helperの設定に「standby_wait_time=X」および「run_online_check=yes」を追加する
→赤枠部分を追加(X=10の場合の例)
external/stonith-helper
standby_wait_time 10
run_online_check yes](https://image.slidesharecdn.com/osc2014kyoto-140825042821-phpapp01/85/Pacemaker-PostgreSQL-PG-REX-34-320.jpg)




Pacemaker + PostgreSQL レプリケーション構成(PG-REX)のフェイルオーバー高速化
- 1. Pacemaker + PostgreSQL レプリケーション構成(PG-REX) のフェイルオーバー高速化 2014年8月2日 OSC2014 Kansai@Kyoto Linux-HA Japan 東 一彦 Linux-HA Japan Project
- 2. Linux-HA Japan Project 2 本日のメニュー [前菜] ① Pacemakerって何? ② PG-REXって何? [メインディッシュ] ③ PG-REXのF.O短縮 ③-1 分析編 ③-2 改善編 (高速版PG-REXの誕生) ④ 高速版PG-REXの使用方法 [デザート] ⑤ Linux-HA Japan について
- 3. Linux-HA Japan Project 3 ① Pacemakerって何?
- 4. Linux-HA Japan Project 4 Pacemakerはオープンソースの HAクラスタソフトです。
- 5. Linux-HA Japan Project 5 High Availability = 高可用性 つまり 一台のコンピュータでは得られない高い信頼 性を狙うために、 複数のコンピュータを結合し、 ひとまとまりとしたシステムのこと サービス継続性
- 6. Linux-HA Japan Project 6 現用系 待機系 サービス HAクラスタを導入すると、 故障で現用系でサービスができなくなったときに、自動で待 機系でサービスを起動させます →このことを「フェイルオーバー」と言います (以降、F.Oと表記) サービス 故障 フェイルオーバー
- 7. Linux-HA Japan Project 7 は このHAクラスタソフトとして 実績のある「Heartbeat」と 呼ばれていたソフトの後継です。
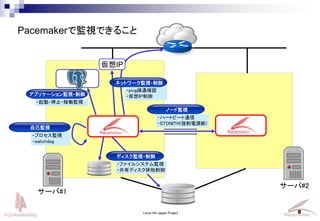
- 8. Linux-HA Japan Project 8 サーバ#1 サーバ#2 アプリケーション監視?制御 仮想IP 自己監視 ノード監視 ディスク監視?制御 ネットワーク監視?制御 ?プロセス監視 ?watchdog ?ファイルシステム監視 ?共有ディスク排他制御 ?ハートビート通信 ?STONITH(強制電源断) ?ping疎通確認 ?仮想IP制御 ?起動?停止?稼働監視 Pacemakerで監視できること
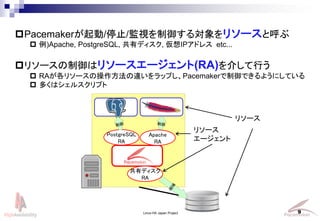
- 9. 9 PostgreSQL RA ?Pacemakerが起動/停止/監視を制御する対象をリソースと呼ぶ ? 例)Apache, PostgreSQL, 共有ディスク, 仮想IPアドレス etc... ?リソースの制御はリソースエージェント(RA)を介して行う ? RAが各リソースの操作方法の違いをラップし、Pacemakerで制御できるようにしている ? 多くはシェルスクリプト Apache RA 共有ディスク RA リソース リソース エージェント Linux-HA Japan Project
- 10. Linux-HA Japan Project 10 ② PG-REXって何?
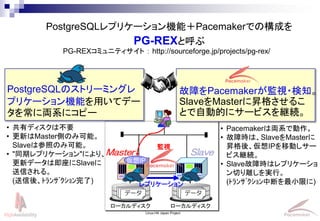
- 11. Linux-HA Japan Project Master Slave データ ローカルディスク データ ローカルディスク レプリケーション 監視 PG-REXコミュニティサイト : http://sourceforge.jp/projects/pg-rex/ 仮想IP PostgreSQLレプリケーション機能+Pacemakerでの構成を PG-REXと呼ぶ PostgreSQLのストリーミングレ プリケーション機能を用いてデー タを常に両系にコピー ? 共有ディスクは不要 ? 更新はMaster側のみ可能。 Slaveは参照のみ可能。 ? "同期レプリケーション"により、 更新データは即座にSlaveに 送信される。 (送信後、?????????完了) 故障をPacemakerが監視?検知。 SlaveをMasterに昇格させるこ とで自動的にサービスを継続。 ? Pacemakerは両系で動作。 ? 故障時は、SlaveをMasterに 昇格後、仮想IPを移動しサー ビス継続。 ? Slave故障時はレプリケーショ ン切り離しを実行。 (?????????中断を最小限に)
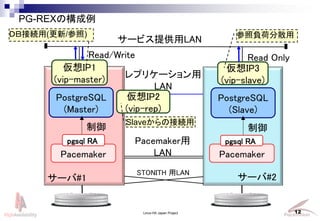
- 12. Linux-HA Japan Project 12 PG-REXの構成例 Pacemaker Pacemaker サービス提供用LAN PostgreSQL (Master) PostgreSQL (Slave) レプリケーション用 LAN 仮想IP1 (vip-master) 仮想IP2 (vip-rep) 仮想IP3 (vip-slave) pgsql RA pgsql RA 制御 制御 サーバ#1 サーバ#2 Pacemaker用 LAN Read/Write Read Only STONITH 用LAN 参照負荷分散用 Slaveからの接続用 DB接続用(更新/参照)
- 13. Linux-HA Japan Project 13 ③ PG-REXのF.O短縮 ~分析編~
- 14. ? 「故障」と一口に言っても、様々な故障があります。 ? 故障の内容によって、Pacemakerが行う対処も様々です。 大きく以下3つに分けられます。 Linux-HA Japan Project 14 対処 (A)リソース再起動 (B)通常F.O (C)STONITH後F.O 概要 同じサーバ上でリソースを もう一度起動または設定変 更する。F.Oはしない。 サービス継続に直接関係な いリソース故障時の対処。 故障したサーバの関連リ ソースを停止後、Standby サーバでリソースを起動す る。いわゆる「フェイルオー バー」。 故障サーバの電源を強制 的に断(STONITH)後、 Standbyサーバでリソース を起動。 故障サーバの状態が確認 できない場合に2重起動を 防ぐ対処。 故障例 ?レプリケーション用VIP故障 ?レプリケーション用NW断 ?DBプロセス停止 ?サービス用VIP故障 ?サービス用NW断 ?サーバ電源停止 ?Pacemaker停止 ?IC-LAN断 ?リソース停止失敗 短 長サービス中断時間
- 15. Linux-HA Japan Project 15 故障発生からの経過時間[秒] ? PG-REXでF.O時間を実測してみた。 F.Oに90秒近くかかる(DB負荷なし) 故障パターンとF.O時間[秒] No. 故障 対処 1 ?????????VIP故障 (A)????再起動 2 ?????????NW断 3 Master側 ?????用NW断 (B)通常F.O 4 Master側 Pacemaker故障 (C)STONITH後 F.O 5 Master側 DB 停止失敗 hp DL360p Gen8 CPU Xeon E5-2640 2.5GHz (6core)×1 メモリ 16GB HDD SAS,10krpm,300GB×6(RAID1+0) RAID?????? Smart Array P420i/1GB FBWC 種別 名称 バージョン OS Red Hat Enterprise Linux 6.4 (x86_64) DBMS PostgreSQL 9.2.4-1PGDG.rhel6.x86_64 クラスタ Pacemaker 1.0.13-1.1.el6.x86_64 ハードソフト 目標値
- 16. Linux-HA Japan Project 16 ? DBに負荷をかけてみた。 No. 故障 対処 5 Master側 DB 停止失敗 (DB負荷あり) (C)STONITH後 F.O 負荷条件 ?OSDL配布のDBT-2の負荷(ただし負荷ツールは少し改造) http://sourceforge.net/apps/mediawiki/osdldbt/index.php?title=Main_Page#dbt2 ?DB規模は200WH※(約24GB) ※WH(ウェアハウス)はDBT-2で定義されるDB規模の単位。 1WH あたり 約120MB のDBが生成される。 故障発生からの経過時間[秒] 目標値 DB負荷ありだとDBのpromote処理でさらに時間がかかる???orz 分析?改善を実施
- 17. No. 故障 対処 5 Master側 DB 停止失敗 (DB負荷あり) (C)STONITH後 F.O 故障発生からの経過時間[秒] Linux-HA Japan Project 17 ? 分析してみた。 それぞれ何の時間? ①故障を検知し、STONITHの実行が必要と判断するまでの時間。 →Pacemakerが一生懸命がんばっているのでまぁしかたないか??? ②SlaveがSTONITH実行を待つ時間。 →? 短くできるかも???? ③STONITHを実行し、次に何をすべきかPacemakerが考える時間。 →Pacemakerが一生懸命がんばっているのでまぁしかたないか??? ④SlaveがSTONITH実行を待つ時間。 →? 短くできるかも???? (再掲) ① ② ③ ④ ⑤ ⑤PostgreSQLがMasterに昇格(promote)する処理。 →? PostgreSQL専門家に聞いてみよう??? 怪しい待ち時間を 発見 さらに分析する 凡例
- 18. Linux-HA Japan Project 18 ? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [1/4] →まずは、「スプリットブレイン」について復習 出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」 相手が 停止したな... 相手が 停止したな... Pacemaker通信用の LANが切れ、互いに 相手の状態を確認で きない。 HAクラスタにとって 最もやばい状況! PG-REXの場合共有 ディスクは無いが、 両系でDB(Master)が 起動しデータに不整 合が生じる!
- 19. Linux-HA Japan Project 19 ? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [2/4] 出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」 →次に「STONITH」について復習 「状態が確認できな い」または「リソース の停止に失敗」した ノードの電源を強制 的に切る機能。 スプリットブレイン対 策のひとつ。 「Shoot-The-Other- Node-In-The-Head」 の略。
- 20. Linux-HA Japan Project 20 ? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [3/4] →もしたまたま同時にSTONITHしたら???? 出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」 相手が 停止したな... 相手が 停止したな... 両系マウント?データ 破壊は防げるが、 なるべくならサービス 継続したい!!
- 21. Linux-HA Japan Project 21 ? ②④「SlaveがSTONITH実行を待つ時間」ってどういうこと? [4/4] 出典:OSC 2013 Kansai@Kyoto講演「HAクラスタをフェイルオーバ失敗から救おう!」 →で、登場するのが「stonith-helper」と「待ち時間」 PG-REXでも この機能を使用。 自分がSlaveなら STONITH実行を待つ。 (??????25秒)
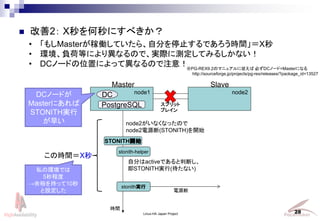
- 22. Linux-HA Japan Project 22 ? ②と④の待ち時間について再考 →stonith-helperのロジックを、2回待たなくていいように改善!(改善1) →よく考えたら、PG-REXではもう少し短くできる!(改善2) それぞれ対処しました!! No. 故障 対処 5 Master側 DB 停止失敗 (DB負荷あり) (C)STONITH後 F.O 故障発生からの経過時間[秒] (再掲) ② ④ こんな疑問が浮かびますよね??? ? そもそも25秒も待つ必要あるの? ? なんで、②④の2回も待つの? 「DB停止失敗」なのでSTONITHするしかないはず??? → 解析の結果、本来不要な待ち時間であるが stonith-helperのロジックの 都合上、2回実行していたことがわかった。 →25秒はstonith-helperのデフォルト待ち時間。パラメタで設定可能。
- 23. Linux-HA Japan Project 23 ③ PG-REXのF.O短縮 ~改善編~ (高速版PG-REX誕生)
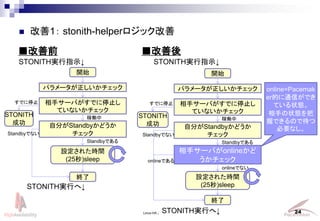
- 24. Linux-HA Japan Project 24 ? 改善1: stonith-helperロジック改善 ■改善前 ■改善後 パラメータが正しいかチェック 開始 相手サーバがすでに停止し ていないかチェック 自分がStandbyかどうか チェック 終了 STONITH実行へ↓ STONITH実行指示↓ Standbyでない すでに停止 STONITH 成功 設定された時間 (25秒)sleep Standbyである 稼働中 パラメータが正しいかチェック 開始 相手サーバがすでに停止し ていないかチェック 自分がStandbyかどうか チェック 終了 Standbyでない すでに停止 STONITH 成功 設定された時間 (25秒)sleep Standbyである 稼働中 相手サーバがonlineかど うかチェック onlineでない onlineである online=Pacemak er的に通信ができ ている状態。 相手の状態を把 握できるので待つ 必要なし。 STONITH実行へ↓ STONITH実行指示↓
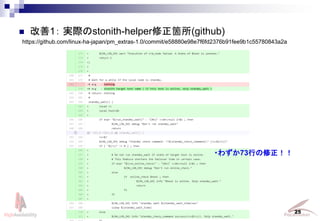
- 25. Linux-HA Japan Project 25 https://github.com/linux-ha-japan/pm_extras-1.0/commit/e58880e98e7f6fd2376b91fee9b1c55780843a2a ? 改善1: 実際のstonith-helper修正箇所(github) ?わずか73行の修正!!
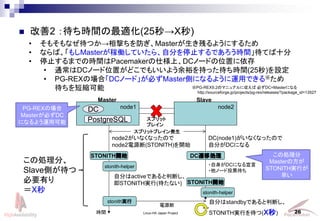
- 26. Linux-HA Japan Project 26 ? 改善2 :待ち時間の最適化(25秒→X秒) ? そもそもなぜ待つか→相撃ちを防ぎ、Masterが生き残るようにするため ? ならば、「もしMasterが稼働していたら、自分を停止するであろう時間」待てば十分 ? 停止するまでの時間はPacemakerの仕様上、DCノードの位置に依存 ? 通常はDCノード位置がどこでもいいよう余裕を持った待ち時間(25秒)を設定 ? PG-REXの場合「DCノード」が必ずMaster側になるように運用できる※ため 待ちを短縮可能 DC(node1)がいなくなったので 自分がDCになる node2がいなくなったので node2電源断(STONITH)を開始 時間 ?自身がDCになる宣言 ?他ノード投票待ち 自分はactiveであると判断し、 即STONITH実行(待たない) STONITH開始 DC遷移処理 stonith-helper stonith実行 電源断 node1 Master Slave PostgreSQL DC node2 スプリット ブレイン スプリットブレイン発生 自分はstandbyであると判断し、 STONITH実行を待つ(x秒) stonith-helper STONITH開始 この処理分、 Slave側が待つ 必要有り =X秒 この処理分 Masterの方が STONITH実行が 早い PG-REXの場合 Masterが必ずDC になるよう運用可能 ※PG-REX9.2のマニュアルに従えば 必ずDC=Masterになる http://sourceforge.jp/projects/pg-rex/releases/?package_id=13527
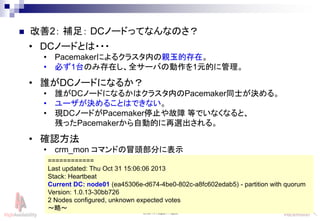
- 27. Linux-HA Japan Project 27 ? 改善2: 補足: DCノードってなんなのさ? ? DCノードとは??? ? Pacemakerによるクラスタ内の親玉的存在。 ? 必ず1台のみ存在し、全サーバの動作を1元的に管理。 ? 誰がDCノードになるか? ? 誰がDCノードになるかはクラスタ内のPacemaker同士が決める。 ? ユーザが決めることはできない。 ? 現DCノードがPacemaker停止や故障 等でいなくなると、 残ったPacemakerから自動的に再選出される。 ? 確認方法 ? crm_mon コマンドの冒頭部分に表示 ============ Last updated: Thu Oct 31 15:06:06 2013 Stack: Heartbeat Current DC: node01 (ea45306e-d674-4be0-802c-a8fc602edab5) - partition with quorum Version: 1.0.13-30bb726 2 Nodes configured, unknown expected votes ~略~
- 28. Linux-HA Japan Project 28 ? 改善2: X秒を何秒にすべきか? ? 「もしMasterが稼働していたら、自分を停止するであろう時間」=X秒 ? 環境、負荷等により異なるので、実際に測定してみるしかない! ? DCノードの位置によって異なるので注意! node2がいなくなったので node2電源断(STONITH)を開始 時間 自分はactiveであると判断し、 即STONITH実行(待たない) STONITH開始 stonith-helper stonith実行 電源断 node1 Master Slave PostgreSQL DC node2 スプリット ブレイン この時間=X秒 DCノードが Masterにあれば STONITH実行 が早い ※PG-REX9.2のマニュアルに従えば 必ずDCノード=Masterになる http://sourceforge.jp/projects/pg-rex/releases/?package_id=13527 私の環境では 5秒程度 →余裕を持って10秒 と設定した
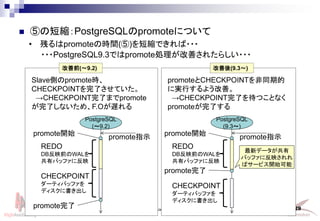
- 29. Linux-HA Japan Project 29 ? ⑤の短縮:PostgreSQLのpromoteについて ? 残るはpromoteの時間(⑤)を短縮できれば??? Slave側のpromote時、 CHECKPOINTを完了させていた。 →CHECKPOINT完了までpromote が完了しないため、F.Oが遅れる promoteとCHECKPOINTを非同期的 に実行するよう改善。 →CHECKPOINT完了を待つことなく promoteが完了する 改善前(~9.2) 改善後(9.3~) promote開始 promote完了 REDO DB反映前のWALを 共有バッファに反映 CHECKPOINT ダーティバッファを ディスクに書き出し PostgreSQL (~9.2) promote指示 promote開始 promote完了 REDO DB反映前のWALを 共有バッファに反映 CHECKPOINT ダーティバッファを ディスクに書き出し PostgreSQL (9.3~) promote指示 最新データが共有 バッファに反映されれ ばサービス開始可能 ???PostgreSQL9.3ではpromote処理が改善されたらしい???
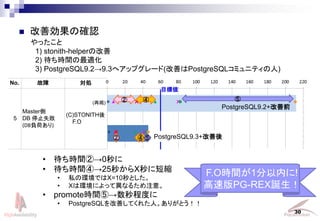
- 30. 30 ? 改善効果の確認 No. 故障 対処 5 Master側 DB 停止失敗 (DB負荷あり) (C)STONITH後 F.O 目標値 (再掲) PostgreSQL9.2+改善前 PostgreSQL9.3+改善後② ④ ⑤ ⑤② ④ ? 待ち時間②→0秒に ? 待ち時間④→25秒からX秒に短縮 ? 私の環境ではX=10秒とした。 ? Xは環境によって異なるため注意。 ? promote時間⑤→数秒程度に ? PostgreSQLを改善してくれた人。ありがとう!! F.O時間が1分以内に! 高速版PG-REX誕生! やったこと 1) stonith-helperの改善 2) 待ち時間の最適化 3) PostgreSQL9.2→9.3へアップグレード(改善はPostgreSQLコミュニティの人)
- 31. Linux-HA Japan Project 31 ④ 高速版PG-REXの使用方法
- 32. Linux-HA Japan Project 32 で、高速版PG-REXっていつ使えるの? 7/8に PG-REX9.3 をリリースしました!! http://sourceforge.jp/projects/pg-rex/releases/p14274 ????? F/O高速化のポイントは??? ?????
- 33. Linux-HA Japan Project 33 ? 1) 最新Pacemakerへアップグレード(リポジトリパッケージ1.0.13-1.2以降) ? http://linux-ha.sourceforge.jp/wp/dl/packages で最新版をゲット! ? 2) PostgreSQL9.3へアップグレード(9.3.4以降がおすすめ) ? RHEL系rpmは以下で配布。 http://yum.postgresql.org/packages.php ? 3) 以下設定を変更 ? stonith-helperの設定に「standby_wait_time=X」および 「run_online_check=yes」を追加する。(詳細後述) ? pgsql RAはPacemaker同梱版を使用する。 PG-REX9.3 F/O高速化のポイントは以下3点。 (PG-REX9.2をお使いの方でも、以下を実施すれば高速化できます)
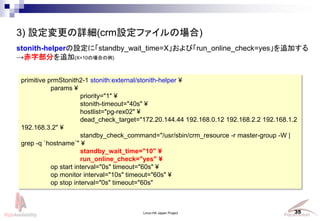
- 34. Linux-HA Japan Project 34 3) 設定変更の詳細(pm_crmgen使用の場合) #表 5-5-1 クラスタ設定 … Primitiveリソース (id=prmStonith2-1) PRIMITIVE P # A type # パラメータ種別 params O type # オペレーション start monitor stop 自身がSlaveのときにSTONITH実行を待つ時間[秒] standby_check_command /usr/sbin/crm_resource -r master-group -W | grep -q `hostname` Masterノード判定コマンド standby_wait_time 10 60s 0s 60s 10s 60s 0s タイムアウト値 監視間隔 on_fail(障害時の動作) 起動前処理 run_online_check yes standby_wait待ちを、可能な場合にスキップするか。 timeout interval on-fail start-delay 備考 id class provider type リソースID class provider type prmStonith2-1 stonith external/stonith-helper 項目 設定内容 概要 hostlist priority 1 name value stonith-timeout 40s dead_check_target 172.20.144.44 192.168.0.12 192.168.2.2 192.168.1.2 192.168.3.2 STONITH実行優先順位 stonith-helperプラグインのタイムアウト値 概要 stonith-helperプラグイン(STONITHプラグイン) STONITH対象ノードの全てのIPアドレス(運用LAN、インター pg-rex02 STONITH対象ノードのホスト名 stonith-helperの設定に「standby_wait_time=X」および「run_online_check=yes」を追加する →赤枠部分を追加(X=10の場合の例) external/stonith-helper standby_wait_time 10 run_online_check yes
- 35. Linux-HA Japan Project 35 3) 設定変更の詳細(crm設定ファイルの場合) stonith-helperの設定に「standby_wait_time=X」および「run_online_check=yes」を追加する →赤字部分を追加(X=10の場合の例) primitive prmStonith2-1 stonith:external/stonith-helper ? params ? priority="1" ? stonith-timeout="40s" ? hostlist="pg-rex02" ? dead_check_target="172.20.144.44 192.168.0.12 192.168.2.2 192.168.1.2 192.168.3.2" ? standby_check_command="/usr/sbin/crm_resource -r master-group -W | grep -q `hostname`" ? standby_wait_time="10" ? run_online_check="yes" ? op start interval="0s" timeout="60s" ? op monitor interval="10s" timeout="60s" ? op stop interval="0s" timeout="60s"
- 36. Linux-HA Japan Project 36 ? まとめ ? ちょっとした改造でもコミュニティに貢献できる ? 私がやったのはたった73行+設定変更 ???でも効果はあったはず!(自画自賛) みなさんも、ユーザ/投稿者どちらでもかまわないので、 ぜひコミュニティに参加してください! Linux-HA Japan :http://linux-ha.sourceforge.jp/wp/ PG-REX :http://sourceforge.jp/projects/pg-rex/ ? PostgreSQLレプリケーション+Pacemaker=PG-REX ? フェールオーバー時間が1分以内となり、より使えるように!
- 37. Linux-HA Japan Project 37 ⑤ Linux-HA Japanについて
- 38. Linux-HA Japan Project 38 Linux-HA Japan URL http://linux-ha.sourceforge.jp/ Pacemaker関連の最新情報を 日本語で発信 Pacemakerのダウンロードもこ ちらからどうぞ。 (インストールが楽なリポジトリパッケージ を公開しています。) http://sourceforge.jp/projects/linux-ha/
- 39. Linux-HA Japan Project 39 Linux-HA Japanメーリングリスト ? ML登録用URL http://linux-ha.sourceforge.jp/ の「メーリングリスト」をクリック ? MLアドレス linux-ha-japan@lists.sourceforge.jp 日本におけるHAクラスタについての活発な意見交換の場として 「Linux-HA Japan日本語メーリングリスト」 も開設しています。 Linux-HA-Japan MLでは、Pacemaker、Heartbeat3、Corosync DRBDなど、HAクラスタに関連する話題は歓迎! ※スパム防止のために、登録者以外の投稿は許可制です
- 40. Linux-HA Japan Project 40 ご清聴ありがとうございました。 Linux-HA Japan 検索 http://linux-ha.sourceforge.jp/