Parameter Server Approach for Online Learning at Twitter
5 likes18,411 views

Parameter Server approaches for online learning at Twitter allow models to be updated continuously based on new data and improve predictions in real-time. Version 1.0 decouples training and prediction to increase efficiency. Version 2.0 scales training by distributing it across servers. Version 3.0 will scale large complex models by sharding models and features across multiple servers. These approaches enable Twitter to perform online learning on massive datasets and complex models in real-time.














Parameter Server Approach for Online Learning at Twitter
- 1. Parameter Server Approach for Online Learning @ Twitter Joe Xie, Yong Wang and Yue Lu ML Infra Group, Ads Prediction Team Oct 10, 2017
- 2. Outline ? Background ¿C Online learning ¿C Challenges ? Parameter Server Approaches ¿C v1.0 Decouple the training and prediction ¿C v2.0 Scale the training ¿C v3.0 Scale the model ? Future Directions
- 3. Background
- 4. Twitter is Realtime ? Twitter is all about real-time: news, events, trends, hashtags. ¿C Users interest and intent change in realtime. ¿C Context changes in realtime. ¿C New advertisers, new campaigns are added in realtime. ? ML is increasingly at the core of everything we build at Twitter ¿C ML model dynamically adapts to changes spanning as short as a few hours even minutes
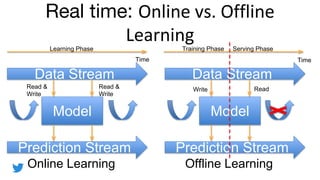
- 5. Real time: Time Model Data Stream Prediction Stream Time Model Data Stream Prediction Stream Online Learning Offline Learning Learning Phase Training Phase Serving Phase ReadWriteRead & Write Read & Write
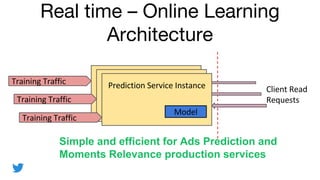
- 6. Real time ¿C Online Learning Architecture Simple and efficient for Ads Prediction and Moments Relevance production services
- 7. Challenges ? Network fanout ¿C The same traffic stream is sent many times over to each prediction instance, wasting network bandwidth. ? Limit to training traffic size ¿COnline training throughput is currently limited by the capacity (CPU / Network bandwidth) of a single mesos worker ? Limit to model size ¿C All model are hosted within the memory for each instance.
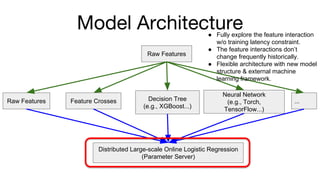
- 9. Model Architecture Raw Features Raw Features Feature Crosses Decision Tree (e.g., XGBoost...) Neural Network (e.g., Torch, TensorFlow...) ... Distributed Large-scale Online Logistic Regression (Parameter Server) í± Fully explore the feature interaction w/o training latency constraint. í± The feature interactions doní»t change frequently historically. í± Flexible architecture with new model structure & external machine learning framework.
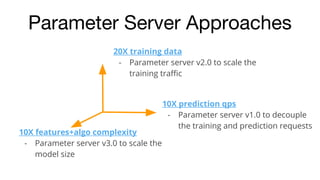
- 10. 20X training data - Parameter server v2.0 to scale the training traffic 10X features+algo complexity - Parameter server v3.0 to scale the model size 10X prediction qps - Parameter server v1.0 to decouple the training and prediction requests Parameter Server Approaches
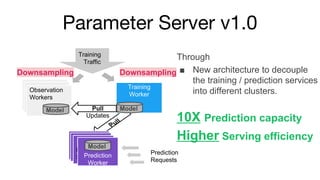
- 11. Parameter Server v1.0 Training Worker Training Traffic Observation Service Observation Service Observation Workers Instance of Prediction Service M od el Instance of Prediction Service M od el Instance of Prediction ServicePrediction Worker Pull Model Model Model Pull Downsampling Through í÷ New architecture to decouple the training / prediction services into different clusters. 10X Prediction capacity Higher Serving efficiency Prediction Requests Updates Downsampling
- 12. Parameter Server v1.0 ? Separated training service ¿CTake training traffic to generate incremental model update ? New observation service ¿C Consume incremental model update ¿C Evaluate training traffic for model quality assurance ? Separated prediction service ¿C Consume incremental model update ¿C Serve the prediction request
- 13. Parameter Server v1.0 ? Launched into ads engagement prediction models. ¿C Mesos Efficiency: 40% reduction in CPU cores required. ¿C Network Efficiency: 60% reduction in fan-out messages required.
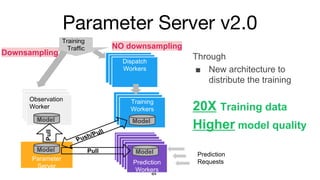
- 14. Parameter Server v2.0 Parameter Server Mo del Instance of Prediction Service Mo del Training Workers Training Traffic Observation Service Observation Service Observation Worker NO downsamplingPull Push/Pull Instance of Prediction Service M od el Instance of Prediction Service M od el Instance of Prediction Service M od el Instance of Prediction Service M od el M od el Instance of Prediction ServicePrediction Workers Pull Model ModelModel Model Through í÷ New architecture to distribute the training 20X Training data Higher model quality Dispatch Workers Dispatch Workers Dispatch Workers Downsampling Prediction Requests
- 15. Parameter Server v2.0 ? New dispatch service ¿CTake un-sampled training traffic and dispatch to training service ? Updated training service ¿CTake training traffic and produce updates for parameter service ¿CReceive model update from parameter service ? New parameter service ¿C Aggregate the updates from training services ¿C Send model update to training / observation / prediction services
- 16. Parameter Server v2.0 ? Launched into ads engagement prediction models. ? First version using simple model-average aggregation. ¿C20x training capacity ¿Cxx% model quality gain
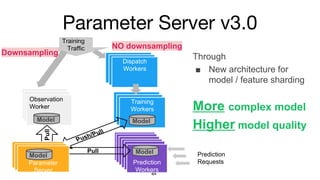
- 17. Parameter Server v3.0 Mo del Instance of Prediction Service Mo del Training Workers Training Traffic Observation Service Observation Service Observation Worker NO downsamplingPull Push/Pull Instance of Prediction Service M od el Instance of Prediction Service M od el Instance of Prediction Service M od el Instance of Prediction Service M od el M od el Instance of Prediction ServicePrediction Workers Pull Model ModelModel Model Dispatch Workers Dispatch Workers Dispatch Workers Downsampling Prediction RequestsParameter Server Parameter Server Parameter Server Model Through í÷ New architecture for model / feature sharding More complex model Higher model quality
- 18. Parameter Server v3.0 ? Updated parameter service (In progress) ¿CModel sharding: Parameter instance hosts single model instead of multiple models. ?xx% model quality gain in experimentation. ¿CFeature sharding: Parameter instance hosts partial of single model.
- 20. Future Works ? ?