笔补谤辩耻别迟はカラムナなのか?
Download as pptx, pdf7 likes3,449 views

Presto は Parquet ファイルにカラムナなIOをしているか調べてみたメモ。













![クエリを実行してみる
presto:parquet> select count(review_body) from amazon_reviews_parquet;
_col0
-----------
160789772
(1 row)
Query 20191214_131823_00001_7rzxe, FINISHED, 1 node
Splits: 1,137 total, 1,137 done (100.00%)
0:19 [161M rows, 34GB] [8.43M rows/s, 1.78GB/s]
presto:parquet> select count(*) from amazon_reviews_parquet;
_col0
-----------
160796570
(1 row)
Query 20191214_132223_00002_7rzxe, FINISHED, 1 node
Splits: 1,136 total, 1,136 done (100.00%)
0:07 [161M rows, 0B] [21.5M rows/s, 0B/s]](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/85/Parquet-23-320.jpg)



![strace で HDFS のシステムコールトレースをとると
$ sudo strace -fe sendfile -s 200 -p 10858
3434 sendfile(1003, 993, [68038656], 65536) = 65536
3546 sendfile(984, 1042, [16862208], 65536) = 65536
3438 sendfile(979, 1007, [86496768], 65536) = 65536
3422 sendfile(971, 1032, [101465600], 65536 <unfinished ...>
? select count(review_body) from …
sendfile システムコールで
64Kbyte(65536 byte) 単位で読んでいる。
$ sudo strace -fe sendfile -s 200 -p 10858
14928 sendfile(1057, 1112, [72695808], 275) = 275
14953 sendfile(1060, 1128, [47949312], 69) = 69
14954 sendfile(1041, 1112, [100519424], 489) = 489
14955 sendfile(1116, 1119, [94451200], 178) = 178
? select count(*) from … sendfile システムコールで読んでいるIOサ
イズはバラバラ。](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/85/Parquet-33-320.jpg)
![システムコールレイヤーでのIOサイズとIO量
? strace で sendfile(2) のシステムコールトレースを取得し、可視化すると、
IOサイズとIO量に差がある。
0
50,000
100,000
150,000
200,000
250,000
300,000
350,000
400,000
450,000
500,000
65536 165 177 279 24576 382 288 240 513 505
回数
IOサイズ
0
5
10
15
20
25
165 279 177 382 288 240 513 505 29861 29689
回数 IOサイズ
> select count(review_body) from … > select count(*) from …
$ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s'
strace_hdfs_review_body.log|sort|uniq -c|sort -r|head -10](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/85/Parquet-34-320.jpg)



![Appendix.5 strace + perl ワンライナーで加工
$ ps -fU hdfs,presto
UID PID PPID C STIME TTY TIME CMD
hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server -
XX:OnOutOfMemoryError=
hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m -
XX:+PreserveFramePointer -serve
presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 -
XX:+UseG1GC -XX:G1Hea
$ sudo strace -fe sendfile -s 200 -o strace_hdfs_review_body.log -p 10858
$ head -3 strace_hdfs_review_body.log
3546 sendfile(984, 1042, [16796672], 65536★ <unfinished ...>
3438 sendfile(979, 1007, [86431232], 65536 <unfinished ...>
3546<... sendfile resumed> ) = 65536
$ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s' strace_hdfs_review_body.log|sort|uniq -c|sort -r|head
-10
465521 65536
24 165
22 177
21 279
20 382
20 288
20 24576
19 240
18 513
17 505](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/85/Parquet-45-320.jpg)

笔补谤辩耻别迟はカラムナなのか?
- 1. Parquet はカラムナなのか? Yohei Azekatsu Twitter: @yoheia Dec, 2019
- 2. アジェンダ ? お話すること ? クイズ ? カラムナフォーマット Parquet とは ? Presto は Parquet をどのように読むか ? Presto on EMR で検証してみた ? まとめ ? Appendix
- 3. お話すること ? Athena や Presto on EMR で Parquet にクエリすると、必要なカラムの データだけを読んでいるか調べてみた。 ? 検証手順はブログで公開しています。 ? https://yohei-a.hatenablog.jp/entry/20191208/1575766148 出典: https://prestodb.io/overview.html /julienledem/strata-ny-2017-parquet-arrow-roadmap/13
- 4. クイズ
- 5. どのクエリが一番速いでしょう? ? Athena や Presto で以下のクエリを実行すると、どれが一番速いでしょう? ? データは S3や HDFS にある parquet ファイル。 1. select count(*) from amazon_reviews_parquet; 2. select count(product_title) from amazon_reviews_parquet; 3. select count(review_body) from amazon_reviews_parquet; 使用したデータ: https://registry.opendata.aws/amazon-reviews/
- 6. 答え(Athena) 使用したデータ: https://registry.opendata.aws/amazon-reviews/ # クエリ 実行時間 スキャンサイズ 1 select count(*) from amazon_reviews_parquet 6.28秒 0B 2 select count(product_title) from amazon_reviews_parquet 13.77秒 5.27GB 3 select count(review_body) from amazon_reviews_parquet 30.39秒 34GB ? count(*) が最もスキャンサイズが小さく速い。 ? カラム長が最も長い review_body が最もスキャンサイズが大きく遅い。 AWSマネジメントコンソールのAthenaの履歴タブ
- 7. 答え(Presto on EMR) 使用したデータ: https://registry.opendata.aws/amazon-reviews/ # クエリ 実行時間 スキャンサイズ 1 select count(*) from amazon_reviews_parquet 8秒 0B 2 select count(product_title) from amazon_reviews_parquet 9秒 5.27GB 3 select count(review_body) from amazon_reviews_parquet 17秒 34GB ? 順位とスキャンサイズは Athena と同じ。
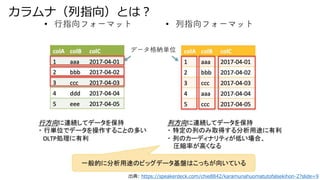
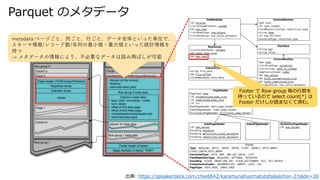
- 13. Parquet のメタデータ 出典: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2?slide=30 Footer で Row group 毎の行数を 持っているので select count(*) は Footer だけしか読まなくて済む。
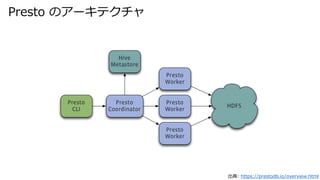
- 15. Presto は Parquet をどのように読むか
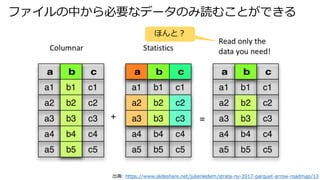
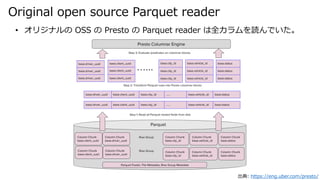
- 17. Original open source Parquet reader 出典: https://eng.uber.com/presto/ ? オリジナルの OSS の Presto の Parquet reader は全カラムを読んでいた。
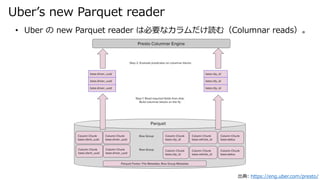
- 18. Uber’s new Parquet reader 出典: https://eng.uber.com/presto/ ? Uber の new Parquet reader は必要なカラムだけ読む(Columnar reads)。
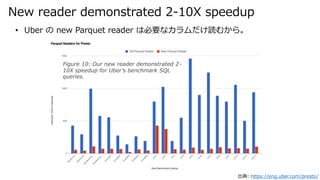
- 19. New reader demonstrated 2-10X speedup 出典: https://eng.uber.com/presto/ ? Uber の new Parquet reader は必要なカラムだけ読むから。 Figure 10: Our new reader demonstrated 2- 10X speedup for Uber’s benchmark SQL queries.
- 20. Presto に new Parquet reader が入っている 出典: https://prestodb.io/docs/current/release/release-0.138.html ? Release 0.138 から Presto にも入っている
- 21. Presto のソースコード 出典: https://prestodb.io/docs/current/release/release-0.138.html ? Release 0.137 ? https://github.com/prestodb/presto/releases/tag/0.137 ? https://github.com/prestodb/presto/tree/73d6484905b0813d0e20ea71478136547913764a/presto- hive/src/main/java/com/facebook/presto/hive/parquet/reader ? Release 0.138(New Hive Parquet Reader が入った) ? https://github.com/prestodb/presto/releases/tag/0.138 ? https://github.com/prestodb/presto/tree/10b581a53608c7657385cc7d49b8e699ee38ddb0/presto- hive/src/main/java/com/facebook/presto/hive/parquet/reader
- 22. Presto on EMR で検証してみた
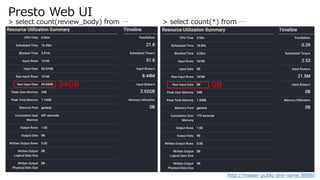
- 23. クエリを実行してみる presto:parquet> select count(review_body) from amazon_reviews_parquet; _col0 ----------- 160789772 (1 row) Query 20191214_131823_00001_7rzxe, FINISHED, 1 node Splits: 1,137 total, 1,137 done (100.00%) 0:19 [161M rows, 34GB] [8.43M rows/s, 1.78GB/s] presto:parquet> select count(*) from amazon_reviews_parquet; _col0 ----------- 160796570 (1 row) Query 20191214_132223_00002_7rzxe, FINISHED, 1 node Splits: 1,136 total, 1,136 done (100.00%) 0:07 [161M rows, 0B] [21.5M rows/s, 0B/s]
- 24. Presto Web UI http://master-public-dns-name:8889/ > select count(review_body) from … > select count(*) from … 34GB 0B
- 25. コールスタックを见ると
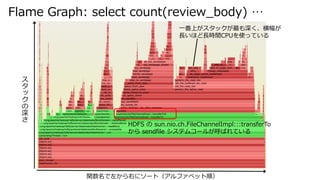
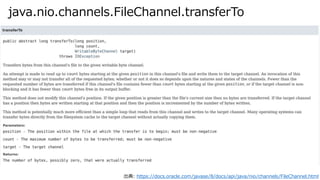
- 26. Flame Graph: select count(review_body) … HDFS の sun.nio.ch.FileChannelImpl:::transferTo から sendfile システムコールが呼ばれている ス タ ッ ク の 深 さ 関数名で左から右にソート(アルファベット順) 一番上がスタックが最も深く、横幅が 長いほど長時間CPUを使っている
- 27. Flame Graph: select count(review_body) … ユ ー ザ ー 空 間 カ ー ネ ル 空 間 sendfile システムコール ファイルシステム(XFS) からフィルを読んで ソケットにデータを 送っている
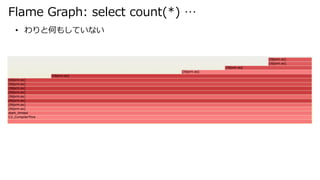
- 28. Flame Graph: select count(*) … ス タ ッ ク の 深 さ ? わりと何もしていない
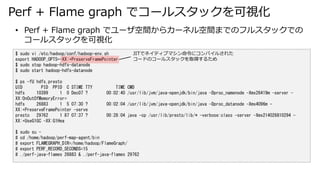
- 29. Perf + Flame graph でコールスタックを可視化 $ sudo vi /etc/hadoop/conf/hadoop-env.sh export HADOOP_OPTS=-XX:+PreserveFramePointer $ sudo stop hadoop-hdfs-datanode $ sudo start hadoop-hdfs-datanode $ ps -fU hdfs,presto UID PID PPID C STIME TTY TIME CMD hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server - XX:OnOutOfMemoryError= hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m - XX:+PreserveFramePointer -serve presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 - XX:+UseG1GC -XX:G1Hea $ sudo su - # cd /home/hadoop/perf-map-agent/bin # export FLAMEGRAPH_DIR=/home/hadoop/FlameGraph/ # export PERF_RECORD_SECONDS=15 # ./perf-java-flames 26883 & ./perf-java-flames 29762 ? Perf + Flame graph でユーザ空間からカーネル空間までのフルスタックでの コールスタックを可視化 JITでネイティブマシン命令にコンパイルされた コードのコールスタックを取得するため
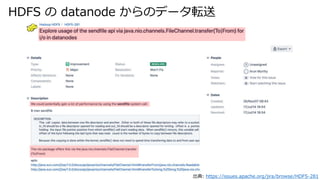
- 30. HDFS の datanode からのデータ転送 出典: https://issues.apache.org/jira/browse/HDFS-281
- 33. strace で HDFS のシステムコールトレースをとると $ sudo strace -fe sendfile -s 200 -p 10858 3434 sendfile(1003, 993, [68038656], 65536) = 65536 3546 sendfile(984, 1042, [16862208], 65536) = 65536 3438 sendfile(979, 1007, [86496768], 65536) = 65536 3422 sendfile(971, 1032, [101465600], 65536 <unfinished ...> ? select count(review_body) from … sendfile システムコールで 64Kbyte(65536 byte) 単位で読んでいる。 $ sudo strace -fe sendfile -s 200 -p 10858 14928 sendfile(1057, 1112, [72695808], 275) = 275 14953 sendfile(1060, 1128, [47949312], 69) = 69 14954 sendfile(1041, 1112, [100519424], 489) = 489 14955 sendfile(1116, 1119, [94451200], 178) = 178 ? select count(*) from … sendfile システムコールで読んでいるIOサ イズはバラバラ。
- 34. システムコールレイヤーでのIOサイズとIO量 ? strace で sendfile(2) のシステムコールトレースを取得し、可視化すると、 IOサイズとIO量に差がある。 0 50,000 100,000 150,000 200,000 250,000 300,000 350,000 400,000 450,000 500,000 65536 165 177 279 24576 382 288 240 513 505 回数 IOサイズ 0 5 10 15 20 25 165 279 177 382 288 240 513 505 29861 29689 回数 IOサイズ > select count(review_body) from … > select count(*) from … $ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s' strace_hdfs_review_body.log|sort|uniq -c|sort -r|head -10
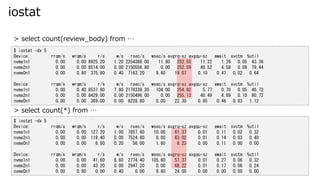
- 35. iostat $ iostat -dx 5 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.00 8925.20 1.20 2254386.00 11.80 252.55 11.22 1.26 0.05 43.36 nvme2n1 0.00 0.00 8514.00 0.00 2150556.80 0.00 252.59 40.52 4.58 0.09 79.44 nvme0n1 0.00 0.80 375.80 0.40 7163.20 9.60 19.07 0.10 0.47 0.02 0.64 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.40 8537.80 7.80 2178339.20 104.00 254.92 5.77 0.70 0.05 46.72 nvme2n1 0.00 0.00 8429.00 0.00 2150496.00 0.00 255.13 40.49 4.69 0.10 80.72 nvme0n1 0.00 0.00 369.00 0.00 8228.80 0.00 22.30 0.05 0.46 0.03 1.12 $ iostat -dx 5 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.00 127.20 1.00 7857.60 10.00 61.37 0.01 0.11 0.02 0.32 nvme2n1 0.00 0.00 119.40 0.00 7524.80 0.00 63.02 0.01 0.14 0.03 0.40 nvme0n1 0.00 0.00 6.80 0.20 56.00 1.60 8.23 0.00 0.11 0.00 0.00 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.00 41.60 8.60 2774.40 105.60 57.37 0.01 0.27 0.06 0.32 nvme2n1 0.00 0.00 43.20 0.00 2947.20 0.00 68.22 0.01 0.17 0.06 0.24 nvme0n1 0.00 0.80 0.00 0.40 0.00 9.60 24.00 0.00 0.00 0.00 0.00 > select count(review_body) from … > select count(*) from …
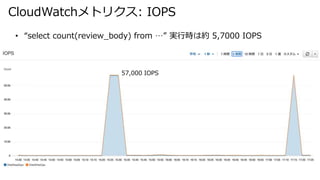
- 36. CloudWatchメトリクス: IOPS ? “select count(review_body) from …” 実行時は約 5,7000 IOPS 57,000 IOPS
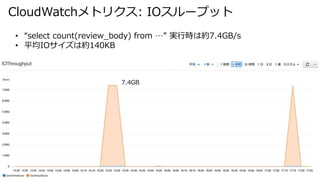
- 37. CloudWatchメトリクス: IOスループット ? “select count(review_body) from …” 実行時は約7.4GB/s ? 平均IOサイズは約140KB 7.4GB
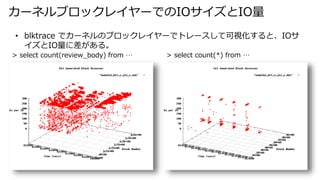
- 38. カーネルブロックレイヤーでのIOサイズとIO量 > select count(review_body) from … > select count(*) from … ? blktrace でカーネルのブロックレイヤーでトレースして可視化すると、IOサ イズとIO量に差がある。
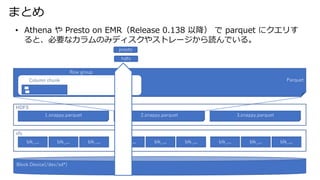
- 39. まとめ ? Athena や Presto on EMR(Release 0.138 以降) で parquet にクエリす ると、必要なカラムのみディスクやストレージから読んでいる。 presto hdfs 1.snappy.parquet 2.snappy.parquet 3.snappy.parquet HDFS xfs blk_... blk_... blk_... blk_... blk_... blk_... blk_... blk_... blk_... Block Device(/dev/sd*) Parquet Row group Column chunk
- 40. Appendix
- 41. Appendix.1 検証に使った EMR ? emr-5.28.0 ? Hadoop ディストリビューション: Amazon 2.8.5 ? アプリケーション: Hive 2.3.6, Pig 0.17.0, Hue 4.4.0, Presto 0.227, Ganglia 3.7.2 ? r5d.8xlarge、コア?マスターノードなし
- 42. Appendix.2 perf + Flame graph $ ps -fU hdfs,presto UID PID PPID C STIME TTY TIME CMD hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server - XX:OnOutOfMemoryError= hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m - XX:+PreserveFramePointer -serve presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 - XX:+UseG1GC -XX:G1Hea $ sudo su - # cd /home/hadoop/perf-map-agent/bin # export FLAMEGRAPH_DIR=/home/hadoop/FlameGraph/ # export PERF_RECORD_SECONDS=15 # ./perf-java-flames 26883 & ./perf-java-flames 29762
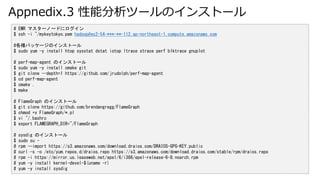
- 43. Appnedix.3 性能分析ツールのインストール # EMR マスターノードにログイン $ ssh -i ~/mykeytokyo.pem hadoop@ec2-54-***-**-112.ap-northeast-1.compute.amazonaws.com #各種パッケージのインストール $ sudo yum -y install htop sysstat dstat iotop ltrace strace perf blktrace gnuplot # perf-map-agent のインストール $ sudo yum -y install cmake git $ git clone --depth=1 https://github.com/jrudolph/perf-map-agent $ cd perf-map-agent $ cmake . $ make # FlameGraph のインストール $ git clone https://github.com/brendangregg/FlameGraph $ chmod +x FlameGraph/*.pl $ vi ~/.bashrc $ export FLAMEGRAPH_DIR=~/FlameGraph # sysdig のインストール $ sudo su - # rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public # curl -s -o /etc/yum.repos.d/draios.repo https://s3.amazonaws.com/download.draios.com/stable/rpm/draios.repo # rpm -i https://mirror.us.leaseweb.net/epel/6/i386/epel-release-6-8.noarch.rpm # yum -y install kernel-devel-$(uname -r) # yum -y install sysdig
- 44. Appnedix.4 JVM のオプションを設定 # JVM のオプションを設定 $ sudo vi /etc/hadoop/conf/hadoop-env.sh # Extra Java runtime options. Empty by default. export HADOOP_OPTS=-XX:+PreserveFramePointer # HDFS の Datanode を再起動 $ sudo stop hadoop-hdfs-datanode hadoop-hdfs-datanode stop/waiting $ sudo status hadoop-hdfs-datanode hadoop-hdfs-datanode stop/waiting $ sudo start hadoop-hdfs-datanode hadoop-hdfs-datanode start/running, process 27016 # Presto Server を再起動 $ sudo initctl list|grep presto presto-server start/running, process 17624 $ sudo stop presto-server presto-server stop/waiting $ sudo start presto-server presto-server start/running, process 29763
- 45. Appendix.5 strace + perl ワンライナーで加工 $ ps -fU hdfs,presto UID PID PPID C STIME TTY TIME CMD hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server - XX:OnOutOfMemoryError= hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m - XX:+PreserveFramePointer -serve presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 - XX:+UseG1GC -XX:G1Hea $ sudo strace -fe sendfile -s 200 -o strace_hdfs_review_body.log -p 10858 $ head -3 strace_hdfs_review_body.log 3546 sendfile(984, 1042, [16796672], 65536★ <unfinished ...> 3438 sendfile(979, 1007, [86431232], 65536 <unfinished ...> 3546<... sendfile resumed> ) = 65536 $ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s' strace_hdfs_review_body.log|sort|uniq -c|sort -r|head -10 465521 65536 24 165 22 177 21 279 20 382 20 288 20 24576 19 240 18 513 17 505
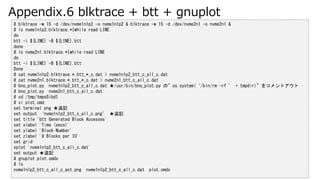
- 46. Appendix.6 blktrace + btt + gnuplot # blktrace -w 15 -d /dev/nvme1n1p2 -o nvme1n1p2 & blktrace -w 15 -d /dev/nvme2n1 -o nvme2n1 & # ls nvme1n1p2.blktrace.*|while read LINE do btt -i ${LINE} -B ${LINE}.btt done # ls nvme2n1.blktrace.*|while read LINE do btt -i ${LINE} -B ${LINE}.btt Done # cat nvme1n1p2.blktrace.*.btt_*_c.dat > nvme1n1p2_btt_c_all_c.dat # cat nvme2n1.blktrace.*.btt_*_c.dat > nvme2n1_btt_c_all_c.dat # bno_plot.py nvme1n1p2_btt_c_all_c.dat ★/usr/bin/bno_plot.py の”os.system(‘/bin/rm -rf ’ + tmpdir)”をコメントアウト # bno_plot.py nvme2n1_btt_c_all_c.dat # cd /tmp/tmpoSibdI # vi plot.cmd set terminal png ★追記 set output ‘nvme1n1p2_btt_c_all_c.png’ ★追記 set title 'btt Generated Block Accesses' set xlabel 'Time (secs)' set ylabel 'Block Number' set zlabel '# Blocks per IO' set grid splot 'nvme1n1p2_btt_c_all_c.dat' set output ★追記 # gnuplot plot.cmds # ls nvme1n1p2_btt_c_all_c_ast.png nvme1n1p2_btt_c_all_c.dat plot.cmds
- 47. Appendix.7 参考情報 ? Presto で Parquet にクエリすると、参照するカラムのみ読んでいることを確認した ? https://yohei-a.hatenablog.jp/entry/20191208/1575766148 ? カラムナフォーマットのきほん ?データウェアハウスを支える技術? ? https://engineer.retty.me/entry/columnar-storage-format ? Strata NY 2017 Parquet Arrow roadmap ? /julienledem/strata-ny-2017-parquet-arrow-roadmap ? Engineering Data Analytics with Presto and Apache Parquet at Uber ? https://eng.uber.com/presto/ ? Even Faster: When Presto Meets Parquet @ Uber ? https://events.static.linuxfound.org/sites/events/files/slides/Presto.pdf ? blktrace で block IO の分布を可視化する ? https://blog.etsukata.com/2013/12/blktrace-block-io.html ? Java Mixed-Mode Flame Graphs で Java の CPU ネックをフルスタックで分析する ? https://yohei-a.hatenablog.jp/entry/20160506/1462536427
Editor's Notes
- #4: Prestoはfacebookが開発したSQLエンジン HDFSやS3のファイルにSQLで問合せができる AthenaはPrestoのマネージド?サービス