PL/SQL - 10g Release1
Download as ppt, pdf5 likes422 views

ьЬаэФДыаИьКдэЖа эЪМьВм ьЮмьзБ ьЛЬ, ьВмыВ┤ ы░ЬэСЬ ьЪйьЬ╝ыбЬ ызМыУа PL/SQL ы░ЬэСЬ ьЮРыгМ ьЮЕыЛИыЛд.




![6
Fundamentals of the PL/SQL Language
яБ╢ Character Set
яБ╡ PL/SQL ьЧРьДЬыКФ ыЛдьЭМъ│╝ ъ░ЩьЭА ым╕ьЮР ы░П эК╣ьИШым╕ьЮР ыУдьЭД ьВмьЪйэХа ьИШ ьЮИьК╡ыЛИыЛд .
тАУ A .. Z ьЩА a .. z
тАУ ьИльЮР 0 .. 9
тАУ ьЛмы│╝ : ( ) + _ * / < > = ! ~ ^ ; : . тАЩ @ % , тАЭ # $ & _ | { } ? [ ]
тАУ Tabs, Spaces, Carriage returns
тАв PL/SQL ьЧРьДЬыКФ ыМАьЖМым╕ьЮРые╝ ъ╡мы╢ДэХШьзА ьХКьК╡ыЛИыЛд .
яБ╢ Lexical Units
яБ╡ Delimiters
Symbol Meaning Symbol Meaning Symbol Meaning
+ addition operator * multiplication operator => association operator
% attribute indicator тАЬ quoted identifier delimiter || concatenation operator
тАШ character string delimiter = relational operator ** exponentiation operator
. component selector < relational operator << label delimiter (begin)
/ division operator > relational operator >> label delimiter (end)
( expression or list delimiter @ remote access indicator <> relational operator
) expression or list delimiter ; statement terminator != relational operator
: host variable indicator - subtraction/negation operator ~= relational operator
, item separator := assignment operator ^= relational operator](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-6-320.jpg)







![16
Using PL/SQL Control Structures
яБ╡ Using the CASE Statement
CASE selector
WHEN expression1 THEN sequence_of_statements1;
WHEN expression2 THEN sequence_of_statements2;
тАж
WHEN expressionN THEN sequence_of_statementsN;
[ELSE sequence_of_statementsN+1;]
END CASE;](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-16-320.jpg)

![18
Using PL/SQL Control Structures
яБ╡ Using the WHILE-LOOP Statement
WHILE condition LOOP
sequence_of_statements
END LOOP;
яБ╡ Using the FOR-LOOP Statement
FOR counter IN [REVERSE] lower_bound..higher_bound LOOP
squence_of_statements
END LOOP;](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-18-320.jpg)



![22
Using PL/SQL Collections and Records
яБ╢ What is a PL/SQL Record?
Collection ьЭ┤ ы░░ьЧ┤ эШХэГЬьЭШ data type ьЭ┤ыЭ╝ый┤ , Record( ыаИь╜ФыУЬ ) ыКФ эЕМьЭ┤ы╕Ф эШХэГЬьЭШ data type ьЮЕыЛИыЛд . эЕМьЭ┤ы╕Ф
ьЭШ column ь▓ШыЯ╝ ьЧмыЯм ъ░ЬьЭШ эХДыУЬыбЬ ъ╡мьД▒ыРШьЦ┤ ьЮИъ│а , PL/SQL ы╕ФыбЭьЧРьДЬ ьЮДьЛЬыбЬ ьВмьЪйэХа ьИШ ьЮИыКФ data type ьЭШ эХШыВШ
ыЭ╝ъ│а эХа ьИШ ьЮИьК╡ыЛИыЛд . Collection ьЧР эХ┤ыЛ╣эХШыКФ Varray, Nested table, Associative array ыКФ ыкиыСР эФДыбЬъ╖╕ыЮШ
ы░Н ьЦ╕ьЦ┤ьЧРьДЬ ьВмьЪйэХШыКФ ы░░ьЧ┤ эШХэГЬьЭШ ъ╡мьб░ые╝ ъ░АьзСыЛИыЛд . ьжЙ ьЭ┤ыУдьЭД ъ╡мьД▒эХШыКФ ьЪФьЖМыУдьЭШ ыН░ьЭ┤эД░ эГАьЮЕьЭА ыкиыСР ъ░ЩьХД
ьХ╝ эХйыЛИыЛд . ы░Шый┤ эЕМьЭ┤ы╕ФьЭШ column ыУдьЭ┤ ьДЬыбЬ ыЛдые╕ ьЬаэШХьЭШ data type ьЬ╝ыбЬ ъ╡мьД▒ыРШыУпьЭ┤ Record ьЧньЛЬ эХ┤ыЛ╣
field(Record ьЧРьДЬыКФ element ыЮА ызР ыМАьЛа field ыЮА ьЪйьЦ┤ые╝ ьВмьЪй ) ыУдьЭ┤ ъ░Бъ╕░ ыЛдые╕ data type ьЭД ъ░АьзИ ьИШ ьЮИьК╡
ыЛИыЛд . эФДыбЬъ╖╕ыЮШы░Н ьЦ╕ьЦ┤ьЩА ы╣Дъ╡РэХШый┤ Record ыКФ Structure( ъ╡мьб░ь▓┤ ) ьЧР эХ┤ыЛ╣эХЬыЛдъ│а ы│╝ ьИШ ьЮИьК╡ыЛИыЛд .
Record ъ░А эЕМьЭ┤ы╕Ф эШХэГЬьЭШ ъ╡мьб░ые╝ ъ░АьзАъ│а ьЮИьЬ╝ыпАыбЬ , ьЛдьаЬ ыМАы╢Аы╢ДьЭШ ъ▓╜ьЪ░ эЕМьЭ┤ы╕ФьЭШ ыН░ьЭ┤эД░ые╝ ьЭ╜ьЦ┤ьШдъ▒░ыВШ ьб░ьЮСэХШ
ъ╕░ ьЬДэХ┤ PL/SQL ы╕ФыЮЩ ыВ┤ьЧРьДЬ ьЮДьЛЬьаБьЭ╕ data ьаАьЮеьЖМ ьЧнэХаьЭД ьИШэЦЙэХйыЛИыЛд . Record ьЧньЛЬ Collection ь▓ШыЯ╝
TYPE ьЭД ьВмьЪйэХШьЧм ьДаьЦ╕эХа ьИШ ьЮИьК╡ыЛИыЛд .
тАУ [ TYPE ьЭД ьВмьЪйэХЬ ъ╡мым╕эШХьЛЭ ]
TYPE ыаИь╜ФыУЬьЭ┤ыжД IS RECORD ( эХДыУЬ 1 ыН░ьЭ┤эД░эГАьЮЕ 1, эХДыУЬ 2 ыН░ьЭ┤эД░эГАьЮЕ 2, тАж);
тАУ [ эЕМьЭ┤ы╕ФыкЕьЭД ьВмьЪйэХЬ ъ╡мым╕эШХьЛЭ ]
ыаИь╜ФыУЬьЭ┤ыжД эЕМьЭ┤ы╕ФыкЕ %ROWTYPE;
тАУ [ ь╗дьДЬыкЕьЭД ьВмьЪйэХЬ ъ╡мым╕эШХьЛЭ ]
ыаИь╜ФыУЬьЭ┤ыжД ь╗дьДЬыкЕ %ROWTYPE;](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-22-320.jpg)


![25
Performing SQL Operations from PL/SQL
яБ╡ Overview of Implicit Cursor Attributes( ым╡ьЛЬьаБ ь╗дьДЬ ьЖНьД▒ыУд )
тАв %FOUND : ъ░АьЮе ь╡Ьъ╖╝ьЧР ьЭ╕ь╢ЬэХЬ эЦЙьЭ┤ ьЮИьЬ╝ый┤ TRUE
тАв %ISOPEN : ь╗дьДЬъ░А ьЧ┤ыадьЮИьЬ╝ый┤ TRUE
тАв %NOTFOUND : ъ░АьЮе ь╡Ьъ╖╝ьЧР ьЭ╕ь╢ЬэХЬ эЦЙьЭ┤ ьЧЖьЬ╝ый┤ TRUE
тАв %ROWCOUNT : ъ░АьЮе ь╡Ьъ╖╝ьЧР ьЭ╕ь╢ЬэХЬ эЦЙьЭШ ъ░ЬьИШ
яБ╡ Overview of Explicit Cursor
Explicit Cursor( ыкЕьЛЬьаБ ь╗дьДЬ ) ыЮА ьВмьЪйьЮРъ░А ьзБьаС ь┐╝ыжмьЭШ ъ▓░ъ│╝ьЧР ьаСъ╖╝эХ┤ьДЬ ьЭ┤ые╝ ьВмьЪйэХШъ╕░ ьЬДэХ┤ ыкЕьЛЬьаБьЬ╝
ыбЬ ьДаьЦ╕эХЬ ь╗дьДЬые╝ ызРэХйыЛИыЛд . ьЭ╝ы░ШьаБьЬ╝ыбЬ ь╗дьДЬые╝ ьВмьЪйэХЬыЛдъ│а эХШый┤ ыкЕьЛЬьаБ ь╗дьДЬые╝ ьВмьЪйэХШыКФ ъ▓ГьЮЕыЛИыЛд . ыЛд
ьЭМьЭА ыкЕьЛЬьаБ ь╗дьДЬые╝ ьВмьЪйэХШъ╕░ ьЬДэХЬ ьаИь░и ьЮЕыЛИыЛд .
тАУ ь╗дьДЬ ьДаьЦ╕ : ь╗дьДЬьЧР ьЭ┤ыжДьЭД ьг╝ъ│а , ьЭ┤ ь╗дьДЬъ░А ьаСъ╖╝эХШыадыКФ ь┐╝ыжмые╝ ьаХьЭШэХйыЛИыЛд .
[ CURSOR ь╗дьДЬыкЕ IS SELECT ым╕ьЮе ; ]
тАУ ь╗дьДЬ ьЧ┤ъ╕░ (Open) : ь╗дьДЬыбЬ ьаХьЭШыРЬ ь┐╝ыжмые╝ ьЛдэЦЙэХШыКФ ьЧнэХаьЭД эХйыЛИыЛд .
[ OPEN ь╗дьДЬыкЕ ; ]
тАУ эМиь╣Ш (Fetch) : ь┐╝ыжмьЭШ ъ▓░ъ│╝ьЧР ьаСъ╖╝эХйыЛИыЛд . ы│┤эЖ╡ ь┐╝ыжмыКФ эХЬ ъ░Ь ьЭ┤ьГБьЭШ ъ▓░ъ│╝ые╝ ы░ШэЩШэХШыпАыбЬ
Loop ые╝ ыПМый░ ъ░Ьы│Д ъ░ТыУдьЧР ьаСъ╖╝эХ┤ьДЬ ьЮДьЭШьЭШ ь▓Шыжмые╝ эХШъ▓М ыРйыЛИыЛд .
[ FETCH ь╗дьДЬыкЕ INTO ы│АьИШтАж ; ]
тАУ ь╗дьДЬ ыЛлъ╕░ (Close) : эМиь╣Ш ьЮСьЧЕьЭ┤ ыБЭыВШый┤ ь╗дьДЬ ь▓Шыжмые╝ ыБЭыВ┤ъ│а ыйФыкиыжмьГБьЧР ьб┤ьЮмэХШыКФ ь┐╝ыжмьЭШ ъ▓░
ъ│╝ые╝ ьЖМый╕ьЛЬэВ╡ыЛИыЛд .
[ CLOSE ь╗дьДЬыкЕ ; ]](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-25-320.jpg)


![28
Using PL/SQL Subprograms
яБ╢ What Are Subprograms?
PL/SQL Subprogram ьЭА parameter ьЩА ъ│аьЬаьЭШ ьЭ┤ыжДьЭД ъ░АьзД PL/SQL Block ьЭД ызРэХШый░ , Database ъ░Эь▓┤ыбЬ ьб┤ьЮмэХйыЛИ
ыЛд . ьжЙ эХДьЪФэХа ыХМызИыЛд эШ╕ь╢ЬэХ┤ьДЬ ьВмьЪйэХа ьИШ ьЮИыЛдыКФ ьЭШып╕ ьЮЕыЛИыЛд . ьЭ┤ыЯмэХЬ Subprogram ьЧРыКФ Stored
Procedure( ыВ┤ьЮе эФДыбЬьЛЬьаА ) ьЩА Function( эХиьИШ ) ъ░А ьЮИьК╡ыЛИыЛд .
Stored Procedure ыКФ ъ╖╕ыГе тАШэФДыбЬьЛЬьаАтАЩыЭ╝ъ│аыПД ы╢Аые┤ый░ Database ьГБьЧРьДЬ ьВмьЪйьЮРъ░А ьзАьаХэХЬ ьЮДьЭШьЭШ ь▓Шыжмые╝ ьИШэЦЙэХШыКФ
ы╕ФыбЭьЭД ызРэХйыЛИыЛд . Function( эХиьИШ ) ыШРыКФ Stored Function ьЭА SQL эХиьИШьЩА ъ░ЩьЭА ьвЕыеШыбЬ , ьВмьЪйьЮРъ░А ьзБьаС ьаХьЭШ
эХ┤ьДЬ ьЮСьД▒эХЬ эХиьИШые╝ ызРэХйыЛИыЛд . ы│┤эЖ╡ PL/SQL ьЧРьДЬ эХиьИШыЭ╝ эХШый┤ ыВ┤ьЮеэХиьИШые╝ ызРэХШый░ ьЭ┤ ыШРэХЬ User Defined
Function( ьВмьЪйьЮР ьаХьЭШ эХиьИШ ) эШ╣ьЭА ъ╖╕ыГе тАШэХиьИШтАЩыЭ╝ъ│аыПД ы╢Иыж╜ыЛИыЛд .
яБ╢ Understanding PL/SQL Functions
SQL ьЧРьДЬ Function( эХиьИШ ) эХШ эХШый┤ ы│┤эЖ╡ Oracle ьЧРьДЬ ьаЬъ│╡эХШыКФ SQL эХиьИШыУдьЭД ызРэХШьзАызМ , PL/SQL ьЧРьДЬ эХиьИШыЭ╝
эХШый┤ User Defined Function( ьВмьЪйьЮР ьаХьЭШ эХиьИШ ) ые╝ ызРэХйыЛИыЛд . ъ╖╕ыаЗыЛдъ│а SQL эХиьИШьЩА ьВмьЪйьЮР ьаХьЭШ эХиьИШьЭШ ьЖН
ьД▒ьЭ┤ыВШ ъ╕░ыКеьЭ┤ ыЛдые╕ ъ▓ГьЭА ьХДыЛИый░ , ыЛдызМ Oracle ьЧРьДЬ ьаЬъ│╡эХШыКФьзА ьХДыЛИый┤ ьВмьЪйьЮРъ░А ьзБьаС ьЮСьД▒эХШыКФьзАьЧР ыФ░ыЭ╝ ъ╡м
ы╢ДыРйыЛИыЛд .
эХиьИШыКФ SQL эХиьИШь▓ШыЯ╝ ьЭ╝ьаХэХЬ ьЧ░ьВ░ьЭД ьИШэЦЙэХЬ ыТд ъ░ТьЭД ы░ШэЩШэХйыЛИыЛд . эХиьИШыКФ Specification( ыкЕьД╕ы╢А ) ьЩА
Body( ъ╡мэШДы╢А ) ыбЬ ыВШыИМ ьИШ ьЮИьЬ╝ый░ , ъ╡мэШДы╢АыКФ Anonymous Block ь▓ШыЯ╝ ьДаьЦ╕ , ьЛдэЦЙ , ьШИьЩ╕ь▓Шыжмы╢АыбЬ ъ╡мьД▒ ыРйыЛИыЛд
.
[ ъ╡мым╕эШХьЛЭ ]
CREATE OR REPLACE FUNCTION эХиьИШыкЕ ( эММыЭ╝ып╕эД░ 1 ыН░ьЭ┤эД░эГАьЮЕ , эММыЭ╝ып╕эД░ 2 ыН░ьЭ┤эД░эГАьЮЕ , тАж)
RETURN ыН░ьЭ┤эД░эГАьЮЕ IS [AS]
ы│АьИШьДаьЦ╕тАж ;
BEGIN
ь▓ШыжмыВ┤ьЪйтАж ;
RETURN ыжмэД┤ъ░Т ;
END;](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-28-320.jpg)
![29
Using PL/SQL Subprograms
тАв CREATE OR REPLACE FUNCTION : VIEW ые╝ ьГЭьД▒эХа ыХМьЩА ъ░ЩьЭ┤ CREATE OR REPLACE ые╝ ьВмьЪйэХ┤ьДЬ ъ╕░ьб┤
ьЧР ьЮСьД▒ыРЬ эХиьИШые╝ ьИШьаХэХа ъ▓╜ьЪ░ , ы│ДыПДыбЬ DROP ьЛЬэВдьзА ьХКьХДыПД ыРйыЛИыЛд .
тАв эХиьИШыкЕ : ьГЭьД▒эХа эХиьИШыкЕьЭД ыкЕьЛЬэХйыЛИыЛд .
тАв эММыЭ╝ып╕эД░ 1 ыН░ьЭ┤эД░эГАьЮЕ , тАж : эХиьИШьЭШ эММыЭ╝ып╕эД░ыбЬ ьШдыКФ эММыЭ╝ып╕эД░ ьЭ┤ыжДъ│╝ ыН░ьЭ┤эД░ эГАьЮЕьЭД ыкЕьЛЬэХйыЛИыЛд .
тАв RETURN : ы░ШэЩШэХа ыН░ьЭ┤эД░ эГАьЮЕьЭД ыкЕьЛЬэХйыЛИыЛд .
тАв BEGIN тАж END : эХиьИШъ░А ь▓ШыжмэХа ыВ┤ьЪйьЭД ыкЕьЛЬэХШый░ , ызи ызИьзАызЙьЧР эХиьИШъ░А ы░ШэЩШэХа ъ░ТьЭД RETURN ыЛдьЭМьЧР
ыкЕьЛЬэХйыЛИыЛд .
яБ╢ Understanding PL/SQL Procedures
Procedure( эФДыбЬьЛЬьаА ) ыКФ эК╣ьаХэХЬ ь▓Шыжмые╝ ьИШэЦЙэХШыКФ PL/SQL Subprogram ьЮЕыЛИыЛд . эХиьИШьЩА ызИь░мъ░АьзАыбЬ эФДыбЬьЛЬьаА
ыКФ Database ьЧР ьаАьЮеыРШьЦ┤ ьЮИыКФ ъ░Эь▓┤ьЭ┤ый░ , ьЭ┤ыЯмэХЬ ьЭ┤ьЬаыбЬ Stored Procedure( ыВ┤ьЮе эФДыбЬьЛЬьаА ) ыЭ╝ъ│аыПД ы╢АыжЕыЛИыЛд
. эФДыбЬьЛЬьаА ьЧньЛЬ эММыЭ╝ып╕эД░ыУдьЭД ы░ЫьХД эК╣ьаХ ь▓Шыжмые╝ ьИШэЦЙэХШъ╕░ыКФ эХШьзАызМ , эХиьИШьЩАыКФ ыЛмыжм ъ░ТьЭД ы░ШэЩШэХШьзА ьХКьК╡ыЛИыЛд
.
[ ъ╡мым╕эШХьЛЭ ]
CREATE OR REPLACE PROCEDURE эФДыбЬьЛЬьаАыкЕ ( эММыЭ╝ып╕эД░ 1 ыН░ьЭ┤эД░эГАьЮЕ [IN | OUT | INOUT], тАж)
IS [AS]
ы│АьИШьДаьЦ╕ы╢АтАж ;
BEGIN
эФДыбЬьЛЬьаА ы│╕ым╕ь▓ШыжмтАж ;
END;
[ ьЛдэЦЙъ╡мым╕эШХьЛЭ ]
EXEC эШ╣ьЭА EXECUTE эФДыбЬьЛЬьаАыкЕ ( эММыЭ╝ып╕эД░тАж );](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-29-320.jpg)

![31
Using PL/SQL Packages
яБ╡ Understanding The Package Specification
Package Specification( эМиэВдьзА ыкЕьД╕ы╢А ) ыКФ эМиэВдьзАьЧРьДЬ ьВмьЪйэХа ьИШ эГАьЮЕъ│╝ ь╗дьДЬ , эХиьИШ , эФДыбЬьЛЬьаАыУдьЭД
ьДаьЦ╕эХйыЛИыЛд .
[ Example ] ьЧРьДЬ ъ╡╡ьЭА ъ╕АьЮРыбЬ эСЬьЛЬыРЬ ы╢Аы╢ДьЭ┤ ы░ФыбЬ эМиэВдьзА ьДаьЦ╕ ым╕ы▓ХьЧР эХ┤ыЛ╣ыРйыЛИыЛд . эМиэВдьзА ьаХьЭШыКФ эХиьИШ
ыВШ эФДыбЬьЛЬьаАьЩА ызИь░мъ░АьзАыбЬ тАШ CREATE OR REPLACE PACKAGEтАЩ ъ╡мым╕ьЭД ьВмьЪйэХйыЛИыЛд .
ъ╖╕ыж╝ 9. Package Scope [ Example ]
CREATE OR REPLACE PACKAGE employee_process AS
-- эГАьЮЕ , ь╗дьДЬ , Exception ьДаьЦ╕
TYPE EmpRecord IS RECORD (emp_id INT, salary
REAL);
TYPE DeptRecord IS RECORD (dept_id INT, loc_id
INT);
-- ьЬДьЧРьДЬ ьДаьЦ╕эХЬ EmpRecord ые╝ ы░ШэЩШэХШыКФ ь╗дьДЬ ьДаьЦ╕
CURSOR salaries RETURN EmpRecord;
-- ъ╕ЙьЧмъ░А ызЮьзА ьХКьЭД ъ▓иьЪ░ ьШИьЩ╕ь▓Шыжмые╝ ьЬДэХЬ exception
ьДаьЦ╕
invalid_salary EXCEPTION;
--
PROCEDURE hire_employee (
first_name VARCHAR2,
last_name VARCHAR2,
тАж );
PROCEDURE fire_employee (emp_id INT);
FUNCTION nth_highest_salary (n INT) RETURN
EmpRecord;
END employee_process;](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-31-320.jpg)
![32
Using PL/SQL Packages
яБ╡ Understanding The Package Body
Package Body( эМиэВдьзА ъ╡мэШДы╢А ) ьЭА ыкЕэВдьзА ыкЕьД╕ы╢АьЧРьДЬ ьДаьЦ╕ыРЬ ъ░Б ь╗дьДЬ ы░П Subprograms ьЭД эПмэХиэХйыЛИыЛд .
эМиэВдьзА ъ╡мэШДы╢АыКФ тАШ CREATE OR REPLACE PACKAGE BODYтАЩ ъ╡мым╕ьЭД ьВмьЪйэХйыЛИыЛд .
[ Example ]
CREATE OR REPLACE PACKAGE BODY employee_process AS
-- ьЭ┤ ы│АьИШыКФ ъ╡мэШДы╢АьЧР ьДаьЦ╕ыРШьЧИьЬ╝ыпАыбЬ PRIVATE ьЖНьД▒ьЭД ъ░АьзСыЛИыЛд .
number_hired INT;
-- ыкЕьД╕ы╢АьЧРьДЬ ьДаьЦ╕эХЬ ь╗дьДЬые╝ ьаХьЭШэХйыЛИыЛд .
CURSOR salaries RETURN EmpRecord IS
SELECT employee_id, salary
FROM employees
ORDER BY salary DESC;
-- ьЛаъ╖ЬьВмьЫРьЭД ыУ▒ыбЭэХйыЛИыЛд .
PROCEDURE hire_employee (
first_name VARCHAR2,
last_name VARCHAR2,
тАж ) IS
new_employee_id
BEGIN
-- ьЛаъ╖ЬьВмьЫР ыУ▒ыбЭьЭД ьЬДэХЬ , employee_id ъ░ТьЭШ ьЛЬэААьКд ы▓ИэШ╕ые╝ ъ░Аьа╕ьШ┤
SELECT employee_seq.NEXTVAL
INTO new_employee_id
FROM dual;
яГи ъ│ДьЖН](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-32-320.jpg)

![34
Handling PL/SQL Errors
яБ╢ Overview of PL/SQL Runtime Error Handling
PL/SQL ьЧРьДЬ Error ьГБэЩйьЭД ьб░ьаИэХШыКФ ъ▓ГьЭД Exception ьЭ┤ыЭ╝ъ│а ы╢АыжЕыЛИыЛд . Exceptions ьЭА ыВ┤ы╢АьаБьЬ╝ыбЬ ьаХьЭШ
(System Runtime ьЧР ьЭШэХ┤ьДЬ ) эХШъ▒░ыВШ ьВмьЪйьЮРъ░А ьаХьЭШэХйыЛИыЛд .
Exception ьЭД ь▓ШыжмэХШыКФ ы╢Аы╢ДьЭД ьШИьЩ╕ь▓Шыжмы╢АыЭ╝ъ│аыПД ы╢Аые┤ыКФыН░ , ьШИьЩ╕ь▓Шыжмы╢АыКФ BEGIN( ьЛдэЦЙы╢А ) ьЧРьДЬ ыбЬьзБьЭД ь▓ШыжмэХШ
ыНШ ьдС ы░ЬьГЭэХа ьИШ ьЮИыКФ ъ░БьвЕ ьШдыеШыУдьЧР ыМАэХ┤ ь▓ШыжмэХШыКФ ы╢Аы╢ДьЮЕыЛИыЛд . ьжЙ , Oracle ьЧРьДЬ SQL ым╕ьЮеьЭД ьЛдэЦЙ ьЛЬ ьШдыеШ
ъ░А ы░ЬьГЭэХШъ▓М ыРШый┤ ьЮРыПЩьЬ╝ыбЬ ORA-XXXX ьШдыеШ ы▓ИэШ╕ьЩА эХиъ╗Ш ыйФьЛЬьзАъ░А ы░ШэЩШыРШыКФыН░ , ьВмьЪйьЮРъ░А ьзБьаС ьЭ┤ыЯмэХЬ ыйФьЛЬьзА
ые╝ ыМАь▓┤эХШъ▒░ыВШ ьШдыеШъ░А ы░ЬьГЭэХа ъ▓╜ьЪ░ ь▓ШыжмэХа ыбЬьзБьЭД ъ╕░ьИаэХа ы╢Аы╢ДьЮЕыЛИыЛд . JAVA ьЩА ъ░ЩьЭА эФДыбЬъ╖╕ыЮШы░Н ьЦ╕ьЦ┤ьЭШ TRY
тАж CATCH ым╕ьЧРьДЬ CATCH ьЧР эХ┤ыЛ╣ыРШыКФ ы╢Аы╢ДьЮЕыЛИыЛд .
[ Example ]
DECLARE
counter INTEGER;
BEGIN
counter := 10;
counter := counter / 0;
dbms_output.put_line(counter);
EXCEPTION WHEN OTHERS THEN
dbms_output.put_line(тАШERRORSтАЩ);
END;
ьЬДьЭШ [ Example ] ьЭА counter ыЭ╝ыКФ ы│АьИШые╝ 0 ьЬ╝ыбЬ ыВШыИДыадъ│а ьЛЬыПДэХШьШАьЭД ъ▓╜ьЪ░ ы░ЬьГЭэХШыКФ ьЧРыЯмьЧР ыМАэХ┤ ьШдыеШь▓Шыжм
ые╝ эХШыКФ ъ▓ГьЮЕыЛИыЛд . ьЬДьЭШ ьШИьЩ╕ь▓Шыжмы╢А (EXCEPTION~) ыКФ ьГЭыЮ╡ьЭ┤ ъ░АыКеэХйыЛИыЛд .
* ьЬДьЭШ OTHERS ыЭ╝ыКФ эВдьЫМыУЬыКФ PL/SQL ьЭД ьЮСьД▒эХШыКФ ьВмьЪйьЮРъ░А ыкЕьЛЬэХЬ ъ▓╗ ьЭ┤ьЩ╕ьЭШ ыкиыУа ьШдыеШые╝ ьЮбьХДыВ┤ыКФ ы╢Аы╢ДьЭ┤ыЭ╝
ъ│а ьГЭъ░БэХШьЛЬый┤ ыРйыЛИыЛд .](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-34-320.jpg)
![35
Handling PL/SQL Errors
яБ╢ Advantages of PL/SQL Exceptions
Exceptions ьЭД ьЭ┤ьЪйэХШый┤ ьЧмыЯм SQL ъ╡мым╕ьЧРьДЬ ы░ЬьГЭэХШыКФ ьЮаьЮмьаБьЭ╕ Error ьЧР ыЛиьзА PL/SQL Exception Handler
Block ьЧР ь╢Фъ░АэХШыКФ ъ▓Г ызМьЬ╝ыбЬ ыМАь▓ШэХа ьИШ ьЮИьК╡ыЛИыЛд .
ьВмьЪйьЮРъ░А ьШдыеШые╝ ь▓ШыжмэЦИыЛдый┤ ы░ЬьГЭ ъ░АыКеэХЬ ьШдыеШые╝ ъ░РьХИэХШьЧм эФДыбЬъ╖╕ыЮШы░НьЭД эХЬ ъ▓ГьЭ┤ыЭ╝ ы│╝ ьИШ ьЮИьК╡ыЛИыЛд . ьжЙ ы░ЬьГЭ
ъ░АыКеэХЬ ыкиыУа ъ▓╜ьЪ░ьЭШ ьИШые╝ ъ░РьХИэХШьЧм ыбЬьзБьЧР ьЭ┤ые╝ ьЛмьЦ┤ ыЖУьЭА ъ▓ГьЮЕыЛИыЛд . ьШИые╝ ыУдьЦ┤ Overview ьЭШ [ Example ] ъ│╝
ъ░ЩьЭ┤ 0 ьЬ╝ыбЬ ыВШыИЧьЕИьЭД ьИШэЦЙэХШъ▓М ыРШьЧИьЭД ъ▓╜ьЪ░ , ьВмьЪйьЮРъ░А ьЭ┤ыЯмэХЬ ъ▓╜ьЪ░ые╝ ып╕ыжм ьГЭъ░БэЦИыЛдый┤ ьШдыеШ ыйФьЛЬьзАые╝ ы│┤ьЧмьг╝
ьзА ьХКъ│а 0 ыМАьЛа ыЛдые╕ ъ░ТьЬ╝ыбЬ ыВШыИДыПДыбЭ ь▓ШыжмэХа ьИШыПД ьЮИьК╡ыЛИыЛд . ъ╖╕ыжмъ│а ъ╖╕ ыЛдьЭМ ыбЬьзБьЭД ь▓ШыжмэХа ьИШъ░А ьЮИыКФ ъ▓ГьЮЕ
ыЛИыЛд . эХШьзАызМ Oracle PL/SQL ьЧФьзДьЧРьДЬ ь▓ШыжмэХШьЧм ыйФьЛЬьзАые╝ ы│┤ьЧмьг╝ъ▓М ыРа ъ▓╜ьЪ░ьЧРыКФ ьШдыеШъ░А ы░ЬьГЭэХЬ ьЛЬьаРьЧРьДЬ ь▓Ш
ыжмъ░А ьдСыЛиыРШый░ , ъ╖╕ ыЛдьЭМ ыбЬьзБьЭА ь▓ШыжмэХа ьИШъ░А ьЧЖьК╡ыЛИыЛд . Oracle ьЭД ьВмьЪйэХШыКФ Application ьЭШ ьвЕыеШьЧР ыФ░ыЭ╝ьДЬ
PL/SQL ьЧФьзДьЭ┤ ьШдыеШь▓Шыжмые╝ эХа ъ▓╜ьЪ░ Application ьЭ┤ ыЛдьЪ┤ыРа ьИШыПД ьЮИьзАызМ ьВмьЪйьЮРъ░А ьЭ┤ыЯмэХЬ ьШдыеШые╝ ьЮбьХДыВ╕ыЛдый┤
эФДыбЬъ╖╕ыЮиьЭ┤ ыЛдьЪ┤ыРШыКФ эШДьГБъ╣МьзАыКФ ызЙьЭД ьИШ ьЮИыКФ ъ▓ГьЮЕыЛИыЛд .
яБ╢ Tips for Handling PL/SQL Errors
[ Example1 ]
DECLARE
pe_ratio NUMBER(3, 1);
BEGIN
DELETE FROM stats WHERE symbol = тАШXYZтАЩ;
SELECT price / NVL(earning, 0) INTO pe_ratio FROM
stocks
WHERE symbol = тАШXYZтАЩ;
INSERT INTO stats (symbol, ratio) VALUES (тАШXYZтАЩ,
pe_ratio);
EXCEPTION
WHEN ZERO_DIVIDE THEN
NULL;
END;](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-35-320.jpg)
![36
Handling PL/SQL Errors
[ Example ] ьЭШ Exception ьЭД эЪиъ│╝ьаБьЬ╝ыбЬ ь▓ШыжмэХа ьИШ ьЮИъ▓М ьЖМьКд эШХэГЬые╝ ьб░ъ╕И ы░Фъ╛╕ьЦ┤ы│┤ый┤ ыЛдьЭМъ│╝ ъ░ЩьК╡ыЛИыЛд .
ыЛдьЭМьЭШ [ Example2 ] ыКФ Exception ъ│╝ SAVEPOINT ьЭШ ьб░эХйьЭД ьЭ┤ьЪйэХЬ ьЖМьКд ь╜ФыУЬьЮЕыЛИыЛд .
[ Better Example1 ]
DECLARE
pe_ratio NUMBER(3, 1);
BEGIN
DELETE FROM stats WHERE symbol = тАШXYZтАЩ;
BEGIN ---------------- sub-block begins
SELECT price / NVL(earnings, 0) INTO pe_ratio FROM
stocks
WHERE symbol = тАШXYZтАЩ;
EXCEPTION
WHEN ZERO_DIVIDE THEN
pe_ratio := 0;
END; ---------------- sub-block ends
INSERT INTO stats (symbols, ratio) VALUES (тАШXYZтАЩ, pe_ratio);
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
[ Example2 ]
DECLARE
name VARCHAR2(20);
тАж
suffix NUMBER := 1;
яГи ъ│ДьЖН](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-36-320.jpg)

![38
Thought
яБ╢ #1. Which Better Good Between Only SQL and PL/SQL
тА╗ ыЛдьЭМьЭШ ыВ┤ьЪйьЭА Naver ы░П Google ыУ▒ьЭШ ъ▓АьГЙьЭД эЖ╡эХ┤ьДЬ ьИШьзСэХЬ ыВ┤ьЪйьЮЕыЛИыЛд .
яБ╡ Better Good Situation in Only SQL
PL/SQL ьЭА ьВмьЛд Cursor( ь╗дьДЬ ) эФДыбЬъ╖╕ыЮШы░НьЮЕыЛИыЛд . ь╗дьДЬые╝ ьЭ┤ьЪйэХШый┤ ьЙ╜ъ│а эО╕ыжмэХШъ▓М data ые╝ ьб░ьЮСэХШъ▒░ыВШ
ьЦ╗ьЭД ьИШ ьЮИьК╡ыЛИыЛд . эХШьзАызМ , Database ьЭШ ьД▒ыКе ьаАэХШьЭШ ьг╝ы▓ФьЭ┤ ы░ФыбЬ Cursor ьЮЕыЛИыЛд . ъ╖╕ ьЭ┤ьЬаыКФ Cursor
ыЭ╝ыКФ ъ▓ГьЭ┤ ьИЬь░иьаБьЭ╕ ьЖНьД▒ьЭД ъ░АьзАъ╕░ ыХМым╕ьЮЕыЛИыЛд . Database ъ░А ьЫРыЮШы╢АэД░ ыЛдыЯЙьЭШ data ые╝ эХЬъ║╝ы▓ИьЧР ь▓ШыжмэХШ
ыКФ ьзСэХйьаБьЭ╕ ьЖНьД▒ьЭД ъ░АьзАъ│а ьЮИъ╕░ ыХМым╕ьЧР Cursor ьЩА Database ыКФ ъ╢БэХйьЭ┤ ьЮШ ызЮьзА ьХКьК╡ыЛИыЛд . ы╣ДыФФьШдъ░Аъ▓М
ьЧРьДЬ ьаДь▓┤эЪМьЫР ьдС ы╣ДыФФьШдые╝ ыСР ы▓И ьЭ┤ьГБ ы╣Мыадъ░Д эЪМьЫРьЭД ъ╡мэХШыКФ ьШИьаЬыбЬ ыУдьЦ┤ы│┤ъ▓аьК╡ыЛИыЛд .
[ PL/SQL ьЭД ьЭ┤ьЪй ьЛЬ ьЮРьг╝ ьВмьЪйэХШъ▓М ыРШыКФ ьКдэГАьЭ╝ ]
DECLARE ы│АьИШ
LOOP
эЪМьЫРьЭ┤ ы╣Мыж░ ы╣ДыФФьШд ъ░ЬьИШ ь╢ФьаБ ;
IF эЪМьЫРьЭ┤ ы╣Мыж░ ы╣ДыФФьШд ьИШ >=2 THEN
тАж.
END IF;
END LOOP;
END;
ьЭ┤ыЯ░ эШХэГЬыбЬ PL/SQL ьЭД ъ╡мьД▒эХШъ▓М ыРШый┤ Database ыКФ ьаДь▓┤ ыМАьЧм эЪЯьИШызМэБ╝ ыгиэФДые╝ ыПМыжмъ▓М ыРйыЛИыЛд . ьЭ┤ыЯмэХЬ
ы░йьЛЭьЭА ьИЬь░иьаБьЭ╕ ы░йьЛЭьЬ╝ыбЬ ъ╡мэШДьЭД эХЬ эШХэГЬьЮЕыЛИыЛд .
яГи ъ│ДьЖН](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-38-320.jpg)
![39
Thought
эХШьзАызМ , ьЭ┤ъ▓ГьЭД SQL ьЭД ьЭ┤ьЪйэХШьЧм ьзСэХйьаБьЭ╕ ы░йьЛЭьЬ╝ыбЬ ъ╡мэШДэХ┤ ы│┤ый┤ Database ыКФ ыФ▒ ыСР ы▓ИьЭШ ьЛдэЦЙызМьЬ╝ыбЬ
ъ▓░ъ│╝ые╝ ыВ╝ ьИШ ьЮИъ▓М ыРйыЛИыЛд . ыЛдьЭМьЭ┤ эЫиьФм Database ьЧР ьаБэХйэХЬ ъ╡мьб░ые╝ ьзАыЛМ ы░йьЛЭьЮЕыЛИыЛд .
[ SQL ызМьЭД ьЭ┤ьЪйэХШьЧм ыШСъ░ЩьЭА ъ▓░ъ│╝ые╝ ь╢ЬыаеэХШыКФ ъ╡мым╕ ]
SELECT эЪМьЫРьЭ┤ыжД
FROM ы╣ДыФФьШд ыМАьЧм
MINUS
SELECT DISTINCT эЪМьЫРьЭ┤ыжД
FROM ы╣ДыФФьШдыМАьЧм
яБ╡ Better Good Situation in PL/SQL
Application ъ│╝ Database ьГБьЧРьДЬыКФ ызОьЭА Network Traffic ьЭ┤ ы░ЬьГЭэХйыЛИыЛд . ьШИые╝ ыУдьЦ┤ ьЧмыЯм ъ░ЬьЭШ
SELECT, INSERT, DELETE ым╕ьЭД ы│┤ыВ┤ыадый┤ Only SQL ьЭА эХЬы▓ИьЧР эХШыВШьЭШ SQL ызМьЭД ы│┤ыВ┤ьХ╝ эХйыЛИыЛд .
[ SQL Example ]
SELECT * FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ ъ╣АэГЬьЪ░тАЩ ;
INSERT INTO эХЩьаБы╢А ( ьЭ┤ыжД , ьД▒ы│Д , .. ) VALUES ( ъ╣АэГЬэЭм , ьЧм , .. );
DELETE FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ эЩНъ╕╕ыПЩ ;
яГи ъ│ДьЖН](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-39-320.jpg)
![40
Thought
эХШьзАызМ , ыЛдьЭМьЭШ PL/SQL ьЭД ьВмьЪйэХШъ▓М ыРШый┤ Application ъ│╝ Database ыКФ ыЛи эХЬы▓ИьЭШ Connection ызМьЬ╝ыбЬыПД
ьЧмыЯм ъ░ЬьЭШ SQL ым╕ьЭД ыПЩьЛЬьЧР ы│┤ыВ╝ ьИШ ьЮИьК╡ыЛИыЛд .
[ PL/SQL Example ]
DECLARE
BEGIN
SELECT * FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ ъ╣АэГЬьЪ░тАЩ ;
INSERT INTO эХЩьаБы╢А ( ьЭ┤ыжД , ьД▒ы│Д , .. ) VALUES ( ъ╣АэГЬэЭм , ьЧм , .. );
DELETE FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ эЩНъ╕╕ыПЩ ;
COMMIT;
END;
ьЭ┤ыЯмэХЬ ъ▓╜ьЪ░ьЧРьДЬыКФ PL/SQL ьЭ┤ Only SQL ьЭД ьВмьЪйэХШыКФ ъ▓Гы│┤ыЛд эЫиьФм Network Traffic ьЧР ы╢АыЛ┤ьЭД ьг╝ьзА ьХКъ│а
SQL ьЭД ьЛдэЦЙ ьЛЬэВм ьИШ ьЮИьК╡ыЛИыЛд .](https://image.slidesharecdn.com/26a90514-15e1-42e8-816c-042fcb643ef9-141204203826-conversion-gate01/85/PL-SQL-10g-Release1-40-320.jpg)



PL/SQL - 10g Release1
- 1. PL/SQL (Procedural Language / Structured Query Language) 10g Release 1
- 2. ыкйь░иыкйь░и яГо Overview of PL/SQLOverview of PL/SQL яГо Fundamentals of the PL/SQL LanguageFundamentals of the PL/SQL Language яГо PL/SQL DatatypesPL/SQL Datatypes яГо Using PL/SQL Control StructureUsing PL/SQL Control Structure яГо Using PL/SQL Collections and RecordsUsing PL/SQL Collections and Records яГо Performing SQL Operations from PL/SQLPerforming SQL Operations from PL/SQL яГо Using PL/SQL SubprogramsUsing PL/SQL Subprograms яГо Using PL/SQL PackageUsing PL/SQL Package яГо Handling PL/SQL ErrorsHandling PL/SQL Errors яГо ThoughtThought
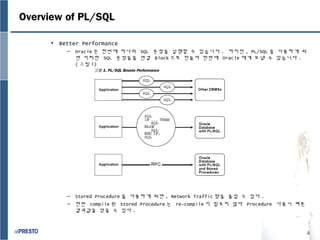
- 3. 3 Overview of PL/SQL яБ╢ Advantage of PL/SQL яБ╡ PL/SQL ьЭА ъ│аьД▒ыКе Transaction Processing ьЦ╕ьЦ┤ыбЬьДЬ ыЛдьЭМъ│╝ ъ░ЩьЭА ьЮеьаРьЭД ьаЬъ│╡ эХШъ│а ьЮИьК╡ыЛИыЛд . тАУ SQL ьЭД ьзАьЫРэХйыЛИыЛд . (Support for SQL) тАУ ъ░Эь▓┤ьзАэЦе эФДыбЬъ╖╕ыЮШы░НьЭД ьзАьЫРэХйыЛИыЛд . (Support for object-oriented programming) тАУ SQL ызМьЭД ьВмьЪйьЛЬы│┤ыЛд ыНФ ыВШьЭА ьД▒ыКеьЭД ьаЬъ│╡эХйыЛИыЛд . (Better performance) тАУ ыЖТьЭА ьГЭьВ░ьД▒ьЭД ьаЬъ│╡эХйыЛИыЛд . (Higher productivity) тАУ ьЦ┤ыФФьЧРьДЬыВШ ьВмьЪйьЭ┤ ъ░АыКеэХйыЛИыЛд . (Full portability) тАУ Oracle ъ│╝ьЭШ ьЬ╡эЩФыПДъ░А ыЖТьК╡ыЛИыЛд . (Tight integration with Oracle) тАУ ы│┤ьХИьД▒ьЭ┤ ыЖТьК╡ыЛИыЛд . (Tight security) тАв Tight Integration with Oracle тАУ PL/SQL ьЭА SQL ъ│╝ьЭШ ьЬ╡эЩФъ░А ьЮШ ыРШьЦ┤ьзАыКФ ьЦ╕ьЦ┤ьЮЕыЛИыЛд . SQL ъ│╝ PL/SQL ьВмьЭ┤ьЧРьДЬыКФ datatype ьЭД ы│АэЩШ ьЛЬь╝ЬьдД эХДьЪФъ░А ьЧЖьК╡ыЛИыЛд . тАУ ьЭ╝ьЭ╝ьЭ┤ Table Columns ъ│╝ Rows ьЭШ datatype ьЭД ьХМъ│а ьЮИьЭД эХДьЪФъ░А ьЧЖьК╡ыЛИыЛд . тАв Support for SQL тАУ SQL ьЭ┤ Database ьЦ╕ьЦ┤ьЭШ эСЬьдАьЭ┤ ыРа ьИШ ьЮИьЧИыНШ ъ▓ГьЭА SQL ьЭ┤ ьЬаьЧ░эХШъ│а , ъ░ХыаеэХШъ│а , ы░░ьЪ░ъ╕░ ьЙ╜ ъ╕░ ыХМым╕ьЮЕыЛИыЛд . PL/SQL ьЭА ьЭ┤ыЯмэХЬ SQL ьЭД ьЭ┤ьЪйэХШьЧм Database ьХИьЭШ data ыУдьЭД ыЛдыг░ ьИШ ьЮИьК╡ыЛИ ыЛд . тАУ SQL ьЭД ьЭ┤ьЪйэХЬ data ьб░ьЮС , cursor ьаЬьЦ┤ , transaction ьаЬьЦ┤ ыкЕыа╣ , ьЭ┤ы┐РызМ ьХДыЛИыЭ╝ SQL эХи ьИШ , ьЧ░ьВ░ьЮР , pseudocolumns( ъ░АьзЬь╗мыЯ╝ ) ьЭД ьВмьЪйэХа ьИШ ьЮИьК╡ыЛИыЛд .
- 4. 4 Overview of PL/SQL тАв Better Performance тАУ Oracle ьЭА эХЬы▓ИьЧР эХШыВШьЭШ SQL ым╕ьЮеьЭД ьЛдэЦЙэХа ьИШ ьЮИьК╡ыЛИыЛд . эХШьзАызМ , PL/SQL ьЭД ьВмьЪйэХШъ▓М ыРШ ый┤ ьЭ┤ыЯмэХЬ SQL ым╕ьЮеыУдьЭД ьЧ░ъ▓░ Block ьЬ╝ыбЬ ызМыУдьЦ┤ эХЬы▓ИьЧР Oracle ьЧРъ▓М ы│┤ыВ╝ ьИШ ьЮИьК╡ыЛИыЛд . ( ъ╖╕ыж╝ 1) тАУ Stored Procedure ьЭД ьВмьЪйэХШъ▓М ыРШый┤ , Network Traffic ыЯЙьЭД ьдДьЭ╝ ьИШ ьЮИыЛд . тАУ эХЬы▓И compile ыРЬ Stored Procedure ыКФ re-compile ьЭ┤ эХДьЪФь╣Ш ьХКьХД Procedure ьВмьЪйьЛЬ ы╣аые╕ ъ▓░ъ│╝ъ░ТьЭД ьЦ╗ьЭД ьИШ ьЮИыЛд . ъ╖╕ыж╝ 1. PL/SQL Boosts Performance
- 5. 5 Overview of PL/SQL тАв Full Portability тАУ Application ьЧРьДЬ ьЮСьД▒ыРЬ PL/SQL ьЭА Oracle Database ъ░А ъ╡мыПЩыРШьЦ┤ьзАыКФ ьЦ┤ыЦаэХЬ ьЪ┤ьШБь▓┤ьаЬыВШ эФМ ыЮлэП╝ьЧРьДЬыПД ьВмьЪйьЭ┤ ъ░АыКеэХйыЛИыЛд . яБ╢ PL/SQL Architecture Oralce ьДаэЦЙ Compiler ьЧРьДЬ PL/SQL Block ьЭД ьаЬь╢ЬэХШый┤ Oracle Server ыВ┤ьЭШ PL/SQL ьЧФьзДьЭ┤ ьЭ┤ые╝ ь▓ШыжмэХйыЛИыЛд . PL/SQL ьЧФьзДьЭА Block ыВ┤ьЭШ SQL ъ│╝ procedural ьЭД ы╢Дыжм эХШьЧм SQL ьЭД Oracle Server ыВ┤ьЭШ SQL Statement Executor ьЧР ы│┤ыВ┤ъ│а , procedural ьЭД PL/SQL ьЧФьзДыВ┤ьЭШ Procedural Statement Executor ьЧРъ▓М ы│┤ыГЕыЛИыЛд . ъ╖╕ эЫД PL/SQL ьЧФьзДьЭА SQL Statement Executor ыбЬы╢АэД░ ь▓ШыжмыРШьЦ┤ьзД SQL ъ▓░ъ│╝ъ░ТьЭД ы░ЫьХДьДЬ ь╡ЬьвЕъ▓░ъ│╝ые╝ ы│┤ьЧмьдНыЛИыЛд . ъ╖╕ыж╝ 2. PL/SQL ь▓Шыжмъ│╝ьаХ
- 6. 6 Fundamentals of the PL/SQL Language яБ╢ Character Set яБ╡ PL/SQL ьЧРьДЬыКФ ыЛдьЭМъ│╝ ъ░ЩьЭА ым╕ьЮР ы░П эК╣ьИШым╕ьЮР ыУдьЭД ьВмьЪйэХа ьИШ ьЮИьК╡ыЛИыЛд . тАУ A .. Z ьЩА a .. z тАУ ьИльЮР 0 .. 9 тАУ ьЛмы│╝ : ( ) + _ * / < > = ! ~ ^ ; : . тАЩ @ % , тАЭ # $ & _ | { } ? [ ] тАУ Tabs, Spaces, Carriage returns тАв PL/SQL ьЧРьДЬыКФ ыМАьЖМым╕ьЮРые╝ ъ╡мы╢ДэХШьзА ьХКьК╡ыЛИыЛд . яБ╢ Lexical Units яБ╡ Delimiters Symbol Meaning Symbol Meaning Symbol Meaning + addition operator * multiplication operator => association operator % attribute indicator тАЬ quoted identifier delimiter || concatenation operator тАШ character string delimiter = relational operator ** exponentiation operator . component selector < relational operator << label delimiter (begin) / division operator > relational operator >> label delimiter (end) ( expression or list delimiter @ remote access indicator <> relational operator ) expression or list delimiter ; statement terminator != relational operator : host variable indicator - subtraction/negation operator ~= relational operator , item separator := assignment operator ^= relational operator
- 7. 7 Fundamentals of the PL/SQL Language яБ╡ Identifiers тАв PL/SQL ыВ┤ьЭШ constants, exceptions, cursors, subprograms, package ыШРыКФ ы│АьИШыкЕ , ь╗дьДЬыкЕьЬ╝ыбЬ ьЛЭы│ДэХа ьИШ ьЮИъ│а ьВмьЪй ъ░АыКеэХЬ эШХэГЬьЮЕыЛИыЛд . тАУ phone2 тАУ credit_limit тАУ LastName тАУ oracle$number тАв ьЛЭы│ДэХа ьИШ ьЧЖъ│а ьВмьЪйьЭ┤ ы╢Иъ░АыКеэХЬ эШХэГЬьЮЕыЛИыЛд . тАУ mine&yours -- тАШ&тАЩ ъ╕░эШ╕ эЧИьЪйэХШьзА ьХКьЭМ тАУ debit-amount -- тАШ-тАЩ ъ╕░эШ╕ эЧИьЪйэХШьзА ьХКьЭМ тАУ on/off -- тАШ/тАЩ ъ╕░эШ╕ эЧИьЪйэХШьзА ьХКьЭМ тАУ user id -- ъ│╡ы░▒ эЧИьЪйэХШьзА ьХКьЭМ тАв ыЛдьЭМьЭА ъ░ЩьЭА ьЭШып╕ ьЮЕыЛИыЛд . ( ыМАьЖМым╕ьЮРые╝ ъ╡мы╢ДэХШьзА ьХКьЭМ ) тАУ lastname тАУ LastName тАУ LASTNAME тАв ь╡ЬыМА 30 ьЮР ьЭ┤ьГБьЭД ыДШьзА ьХКьК╡ыЛИыЛд .
- 8. 8 Fundamentals of the PL/SQL Language яБ╡ Literals тАв ьИльЮР тАУ 030, 6, -14, 0, +32767 тАУ 3.14, 0.0, -12.0, +8300.00, .5, 25. тАУ 2E5, 1.0E-7, 3.14159e0, -1E38, -9.5e-3 тАв ым╕ьЮР тАУ тАШZтАЩ, тАШ&тАЩ, тАШ7тАЩ, тАШ тАШ, тАШzтАЩ, тАШ(тАШ тАв ым╕ьЮРьЧ┤ тАУ тАШHello, world!тАЩ тАУ тАЩ10-NOV-91тАЩ тАУ тАШ ъ╖╕ыКФ тАЬьаХызР ьвЛьЭА ыВаьФиьЮЕыЛИыЛд .!тАЭ ыЭ╝ъ│а ызРэЦИьК╡ыЛИыЛд .тАЩ тАУ тАШ$1,000,000тАЩ тАв Boolean тАУ TRUE, FALSE, NULL тАв ьЛЬъ░Д тАУ d1 DATE := DATE тАШ2009-01-01тАЩ; тАУ t1 TIMESTAMP := TIMESTAMP тАШ1983-09-18 00:30:01тАЩ;
- 9. 9 Fundamentals of the PL/SQL Language яБ╡ Comments тАв эХЬьдД ьг╝ьДЭ тАУ v_date DATE := DATE тАШ2009-01-01тАЩ; -- ыВаьзЬые╝ ыЛ┤ъ╕░ ьЬДэХЬ ы│АьИШ ьДаьЦ╕ тАв ьЧмыЯмьдД ьг╝ьДЭ тАУ /* v_date ыКФ ыВаьзЬые╝ ыЛ┤ъ╕░ ьЬДэХЬ ы│АьИШ v_time ыКФ ьЛЬъ░ДьЭД ыЛ┤ъ╕░ ьЬДэХЬ ы│АьИШ */ v_date DATE := DATE тАШ2009-01-01тАЩ; v_time TIMESTAMP := TIMESTAMP тАШ1983-09-18 00:30:01тАЩ; яБ╢ Declarations тАв ыЛдьЭМьЭШ эШХэГЬыбЬ ы│АьИШ ьДаьЦ╕ьЭ┤ ъ░АыКеэХйыЛИыЛд . тАУ DECLARE birthday DATE; -- ы│АьИШызМьЭД ьДаьЦ╕ age INTEGER := 27; -- ы│АьИШ ьДаьЦ╕ъ│╝ ыПЩьЛЬьЧР ь┤Иъ╕░ъ░Т ьЮЕыае name VARCHAR2(10) DEFAULT тАШ эЩНъ╕╕ыПЩтАЩ ; -- ъ╕░ы│╕ъ░Т = тАШ эЩНъ╕╕ыПЩтАЩ id VARCHAR2(10) NOT NULL; -- NULL эЧИьЪй ьХИ эХи today birthday%TYPE; -- birthday ьЩА ъ░ЩьЭА ыН░ьЭ┤эД░ эШХьЭ┤ ьаБьЪйыРи Jane info%ROWTYPE; -- info эЕМьЭ┤ы╕ФьЭШ ROW ые╝ ыМАьЮЕэХи email CONSTANT VARCHAR2(30); -- ьГБьИШ ьДаьЦ╕
- 10. 10 Fundamentals of the PL/SQL Language яБ╢ Structures тАв ьДаьЦ╕ы╢А (declaractive part) тАУ ьЛдэЦЙы╢АьЧРьДЬ ьВмьЪйэХа ы│АьИШыВШ ьГБьИШые╝ ьДаьЦ╕эХШыКФ ы╢Аы╢ДьЮЕыЛИыЛд . тАУ ьДаьЦ╕ы╢АыКФ тАШ DECLAREтАЩ ые╝ ьВмьЪйэХ┤ьДЬ ыВШэГАыГЕыЛИыЛд . тАв ьЛдэЦЙы╢А (executable part) тАУ ьЛдьаЬ ь▓ШыжмэХа ыбЬьзБьЭД ыЛ┤ыЛ╣эХШыКФ ы╢Аы╢ДьЮЕыЛИыЛд . тАУ ьЛдэЦЙы╢АыКФ тАШ BEGINтАЩ ьЬ╝ыбЬ ьЛЬьЮСыРШьЦ┤ тАШ ENDтАЩ ыбЬ ыБЭыВШъ▓М ыРйыЛИыЛд . тАв ьШИьЩ╕ь▓Шыжмы╢А (exception-building part) тАУ ьЛдэЦЙы╢АьЧРьДЬ ыбЬьзБьЭД ь▓ШыжмэХШыНШ ьдС ы░ЬьГЭэХа ьИШ ьЮИыКФ ъ░БьвЕ ьШдыеШыУдьЧР ыМАэХ┤ ь▓Шыжмые╝ эХШыКФ ы╢Аы╢ДьЮЕыЛИыЛд . тАУ ьШИьЩ╕ь▓Шыжмы╢АыКФ тАШ EXCEPTIONтАЩ ьЭД ьВмьЪйэХ┤ьДЬ ыВШэГАыГЕыЛИыЛд . тАУ ьШИьЩ╕ь▓Шыжмы╢АыКФ ьГЭыЮ╡ьЭ┤ ъ░АыКеэХйыЛИыЛд . DECLARE -- ьДаьЦ╕ы╢А counter INTEGER; BEGIN -- ьЛдэЦЙы╢А ьЛЬьЮС counter := counter + 1; IF counter IS NULL THEN dbms_output.put_line(тАШResult : COUNTER IS NullтАЩ); END IF; EXCEPTION WHEN OTHERS THEN -- ьШИьЩ╕ь▓Шыжмы╢А ( ьГЭыЮ╡ъ░АыКе ) dbms_output.put_line(тАШERRORSтАЩ); END; -- ьЛдэЦЙы╢А ыБЭыВи
- 11. 11 Fundamentals of the PL/SQL Language яБ╢ Scope and Visibility of PL/SQL Identifiers ыЛдьЭМ ъ╖╕ыж╝ 3 ьЭА ы│АьИШъ░А ьДаьЦ╕ыРЬ ьЬДь╣ШьЧР ыФ░ыЭ╝ьДЬ ьЬаэЪиэХЬ ы▓ФьЬДьЩА ы│АьИШьЭШ ьШБэЦеьЭ┤ ып╕ь╣а ьИШ ьЮИыКФ ы▓ФьЬДые╝ ыВШэГАыГЕыЛИыЛд . (Outer x = ьаДьЧны│АьИШ , Inner x = ьзАьЧны│АьИШ ) ъ╖╕ыж╝ 3. Scope and Visibility
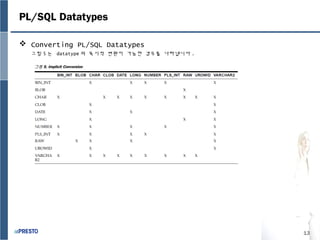
- 12. 12 PL/SQL Datatypes яБ╢ Overview of Predefined PL/SQL Datatypes тАв Scalar Type ьЭА Number ыШРыКФ Character String ыУ▒ьЭШ ъ▓ГьЭД ьЭШып╕эХШыКФыН░ , эХШыВШьЭШ ъ░ТызМьЭД ъ░АьзИ ьИШ ьЮИ ьЬ╝ый░ , ыВ┤ы╢А ъ╡мьД▒ьЪФьЖМые╝ ъ░Цъ│а ьЮИьзА ьХКьК╡ыЛИыЛд . тАв Composite Type ьЭА ы░░ьЧ┤ьЭШ ьЪФьЖМыУд (elements of an array) ыУ▒ьЭШ ъ▓ГьЭД ьЭШып╕эХШыКФыН░ , ъ░Бъ░БьЭД ъ░Ьы│ДьаБьЬ╝ ыбЬ ыЛдыг░ ьИШ ьЮИьЬ╝ый░ , ыВ┤ы╢А ъ╡мьД▒ьЪФьЖМые╝ ъ░Цъ│а ьЮИьК╡ыЛИыЛд . тАв Reference Type ьЭА Pointer ыЭ╝ъ│аыПД ы╢ИыжмьЪ░ыКФ ъ░ТыУд ьжЙ , ыЛдые╕ эФДыбЬъ╖╕ыЮиьЭШ Item(Values) ыУдьЭД ъ░АыжмэВд ыКФ ьг╝ьЖМъ░ТьЭД ъ░АьзАъ│а ьЮИьК╡ыЛИыЛд . тАв LOB(Large Obejct) Type ьЭА ыМАьЪйыЯЙ ыН░ьЭ┤эД░ые╝ ьаАьЮеэХШый░ , Long эГАьЮЕъ│╝ыКФ ыЛмыжм ьЙмьЪ┤ ъ▓АьГЙьЭ┤ ъ░АыКеэХйыЛИ ыЛд . ъ╖╕ыж╝ 4. Built-in Datatypes
- 13. 13 PL/SQL Datatypes яБ╢ Converting PL/SQL Datatypes ъ╖╕ыж╝ 5 ыКФ datatype ьЭШ ым╡ьЛЬьаБ ы│АэЩШьЭ┤ ъ░АыКеэХЬ ъ▓╜ьЪ░ые╝ ыВШэГАыГЕыЛИыЛд . ъ╖╕ыж╝ 5. Implicit Conversion
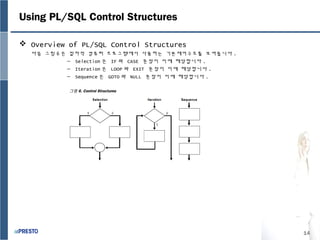
- 14. 14 Using PL/SQL Control Structures яБ╢ Overview of PL/SQL Control Structures ыЛдьЭМ ъ╖╕ыж╝ 6 ьЭА ьаИь░иьаБ ь╗┤эУиэД░ эФДыбЬъ╖╕ыЮиьЧРьДЬ ьВмьЪйэХШыКФ ъ╕░ы│╕ьаЬьЦ┤ъ╡мьб░ые╝ ы│┤ьЧмьдНыЛИыЛд . тАУ Selection ьЭА IF ьЩА CASE ым╕ьЮеьЭ┤ ьЭ┤ьЧР эХ┤ыЛ╣эХйыЛИыЛд . тАУ Iteration ьЭА LOOP ьЩА EXIT ым╕ьЮеьЭ┤ ьЭ┤ьЧР эХ┤ыЛ╣эХйыЛИыЛд . тАУ Sequence ьЭА GOTO ьЩА NULL ым╕ьЮеьЭ┤ ьЭ┤ьЧР эХ┤ыЛ╣эХйыЛИыЛд . ъ╖╕ыж╝ 6. Control Structures
- 15. 15 Using PL/SQL Control Structures яБ╢ IF and CASE Statements яБ╡ Using the IF-THEN Statement IF condition THEN sequence_of _statements END IF; яБ╡ Using the IF-THEN-ELSE Statement IF condition THEN sequence_of _statements1 ELSE sequence_of _statements2 END IF; яБ╡ Using the IF-THEN-ELSIF Statement IF condition1 THEN sequence_of _statements1 ELSIF condition2 THEN sequence_of _statements2 ELSE sequence_of _statements3 END IF;
- 16. 16 Using PL/SQL Control Structures яБ╡ Using the CASE Statement CASE selector WHEN expression1 THEN sequence_of_statements1; WHEN expression2 THEN sequence_of_statements2; тАж WHEN expressionN THEN sequence_of_statementsN; [ELSE sequence_of_statementsN+1;] END CASE;
- 17. 17 Using PL/SQL Control Structures яБ╢ LOOP and EXIT Statements яБ╡ Using the LOOP Statement LOOP squence_of_statements END LOOP; яБ╡ Using the EXIT Statement LOOP IF credit_rating < 3 THEN EXIT; -- exit loop immediately END IF; END LOOP; -- control resume here; яБ╡ Using the EXIT-WHEN Statement LOOP FETCH c1 INTO тАж EXIT WHEN c1%NOTFOUND; -- exit loop if condition is true тАж END LOOP; CLOSE c1;
- 18. 18 Using PL/SQL Control Structures яБ╡ Using the WHILE-LOOP Statement WHILE condition LOOP sequence_of_statements END LOOP; яБ╡ Using the FOR-LOOP Statement FOR counter IN [REVERSE] lower_bound..higher_bound LOOP squence_of_statements END LOOP;
- 19. 19 Using PL/SQL Control Structures яБ╢ GOTO and NULL Statements яБ╡ Using the GOTO Statement BEGIN тАж GOTO insert_row; тАж <<insert_row>> INSERT INTO emp VALUES тАж END; яБ╡ Using the NULL Statement EXCEPTION WHEN ZERO_DIVIDE THEN ROLLBACK; WHEN VALUE_ERROR THEN INSERT INTO errors VALUES тАж COMMIT; WHEN OTHERS THEN NULL; END
- 20. 20 Using PL/SQL Collections and Records яБ╢ What is a Collection? PL/SQL ьЧРьДЬыКФ ыЛдьЭМ 3 ъ░АьзАьЭШ type ьЭШ Collection( ьзСэХй ) ьЭД ьаЬъ│╡эХйыЛИыЛд . тАв Associative arrays (Index-by tables) - ьЧ░ъ┤Аы░░ьЧ┤ тАв Nested tables тАУ ьдСь▓й эЕМьЭ┤ы╕Ф тАв Variable arrays (Varrays) - ъ│аьаХы░░ьЧ┤ яБ╡ Understanding Nested Tables Nested table( ьдСь▓й эЕМьЭ┤ы╕Ф ) ьЭА Varray ьЩА эЭбьВмэХЬ ъ╡мьб░ые╝ ъ░АьзСыЛИыЛд . эХШьзАызМ ыСР ъ░АьзА ьаРьЧРьДЬ Varray ьЩА ыКФ ь░иьЭ┤ъ░А ьЮИыКФыН░ , ь▓льз╕ , ьдСь▓й эЕМьЭ┤ы╕ФьЭА ьДаьЦ╕ ьЛЬьЧР ьаДь▓┤ эБмъ╕░ые╝ ыкЕьЛЬэХа эХДьЪФъ░А ьЧЖьК╡ыЛИыЛд . ыСШьз╕ , Varray ьЭШ ъ▓╜ьЪ░ ьЪФьЖМыУдьЧР ыН░ьЭ┤эД░ые╝ ь░╕ьб░эХа ыХМ ъ░Бъ░БьЭШ ьЪФьЖМыУд ьИЬьДЬыМАыбЬ ь░╕ьб░эХ┤ьХ╝ эХШыКФыН░ , ьдСь▓й эЕМьЭ┤ы╕ФьЭШ ъ▓╜ьЪ░ ьИЬьДЬые╝ ьзАэВм эХДьЪФъ░А ьЧЖьК╡ыЛИыЛд . ыЛдьЭМ ъ╖╕ыж╝ 7 ьЭА Array ьЩА Nested Table ьЩАьЭШ ь░иьЭ┤ьаРьЭД ыВШэГАыГЕыЛИыЛд . ъ╖╕ыж╝ 7. Array versus Nested Table
- 21. 21 Using PL/SQL Collections and Records яБ╡ Understanding Varrays Varray( ъ│аьаХы░░ьЧ┤ ) ыКФ Variable array ьЭШ ьХ╜ьЮРыбЬ ъ│аьаХ ъ╕╕ьЭ┤ (fixed number) ые╝ ъ░АьзД ы░░ьЧ┤ьЭД ьЭШып╕эХйыЛИыЛд . ъ│аьаХъ╕╕ьЭ┤ые╝ ъ░Цъ│а ьЮИыЛдыКФ ъ▓ГьЭ┤ Varray ьДаьЦ╕ ьЛЬ ы░░ьЧ┤ьЭШ ьаДь▓┤ эБмъ╕░ые╝ ыкЕьЛЬэХ┤ьХ╝ эХиьЭД ьЭШып╕эХйыЛИыЛд . ыШРэХЬ Varray ыКФ эЕМьЭ┤ы╕Ф ыВ┤ьЧР ьаАьЮеыРа ьИШ ьЮИыКФыН░ , ьЭ┤ ызРьЭШ ьЭШып╕ыКФ эЕМьЭ┤ы╕ФьЭШ эХШыВШьЭШ ь╗мыЯ╝ эГАьЮЕьЬ╝ыбЬ Varray ъ░А ьВмьЪйыРа ьИШ ьЮИьЭМьЭД ьЭШып╕эХйыЛИыЛд . эФДыбЬъ╖╕ыЮШы░Н ьЦ╕ьЦ┤ьЧРьДЬ ьВмьЪйэХШыКФ ы░░ьЧ┤ъ│╝ ъ░ЩыЛдъ│а ы│┤ьЛЬый┤ ыРйыЛИыЛд . ыЛдьЭМ ъ╖╕ыж╝ 8 ьЭА Varray ые╝ ыВШэГАыГЕыЛИыЛд . яБ╡ Understanding Associative arrays Associative array( ьЧ░ъ┤Аы░░ьЧ┤ ) ыКФ Index-by table ьЭ┤ыЭ╝ъ│аыПД эХШый░ эВдьЩА ъ░ТьЭШ ьМНьЬ╝ыбЬ ъ╡мьД▒ыРЬ Collection ьЬ╝ыбЬ , эХШыВШьЭШ эВдыКФ эХШыВШьЭШ ъ░Тъ│╝ ьЧ░ъ┤АыРШьЦ┤ ьЮИьК╡ыЛИыЛд . JAVA ыВШ C# ъ│╝ ъ░ЩьЭА 3G ьЦ╕ьЦ┤ьЧРьДЬ ьВмьЪйэХШыКФ Hash Table ъ│╝ ыПЩьЭ╝эХЬ ъ░ЬыЕРьЮЕыЛИыЛд . Varray ъ░А ьЪФьЖМьЭШ ьЭ╕ыН▒ьКдые╝ эЖ╡эХ┤ ъ░Б ьЪФьЖМьЭШ ъ░ТьЧР ьаСъ╖╝эХШыКФ ы░Шый┤ , Associative array ыКФ эВдьЧР ьЭШэХ┤ ъ░ТьЧР ьаСъ╖╝эХйыЛИыЛд . ъ╖╕ыж╝ 8. Varray of Size 10
- 22. 22 Using PL/SQL Collections and Records яБ╢ What is a PL/SQL Record? Collection ьЭ┤ ы░░ьЧ┤ эШХэГЬьЭШ data type ьЭ┤ыЭ╝ый┤ , Record( ыаИь╜ФыУЬ ) ыКФ эЕМьЭ┤ы╕Ф эШХэГЬьЭШ data type ьЮЕыЛИыЛд . эЕМьЭ┤ы╕Ф ьЭШ column ь▓ШыЯ╝ ьЧмыЯм ъ░ЬьЭШ эХДыУЬыбЬ ъ╡мьД▒ыРШьЦ┤ ьЮИъ│а , PL/SQL ы╕ФыбЭьЧРьДЬ ьЮДьЛЬыбЬ ьВмьЪйэХа ьИШ ьЮИыКФ data type ьЭШ эХШыВШ ыЭ╝ъ│а эХа ьИШ ьЮИьК╡ыЛИыЛд . Collection ьЧР эХ┤ыЛ╣эХШыКФ Varray, Nested table, Associative array ыКФ ыкиыСР эФДыбЬъ╖╕ыЮШ ы░Н ьЦ╕ьЦ┤ьЧРьДЬ ьВмьЪйэХШыКФ ы░░ьЧ┤ эШХэГЬьЭШ ъ╡мьб░ые╝ ъ░АьзСыЛИыЛд . ьжЙ ьЭ┤ыУдьЭД ъ╡мьД▒эХШыКФ ьЪФьЖМыУдьЭШ ыН░ьЭ┤эД░ эГАьЮЕьЭА ыкиыСР ъ░ЩьХД ьХ╝ эХйыЛИыЛд . ы░Шый┤ эЕМьЭ┤ы╕ФьЭШ column ыУдьЭ┤ ьДЬыбЬ ыЛдые╕ ьЬаэШХьЭШ data type ьЬ╝ыбЬ ъ╡мьД▒ыРШыУпьЭ┤ Record ьЧньЛЬ эХ┤ыЛ╣ field(Record ьЧРьДЬыКФ element ыЮА ызР ыМАьЛа field ыЮА ьЪйьЦ┤ые╝ ьВмьЪй ) ыУдьЭ┤ ъ░Бъ╕░ ыЛдые╕ data type ьЭД ъ░АьзИ ьИШ ьЮИьК╡ ыЛИыЛд . эФДыбЬъ╖╕ыЮШы░Н ьЦ╕ьЦ┤ьЩА ы╣Дъ╡РэХШый┤ Record ыКФ Structure( ъ╡мьб░ь▓┤ ) ьЧР эХ┤ыЛ╣эХЬыЛдъ│а ы│╝ ьИШ ьЮИьК╡ыЛИыЛд . Record ъ░А эЕМьЭ┤ы╕Ф эШХэГЬьЭШ ъ╡мьб░ые╝ ъ░АьзАъ│а ьЮИьЬ╝ыпАыбЬ , ьЛдьаЬ ыМАы╢Аы╢ДьЭШ ъ▓╜ьЪ░ эЕМьЭ┤ы╕ФьЭШ ыН░ьЭ┤эД░ые╝ ьЭ╜ьЦ┤ьШдъ▒░ыВШ ьб░ьЮСэХШ ъ╕░ ьЬДэХ┤ PL/SQL ы╕ФыЮЩ ыВ┤ьЧРьДЬ ьЮДьЛЬьаБьЭ╕ data ьаАьЮеьЖМ ьЧнэХаьЭД ьИШэЦЙэХйыЛИыЛд . Record ьЧньЛЬ Collection ь▓ШыЯ╝ TYPE ьЭД ьВмьЪйэХШьЧм ьДаьЦ╕эХа ьИШ ьЮИьК╡ыЛИыЛд . тАУ [ TYPE ьЭД ьВмьЪйэХЬ ъ╡мым╕эШХьЛЭ ] TYPE ыаИь╜ФыУЬьЭ┤ыжД IS RECORD ( эХДыУЬ 1 ыН░ьЭ┤эД░эГАьЮЕ 1, эХДыУЬ 2 ыН░ьЭ┤эД░эГАьЮЕ 2, тАж); тАУ [ эЕМьЭ┤ы╕ФыкЕьЭД ьВмьЪйэХЬ ъ╡мым╕эШХьЛЭ ] ыаИь╜ФыУЬьЭ┤ыжД эЕМьЭ┤ы╕ФыкЕ %ROWTYPE; тАУ [ ь╗дьДЬыкЕьЭД ьВмьЪйэХЬ ъ╡мым╕эШХьЛЭ ] ыаИь╜ФыУЬьЭ┤ыжД ь╗дьДЬыкЕ %ROWTYPE;
- 23. 23 Performing SQL Operations from PL/SQL яБ╢ Overview of SQL Support in PL/SQL SQL ые╝ эЩХьЮеэХ┤ьДЬ , PL/SQL ыКФ эЮШъ│╝ ьВмьЪй ьЪйьЭ┤ьЭШ ьЬаьЭ╝эХЬ ьб░эХйьЭД ьаЬьХИэХйыЛИыЛд . PL/SQL ьЭА SQL ьЭШ ыкиыУа data ьб░ьЮС , transaction ьаЬьЦ┤ , эХиьИШ , Pseudocolumns ъ╖╕ыжмъ│а ьаЬьЦ┤ьЮР ыУ▒ ыкиыУа ъ▓ГьЭД ьВмьЪйэХа ьИШ ьЮИъ▓М ьзАьЫРэХиьЬ╝ыбЬьНи Oracle ьЭШ data ые╝ ьХИьаДэХШъ│а ьЬаьЧ░эХШъ▓М ыЛдыг░ ьИШ ьЮИъ▓М эХйыЛИыЛд . ыШРэХЬ PL/SQL ьЭА session ьаЬьЦ┤ , data ьаЬьЦ┤ , SQL data ьаХьЭШ ьЛдэЦЙ ыУ▒ dynamic SQL ьЭД ьзАьЫРэХйыЛИыЛд . ъ╖╕ыжмъ│а PL/SQL ьЭА эШДьЮмьЭШ ANSI/ISO SQL ъ╕░ьдАьЭД ыФ░ыжЕыЛИ ыЛд . яБ╡ Data Manipulation тАУ PL/SQL ьЭА Oracle data ые╝ ьб░ьЮСэХа ьИШ ьЮИыКФ INSERT, UPDATE, DELETE, SELECT ъ╖╕ыжмъ│а LOCK TABLE ыкЕыа╣ьЦ┤ ыУ▒ьЭД ьзАьЫРэХйыЛИыЛд . яБ╡ Transaction Control тАУ Oracle ьЭА Transaction ьзАэЦеьЮЕыЛИыЛд . ьЭ┤ъ▓ГьЭА Oracle ьЭ┤ ыН░ьЭ┤эД░ ым┤ъ▓░ьД▒ьЭД ьзАэЦеэХШъ╕░ ьЬДэХ┤ Transaction ьЭД ьЭ┤ьЪйэХЬыЛдыКФ ъ▓ГьЭД ьЭШып╕эХйыЛИыЛд . яБ╡ SQL Functions тАУ SQL ьЧРьДЬ эШ╕ь╢ЬэХШьЧм ьВмьЪйэХШыКФ COUNT ыУ▒ьЭШ эХиьИШые╝ ьзАьЫРэХйыЛИыЛд . яБ╡ SQL Pseudocolumns тАУ PL/SQL ьЭА SQL Pseudocolumn ьЭД ьЭ╕ьЛЭэХйыЛИыЛд . : CURRVAL, LEVEL, NEXTVAL, ROWID ъ╖╕ыжмъ│а ROWNUM ыУ▒ .
- 24. 24 Performing SQL Operations from PL/SQL яБ╡ SQL Operators тАУ PL/SQL ьЭА SQL ьЭШ ыкиыУа ьЧ░ьВ░ьЮРыУд ( ы╣Дъ╡Р ьЧ░ьВ░ьЮР , Row ьЧ░ьВ░ьЮР ыУ▒ ) ьЭД ьВмьЪй ъ░АыКеэХШъ▓М ьзАьЫР эХй ыЛИыЛд яБ╢ Performing DML Operation from PL/SQL (INSERT, UPDATE, DELETE) тАУ эК╣ы│ДэХЬ ьВмьЪйы▓Х ( ъ╕░эШ╕ ) ьЧЖьЭ┤ INSERT, UPDATE, DELETE ые╝ PL/SQL ьЧРьДЬ ьВмьЪйэХа ьИШ ьЮИьК╡ыЛИыЛд . тАУ SQL%ROWCOUNT ые╝ ьВмьЪйэХШьЧм ьЦ╝ызИыВШ ызОьЭА ROW ъ░А ьШБэЦеьЭД ы░ЫыКФ ыУ▒ьЭД ьХМ ьИШ ьЮИьК╡ыЛИыЛд . яБ╡ What is a Cursor? SELECT ым╕ьЮеьЭД ьЛдэЦЙэХШый┤ ьб░ъ▒┤ьЧР ыФ░ые╕ ъ▓░ъ│╝ъ░А ь╢Фь╢ЬыРйыЛИыЛд . ь╢Фь╢ЬыРШыКФ ъ▓░ъ│╝ыКФ эХЬ ъ▒┤ьЭ┤ ыРа ьИШ ыПД ьЮИъ│а ьЧмыЯм ъ▒┤ьЭ┤ ыРа ьИШыПД ьЮИьЬ╝ыпАыбЬ ьЭ┤ые╝ ResultSet эШ╣ьЭА ъ▓░ъ│╝ьзСэХйьЭ┤ыЭ╝ъ│а ы╢Аые┤ъ╕░ыПД эХйыЛИыЛд . ь┐╝ыжмьЧР ьЭШэХ┤ ы░ШэЩШыРШыКФ ъ▓░ъ│╝ыКФ ыйФыкиыжм ьГБьЧР ьЬДь╣ШэХШъ▓М ыРШыКФыН░ PL/SQL ьЧРьДЬыКФ ы░ФыбЬ ь╗дьДЬ (cursor) ые╝ ьВмьЪйэХШьЧм ьЭ┤ ъ▓░ъ│╝ьзСэХйьЧР ьаСъ╖╝ эХа ьИШ ьЮИьК╡ыЛИыЛд . ьжЙ ь╗дьДЬые╝ ьВмьЪйэХШый┤ ъ▓░ъ│╝ьзСэХйьЭШ ъ░Б ъ░Ьы│Д ыН░ьЭ┤эД░ьЧР ьаСъ╖╝ьЭ┤ ъ░АыКеэХйыЛИыЛд . ь╗дьДЬьЭШ ьвЕыеШьЧР ыКФ Implicit Cursor( ым╡ьЛЬьаБ ь╗дьДЬ ) ьЩА Explicit Cursor( ыкЕьЛЬьаБ ь╗дьДЬ ) ъ░А ьЮИьК╡ыЛИыЛд . яБ╡ Overview of Implicit Cursor Implicit Cursor( ым╡ьЛЬьаБ ь╗дьДЬ ) ыЮА Oracle ыВ┤ы╢АьЧРьДЬ ъ░Бъ░БьЭШ ь┐╝ыжм ъ▓░ъ│╝ьЧР ьаСъ╖╝эХШьЧм ьВмьЪйэХШъ╕░ ьЬДэХЬ ыВ┤ы╢А ьаБ ь╗дьДЬыЭ╝ эХа ьИШ ьЮИьК╡ыЛИыЛд . ым╡ьЛЬьаБ ь╗дьДЬыКФ ыкиыУа ь┐╝ыжмъ░А ьЛдэЦЙыРа ыХМызИыЛд ьШдэФИ ыРйыЛИыЛд . Oracle ыВ┤ы╢АьЧРьДЬ ьаСъ╖╝эХШъ│а ьВмьЪйыРШыКФ ь╗дьДЬьЭ┤ыпАыбЬ ьДаьЦ╕ , ьШдэФИ ыУ▒ьЭШ ьЮСьЧЕьЭД эХа эХДьЪФъ░А ьЧЖьЬ╝ый░ , ыкЕьЛЬьаБ ь╗дьДЬьЧРьДЬ ьДдыкЕэХЬ ь╗д ьДЬ ьЖНьД▒ыУдьЭД ым╡ьЛЬьаБ ь╗дьДЬьЧРьДЬыПД ыПЩьЭ╝эХШъ▓М ьВмьЪйэХа ьИШ ьЮИьК╡ыЛИыЛд .
- 25. 25 Performing SQL Operations from PL/SQL яБ╡ Overview of Implicit Cursor Attributes( ым╡ьЛЬьаБ ь╗дьДЬ ьЖНьД▒ыУд ) тАв %FOUND : ъ░АьЮе ь╡Ьъ╖╝ьЧР ьЭ╕ь╢ЬэХЬ эЦЙьЭ┤ ьЮИьЬ╝ый┤ TRUE тАв %ISOPEN : ь╗дьДЬъ░А ьЧ┤ыадьЮИьЬ╝ый┤ TRUE тАв %NOTFOUND : ъ░АьЮе ь╡Ьъ╖╝ьЧР ьЭ╕ь╢ЬэХЬ эЦЙьЭ┤ ьЧЖьЬ╝ый┤ TRUE тАв %ROWCOUNT : ъ░АьЮе ь╡Ьъ╖╝ьЧР ьЭ╕ь╢ЬэХЬ эЦЙьЭШ ъ░ЬьИШ яБ╡ Overview of Explicit Cursor Explicit Cursor( ыкЕьЛЬьаБ ь╗дьДЬ ) ыЮА ьВмьЪйьЮРъ░А ьзБьаС ь┐╝ыжмьЭШ ъ▓░ъ│╝ьЧР ьаСъ╖╝эХ┤ьДЬ ьЭ┤ые╝ ьВмьЪйэХШъ╕░ ьЬДэХ┤ ыкЕьЛЬьаБьЬ╝ ыбЬ ьДаьЦ╕эХЬ ь╗дьДЬые╝ ызРэХйыЛИыЛд . ьЭ╝ы░ШьаБьЬ╝ыбЬ ь╗дьДЬые╝ ьВмьЪйэХЬыЛдъ│а эХШый┤ ыкЕьЛЬьаБ ь╗дьДЬые╝ ьВмьЪйэХШыКФ ъ▓ГьЮЕыЛИыЛд . ыЛд ьЭМьЭА ыкЕьЛЬьаБ ь╗дьДЬые╝ ьВмьЪйэХШъ╕░ ьЬДэХЬ ьаИь░и ьЮЕыЛИыЛд . тАУ ь╗дьДЬ ьДаьЦ╕ : ь╗дьДЬьЧР ьЭ┤ыжДьЭД ьг╝ъ│а , ьЭ┤ ь╗дьДЬъ░А ьаСъ╖╝эХШыадыКФ ь┐╝ыжмые╝ ьаХьЭШэХйыЛИыЛд . [ CURSOR ь╗дьДЬыкЕ IS SELECT ым╕ьЮе ; ] тАУ ь╗дьДЬ ьЧ┤ъ╕░ (Open) : ь╗дьДЬыбЬ ьаХьЭШыРЬ ь┐╝ыжмые╝ ьЛдэЦЙэХШыКФ ьЧнэХаьЭД эХйыЛИыЛд . [ OPEN ь╗дьДЬыкЕ ; ] тАУ эМиь╣Ш (Fetch) : ь┐╝ыжмьЭШ ъ▓░ъ│╝ьЧР ьаСъ╖╝эХйыЛИыЛд . ы│┤эЖ╡ ь┐╝ыжмыКФ эХЬ ъ░Ь ьЭ┤ьГБьЭШ ъ▓░ъ│╝ые╝ ы░ШэЩШэХШыпАыбЬ Loop ые╝ ыПМый░ ъ░Ьы│Д ъ░ТыУдьЧР ьаСъ╖╝эХ┤ьДЬ ьЮДьЭШьЭШ ь▓Шыжмые╝ эХШъ▓М ыРйыЛИыЛд . [ FETCH ь╗дьДЬыкЕ INTO ы│АьИШтАж ; ] тАУ ь╗дьДЬ ыЛлъ╕░ (Close) : эМиь╣Ш ьЮСьЧЕьЭ┤ ыБЭыВШый┤ ь╗дьДЬ ь▓Шыжмые╝ ыБЭыВ┤ъ│а ыйФыкиыжмьГБьЧР ьб┤ьЮмэХШыКФ ь┐╝ыжмьЭШ ъ▓░ ъ│╝ые╝ ьЖМый╕ьЛЬэВ╡ыЛИыЛд . [ CLOSE ь╗дьДЬыкЕ ; ]
- 26. 26 Performing SQL Operations from PL/SQL яБ╢ Overview of Transaction Processing in PL/SQL яБ╡ Using COMMIT, ROLLBACK, and SAVEPOINT in PL/SQL тАв COMMIT BEGIN UPDATE accts SET bal = my_bal - debit WHERE acctno = 7715; UPDATE accts SET bal = my_bal + credit WHERE acctno = 7720; COMMIT WORK; END; тАв ROLLBACK DECLARE emp_id INTEGER; BEGIN SELECT empno, тАж INTO emp_id, тАж FROM new_emp WHERE тАж INSERT INTO emp VALUES (emp_id, тАж); INSERT INTO tax VALUES (emp_id, тАж); EXCEPTION WHEN DUP_VAL_ON_INDEX THEN ROLLBACK; END;
- 27. 27 Performing SQL Operations from PL/SQL тАв SAVEPOINT DECLARE emp_id emp.empno.%TYPE; BEGIN UPDATE emp SET тАж WHERE empno = emp_id; DELETE FROM emp WHERE тАж SAVEPOINT do_insert; INSERT INTO emp VALUES (emp_id, тАж); EXCEPTION WHEN DUP_VAL_ON_INDEX THEN ROLLBACK TO do_insert; END;
- 28. 28 Using PL/SQL Subprograms яБ╢ What Are Subprograms? PL/SQL Subprogram ьЭА parameter ьЩА ъ│аьЬаьЭШ ьЭ┤ыжДьЭД ъ░АьзД PL/SQL Block ьЭД ызРэХШый░ , Database ъ░Эь▓┤ыбЬ ьб┤ьЮмэХйыЛИ ыЛд . ьжЙ эХДьЪФэХа ыХМызИыЛд эШ╕ь╢ЬэХ┤ьДЬ ьВмьЪйэХа ьИШ ьЮИыЛдыКФ ьЭШып╕ ьЮЕыЛИыЛд . ьЭ┤ыЯмэХЬ Subprogram ьЧРыКФ Stored Procedure( ыВ┤ьЮе эФДыбЬьЛЬьаА ) ьЩА Function( эХиьИШ ) ъ░А ьЮИьК╡ыЛИыЛд . Stored Procedure ыКФ ъ╖╕ыГе тАШэФДыбЬьЛЬьаАтАЩыЭ╝ъ│аыПД ы╢Аые┤ый░ Database ьГБьЧРьДЬ ьВмьЪйьЮРъ░А ьзАьаХэХЬ ьЮДьЭШьЭШ ь▓Шыжмые╝ ьИШэЦЙэХШыКФ ы╕ФыбЭьЭД ызРэХйыЛИыЛд . Function( эХиьИШ ) ыШРыКФ Stored Function ьЭА SQL эХиьИШьЩА ъ░ЩьЭА ьвЕыеШыбЬ , ьВмьЪйьЮРъ░А ьзБьаС ьаХьЭШ эХ┤ьДЬ ьЮСьД▒эХЬ эХиьИШые╝ ызРэХйыЛИыЛд . ы│┤эЖ╡ PL/SQL ьЧРьДЬ эХиьИШыЭ╝ эХШый┤ ыВ┤ьЮеэХиьИШые╝ ызРэХШый░ ьЭ┤ ыШРэХЬ User Defined Function( ьВмьЪйьЮР ьаХьЭШ эХиьИШ ) эШ╣ьЭА ъ╖╕ыГе тАШэХиьИШтАЩыЭ╝ъ│аыПД ы╢Иыж╜ыЛИыЛд . яБ╢ Understanding PL/SQL Functions SQL ьЧРьДЬ Function( эХиьИШ ) эХШ эХШый┤ ы│┤эЖ╡ Oracle ьЧРьДЬ ьаЬъ│╡эХШыКФ SQL эХиьИШыУдьЭД ызРэХШьзАызМ , PL/SQL ьЧРьДЬ эХиьИШыЭ╝ эХШый┤ User Defined Function( ьВмьЪйьЮР ьаХьЭШ эХиьИШ ) ые╝ ызРэХйыЛИыЛд . ъ╖╕ыаЗыЛдъ│а SQL эХиьИШьЩА ьВмьЪйьЮР ьаХьЭШ эХиьИШьЭШ ьЖН ьД▒ьЭ┤ыВШ ъ╕░ыКеьЭ┤ ыЛдые╕ ъ▓ГьЭА ьХДыЛИый░ , ыЛдызМ Oracle ьЧРьДЬ ьаЬъ│╡эХШыКФьзА ьХДыЛИый┤ ьВмьЪйьЮРъ░А ьзБьаС ьЮСьД▒эХШыКФьзАьЧР ыФ░ыЭ╝ ъ╡м ы╢ДыРйыЛИыЛд . эХиьИШыКФ SQL эХиьИШь▓ШыЯ╝ ьЭ╝ьаХэХЬ ьЧ░ьВ░ьЭД ьИШэЦЙэХЬ ыТд ъ░ТьЭД ы░ШэЩШэХйыЛИыЛд . эХиьИШыКФ Specification( ыкЕьД╕ы╢А ) ьЩА Body( ъ╡мэШДы╢А ) ыбЬ ыВШыИМ ьИШ ьЮИьЬ╝ый░ , ъ╡мэШДы╢АыКФ Anonymous Block ь▓ШыЯ╝ ьДаьЦ╕ , ьЛдэЦЙ , ьШИьЩ╕ь▓Шыжмы╢АыбЬ ъ╡мьД▒ ыРйыЛИыЛд . [ ъ╡мым╕эШХьЛЭ ] CREATE OR REPLACE FUNCTION эХиьИШыкЕ ( эММыЭ╝ып╕эД░ 1 ыН░ьЭ┤эД░эГАьЮЕ , эММыЭ╝ып╕эД░ 2 ыН░ьЭ┤эД░эГАьЮЕ , тАж) RETURN ыН░ьЭ┤эД░эГАьЮЕ IS [AS] ы│АьИШьДаьЦ╕тАж ; BEGIN ь▓ШыжмыВ┤ьЪйтАж ; RETURN ыжмэД┤ъ░Т ; END;
- 29. 29 Using PL/SQL Subprograms тАв CREATE OR REPLACE FUNCTION : VIEW ые╝ ьГЭьД▒эХа ыХМьЩА ъ░ЩьЭ┤ CREATE OR REPLACE ые╝ ьВмьЪйэХ┤ьДЬ ъ╕░ьб┤ ьЧР ьЮСьД▒ыРЬ эХиьИШые╝ ьИШьаХэХа ъ▓╜ьЪ░ , ы│ДыПДыбЬ DROP ьЛЬэВдьзА ьХКьХДыПД ыРйыЛИыЛд . тАв эХиьИШыкЕ : ьГЭьД▒эХа эХиьИШыкЕьЭД ыкЕьЛЬэХйыЛИыЛд . тАв эММыЭ╝ып╕эД░ 1 ыН░ьЭ┤эД░эГАьЮЕ , тАж : эХиьИШьЭШ эММыЭ╝ып╕эД░ыбЬ ьШдыКФ эММыЭ╝ып╕эД░ ьЭ┤ыжДъ│╝ ыН░ьЭ┤эД░ эГАьЮЕьЭД ыкЕьЛЬэХйыЛИыЛд . тАв RETURN : ы░ШэЩШэХа ыН░ьЭ┤эД░ эГАьЮЕьЭД ыкЕьЛЬэХйыЛИыЛд . тАв BEGIN тАж END : эХиьИШъ░А ь▓ШыжмэХа ыВ┤ьЪйьЭД ыкЕьЛЬэХШый░ , ызи ызИьзАызЙьЧР эХиьИШъ░А ы░ШэЩШэХа ъ░ТьЭД RETURN ыЛдьЭМьЧР ыкЕьЛЬэХйыЛИыЛд . яБ╢ Understanding PL/SQL Procedures Procedure( эФДыбЬьЛЬьаА ) ыКФ эК╣ьаХэХЬ ь▓Шыжмые╝ ьИШэЦЙэХШыКФ PL/SQL Subprogram ьЮЕыЛИыЛд . эХиьИШьЩА ызИь░мъ░АьзАыбЬ эФДыбЬьЛЬьаА ыКФ Database ьЧР ьаАьЮеыРШьЦ┤ ьЮИыКФ ъ░Эь▓┤ьЭ┤ый░ , ьЭ┤ыЯмэХЬ ьЭ┤ьЬаыбЬ Stored Procedure( ыВ┤ьЮе эФДыбЬьЛЬьаА ) ыЭ╝ъ│аыПД ы╢АыжЕыЛИыЛд . эФДыбЬьЛЬьаА ьЧньЛЬ эММыЭ╝ып╕эД░ыУдьЭД ы░ЫьХД эК╣ьаХ ь▓Шыжмые╝ ьИШэЦЙэХШъ╕░ыКФ эХШьзАызМ , эХиьИШьЩАыКФ ыЛмыжм ъ░ТьЭД ы░ШэЩШэХШьзА ьХКьК╡ыЛИыЛд . [ ъ╡мым╕эШХьЛЭ ] CREATE OR REPLACE PROCEDURE эФДыбЬьЛЬьаАыкЕ ( эММыЭ╝ып╕эД░ 1 ыН░ьЭ┤эД░эГАьЮЕ [IN | OUT | INOUT], тАж) IS [AS] ы│АьИШьДаьЦ╕ы╢АтАж ; BEGIN эФДыбЬьЛЬьаА ы│╕ым╕ь▓ШыжмтАж ; END; [ ьЛдэЦЙъ╡мым╕эШХьЛЭ ] EXEC эШ╣ьЭА EXECUTE эФДыбЬьЛЬьаАыкЕ ( эММыЭ╝ып╕эД░тАж );
- 30. 30 Using PL/SQL Packages яБ╢ What Is a PL/SQL Package? Function( эХиьИШ ) ыВШ Procedure( эФДыбЬьЛЬьаА ) ые╝ ым╢ьЦ┤ ыЖУьЭА ъ▓ГьЭД Oracle ьЧРьДЬыКФ Package( эМиэВдьзА ) ыЭ╝ ы╢АыжЕыЛИыЛд . ьвА ыНФ ьЮРьД╕эЮИ ьДдыкЕэХШый┤ , эМиэВдьзАыЮА Oracle Database ьЧР ьаАьЮеыРЬ эФДыбЬьЛЬьаА , эХиьИШ ы┐РызМ ьХДыЛИыЭ╝ ы│АьИШ , ьГБьИШ , ь╗дьДЬ , Exception ыУдьЭД эХШыВШыбЬ ым╢ьЭА ь║бьКРэЩФыРЬ ъ░Эь▓┤ые╝ ызРэХйыЛИыЛд . яБ╡ Advantages of PL/SQL Packages тАв Application ьЭД ьвА ыНФ эЪиьЬиьаБьЬ╝ыбЬ ъ░Ьы░ЬэХа ьИШ ьЮИъ▓М ыПДьЩАьдНыЛИыЛд . тАв ъ┤АыаиыРЬ Schema Objects ые╝ re-compile эХа эХДьЪФ ьЧЖьЭ┤ ьИШьаХьЭ┤ ъ░АыКеэХйыЛИыЛд . тАв эХЬ ы▓ИьЧР ьЧмыЯм ъ░ЬьЭШ Package Objects ые╝ ыйФыкиыжмыбЬ ыбЬыУЬэХа ьИШ ьЮИьК╡ыЛИыЛд . тАв Procedure( эФДыбЬьЛЬьаА ) ыВШ Function( эХиьИШ ) ыУдьЭШ ьШды▓ДыбЬыФйьЭ┤ ъ░АыКеэХйыЛИыЛд . тАв Package ыВ┤ьЭШ ыкиыУа эГАьЮЕ , эХныкй , Subprograms ьЭД PUBLIC ьЭ┤ыВШ PRIVATE ьЬ╝ыбЬ ьДаьЦ╕эХ┤ ьДЬ ьВмьЪйэХа ьИШ ьЮИьК╡ыЛИыЛд .
- 31. 31 Using PL/SQL Packages яБ╡ Understanding The Package Specification Package Specification( эМиэВдьзА ыкЕьД╕ы╢А ) ыКФ эМиэВдьзАьЧРьДЬ ьВмьЪйэХа ьИШ эГАьЮЕъ│╝ ь╗дьДЬ , эХиьИШ , эФДыбЬьЛЬьаАыУдьЭД ьДаьЦ╕эХйыЛИыЛд . [ Example ] ьЧРьДЬ ъ╡╡ьЭА ъ╕АьЮРыбЬ эСЬьЛЬыРЬ ы╢Аы╢ДьЭ┤ ы░ФыбЬ эМиэВдьзА ьДаьЦ╕ ым╕ы▓ХьЧР эХ┤ыЛ╣ыРйыЛИыЛд . эМиэВдьзА ьаХьЭШыКФ эХиьИШ ыВШ эФДыбЬьЛЬьаАьЩА ызИь░мъ░АьзАыбЬ тАШ CREATE OR REPLACE PACKAGEтАЩ ъ╡мым╕ьЭД ьВмьЪйэХйыЛИыЛд . ъ╖╕ыж╝ 9. Package Scope [ Example ] CREATE OR REPLACE PACKAGE employee_process AS -- эГАьЮЕ , ь╗дьДЬ , Exception ьДаьЦ╕ TYPE EmpRecord IS RECORD (emp_id INT, salary REAL); TYPE DeptRecord IS RECORD (dept_id INT, loc_id INT); -- ьЬДьЧРьДЬ ьДаьЦ╕эХЬ EmpRecord ые╝ ы░ШэЩШэХШыКФ ь╗дьДЬ ьДаьЦ╕ CURSOR salaries RETURN EmpRecord; -- ъ╕ЙьЧмъ░А ызЮьзА ьХКьЭД ъ▓иьЪ░ ьШИьЩ╕ь▓Шыжмые╝ ьЬДэХЬ exception ьДаьЦ╕ invalid_salary EXCEPTION; -- PROCEDURE hire_employee ( first_name VARCHAR2, last_name VARCHAR2, тАж ); PROCEDURE fire_employee (emp_id INT); FUNCTION nth_highest_salary (n INT) RETURN EmpRecord; END employee_process;
- 32. 32 Using PL/SQL Packages яБ╡ Understanding The Package Body Package Body( эМиэВдьзА ъ╡мэШДы╢А ) ьЭА ыкЕэВдьзА ыкЕьД╕ы╢АьЧРьДЬ ьДаьЦ╕ыРЬ ъ░Б ь╗дьДЬ ы░П Subprograms ьЭД эПмэХиэХйыЛИыЛд . эМиэВдьзА ъ╡мэШДы╢АыКФ тАШ CREATE OR REPLACE PACKAGE BODYтАЩ ъ╡мым╕ьЭД ьВмьЪйэХйыЛИыЛд . [ Example ] CREATE OR REPLACE PACKAGE BODY employee_process AS -- ьЭ┤ ы│АьИШыКФ ъ╡мэШДы╢АьЧР ьДаьЦ╕ыРШьЧИьЬ╝ыпАыбЬ PRIVATE ьЖНьД▒ьЭД ъ░АьзСыЛИыЛд . number_hired INT; -- ыкЕьД╕ы╢АьЧРьДЬ ьДаьЦ╕эХЬ ь╗дьДЬые╝ ьаХьЭШэХйыЛИыЛд . CURSOR salaries RETURN EmpRecord IS SELECT employee_id, salary FROM employees ORDER BY salary DESC; -- ьЛаъ╖ЬьВмьЫРьЭД ыУ▒ыбЭэХйыЛИыЛд . PROCEDURE hire_employee ( first_name VARCHAR2, last_name VARCHAR2, тАж ) IS new_employee_id BEGIN -- ьЛаъ╖ЬьВмьЫР ыУ▒ыбЭьЭД ьЬДэХЬ , employee_id ъ░ТьЭШ ьЛЬэААьКд ы▓ИэШ╕ые╝ ъ░Аьа╕ьШ┤ SELECT employee_seq.NEXTVAL INTO new_employee_id FROM dual; яГи ъ│ДьЖН
- 33. 33 Using PL/SQL Packages яГиъ│ДьЖН -- ьЛаъ╖ЬьВмьЫР ыУ▒ыбЭь▓Шыжм . INSERT INTO employees (employee_id, first_name, тАж) VALUES (new_employee_id, first_name, тАж); number_hired := number_hired + 1; END hire_employee; тАж -- ьзБъ╕ЙьЧР ыФ░ые╕ ъ╕ЙьЧмьХб ы▓ФьЬДьЧР эПмэХиыРШыКФьзАые╝ ъ▓АьВмэХШьЧм ъ╖╕ ъ▓░ъ│╝ые╝ ы░ШэЩШэХШыКФ эХиьИШ FUNCTION sal_ok (j_id VARCHAR2, salary REAL) RETURN BOOLEAN IS min_sal REAL; max_sal REAL; BEGIN -- эХ┤ыЛ╣ ьзБъ╕ЙьЭШ ь╡ЬьЖМ , ь╡ЬыМАъ╕ЙьЧмьХбьЭД ъ░Аьа╕ьШ╡ыЛИыЛд . SELECT min_salary, max_salary INTO min_sal, max_sal FROM jobs WHERE job_id = j_id; -- эММыЭ╝ып╕эД░ыбЬ ыУдьЦ┤ьШдыКФ salary ъ╕ИьХбьЭ┤ эХ┤ыЛ╣ ьзБъ╕ЙьЭШ ь╡ЬьЖМьЩА ь╡ЬыМАъ╕ИьХб ьВмьЭ┤ьЧР ьЮИьЭД ъ▓╜ьЪ░ьЧРыКФ TRUE ые╝ , -- ъ╖╕ыаЗьзА ьХКьЬ╝ый┤ FALSE ые╝ ы░ШэЩШэХйыЛИыЛд . (ANS ьб░ъ▒┤ьЭ┤ыпАыбЬ ыСР ьб░ъ▒┤ ыкиыСР ызМьб▒эХ┤ьХ╝ TRUE ые╝ ы░ШэЩШэХй ыЛИыЛд .) RETURN (salary >= min_sal) AND (salary <= max_sal) END sal_ok; тАж BEGIN number_hired := 0; END employee_process;
- 34. 34 Handling PL/SQL Errors яБ╢ Overview of PL/SQL Runtime Error Handling PL/SQL ьЧРьДЬ Error ьГБэЩйьЭД ьб░ьаИэХШыКФ ъ▓ГьЭД Exception ьЭ┤ыЭ╝ъ│а ы╢АыжЕыЛИыЛд . Exceptions ьЭА ыВ┤ы╢АьаБьЬ╝ыбЬ ьаХьЭШ (System Runtime ьЧР ьЭШэХ┤ьДЬ ) эХШъ▒░ыВШ ьВмьЪйьЮРъ░А ьаХьЭШэХйыЛИыЛд . Exception ьЭД ь▓ШыжмэХШыКФ ы╢Аы╢ДьЭД ьШИьЩ╕ь▓Шыжмы╢АыЭ╝ъ│аыПД ы╢Аые┤ыКФыН░ , ьШИьЩ╕ь▓Шыжмы╢АыКФ BEGIN( ьЛдэЦЙы╢А ) ьЧРьДЬ ыбЬьзБьЭД ь▓ШыжмэХШ ыНШ ьдС ы░ЬьГЭэХа ьИШ ьЮИыКФ ъ░БьвЕ ьШдыеШыУдьЧР ыМАэХ┤ ь▓ШыжмэХШыКФ ы╢Аы╢ДьЮЕыЛИыЛд . ьжЙ , Oracle ьЧРьДЬ SQL ым╕ьЮеьЭД ьЛдэЦЙ ьЛЬ ьШдыеШ ъ░А ы░ЬьГЭэХШъ▓М ыРШый┤ ьЮРыПЩьЬ╝ыбЬ ORA-XXXX ьШдыеШ ы▓ИэШ╕ьЩА эХиъ╗Ш ыйФьЛЬьзАъ░А ы░ШэЩШыРШыКФыН░ , ьВмьЪйьЮРъ░А ьзБьаС ьЭ┤ыЯмэХЬ ыйФьЛЬьзА ые╝ ыМАь▓┤эХШъ▒░ыВШ ьШдыеШъ░А ы░ЬьГЭэХа ъ▓╜ьЪ░ ь▓ШыжмэХа ыбЬьзБьЭД ъ╕░ьИаэХа ы╢Аы╢ДьЮЕыЛИыЛд . JAVA ьЩА ъ░ЩьЭА эФДыбЬъ╖╕ыЮШы░Н ьЦ╕ьЦ┤ьЭШ TRY тАж CATCH ым╕ьЧРьДЬ CATCH ьЧР эХ┤ыЛ╣ыРШыКФ ы╢Аы╢ДьЮЕыЛИыЛд . [ Example ] DECLARE counter INTEGER; BEGIN counter := 10; counter := counter / 0; dbms_output.put_line(counter); EXCEPTION WHEN OTHERS THEN dbms_output.put_line(тАШERRORSтАЩ); END; ьЬДьЭШ [ Example ] ьЭА counter ыЭ╝ыКФ ы│АьИШые╝ 0 ьЬ╝ыбЬ ыВШыИДыадъ│а ьЛЬыПДэХШьШАьЭД ъ▓╜ьЪ░ ы░ЬьГЭэХШыКФ ьЧРыЯмьЧР ыМАэХ┤ ьШдыеШь▓Шыжм ые╝ эХШыКФ ъ▓ГьЮЕыЛИыЛд . ьЬДьЭШ ьШИьЩ╕ь▓Шыжмы╢А (EXCEPTION~) ыКФ ьГЭыЮ╡ьЭ┤ ъ░АыКеэХйыЛИыЛд . * ьЬДьЭШ OTHERS ыЭ╝ыКФ эВдьЫМыУЬыКФ PL/SQL ьЭД ьЮСьД▒эХШыКФ ьВмьЪйьЮРъ░А ыкЕьЛЬэХЬ ъ▓╗ ьЭ┤ьЩ╕ьЭШ ыкиыУа ьШдыеШые╝ ьЮбьХДыВ┤ыКФ ы╢Аы╢ДьЭ┤ыЭ╝ ъ│а ьГЭъ░БэХШьЛЬый┤ ыРйыЛИыЛд .
- 35. 35 Handling PL/SQL Errors яБ╢ Advantages of PL/SQL Exceptions Exceptions ьЭД ьЭ┤ьЪйэХШый┤ ьЧмыЯм SQL ъ╡мым╕ьЧРьДЬ ы░ЬьГЭэХШыКФ ьЮаьЮмьаБьЭ╕ Error ьЧР ыЛиьзА PL/SQL Exception Handler Block ьЧР ь╢Фъ░АэХШыКФ ъ▓Г ызМьЬ╝ыбЬ ыМАь▓ШэХа ьИШ ьЮИьК╡ыЛИыЛд . ьВмьЪйьЮРъ░А ьШдыеШые╝ ь▓ШыжмэЦИыЛдый┤ ы░ЬьГЭ ъ░АыКеэХЬ ьШдыеШые╝ ъ░РьХИэХШьЧм эФДыбЬъ╖╕ыЮШы░НьЭД эХЬ ъ▓ГьЭ┤ыЭ╝ ы│╝ ьИШ ьЮИьК╡ыЛИыЛд . ьжЙ ы░ЬьГЭ ъ░АыКеэХЬ ыкиыУа ъ▓╜ьЪ░ьЭШ ьИШые╝ ъ░РьХИэХШьЧм ыбЬьзБьЧР ьЭ┤ые╝ ьЛмьЦ┤ ыЖУьЭА ъ▓ГьЮЕыЛИыЛд . ьШИые╝ ыУдьЦ┤ Overview ьЭШ [ Example ] ъ│╝ ъ░ЩьЭ┤ 0 ьЬ╝ыбЬ ыВШыИЧьЕИьЭД ьИШэЦЙэХШъ▓М ыРШьЧИьЭД ъ▓╜ьЪ░ , ьВмьЪйьЮРъ░А ьЭ┤ыЯмэХЬ ъ▓╜ьЪ░ые╝ ып╕ыжм ьГЭъ░БэЦИыЛдый┤ ьШдыеШ ыйФьЛЬьзАые╝ ы│┤ьЧмьг╝ ьзА ьХКъ│а 0 ыМАьЛа ыЛдые╕ ъ░ТьЬ╝ыбЬ ыВШыИДыПДыбЭ ь▓ШыжмэХа ьИШыПД ьЮИьК╡ыЛИыЛд . ъ╖╕ыжмъ│а ъ╖╕ ыЛдьЭМ ыбЬьзБьЭД ь▓ШыжмэХа ьИШъ░А ьЮИыКФ ъ▓ГьЮЕ ыЛИыЛд . эХШьзАызМ Oracle PL/SQL ьЧФьзДьЧРьДЬ ь▓ШыжмэХШьЧм ыйФьЛЬьзАые╝ ы│┤ьЧмьг╝ъ▓М ыРа ъ▓╜ьЪ░ьЧРыКФ ьШдыеШъ░А ы░ЬьГЭэХЬ ьЛЬьаРьЧРьДЬ ь▓Ш ыжмъ░А ьдСыЛиыРШый░ , ъ╖╕ ыЛдьЭМ ыбЬьзБьЭА ь▓ШыжмэХа ьИШъ░А ьЧЖьК╡ыЛИыЛд . Oracle ьЭД ьВмьЪйэХШыКФ Application ьЭШ ьвЕыеШьЧР ыФ░ыЭ╝ьДЬ PL/SQL ьЧФьзДьЭ┤ ьШдыеШь▓Шыжмые╝ эХа ъ▓╜ьЪ░ Application ьЭ┤ ыЛдьЪ┤ыРа ьИШыПД ьЮИьзАызМ ьВмьЪйьЮРъ░А ьЭ┤ыЯмэХЬ ьШдыеШые╝ ьЮбьХДыВ╕ыЛдый┤ эФДыбЬъ╖╕ыЮиьЭ┤ ыЛдьЪ┤ыРШыКФ эШДьГБъ╣МьзАыКФ ызЙьЭД ьИШ ьЮИыКФ ъ▓ГьЮЕыЛИыЛд . яБ╢ Tips for Handling PL/SQL Errors [ Example1 ] DECLARE pe_ratio NUMBER(3, 1); BEGIN DELETE FROM stats WHERE symbol = тАШXYZтАЩ; SELECT price / NVL(earning, 0) INTO pe_ratio FROM stocks WHERE symbol = тАШXYZтАЩ; INSERT INTO stats (symbol, ratio) VALUES (тАШXYZтАЩ, pe_ratio); EXCEPTION WHEN ZERO_DIVIDE THEN NULL; END;
- 36. 36 Handling PL/SQL Errors [ Example ] ьЭШ Exception ьЭД эЪиъ│╝ьаБьЬ╝ыбЬ ь▓ШыжмэХа ьИШ ьЮИъ▓М ьЖМьКд эШХэГЬые╝ ьб░ъ╕И ы░Фъ╛╕ьЦ┤ы│┤ый┤ ыЛдьЭМъ│╝ ъ░ЩьК╡ыЛИыЛд . ыЛдьЭМьЭШ [ Example2 ] ыКФ Exception ъ│╝ SAVEPOINT ьЭШ ьб░эХйьЭД ьЭ┤ьЪйэХЬ ьЖМьКд ь╜ФыУЬьЮЕыЛИыЛд . [ Better Example1 ] DECLARE pe_ratio NUMBER(3, 1); BEGIN DELETE FROM stats WHERE symbol = тАШXYZтАЩ; BEGIN ---------------- sub-block begins SELECT price / NVL(earnings, 0) INTO pe_ratio FROM stocks WHERE symbol = тАШXYZтАЩ; EXCEPTION WHEN ZERO_DIVIDE THEN pe_ratio := 0; END; ---------------- sub-block ends INSERT INTO stats (symbols, ratio) VALUES (тАШXYZтАЩ, pe_ratio); EXCEPTION WHEN OTHERS THEN NULL; END; [ Example2 ] DECLARE name VARCHAR2(20); тАж suffix NUMBER := 1; яГи ъ│ДьЖН
- 37. 37 Handling PL/SQL Errors яГиъ│ДьЖН BEGIN FOR I IN 1..10 LOOP -- try 10 times BEGIN -- sub-block begins SAVEPOINT start_transaction; -- mark a savepoint /* Remove rows from a table of survey results. */ DELETE FROM results WHERE answer1 = тАШNOтАЩ; /* Add a survey respondentтАЩs name and answers. */ INSERT INTO results VALUES (name, тАж); -- raises DUP_VAL_ON_INDEX if two respondents have the same name COMMIT; EXIT; EXCEPTION WHEN DUP_VAL_ON_INDEX THEN ROLLBACK TO start_transaction; -- undo changes suffix := suffix + 1; -- try to fix problem name := name || TO_CHAR(suffix); END; -- sub-block ends END LOOP; END;
- 38. 38 Thought яБ╢ #1. Which Better Good Between Only SQL and PL/SQL тА╗ ыЛдьЭМьЭШ ыВ┤ьЪйьЭА Naver ы░П Google ыУ▒ьЭШ ъ▓АьГЙьЭД эЖ╡эХ┤ьДЬ ьИШьзСэХЬ ыВ┤ьЪйьЮЕыЛИыЛд . яБ╡ Better Good Situation in Only SQL PL/SQL ьЭА ьВмьЛд Cursor( ь╗дьДЬ ) эФДыбЬъ╖╕ыЮШы░НьЮЕыЛИыЛд . ь╗дьДЬые╝ ьЭ┤ьЪйэХШый┤ ьЙ╜ъ│а эО╕ыжмэХШъ▓М data ые╝ ьб░ьЮСэХШъ▒░ыВШ ьЦ╗ьЭД ьИШ ьЮИьК╡ыЛИыЛд . эХШьзАызМ , Database ьЭШ ьД▒ыКе ьаАэХШьЭШ ьг╝ы▓ФьЭ┤ ы░ФыбЬ Cursor ьЮЕыЛИыЛд . ъ╖╕ ьЭ┤ьЬаыКФ Cursor ыЭ╝ыКФ ъ▓ГьЭ┤ ьИЬь░иьаБьЭ╕ ьЖНьД▒ьЭД ъ░АьзАъ╕░ ыХМым╕ьЮЕыЛИыЛд . Database ъ░А ьЫРыЮШы╢АэД░ ыЛдыЯЙьЭШ data ые╝ эХЬъ║╝ы▓ИьЧР ь▓ШыжмэХШ ыКФ ьзСэХйьаБьЭ╕ ьЖНьД▒ьЭД ъ░АьзАъ│а ьЮИъ╕░ ыХМым╕ьЧР Cursor ьЩА Database ыКФ ъ╢БэХйьЭ┤ ьЮШ ызЮьзА ьХКьК╡ыЛИыЛд . ы╣ДыФФьШдъ░Аъ▓М ьЧРьДЬ ьаДь▓┤эЪМьЫР ьдС ы╣ДыФФьШдые╝ ыСР ы▓И ьЭ┤ьГБ ы╣Мыадъ░Д эЪМьЫРьЭД ъ╡мэХШыКФ ьШИьаЬыбЬ ыУдьЦ┤ы│┤ъ▓аьК╡ыЛИыЛд . [ PL/SQL ьЭД ьЭ┤ьЪй ьЛЬ ьЮРьг╝ ьВмьЪйэХШъ▓М ыРШыКФ ьКдэГАьЭ╝ ] DECLARE ы│АьИШ LOOP эЪМьЫРьЭ┤ ы╣Мыж░ ы╣ДыФФьШд ъ░ЬьИШ ь╢ФьаБ ; IF эЪМьЫРьЭ┤ ы╣Мыж░ ы╣ДыФФьШд ьИШ >=2 THEN тАж. END IF; END LOOP; END; ьЭ┤ыЯ░ эШХэГЬыбЬ PL/SQL ьЭД ъ╡мьД▒эХШъ▓М ыРШый┤ Database ыКФ ьаДь▓┤ ыМАьЧм эЪЯьИШызМэБ╝ ыгиэФДые╝ ыПМыжмъ▓М ыРйыЛИыЛд . ьЭ┤ыЯмэХЬ ы░йьЛЭьЭА ьИЬь░иьаБьЭ╕ ы░йьЛЭьЬ╝ыбЬ ъ╡мэШДьЭД эХЬ эШХэГЬьЮЕыЛИыЛд . яГи ъ│ДьЖН
- 39. 39 Thought эХШьзАызМ , ьЭ┤ъ▓ГьЭД SQL ьЭД ьЭ┤ьЪйэХШьЧм ьзСэХйьаБьЭ╕ ы░йьЛЭьЬ╝ыбЬ ъ╡мэШДэХ┤ ы│┤ый┤ Database ыКФ ыФ▒ ыСР ы▓ИьЭШ ьЛдэЦЙызМьЬ╝ыбЬ ъ▓░ъ│╝ые╝ ыВ╝ ьИШ ьЮИъ▓М ыРйыЛИыЛд . ыЛдьЭМьЭ┤ эЫиьФм Database ьЧР ьаБэХйэХЬ ъ╡мьб░ые╝ ьзАыЛМ ы░йьЛЭьЮЕыЛИыЛд . [ SQL ызМьЭД ьЭ┤ьЪйэХШьЧм ыШСъ░ЩьЭА ъ▓░ъ│╝ые╝ ь╢ЬыаеэХШыКФ ъ╡мым╕ ] SELECT эЪМьЫРьЭ┤ыжД FROM ы╣ДыФФьШд ыМАьЧм MINUS SELECT DISTINCT эЪМьЫРьЭ┤ыжД FROM ы╣ДыФФьШдыМАьЧм яБ╡ Better Good Situation in PL/SQL Application ъ│╝ Database ьГБьЧРьДЬыКФ ызОьЭА Network Traffic ьЭ┤ ы░ЬьГЭэХйыЛИыЛд . ьШИые╝ ыУдьЦ┤ ьЧмыЯм ъ░ЬьЭШ SELECT, INSERT, DELETE ым╕ьЭД ы│┤ыВ┤ыадый┤ Only SQL ьЭА эХЬы▓ИьЧР эХШыВШьЭШ SQL ызМьЭД ы│┤ыВ┤ьХ╝ эХйыЛИыЛд . [ SQL Example ] SELECT * FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ ъ╣АэГЬьЪ░тАЩ ; INSERT INTO эХЩьаБы╢А ( ьЭ┤ыжД , ьД▒ы│Д , .. ) VALUES ( ъ╣АэГЬэЭм , ьЧм , .. ); DELETE FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ эЩНъ╕╕ыПЩ ; яГи ъ│ДьЖН
- 40. 40 Thought эХШьзАызМ , ыЛдьЭМьЭШ PL/SQL ьЭД ьВмьЪйэХШъ▓М ыРШый┤ Application ъ│╝ Database ыКФ ыЛи эХЬы▓ИьЭШ Connection ызМьЬ╝ыбЬыПД ьЧмыЯм ъ░ЬьЭШ SQL ым╕ьЭД ыПЩьЛЬьЧР ы│┤ыВ╝ ьИШ ьЮИьК╡ыЛИыЛд . [ PL/SQL Example ] DECLARE BEGIN SELECT * FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ ъ╣АэГЬьЪ░тАЩ ; INSERT INTO эХЩьаБы╢А ( ьЭ┤ыжД , ьД▒ы│Д , .. ) VALUES ( ъ╣АэГЬэЭм , ьЧм , .. ); DELETE FROM эХЩьаБы╢А WHERE ьЭ┤ыжД = тАШ эЩНъ╕╕ыПЩ ; COMMIT; END; ьЭ┤ыЯмэХЬ ъ▓╜ьЪ░ьЧРьДЬыКФ PL/SQL ьЭ┤ Only SQL ьЭД ьВмьЪйэХШыКФ ъ▓Гы│┤ыЛд эЫиьФм Network Traffic ьЧР ы╢АыЛ┤ьЭД ьг╝ьзА ьХКъ│а SQL ьЭД ьЛдэЦЙ ьЛЬэВм ьИШ ьЮИьК╡ыЛИыЛд .
- 41. 41 Thought яБ╢ #2. A Choice Between яБ╡ When Choosing Between Nested Tables and Associative Arrays? Nested Table( ьдСь▓й эЕМьЭ┤ы╕Ф ) ьЭА Database Column ьЧР ьаАьЮеэХа ьИШ ьЮИьК╡ыЛИыЛд . ъ╖╕ыЯмыВШ Associative Arrays( ьЧ░ъ┤Аы░░ьЧ┤ ) ьЭА ъ╖╕ыаЗьзА ык╗эХйыЛИыЛд . Nested Table ьЭА эБ░ эЕМьЭ┤ы╕Фъ│╝ Single-Column эЕМьЭ┤ы╕Фъ│╝ьЭШ Normally Join ьЭД эХа ъ▓╜ьЪ░ьЧР ъ░ДыЛиэХЬ SQL ызМьЬ╝ыбЬыПД ъ░АыКеэХйыЛИыЛд .Associative Arrays ьЭА эМиэВдьзАъ░А ь┤Иъ╕░эЩФ ыРШъ▒░ыВШ ы╣Иы▓ИэЮИ эФДыбЬьЛЬьаАъ░А эШ╕ь╢ЬыРШыКФ ыйФыкиыжм ьХИьЧРьДЬ ьГБыМАьаБьЬ╝ыбЬ ьаБьЭА эЕМьЭ┤ы╕Ф ъ▓АьГЙызМьЬ╝ыбЬ Collection ьЭД ъ╡мьД▒эХа ыХМ ьЦ┤ьЪ╕ыж╜ыЛИыЛд . яБ╡ When Choosing Between Nested Tables and Variable Arrays? Varrays( ъ│аьаХы░░ьЧ┤ ) ьЭА ыЛдьЭМъ│╝ ъ░ЩьЭА ьГБэЩйьЧР ьЬаьЪйэХйыЛИыЛд . - ъ╡мьД▒ьЪФьЖМьЭШ ъ░ЬьИШые╝ ьХМ ьИШ ьЮИыКФ ъ▓╜ьЪ░ - ъ╡мьД▒ьЪФьЖМыУдьЭ┤ ьИЬь░иыМАыбЬ ыкиыСР ьХбьД╕ьКд ыРШьЦ┤ ьзАыКФ ъ▓╜ьЪ░ Nested Tables( ьдСь▓й эЕМьЭ┤ы╕Ф ) ьЭА ыЛдьЭМъ│╝ ъ░ЩьЭА ьГБэЩйьЧР ьЬаьЪйэХйыЛИыЛд . - Index ъ░ТьЭ┤ ьЧ░ьЖНьаБьЭ┤ьзА ьХКьЭА ъ▓╜ьЪ░ - Index ъ░ТьЭД ьЬДэХЬ эХЬъ│Дые╝ ып╕ыжм ьаХьЭШ эХШьзА ык╗эХа ъ▓╜ьЪ░ - ыкЗыкЗьЭШ ъ╡мьД▒ьЪФьЖМые╝ ьзАьЪ░ъ▒░ыВШ ьИШьаХэХ┤ьХ╝ эХа ъ▓╜ьЪ░ . ыЛи , эХЬы▓ИьЧР ыкиыУа ъ╡мьД▒ьЪФьЖМые╝ эЦЙэХа ьИШ ьЧЖьЭМ .
- 42. 42 Thought яБ╢ #3. Why Use a Function? яБ╡ ьДЬы╕Мь┐╝ыжмые╝ ьВмьЪйэХЬ ъ▓╜ьЪ░ яБ╡ эХиьИШые╝ ьВмьЪйэХЬ ъ▓╜ьЪ░ SELECT a.employee_id, a.first_name || тАШ тАШ || a.last_name names, ( SELECT b.department_name FROM departments b WHEREa.department_id = b.department_id ) dep_names FROM employees a WHERE a.department_id = 100; CREATE OF REPLACE FUNCTION get_dep_name (dep_id NUMBER) RETURN VARCHAR2 IS sDepName VARCHAR2(30); BEGIN SELECT department_name INTO sDepName FROM departments WHERE department_id = dep_id; RETURN sDepName; END; SELECT a.employee_id, a.first_name || тАШ тАШ || a.last_name names, get_dep_name(a.department_id) dep_names FROM employees a WHERE a.department_id = 100;
- 43. 43 ьЬДьЭШ ыСР ъ▓╜ьЪ░ьЭШ ьШИьаЬыКФ employees эЕМьЭ┤ы╕ФьЧРьДЬ ьб░ъ▒┤ьЧР ызЮыКФ ъ▓░ъ│╝ьЧР departments эЕМьЭ┤ы╕ФьЧР ьЮИыКФ ы╢АьДЬыкЕьЭД ъ░Щ ьЭ┤ ь╢ЬыаеэХШыКФ ьШИьаЬ ьЮЕыЛИыЛд . эХиьИШые╝ ьВмьЪйэХЬ ъ▓╜ьЪ░ьЭШ get_dep_name эХиьИШыКФ эММыЭ╝ып╕эД░ыбЬ ы╢АьДЬы▓ИэШ╕ъ░А ыДШьЦ┤ьШдый┤ эХ┤ыЛ╣ ы╢АьДЬы▓ИэШ╕ьЧР ызЮыКФ ы╢АьДЬыкЕьЭД ь░╛ьХД ы░ШэЩШэХШыКФ эХиьИШ ьЮЕыЛИыЛд . ыСР ъ░АьзА ъ▓╜ьЪ░ ыкиыСР ъ▓░ъ│╝ыКФ ыПЩьЭ╝эХШьзАызМ эХиьИШые╝ ьВмьЪйэХШьШАьЭД ъ▓╜ьЪ░ьЧРыКФ ьб░ьЭ╕ьЭ┤ ы░ЬьГЭэХШьзА ьХКьК╡ыЛИыЛд . ы╢АьДЬы▓ИэШ╕ые╝ эХи ьИШьЭШ эММыЭ╝ып╕эД░ыбЬ ыДШъ╕░ый┤ ъ╖╕ ы╢АьДЬы▓ИэШ╕ьЧР ыМАэХЬ ы╢АьДЬыкЕьЭД ъ░Аьа╕ьШм ы┐РьЮЕыЛИыЛд . эХиьИШые╝ ьВмьЪйэХШьШАьЭД ъ▓╜ьЪ░ ь░иэЫД ьЬаьзА ы│┤ьИШ ь░иьЫРьЧРьДЬ ьЪйьЭ┤эХШыЛдыКФ ьЮеьаРъ│╝ ьЖМьКдъ░А ыЛиьИЬэХ┤ ьзДыЛдыКФ ьЮеьаРьЭ┤ ьЮИьК╡ыЛИыЛд . ьЪ░ыжм эЪМьВмьЭШ ъ░ЩьЭА ъ▓╜ьЪ░ WNTAS ьЧРьДЬ NID эГАьЭ┤эЛАьЭД ъ░Аьа╕ьШм ъ▓╜ьЪ░ ьДЬы╕Мь┐╝ыжмыВШ ьб░ьЭ╕ьЭД ьВмьЪйэХШьзА ьХКъ│а , NID_TITLE ьЭ┤ыЮА эХиьИШые╝ ызМыУдьЦ┤ьДЬ ьВмьЪйэХШъ│а ьЮИьК╡ыЛИыЛд . Thought