Practical webcrawling with scrapy
Download as PPTX, PDF1 like407 views

This document provides an overview of practical web crawling using Scrapy, an open source framework for extracting data from websites and APIs. It discusses Scrapy concepts like XPath/CSS selectors and spiders, and how to install Scrapy, create a project structure, define items to extract, and develop a basic spider to crawl websites. The document also demonstrates some useful Scrapy tools like the scrapy shell.
1 of 17
Download to read offline















Recommended
Web 2.0 tools (1)
Web 2.0 tools (1)flo15
Ìý
This document lists and briefly describes several Web 2.0 tools that can be used for school projects including Bio cube for creating biographies, Voki for adding voice to projects, Gliffy and Bubbl.us for brainstorming and organizing ideas, WolframAlpha for answering questions, Student Publisher for creating book reports, Spruz for building websites, Quick Maps for getting directions, ºÝºÝߣbomb for making slides, Photopeach for designing collages, and ºÝºÝߣshare for sharing presentations.XPath Introduction
XPath IntroductionStuart Myles
Ìý
XPath is a language for defining parts of an XML document. It allows you to locate and operate on elements and attributes using path expressions that work like URLs or file system directories. XPath contains functions for selecting nodes, evaluating expressions, and extracting information from XML documents. It is used by several XML standards and technologies like XSLT, XQuery, XML Schema, and Schematron. The document provides an introduction to XPath basics like selecting elements, using attributes and namespaces, and built-in functions for strings, numbers, and booleans. Additional resources are listed for learning more about XPath.Scrapy
ScrapyFrancisco Sousa
Ìý
This document introduces Scrapy, an open source and collaborative framework for extracting data from websites. It discusses what Scrapy is used for, its advantages over alternatives like Beautiful Soup, and provides steps to install Scrapy and create a sample scraping project. The sample project scrapes review data from The Verge website, including the title, number of comments, and author for the first 5 review pages. The document concludes by explaining how to run the spider and store the extracted data in a file.Web scraping with Ruby
Web scraping with RubyHidehiro Nagaoka
Ìý
The document outlines a workshop on web scraping with Ruby. It introduces setting up tools for scraping, basic scraping concepts like HTML DOM and APIs, and demonstrates how to scrape websites with live code. Attendees are encouraged to try scraping on their own and given additional resources to scrape dynamic websites. The workshop is aimed at helping participants understand and enjoy web scraping.Automated Acceptance Testing from Scratch
Automated Acceptance Testing from ScratchExcella
Ìý
On March 18th, 2015 Excella's Dan Davis presented Automated Acceptance Testing from Scratch to the Tech Talk DC Meetup group.Learning to code
Learning to codeSara-Jayne Terp
Ìý
A presentation given to SIPA New Media Task Force members who wanted to start coding but weren't sure where to start. Elasticsearch PHP UG BG
Elasticsearch PHP UG BGNikolay Ignatov
Ìý
Elasticsearch is a distributed, open source search and analytics engine. It allows for real-time search, analysis, and storage of data across many nodes. Elasticsearch is the central component of the Elastic Stack, and can be easily integrated with PHP. Some potential use cases discussed include using Elasticsearch as a content hub, headless CMS, SLA monitoring system, or for asynchronous storage. The presentation provided an overview of Elasticsearch's architecture and functionality.Drupal and Elasticsearch - The "new school" search engine
Drupal and Elasticsearch - The "new school" search engineNikolay Ignatov
Ìý
This document provides an overview of Elasticsearch, including:
- Elasticsearch is a distributed, RESTful search and analytics engine that allows for real-time search, indexing, and analytics of data.
- It was created by Shay Banon and is open source, written in Java and built on Apache Lucene.
- Elasticsearch can be used to power search on Drupal sites through modules like the Elasticsearch Connector which integrate Elasticsearch with Drupal.Becoming a more productive Rails Developer
Becoming a more productive Rails DeveloperJohn McCaffrey
Ìý
A presentation by John McCaffrey of RailsPerformance.com on how to manage technical information, ask technical questions, expand Ruby and Rails knowledge, and work on interesting side projects for open source, non-profits or as a freelancerCrab - A Python Framework for Building Recommendation Systems
Crab - A Python Framework for Building Recommendation SystemsMarcel Caraciolo
Ìý
Crab is a Python framework for building recommendation engines. It began as a Mahout alternative for Python developers and is being rewritten as a Scikit-learn submodule. Crab currently features collaborative filtering algorithms and evaluation metrics. Developers are working in sprints to optimize performance by integrating Numpy and migrating Crab to work as a Scikit in order to make it faster and more accessible to the scientific community.A Year of Pyxley: My First Open Source Adventure
A Year of Pyxley: My First Open Source AdventureNick Kridler
Ìý
A quick introduction of Pyxley and the lessons learned over the last year of maintaining the package. Pyxley is a set of wrappers and helpers in Python that streamline the development of React.js based web applications driven by a Flask backend.Contributing to rails
Contributing to railsLukas Eppler
Ìý
This document provides information on contributing to the Ruby on Rails framework. It discusses why developers should contribute (e.g. giving back to an open source project they use), what types of contributions are needed (e.g. fixing bugs, writing documentation), and how to get started (e.g. setting up their development environment, downloading the Rails source code, and running tests). The document also lists some specific contribution tasks and resources for learning more about the contribution process.Scraping Scripting Hacking
Scraping Scripting HackingMike Ellis
Ìý
A whistle-stop tour through some techniques for getting at data when there's no official routes like API's, RSS, etc.Decisionstats.com Data Science Virtual Internship
Decisionstats.com Data Science Virtual InternshipAjay Ohri
Ìý
This internship report summarizes Chandan Kumar Routray's internship with Decision Stats Consultancy from June 18th to present. During his internship, Chandan learned many technical skills like analytics, web development, and blog writing. He completed daily assignments from his mentor Ajay Ohri involving learning new tools, writing blog posts, and building projects. Through this internship, Chandan gained experience with programming languages like Python, R, and JavaScript, as well as tools for data analysis, web development, cloud computing, and more. Chandan found the internship challenging but rewarding, and was offered an opportunity to continue interning with Decision Stats Consultancy.Drupal and Elasticsearch
Drupal and ElasticsearchNikolay Ignatov
Ìý
This document discusses Elasticsearch, an open source, distributed, RESTful search and analytics engine. It introduces Elasticsearch technology and explains how it works, who created it, who uses it, and why. It then covers how to install Elasticsearch, how indexing and searching are distributed across nodes, and some key APIs. Finally, it discusses full text search implementation and provides video and demo resources for learning more.Frontend as a first class citizen
Frontend as a first class citizenMarcin Grzywaczewski
Ìý
Frontend development skills are more and more demanded from our clients and stakeholders. Thanks to Facebook, they know what a dynamic UI is and they want it too in their products.
It can be a scary situation for people working mostly on a backend side of web applications. In this presentation I want to show that JavaScript can be really fun to write and mature enough to cope with backend technologies.Chris regan schema
Chris regan schemaProductCamp SoCal
Ìý
The document discusses product schema, structured data, and search engine optimization. It provides examples of using schema.org's product schema for products online. It also lists various resources for learning about schema, including blogs, tools for adding schema markup, and conferences focused on semantic web technologies and schema.TriplePlay-WebAppPenTestingTools
TriplePlay-WebAppPenTestingToolsYury Chemerkin
Ìý
This document provides an overview of the best tools for penetration testing web applications. It discusses Nikto for server enumeration and vulnerability scanning, Webscarab for intercepting requests and modifying parameters, w3af as an open source web application exploitation framework, and Firefox with extensions like Firebug and YSlow for manual testing. Commercial tools like Core Impact and Cenzic Hailstorm are also highlighted for their methodologies and capabilities. Additional resources like Samurai Linux are mentioned as a ready-to-go penetration testing environment with pre-installed web assessment tools.Prototyping like it is 2022 
Prototyping like it is 2022 Michael Yagudaev
Ìý
Iterating and shipping software quickly to help you build what users want. Keeping it simple and scaling architecture over time, not right away.TDC 2016 SP - 5 libs de teste JavaScript que você deveria conhecer
TDC 2016 SP - 5 libs de teste JavaScript que você deveria conhecerStefan Teixeira
Ìý
The document discusses 5 JavaScript testing libraries that are recommended for testing:
1. Karma - A test runner that executes unit tests in real browsers. It features live feedback on each save and integrates with various frameworks.
2. Sinon.js - The best framework for mocks, stubs, and spies. It also facilitates AJAX and fake server testing.
3. Supertest - A very simple library for testing HTTP requests independently of any framework.
4. Protractor - A framework for end-to-end testing using Selenium WebDriver. Created by the AngularJS team but also works well with non-Angular apps.
5. VisualReview-protractor - An API for Protractor thatSearch Engine Spiders
Search Engine SpidersCJ Jenkins
Ìý
Full tutorial on what spiders are, how they work, why we need them and how to create and maintain your own.Exploring Content API Options - March 23rd 2016
Exploring Content API Options - March 23rd 2016Jani Tarvainen
Ìý
Today the market is awash with options available for developers to consume content using the APIs. Some go as far as describing their offering as a CMS without the bad parts, where as some choose to provide content using a data centric API platform.
All of this while the classic Content Management System players are opening up their core via APIs and modernising their technical platforms. Is there a silver bullet for Content APIs? Let's find out!
Original presentation format available on Sway: https://sway.com/YIZfYDgcQyJwcmWIWeb scraping with BeautifulSoup, LXML, RegEx and Scrapy
Web scraping with BeautifulSoup, LXML, RegEx and ScrapyLITTINRAJAN
Ìý
Web Scraping Introduction. It will cover cover all the most available libraries and the way they can be handled to scrape our required data. Created by Littin Rajan
Apache contribution-bar camp-colombo
Apache contribution-bar camp-colomboSagara Gunathunga
Ìý
This document provides information to help individuals find ways to contribute to Apache projects. It outlines various roles and backgrounds that are welcome to contribute, such as engineers, writers, students, and more. It also provides guidance on how to get started, including finding a suitable project, participating in discussions, addressing issues, and submitting patches for review. The document emphasizes starting small, such as by helping others on mailing lists or reproducing sample issues, and provides several project-specific resources for new contributors.Platform Selection
Platform SelectionWilco van Duinkerken
Ìý
A presentation given for the course of ICT Entrepreneurship at Utrecht University. Each group of students is working on a business idea. This presentation aims to give them information on what development platforms are available to develop their prototypes.How to be a contributor to Drupal by Drupalista.me
How to be a contributor to Drupal by Drupalista.meJose palala
Ìý
This document outlines how new developers can contribute to open source projects to increase their skills and career opportunities. It encourages contributing to the Drupal project by fixing bugs, writing code, and submitting patches. The process involves finding issues to work on, learning coding standards and tools like Git, testing and reviewing patches. The creator of the site wants to help tech entrepreneurs and developers get involved in open source contributions to boost their resumes and skills.How to Teach Yourself to Code
How to Teach Yourself to CodeMattan Griffel
Ìý
The document provides guidance on learning how to code by teaching yourself Ruby on Rails. It recommends starting with Rails as it is the easiest framework to learn and allows building prototypes quickly. The document outlines a "brute force" learning approach of speeding through introductory tutorials to get exposure to concepts without worrying about not understanding everything the first time. It also recommends resources like Codecademy, Ruby Koans, and attending local meetups and hackathons for support during the learning process.

More Related Content
Similar to Practical webcrawling with scrapy (20)
Becoming a more productive Rails Developer
Becoming a more productive Rails DeveloperJohn McCaffrey
Ìý
A presentation by John McCaffrey of RailsPerformance.com on how to manage technical information, ask technical questions, expand Ruby and Rails knowledge, and work on interesting side projects for open source, non-profits or as a freelancerCrab - A Python Framework for Building Recommendation Systems
Crab - A Python Framework for Building Recommendation SystemsMarcel Caraciolo
Ìý
Crab is a Python framework for building recommendation engines. It began as a Mahout alternative for Python developers and is being rewritten as a Scikit-learn submodule. Crab currently features collaborative filtering algorithms and evaluation metrics. Developers are working in sprints to optimize performance by integrating Numpy and migrating Crab to work as a Scikit in order to make it faster and more accessible to the scientific community.A Year of Pyxley: My First Open Source Adventure
A Year of Pyxley: My First Open Source AdventureNick Kridler
Ìý
A quick introduction of Pyxley and the lessons learned over the last year of maintaining the package. Pyxley is a set of wrappers and helpers in Python that streamline the development of React.js based web applications driven by a Flask backend.Contributing to rails
Contributing to railsLukas Eppler
Ìý
This document provides information on contributing to the Ruby on Rails framework. It discusses why developers should contribute (e.g. giving back to an open source project they use), what types of contributions are needed (e.g. fixing bugs, writing documentation), and how to get started (e.g. setting up their development environment, downloading the Rails source code, and running tests). The document also lists some specific contribution tasks and resources for learning more about the contribution process.Scraping Scripting Hacking
Scraping Scripting HackingMike Ellis
Ìý
A whistle-stop tour through some techniques for getting at data when there's no official routes like API's, RSS, etc.Decisionstats.com Data Science Virtual Internship
Decisionstats.com Data Science Virtual InternshipAjay Ohri
Ìý
This internship report summarizes Chandan Kumar Routray's internship with Decision Stats Consultancy from June 18th to present. During his internship, Chandan learned many technical skills like analytics, web development, and blog writing. He completed daily assignments from his mentor Ajay Ohri involving learning new tools, writing blog posts, and building projects. Through this internship, Chandan gained experience with programming languages like Python, R, and JavaScript, as well as tools for data analysis, web development, cloud computing, and more. Chandan found the internship challenging but rewarding, and was offered an opportunity to continue interning with Decision Stats Consultancy.Drupal and Elasticsearch
Drupal and ElasticsearchNikolay Ignatov
Ìý
This document discusses Elasticsearch, an open source, distributed, RESTful search and analytics engine. It introduces Elasticsearch technology and explains how it works, who created it, who uses it, and why. It then covers how to install Elasticsearch, how indexing and searching are distributed across nodes, and some key APIs. Finally, it discusses full text search implementation and provides video and demo resources for learning more.Frontend as a first class citizen
Frontend as a first class citizenMarcin Grzywaczewski
Ìý
Frontend development skills are more and more demanded from our clients and stakeholders. Thanks to Facebook, they know what a dynamic UI is and they want it too in their products.
It can be a scary situation for people working mostly on a backend side of web applications. In this presentation I want to show that JavaScript can be really fun to write and mature enough to cope with backend technologies.Chris regan schema
Chris regan schemaProductCamp SoCal
Ìý
The document discusses product schema, structured data, and search engine optimization. It provides examples of using schema.org's product schema for products online. It also lists various resources for learning about schema, including blogs, tools for adding schema markup, and conferences focused on semantic web technologies and schema.TriplePlay-WebAppPenTestingTools
TriplePlay-WebAppPenTestingToolsYury Chemerkin
Ìý
This document provides an overview of the best tools for penetration testing web applications. It discusses Nikto for server enumeration and vulnerability scanning, Webscarab for intercepting requests and modifying parameters, w3af as an open source web application exploitation framework, and Firefox with extensions like Firebug and YSlow for manual testing. Commercial tools like Core Impact and Cenzic Hailstorm are also highlighted for their methodologies and capabilities. Additional resources like Samurai Linux are mentioned as a ready-to-go penetration testing environment with pre-installed web assessment tools.Prototyping like it is 2022
Prototyping like it is 2022 Michael Yagudaev
Ìý
Iterating and shipping software quickly to help you build what users want. Keeping it simple and scaling architecture over time, not right away.TDC 2016 SP - 5 libs de teste JavaScript que você deveria conhecer
TDC 2016 SP - 5 libs de teste JavaScript que você deveria conhecerStefan Teixeira
Ìý
The document discusses 5 JavaScript testing libraries that are recommended for testing:
1. Karma - A test runner that executes unit tests in real browsers. It features live feedback on each save and integrates with various frameworks.
2. Sinon.js - The best framework for mocks, stubs, and spies. It also facilitates AJAX and fake server testing.
3. Supertest - A very simple library for testing HTTP requests independently of any framework.
4. Protractor - A framework for end-to-end testing using Selenium WebDriver. Created by the AngularJS team but also works well with non-Angular apps.
5. VisualReview-protractor - An API for Protractor thatSearch Engine Spiders
Search Engine SpidersCJ Jenkins
Ìý
Full tutorial on what spiders are, how they work, why we need them and how to create and maintain your own.Exploring Content API Options - March 23rd 2016
Exploring Content API Options - March 23rd 2016Jani Tarvainen
Ìý
Today the market is awash with options available for developers to consume content using the APIs. Some go as far as describing their offering as a CMS without the bad parts, where as some choose to provide content using a data centric API platform.
All of this while the classic Content Management System players are opening up their core via APIs and modernising their technical platforms. Is there a silver bullet for Content APIs? Let's find out!
Original presentation format available on Sway: https://sway.com/YIZfYDgcQyJwcmWIWeb scraping with BeautifulSoup, LXML, RegEx and Scrapy
Web scraping with BeautifulSoup, LXML, RegEx and ScrapyLITTINRAJAN
Ìý
Web Scraping Introduction. It will cover cover all the most available libraries and the way they can be handled to scrape our required data. Created by Littin RajanApache contribution-bar camp-colombo
Apache contribution-bar camp-colomboSagara Gunathunga
Ìý
This document provides information to help individuals find ways to contribute to Apache projects. It outlines various roles and backgrounds that are welcome to contribute, such as engineers, writers, students, and more. It also provides guidance on how to get started, including finding a suitable project, participating in discussions, addressing issues, and submitting patches for review. The document emphasizes starting small, such as by helping others on mailing lists or reproducing sample issues, and provides several project-specific resources for new contributors.Platform Selection
Platform SelectionWilco van Duinkerken
Ìý
A presentation given for the course of ICT Entrepreneurship at Utrecht University. Each group of students is working on a business idea. This presentation aims to give them information on what development platforms are available to develop their prototypes.How to be a contributor to Drupal by Drupalista.me
How to be a contributor to Drupal by Drupalista.meJose palala
Ìý
This document outlines how new developers can contribute to open source projects to increase their skills and career opportunities. It encourages contributing to the Drupal project by fixing bugs, writing code, and submitting patches. The process involves finding issues to work on, learning coding standards and tools like Git, testing and reviewing patches. The creator of the site wants to help tech entrepreneurs and developers get involved in open source contributions to boost their resumes and skills.How to Teach Yourself to Code
How to Teach Yourself to CodeMattan Griffel
Ìý
The document provides guidance on learning how to code by teaching yourself Ruby on Rails. It recommends starting with Rails as it is the easiest framework to learn and allows building prototypes quickly. The document outlines a "brute force" learning approach of speeding through introductory tutorials to get exposure to concepts without worrying about not understanding everything the first time. It also recommends resources like Codecademy, Ruby Koans, and attending local meetups and hackathons for support during the learning process.Recently uploaded (20)
autonomous vehicle project for engineering.pdf
autonomous vehicle project for engineering.pdfJyotiLohar6
Ìý
autonomous vehicle project for engineering
15. Smart Cities Big Data, Civic Hackers, and the Quest for a New Utopia.pdf
15. Smart Cities Big Data, Civic Hackers, and the Quest for a New Utopia.pdfNgocThang9
Ìý
Smart Cities Big Data, Civic Hackers, and the Quest for a New Utopia
Industrial Valves, Instruments Products Profile
Industrial Valves, Instruments Products Profilezebcoeng
Ìý
We’re excited to share our product profile, showcasing our expertise in Industrial Valves, Instrumentation, and Hydraulic & Pneumatic Solutions.
We also supply API-approved valves from globally trusted brands, ensuring top-notch quality and internationally certified solutions. Let’s explore valuable business opportunities together!
We specialize in:
• Industrial Valves (Gate, Globe, Ball, Butterfly, Check)
• Instrumentation (Pressure Gauges, Transmitters, Flow Meters)
• Pneumatic Products (Cylinders, Solenoid Valves, Fittings)
As authorized partners of trusted global brands, we deliver high-quality solutions tailored to meet your industrial needs with seamless support.
google_developer_group_ramdeobaba_university_EXPLORE_PPT
google_developer_group_ramdeobaba_university_EXPLORE_PPTJayeshShete1
Ìý
EXPLORE 6 EXCITING DOMAINS:
1. Machine Learning: Discover the world of AI and ML!
2. App Development: Build innovative mobile apps!
3. Competitive Programming: Enhance your coding skills!
4. Web Development: Create stunning web applications!
5. Blockchain: Uncover the power of decentralized tech!
6. Cloud Computing: Explore the world of cloud infrastructure!
Join us to unravel the unexplored, network with like-minded individuals, and dive into the world of tech!How to Build a Maze Solving Robot Using Arduino
How to Build a Maze Solving Robot Using ArduinoCircuitDigest
Ìý
Learn how to make an Arduino-powered robot that can navigate mazes on its own using IR sensors and "Hand on the wall" algorithm.
This step-by-step guide will show you how to build your own maze-solving robot using Arduino UNO, three IR sensors, and basic components that you can easily find in your local electronics shop.Frankfurt University of Applied Science urkunde
Frankfurt University of Applied Science urkundeLisa Emerson
Ìý
Duplicate Frankfurt University of Applied Science urkunde, make a Frankfurt UAS degree.US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...
US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...Thane Heins NOBEL PRIZE WINNING ENERGY RESEARCHER
Ìý
Preface: The ReGenX Generator innovation operates with a US Patented Frequency Dependent Load Current Delay which delays the creation and storage of created Electromagnetic Field Energy around the exterior of the generator coil. The result is the created and Time Delayed Electromagnetic Field Energy performs any magnitude of Positive Electro-Mechanical Work at infinite efficiency on the generator's Rotating Magnetic Field, increasing its Kinetic Energy and increasing the Kinetic Energy of an EV or ICE Vehicle to any magnitude without requiring any Externally Supplied Input Energy. In Electricity Generation applications the ReGenX Generator innovation now allows all electricity to be generated at infinite efficiency requiring zero Input Energy, zero Input Energy Cost, while producing zero Greenhouse Gas Emissions, zero Air Pollution and zero Nuclear Waste during the Electricity Generation Phase. In Electric Motor operation the ReGen-X Quantum Motor now allows any magnitude of Work to be performed with zero Electric Input Energy.
Demonstration Protocol: The demonstration protocol involves three prototypes;
1. Protytpe #1, demonstrates the ReGenX Generator's Load Current Time Delay when compared to the instantaneous Load Current Sine Wave for a Conventional Generator Coil.
2. In the Conventional Faraday Generator operation the created Electromagnetic Field Energy performs Negative Work at infinite efficiency and it reduces the Kinetic Energy of the system.
3. The Magnitude of the Negative Work / System Kinetic Energy Reduction (in Joules) is equal to the Magnitude of the created Electromagnetic Field Energy (also in Joules).
4. When the Conventional Faraday Generator is placed On-Load, Negative Work is performed and the speed of the system decreases according to Lenz's Law of Induction.
5. In order to maintain the System Speed and the Electric Power magnitude to the Loads, additional Input Power must be supplied to the Prime Mover and additional Mechanical Input Power must be supplied to the Generator's Drive Shaft.
6. For example, if 100 Watts of Electric Power is delivered to the Load by the Faraday Generator, an additional >100 Watts of Mechanical Input Power must be supplied to the Generator's Drive Shaft by the Prime Mover.
7. If 1 MW of Electric Power is delivered to the Load by the Faraday Generator, an additional >1 MW Watts of Mechanical Input Power must be supplied to the Generator's Drive Shaft by the Prime Mover.
8. Generally speaking the ratio is 2 Watts of Mechanical Input Power to every 1 Watt of Electric Output Power generated.
9. The increase in Drive Shaft Mechanical Input Power is provided by the Prime Mover and the Input Energy Source which powers the Prime Mover.
10. In the Heins ReGenX Generator operation the created and Time Delayed Electromagnetic Field Energy performs Positive Work at infinite efficiency and it increases the Kinetic Energy of the system.
Wireless-Charger presentation for seminar .pdf
Wireless-Charger presentation for seminar .pdfAbhinandanMishra30
Ìý
Wireless technology used in chargerdecarbonization steel industry rev1.pptx
decarbonization steel industry rev1.pptxgonzalezolabarriaped
Ìý
Webinar Decarbonization steel industryGauges are a Pump's Best Friend - Troubleshooting and Operations - v.07
Gauges are a Pump's Best Friend - Troubleshooting and Operations - v.07Brian Gongol
Ìý
No reputable doctor would try to conduct a basic physical exam without the help of a stethoscope. That's because the stethoscope is the best tool for gaining a basic "look" inside the key systems of the human body. Gauges perform a similar function for pumping systems, allowing technicians to "see" inside the pump without having to break anything open. Knowing what to do with the information gained takes practice and systemic thinking. This is a primer in how to do that.Integration of Additive Manufacturing (AM) with IoT : A Smart Manufacturing A...
Integration of Additive Manufacturing (AM) with IoT : A Smart Manufacturing A...ASHISHDESAI85
Ìý
Combining 3D printing with Internet of Things (IoT) enables the creation of smart, connected, and customizable objects that can monitor, control, and optimize their performance, potentially revolutionizing various industries. oT-enabled 3D printers can use sensors to monitor the quality of prints during the printing process. If any defects or deviations from the desired specifications are detected, the printer can adjust its parameters in real time to ensure that the final product meets the required standards.Air pollution is contamination of the indoor or outdoor environment by any ch...
Air pollution is contamination of the indoor or outdoor environment by any ch...dhanashree78
Ìý
Air pollution is contamination of the indoor or outdoor environment by any chemical, physical or biological agent that modifies the natural characteristics of the atmosphere.
Household combustion devices, motor vehicles, industrial facilities and forest fires are common sources of air pollution. Pollutants of major public health concern include particulate matter, carbon monoxide, ozone, nitrogen dioxide and sulfur dioxide. Outdoor and indoor air pollution cause respiratory and other diseases and are important sources of morbidity and mortality.
WHO data show that almost all of the global population (99%) breathe air that exceeds WHO guideline limits and contains high levels of pollutants, with low- and middle-income countries suffering from the highest exposures.
Air quality is closely linked to the earth’s climate and ecosystems globally. Many of the drivers of air pollution (i.e. combustion of fossil fuels) are also sources of greenhouse gas emissions. Policies to reduce air pollution, therefore, offer a win-win strategy for both climate and health, lowering the burden of disease attributable to air pollution, as well as contributing to the near- and long-term mitigation of climate change.

Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...J. Agricultural Machinery
Ìý
Optimal use of resources, including energy, is one of the most important principles in modern and sustainable agricultural systems. Exergy analysis and life cycle assessment were used to study the efficient use of inputs, energy consumption reduction, and various environmental effects in the corn production system in Lorestan province, Iran. The required data were collected from farmers in Lorestan province using random sampling. The Cobb-Douglas equation and data envelopment analysis were utilized for modeling and optimizing cumulative energy and exergy consumption (CEnC and CExC) and devising strategies to mitigate the environmental impacts of corn production. The Cobb-Douglas equation results revealed that electricity, diesel fuel, and N-fertilizer were the major contributors to CExC in the corn production system. According to the Data Envelopment Analysis (DEA) results, the average efficiency of all farms in terms of CExC was 94.7% in the CCR model and 97.8% in the BCC model. Furthermore, the results indicated that there was excessive consumption of inputs, particularly potassium and phosphate fertilizers. By adopting more suitable methods based on DEA of efficient farmers, it was possible to save 6.47, 10.42, 7.40, 13.32, 31.29, 3.25, and 6.78% in the exergy consumption of diesel fuel, electricity, machinery, chemical fertilizers, biocides, seeds, and irrigation, respectively. US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...
US Patented ReGenX Generator, ReGen-X Quatum Motor EV Regenerative Accelerati...Thane Heins NOBEL PRIZE WINNING ENERGY RESEARCHER
Ìý
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...
Optimization of Cumulative Energy, Exergy Consumption and Environmental Life ...J. Agricultural Machinery
Ìý
Practical webcrawling with scrapy
- 1. Practical web crawling with Scrapy Iván Compañy @pyivanc
- 2. First of all • A complete guide for web crawling • It covers all the functionalities of Scrapy This is not about:
- 3. First of all • A good way to start with the web crawling • A way to start learning Scrapy This is about:
- 4. First of all • XPath/CSS selectors • Web spiders Some concepts
- 6. Scrapy Framework to extract information from websites (and API’s)
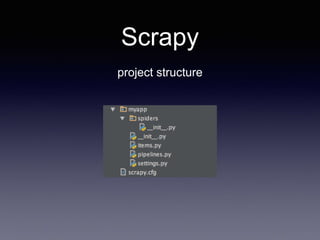
- 8. Scrapy creating your project scrapy startproject myapp
- 10. Scrapy creating your first item https://github.com/pyivanc/scrapy-class items.py
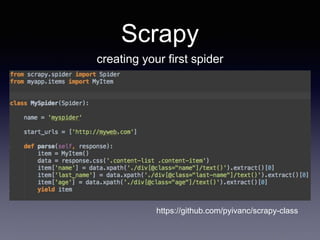
- 11. Scrapy creating your first spider https://github.com/pyivanc/scrapy-class
- 12. Scrapy Let’s see some examples!
- 13. Scrapy Useful tools scrapy shell ‘h³Ù³Ù±è://³¾²â·É±ð²ú.³¦´Ç³¾&#³æ27;
- 16. Questions?
- 17. Thank you!