Predictive Modeling using R

A project to create at least two predictive Machine Learning models to analyze a business situation. Description of Business Situation - The hiring managers of Pas de Poissen sought the guidance of a consulting firm to determine which of the nationality of the foreign workforce, entering Canada, would have the highest probability that a judge would approve their appeal to remain, and subsequently be employable in the country. Establishing a model to best determine which candidates to hire provided exceptional cost saving opportunities. In the past, if the company was informed that one of their new foreign national workers was not granted an appeal, and was actively on a fishing deployment, at times lasting for over 45 days, the trawler was forced to return to port. A vessel having to return equated to missed opportunistic revenue, as it could no longer fish, and unexpected fuel expenses to return to homeport. Furthermore, the penalty for knowing employing an illegal foreign worker was harsh from both the Canadian and U.S fisheries enforcement agencies. Deliverables - A description of the business problem we are addressing How and where we obtained the data, and the steps we went through to insure that it was "clean" A summary of modeling steps, with reference to the predictive models in the project file Assessment of the accuracy of models, with reference to project file results Our interpretation of the results of our analysis What we learnt, and how might it inform the business situation that we chose to analyze Source: Rattle Library Name: ŌĆ£Green: Refugee AppealŌĆØ Predictive Models : "Forest Model" and "Boosting Model"




![Forest
╠²Model
╠²
!ŌĆ» Create
╠²Importance
╠²level
╠²of
╠²Type
╠²1,
╠²Type
╠²2
╠²error
╠²rate
╠²by
╠²sampling
╠²data
╠²(35,35)
╠²
!ŌĆ» randomForest(formula
╠²=
╠²IMO_decision
╠²~
╠².,
╠²data
╠²=
╠²crs$dataset[crs$sample,
╠²
c(crs$input,
╠²crs$target)],ntree
╠²=
╠²421,
╠²mtry
╠²=
╠²5,
╠²sampsize
╠²=
╠²c(35,
╠²35),
╠²
importance
╠²=
╠²TRUE,
╠²replace
╠²=
╠²FALSE,
╠²na.ac?on
╠²=
╠²na.rough’¼üx)
╠²
!ŌĆ»
╠²OOB
╠²es?mate
╠²of
╠²
╠²error
╠²rate:
╠²36.48%,
╠²Type
╠²1
╠²error
╠²rate
╠²=
╠²36.4
╠²%,
╠²Type
╠²2
╠²error
╠²
rate
╠²=
╠²36.6%
╠²
!ŌĆ» OOB
╠²increased
╠².
╠²Type
╠²1
╠²increased
╠²as
╠²expected
╠².
╠²Not
╠²a
╠²good
╠²solu?on
╠²
╠²
╠²
!ŌĆ» Our
╠²Best
╠²Solu?on
╠²so
╠²far
╠²is
╠²
╠²
╠²
!ŌĆ» 95%
╠²CI:
╠²0.5462-┬ŁŌĆÉ0.6554
╠²(DeLong)
╠²
╠²
!ŌĆ» OOB
╠²es?mate
╠²of
╠²
╠²error
╠²rate:
╠²29.32%,
╠²Type
╠²1
╠²error
╠²rate
╠²=
╠²14.28%,
╠²Type
╠²2
╠²error
╠²
rate
╠²=
╠²65.6
╠²%.
╠²
!ŌĆ» Run
╠²the
╠²evalua?on
╠²on
╠²the
╠²test
╠²data
╠²set
╠²to
╠²get
╠²the
╠²’¼ünal
╠²result.
╠²
╠²
╠²
╠²
╠²
╠²](https://image.slidesharecdn.com/finalassignementcwbpptx-151103174612-lva1-app6892/85/Predictive-Modeling-using-R-5-320.jpg)

![Boos?ng
╠²Model
╠²
ŌĆóŌĆ» Run
╠²the
╠²Boos?ng
╠²model
╠²with
╠²default
╠²op?ons
╠²
ŌĆóŌĆ» OOB
╠²es?mate
╠²of
╠²
╠²error
╠²rate:
╠²21.8%
╠²
ŌĆóŌĆ» Type
╠²1
╠²error
╠²rate
╠²is
╠²6.9%,
╠²Type
╠²2
╠²error
╠²rate
╠²is
╠²61.1
╠²%.
╠²Look
╠²for
╠²error
╠²trends
╠²and
╠²importance
╠²of
╠²variables.
╠²
Analysis-┬ŁŌĆÉ
╠²Success
╠²and
╠²language
╠²are
╠²major
╠²predictors
╠²
ŌĆóŌĆ» Training
╠²Error
╠²is
╠²high
╠²ini?ally,
╠²down
╠²warding
╠²as
╠²number
╠²of
╠²itera?ons
╠²increase.
╠²
ŌĆóŌĆ» Try
╠²to
╠²look
╠²at
╠²the
╠²point
╠²where
╠²error
╠²graph
╠²becomes
╠²constant.
╠²
ŌĆóŌĆ» 1ŌĆÖs
╠²as
╠²shown
╠²in
╠²the
╠²graph
╠²depict
╠²the
╠²trend,
╠²but
╠²the
╠²trend
╠²again
╠²is
╠²changing
╠²beyond
╠²itera?on
╠²50.
╠²
ŌĆóŌĆ» Build
╠²more
╠²itera?ons
╠²to
╠²’¼ügure
╠²out
╠²the
╠²trend
╠²and
╠²the
╠²point
╠²a`er
╠²which
╠²error
╠²rate
╠²is
╠²constant.
╠²
ŌĆóŌĆ» Analysis-┬ŁŌĆÉ
╠²Success
╠²and
╠²language
╠²are
╠²major
╠²predictors
╠²
ŌĆóŌĆ» Build
╠²the
╠²model
╠²with
╠²itera?on
╠²=
╠²200
╠²
ŌĆóŌĆ» Analysis-┬ŁŌĆÉ:
╠²The
╠²trend
╠²seems
╠²clear.
╠²A`er
╠²140
╠²itera?ons,
╠²the
╠²error
╠²rate
╠²graph
╠²becomes
╠²constant.
╠²
ŌĆóŌĆ» Set
╠²the
╠²itera?ons
╠²to
╠²140
╠²and
╠²con?nue
╠²the
╠²boos?ng
╠²model.
╠²
ŌĆóŌĆ» Analysis-┬ŁŌĆÉ:
╠²OOB
╠²error
╠²is
╠²21.2
╠²%
╠²but
╠²Type
╠²
╠²2
╠²errors
╠²are
╠²very
╠²large.
╠²
╠²
ŌĆóŌĆ» AUC
╠²=68%.
╠²S?ll
╠²room
╠²for
╠²improvement.
╠²Set
╠²the
╠²importance
╠²matrix.
╠²We
╠²need
╠²less
╠²Type
╠²2
╠²error.
╠²
ŌĆóŌĆ» Call:
╠²
ada(IMO_decision
╠² ~
╠² .,
╠² data
╠² =
╠² crs$dataset[crs$train,
╠² c(crs$input,
╠²
╠² crs$target)],
╠² control
╠² =
╠²
rpart.control(maxdepth
╠²=
╠²30,
╠²cp
╠²=
╠²0.01,
╠²
╠²minsplit
╠²=
╠²20,
╠²xval
╠²=
╠²10),
╠²parms
╠²=
╠²list(split
╠²=
╠²"informa?on",
╠²
╠²loss
╠²=
╠²
matrix(c(0,
╠²1,
╠²1.5,
╠²0),
╠²byrow
╠²=
╠²TRUE,
╠²nrow
╠²=
╠²2)),
╠²iter
╠²=
╠²140)
╠²
╠²](https://image.slidesharecdn.com/finalassignementcwbpptx-151103174612-lva1-app6892/85/Predictive-Modeling-using-R-7-320.jpg)



































More Related Content
Similar to Predictive Modeling using R (20)
Recently uploaded (20)




![PLAN_OF_WORK_PPT_BY_ROHIT_BHAIRAM_--2212020201003[1] new.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/planofworkpptbyrohitbhairam-22120202010031new-250329072214-99e4fccd-thumbnail.jpg?width=560&fit=bounds)













Predictive Modeling using R
- 1. Background ╠² Pas ╠²de ╠²Poisson ╠²is ╠²a ╠²’¼üshing ╠²conglomerate ╠²headquartered ╠²in ╠²Montreal, ╠²CN. ╠² ╠²The ╠² ’¼éeet ╠²is ╠²located ╠²remotely ╠²in ╠²two ╠²loca?ons, ╠²Halifax, ╠²NS ╠²and ╠²St. ╠²JohnŌĆÖs ╠² Newfoundland. ╠² ╠²The ╠²St. ╠²JohnŌĆÖs ╠²’¼éeets ╠²primarily ╠²work ╠²the ╠²near ╠²shore ╠²’¼üshing ╠² grounds ╠²of ╠²Nova ╠²Sco?a ╠²and ╠²Newfoundland ╠²within ╠²12 ╠²nau?cal ╠²miles ╠²from ╠² shore. ╠² ╠²The ╠²Halifax ╠²loca?ons, ╠²however, ╠²have ╠²’¼üshing ╠²deployments ╠²that ╠²are ╠² located ╠²much ╠²further ╠²o’¼Ćshore, ╠²and ╠²in ╠²most ╠²cases, ╠²using ╠²U.S. ╠²territorial ╠²waters ╠² in ╠²the ╠²North ╠²Atlan?c ╠²under ╠²the ╠²CANAM ╠²bilateral ╠²agreements. ╠² ╠² ╠² The ╠²en?re ╠²crew ╠²of ╠²the ╠²St. ╠²Johns ╠²’¼éeet ╠²are ╠²Canadian ╠²residents. ╠² ╠²Hiring ╠²managers ╠² ensure ╠²that ╠²90% ╠²of ╠²the ╠²deck ╠²hands ╠²working ╠²on ╠²the ╠²Halifax ╠²’¼éeet ╠²are ╠²foreign ╠² workers ╠²as ╠²the ╠²labor ╠²rate ╠²is ╠²signi’¼ücantly ╠²lower ╠²and ╠²the ╠²turnover ╠²rate ╠²is ╠²6 ╠²?mes ╠² the ╠²rate ╠²of ╠²St. ╠²Johns ╠²because ╠²the ╠²weather ╠²is ╠²constantly ╠²rough ╠²in ╠²the ╠²North ╠² Atlan?c ╠²crea?ng ╠²excep?onally ╠²poor ╠²working ╠²condi?ons, ╠²but ╠²paying ╠²well. ╠²
- 2. Execu?ve ╠²Summary ╠² The ╠²hiring ╠²managers ╠²of ╠²Pas ╠²de ╠²Poissen ╠²sought ╠²the ╠²guidance ╠²of ╠²a ╠²consul?ng ╠² ’¼ürm ╠²to ╠²determine ╠²which ╠²of ╠²the ╠²na?onality ╠²of ╠²the ╠²foreign ╠²work ╠²force, ╠²entering ╠² Canada, ╠²would ╠²have ╠²the ╠²highest ╠²probability ╠²that ╠²a ╠²judge ╠²would ╠²approve ╠²their ╠² appeal ╠²to ╠²remain, ╠²and ╠²subsequently ╠²be ╠²employable ╠²in ╠²the ╠²country. ╠² ╠² ╠² Establishing ╠²a ╠²model ╠²to ╠²best ╠²determine ╠²which ╠²candidates ╠²to ╠²hire ╠²provided ╠² excep?onal ╠²cost ╠²saving ╠²opportuni?es. ╠² ╠²In ╠²the ╠²past, ╠²if ╠²the ╠²company ╠²was ╠² informed ╠²that ╠²one ╠²of ╠²their ╠²new ╠²foreign ╠²na?onal ╠²workers ╠²was ╠²not ╠²granted ╠²an ╠² appeal, ╠²and ╠²was ╠²ac?vely ╠²on ╠²a ╠²’¼üshing ╠²deployment, ╠²at ╠²?mes ╠²las?ng ╠²for ╠²over ╠²45 ╠² days, ╠²the ╠²trawler ╠²was ╠²forced ╠²to ╠²return ╠²to ╠²port. ╠² ╠²A ╠²vessel ╠²having ╠²to ╠²return ╠² equated ╠²to ╠²missed ╠²opportunis?c ╠²revenue, ╠²as ╠²it ╠²could ╠²no ╠²longer ╠²’¼üsh, ╠²and ╠² unexpected ╠²fuel ╠²expenses ╠²for ╠²return ╠²transit. ╠² ╠²Furthermore, ╠²the ╠²penalty ╠²for ╠² knowing ╠²employing ╠²an ╠²illegal ╠²foreign ╠²worker ╠²was ╠²harsh ╠²from ╠²both ╠²the ╠² Canadian ╠²and ╠²U.S ╠²’¼üsheries ╠²enforcement ╠²agencies. ╠²
- 3. Data ╠²Integrity ╠² ŌĆóŌĆ» Source: ╠²Ra[le ╠²Library ╠² ŌĆóŌĆ» Name: ╠²ŌĆ£Green: ╠²Refugee ╠²AppealŌĆØ ╠² ŌĆóŌĆ» ŌĆ£CleaningŌĆØ ╠²steps ╠² ŌĆóŌĆ» Used ╠²transform ╠²tag ╠²to ╠²remove ╠²missing ╠²and ╠²ignored ╠²data ╠²a`er ╠² comparing ╠²the ╠²original ╠²and ╠²ŌĆ£cleanedŌĆØ ╠²OOB ╠²error ╠²rates. ╠² ╠² Addi?onally, ╠²the ╠²categorical ╠²data ╠²ŌĆ£judgesŌĆØ ╠²was ╠²deemed ╠²to ╠²be ╠² sta?s?cally ╠²insigni’¼ücant ╠²for ╠²our ╠²purposes, ╠²hence ╠²it ╠²was ╠²omi[ed ╠² thus ╠²increasing ╠²the ╠²integrity ╠²of ╠²the ╠²the ╠²dataset. ╠² ŌĆóŌĆ» Steps: ╠² ╠²In ╠²order ╠²to ╠²ful’¼üll ╠²the ╠²hiring ╠²strategy ╠²we ╠²targeted ╠²informa?on, ╠²from ╠² the ╠²data ╠²(using ╠²ra[le, ╠²R ╠²and ╠²excel), ╠²that ╠²would ╠²serve ╠²to ╠²determine ╠²the ╠² informa?on ╠²necessary ╠²to ╠²depict ╠²future ╠²hires ╠²based ╠²on ╠²the ╠²probability ╠²to ╠² determine ╠²an ╠²approved ╠²appeal. ╠² ╠²
- 4. Forest ╠²Model ╠² !ŌĆ» Imported ╠²the ╠²data ╠²and ╠²Rescaled ╠² ╠² !ŌĆ» Created ╠²a ╠²Forest ╠²model ╠²with ╠²default ╠²op?ons ╠² !ŌĆ» OOB ╠²error ╠²=30.62% ╠², ╠²Type ╠²1= ╠²16.12 ╠²% ╠²and ╠²Type ╠²2 ╠²=65.5 ╠²%error, ╠²AUC ╠²= ╠²0.644 ╠² !ŌĆ» Our ╠²business ╠²requires ╠²more ╠²focus ╠²on ╠²Type ╠²1 ╠²error ╠²rather ╠²than ╠²Type ╠²2 ╠²error ╠² !ŌĆ» Checked ╠²the ╠²trend ╠²of ╠²errors ╠²and ╠²importance ╠² !ŌĆ» Created ╠²a ╠²sample ╠²of ╠²35,35 ╠² !ŌĆ» OOB ╠²es?mate ╠²of ╠² ╠²error ╠²rate: ╠²35.83%, ╠²Type ╠²1 ╠²error ╠²rate ╠²= ╠²35.02%, ╠²Type ╠²2 ╠²error ╠²rate ╠²= ╠² ╠² 37.77%, ╠²AUC ╠²= ╠²0.653 ╠² !ŌĆ» Error ╠²rate ╠²increased, ╠²Type ╠²1 ╠²increased-┬ŁŌĆÉ ╠²not ╠²good ╠² !ŌĆ» No ╠²major ╠²change, ╠²although ╠²type ╠²2 ╠²decreased ╠² !ŌĆ» Look ╠²for ╠²a ╠²be[er ╠²one. ╠²Prune ╠²the ╠²trees ╠²at ╠²minimum ╠²complexity ╠² !ŌĆ» Here ╠²tree ╠²= ╠²421 ╠²and ╠²complexity ╠²= ╠²0.2913 ╠² !ŌĆ» Now, ╠²OOB ╠²es?mate ╠²of ╠² ╠²error ╠²rate: ╠²29.32% ╠², ╠²AUC ╠²= ╠²0.646, ╠²Type ╠²1 ╠²error ╠²= ╠²14.28571%, ╠² Type ╠²2 ╠²error= ╠²65.55% ╠² ╠² !ŌĆ» Type ╠²2 ╠²is ╠²s?ll ╠²large ╠²but ╠²we ╠²are ╠²not ╠²much ╠²concerned ╠²about ╠²that. ╠² !ŌĆ» Best ╠²model ╠²so ╠²far ╠²
- 5. Forest ╠²Model ╠² !ŌĆ» Create ╠²Importance ╠²level ╠²of ╠²Type ╠²1, ╠²Type ╠²2 ╠²error ╠²rate ╠²by ╠²sampling ╠²data ╠²(35,35) ╠² !ŌĆ» randomForest(formula ╠²= ╠²IMO_decision ╠²~ ╠²., ╠²data ╠²= ╠²crs$dataset[crs$sample, ╠² c(crs$input, ╠²crs$target)],ntree ╠²= ╠²421, ╠²mtry ╠²= ╠²5, ╠²sampsize ╠²= ╠²c(35, ╠²35), ╠² importance ╠²= ╠²TRUE, ╠²replace ╠²= ╠²FALSE, ╠²na.ac?on ╠²= ╠²na.rough’¼üx) ╠² !ŌĆ» ╠²OOB ╠²es?mate ╠²of ╠² ╠²error ╠²rate: ╠²36.48%, ╠²Type ╠²1 ╠²error ╠²rate ╠²= ╠²36.4 ╠²%, ╠²Type ╠²2 ╠²error ╠² rate ╠²= ╠²36.6% ╠² !ŌĆ» OOB ╠²increased ╠². ╠²Type ╠²1 ╠²increased ╠²as ╠²expected ╠². ╠²Not ╠²a ╠²good ╠²solu?on ╠² ╠² ╠² !ŌĆ» Our ╠²Best ╠²Solu?on ╠²so ╠²far ╠²is ╠² ╠² ╠² !ŌĆ» 95% ╠²CI: ╠²0.5462-┬ŁŌĆÉ0.6554 ╠²(DeLong) ╠² ╠² !ŌĆ» OOB ╠²es?mate ╠²of ╠² ╠²error ╠²rate: ╠²29.32%, ╠²Type ╠²1 ╠²error ╠²rate ╠²= ╠²14.28%, ╠²Type ╠²2 ╠²error ╠² rate ╠²= ╠²65.6 ╠²%. ╠² !ŌĆ» Run ╠²the ╠²evalua?on ╠²on ╠²the ╠²test ╠²data ╠²set ╠²to ╠²get ╠²the ╠²’¼ünal ╠²result. ╠² ╠² ╠² ╠² ╠² ╠²
- 6. Final ╠²Confusion ╠²Matrix-┬ŁŌĆÉ ╠²Forest ╠²Model ╠²
- 7. Boos?ng ╠²Model ╠² ŌĆóŌĆ» Run ╠²the ╠²Boos?ng ╠²model ╠²with ╠²default ╠²op?ons ╠² ŌĆóŌĆ» OOB ╠²es?mate ╠²of ╠² ╠²error ╠²rate: ╠²21.8% ╠² ŌĆóŌĆ» Type ╠²1 ╠²error ╠²rate ╠²is ╠²6.9%, ╠²Type ╠²2 ╠²error ╠²rate ╠²is ╠²61.1 ╠²%. ╠²Look ╠²for ╠²error ╠²trends ╠²and ╠²importance ╠²of ╠²variables. ╠² Analysis-┬ŁŌĆÉ ╠²Success ╠²and ╠²language ╠²are ╠²major ╠²predictors ╠² ŌĆóŌĆ» Training ╠²Error ╠²is ╠²high ╠²ini?ally, ╠²down ╠²warding ╠²as ╠²number ╠²of ╠²itera?ons ╠²increase. ╠² ŌĆóŌĆ» Try ╠²to ╠²look ╠²at ╠²the ╠²point ╠²where ╠²error ╠²graph ╠²becomes ╠²constant. ╠² ŌĆóŌĆ» 1ŌĆÖs ╠²as ╠²shown ╠²in ╠²the ╠²graph ╠²depict ╠²the ╠²trend, ╠²but ╠²the ╠²trend ╠²again ╠²is ╠²changing ╠²beyond ╠²itera?on ╠²50. ╠² ŌĆóŌĆ» Build ╠²more ╠²itera?ons ╠²to ╠²’¼ügure ╠²out ╠²the ╠²trend ╠²and ╠²the ╠²point ╠²a`er ╠²which ╠²error ╠²rate ╠²is ╠²constant. ╠² ŌĆóŌĆ» Analysis-┬ŁŌĆÉ ╠²Success ╠²and ╠²language ╠²are ╠²major ╠²predictors ╠² ŌĆóŌĆ» Build ╠²the ╠²model ╠²with ╠²itera?on ╠²= ╠²200 ╠² ŌĆóŌĆ» Analysis-┬ŁŌĆÉ: ╠²The ╠²trend ╠²seems ╠²clear. ╠²A`er ╠²140 ╠²itera?ons, ╠²the ╠²error ╠²rate ╠²graph ╠²becomes ╠²constant. ╠² ŌĆóŌĆ» Set ╠²the ╠²itera?ons ╠²to ╠²140 ╠²and ╠²con?nue ╠²the ╠²boos?ng ╠²model. ╠² ŌĆóŌĆ» Analysis-┬ŁŌĆÉ: ╠²OOB ╠²error ╠²is ╠²21.2 ╠²% ╠²but ╠²Type ╠² ╠²2 ╠²errors ╠²are ╠²very ╠²large. ╠² ╠² ŌĆóŌĆ» AUC ╠²=68%. ╠²S?ll ╠²room ╠²for ╠²improvement. ╠²Set ╠²the ╠²importance ╠²matrix. ╠²We ╠²need ╠²less ╠²Type ╠²2 ╠²error. ╠² ŌĆóŌĆ» Call: ╠² ada(IMO_decision ╠² ~ ╠² ., ╠² data ╠² = ╠² crs$dataset[crs$train, ╠² c(crs$input, ╠² ╠² crs$target)], ╠² control ╠² = ╠² rpart.control(maxdepth ╠²= ╠²30, ╠²cp ╠²= ╠²0.01, ╠² ╠²minsplit ╠²= ╠²20, ╠²xval ╠²= ╠²10), ╠²parms ╠²= ╠²list(split ╠²= ╠²"informa?on", ╠² ╠²loss ╠²= ╠² matrix(c(0, ╠²1, ╠²1.5, ╠²0), ╠²byrow ╠²= ╠²TRUE, ╠²nrow ╠²= ╠²2)), ╠²iter ╠²= ╠²140) ╠² ╠²
- 8. Final ╠²Confusion ╠²Matrix-┬ŁŌĆÉ ╠²Boos?ng ╠² Model ╠² ŌĆóŌĆ» ╠² ╠² ╠² ╠² ╠² ╠² ╠² ŌĆóŌĆ» Analysis-┬ŁŌĆÉ: ╠²Best ╠²so ╠²far, ╠²although ╠²type ╠²2 ╠²error ╠²is ╠² s?ll ╠²big ╠² ╠² ╠² ŌĆóŌĆ» Giving ╠²more ╠²importance ╠²doesnŌĆÖt ╠²help ╠² ╠² ╠² ŌĆóŌĆ» No ╠²major ╠²change ╠²in ╠²ROC. ╠²
- 9. Comparison ╠²of ╠²Models ╠² Forest ╠²Model ╠² Boos,ng ╠²Model ╠²
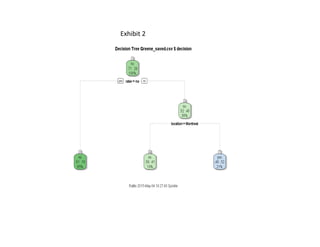
- 10. Conclusion ╠² ╠² ╠² ╠² ╠²With ╠²the ╠²best ╠²dataset, ╠²it ╠²shows ╠²that ╠²there ╠²is ╠²a ╠²strong ╠²sta?s?cal ╠²signi’¼ücance ╠²that ╠² Czechoslovakia, ╠²exhibit ╠²1, ╠²is ╠²the ╠²na?on ╠²with ╠²the ╠²highest ╠²probability ╠²of ╠²winning ╠² appeal ╠²based ╠²on ╠²data ╠²analyzed ╠²in ╠²MS ╠²Excel. ╠² ╠²Furthermore, ╠²exhibit ╠²2 ╠²shows ╠²29% ╠²of ╠² all ╠²applicants ╠²are ╠²denied ╠²their ╠²appeal. ╠² ╠²Of ╠²those ╠²the ╠²Rater, ╠²person ╠²who ╠²determines ╠² the ╠²merit ╠²of ╠²their ╠²case ╠²going ╠²forward ╠²predicts ╠²with, ╠²an ╠²81% ╠²con’¼üdence ╠²rate ╠²that, ╠² when ╠²he ╠²or ╠²she ╠²predicts ╠²a ╠²appeal ╠²denial, ╠²it ╠²is ╠²the ╠²correct ╠²predic?on, ╠²conversely ╠² they ╠²are ╠²only ╠²correct ╠²48% ╠²of ╠²the ╠²?me ╠²when ╠²they ╠²predict ╠²an ╠²awarded ╠²appeal ╠²by ╠²the ╠² judge. ╠² ╠²Finally, ╠²the ╠²data ╠²shows ╠²that ╠²most ╠²applicants ╠²the ╠²seek ╠²an ╠²appeal ╠²have ╠²a ╠² higher ╠²approval ╠²probability ╠²with ╠²the ╠²courts ╠²in ╠²Montreal ╠²and ╠²not ╠²Toronto. ╠² ╠² ╠² ╠² ╠² ╠²As ╠²with ╠²the ╠²Appeal ╠²data ╠²(above) ╠²the ╠²same ╠²inferences ╠²can ╠²be ╠²established ╠²with ╠² individual ╠²Judge ╠²data. ╠²For ╠²the ╠²judges ╠²tree, ╠²exhibit ╠²3, ╠²if ╠²we ╠²assume ╠²that ╠²the ╠²rater ╠² predicts ╠²success ╠²for ╠²33-┬ŁŌĆÉ34% ╠²of ╠²claimants, ╠²72% ╠²of ╠²those ╠²posi?ve ╠²predic?ons ╠²are ╠² cases ╠²that ╠²are ╠²to ╠²be ╠²heard ╠²by ╠²judges ╠²that ╠²ARE ╠²NOT ╠²Heald, ╠²Hugessen, ╠²Iacobucci, ╠² MacGuigan, ╠²Pra[e, ╠²and ╠²Stone. ╠²We ╠²can ╠²infer ╠²that ╠²Desjardins, ╠²Mahoney, ╠²Marceau, ╠² and ╠²Urie ╠²ARE ╠²judges ╠²that ╠²will ╠²have ╠²the ╠²highest ╠²probability ╠²of ╠²ruling ╠²posi?ve ╠²on ╠²an ╠² appeal. ╠² ╠²Therefore, ╠²as ╠²Desjardins ╠²is ╠²from ╠²Montreal ╠²and ╠²rules ╠²favorably ╠²on ╠² Czechoslovakian ╠²na?onals, ╠²it ╠²would ╠²behoove ╠²the ╠²company ╠²to ╠²create ╠²a ╠²goal ╠² congruent ╠²strategy ╠²that ╠²favors ╠²those ╠²results. ╠²
- 11. Exhibit ╠²1 ╠² Appeal ╠²Rate ╠²by ╠²Na?on ╠² NATION ╠² APPROVED ╠²APPEAL ╠²RATE ╠² CZECHOSLOVAKIA ╠² 73% ╠² SRI ╠²LANKA ╠² 36% ╠² EL ╠²SALVADOR ╠² 36% ╠² ARGENTINA ╠² 25% ╠² IRAN ╠² 25% ╠² CHINA ╠² 22% ╠² BULGARIA ╠² 7% ╠²
- 12. Exhibit ╠²2 ╠²
- 13. Exhibit ╠²3 ╠²