PyCon Korea 2015: нғҗмғүм ҒмңјлЎң нҒ° лҚ°мқҙн„° 분м„қн•ҳкё°
68 likes7,045 views

2015л…„ 8мӣ” 30мқјм—җ PyCon Koreaм—җм„ң л°ңн‘ңн•ң "нғҗмғүм ҒмңјлЎң нҒ° лҚ°мқҙн„° 분м„қн•ҳкё°" л°ңн‘ңмһҗлЈҢмһ…лӢҲлӢӨ. 분мһҗмғқл¬јн•ҷм—җм„ң л§Һмқҙ м“°мқҙлҠ” нҒ° лҚ°мқҙн„° 분м„қлҸ„кө¬л“Өмқ„ мҶҢк°ңн•©лӢҲлӢӨ.

































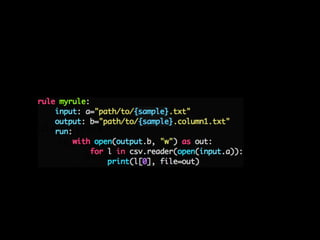
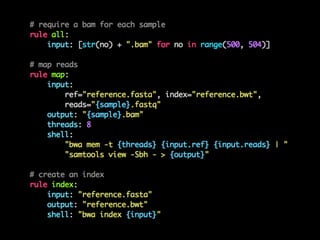
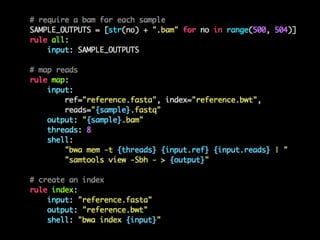






























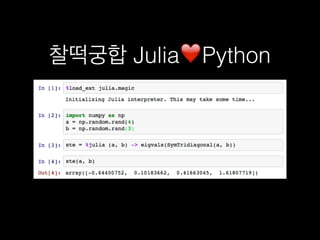
![def water(seq1, seq2):
m, n = len(seq1), len(seq2) # length of two sequences
# Generate DP table and traceback path pointer matrix
score = zeros((m+1, n+1)) # the DP table
pointer = zeros((m+1, n+1)) # to store the traceback path
max_score = 0 # initial maximum score in DP table
# Calculate DP table and mark pointers
for i in range(1, m + 1):
for j in range(1, n + 1):
score_diagonal = score[i-1][j-1] + match_score(seq1[i-1], seq2[j-1])
score_up = score[i][j-1] + gap_penalty
score_left = score[i-1][j] + gap_penalty
score[i][j] = max(0,score_left, score_up, score_diagonal)
if score[i][j] == 0:
pointer[i][j] = 0 # 0 means end of the path
if score[i][j] == score_left:
pointer[i][j] = 1 # 1 means trace up
if score[i][j] == score_up:
pointer[i][j] = 2 # 2 means trace left
if score[i][j] == score_diagonal:
pointer[i][j] = 3 # 3 means trace diagonal
if score[i][j] >= max_score:
max_i = i
max_j = j
max_score = score[i][j];
https://github.com/alevchuk/pairwise-alignment-in-python](https://image.slidesharecdn.com/pyconkr2015-exploratorydataanalysis-150831023201-lva1-app6891/85/PyCon-Korea-2015-89-320.jpg)

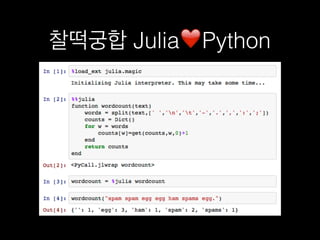
![# precell
precell(::Void) = PreCell([][:,:], 0, 0)
function precell(el::AbstractString)
if contains(el, "n")
a = map(split(el, "n")) do x
width = strwidth(x)
string(x, repeat(" ", width-length(x)))
end[:, :]
m,n = size(a)
PreCell(a, maximum(map(length, a)), m)
else
width = strwidth(el)
PreCell([string(el, repeat(" ", width-length(el)))][:,:], width, 1)
end
end
part of Millboard.jl by wookay](https://image.slidesharecdn.com/pyconkr2015-exploratorydataanalysis-150831023201-lva1-app6891/85/PyCon-Korea-2015-94-320.jpg)







PyCon Korea 2015: нғҗмғүм ҒмңјлЎң нҒ° лҚ°мқҙн„° 분м„қн•ҳкё°
- 1. нғҗмғүм ҒмңјлЎң нҒ° лҚ°мқҙн„° 분м„қн•ҳкё° мһҘнҳңмӢқ кё°мҙҲкіјн•ҷм—°кө¬мӣҗ RNAм—°кө¬лӢЁ л°°кІҪ мқҙлҜём§Җ мң„м№ҳ: http://4.bp.blogspot.com/-bB4jFkQ_jBk/T70ipuyFn6I/AAAAAAAAAOE/cnbxI03ve0Y/s1600/ snake_pile_2crop+by+Tracy+Langkilde.jpg
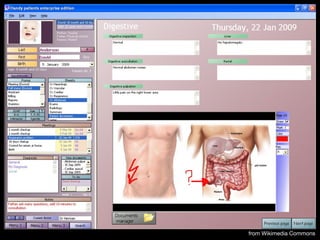
- 2. Electronic Health Records (EHR) л°°кІҪ мқҙлҜём§Җ мң„м№ҳ: http://www.trbimg.com/img-552d5b6b/turbine/la-sci-sn-medical-records-breaches-20150414-001/800/800x450
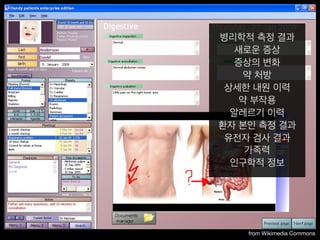
- 4. from Wikimedia Commons лі‘лҰ¬н•ҷм Ғ мёЎм • кІ°кіј мғҲлЎңмҡҙ мҰқмғҒ мҰқмғҒмқҳ ліҖнҷ” м•Ҫ мІҳл°© мғҒм„ён•ң лӮҙмӣҗ мқҙл Ҙ м•Ҫ л¶Җмһ‘мҡ© м•Ңл ҲлҘҙкё° мқҙл Ҙ нҷҳмһҗ ліёмқё мёЎм • кІ°кіј мң м „мһҗ кІҖмӮ¬ кІ°кіј к°ҖмЎұл Ҙ мқёкө¬н•ҷм Ғ м •ліҙ
- 5. н•ҳлІ„л“ң мқҳлҢҖ Isaac Kohane к·ёлЈ№ к·ёлЈ№ лӢЁмІҙ мӮ¬м§„
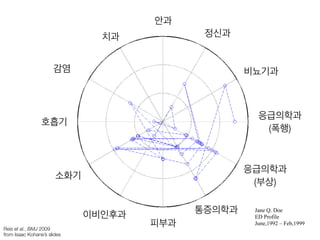
- 6. нҳёнқЎкё° Jane Q. Doe ED Profile June,1992 вҖ“ Feb,1999 Reis et al., BMJ 2009 from Isaac KohaneвҖҷs slides к°җм—ј м№ҳкіј м•Ҳкіј м •мӢ кіј 비лҮЁкё°кіј мҶҢнҷ”кё° мқҙ비мқёнӣ„кіј н”јл¶Җкіј нҶөмҰқмқҳн•ҷкіј мқ‘кёүмқҳн•ҷкіј (л¶ҖмғҒ) мқ‘кёүмқҳн•ҷкіј (нҸӯн–ү)
- 7. 6 к°Җм •нҸӯл Ҙ domestic violence л°°кІҪ мқҙлҜём§Җ мң„м№ҳ: https://garyullah.п¬Ғles.wordpress.com/2015/01/man-with-clenched-п¬Ғst-an-014.jpg
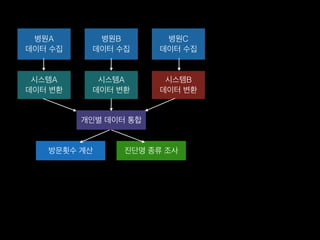
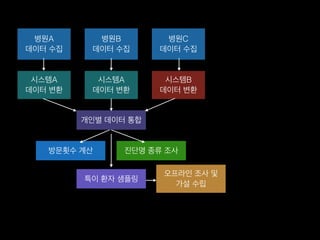
- 8. лі‘мӣҗA лҚ°мқҙн„° мҲҳ집 лі‘мӣҗB лҚ°мқҙн„° мҲҳ집 лі‘мӣҗC лҚ°мқҙн„° мҲҳ집 мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңB лҚ°мқҙн„° ліҖнҷҳ к°ңмқёлі„ лҚ°мқҙн„° нҶөн•© л°©л¬ёнҡҹмҲҳ кі„мӮ° 진лӢЁлӘ… мў…лҘҳ мЎ°мӮ¬
- 9. лі‘мӣҗA лҚ°мқҙн„° мҲҳ집 лі‘мӣҗB лҚ°мқҙн„° мҲҳ집 лі‘мӣҗC лҚ°мқҙн„° мҲҳ집 мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңB лҚ°мқҙн„° ліҖнҷҳ к°ңмқёлі„ лҚ°мқҙн„° нҶөн•© л°©л¬ёнҡҹмҲҳ кі„мӮ° 진лӢЁлӘ… мў…лҘҳ мЎ°мӮ¬ нҠ№мқҙ нҷҳмһҗ мғҳн”Ңл§Ғ мҳӨн”„лқјмқё мЎ°мӮ¬ л°Ҹ к°Җм„Ө мҲҳлҰҪ
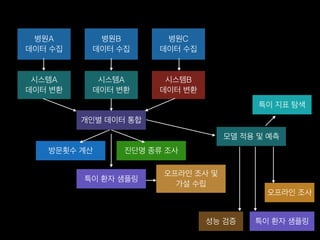
- 10. лі‘мӣҗA лҚ°мқҙн„° мҲҳ집 лі‘мӣҗB лҚ°мқҙн„° мҲҳ집 лі‘мӣҗC лҚ°мқҙн„° мҲҳ집 мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңB лҚ°мқҙн„° ліҖнҷҳ к°ңмқёлі„ лҚ°мқҙн„° нҶөн•© л°©л¬ёнҡҹмҲҳ кі„мӮ° 진лӢЁлӘ… мў…лҘҳ мЎ°мӮ¬ нҠ№мқҙ нҷҳмһҗ мғҳн”Ңл§Ғ мҳӨн”„лқјмқё мЎ°мӮ¬ л°Ҹ к°Җм„Ө мҲҳлҰҪ лӘЁлҚё м Ғмҡ© л°Ҹ мҳҲмёЎ м„ұлҠҘ кІҖмҰқ нҠ№мқҙ нҷҳмһҗ мғҳн”Ңл§Ғ мҳӨн”„лқјмқё мЎ°мӮ¬ нҠ№мқҙ м§Җн‘ң нғҗмғү
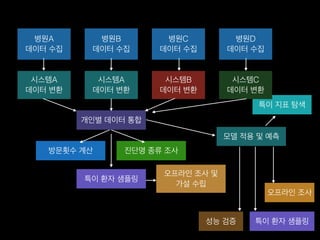
- 11. лі‘мӣҗA лҚ°мқҙн„° мҲҳ집 лі‘мӣҗB лҚ°мқҙн„° мҲҳ집 лі‘мӣҗC лҚ°мқҙн„° мҲҳ집 мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңA лҚ°мқҙн„° ліҖнҷҳ мӢңмҠӨн…ңB лҚ°мқҙн„° ліҖнҷҳ к°ңмқёлі„ лҚ°мқҙн„° нҶөн•© л°©л¬ёнҡҹмҲҳ кі„мӮ° 진лӢЁлӘ… мў…лҘҳ мЎ°мӮ¬ нҠ№мқҙ нҷҳмһҗ мғҳн”Ңл§Ғ мҳӨн”„лқјмқё мЎ°мӮ¬ л°Ҹ к°Җм„Ө мҲҳлҰҪ лӘЁлҚё м Ғмҡ© л°Ҹ мҳҲмёЎ м„ұлҠҘ кІҖмҰқ нҠ№мқҙ нҷҳмһҗ мғҳн”Ңл§Ғ мҳӨн”„лқјмқё мЎ°мӮ¬ нҠ№мқҙ м§Җн‘ң нғҗмғү лі‘мӣҗD лҚ°мқҙн„° мҲҳ집 мӢңмҠӨн…ңC лҚ°мқҙн„° ліҖнҷҳ
- 12. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ
- 13. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ).
- 14. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ.
- 15. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ.
- 16. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ.
- 17. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё
- 18. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ!
- 19. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ! мҪ”л“ң 추к°Җк°Җ л§Өмҡ° к°„нҺё
- 20. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ! мҪ”л“ң 추к°Җк°Җ л§Өмҡ° к°„нҺё н”„л Ҳмһ„мӣҢнҒ¬к°Җ мң м—°н•ҳкі м„ұмҲҷн•ҙм•ј н•Ё
- 21. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ! мҪ”л“ң 추к°Җк°Җ л§Өмҡ° к°„нҺё н”„л Ҳмһ„мӣҢнҒ¬к°Җ мң м—°н•ҳкі м„ұмҲҷн•ҙм•ј н•Ё лҚ°мқҙн„°к°Җ мһ‘м§ҖлҠ” м•ҠлӢӨ.
- 22. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ! мҪ”л“ң 추к°Җк°Җ л§Өмҡ° к°„нҺё н”„л Ҳмһ„мӣҢнҒ¬к°Җ мң м—°н•ҳкі м„ұмҲҷн•ҙм•ј н•Ё лҚ°мқҙн„°к°Җ мһ‘м§ҖлҠ” м•ҠлӢӨ. м ҒлӢ№нһҲ л№Ёлқјм•ј н•Ё
- 23. Jupyter Notebook
- 26. мқёмғқ
- 28. мқёмғқ JupyterмҷҖ н•Ёк»ҳ рҹҳҒрҹҳ„рҹҳҖрҹҳӢрҹҳҚ Jupyter м“°кё° м „ рҹҳӮрҹҳ‘рҹҳ–рҹҳҘрҹҳЁ
- 29. мқёмғқ pandasмҷҖ н•Ёк»ҳ рҹҳҒрҹҳ„рҹҳҖрҹҳӢрҹҳҚ pandas м“°кё° м „ рҹҳӮрҹҳ‘рҹҳ–рҹҳҘрҹҳЁ
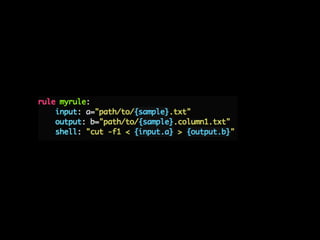
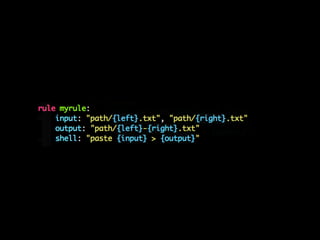
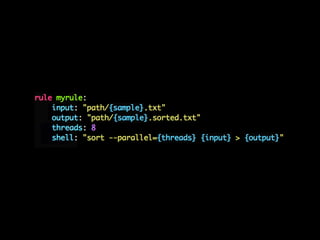
- 30. Snakemake
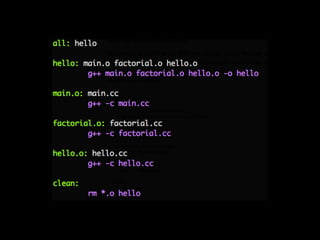
- 33. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ•
- 34. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ
- 35. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ
- 36. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ
- 37. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ”
- 38. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ” makeк°Җ м•Ҳ мўӢмқҖ кІғ
- 39. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ” makeк°Җ м•Ҳ мўӢмқҖ кІғ - мқҙмғҒн•ҳкі лӘ»мғқкёҙ л¬ёлІ•
- 40. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ” makeк°Җ м•Ҳ мўӢмқҖ кІғ - мқҙмғҒн•ҳкі лӘ»мғқкёҙ л¬ёлІ• - мҠӨнҒ¬лҰҪнҢ…мқҙ л§Өмҡ° м ңн•ңм Ғмһ„
- 41. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ” makeк°Җ м•Ҳ мўӢмқҖ кІғ - мқҙмғҒн•ҳкі лӘ»мғқкёҙ л¬ёлІ• - мҠӨнҒ¬лҰҪнҢ…мқҙ л§Өмҡ° м ңн•ңм Ғмһ„ - нҢҢмқјмқҙлҰ„м—җ мҷҖмқјл“ңм№ҙл“ң л°Ҹ нҢЁн„ҙ лӘ» м”Җ
- 42. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ” makeк°Җ м•Ҳ мўӢмқҖ кІғ - мқҙмғҒн•ҳкі лӘ»мғқкёҙ л¬ёлІ• - мҠӨнҒ¬лҰҪнҢ…мқҙ л§Өмҡ° м ңн•ңм Ғмһ„ - нҢҢмқјмқҙлҰ„м—җ мҷҖмқјл“ңм№ҙл“ң л°Ҹ нҢЁн„ҙ лӘ» м”Җ - л¶ҖмЎұн•ң лі‘л ¬нҷ”, нҒҙлҹ¬мҠӨн„° м§Җмӣҗ
- 43. makeк°Җ мўӢмқҖ кІғ - м•„мЈј к°„кІ°н•ң л¬ёлІ• - к°ҖліҚлӢӨ - нҢҢмқј кё°л°ҳ мқҳмЎҙм„ұ - вҖңк·ңм№ҷвҖқ - лі‘л ¬нҷ” makeк°Җ м•Ҳ мўӢмқҖ кІғ - мқҙмғҒн•ҳкі лӘ»мғқкёҙ л¬ёлІ• - мҠӨнҒ¬лҰҪнҢ…мқҙ л§Өмҡ° м ңн•ңм Ғмһ„ - нҢҢмқјмқҙлҰ„м—җ мҷҖмқјл“ңм№ҙл“ң л°Ҹ нҢЁн„ҙ лӘ» м”Җ - л¶ҖмЎұн•ң лі‘л ¬нҷ”, нҒҙлҹ¬мҠӨн„° м§Җмӣҗ - нҳ„лҢҖкіјн•ҷмқҳ нҳңнғқмқ„ л°ӣм§Җ лӘ»н•Ё
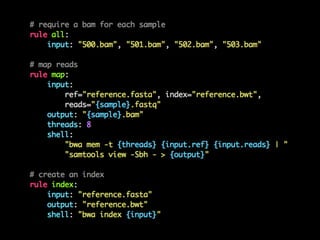
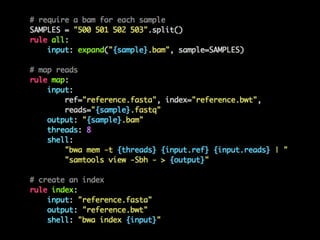
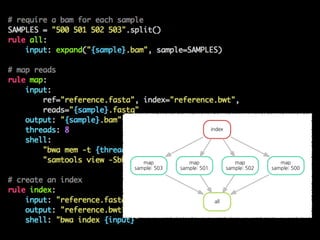
- 54. map sample: 503 all map sample: 501 index map sample: 502 map sample: 500
- 56. makeмҷҖ л§Ҳм°¬к°Җм§ҖлЎң - мқҳмЎҙм„ұмқҙ м—ҶлҠ” мһ‘м—…мқҖ лі‘л ¬лЎң мӢӨн–үлҗЁ
- 57. makeмҷҖ л§Ҳм°¬к°Җм§ҖлЎң - мқҳмЎҙм„ұмқҙ м—ҶлҠ” мһ‘м—…мқҖ лі‘л ¬лЎң мӢӨн–үлҗЁ - мқҙлҜё мһҲлҠ” мғҲ нҢҢмқјмқҖ л¬ҙмӢңн•ҳкі м§ҖлӮҳк°җ
- 58. makeмҷҖ л§Ҳм°¬к°Җм§ҖлЎң - мқҳмЎҙм„ұмқҙ м—ҶлҠ” мһ‘м—…мқҖ лі‘л ¬лЎң мӢӨн–үлҗЁ - мқҙлҜё мһҲлҠ” мғҲ нҢҢмқјмқҖ л¬ҙмӢңн•ҳкі м§ҖлӮҳк°җ # мҳҲ비 мӢӨн–ү $ snakemake -n
- 59. makeмҷҖ л§Ҳм°¬к°Җм§ҖлЎң - мқҳмЎҙм„ұмқҙ м—ҶлҠ” мһ‘м—…мқҖ лі‘л ¬лЎң мӢӨн–үлҗЁ - мқҙлҜё мһҲлҠ” мғҲ нҢҢмқјмқҖ л¬ҙмӢңн•ҳкі м§ҖлӮҳк°җ # мҳҲ비 мӢӨн–ү $ snakemake -n # мөңлҢҖ 8мҪ”м–ҙк№Ңм§Җ мӮ¬мҡ©н•ҙм„ң лі‘л ¬лЎң лҸҢлҰј $ snakemake --cores 8
- 60. makeмҷҖ л§Ҳм°¬к°Җм§ҖлЎң - мқҳмЎҙм„ұмқҙ м—ҶлҠ” мһ‘м—…мқҖ лі‘л ¬лЎң мӢӨн–үлҗЁ - мқҙлҜё мһҲлҠ” мғҲ нҢҢмқјмқҖ л¬ҙмӢңн•ҳкі м§ҖлӮҳк°җ # мҳҲ비 мӢӨн–ү $ snakemake -n # мөңлҢҖ 8мҪ”м–ҙк№Ңм§Җ мӮ¬мҡ©н•ҙм„ң лі‘л ¬лЎң лҸҢлҰј $ snakemake --cores 8 # нҒҙлҹ¬мҠӨн„°м—җм„ң мөңлҢҖ 20к°ң мһ‘м—…к№Ңм§Җ нҒҗм—җ л„Јкі лҸҢлҰј $ snakemake --jobs 20 --cluster вҖңqsub -pe threaded {threads}вҖқ
- 61. makeмҷҖ л§Ҳм°¬к°Җм§ҖлЎң - мқҳмЎҙм„ұмқҙ м—ҶлҠ” мһ‘м—…мқҖ лі‘л ¬лЎң мӢӨн–үлҗЁ - мқҙлҜё мһҲлҠ” мғҲ нҢҢмқјмқҖ л¬ҙмӢңн•ҳкі м§ҖлӮҳк°җ # мҳҲ비 мӢӨн–ү $ snakemake -n # мөңлҢҖ 8мҪ”м–ҙк№Ңм§Җ мӮ¬мҡ©н•ҙм„ң лі‘л ¬лЎң лҸҢлҰј $ snakemake --cores 8 # нҒҙлҹ¬мҠӨн„°м—җм„ң мөңлҢҖ 20к°ң мһ‘м—…к№Ңм§Җ нҒҗм—җ л„Јкі лҸҢлҰј $ snakemake --jobs 20 --cluster вҖңqsub -pe threaded {threads}вҖқ # DRMAAлҘј м§Җмӣҗн•ҳлҠ” нҒҙлҹ¬мҠӨн„°м—җ л„Јкі лҸҢлҰј $ snakemake --jobs 20 --drmaa
- 62. File-driven programming? вҖңліҙмқјлҹ¬нҢҗмқҙ н•„мҡ” м—ҶлҠ”вҖқ н”„лЎңк·ёлһЁ лӮҙмһҘнҳ• лі‘л ¬нҷ” мқҙлІӨнҠё лЈЁн”„
- 63. snakemake GUI resource quota task priority code/data versions audit trailconп¬Ғgurations HTML reporting R embedding benchmarking modularization version tracking
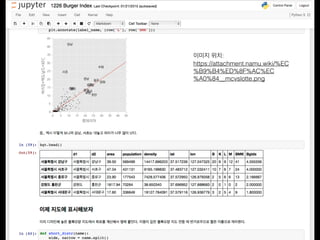
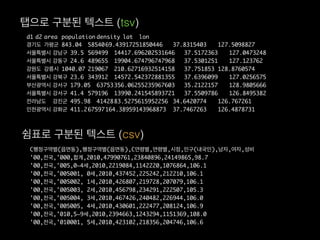
- 65. d1 d2 area population density lat lon кІҪкё°лҸ„ к°ҖнҸүкө° 843.04 5854069.43917251850446 37.8315403 127.5098827 м„ңмҡёнҠ№лі„мӢң к°•лӮЁкө¬ 39.5 569499 14417.696202531646 37.5172363 127.0473248 м„ңмҡёнҠ№лі„мӢң к°•лҸҷкө¬ 24.6 489655 19904.674796747968 37.5301251 127.123762 к°•мӣҗлҸ„ к°•лҰүмӢң 1040.07 219067 210.62716932514158 37.751853 128.8760574 м„ңмҡёнҠ№лі„мӢң к°•л¶Ғкө¬ 23.6 343912 14572.542372881355 37.6396099 127.0256575 л¶ҖмӮ°кҙ‘м—ӯмӢң к°•м„ңкө¬ 179.05 63753356.06255235967603 35.2122157 128.9805666 м„ңмҡёнҠ№лі„мӢң к°•м„ңкө¬ 41.4 579196 13990.241545893721 37.5509786 126.8495382 м „лқјлӮЁлҸ„ 강진кө° 495.98 4142883.5275615952256 34.6420774 126.767261 мқёмІңкҙ‘м—ӯмӢң к°•нҷ”кө° 411.267597164.38959143968873 37.7467263 126.4878731 нғӯмңјлЎң кө¬л¶„лҗң н…ҚмҠӨнҠё (tsv) Cн–үм •кө¬м—ӯлі„(мқҚл©ҙлҸҷ),н–үм •кө¬м—ӯлі„(мқҚл©ҙлҸҷ),Cм—°л №лі„,м—°л №лі„,мӢңм җ,мқёкө¬(лӮҙкөӯмқё),лӮЁмһҗ,м—¬мһҗ,м„ұ비 '00,м „көӯ,'000,н•©кі„,2010,47990761,23840896,24149865,98.7 '00,м „көӯ,'005,0~4м„ё,2010,2219084,1142220,1076864,106.1 '00,м „көӯ,'005001, 0м„ё,2010,437452,225242,212210,106.1 '00,м „көӯ,'005002, 1м„ё,2010,426807,219728,207079,106.1 '00,м „көӯ,'005003, 2м„ё,2010,456798,234291,222507,105.3 '00,м „көӯ,'005004, 3м„ё,2010,467426,240482,226944,106.0 '00,м „көӯ,'005005, 4м„ё,2010,430601,222477,208124,106.9 '00,м „көӯ,'010,5~9м„ё,2010,2394663,1243294,1151369,108.0 '00,м „көӯ,'010001, 5м„ё,2010,423102,218356,204746,106.6 мүјн‘ңлЎң кө¬л¶„лҗң н…ҚмҠӨнҠё (csv)
- 66. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ! мҪ”л“ң 추к°Җк°Җ л§Өмҡ° к°„нҺё н”„л Ҳмһ„мӣҢнҒ¬к°Җ мң м—°н•ҳкі м„ұмҲҷн•ҙм•ј н•Ё лҚ°мқҙн„°к°Җ мһ‘м§ҖлҠ” м•ҠлӢӨ. м ҒлӢ№нһҲ л№Ёлқјм•ј н•Ё
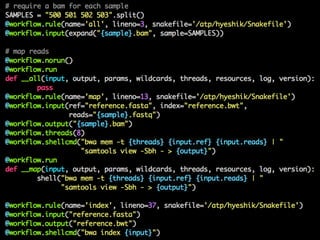
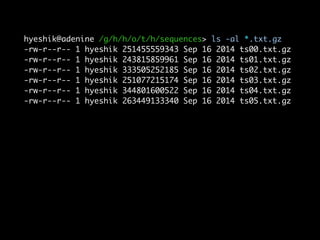
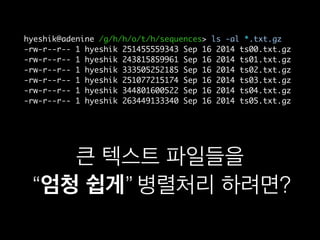
- 67. hyeshik@adenine /g/h/h/o/t/h/sequences> ls -al *.txt.gz -rw-r--r-- 1 hyeshik 251455559343 Sep 16 2014 ts00.txt.gz -rw-r--r-- 1 hyeshik 243815859961 Sep 16 2014 ts01.txt.gz -rw-r--r-- 1 hyeshik 333505252185 Sep 16 2014 ts02.txt.gz -rw-r--r-- 1 hyeshik 251077215174 Sep 16 2014 ts03.txt.gz -rw-r--r-- 1 hyeshik 344801600522 Sep 16 2014 ts04.txt.gz -rw-r--r-- 1 hyeshik 263449133340 Sep 16 2014 ts05.txt.gz
- 68. hyeshik@adenine /g/h/h/o/t/h/sequences> ls -al *.txt.gz -rw-r--r-- 1 hyeshik 251455559343 Sep 16 2014 ts00.txt.gz -rw-r--r-- 1 hyeshik 243815859961 Sep 16 2014 ts01.txt.gz -rw-r--r-- 1 hyeshik 333505252185 Sep 16 2014 ts02.txt.gz -rw-r--r-- 1 hyeshik 251077215174 Sep 16 2014 ts03.txt.gz -rw-r--r-- 1 hyeshik 344801600522 Sep 16 2014 ts04.txt.gz -rw-r--r-- 1 hyeshik 263449133340 Sep 16 2014 ts05.txt.gz нҒ° н…ҚмҠӨнҠё нҢҢмқјл“Өмқ„ вҖңм—„мІӯ мүҪкІҢвҖқ лі‘л ¬мІҳлҰ¬ н•ҳл Өл©ҙ?
- 69. hyeshik@adenine /g/h/h/o/t/h/sequences> ls -al *.txt.gz -rw-r--r-- 1 hyeshik 251455559343 Sep 16 2014 ts00.txt.gz -rw-r--r-- 1 hyeshik 243815859961 Sep 16 2014 ts01.txt.gz -rw-r--r-- 1 hyeshik 333505252185 Sep 16 2014 ts02.txt.gz -rw-r--r-- 1 hyeshik 251077215174 Sep 16 2014 ts03.txt.gz -rw-r--r-- 1 hyeshik 344801600522 Sep 16 2014 ts04.txt.gz -rw-r--r-- 1 hyeshik 263449133340 Sep 16 2014 ts05.txt.gz нҒ° н…ҚмҠӨнҠё нҢҢмқјл“Өмқ„ вҖңм—„мІӯ мүҪкІҢвҖқ лі‘л ¬мІҳлҰ¬ н•ҳл Өл©ҙ?вҖңм—„мІӯ мүҪкІҢвҖқ
- 70. нҒ° н…ҚмҠӨнҠё нҢҢмқјл“Өмқ„ вҖңм—„мІӯ мүҪкІҢвҖқ лі‘л ¬мІҳлҰ¬ н•ҳл Өл©ҙ?вҖңм—„мІӯ мүҪкІҢвҖқ
- 71. нҒ° н…ҚмҠӨнҠё нҢҢмқјл“Өмқ„ вҖңм—„мІӯ мүҪкІҢвҖқ лі‘л ¬мІҳлҰ¬ н•ҳл Өл©ҙ?вҖңм—„мІӯ мүҪкІҢвҖқ 압축мқ„ м•Ҳ н•ңлӢӨ.
- 72. нҒ° н…ҚмҠӨнҠё нҢҢмқјл“Өмқ„ вҖңм—„мІӯ мүҪкІҢвҖқ лі‘л ¬мІҳлҰ¬ н•ҳл Өл©ҙ?вҖңм—„мІӯ мүҪкІҢвҖқ 압축мқ„ м•Ҳ н•ңлӢӨ. нҢҢмқјмқ„ мӘјк° лӢӨ.
- 73. нҒ° н…ҚмҠӨнҠё нҢҢмқјл“Өмқ„ вҖңм—„мІӯ мүҪкІҢвҖқ лі‘л ¬мІҳлҰ¬ н•ҳл Өл©ҙ?вҖңм—„мІӯ мүҪкІҢвҖқ 압축мқ„ м•Ҳ н•ңлӢӨ. нҢҢмқјмқ„ мӘјк° лӢӨ. tabixлҘј м“ҙлӢӨ.
- 75. gzip 압축 нҢҢмқј gz block 1 gz block 2 gz block 3 gz block 4 gz block 5 gz block 6 gz block 7 gz block 8 gz block 9 gz block 10 bgzf
- 76. gzip 압축 нҢҢмқј gz block 1 gz block 2 gz block 3 gz block 4 gz block 5 gz block 6 gz block 7 gz block 8 gz block 9 gz block 10 bgzf 100% н•ҳмң„нҳёнҷҳ
- 77. tabix м“°кё°
- 78. # мқёлҚұмҠӨлҘј л§Ңл“ лӢӨ. $ tabix -0 -s1 -b2 ts02.txt.gz tabix м“°кё°
- 79. # мқёлҚұмҠӨлҘј л§Ңл“ лӢӨ. $ tabix -0 -s1 -b2 ts02.txt.gz # м—јмғүмІҙ лӘ©лЎқмқ„ ліёлӢӨ. (м—јмғүмІҙ=л ҲлІЁ1 мқёлҚұмҠӨ) $ tabix вҖ”вҖ”list-chroms ts02.txt.gz tabix м“°кё°
- 80. # мқёлҚұмҠӨлҘј л§Ңл“ лӢӨ. $ tabix -0 -s1 -b2 ts02.txt.gz # м—јмғүмІҙ лӘ©лЎқмқ„ ліёлӢӨ. (м—јмғүмІҙ=л ҲлІЁ1 мқёлҚұмҠӨ) $ tabix вҖ”вҖ”list-chroms ts02.txt.gz # м—јмғүмІҙ 1101 лҚ°мқҙн„° м „мІҙлҘј м¶ңл Ҙн•ңлӢӨ. $ tabix ts02.txt.gz 1101 tabix м“°кё°
- 81. # мқёлҚұмҠӨлҘј л§Ңл“ лӢӨ. $ tabix -0 -s1 -b2 ts02.txt.gz # м—јмғүмІҙ лӘ©лЎқмқ„ ліёлӢӨ. (м—јмғүмІҙ=л ҲлІЁ1 мқёлҚұмҠӨ) $ tabix вҖ”вҖ”list-chroms ts02.txt.gz # м—јмғүмІҙ 1101 лҚ°мқҙн„° м „мІҙлҘј м¶ңл Ҙн•ңлӢӨ. $ tabix ts02.txt.gz 1101 # м—јмғүмІҙ 1101мқҳ 10000л¶Җн„° 10100 мһҗлҰ¬к№Ңм§Җ м¶ңл Ҙн•ңлӢӨ. $ tabix ts02.txt.gz 1101:10000-10100 tabix м“°кё°
- 82. tabix н•ңкі„м җ
- 83. tabix н•ңкі„м җ мҙҲкё° мқёлҚұмӢұмқҖ лі‘л ¬нҷ”лҗҳм§Җ м•ҠлҠ”лӢӨ.
- 84. tabix н•ңкі„м җ л°ҳл“ңмӢң 2л ҲлІЁ мқёлҚұмҠӨлЎң м •л ¬лҸј мһҲм–ҙм•ј н•ңлӢӨ. мҙҲкё° мқёлҚұмӢұмқҖ лі‘л ¬нҷ”лҗҳм§Җ м•ҠлҠ”лӢӨ.
- 85. tabix н•ңкі„м җ л°ҳл“ңмӢң 2л ҲлІЁ мқёлҚұмҠӨлЎң м •л ¬лҸј мһҲм–ҙм•ј н•ңлӢӨ. л ҲлІЁ 1 мқёлҚұмҠӨлҠ” лІ”мң„м§Җм •мқҙ м•Ҳ лҗңлӢӨ. мҙҲкё° мқёлҚұмӢұмқҖ лі‘л ¬нҷ”лҗҳм§Җ м•ҠлҠ”лӢӨ.
- 87. Exploratory Data Analysis нғҗмғүм Ғ лҚ°мқҙн„° 분м„қ вҖңмһ¬лҜёмһҲлҠ” кІғвҖқмқ„ м°ҫм•„м•ј н•ңлӢӨ (= м•һмңјлЎң лӯҳ н• м§Җ лӘЁлҘёлӢӨ). мҪ”л“ңлҠ” л№ЁлҰ¬ л§Ңл“Өм–ҙм„ң (кұ°мқҳ) н•ң лІҲл§Ң м“ҙлӢӨ. м–ём ң м–ҙл–Ө лҚ°мқҙн„°к°Җ 추к°Җлҗ м§Җ лӘЁлҘёлӢӨ. к·ёл ҮлӢӨкі мһ¬мӮ¬мҡ©мқҙ м•„мҳҲ м—ҶлҠ” кІғлҸ„ м•„лӢҲлӢӨ. мҪ”л“ң 추к°Җ/мҲҳм •мқҙ л§Өмҡ° к°„нҺё нқҗлҰ„лҸ„ мҠүмҠү мүҪкІҢ л°”кҝ”м•ј н•Ё мЎ°кёҲм”© мЎ°кёҲм”© мӢӨн–үн• мҲҳ мһҲм–ҙм•ј н•Ё л¬ҙм—Үмқҙл“ н• мҲҳ мһҲмқ„ кІғ к°ҷмқҖ лӘЁл“Ҳнҷ”, мһ¬нҳ„м„ұ, нҷ• мһҘм„ұ нҷ•ліҙ! мҪ”л“ң 추к°Җк°Җ л§Өмҡ° к°„нҺё н”„л Ҳмһ„мӣҢнҒ¬к°Җ мң м—°н•ҳкі м„ұмҲҷн•ҙм•ј н•Ё лҚ°мқҙн„°к°Җ мһ‘м§ҖлҠ” м•ҠлӢӨ. м ҒлӢ№нһҲ л№Ёлқјм•ј н•Ё
- 88. Dynamic programming Monte Carlo simulation Permutation tests л°°кІҪ мқҙлҜём§Җ мң„м№ҳ: http://i.imgur.com/pSyG4xJ.jpg
- 89. def water(seq1, seq2): m, n = len(seq1), len(seq2) # length of two sequences # Generate DP table and traceback path pointer matrix score = zeros((m+1, n+1)) # the DP table pointer = zeros((m+1, n+1)) # to store the traceback path max_score = 0 # initial maximum score in DP table # Calculate DP table and mark pointers for i in range(1, m + 1): for j in range(1, n + 1): score_diagonal = score[i-1][j-1] + match_score(seq1[i-1], seq2[j-1]) score_up = score[i][j-1] + gap_penalty score_left = score[i-1][j] + gap_penalty score[i][j] = max(0,score_left, score_up, score_diagonal) if score[i][j] == 0: pointer[i][j] = 0 # 0 means end of the path if score[i][j] == score_left: pointer[i][j] = 1 # 1 means trace up if score[i][j] == score_up: pointer[i][j] = 2 # 2 means trace left if score[i][j] == score_diagonal: pointer[i][j] = 3 # 3 means trace diagonal if score[i][j] >= max_score: max_i = i max_j = j max_score = score[i][j]; https://github.com/alevchuk/pairwise-alignment-in-python
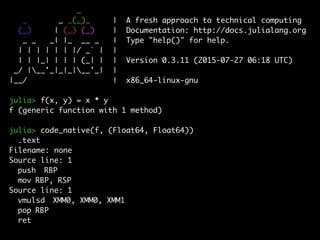
- 91. _ _ _ _(_)_ | A fresh approach to technical computing (_) | (_) (_) | Documentation: http://docs.julialang.org _ _ _| |_ __ _ | Type "help()" for help. | | | | | | |/ _` | | | | |_| | | | (_| | | Version 0.3.11 (2015-07-27 06:18 UTC) _/ |__'_|_|_|__'_| | |__/ | x86_64-linux-gnu julia> f(x, y) = x * y f (generic function with 1 method) julia> code_native(f, (Float64, Float64)) .text Filename: none Source line: 1 push RBP mov RBP, RSP Source line: 1 vmulsd XMM0, XMM0, XMM1 pop RBP ret
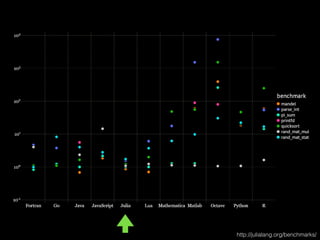
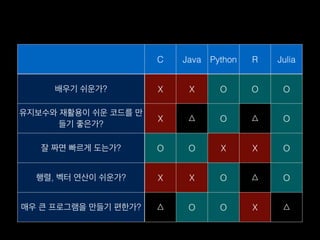
- 93. C Java Python R Julia л°°мҡ°кё° мү¬мҡҙк°Җ? X X O O O мң м§ҖліҙмҲҳмҷҖ мһ¬нҷңмҡ©мқҙ мү¬мҡҙ мҪ”л“ңлҘј л§Ң л“Өкё° мўӢмқҖк°Җ? X в–і O в–і O мһҳ м§ңл©ҙ л№ лҘҙкІҢ лҸ„лҠ”к°Җ? O O X X O н–үл ¬, лІЎн„° м—°мӮ°мқҙ мү¬мҡҙк°Җ? X X O в–і O л§Өмҡ° нҒ° н”„лЎңк·ёлһЁмқ„ л§Ңл“Өкё° нҺён•ңк°Җ? в–і O O X в–і
- 94. # precell precell(::Void) = PreCell([][:,:], 0, 0) function precell(el::AbstractString) if contains(el, "n") a = map(split(el, "n")) do x width = strwidth(x) string(x, repeat(" ", width-length(x))) end[:, :] m,n = size(a) PreCell(a, maximum(map(length, a)), m) else width = strwidth(el) PreCell([string(el, repeat(" ", width-length(el)))][:,:], width, 1) end end part of Millboard.jl by wookay
- 97. мҡ”м•Ҫ
- 98. мҡ”м•Ҫ вҖў Jupyter notebook м“°л©ҙ лҳ‘лҳ‘н•ҙ집лӢҲлӢӨ.
- 99. мҡ”м•Ҫ вҖў Jupyter notebook м“°л©ҙ лҳ‘лҳ‘н•ҙ집лӢҲлӢӨ. вҖў Snakemake м“°л©ҙ мҲҳлӘ…мқҙ лҠҳм–ҙлӮ©лӢҲлӢӨ.
- 100. мҡ”м•Ҫ вҖў Jupyter notebook м“°л©ҙ лҳ‘лҳ‘н•ҙ집лӢҲлӢӨ. вҖў Snakemake м“°л©ҙ мҲҳлӘ…мқҙ лҠҳм–ҙлӮ©лӢҲлӢӨ. вҖў нҒ° н…ҚмҠӨнҠё нҢҢмқјмқ„ лӮҳлҲ м„ң мІҳлҰ¬н•ҳл Өл©ҙ tabix!
- 101. мҡ”м•Ҫ вҖў Jupyter notebook м“°л©ҙ лҳ‘лҳ‘н•ҙ집лӢҲлӢӨ. вҖў Snakemake м“°л©ҙ мҲҳлӘ…мқҙ лҠҳм–ҙлӮ©лӢҲлӢӨ. вҖў нҒ° н…ҚмҠӨнҠё нҢҢмқјмқ„ лӮҳлҲ м„ң мІҳлҰ¬н•ҳл Өл©ҙ tabix! вҖў мҶҚлҸ„к°Җ н•„мҡ”н• л•җ нҢҢмқҙмҚ¬кіј мӨ„лҰ¬м•„лҘј к°ҷмқҙ м“°м„ёмҡ”!
- 102. Acknowledgements Johannes KГ¶ster Dana-Farber Cancer Institute Heng Li Broad Institute Bezanson, Karpinski, Shah, and Edelman MIT л…ёмҡ°кІҪ мӨ„лҰ¬м•„ н•ңкөӯ мӮ¬мҡ©мһҗ к·ёлЈ№
- 103. нғҗмғүм ҒмңјлЎң нҒ° лҚ°мқҙн„° 분м„қн•ҳкё° мһҘнҳңмӢқ кё°мҙҲкіјн•ҷм—°кө¬мӣҗ RNAм—°кө¬лӢЁ л°°кІҪ мқҙлҜём§Җ мң„м№ҳ: http://4.bp.blogspot.com/-bB4jFkQ_jBk/T70ipuyFn6I/AAAAAAAAAOE/cnbxI03ve0Y/s1600/ snake_pile_2crop+by+Tracy+Langkilde.jpg