



















![References:
â 1. Luke Campagnola. PyQtGraph Project Home page:
http://www.pyqtgraph.org/ [Internet] [cited 24 April 2018]
â 2. Luke Campagnola. PyQtGraph Project Official Documentation page:
http://www.pyqtgraph.org/documentation/installation.html [Internet] [cited 24
April 2018]
â 3. Pirate Metrics: A new way to measure open source community success.
https://opensource.com/business/16/6/pirate-metrics [Internet] [cited 24 April
2018]](https://image.slidesharecdn.com/pyqtgraphevening-180520142012/85/PyQtGraph-evening-22-320.jpg)
































More Related Content
Similar to PyQtGraph evening (20)
Recently uploaded (20)

















PyQtGraph evening
- 1. Towards Better Open-Source Development: Improving PyQtGraphâs Feature-Development Process Thesis Presentation By Aditya Kelekar BE (IT) Metropolia University of Applied Sciences
- 2. - â Letâs spare a moment to think about what is happening with a giant open- source software projectâĶ. At a well-known open-source project
- 4. Source: Linux Kernel Report 2017, Linux Foundation Figure 1: Top companies contributing to the Linux kernel, 4.8â 4.13 in 2017 Linux Kernel Contributors
- 5. Table of Contents â 1. What is PyQtGraph and where does it come from? â 2. Open Source Feature Development: Known Facts â 3. Analysis of PyQtGraphâs Feature Development Process â 4. Guidelines for PyQtGraphâs Feature Process Improvements â 5. Conclusions
- 6. PyQtGraph: A graphic library Functionalities: â Basic 2D plotting â Image display with interactive lookup tables â 3D graphics system â Library of widgets and modules useful for science/engineering applications Source: www.pyqtgraph.orgFigure 2: Histogram drawn with PyQtGraph
- 7. PyQtGraph: Components & Competitors Figure 3: PyQtGraphâs Dependencies and Other Graphics Libraries NOTE: Size of shapes is not an indicator of any metric
- 8. Feature Development in Open-Soure Software â Iterative process with a public repository â Mailing list, Forum Boards â Small, frequent changes to code repository â Few key developers (that is, limited resources) â Atleast one maintainer
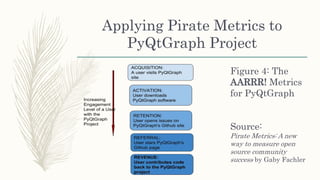
- 10. Applying Pirate Metrics to PyQtGraph Project Figure 4: The AARRR! Metrics for PyQtGraph Source: Pirate Metrics: A new way to measure open source community success by Gaby Fachler
- 11. To Accept or Not to Accept? â A dilemma often presenting itself to the maintainer: â One side: â Accepting (new) code appeases the feature contributor; (possibly also) other users â Other side: â New code becomes the responsibility of the maintainer
- 12. PyQtGraphâs Code Development â Bug Reports and New Feature Proposals on GitHub Issues, GitHub Pull Request and PyQtGraph GoogleGroups pages â Maintainer of the GitHub (and also founder): Luke Campagnola â 8-10 user queries/feature proposals every month â 60 percent of user queries/feature proposals are answered â About 40 âlistedâ contributors â All development is voluntary-based â FAQ for prospective contributors is available
- 13. PyQtGraph Google Group Statistics Figure 5: Data Related to Number of Posts on PyQtGraph âGoogle Groupâ Forum site
- 14. Analysing the Library Forum Posts â Only posts where the maintainer had commented were analysed â Corresponding changes in code in Github were studied â A list of observations was created â 3 cases of feature development were studied â The 3 cases represented different feature development outcomes
- 15. A Successful Development Cycle aa Figure 6: Timeline of events for a typical successful feature-addition process.
- 16. Case of Unsuccessful Feature Development Figure 7: Timeline of interactions for the âNew Time Axisâ proposed feature
- 17. Suggested Improvements for Feature Development Process â Need for a Collaboration Tool. (Objective: focus the current development resources towards feature completion) â A new metric to assign collaboration level for new feature code posts â Visibility of across GithHub and Google Groups forum â While feature development in progress: correction list auto-tracking features
- 18. Pirate Metrics + Interactions Component Figure 8: Extended Pirate Metrics with Interactions component
- 20. PyQtGraphâs GitHub Pull Requests Page
- 21. Conclusions: Beneficiaries & Limitiations of Scope â This study could aid: âĒ a developer wishing to contribute to the PyQtGraph project code âĒ maintainer of the PyQtGraph project âĒ User studying the open-source process - Limitations: ï§ Research based only on one open-source library ï§ Each open-source project may have its own dynamics
- 22. References: â 1. Luke Campagnola. PyQtGraph Project Home page: http://www.pyqtgraph.org/ [Internet] [cited 24 April 2018] â 2. Luke Campagnola. PyQtGraph Project Official Documentation page: http://www.pyqtgraph.org/documentation/installation.html [Internet] [cited 24 April 2018] â 3. Pirate Metrics: A new way to measure open source community success. https://opensource.com/business/16/6/pirate-metrics [Internet] [cited 24 April 2018]
- 23. Thank You! And now the exerciseâĶ
- 24. Plotting a Graph âImagine an Apple Tree that grows uniformly at the rate of 1 meter per year. It was planted in 2010. Can you show how it has grown?