



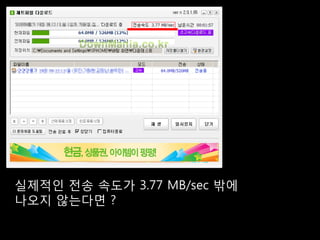






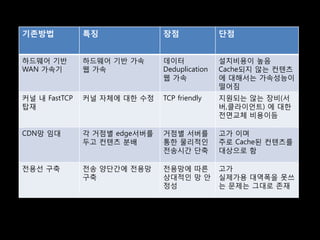
















![ĒöäļĪ£ĒåĀņĮ£ļ│ä ņĀäņåĪņä▒ļŖź ļ╣äĻĄÉ [WAN Simulator : RTT 100ms, 100MB ĒīīņØ╝]
3,311ņ┤ł
FTP 1,234ņ┤ł
423ņ┤ł
681ņ┤ł
UDT 203ņ┤ł
56ņ┤ł
Packet loss
19ņ┤ł
ASPERA 32ņ┤ł 5%
55ņ┤ł 1%
0.1%
206ņ┤ł
Rapidant-TCP 78ņ┤ł
50ņ┤ł
18ņ┤ł
Rapidant-UDP 16ņ┤ł
13ņ┤ł
0 500 1000 1500 2000 2500 3000 3500 ņŗ£Ļ░ä(ņ┤ł)](https://image.slidesharecdn.com/sdec2011-rapidant-110701180520-phpapp02/85/SDEC2011-Rapidant-36-320.jpg)
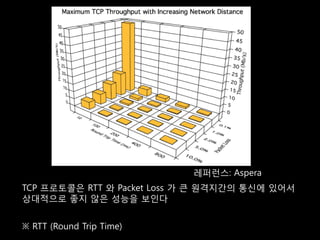
![ĒöäļĪ£ĒåĀņĮ£ļ│ä ņĀäņåĪņä▒ļŖź ļ╣äĻĄÉ [WAN Simulator : RTT 300ms, 100MBĒīīņØ╝]
8,925ņ┤ł
FTP 3,482ņ┤ł
1,338ņ┤ł
1,173ņ┤ł
UDT 291ņ┤ł
59ņ┤ł
Packet loss
25ņ┤ł
ASPERA 22ņ┤ł 5%
48ņ┤ł 1%
383ņ┤ł 0.1%
Rapidant-TCP 225ņ┤ł
74ņ┤ł
35ņ┤ł
Rapidant-UDP 29ņ┤ł
63ņ┤ł
0 2000 4000 6000 8000 10000 ņŗ£Ļ░ä(ņ┤ł)](https://image.slidesharecdn.com/sdec2011-rapidant-110701180520-phpapp02/85/SDEC2011-Rapidant-37-320.jpg)
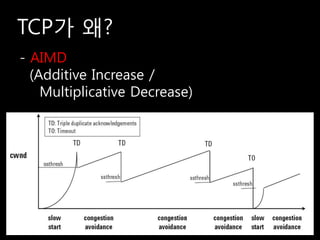
![ĒöäļĪ£ĒåĀņĮ£ļ│ä ņĀäņåĪņä▒ļŖź ļ╣äĻĄÉ [ņĢäņģłĒāĆņøī->EC2 : RTT 240ms]
1,028ņ┤ł
FTP
99ņ┤ł
500ņ┤ł
Aspera
52ņ┤ł ņĀäņåĪņÜ®ļ¤ē
1GB
553ņ┤ł 100MB
Rapidant-UDP
57ņ┤ł
130ņ┤ł
Rapidant-TCP
20ņ┤ł
0 200 400 600 800 1,000 1,200 ņŗ£Ļ░ä(ņ┤ł)
Seoul, Korea Rep. to North Virginia, US. ( RTT : 240ms )](https://image.slidesharecdn.com/sdec2011-rapidant-110701180520-phpapp02/85/SDEC2011-Rapidant-38-320.jpg)



SDEC2011 Rapidant
- 2. S/W ĻĖ░ļ░śņØś Ļ│ĀņåŹ ĒīīņØ╝ ņĀäņåĪ Ēöīļ×½ĒÅ╝ (Rapidant) rapidant@samsung.com 2011.6. Copyright ŌōÆ 2010 Samsung SDS Co., Ltd. All rights reserved
- 3. Ļ│ĀņåŹ ĒīīņØ╝ ņĀäņåĪ Čźīļ×½ĒÅ╝?
- 4. ņÜ░ļ”¼ņ¦æ ņØĖĒä░ļäĘņØĆ Ļ┤æņ╝ĆņØ┤ļĖöņØ┤ļØ╝ņä£ 100Mbps ņåŹļÅäĻ░Ć ļéśņś”ļŗżļŖöļŹ░ŌĆ” 100MbpsļŖö 1ņ┤łņŚÉ ņĢĮ 12MB ĒīīņØ╝ņØä ļŗżņÜ┤ļ░øļŖö ņåŹļÅä
- 5. ņŗżņĀ£ņĀüņØĖ ņĀäņåĪ ņåŹļÅäĻ░Ć 3.77 MB/sec ļ░¢ņŚÉ ļéśņśżņ¦Ć ņĢŖļŖöļŗżļ®┤ ?
- 6. ļÅäļīĆņ▓┤ ņÖ£ ņĀäņåĪņåŹļÅäĻ░Ć ņĢł ļéśņś¦Ļ╣īņÜö ?
- 7. ļŁÉĻ░Ć ļ¼ĖņĀ£ĻĖĖļל? - ņä£ļ▓ä Ļ│╝ļČĆŪĻś
- 8. ļŁÉĻ░Ć ļ¼ĖņĀ£ĻĖĖļל? - ņä£ļ▓ä Ļ│╝ļČĆŪĻś - ļäżĒŖĖņøīĒü¼ ļīĆņŚŁĒÅŁ ļ¬©ļæÉ ņåīļ¬©
- 9. ļŁÉĻ░Ć ļ¼ĖņĀ£ĻĖĖļל? - ņä£ļ▓ä Ļ│╝ļČĆŪĻś - ļäżĒŖĖņøīĒü¼ ļīĆņŚŁĒÅŁ ļ¬©ļæÉ ņåīļ¬© - TCP/IP ĒöäļĪ£ĒåĀņĮ£ ļĢīļ¼ĖņŚÉ
- 10. ļĀłĒŹ╝ļ¤░ņŖż: Aspera TCP ĒöäļĪ£ĒåĀņĮ£ņØĆ RTT ņÖĆ Packet Loss Ļ░Ć Ēü░ ņøÉĻ▓®ņ¦ĆĻ░éņØś ĒåĄņŗ×ņŚÉ ņ׳ņ¢┤ņä£ ņāüļīĆņĀüņ£╝ļĪ£ ņóŗņ¦Ć ņĢŖņØĆ ņä▒ļŖźņØä ļ│┤ņØĖļŗż ŌĆ╗ RTT (Round Trip Time)
- 11. TCPĻ░Ć ņÖ£? - AIMD (Additive Increase / Multiplicative Decrease)
- 12. Congestion Control A Congestion Control Internet B D Congestion Control C
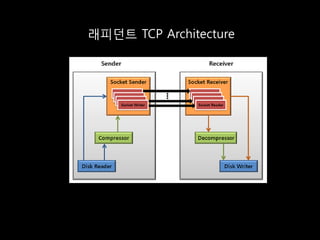
- 13. ņØ┤ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ£ ĻĖ░ņĪ┤ ļ░®ļ▓Ģļōż - ĒĢśļō£ņø©ņ¢┤ ĻĖ░ļ░ś WAN Ļ░ĆņåŹĻĖ░ - ņ╗żļäÉ ļé┤ FastTCP Ēāæņ×¼ - CDNļ¦Ø ņ×äļīĆ - ņĀäņÜ®ņäĀ ĻĄ¼ņČĢ
- 15. ĻĖ░ņĪ┤ļ░®ļ▓Ģ ĒŖ╣ņ¦Ģ ņןņĀÉ ļŗ©ņĀÉ ĒĢśļō£ņø©ņ¢┤ ĻĖ░ļ░ś ĒĢśļō£ņø©ņ¢┤ ĻĖ░ļ░ś Ļ░ĆņåŹ ļŹ░ņØ┤Ēä░ ņäżņ╣śļ╣äņÜ®ņØ┤ ļåÆņØī WAN Ļ░ĆņåŹĻĖ░ ņø╣ Ļ░ĆņåŹ Deduplication CacheļÉśņ¦Ć ņĢŖļŖö ņ╗©ĒģÉņĖĀ ņø╣ Ļ░ĆņåŹ ņŚÉ ļīĆĒĢ┤ņä£ļŖö Ļ░ĆņåŹņä▒ļŖźņØ┤ ļ¢©ņ¢┤ņ¦É ņ╗żļäÉ ļé┤ FastTCP ņ╗żļäÉ ņ×Éņ▓┤ņŚÉ ļīĆĒĢ£ ņłśņĀĢ TCP friendly ņ¦ĆņøÉļÉśļŖö ņĢŖļŖö ņןļ╣ä(ņä£ Ēāæņ×¼ ļ▓ä,Ēü┤ļØ╝ņØ┤ņ¢ĖĒŖĖ) ņŚÉ ļīĆĒĢ£ ņĀäļ®┤ĻĄÉņ▓┤ ļ╣äņÜ®ņØ┤ļō¼ CDNļ¦Ø ņ×äļīĆ Ļ░ü Ļ▒░ņĀÉļ│ä edgeņä£ļ▓äļź╝ Ļ▒░ņĀÉļ│ä ņä£ļ▓äļź╝ Ļ│ĀĻ░Ć ņØ┤ļ®░ ļæÉĻ│Ā ņ╗©ĒģÉņĖĀ ļČäļ░░ ĒåĄĒĢ£ ļ¼╝ļ”¼ņĀüņØĖ ņŻ╝ļĪ£ CacheļÉ£ ņ╗©ĒģÉņĖĀļź╝ ņĀäņåĪņŗ£Ļ░é ļŗ©ņČĢ ļīĆņāüņ£╝ļĪ£ ĒĢ© ņĀäņÜ®ņäĀ ĻĄ¼ņČĢ ņĀäņåĪ ņ¢æļŗ©Ļ░éņŚÉ ņĀäņÜ®ļ¦Ø ņĀäņÜ®ļ¦ØņŚÉ ļö░ļźĖ Ļ│ĀĻ░Ć ĻĄ¼ņČĢ ņāüļīĆņĀüņØĖ ļ¦Ø ņĢł ņŗżņĀ£Ļ░ĆņÜ® ļīĆņŚŁĒÅŁņØä ļ¬╗ņō░ ņĀĢņä▒ ļŖö ļ¼ĖņĀ£ļŖö ĻĘĖļīĆļĪ£ ņĪ┤ņ×¼
- 16. ņÜ░ļ”¼ņØś ņĀæĻĘ╝ - ļäżĒŖĖņøīĒü¼ ĻĄ¼ņČĢ ļ╣äņÜ®ņØ┤ ņŚåļÅäļĪØ! - ĒĢśļō£ņø©ņ¢┤ ĻĄ¼ņ×ģ ļ╣äņÜ®ņØ┤ ņŚåļÅäļĪØ! - OS ņ╗żļäÉ ņłśņĀĢ ļō▒ ņäżņ╣ś ļ╣äņÜ®ņØ┤ ņŚåļÅäļĪØ! - ļ╣äņÜ®ņØä ņĄ£ņåīĒÖö ĒĢ┤ļ│┤ņ×É!
- 17. S/W ĻĖ░ļ░śņØś Ļ│ĀņåŹ ĒīīņØ╝ ņĀäņåĪ Ēöīļ×½ĒÅ╝(Rapidant)
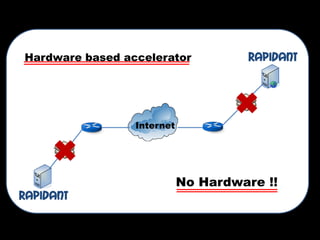
- 18. Hardware based accelerator Internet No Hardware !!
- 19. - Ēöīļ×½ĒÅ╝ ļ╣äņóģņåŹņĀüņØĖ ņĀäņåĪ ĒöäļĪ£ĒåĀņĮ£ ņČöĻĄ¼
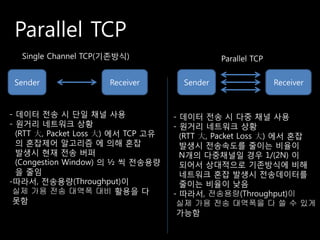
- 20. Parallel TCP - ļŹ░ņØ┤Ēä░ ņĀäņåĪņŚÉ ĒĢśļéśņØś TCPņ▒äļäÉņØ┤ ņĢäļŗī, ļŗż ņłśņØś ņ▒äļäÉņØä ļÅÖņŗ£ņŚÉ ņé¼ņÜ®ĒĢ┤ ņĀäņåĪļźĀņØä ļåÆņ×ä W/2 W/(2N) ņ╗Ą : ņé¼ņÜ®ĒĢĀ ņ׳ļŖö ņĄ£ļīĆ ļäżĒŖĖņøīĒü¼ ļīĆņŚŁĒÅŁ ļ╣©ļīĆ 1Ļ░£ : ĒĢśļéśņØś TCPņ▒äļäÉņØä ņé¼ņÜ®ĒĢĀ ļĢīņØś ļ¬©ņŖĄ
- 21. Parallel TCP Single Channel TCP(ĻĖ░ņĪ┤ļ░®ņŗØ) Parallel TCP Sender Receiver Sender Receiver - ļŹ░ņØ┤Ēä░ ņĀäņåĪ ņŗ£ ļŗ©ņØ╝ ņ▒äļäÉ ņé¼ņÜ® - ļŹ░ņØ┤Ēä░ ņĀäņåĪ ņŗ£ ļŗżņżæ ņ▒äļäÉ ņé¼ņÜ® - ņøÉĻ▒░ļ”¼ ļäżĒŖĖņøīĒü¼ ņāüĒÖ® - ņøÉĻ▒░ļ”¼ ļäżĒŖĖņøīĒü¼ ņāüĒÖ® (RTT Õż¦, Packet Loss Õż¦) ņŚÉņä£ TCP Ļ│Āņ£Ā (RTT Õż¦, Packet Loss Õż¦) ņŚÉņä£ Ēś╝ņ×Ī ņØś Ēś╝ņ×ĪņĀ£ņ¢┤ ņĢīĻ│Āļ”¼ņ”ś ņŚÉ ņØśĒĢ┤ Ēś╝ņ×Ī ļ░£ņāØņŗ£ ņĀäņåĪņåŹļÅäļź╝ ņżäņØ┤ļŖö ļ╣äņ£©ņØ┤ ļ░£ņāØņŗ£ Ēśäņ×¼ ņĀäņåĪ ļ▓äĒŹ╝ NĻ░£ņØś ļŗżņżæņ▒äļäÉņØ╝ Ļ▓ĮņÜ░ 1/(2N) ņØ┤ (Congestion Window) ņØś ┬Į ņö® ņĀäņåĪņÜ®ļ¤ē ļÉśņ¢┤ņä£ ņāüļīĆņĀüņ£╝ļĪ£ ĻĖ░ņĪ┤ļ░®ņŗØņŚÉ ļ╣äĒĢ┤ ņØä ņżäņ×ä ļäżĒŖĖņøīĒü¼ Ēś╝ņ×Ī ļ░£ņāØņŗ£ ņĀäņåĪļŹ░ņØ┤Ēä░ļź╝ -ļö░ļØ╝ņä£, ņĀäņåĪņÜ®ļ¤ē(Throughput)ņØ┤ ņżäņØ┤ļŖö ļ╣äņ£©ņØ┤ ļé«ņØī ņŗżņĀ£ Ļ░ĆņÜ® ņĀäņåĪ ļīĆņŚŁĒÅŁ ļīĆļ╣ä ĒÖŚņÜ®ņØä ļŗż - ļö░ļØ╝ņä£, ņĀäņåĪņÜ®ļ¤ē(Throughput)ņØ┤ ļ¬╗ĒĢ© ņŗżņĀ£ Ļ░ĆņÜ® ņĀäņåĪ ļīĆņŚŁĒÅŁņØä ļŗż ņōĖ ņłś ņ׳Ļ▓ī Ļ░ĆļŖźĒĢ©
- 22. Reliable UDP - ļŹ░ņØ┤Ēä░ ņŗ×ļó░ņä▒ ļ░Å Ēś╝ņ×Ī ĒÜīĒö╝(Congestion Control) ņŚåļŖö UDPņŚÉ ļŹ░ņØ┤Ēä░ ņŗ×ļó░ņä▒ ņČöĻ░Ć ļ░Å Ļ│ĀņåŹ ņĀäņåĪņØä Ļ░ĆļŖźĒĢ£ Ēś╝ņ×ĪĒÜīĒö╝ ņĢīĻ│Āļ”¼ņ”ś ņ£╝ļĪ£ ņ¦üņĀæ ĻĄ¼Ēśä
- 23. Reliable UDP - ļŹ░ņØ┤Ēä░ ņĀäņåĪ ņŗ×ļó░ņä▒ ņĀ£Ļ│Ą : ņ£ĀņŗżļÉ£ Ēī©ĒéĘņØś ņ×¼ņĀäņåĪ ĻĖ░ļŖźņØä Ļ░Ćņ¦É. (UDPļŖö ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ ņ£Āņŗż Ēī©ĒéĘņŚÉ ļīĆĒĢ£ Ļ│ĀļĀż ņŚåņØī) - Rate-based ņĀäņåĪ ņĀ£ņ¢┤ ņĢīĻ│Āļ”¼ņ”ś ņé¼ņÜ® : ļäżĒŖĖņøīĒü¼ ņāüĒÖ®ņŚÉ ļö░ļØ╝ ņ£ĀļÅÖņĀüņ£╝ļĪ£ ņĀäņåĪļźĀņØä ņĀ£ņ¢┤ĒĢ©. (ļäżĒŖĖņøīĒü¼ Ēś╝ņ×ĪņØä Ēö╝ĒĢśļŖö ļÅÖņŗ£ņŚÉ, ļīĆņŚŁĒÅŁņØä ĒÜ©ņ£©ņĀüņ£╝ļĪ£ ņé¼ņÜ®ĒĢśĻ▓ī ĒĢ©.) : TCP ņØś Ļ│Āņ£Ā Ēś╝ņ×ĪņĀ£ņ¢┤ ņĢīĻ│Āļ”¼ņ”śņØä ļö░ļź┤ņ¦Ć ņĢŖņ£╝ļ»ĆļĪ£ ņ×Éņ£ĀļĪ£ņÜ┤ ņĀäņåĪ ņ£© ņĀ£ņ¢┤ Ļ░ĆļŖź - Fairness Ļ│ĀļĀż : ņĀäņåĪ ļīĆņŚŁĒÅŁņØä Ļ│Ąņ£ĀĒĢśļŖö ĒŖĖļלĒöĮĻ░éņØś fairnessļź╝ Ļ│ĀļĀżĒĢ©. (ņŚ¼ļ¤¼ ĒŖĖļלĒöĮņØ┤ ļÅÖņŗ£ņŚÉ ņä£ļ╣äņŖżĒĢśļŖö ņāüņÜ®ļ¦ØņŚÉ ņĀüņÜ® Ļ░ĆļŖź)
- 24. Parallel TCP Reliable UDP - ĻĖ░ļ│ĖņĀüņØĆ Ēś╝ņ×ĪņĀ£ņ¢┤ ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ AIMD - TCP ļ░®ņŗØņŚÉ ļ╣äĒĢ┤ ņäĖļ░ĆĒĢ£ Ēś╝ņ×ĪņĀ£ņ¢┤ Ļ░ĆļŖź ļź╝ ņé¼ņÜ®ĒĢśļ»ĆļĪ£ ņāüļīĆņĀüņ£╝ļĪ£ UDPņŚÉ ļ╣äĒĢ┤ņä£ļŖö TCP Friendly ĒĢ© -ļ│æļĀ¼ ņŚ░Ļ▓░ņØ┤ ņĢäļŗłļ»ĆļĪ£ ņāüļīĆņĀüņ£╝ļĪ£ Parallel (ņāüļīĆ TCP ĒŖĖļלĒöĮ ņĀäņåĪņØä Ļ░ĆļŖźĒĢ£ ļ▓öņ£ä TCP ĒÖ¢Ļ▓ĮņŚÉ ļ╣äĒĢ┤ ļ®öļ¬©ļ”¼ ņé¼ņÜ®ļ¤ē ņĀüņØī ļé┤ ļ│┤ņן) -UDP Ļ│Āņ£ĀņØś ĒŖ╣ņä▒ņ£╝ļĪ£ ņØĖĒĢ┤ ņāüļīĆņĀüņ£╝ļĪ£ -TCP ĻĖ░ļ░śņØ┤ļ»ĆļĪ£ HTTP ļō▒ņØä ĒåĄĒĢ┤ ņāüļīĆņĀü ņāüļīĆ TCP ĒŖĖļלĒöĮņŚÉ ļīĆĒĢ┤ ņóĆļŹö AggressiveĒĢ© ņ£╝ļĪ£ ļ░®ĒÖöļ▓Į ĒåĄĻ│╝ņŚÉ ņ£Āļ”¼ (ņāüļīĆ TCP ĒŖĖļלĒöĮņØä Ēī©ĒéĘ ņåÉņŗż ņŗ£ĒéżļŖö ĒÖĢļźĀņØ┤ Ēü╝) -UDP ļ░®ņŗØņŚÉ ļ╣äĒĢ┤ ņäĖļ░ĆĒĢ£ Ēś╝ņ×ĪņĀ£ņ¢┤ ļ®öņ╗żļŗł ņ”śņØä ĻĄ¼ĒśäĒĢśĻĖ░ Ēלļō¼ -ņØ╝ļ░śņĀüņØĖ ņĪ░Ļ▒┤ņŚÉņä£ TCPņŚÉ ļ╣äĒĢ┤ ļ╣Āļ”ä (ļŗ©, ļäżĒŖĖņøīĒü¼ ĒÖ¢Ļ▓ĮņŚÉ ļö░ļØ╝ ļŗ¼ļØ╝ņ¦ł ņłś ņ׳ņØī) -ņØ╝ļ░śņĀüņØĖ ņĪ░Ļ▒┤ņŚÉņä£ UDPņŚÉ ļ╣äĒĢ┤ ļŖÉļ”╝ (ļŗ©, ļäżĒŖĖņøīĒü¼ ĒÖ¢Ļ▓ĮņŚÉ ļö░ļØ╝ ļŗ¼ļØ╝ņ¦ł ņłś ņ׳ņØī) - ļ░®ĒÖöļ▓Į ĒåĄĻ│╝ņŚÉ ņāüļīĆņĀüņ£╝ļĪ£ ļČłļ”¼
- 25. ņĀĢļ¦É S/Wļ¦ī ņäżņ╣śĒĢśļ®┤ ņĀäņåĪ ņåŹļÅäĻ░Ć ļ╣©ļØ╝ņ¦łĻ╣ī ?
- 26. Ļ┤ĆļĀ© ĻĖ░ņłĀ ļÅÖĒ¢ź ņāüņÜ® ņåöļŻ©ņģś - Aspera -Ēøäņ¦Ćņ»ö BI.DAN-GUN ņśżĒöłņåīņŖż ĒöäļĪ£ņĀØĒŖĖ - UDT4 - RBUDP - FDT - GridFTP
- 27. Congestion Control Queuing Delay based RTTņØś ņāüĒā£ļ│ĆĒÖöļź╝ ĒåĄĒĢ┤ Congestion Ļ│╝ Bottleneck ĒüÉ ņé¼ņØ┤ņ”łņØś ļ│ĆĒÖöļź╝ ņśłņĖĪĒĢśņŚ¼ Ēī©ĒéĘ ņĀä ņåĪņĪ░ņĀłņØä ĒĢśļŖö ļ░®ļ▓Ģ Packet Loss based ņĀäņåĪ Ēī©ĒéĘ ņåÉņŗżņØä CongestionņŚ¼ļČĆņŚÉ ļīĆĒĢ£ ņ¦ĆĒæ£ļĪ£ ņé╝Ļ│Ā Ēī©ĒéĘ ņĀäņåĪņØä ņĪ░ņĀłĒĢśļŖö ļ░®ļ▓Ģ
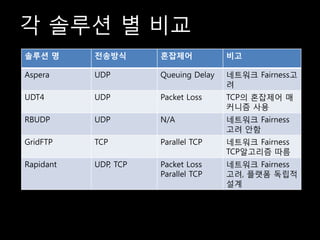
- 28. Ļ░ü ņåöļŻ©ņģś ļ│ä ļ╣äĻĄÉ ņåöļŻ©ņģś ļ¬ģ ņĀäņåĪļ░®ņŗØ Ēś╝ņ×ĪņĀ£ņ¢┤ ļ╣äĻ│Ā Aspera UDP Queuing Delay ļäżĒŖĖņøīĒü¼ FairnessĻ│Ā ļĀż UDT4 UDP Packet Loss TCPņØś Ēś╝ņ×ĪņĀ£ņ¢┤ ļ¦ż ņ╗żļŗłņ”ś ņé¼ņÜ® RBUDP UDP N/A ļäżĒŖĖņøīĒü¼ Fairness Ļ│ĀļĀż ņĢłĒĢ© GridFTP TCP Parallel TCP ļäżĒŖĖņøīĒü¼ Fairness TCPņĢīĻ│Āļ”¼ņ”ś ļö░ļ”ä Rapidant UDP, TCP Packet Loss ļäżĒŖĖņøīĒü¼ Fairness Parallel TCP Ļ│ĀļĀż, Ēöīļ×½ĒÅ╝ ļÅģļ”ĮņĀü ņäżĻ│ä
- 29. ņśüĒÖö Avatar ņøÉļ│Ė ņśüņāü ņĀäņåĪ FTP ļīĆļ╣ä ņĄ£ļīĆ ņĀäņåĪņåŹļÅä ņ░©ņØ┤ 30ļ░░ ņÜ®ļ¤ē : 2TB FTP : 0.187MB/s (131 days) Aspera : 5.6MB/s (4 days) Aspera
- 30. High Energy Physics Experiment 1ĒģīļØ╝ ļ░öņØ┤ĒŖĖ ņĀäņåĪņŚÉ FTPļĪ£ 9ņŻ╝ Cern, ņŖżņ£äņŖż ņÜ®ļ¤ē : 1TB FTP : 0.195MB/s (62 days) GridFTP : 6MB/s (2 days) GridFTP
- 31. ņ£ĀņĀäņ×É ļČäņäØ ļŹ░ņØ┤Ēä░ ņØĖļŗ╣ 800ĻĖ░Ļ░Ć ļ░öņØ┤ĒŖĖ ĒĢ┤ņÖĖ lab ņÜ®ļ¤ē : 1TB FTP : 1.82MB/s (6.6ņØ╝) Rapidant : 9.74MB/s (1.2ņØ╝) Rapidant
- 32. S/WĻĖ░ļ░ś Ļ│ĀņåŹņĀäņåĪņØ┤ ņō░ņØ╝ ņłś ņ׳ļŖö ņśüņŚŁņØĆ ņ¢┤ļööņØĖĻ░ĆņÜö?
- 33. Digital Media -Broadcast & Entertainment Media -Multimedia Publishing Game & Software Development -Global Software Development -Rapid Game Development Cloud Computing -Content Aggregation, Distribution -Database Hosting Global Enterprise -Data Processing Outsourcing -High Speed Remote Backups -Digital Asset Distribution Life Sciences Intelligence & Defense
- 35. ņŗżĒŚś ĒÖ¢Ļ▓Į -WAN ņŗ£ļ«¼ļĀłņØ┤Ēä░ (Packet Loss: 0.1%, 1.0%, 5% RTT: 100 ms, 300 ms, 100MBĒīīņØ╝) -ņŗż ĒÖ¢Ļ▓Į ĒģīņŖżĒŖĖ (ņĢäņģłņé¼ņśź -> ļ»ĖĻĄŁ North Virginia ņĢä ļ¦łņĪ┤ EC2, 100MB, 1G ĒīīņØ╝)
- 36. ĒöäļĪ£ĒåĀņĮ£ļ│ä ņĀäņåĪņä▒ļŖź ļ╣äĻĄÉ [WAN Simulator : RTT 100ms, 100MB ĒīīņØ╝] 3,311ņ┤ł FTP 1,234ņ┤ł 423ņ┤ł 681ņ┤ł UDT 203ņ┤ł 56ņ┤ł Packet loss 19ņ┤ł ASPERA 32ņ┤ł 5% 55ņ┤ł 1% 0.1% 206ņ┤ł Rapidant-TCP 78ņ┤ł 50ņ┤ł 18ņ┤ł Rapidant-UDP 16ņ┤ł 13ņ┤ł 0 500 1000 1500 2000 2500 3000 3500 ņŗ£Ļ░ä(ņ┤ł)
- 37. ĒöäļĪ£ĒåĀņĮ£ļ│ä ņĀäņåĪņä▒ļŖź ļ╣äĻĄÉ [WAN Simulator : RTT 300ms, 100MBĒīīņØ╝] 8,925ņ┤ł FTP 3,482ņ┤ł 1,338ņ┤ł 1,173ņ┤ł UDT 291ņ┤ł 59ņ┤ł Packet loss 25ņ┤ł ASPERA 22ņ┤ł 5% 48ņ┤ł 1% 383ņ┤ł 0.1% Rapidant-TCP 225ņ┤ł 74ņ┤ł 35ņ┤ł Rapidant-UDP 29ņ┤ł 63ņ┤ł 0 2000 4000 6000 8000 10000 ņŗ£Ļ░ä(ņ┤ł)
- 38. ĒöäļĪ£ĒåĀņĮ£ļ│ä ņĀäņåĪņä▒ļŖź ļ╣äĻĄÉ [ņĢäņģłĒāĆņøī->EC2 : RTT 240ms] 1,028ņ┤ł FTP 99ņ┤ł 500ņ┤ł Aspera 52ņ┤ł ņĀäņåĪņÜ®ļ¤ē 1GB 553ņ┤ł 100MB Rapidant-UDP 57ņ┤ł 130ņ┤ł Rapidant-TCP 20ņ┤ł 0 200 400 600 800 1,000 1,200 ņŗ£Ļ░ä(ņ┤ł) Seoul, Korea Rep. to North Virginia, US. ( RTT : 240ms )
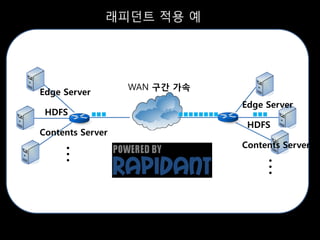
- 40. ļלĒö╝ļŹśĒŖĖ ņĀüņÜ® ņśł WAN ĻĄ¼Ļ░ä Ļ░ĆņåŹ Edge Server Edge Server HDFS HDFS Contents Server Contents Server ŌĆ” ŌĆ”
- 41. Ēī©Ēéżņ¦Ć ņåöļŻ©ņģś ļ░®ņŗØ ņä£ļ▓ä ņä£ļ▓ä S/W ņäżņ╣ś ņä£ļ▓ä PC ļĀłĻ▒░ņŗ£ ņŗ£ņŖżĒģ£ ņØĖĒä░ĒÄśņØ┤ņŖż ļ░®ņŗØ ļלĒö╝ļŹśĒŖĖ ļ¬©ļōł S/WņŚ░ļÅÖ(Open API)
- 42. DEMOļÅÖņśüņāü FTP / Rapidant 100MB ĒīīņØ╝ ņĀäņåĪ ņåŹļÅä ļ╣äĻĄÉ (ņĮöņŚæņŖż ņĢäņģłĒāĆņøī-> ļ»ĖĻĄŁ North Virginia ņĀäņåĪ )