Skilling-up-in-research-data-management-20181128
1 like290 views

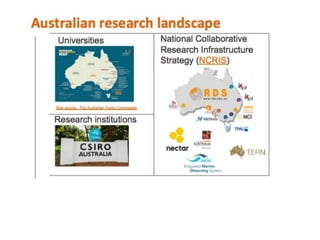
Skilling up In Research Data Management: A crash course for librarians and data stewards Workshop held in Sydney 28th Nov 2018





























































































![ŌŚÅ
ŌŚÅ
ŌŚÅ
ŌŚÅ
ŌŚÅ
ŌŚÅ
ŌŚÅ
ŌŚÅ
Edusmartskills.com. (2018). [online] Available at: https://www.edusmartskills.com/webAssets/images/wso_img.jpg [Accessed 14 May 2018].](https://image.slidesharecdn.com/workshop-slides-skilling-up-in-research-data-mgmt-20181128-181204010324/85/Skilling-up-in-research-data-management-20181128-105-320.jpg)







![Adapted from: Fao.org. (2018). [online] Available at: http://www.fao.org/docrep/015/i2516e/i2516e.pdf [Accessed 1 May 2018].](https://image.slidesharecdn.com/workshop-slides-skilling-up-in-research-data-mgmt-20181128-181204010324/85/Skilling-up-in-research-data-management-20181128-118-320.jpg)





![[ICLR2017 Reading Meeting@DeNA] Introduction of ICLR2017](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2017denaiclr2017english-170616173450-thumbnail.jpg?width=560&fit=bounds)




























More Related Content
Similar to Skilling-up-in-research-data-management-20181128 (20)
More from ARDC (20)


















Recently uploaded (20)



















Skilling-up-in-research-data-management-20181128
- 1. Room 400, Level 4, Building 11
- 11. 1. 2. 3. 4.
- 13. Photo by Ricky Kharawala on Unsplash ŌĆ”
- 19. ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ
- 21. Photo by Andrew Worley on Unsplash
- 22. ŌŚÅ ŌŚÅ ŌŚÅ
- 23. ŌŚÅ ŌŚÅ ŌŚÅ
- 24. ŌŚÅ ŌŚÅ ŌŚÅ
- 26. Photo by Alex Block on Unsplash
- 29. ŌĆóExploratory/Scoping ŌĆóReuse/Secondary data analysis ŌĆóCan be starting point or ad hoc ŌĆóPeer review ŌĆóReproduce/extend results ŌĆóRepurpose (e.g. for mashups, visualisations, simulations) ŌĆóVerify claims (e.g. report findings) *Not in any order; not exhaustive!
- 31. ŌĆóGoogle ŌĆóAsk a colleague ŌĆóFind link to data in a journal article ŌĆóData journals ŌĆóData registries e.g. re3data.org ŌĆóOpen data portals e.g. data.gov ŌĆóInstitutional repositories ŌĆóData / Discipline repositories e.g. Dryad ŌĆóProject website ŌĆóData discovery aggregators like Research Data Australia, Google Dataset ŌĆóLibrary catalogues, databases *Not in any order; not exhaustive!
- 32. When creating metadata records, keep in mind that finding data is: ŌŚÅ Movable feast / changing beast ŌŚÅ No standard practice, universal standard or vocab ŌŚÅ Databases are non-exhaustive ŌŚÅ Methods for searching and terms driven by why people are looking and how the data is stored
- 33. ŌŚÅ Together, weŌĆÖre going to build a rainbow of discipline specific data examples! ŌŚÅ Working in pairs, explore re3data (or beyond!) to find data sources that you would recommend for any specific number of disciplines. ŌŚÅ For each data source: a. find some data b. tell us how you got there - eg google or repository c. why itŌĆÖs a good example to show someone else.
- 34. Here are some scenarios to start you off: ŌŚŗ Showing a researcher where they might find social science data ŌŚŗ Data that may not have a disciplinary ŌĆ£homeŌĆØ ŌŚŗ Incredibly niche specialised scientific data (find a rabbit hole) ŌŚŗ Australian geographic and/or spatialised data ŌŚŗ Internet time server data ŌŚŗ Geological sample data ŌŚÅ re3data.org ŌŚÅ https://researchdata.ands.org.au/ ŌŚÅ https://www.icpsr.umich.edu/ ŌŚÅ https://ada.edu.au/ ŌŚÅ http://www.geosamples.org/ ŌŚÅ https://riojournal.com/
- 41. Your task: 1. Work as a team at your tables 2. Take one of the CSV datasets at 3. Describe the dataset by creating a metadata record. Think about: title, creators, date, short description and so on. 4. Bring your record to whole class discussion Exercise time: 10 mins then whole class discussion
- 44. Your task: 1. Work as a team at your tables 2. Review the record you put together for the CSV file 3. Select a metadata schema of your choice e.g. Dublin Core, RIF-CS, others.. 4. Create a new metadata record using the schema of your choice and the values (attributes) you listed in your original CSV file record Exercise time: 10 mins then whole class discussion
- 48. ŌĆó ŌĆó ŌĆó
- 53. Photo by rawpixel on Unsplash
- 58. Photo by John O'Nolan on Unsplash
- 64. Why oh why should I use a DOI?
- 67. Photo by Amaury Salas on Unsplash Find information about this DOI: 10.4225/08/5858219e78f9a ŌŚÅ What type of research output does this DOI point to? ŌŚÅ What is the organisation associated with this DOI? ŌŚÅ Can you get to the full text from the DOI? Now search for the same DOI in DataCite search: https://search.datacite.org/ ŌŚÅ How do you cite it in Vancouver style? ŌŚÅ Who issued the DOI? Finally, go to DataCite stats: https://stats.datacite.org/ ŌŚÅ For the Australian National Data Service, which organisation minted the most DOIs for 2018?
- 68. Photo by Tyler Nix on Unsplash
- 80. Photo by Cristian Escobar on Unsplash
- 83. There is no change in the high number of researchers valuing a data citation the same as an article - from 78% in 2016 to 77% in 2017 Digital Science Report: The State of Open Data 2017, p.8
- 84. Your task: 1. Work as a team at your tables 2. Look up and read what these publishers are saying about data citation: ŌĆó WileyŌĆÖs Data Citation Policy - https://authorservices.wiley.com/author-resources/Journal-Authors/open- access/data-sharing-citation/index.html ŌĆó Springer Nature Research Data Policy FAQs (why and how cite data) - https://www.springernature.com/gp/authors/research-data-policy/faqs/12 327154 3. Discuss with each other: are the policies the same? Are the citation styles the same? Is it clear information for authors? Exercise time: 5 mins
- 85. ŌĆó ŌĆó ŌĆó
- 86. ŌŚÅ ŌŚÅ ŌŚÅ
- 88. ŌĆó ŌĆ” ŌĆó ŌĆó
- 91. ŌĆ” ŌŚÅ ŌŚÅ
- 93. ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ
- 96. Photo by Alex Block on Unsplash
- 104. ŌŚÅ ŌŚÅ
- 105. ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ Edusmartskills.com. (2018). [online] Available at: https://www.edusmartskills.com/webAssets/images/wso_img.jpg [Accessed 14 May 2018].
- 106. ŌĆ” ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ
- 108. ŌŚÅ ŌŚÅ ŌŚÅ
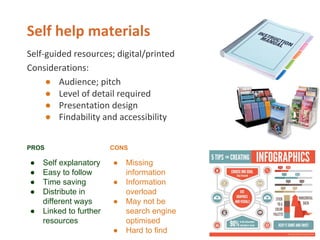
- 111. ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ PROS CONS ŌŚÅ Self explanatory ŌŚÅ Easy to follow ŌŚÅ Time saving ŌŚÅ Distribute in different ways ŌŚÅ Linked to further resources ŌŚÅ Missing information ŌŚÅ Information overload ŌŚÅ May not be search engine optimised ŌŚÅ Hard to find
- 112. ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ
- 115. ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ ŌŚÅ Source: https://visual.ly/community/infographic
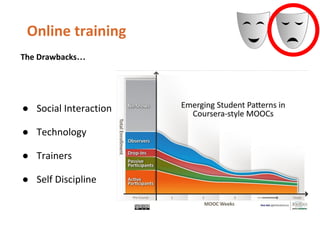
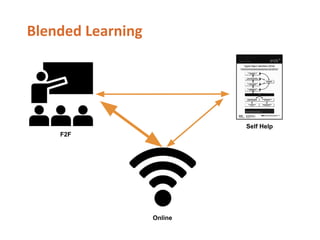
- 116. F2F Online Self Help
- 118. Adapted from: Fao.org. (2018). [online] Available at: http://www.fao.org/docrep/015/i2516e/i2516e.pdf [Accessed 1 May 2018].
- 119. ŌŚÅ Half day, Full day? ŌŚÅ Program Timings? ŌŚÅ Exercises/Activities? ŌŚÅ Content? ŌŚÅ Modules? ŌŚÅ Learning Outcomes? ŌŚÅ Technology? ŌŚÅ Learning assessment? ŌŚÅ How to? ŌŚÅ Software? ppt, piktochart? ŌŚÅ Process or Info sharing? ŌŚÅ A4, Brochure, Web?
- 122. ŌĆ” ŌŚÅ ŌŚÅ ŌŚÅ