

























мҳ¬л°”лҘё 분м„қмқ„ л°©н•ҙн•ҳлҠ” н•Ём • м№ҙл“ң н”јн•ҙк°Җкё°
- 1. лҚ°мқҙн„°лқјмқҙмҰҲ мқҙлҜјнҳё мҳ¬л°”лҘё 분м„қмқ„ л°©н•ҙн•ҳлҠ”вҖЁ н•Ё м • м№ҙ л“ң н”ј н•ҙ к°Җ кё° 1мқј 1м»Өл°Ӣ мһ”л””лӘЁмһ„ мӢңмҰҢ5 | м§ҖмӢқкіөмң нҡҢ
- 2. л°ңн‘ңмһҗ мқҙлҜјнҳё (Miika) Datarize лҚ°мқҙн„° 분м„қк°Җ 1мқј 1м»Өл°Ӣ мһ”л”” лӘЁмһ„м—җ мӢңмҰҢ 1~5 к№Ңм§Җ м „л¶Җ м°ём—¬ мҡ”мғҲлҠ” 분м„қліҙлӢЁ к°ңл°ң(мЈјлЎң JS)мқ„ лҚ” л§Һмқҙ н•©лӢҲлӢӨ "лҚ°мқҙн„°мҷҖ лӘЁлҚёл§Ғ кІ°кіјк°Җ л ҲнҸ¬нҠём—җм„ң л©Ҳ추м§Җ м•Ҡкі ,вҖЁ мӢӨм ңлЎң мӮ¬лһҢл“Өм—җкІҢ лҸ„мӣҖмқ„ мӨ„ мҲҳ мһҲлҸ„лЎқ н•ҳлҠ” м ңн’Ҳмқ„ л§Ңл“Өкі мһҗ н•©лӢҲлӢӨ" https://github.com/lumiamitie/TIL
- 3. мһ”л”” лӘЁмһ„м—җм„ң кіөл¶Җн•ҳкі мһҲлҠ” кІғ мқјн•ҳлӢӨ л§ҲмЈјм№ҳлҠ” к°ңл°ң мқҙмҠҲл“Ө (Git, Docker, JS, Python) нҶөкі„ м„ңм Ғ "Statistical Rethinking" мҡ”м•Ҫ м •лҰ¬ - 5/30 кё°мӨҖ мҙқ 90мқј мӨ‘м—җм„ң 45лІҲмқҳ м»Өл°Ӣмқҙ н•ҙлӢ№лҗЁ "мҳӨлҠҳ лӢӨлЈЁкІҢ лҗ лӮҙмҡ©лҸ„вҖЁ Statistical Rethinking м—җм„ң мқёмғҒ к№Ҡм—ҲлҚҳ л¶Җ분мқ„ м •лҰ¬н•ң кІ°кіјмһ…лӢҲлӢӨ"
- 4. мӢңмһ‘н•ҳкё° м „м—җ : Model ?
- 5. лӘЁнҳ•мқҙлһҖ л¬ҙм—Үмқјк№Ң? нҳ„мӢӨмқ„ 축мҶҢн•ҳм—¬ н•„мҡ”н•ң л¶Җ분мқ„ мӨ‘мӢ¬мңјлЎң л…јлҰ¬м ҒмңјлЎң кө¬м„ұн•ң мһ‘мқҖ м„ёкі„ - лӘЁнҳ• м•Ҳм—җм„ңлҠ” к°ҖлҠҘн•ң лӘЁл“ кІҪмҡ°мқҳ мҲҳлҘј кі л Өн• мҲҳ мһҲлӢӨ - лӘЁнҳ•мқҙ мҳҲмғҒн–ҲлҚҳ лҢҖлЎң лҸҷмһ‘н•ҳлҠ”м§Җ мӢӨм ң м„ёмғҒмқҳ лҚ°мқҙн„°лҘј л°”нғ•мңјлЎң кІҖмҰқн• мҲҳ мһҲлӢӨ мҳӨлҠҳ мқҙм•јкё°н• "лӘЁнҳ•"мқҙлһҖ лӢӨмҶҢ к°ңл…җм Ғмқё мқҙм•јкё° - нҳ„мӢӨмқҳ 축мҶҢнҢҗмқҖ л§һм§Җл§Ң, м–ҙл–»кІҢ 축мҶҢн–ҲлҠ”м§Җ кі лҜјн•ҳм§ҖлҠ” м•Ҡмқ„ кІғ - к°ңл°ңлЎң м№ҳл©ҙ "м•„м§Ғ м„ёл¶Җм Ғмқё лӮҙмҡ©мқҙ кө¬нҳ„лҗҳм§Җ м•ҠмқҖ н•ЁмҲҳ"
- 6. лӘЁнҳ•мқ„ нҶөн•ҙ лҚ°мқҙн„°лҘј мқҙн•ҙн•ҳл Өкі н• л•ҢвҖЁ мҳ¬л°”лҘё н•ҙм„қмқ„ л°©н•ҙн•ҳлҠ” мҡ”мқёл“Ө мӮ¬мӢӨ л„Ҳл¬ҙ л§ҺмқҖлҚ°... (л©ҚмІӯн•ң) лӮҳ - мһҳлӘ»м„ёмҡҙк°Җм„Ө - мҪ”л“ңмӢӨмҲҳ - лҚ°мқҙн„°мһҳлӘ»к°Җм ёмҳҙ - нҢҢм•…н•ҳм§ҖлӘ»н•ңнһҲмҠӨнҶ лҰ¬ - лҸ„л©”мқём§ҖмӢқл¶ҖмЎұ (м ңлҢҖлЎң мҢ“м—¬мһҲлӢӨлҚҳ) лҚ°мқҙн„° - 분м„қмқ„лӘ©м ҒмңјлЎңмҢ“м•„л‘җм§Җм•ҠмқҖлЎңк·ёлҚ©м–ҙлҰ¬ - 분лӘ…мһҲлӢӨкі к·ёлһ¬лҠ”лҚ°л№„м–ҙмһҲлҠ”лҚ°мқҙн„° - м§ҒкҙҖм Ғмқён•ҙм„қкіјлҠ”кұ°лҰ¬к°ҖлЁјм№ҙн…Ңкі лҰ¬мҪ”л“ңк°’л“Ө - л¬ём„ңм—җм •мқҳлҗңмҡ©лҸ„мҷҖлӢӨлҘҙкІҢмӮ¬мҡ©лҗҳкі мһҲлҠ”컬лҹјл“Ө + лҳҗ лӢӨлҘё л¬ҙм–ёк°Җ ...
- 7. к·ё мӨ‘м—җм„ңлҸ„ "ліҖмҲҳ к°„мқҳ кҙҖкі„лЎң мқён•ҙ мғқкё°лҠ” л¬ём ңл“Ө"м—җ лҢҖн•ҙм„ң м•Ңм•„ліҙмһҗ мЎ°кёҲ лҚ” кө¬мІҙм ҒмңјлЎң н’Җм–ҙ мҚЁліҙл©ҙ, "ліҖмҲҳл“Ө мӮ¬мқҙмқҳ кҙҖкі„ л•Ңл¬ём—җвҖЁ мӣҗлһҳ мҡ°лҰ¬к°Җ м•Ңкі мһҗ н–ҲлҚҳ мһ…л Ҙ ліҖмҲҳмҷҖ кІ°кіј ліҖмҲҳмқҳ кҙҖкі„лҘјвҖЁ мһҳлӘ» н•ҙм„қн•ҳкІҢ лҗҳлҠ” кІҪмҡ°"
- 8. Case Study : Problems
- 9. ліҖмҲҳ к°„мқҳ кҙҖкі„лЎң мқён•ҙ мғқкё°лҠ” л¬ём ңл“Ө м–ҙл–Ө кІғл“Өмқҙ мһҲмқ„к№Ң? мҳӨлҠҳ лӢӨлЈ° лӮҙмҡ©мқҖ м„ё к°Җм§Җ мјҖмқҙмҠӨ - Multicollinearity (лӢӨмӨ‘ кіөм„ м„ұ) - Post-Treatment Bias - Collider Bias
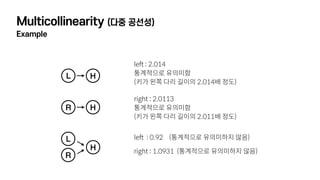
- 10. Multicollinearity (лӢӨмӨ‘ кіөм„ м„ұ) Definition & Example Definition - нҡҢк·Җ лӘЁнҳ•м—җм„ң л‘җ к°ң мқҙмғҒмқҳ мҳҲмёЎ ліҖмҲҳк°Җ м„ңлЎң к°•н•ң мғҒкҙҖкҙҖкі„лҘј к°Җм§ҖлҠ” кІҪмҡ°лҘј л§җн•ңлӢӨ - мӢӨм ңлЎң мҳҲмёЎ ліҖмҲҳмҷҖ кІ°кіј ліҖмҲҳк°Җ м—°кҙҖмқҙ мһҲлҚ”лқјлҸ„, лӘЁнҳ•мқҖ м—°кҙҖмқҙ м—ҶлӢӨлҠ” кІ°лЎ мқ„ лӮҙл ӨлІ„лҰ°лӢӨ Example : лӢӨлҰ¬ кёёмқҙмҷҖ нӮӨмқҳ кҙҖкі„ мӢң뮬л Ҳмқҙм…ҳ - м–‘мӘҪ лӢӨлҰ¬ лӘЁл‘җ нӮӨмқҳ 40~50% кёёмқҙк°Җ лҗҳлҸ„лЎқ мӢң뮬л Ҳмқҙм…ҳмқ„ мҲҳн–үн•ңлӢӨ - к·ёлҰ¬кі к°Ғ лӢӨлҰ¬ кёёмқҙк°Җ нӮӨмҷҖ м–ҙл–Ө кҙҖл Ёмқҙ мһҲлҠ”м§Җ лӘЁнҳ•мқ„ нҶөн•ҙ нҷ•мқён•ңлӢӨ - к·ёлҹ°лҚ° кІ°кіјмқҳ мғҒнғңк°Җ....? L H R H L H R нҡЁкіј мһҲмқҢ нҡЁкіј мһҲмқҢ л‘ҳ лӢӨвҖЁ нҡЁкіј м—ҶмқҢвҖЁ ?????????
- 11. Multicollinearity (лӢӨмӨ‘ кіөм„ м„ұ) Example L H R H L H R left : 2.014вҖЁ нҶөкі„м ҒмңјлЎң мң мқҳлҜён•ЁвҖЁ (нӮӨк°Җ мҷјмӘҪ лӢӨлҰ¬ кёёмқҙмқҳ 2.014л°° м •лҸ„) right : 2.0113вҖЁ нҶөкі„м ҒмңјлЎң мң мқҳлҜён•ЁвҖЁ (нӮӨк°Җ мҷјмӘҪ лӢӨлҰ¬ кёёмқҙмқҳ 2.011л°° м •лҸ„) left : 0.92 (нҶөкі„м ҒмңјлЎң мң мқҳлҜён•ҳм§Җ м•ҠмқҢ) right : 1.0931 (нҶөкі„м ҒмңјлЎң мң мқҳлҜён•ҳм§Җ м•ҠмқҢ)
- 12. Multicollinearity (лӢӨмӨ‘ кіөм„ м„ұ) мҷң л°ңмғқн• к№Ң? нҡҢк·Җ лӘЁнҳ•мқҙ лҸҷмһ‘н•ҳлҠ” л°©мӢқмқҳ нҠ№м„ұ - нҡҢк·Җ лӘЁнҳ•мқ„ нҶөн•ҙ н•ҷмҠөн•ҳлҠ” нҢҢлқјлҜён„°лҠ” лӢӨмқҢкіј к°ҷмқҖ лӮҙмҡ©мқ„ мқҳлҜён•ңлӢӨ - "лӢӨлҘё мӘҪ лӢӨлҰ¬ кёёмқҙлҘј мқҙлҜё м•Ңкі мһҲмқ„ л•Ң, вҖЁ н•ң мӘҪ лӢӨлҰ¬ кёёмқҙлҘј 추к°ҖлЎң м•ҢкІҢ лҗҳм–ҙм„ң м–»кІҢ лҗҳлҠ” к°Җм№ҳлҠ” м–јл§ҲлӮҳ лҗ к№Ң?" - кІ°көӯ м–‘мӘҪ лӢӨлҰ¬ кёёмқҙ лӘЁл‘җ нӮӨлҘј м¶”м •н•ҳлҠ”лҚ° нҡЁкіјк°Җ м—ҶлӢӨлҠ” кІ°лЎ мқ„ лӮҙлҰ¬кІҢ лҗңлӢӨ кіөнҶөм Ғмқё мӣҗмқё ліҖмҲҳк°Җ мЎҙмһ¬н• л•Ң л°ңмғқн•ҳкё° мүҪлӢӨ L U R H м–‘мӘҪ лӢӨлҰ¬ кёёмқҙмқҳвҖЁ кіөнҶө мӣҗмқё нӮӨ
- 13. Post-Treatment Bias Definition & Example Definiton - ліҖмҲҳ Aмқҳ кІ°кіјлЎң мқҙлЈЁм–ҙ진 ліҖмҲҳ BлҘј лӘЁнҳ•м—җ нҸ¬н•ЁмӢңнӮ¬ кІҪмҡ°, Aм—җ лҢҖн•ҙ мһҳлӘ»лҗң н•ҙм„қмқ„ лӮҙлҰҙ мҲҳ мһҲлӢӨ - мҡ°лҰ¬к°Җ нҡЁкіјлҘј кө¬н•ҳкі мӢ¶м–ҙн•ҳлҠ” ліҖмҲҳ(Treatment)лҠ”вҖЁ н•ҙлӢ№ ліҖмҲҳлЎң мқён•ң кІ°кіј (Post-Treatment) ліҖмҲҳк°Җ к°ҷмқҙ мһҲмқ„ л•җ к·ё нҡЁкіјк°Җ к°Җл Өм§Ҳ мҲҳ мһҲлӢӨ Example : кі°нҢЎмқҙ л°©м§Җ нҶ м–‘мқҳ нҡЁкіјлҘј мӢң뮬л Ҳмқҙм…ҳ н•ҙліҙмһҗ - нҶ м–‘м—җкі°нҢЎмқҙк°Җмғқкё°л©ҙмӢқл¬јмқҳм„ұмһҘм—җл°©н•ҙк°ҖлҗңлӢӨ.кі°нҢЎмқҙл°©м§ҖнҶ м–‘мқ„мӮ¬мҡ©н•ҳл©ҙм–јл§ҲлӮҳнҡЁкіјк°ҖмһҲмқ„к№Ң? - ліҖмҲҳлҠ” 4к°ң : мӢқл¬јмқҳ мІҳмқҢ лҶ’мқҙ, мӢӨн—ҳмқҙ лҒқлӮ¬мқ„ л•Ң мӢқл¬јмқҳ лҶ’мқҙ, кі°нҢЎмқҙ л°©м§Җ нҶ м–‘ мӮ¬мҡ© м—¬л¶Җ, кі°нҢЎмқҙ мЎҙмһ¬ м—¬л¶Җ - мқҙ л•Ң лӘЁнҳ•м—җ "кі°нҢЎмқҙ мЎҙмһ¬ м—¬л¶Җ"лҘј нҸ¬н•ЁмӢңнӮӨл©ҙ, кі°нҢЎмқҙ л°©м§Җ нҶ м–‘мқҳ нҡЁкіјк°Җ м—ҶлҠ” кІғмІҳлҹј ліҙмқёлӢӨ
- 14. Post-Treatment Bias Example "кі°нҢЎмқҙ мЎҙмһ¬ м—¬л¶Җ" нҸ¬н•Ён•ҳм§Җ м•Ҡмқ„ л•Ң - кі°нҢЎмқҙ л°©м§Җ нҶ м–‘мқҳ нҡЁкіј : 1.213 - нҶөкі„м ҒмңјлЎң мң мқҳлҜён•Ё "кі°нҢЎмқҙ мЎҙмһ¬ м—¬л¶Җ" нҸ¬н•Ён• л•Ң - кі°нҢЎмқҙ л°©м§Җ нҶ м–‘мқҳ нҡЁкіј : -0.0301 - нҶөкі„м ҒмңјлЎң мң мқҳлҜён•ҳм§Җ м•ҠмқҢ
- 15. Post-Treatment Bias мҷң л°ңмғқн• к№Ң? вҖЁ ліҖмҲҳл“Өмқҳ кҙҖкі„лҘј к·ёлһҳн”„лЎң н‘ңнҳ„н•ҙліҙл©ҙ мқҙл ҮкІҢ лҗңлӢӨ вҖЁ ліҖмҲҳл“Өмқҙ X вҶ’ A вҶ’ Y мҷҖ к°ҷмқҖ нҳ•нғңлЎң мҳҒн–Ҙмқ„ мЈјкі л°ӣлҠ” мғҒнҷ©м—җлҠ”вҖЁ Aк°’м—җ мЎ°кұҙмқҙ кұёлҰҙ л•Ң XмҷҖ YліҖмҲҳк°Җ мЎ°кұҙл¶Җ лҸ…лҰҪ мғҒнғңк°Җ лҗңлӢӨ кі°нҢЎмқҙ л°©м§Җ нҶ м–‘вҖЁ мӮ¬мҡ© м—¬л¶Җ кі°нҢЎмқҙ мЎҙмһ¬ м—¬л¶Җ мӢӨн—ҳмқҙ лҒқлӮ¬мқ„ л•ҢвҖЁ мӢқл¬јмқҳ лҶ’мқҙ мӢқл¬јмқҳ мІҳмқҢ лҶ’мқҙ
- 16. м°ёкі 1 нҠ№м •н•ң ліҖмҲҳм—җ мЎ°кұҙмқ„ л¶Җм—¬н•ңлӢӨлҠ” кІғмқҙ кө¬мІҙм ҒмңјлЎң м–ҙл–Ө мқҳлҜёмқјк№Ң? A вҶ’ B вҶ’ C лқјлҠ” нҳ•нғңмқҳ лӘЁнҳ•мқҙ мһҲмқ„ л•Ң, мқҙ лӘЁнҳ•мқ„ н•ЁмҲҳлЎң лӮҳнғҖлӮҙл©ҙ лӢӨмқҢкіј к°ҷлӢӨ - B = func(A) - C = func(B) - кІ°көӯ C к°’мқ„ м•Ңкё° мң„н•ҙм„ңлҠ” ліҖмҲҳ Aм—җ нҠ№м •н•ң к°’мқ„ мһ…л Ҙн•ҙм•ј н•ңлӢӨвҖЁ вҖЁ вҖЁ л”°лқјм„ң,вҖЁ лӘЁнҳ•м—җ ліҖмҲҳ AлҘј нҸ¬н•Ён•ҳкІҢ лҗҳл©ҙ "ліҖмҲҳ Aм—җ нҠ№м •н•ң к°’мңјлЎң мЎ°кұҙмқ„ л¶Җм—¬" н•ҳкІҢ лҗңлӢӨ
- 17. м°ёкі 2 XмҷҖ Yк°Җ мЎ°кұҙл¶Җ лҸ…лҰҪмқҙ лҗңлӢӨлҠ” кұҙ л¬ҙмҠЁ л§җмқјк№Ң? лӘЁнҳ•м—җ Aк°Җ нҸ¬н•ЁлҗҳлҠ” мЎ°кұҙ н•ҳм—җм„ңлҠ” XмҷҖ YліҖмҲҳк°Җ лҸ…лҰҪм ҒмңјлЎң мӣҖм§ҒмқҙкІҢ лҗңлӢӨ л”°лқјм„ң XліҖмҲҳк°Җ YліҖмҲҳм—җ мҳҒн–Ҙмқ„ мЈјм§Җ лӘ»н•ҳлҠ” мғҒнғңк°Җ лҗңлӢӨлҠ” кІғмқ„ мқҳлҜён•ңлӢӨ X Y X Y лҸ…лҰҪ м•„лӢҳ. Xк°Җ Yм—җ мҳҒн–Ҙмқ„ мӨ„ мҲҳ мһҲлӢӨ лҸ…лҰҪ. Xк°Җ Yм—җ мҳҒн–Ҙмқ„ мӨ„ мҲҳ м—ҶлӢӨ
- 18. Post-Treatment Bias мҷң л°ңмғқн• к№Ң? кі°нҢЎмқҙ м—¬л¶Җ ліҖмҲҳлҘј лӘЁнҳ•м—җ нҸ¬н•ЁмӢңнӮӨл©ҙ, лӢӨмқҢкіј к°ҷмқҖ м§Ҳл¬ёмқ„ н•ҳлҠ” кІғмқҙ лҗңлӢӨ "мӢқл¬јм—җ кі°нҢЎмқҙк°Җ н”јм—ҲлӢӨлҠ” кІғмқ„ мқҙлҜё м•Ңкі мһҲмқ„ л•Ң, вҖЁ кі°нҢЎмқҙ л°©м§Җ нҶ м–‘мқ„ мӮ¬мҡ©н•ҳлҠ” кІғмқҙ мӢқл¬јм—җ м„ұмһҘм—җ мҳҒн–Ҙмқ„ лҜём№ҳлҠ”к°Җ?" вҖЁ м •лӢөмқҖ "м•„лӢҲмҳӨ" к°Җ лҗңлӢӨ кі°нҢЎмқҙ л°©м§Җ нҶ м–‘мқ„ мӮ¬мҡ©н•ҳл©ҙ,вҖЁ кі°нҢЎмқҙк°Җ мғқкё°лҠ” кІғмқ„ л°©м§Җн•ҳлҠ” л°©мӢқмңјлЎң мӢқл¬јмқҳ м„ұмһҘм—җ мҳҒн–Ҙмқ„ лҜём№ҳкё° л•Ңл¬ёмқҙлӢӨ
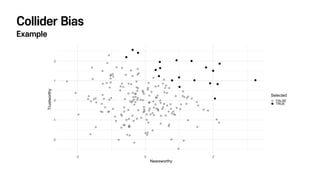
- 19. Collider Bias Definition & Example Definition - м„ңлЎң кҙҖл Ём—ҶлҠ” л‘җ ліҖмҲҳк°Җ лҳҗ лӢӨлҘё ліҖмҲҳм—җ лҸҷмӢңм—җ мҳҒн–Ҙмқ„ лҜём№ кІҪмҡ°, вҖЁ мӣҗмқём—җ н•ҙлӢ№н•ҳлҠ” л‘җ ліҖмҲҳк°Җ м„ңлЎң кҙҖл Ёмқҙ мһҲлҠ” кІғмІҳлҹј ліҙмқёлӢӨ Example : л…јл¬ё кІҢмһ¬ м—¬л¶Җ мӢң뮬л Ҳмқҙм…ҳ - л…јл¬ёмқҳ мӢ лў°лҸ„, к°Җм№ҳ к°’мқ„ лҸ…лҰҪм Ғмқё лӮңмҲҳлЎң мғқм„ұн•ңлӢӨ - мӢ лў°лҸ„ + к°Җм№ҳ м җмҲҳлҘј кё°мӨҖмңјлЎң мғҒмң„ 10% л…јл¬ёмқҙ м„ нғқлҗңлӢӨкі к°Җм •н•ҙліҙмһҗ - к·ёлҹ¬л©ҙ м„ нғқлҗң л…јл¬ёл“Өм—җм„ңлҠ” мӢ лў°лҸ„мҷҖ к°Җм№ҳ мӮ¬мқҙм—җ мқҢмқҳ мғҒкҙҖкҙҖкі„к°Җ лӮҳнғҖлӮңлӢӨ A B Y
- 21. Collider Bias мҷң л°ңмғқн• к№Ң? л‘җ ліҖмҲҳмқҳ кіөнҶө кІ°кіј ліҖмҲҳ(Collider)м—җ мЎ°кұҙмқ„ л¶Җм—¬н• л•Ң л°ңмғқн•ңлӢӨ Collider ліҖмҲҳм—җ мЎ°кұҙмқ„ л¶Җм—¬н•ҳл©ҙ, вҖЁ к·ё мӣҗмқём—җ н•ҙлӢ№н•ҳлҠ” ліҖмҲҳл“Ө мӮ¬мқҙм—җ к°Җм§ң мғҒкҙҖкҙҖкі„лҘј л§Ңл“Өм–ҙлӮёлӢӨ н‘ңліёмқ„ м„ нғқн•ҳлҠ” кіјм •мқҙ кІ°кіјм—җ мҳҒн–Ҙмқ„ лҜём№ҳлҠ” м„ нғқ нҺён–Ҙ(Selection Bias)кіј кҙҖл Ёмқҙ мһҲлӢӨ "мӢ лў°м„ұмқҙ л–Ём–ҙм§ҖлҠ” м—°кө¬к°Җ м Җл„җм—җ кІҢмһ¬лҗҳл Өл©ҙ вҖЁ к·ёл§ҢнҒј лүҙмҠӨкұ°лҰ¬лЎңм„ңлҠ” лҶ’мқҖ к°Җм№ҳк°Җ мһҲм–ҙм•ј н•ңлӢӨ. вҖЁ к·ёл Үм§Җ м•Ҡм•ҳлӢӨл©ҙ м•„мҳҲ м„ нғқмЎ°м°Ё л°ӣм§Җ лӘ»н–Ҳмқ„ кІғмқҙлӢӨ. вҖЁ к·ё л°ҳлҢҖлҸ„ л§Ҳм°¬к°Җм§ҖлӢӨ."
- 22. лӘЁнҳ•м—җ л„Јм–ҙм•ј н•ҳлҠ” ліҖмҲҳмҷҖ л№јм•ј н•ҳлҠ” ліҖмҲҳлҘј м–ҙл–»кІҢ кІ°м •н• мҲҳ мһҲмқ„к№Ң? мӢ¬мҠЁ нҢЁлҹ¬лҸ…мҠӨмІҳлҹј, вҖЁ мӨ‘мҡ”н•ң ліҖмҲҳк°Җ л№ м§ҖлҠ” кІҪмҡ° мһҳлӘ»лҗң н•ҙм„қмқ„ н•ҳкІҢ лҗҳлҠ” кІҪмҡ°к°Җ мһҲлӢӨ м•һм„ң мӮҙнҺҙліё Bias л“Өмқҙ л°ңмғқн•ңлӢӨл©ҙ, вҖЁ ліҖмҲҳк°Җ лӘЁнҳ•м—җ нҸ¬н•ЁлҗҳлҠ” кІғмқҙ мҳӨнһҲл Ө лӮҳмҒң н•ҙм„қмқ„ н•ҳкІҢ л§Ңл“ лӢӨ к·ёл ҮлӢӨл©ҙ лӘЁнҳ•мқ„ мҳ¬л°”лҘҙкІҢ н•ҙм„қн•ҳкё° мң„н•ҙм„ңлҠ” ліҖмҲҳлҘј м–ҙл–»кІҢ м„ нғқн•ҙм•ј н• к№Ң?
- 23. ліҖмҲҳл“Ө мӮ¬мқҙмқҳ кҙҖкі„лҘј <???> лЎң н‘ңнҳ„н•ҳкё°
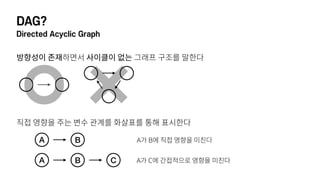
- 24. DAG? Directed Acyclic Graph л°©н–Ҙм„ұмқҙ мЎҙмһ¬н•ҳл©ҙм„ң мӮ¬мқҙнҒҙмқҙ м—ҶлҠ” к·ёлһҳн”„ кө¬мЎ°лҘј л§җн•ңлӢӨ вҖЁ м§Ғм ‘ мҳҒн–Ҙмқ„ мЈјлҠ” ліҖмҲҳ кҙҖкі„лҘј нҷ”мӮҙн‘ңлҘј нҶөн•ҙ н‘ңмӢңн•ңлӢӨ A B C A B Aк°Җ Bм—җ м§Ғм ‘ мҳҒн–Ҙмқ„ лҜём№ңлӢӨ Aк°Җ Cм—җ к°„м ‘м ҒмңјлЎң мҳҒн–Ҙмқ„ лҜём№ңлӢӨ
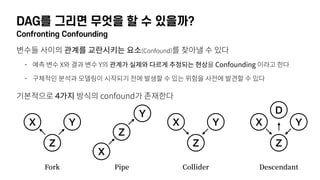
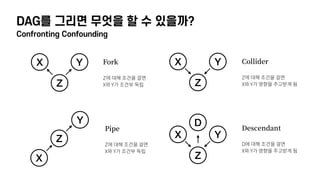
- 25. DAGлҘј к·ёлҰ¬л©ҙ л¬ҙм—Үмқ„ н• мҲҳ мһҲмқ„к№Ң? Confronting Confounding ліҖмҲҳл“Ө мӮ¬мқҙмқҳ кҙҖкі„лҘј көҗлһҖмӢңнӮӨлҠ” мҡ”мҶҢ(Confound)лҘј м°ҫм•„лӮј мҲҳ мһҲлӢӨ - мҳҲмёЎ ліҖмҲҳ XмҷҖ кІ°кіј ліҖмҲҳ Yмқҳ кҙҖкі„к°Җ мӢӨм ңмҷҖ лӢӨлҘҙкІҢ м¶”м •лҗҳлҠ” нҳ„мғҒмқ„ Confounding мқҙлқјкі н•ңлӢӨ - кө¬мІҙм Ғмқё 분м„қкіј лӘЁлҚёл§Ғмқҙ мӢңмһ‘лҗҳкё° м „м—җ л°ңмғқн• мҲҳ мһҲлҠ” мң„н—ҳмқ„ мӮ¬м „м—җ л°ңкІ¬н• мҲҳ мһҲлӢӨ кё°ліём ҒмңјлЎң 4к°Җм§Җ л°©мӢқмқҳ confoundк°Җ мЎҙмһ¬н•ңлӢӨ X Y Z Fork Pipe Collider Descendant X Y Z X Y Z X Y Z D
- 26. DAGлҘј к·ёлҰ¬л©ҙ л¬ҙм—Үмқ„ н• мҲҳ мһҲмқ„к№Ң? Confronting Confounding X Y Z ForkвҖЁ вҖЁ Zм—җ лҢҖн•ҙ мЎ°кұҙмқ„ кұёл©ҙвҖЁ XмҷҖ Yк°Җ мЎ°кұҙл¶Җ лҸ…лҰҪ X Y Z X Y Z X Y Z DPipeвҖЁ вҖЁ Zм—җ лҢҖн•ҙ мЎ°кұҙмқ„ кұёл©ҙвҖЁ XмҷҖ Yк°Җ мЎ°кұҙл¶Җ лҸ…лҰҪ ColliderвҖЁ вҖЁ Zм—җ лҢҖн•ҙ мЎ°кұҙмқ„ кұёл©ҙвҖЁ XмҷҖ Yк°Җ мҳҒн–Ҙмқ„ мЈјкі л°ӣкІҢ лҗЁ DescendantвҖЁ вҖЁ Dм—җ лҢҖн•ҙ мЎ°кұҙмқ„ кұёл©ҙвҖЁ XмҷҖ Yк°Җ мҳҒн–Ҙмқ„ мЈјкі л°ӣкІҢ лҗЁ
- 27. DAGлҠ” л§ҢлҠҘмқёк°Җ? м§Ҳл¬ёмқҙ мқҙлҹ¬л©ҙ м •лӢөмқҖ лӢ№м—°нһҲ м•„лӢҲмҳӨ..кІ мЈ ? DAGлЎң м„ӨлӘ…н•ҳм§Җ лӘ»н•ҳлҠ” л¶Җ분лҸ„ мһҲлӢӨ - interactionвҖЁ ліҖмҲҳл“Ө мӮ¬мқҙм—җ мғҒнҳёмһ‘мҡ©мқҙ л°ңмғқн•ҳлҠ” кІҪмҡ°вҖЁ вҖЁ вҖЁ - мҙҲкё° мЎ°кұҙм—җ лҜјк°җн•ң ліөмһЎкі„лҠ” м• мҙҲм—җ DAGлЎң н‘ңнҳ„н•ҳлҠ” кІғмқҙ м–ҙл өлӢӨ "нҶөкі„ лӘЁнҳ•лҸ„, мқёкіј кҙҖкі„лҘј лӮҳнғҖлӮё DAGлҸ„вҖЁ к·ё мһҗмІҙл§ҢмңјлЎң лӘЁл“ м •ліҙлҘј н‘ңнҳ„н• мҲҳлҠ” м—ҶлӢӨ" Y ~ X1 + X2 Y ~ X1 + X2 + X1:X2 X1 X2 Y X1 X2 Y мқён„°л үм…ҳ X мқён„°л үм…ҳ O
- 28. л§Ҳл¬ҙлҰ¬
- 29. к·ёлһҳм„ң, лҸ„лҢҖмІҙ л¬ҙм—Үмқҙ мҳ¬л°”лҘё н•ҙм„қмқ„ л°©н•ҙн•ҳкі мһҲлҠ”к°Җ? "лӘЁнҳ•" мқҙлқјлҠ” кІғ к·ё мһҗмІҙмқҳ л¬ём ң - лӘЁнҳ•мқҖ н•ӯмғҒ нӢҖлҰҙ мҲҳ мһҲлӢӨ - лӘЁнҳ•м—җм„ң м–»кі мһҗ н•ҳлҠ” кІғмқҙ л¬ҙм—Үмқјк№Ң? мҳҲмёЎ vs м¶”м • к·ёлҹ° лӘЁнҳ•мқ„ лҢҖн•ҳлҠ” "лӮҳмқҳ мһҗм„ё"мқҳ л¬ём ң - кі„мӮ°кё° лҢҖн•ҳл“Ҝмқҙ к°Җм§Җкі мһҲлҠ” ліҖмҲҳ лӘЁнҳ•м—җ лӢӨ л„Јкі лӮҳмҳЁ кІ°кіјлҘј 맹мӢ н•ҳм§Җ л§җмһҗ - лҚ°мқҙн„°к°Җ л§Ңл“Өм–ҙм§ҖлҠ” н”„лЎңм„ёмҠӨ мһҗмІҙм—җ лҢҖн•ҙм„ң кі лҜјн•ҳкё°