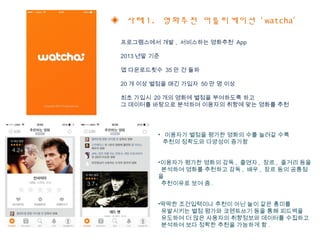
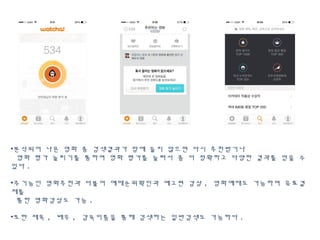
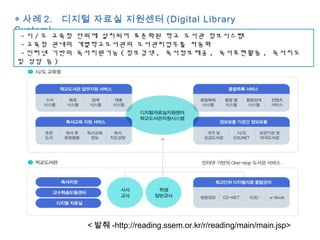
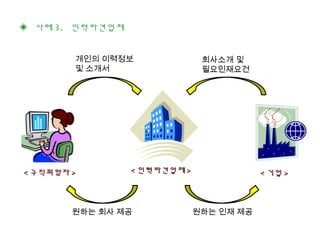
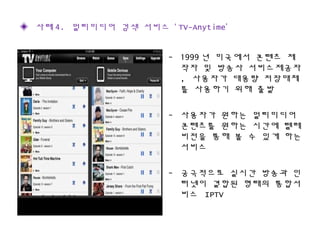
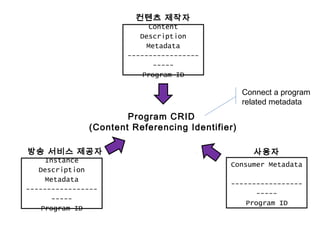
This document discusses data mining techniques and recommendation systems. It describes common data mining techniques like classification, clustering, regression, association rule mining and outlier analysis. It also discusses the knowledge discovery process and applications of data mining. The document then covers recommendation systems, describing content-based, collaborative filtering and hybrid recommendation approaches. It provides examples of these systems.
The document discusses the differences between data lakes and data warehouses, highlighting their distinct architectures, use cases, and accessibility. Data lakes allow for the storage of raw data and experimentation, primarily catering to data scientists, while data warehouses store structured data for business users seeking refined insights. Ultimately, organizations see data lakes as complementary to data warehouses, as they evolve to become crucial in enterprise data management strategies.
Natural Language Search with Knowledge Graphs (Activate 2019)Trey Grainger
╠¤
The document discusses natural language search using knowledge graphs. It provides an overview of knowledge graphs and how they can help with natural language search. Specifically, it discusses how knowledge graphs can represent relationships and semantics in unstructured text. It also describes how semantic knowledge graphs are generated in Solr and how they can be used for tasks like query understanding, expansion and disambiguation.
The document outlines the governance of Azure, focusing on management groups, role-based access control (RBAC), policies, and blueprints. It explains how management groups and subscriptions serve as organizational structures within Azure, along with the roles and policies that can be applied for resource management. Additionally, it discusses the creation and management of blueprints for deploying resources efficiently and in a compliant manner.
Learning to Rank Datasets for Search with Oscar CastanedaDatabricks
╠¤
Oscar Casta├▒eda presented on learning to rank datasets for search using Elasticsearch's learning to rank capabilities. He discussed extracting relevance judgements during data pipelines to bootstrap a dataset ranking model, and leveraging click-through data on dataset profiles to continuously improve the model. The demo showed ranking movie datasets based on a relevance judgement file, with movie profile pages representing dataset profiles. Next steps included describing datasets in a structured way, building a knowledge graph to extract insights, and using topic models to understand datasets.
From Insights to Action, How to build and maintain a Data Driven Organization...Amazon Web Services Korea
╠¤
The document outlines key insights from AWS Data Week 2023, highlighting the importance of a data-driven organization for innovation and decision-making in today's fast-paced business environment. It discusses common challenges faced by enterprises, such as data accessibility and governance, and emphasizes the need for stronger collaboration and the integration of data across departments. Additionally, it presents success stories and the transformative potential of modern data strategies, particularly leveraging data lakes and machine learning to improve operational efficiency and drive new revenue opportunities.
Azure Cosmos DB is Microsoft's globally distributed, multi-model database service that supports multiple APIs such as SQL, Cassandra, MongoDB, Gremlin and Azure Table. It allows storing entities with automatic partitioning and provides automatic online backups every 4 hours with the latest 2 backups stored. The Azure Cosmos DB change feed and Data Migration Tool allow importing and exporting data for backups. An emulator is also available for trying Cosmos DB locally without an Azure account.
Intelligence led policing- pole sandbox (webinar 21012019) Neo4j
╠¤
This document discusses using Neo4j and graph databases for intelligence-led policing. It introduces intelligence-led policing as an information-based model that aims to provide strategic knowledge and a targeted approach to crime reduction. The document outlines the POLE data model for representing people, objects, locations, and events in a graph. It then demonstrates Neo4j for implementing a graph database using crime data from Greater Manchester, with nodes for crimes, locations, people, and relationships between them. Finally, it discusses ways the demo could be extended for real-world use, such as adding more detailed relationships and supporting data traceability.
The document discusses Azure Storage, detailing various account types, redundancy options, encryption methods, and data structures such as block blobs, page blobs, and append blobs. It covers blob access tiers, lifecycle management for cost reduction, and features like snapshots and static hosting. Additionally, it describes table storage with its schemaless design, partitioning strategies, atomic transactions, and the file service for managed file sharing in the cloud.
Facebook, founded by Mark Zuckerberg in 2004, aims to connect people globally while collecting and organizing user data for targeted advertising. The platform's data mining capabilities enable businesses to analyze consumer behavior and enhance customer acquisition and retention, while also addressing privacy concerns. With over 2.13 billion monthly active users, Facebook continues to evolve from a social networking site into a powerful tool for data-driven marketing.
Scaling Django Apps using AWS Elastic BeanstalkLushen Wu
╠¤
The document discusses scaling Django applications using AWS Elastic Beanstalk, outlining the benefits of using it over manual EC2 management, auto-scaling, and load-balancing. It provides a comprehensive guide on creating and configuring an Elastic Beanstalk environment, details deployment processes, and emphasizes the importance of optimizing application performance beyond just scaling resources. Key considerations for using AWS, environment properties, deployment commands, and potential pitfalls during deployment are also addressed.
The document discusses what a website sitemap is and its purpose for planning and organizing a site's architecture, navigation, and content. It covers the different elements and types of sitemaps, and provides guidance on creating a sitemap including outlining the steps, tools, and principles to consider. The sitemap is presented as a collaborative planning tool to map out the logical structure and flow of a website.
The document introduces RDF (Resource Description Framework) as a W3C recommended framework used for describing resources on the web, emphasizing its format and structure based on triples (subject, predicate, object). It discusses the importance of Uniform Resource Identifiers (URIs) for naming resources and the role of RDF Schema (RDFS) in providing classification and interpretation of data. Additionally, the document addresses criticisms of RDF and highlights the framework's significance for semantic web interoperability.
Near Real-Time Netflix Recommendations Using Apache Spark Streaming with Nit...Databricks
╠¤
The document details Netflix's approach to near real-time recommendations, emphasizing the need to personalize content for over 125 million active members across 190 countries while handling vast data effectively. It highlights the challenges of scaling with increasing data volume and the importance of swift processing for timely recommendations and video insights. Key infrastructures and methods for achieving low latency and high performance, including Spark Streaming and auto-remediation strategies, are also discussed.
The document discusses the integration of Black Duck into agile DevOps environments, emphasizing the need for early vulnerability detection in the software development lifecycle (SDLC). It highlights the challenges companies face in managing open source security and the advantages of automating checks to reduce costs, time to market, and risks. Key recommendations include ensuring builds only contain approved components and implementing automated checks in continuous integration processes.
Intelligence led policing- pole sandbox (webinar 21012019) Neo4j
╠¤
This document discusses using Neo4j and graph databases for intelligence-led policing. It introduces intelligence-led policing as an information-based model that aims to provide strategic knowledge and a targeted approach to crime reduction. The document outlines the POLE data model for representing people, objects, locations, and events in a graph. It then demonstrates Neo4j for implementing a graph database using crime data from Greater Manchester, with nodes for crimes, locations, people, and relationships between them. Finally, it discusses ways the demo could be extended for real-world use, such as adding more detailed relationships and supporting data traceability.
The document discusses Azure Storage, detailing various account types, redundancy options, encryption methods, and data structures such as block blobs, page blobs, and append blobs. It covers blob access tiers, lifecycle management for cost reduction, and features like snapshots and static hosting. Additionally, it describes table storage with its schemaless design, partitioning strategies, atomic transactions, and the file service for managed file sharing in the cloud.
Facebook, founded by Mark Zuckerberg in 2004, aims to connect people globally while collecting and organizing user data for targeted advertising. The platform's data mining capabilities enable businesses to analyze consumer behavior and enhance customer acquisition and retention, while also addressing privacy concerns. With over 2.13 billion monthly active users, Facebook continues to evolve from a social networking site into a powerful tool for data-driven marketing.
Scaling Django Apps using AWS Elastic BeanstalkLushen Wu
╠¤
The document discusses scaling Django applications using AWS Elastic Beanstalk, outlining the benefits of using it over manual EC2 management, auto-scaling, and load-balancing. It provides a comprehensive guide on creating and configuring an Elastic Beanstalk environment, details deployment processes, and emphasizes the importance of optimizing application performance beyond just scaling resources. Key considerations for using AWS, environment properties, deployment commands, and potential pitfalls during deployment are also addressed.
The document discusses what a website sitemap is and its purpose for planning and organizing a site's architecture, navigation, and content. It covers the different elements and types of sitemaps, and provides guidance on creating a sitemap including outlining the steps, tools, and principles to consider. The sitemap is presented as a collaborative planning tool to map out the logical structure and flow of a website.
The document introduces RDF (Resource Description Framework) as a W3C recommended framework used for describing resources on the web, emphasizing its format and structure based on triples (subject, predicate, object). It discusses the importance of Uniform Resource Identifiers (URIs) for naming resources and the role of RDF Schema (RDFS) in providing classification and interpretation of data. Additionally, the document addresses criticisms of RDF and highlights the framework's significance for semantic web interoperability.
Near Real-Time Netflix Recommendations Using Apache Spark Streaming with Nit...Databricks
╠¤
The document details Netflix's approach to near real-time recommendations, emphasizing the need to personalize content for over 125 million active members across 190 countries while handling vast data effectively. It highlights the challenges of scaling with increasing data volume and the importance of swift processing for timely recommendations and video insights. Key infrastructures and methods for achieving low latency and high performance, including Spark Streaming and auto-remediation strategies, are also discussed.
The document discusses the integration of Black Duck into agile DevOps environments, emphasizing the need for early vulnerability detection in the software development lifecycle (SDLC). It highlights the challenges companies face in managing open source security and the advantages of automating checks to reduce costs, time to market, and risks. Key recommendations include ensuring builds only contain approved components and implementing automated checks in continuous integration processes.