Дрҗб…©бҶјб„ҖРЖЁб„ӢРЖІб„ҢРЖҘбҶ«Др’б…ЎбҶЁб„ӢРЖҜб„ҸРЖіб„үРЖЈбҶё
1 like888 views

нҒҙлқјмҡ°л“ң көҗмңЎмӮ¬лЎҖ








![нҒҙлқјмҡ°л“ңлҘј нҷңмҡ©н•ң мӢӨмҠө мҡ”мІӯм„ң
2015/4/8 9
OS Ubuntu 12.04 64bit (лҰ¬лҲ…мҠӨ)
м„ңлІ„мӮ¬м–‘
[ ] 4/8
[ ] 8/16
[ ] 8/60
[ ] 16/124
м„ңлІ„лӢ№ мӢӨмҠөмғқ __лӘ…/1лҢҖ
м„ңлІ„ лҢҖмҲҳ мҙқ __ лҢҖ
мҳҲм ң лҚ°мқҙн„° л””мҠӨнҒ¬ мҡ©лҹү __GB
мӮ¬мҡ©мһҗ л””мҠӨнҒ¬ мҡ©лҹү __GB
м ‘мҶҚ л°©лІ•
[ ] SSH
[ ] FTP
[ ] WEB
[ ] R-Studio Server
[ ] Remote Desktop
м„Өм№ҳ S/W лӘ©лЎқ](https://image.slidesharecdn.com/random-150414023411-conversion-gate01/85/-9-320.jpg)











![[м°ҫм•„к°ҖлҠ”м„ёлҜёлӮҳ] нҒҙлқјмҡ°л“ң лҚ°мқҙн„° к°ҖмғҒнҷ”мҶ”лЈЁм…ҳ](https://cdn.slidesharecdn.com/ss_thumbnails/4-160406062636-thumbnail.jpg?width=560&fit=bounds)


![[OpenInfra Days Korea 2018] (Track 4) - GrafanaлҘј мқҙмҡ©н•ң OpenStack нҒҙлқјмҡ°л“ң м„ұлҠҘ лӘЁлӢҲн„°л§Ғ](https://cdn.slidesharecdn.com/ss_thumbnails/42openinfraday201820180626grafana-180704055533-thumbnail.jpg?width=560&fit=bounds)

![[123] electron б„Җб…өбҶ·б„үб…ҘбҶјб„’б…®бҶ«](https://cdn.slidesharecdn.com/ss_thumbnails/123electron-161023163310-thumbnail.jpg?width=560&fit=bounds)



![м ң 15нҡҢ ліҙм•„мҰҲ(BOAZ) л№…лҚ°мқҙн„° м»ЁнҚјлҹ°мҠӨ - [YouPlace нҢҖ] : м№ҙн”„м№ҙмҷҖ мҠӨнҢҢнҒ¬лҘј нҷңмҡ©н•ң мң нҠңлёҢ мҳҒмғҒ мҶҚ м ңмЈј лӘ…мҶҢ кІҖмғү](https://cdn.slidesharecdn.com/ss_thumbnails/10youplace-220124105901-thumbnail.jpg?width=560&fit=bounds)








![[мӣЁл№„лӮҳ] Follow me! нҒҙлқјмҡ°л“ң мқён”„лқј кө¬м¶• кё°ліёнҺё - к°•м§ҖлӮҳ н…ҢнҒ¬ м—җл°ҳм ӨлҰ¬мҠӨнҠё](https://cdn.slidesharecdn.com/ss_thumbnails/follow-mecloudinfra-210723044820-thumbnail.jpg?width=560&fit=bounds)


More Related Content
Similar to Дрҗб…©бҶјб„ҖРЖЁб„ӢРЖІб„ҢРЖҘбҶ«Др’б…ЎбҶЁб„ӢРЖҜб„ҸРЖіб„үРЖЈбҶё (20)
More from Hong ChangBum (20)


















Дрҗб…©бҶјб„ҖРЖЁб„ӢРЖІб„ҢРЖҘбҶ«Др’б…ЎбҶЁб„ӢРЖҜб„ҸРЖіб„үРЖЈбҶё
- 1. нҒҙлқјмҡ°л“ң көҗмңЎ мӮ¬лЎҖ Changbum Hong GenomeCloud, KT
- 2. нҒҙлқјмҡ°л“ңлҘј мқҙмҡ©н•ң көҗмңЎ мӢӨм Ғ вҖў лҶҚ진мІӯ (2014) 1. Galaxy кё°л°ҳ DNA/RNA-Seq көҗмңЎ 2. De-novo көҗмңЎ вҖў EBI вҖ“Workshop (2014) 1. ChIP-seq, Epigenome 분м„қ вҖў нҶөкі„ мң м „н•ҷ мӣҢнҒ¬мғө (2013-2014) 1. лҰ¬лҲ…мҠӨ көҗмңЎ вҖў лҸҷкі„ мң м „мІҙн•ҷнҡҢ (2015) 1. Somatic Mutation көҗмңЎ 2. R кё°л°ҳмқҳ Visualization көҗмңЎ вҖў KOBIC м°Ём„ёлҢҖ мғқлӘ…м •ліҙн•ҷ көҗмңЎ (2015) 1. DNA/RNA-SeqкөҗмңЎ 2. R кё°л°ҳмқҳ мң м „мІҙ 분м„қ көҗмңЎ 2015/4/8 2
- 3. нҒҙлқјмҡ°л“ң мһҘм җ вҖў көҗмңЎмһҗ кҙҖм җ 1. н•ңлІҲ м„Өм •н•ң м„ңлІ„ нҷҳкІҪмқ„ м–ём ңлӮҳ нҷңмҡ© к°ҖлҠҘ (1л…„ нӣ„м—җлҸ„ лӢӨмӢң лҸҷмқјн•ң көҗмңЎнҷҳкІҪмқ„ л°”лЎң л§Ңл“Ө мҲҳ мһҲмқҢ) 2. S/W м„Өм№ҳмӢң көҗмңЎмғқ нҷҳкІҪм—җ л”°лҘё л””лІ„к№… н•„мҡ” м—ҶмқҢ 3. көҗмңЎмғқ лӘЁл‘җ 100% лҸҷмқјн•ң мӢӨмҠө нҷҳкІҪ м ңкіө к°ҖлҠҘ 4. лҚ°мқҙн„°м „лӢ¬мқ„ мң„н•ң USBлӮҳ 버추얼 нҷҳкІҪ(мқҙлҜём§Җ) н•„мҡ” м—ҶмқҢ вҖў көҗмңЎмғқ кҙҖм җ 1. ліөмһЎн•ң S/W м„Өм№ҳ л°Ҹ м„Өм • кіјм • м—Ҷмқҙ л°”лЎң мӢӨмҠө к°ҖлҠҘ 2. мҳҲм ң лҚ°мқҙн„°лҘј лӢӨмҡҙлЎңл“ң н•„мҡ”м—Ҷмқҙ л°”лЎң мӢӨмҠө к°ҖлҠҘ 3. көҗмңЎкё°к°„лӮҙм—җ м–ём ң м–ҙл””м„ңл“ м§Җ мӢӨмҠө к°ҖлҠҘ 4. көҗмңЎнӣ„м—җлҸ„ м–јл§Ҳк°„ көҗмңЎмғқл“Өм—җкІҢ мӢӨмҠө кіөк°„ м ңкіө 2015/4/8 3
- 4. көҗмңЎмӮ¬лЎҖ: Galaxy көҗмңЎ вҖў көҗмңЎлӮҙмҡ© 1. GalaxyлҘј мқҙмҡ©н•ң NGS лҚ°мқҙн„° 분м„қ (DNA/RNA) вҖў м ңкіөлӮҙмҡ© 1. Galaxyк°Җ м„Өм№ҳлҗң нҒҙлҹ¬мҠӨн„° м»ҙн“Ён„° 2. 8core 16GB x 30лҢҖ 3. KTм—җм„ң лҜёлҰ¬ м ңкіөлҗҳлҠ” Galaxy мқҙлҜём§ҖлҘј нҷңмҡ© 4. көҗмңЎмғқм—җкІҢ л°ңкёүн• Galaxy кі„м • мғқм„ұ 5. көҗмңЎлӢ№мқј galaxy м ‘мҶҚ мЈјмҶҢмҷҖ кі„м •мқ„ н• лӢ№ 6. мӣ№мқ„ мқҙмҡ©н•ҳм—¬ galaxy м ‘мҶҚ 2015/4/8 4
- 5. көҗмңЎмӮ¬лЎҖ: De-novo көҗмңЎ вҖў көҗмңЎлӮҙмҡ© 1. De-novo м—җм…Ҳлё”лҰ¬ көҗмңЎ вҖў м ңкіөлӮҙмҡ© 1. 16 core 128 GBмқҳ лҢҖмҡ©лҹү л©”лӘЁлҰ¬ м„ңлІ„ 1лҢҖ 2. 16 core 32 GB 29лҢҖ 3. көҗмңЎмһҗк°Җ көҗмңЎ 1мЈјм „ м§Ғм ‘ м„ңлІ„ нҷҳкІҪ м„Өм • (S/W м„Өм№ҳ л“ұ) 4. нҷҳкІҪм„Өм •лҗң м„ңлІ„ 1лҢҖлҘј мқҙлҜём§Җнҷ” (1мқј) 5. 29лҢҖмқҳ м„ңлІ„лҘј мқҙлҜём§ҖлҘј мқҙмҡ©н•ҳм—¬ м„Өм • (1мқј) 6. SSHлҘј нҶөн•ҙ н„°лҜёл„җ м ‘мҶҚ 2015/4/8 5
- 6. көҗмңЎмӮ¬лЎҖ: EBI Workshop вҖў көҗмңЎлӮҙмҡ© 1. ChIP-Seq, Epigenome лҚ°мқҙн„° 분м„қ вҖў м ңкіөлӮҙмҡ© 1. EBIм—җм„ң мҡ”кө¬н•ҳлҠ” S/W м„Өм№ҳ (м•Ҫ1мЈј) 2. м„Өм№ҳк°Җ мҷ„лЈҢлҗң м„ңлІ„м—җ лҢҖн•ҙм„ң мқҙлҜём§Җ мһ‘м—… мҲҳн–ү (1мқј) 3. лҸҷмӢңм—җ 30лҢҖмқҳ м„ңлІ„лҘј лҸҷмқјн•ң нҷҳкІҪмңјлЎң мғқм„ұ (1мқј) 4. 8core 16GB x 30лҢҖ 5. м„ңлІ„ 1лҢҖм—җ көҗмңЎмғқ 2лӘ…м”© н• лӢ№н•ҳм—¬ мӮ¬мҡ© 6. көҗмңЎмғқмқҖ мӣҗкІ©м ‘мҶҚ S/WлҘј мқҙмҡ©н•ҳм—¬ IGV л“ұ к·ёлһҳн”Ҫ нҷҳкІҪ мӮ¬мҡ© 2015/4/8 6
- 7. көҗмңЎмӮ¬лЎҖ: R көҗмңЎ вҖў көҗмңЎлӮҙмҡ© 1. Rмқ„ мқҙмҡ©н•ң NGS лҚ°мқҙн„° 분м„қ вҖў м ңкіөлӮҙмҡ© 1. R нҢЁнӮӨм§Җ м„Өм№ҳ (м•Ҫ1мЈј) 2. м„Өм№ҳк°Җ мҷ„лЈҢлҗң м„ңлІ„м—җ лҢҖн•ҙм„ң мқҙлҜём§Җ мһ‘м—… мҲҳн–ү (1мқј) 3. лҸҷмӢңм—җ 30лҢҖмқҳ м„ңлІ„лҘј лҸҷмқјн•ң нҷҳкІҪмңјлЎң мғқм„ұ (1мқј) 4. 8core 16GB x 30лҢҖ 5. м„ңлІ„ 1лҢҖм—җ көҗмңЎмғқ 2лӘ…м”© н• лӢ№н•ҳм—¬ мӮ¬мҡ© 6. көҗмңЎмғқмқҖ R Studio ServerлҘј мқҙмҡ©н•ҳм—¬ мӣ№мқ„ нҶөн•ҙ R мҪ”л“ң мһ‘м„ұ л°Ҹ к·ёлһҳн”„ нҷ•мқё 2015/4/8 7
- 8. көҗмңЎмқ„ мң„н•ң м„ңлІ„ мІҙнҒ¬ лҰ¬мҠӨнҠё вҖў көҗмңЎмғқлӢ№ м„ңлІ„ мһҗмӣҗ (cpu, disk) 1. көҗмңЎм—җ н•„мҡ”н•ң 분м„қ мӢңк°„ кі л Өн•ҳм—¬ cpu, memory кІ°м • 2. 분м„қ лҚ°мқҙн„°(мҳҲм ң лҚ°мқҙн„° + көҗмңЎмғқ мғқм„ұ лҚ°мқҙн„°)мқҳ нҒ¬кё°м—җ л”°лқј кіөмң л””мҠӨнҒ¬ (TBкёү) or лЎң컬 л””мҠӨнҒ¬ (80GB) кІ°м • вҖў S/W 1. Ubuntu 12.04 кё°л°ҳм—җм„ң S/W м„Өм№ҳ вҖў м ‘мҶҚл°©лІ• 1. SSH, мӣҗкІ©лҚ°мҠӨнҒ¬нғ‘, мӣ№ 2015/4/8 8
- 9. нҒҙлқјмҡ°л“ңлҘј нҷңмҡ©н•ң мӢӨмҠө мҡ”мІӯм„ң 2015/4/8 9 OS Ubuntu 12.04 64bit (лҰ¬лҲ…мҠӨ) м„ңлІ„мӮ¬м–‘ [ ] 4/8 [ ] 8/16 [ ] 8/60 [ ] 16/124 м„ңлІ„лӢ№ мӢӨмҠөмғқ __лӘ…/1лҢҖ м„ңлІ„ лҢҖмҲҳ мҙқ __ лҢҖ мҳҲм ң лҚ°мқҙн„° л””мҠӨнҒ¬ мҡ©лҹү __GB мӮ¬мҡ©мһҗ л””мҠӨнҒ¬ мҡ©лҹү __GB м ‘мҶҚ л°©лІ• [ ] SSH [ ] FTP [ ] WEB [ ] R-Studio Server [ ] Remote Desktop м„Өм№ҳ S/W лӘ©лЎқ
- 10. нҒҙлқјмҡ°л“ңлҘј мқҙмҡ©н•ң көҗмңЎ н”„лЎңм„ёмҠӨ вҖў мқҙлҜём§Җ мғқм„ұмқ„ мң„н•ң м„ңлІ„ м ңкіө 1. Ubuntu 12.04 кё°л°ҳ 2. S/W л°Ҹ лқјмқҙлёҢлҹ¬лҰ¬ м„Өм№ҳ (path м§Җм •) 3. мҳҲм ң лҚ°мқҙн„° м ҖмһҘ вҖў мқҙлҜём§Җ мғқм„ұ (1мқј) вҖў м„ңлІ„лӢ№ к°ҖлҠҘн•ң мӢӨмҠө мқёмӣҗ нҢҢм•… (1мқёлӢ№ 8/16) 1. 1мқёлӢ№ 8core 16GB 1лҢҖм”© м ңкіө 2. лҳҗлҠ” 16core 32 GBлҘј нҶөн•ҙ м„ңлІ„лӢ№ 2лӘ…м”© м ‘мҶҚ вҖў мқҙлҜём§ҖлҘј нҶөн•ҙ лӢӨмҲҳмқҳ лҸҷмқјн•ң нҷҳкІҪмқҳ м„ңлІ„ мғқм„ұ (1мқј) вҖў көҗмңЎм—җ нҷңмҡ©н• м ‘мҶҚ мЈјмҶҢ, м•„мқҙл””/м•”нҳё лҰ¬мҠӨнҠё м „лӢ¬ 2015/4/8 10
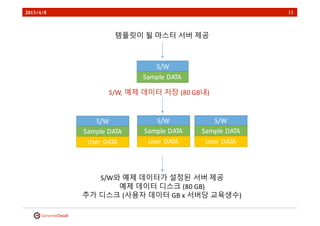
- 11. 2015/4/8 11 S/W н…ңн”ҢлҰҝмқҙ Мэлҗ Мэл§ҲмҠӨн„° Мэм„ңлІ„ Мэм ңкіө S/W, МэмҳҲм ң МэлҚ°мқҙн„° Мэм ҖмһҘ Мэ(80 МэGBлӮҙ) S/W S/WмҷҖ МэмҳҲм ң МэлҚ°мқҙн„°к°Җ Мэм„Өм •лҗң Мэм„ңлІ„ Мэм ңкіө Мэ мҳҲм ң МэлҚ°мқҙн„° Мэл””мҠӨнҒ¬ Мэ(80 МэGB) Мэ 추к°Җ Мэл””мҠӨнҒ¬ Мэ(мӮ¬мҡ©мһҗ МэлҚ°мқҙн„° МэGB Мэx Мэм„ңлІ„лӢ№ МэкөҗмңЎмғқмҲҳ) Мэ Sample МэDATA Sample МэDATA User МэDATA S/W Sample МэDATA User МэDATA S/W Sample МэDATA User МэDATA
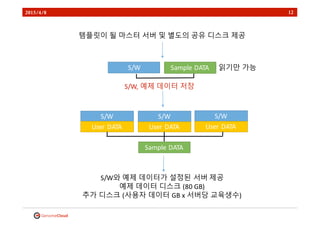
- 12. 2015/4/8 12 S/W н…ңн”ҢлҰҝмқҙ Мэлҗ Мэл§ҲмҠӨн„° Мэм„ңлІ„ Мэл°Ҹ Мэлі„лҸ„мқҳ Мэкіөмң Мэл””мҠӨнҒ¬ Мэм ңкіө S/W, МэмҳҲм ң МэлҚ°мқҙн„° Мэм ҖмһҘ S/W S/WмҷҖ МэмҳҲм ң МэлҚ°мқҙн„°к°Җ Мэм„Өм •лҗң Мэм„ңлІ„ Мэм ңкіө Мэ мҳҲм ң МэлҚ°мқҙн„° Мэл””мҠӨнҒ¬ Мэ(80 МэGB) Мэ 추к°Җ Мэл””мҠӨнҒ¬ Мэ(мӮ¬мҡ©мһҗ МэлҚ°мқҙн„° МэGB Мэx Мэм„ңлІ„лӢ№ МэкөҗмңЎмғқмҲҳ) Мэ Sample МэDATA User МэDATA S/W User МэDATA S/W User МэDATA Sample МэDATA мқҪкё°л§Ң Мэк°ҖлҠҘ
- 13. KT м§Җмӣҗ вҖў S/W м„Өм№ҳ м§Җмӣҗ вҖў л§ҲмҠӨн„° м„ңлІ„м—җ м„Өм •мқҙ мҷ„лЈҢлҗҳл©ҙ мӣҗн•ҳлҠ” лҢҖмҲҳ л§ҢнҒј м„ңлІ„ мғқм„ұ м§Җмӣҗ вҖў мӮ¬мҡ©мһҗ кі„м • мғқм„ұ м§Җмӣҗ вҖў м ‘мҶҚ нҷҳкІҪ м§Җмӣҗ : ssh (кё°ліё), ftp, web(r-studio server, ipython notebook) 2015/4/8 13