ウェーブレットと多重解像度処理
Download as pptx, pdf3 likes11,060 views

ゼミのスライドです。Digital Image Processing ウェーブレットと多重解像度処理

































































ウェーブレットと多重解像度処理
- 1. Digital Image Processing 第7章 ウェーブレットと多重解像度処理(後半) 15X3026 岡本秀明(おっかー) 1
- 2. 目次 ?導入 ?7.4 高速ウェーブレット変換 ?7.5 2次元ウェーブレット変換 ?7.6 ウェーブレットパケット変換 2目次
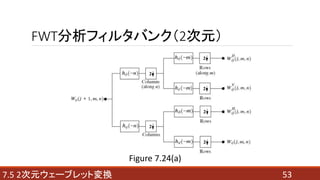
- 5. 目次 ?7.5 2次元ウェーブレット変換 ?2次元への拡張 (2つの関数、離散、逆離散、FWT分析、FWT合成) ?画像をウェーブレット変換する例 ?シムレット ?ウェーブレット変換後の画像処理 (例1 エッジ強調 例2 ノイズ除去) 5目次
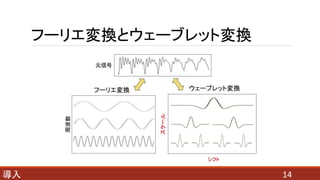
- 7. 導入 7
- 20. 連続ウェーブレット変換 20導入 ? : 元信号 ? : スケールs, シフトtのウェーブレット関数 に基づいたウェーブレット変換 ? : スケールs, シフトtのウェーブレット関数 ???(7.3-9)
- 21. 逆連続ウェーブレット変換 21導入 ただし、 ? : 元信号 ? : スケールs, シフトtのウェーブレット関数 に基づいたウェーブレット変換 ? : スケールs, シフトtのウェーブレット関数 ? : マザーウェーブレットの種類によって変わる定数 ???(7.3-10) ???(7.3-11)
- 24. 離散ウェーブレット変換 24導入 ? : 元信号 ? , : 離散ウェーブレット変換 ? : スケールj0, シフトkのスケーリング関数 ? :スケールj, シフトkのウェーブレット関数 ?M = (L: 原信号のレベル l: 多重解像度解析におけるレベル) ???(7.3-5) ???(7.3-6)
- 25. 逆離散ウェーブレット変換 25導入 ? : 元信号 ? , : 離散ウェーブレット変換 ? : スケールj0, シフトkのスケーリング関数 ? :スケールj, シフトkのウェーブレット関数 ?M = (L: 原信号のレベル l: 多重解像度解析におけるレベル) ???(7.3-7)
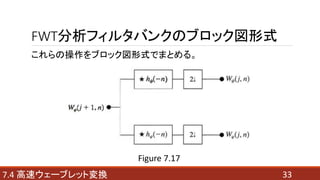
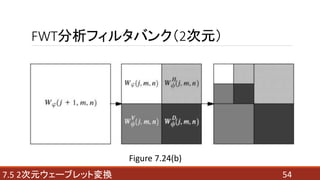
- 29. FWT分析フィルタバンク 解像度が異なる信号のスケーリング係数と ウェーブレット係数の間には、次の関係が成立する。 : ? : ウェーブレット係数 ? : ウェーブレットベクトル ? : スケーリング係数 ? : スケーリングベクトル 297.4 高速ウェーブレット変換 ???(7.4-9) ???(7.4-10)
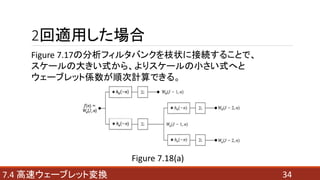
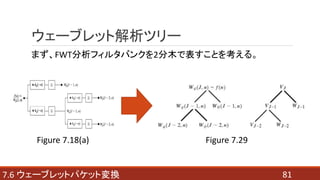
- 34. 2回適用した場合 347.4 高速ウェーブレット変換 Figure 7.18(a) Figure 7.17の分析フィルタバンクを枝状に接続することで、 スケールの大きい式から、よりスケールの小さい式へと ウェーブレット係数が順次計算できる。
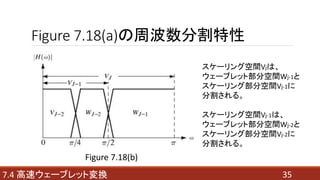
- 35. Figure 7.18(a)の周波数分割特性 357.4 高速ウェーブレット変換 Figure 7.18(b) スケーリング空間Vjは、 ウェーブレット部分空間Wj-1と スケーリング部分空間Vj-1に 分割される。 スケーリング空間Vj-1は、 ウェーブレット部分空間Wj-2と スケーリング部分空間Vj-2に 分割される。
- 36. FWT分析フィルタバンクの例題 367.4 高速ウェーブレット変換 ハールスケーリングおよびウェーブレットベクトルを用いて f(n) = {1, 4, -3, 0} の高速ウェーブレット変換を計算せよ。 ただし、 とする。
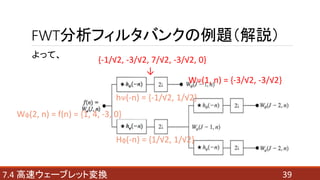
- 37. FWT分析フィルタバンクの例題(解説) 377.4 高速ウェーブレット変換 問題条件をFigure 7.18(a)に適用して、 Wφ(2, n) = f(n) = {1, 4, -3, 0} hΨ(-n) = {-1/√2, 1/√2} Hφ(-n) = {1/√2, 1/√2}
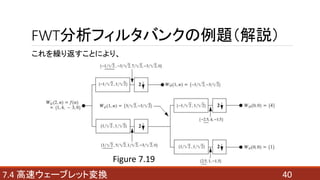
- 38. FWT分析フィルタバンクの例題(解説) 387.4 高速ウェーブレット変換 より、 Wφ(2, n) = {1, 4, -3, 0} と、hΨ(-n) = {-1/√2, 1/√2} の畳み込みの 偶数インデックス部分が、WΨ(1, n)と同値となる。 つまり、 hΨ(-n)を反転させ、 それをWφ(2, n)に通過させた時の2つの関数の積の合計を順に並べる。 このときの偶数番目が求める値となるので {-1/√2, -3/√2, 7/√2, -3/√2, 0} → WΨ(1, n) = {-3/√2, -3/√2}
- 39. FWT分析フィルタバンクの例題(解説) 397.4 高速ウェーブレット変換 よって、 Wφ(2, n) = f(n) = {1, 4, -3, 0} hΨ(-n) = {-1/√2, 1/√2} Hφ(-n) = {1/√2, 1/√2} {-1/√2, -3/√2, 7/√2, -3/√2, 0} ↓ WΨ(1, n) = {-3/√2, -3/√2}
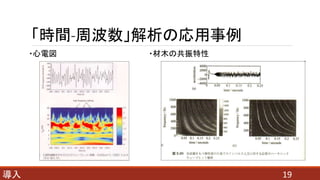
- 41. FWT分析フィルタバンクの例題(解説) 417.4 高速ウェーブレット変換 したがって求める解は、 WΨ(1, n) = {-3/√2, -3/√2} Wφ(1, n) = {5/√2, -3/√2} WΨ(0, n) = {4} Wφ(0, n) = {1}
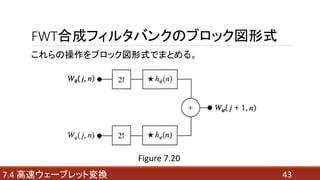
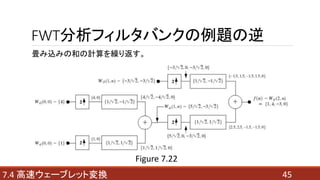
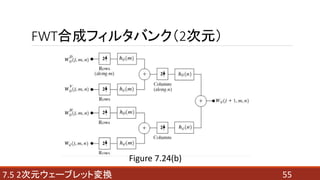
- 42. FWT合成フィルタバンク 逆高速ウェーブレット変換と同義。 スケールjの式から、スケールj+1の式を求めることができる。 ? : ウェーブレット係数 ? : ウェーブレットベクトル ? : スケーリング係数 ? : スケーリングベクトル 427.4 高速ウェーブレット変換 ???(7.4-14)
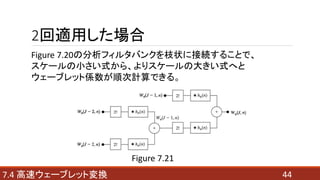
- 44. 2回適用した場合 447.4 高速ウェーブレット変換 Figure 7.21 Figure 7.20の分析フィルタバンクを枝状に接続することで、 スケールの小さい式から、よりスケールの大きい式へと ウェーブレット係数が順次計算できる。
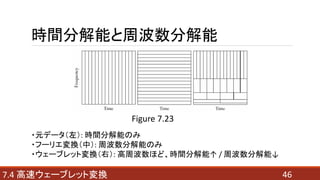
- 46. 時間分解能と周波数分解能 467.4 高速ウェーブレット変換 Figure 7.23 ?元データ(左): 時間分解能のみ ?フーリエ変換(中): 周波数分解能のみ ?ウェーブレット変換(右): 高周波数ほど、時間分解能↑ / 周波数分解能↓
- 48. 目次 ?7.5 2次元ウェーブレット変換 ?2次元への拡張 (2つの関数、離散、逆離散、FWT分析、FWT合成) ?画像をウェーブレット変換する例 ?シムレット ?ウェーブレット変換後の画像処理 (例1 エッジ強調 例2 ノイズ除去) 487.5 2次元ウェーブレット変換
- 57. 577.5 2次元ウェーブレット変換 画像を高速ウェーブレット変換する例 Figure 7.25(b) 元画像を高速ウェーブレット変換した結果。 近似成分 元画像の1/4の大きさ 水平方向の詳細成分 鉛直方向の詳細成分 斜め方向の详细成分
- 58. 587.5 2次元ウェーブレット変換 画像を高速ウェーブレット変換する例 Figure 7.25(c) Figure 7.25(b)の左上の画像を高速ウェーブレット変換した結果。 近似成分 元画像の1/16の大きさ 水平方向の詳細成分 鉛直方向の詳細成分 斜め方向の详细成分
- 59. 597.5 2次元ウェーブレット変換 画像を高速ウェーブレット変換する例 Figure 7.25(d) Figure 7.25(c)の左上の画像を高速ウェーブレット変換した結果。 近似成分 元画像の1/64の大きさ 水平方向の詳細成分 鉛直方向の詳細成分 斜め方向の详细成分
- 60. 607.5 2次元ウェーブレット変換 シムレット 先ほどの画像の例で使われているマザーウェーブレット。 symmetrical wavelet → symlet 最も基本的なウェーブレットと考えられるハールの 基底の不連続さを解消しつつ、 可能な限り対称になるように設計されている。 これにより、一般的な自然画像の変換や圧縮ができるようになる。
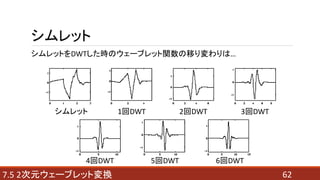
- 62. 627.5 2次元ウェーブレット変換 シムレット シムレットをDWTした時のウェーブレット関数の移り変わりは… シムレット 1回DWT 2回DWT 3回DWT 4回DWT 5回DWT 6回DWT
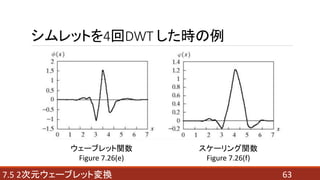
- 63. 637.5 2次元ウェーブレット変換 シムレットを4回DWT した時の例 ウェーブレット関数 Figure 7.26(e) スケーリング関数 Figure 7.26(f)
- 64. 647.5 2次元ウェーブレット変換 シムレットを4回DWT した時の例 Figure 7.26(c) Table 7.3 hφ(n)に対する4回DWT時の正規直交シムレットフィルタ(合成フィルタ)の係数は 以下のようになる。(→ 7.1.2 Subband Coding)
- 65. 657.5 2次元ウェーブレット変換 Figure 7.26(a), (b) 分解フィルタ 残りの正規直交フィルタの係数は以下のようになる。 Figure 7.26(c), (d) 合成フィルタ ??? (7.1-14) より、 シムレットを4回DWT した時の例
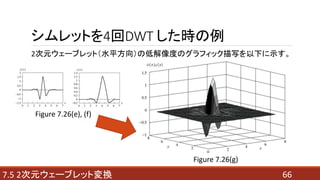
- 66. 667.5 2次元ウェーブレット変換 2次元ウェーブレット(水平方向)の低解像度のグラフィック描写を以下に示す。 Figure 7.26(g) Figure 7.26(e), (f) シムレットを4回DWT した時の例
- 67. 677.5 2次元ウェーブレット変換 ウェーブレット変換後の画像処理 基本的なアプローチはフーリエ領域の場合と同様。 【大まかな手順】 1. 画像の2次元ウェーブレット変換を計算する。 2. フィルタリング処理を適用する。 3. 逆変換を計算する。 スケーリングおよびウェーブレットベクトルは、 ローパスおよびハイパスフィルタとして使用される。 よって、フーリエベースのフィルタリング技術のほとんどは、 同等のウェーブレットベースのフィルタリング技術を有する。
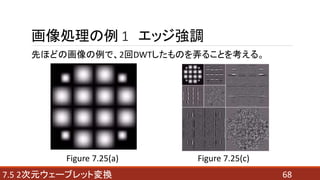
- 68. 687.5 2次元ウェーブレット変換 画像処理の例 1 エッジ強調 先ほどの画像の例で、2回DWTしたものを弄ることを考える。 Figure 7.25(a) Figure 7.25(c)
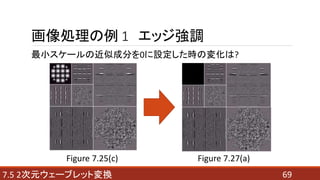
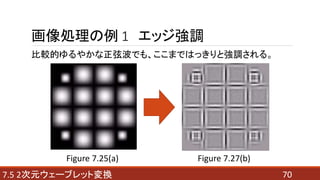
- 69. 697.5 2次元ウェーブレット変換 画像処理の例 1 エッジ強調 最小スケールの近似成分を0に設定した時の変化は? Figure 7.25(c) Figure 7.27(a)
- 70. 707.5 2次元ウェーブレット変換 画像処理の例 1 エッジ強調 比較的ゆるやかな正弦波でも、ここまではっきりと強調される。 Figure 7.25(a) Figure 7.27(b)
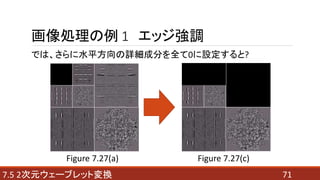
- 71. 717.5 2次元ウェーブレット変換 画像処理の例 1 エッジ強調 では、さらに水平方向の詳細成分を全て0に設定すると? Figure 7.27(a) Figure 7.27(c)
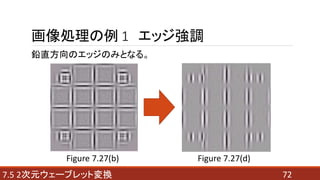
- 72. 727.5 2次元ウェーブレット変換 画像処理の例 1 エッジ強調 鉛直方向のエッジのみとなる。 Figure 7.27(b) Figure 7.27(d)
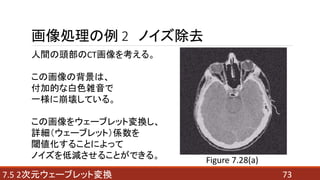
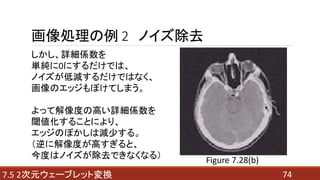
- 73. 737.5 2次元ウェーブレット変換 画像処理の例 2 ノイズ除去 人間の頭部のCT画像を考える。 この画像の背景は、 付加的な白色雑音で 一様に崩壊している。 この画像をウェーブレット変換し、 詳細(ウェーブレット)係数を 閾値化することによって ノイズを低減させることができる。 Figure 7.28(a)
- 74. 747.5 2次元ウェーブレット変換 画像処理の例 2 ノイズ除去 しかし、詳細係数を 単純に0にするだけでは、 ノイズが低減するだけではなく、 画像のエッジもぼけてしまう。 よって解像度の高い詳細係数を 閾値化することにより、 エッジのぼかしは減少する。 (逆に解像度が高すぎると、 今度はノイズが除去できなくなる) Figure 7.28(b)
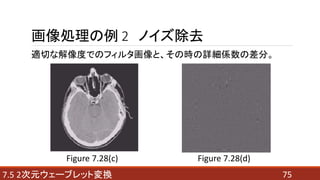
- 75. 757.5 2次元ウェーブレット変換 画像処理の例 2 ノイズ除去 適切な解像度でのフィルタ画像と、その時の詳細係数の差分。 Figure 7.28(c) Figure 7.28(d)
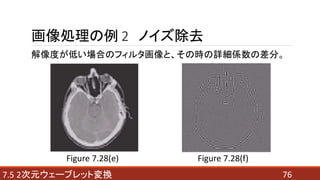
- 76. 767.5 2次元ウェーブレット変換 画像処理の例 2 ノイズ除去 解像度が低い場合のフィルタ画像と、その時の詳細係数の差分。 Figure 7.28(e) Figure 7.28(f)
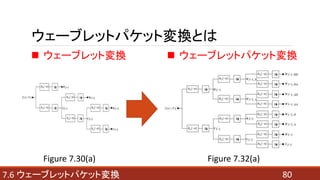
- 80. 807.6 ウェーブレットパケット変換 ウェーブレットパケット変換とは ? ウェーブレット変換 Figure 7.30(a) Figure 7.32(a) ? ウェーブレットパケット変換
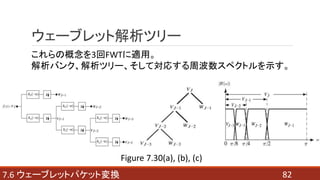
- 82. 827.6 ウェーブレットパケット変換 ウェーブレット解析ツリー これらの概念を3回FWTに適用。 解析バンク、解析ツリー、そして対応する周波数スペクトルを示す。 Figure 7.30(a), (b), (c)
- 83. 837.6 ウェーブレットパケット変換 ウェーブレット解析ツリー この解析ツリーは、ウェーブレット変換をよりコンパクトに表し、 ウェーブレット関数とスケーリング関数の関係性を和集合で 表したものと対応していることがわかる。 Figure 7.30(b) ??? (7.6-1) ??? (7.6-2) ??? (7.6-3)
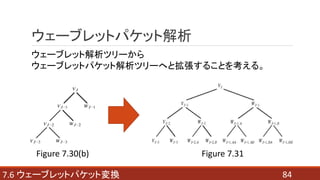
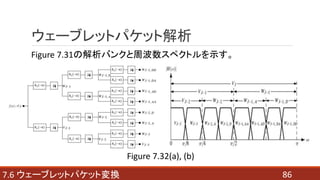
- 84. 847.6 ウェーブレットパケット変換 ウェーブレットパケット解析 ウェーブレット解析ツリーから ウェーブレットパケット解析ツリーへと拡張することを考える。 Figure 7.30(b) Figure 7.31
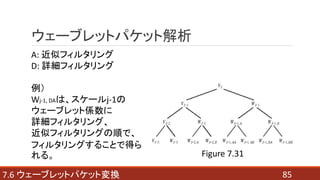
- 85. 857.6 ウェーブレットパケット変換 ウェーブレットパケット解析 A: 近似フィルタリング D: 詳細フィルタリング 例) Wj-1, DAは、スケールj-1の ウェーブレット係数に 詳細フィルタリング、 近似フィルタリングの順で、 フィルタリングすることで得ら れる。 Figure 7.31
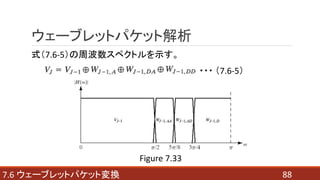
- 87. 877.6 ウェーブレットパケット変換 ウェーブレットパケット解析 Figure 7.32(b)を和集合で表した例を示す。 ??? (7.6-4) ??? (7.6-5)
- 89. 897.6 ウェーブレットパケット変換 ウェーブレットパケット解析 一般に、Pスケールの1次元ウェーブレットパケット変換における 可能な分解の数は以下のように表される。 ??? (7.6-6)
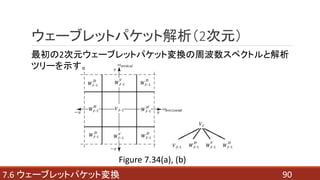
- 90. 907.6 ウェーブレットパケット変換 ウェーブレットパケット解析(2次元) 最初の2次元ウェーブレットパケット変換の周波数スペクトルと解析 ツリーを示す。 Figure 7.34(a), (b)
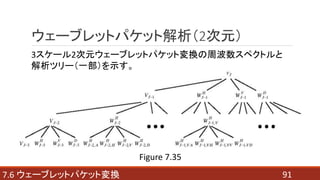
- 91. 917.6 ウェーブレットパケット変換 ウェーブレットパケット解析(2次元) 3スケール2次元ウェーブレットパケット変換の周波数スペクトルと 解析ツリー(一部)を示す。 Figure 7.35
- 92. 927.6 ウェーブレットパケット変換 一般に、Pスケールの2次元ウェーブレットパケット変換における 可能な分解の数は以下のように表される。 つまり、 3スケール2次元ウェーブレットパケット変換の場合 83522通りとなる。 ??? (7.6-7) ウェーブレットパケット解析(2次元)
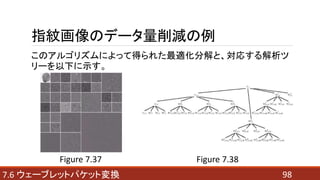
- 97. 977.6 ウェーブレットパケット変換 指紋画像のデータ量削減の例 具体的なアルゴリズムを以下に示す。 親 子 各リーフの情報量において、 1. 4つの子の和 < 親 ならば、分解に子を含める。 2. 4つの子の和 ≧ 親 ならば、親のみを残す。 これにより、不要な子孫を計算せずに済む。
- 98. 987.6 ウェーブレットパケット変換 指紋画像のデータ量削減の例 このアルゴリズムによって得られた最適化分解と、対応する解析ツ リーを以下に示す。 Figure 7.37 Figure 7.38
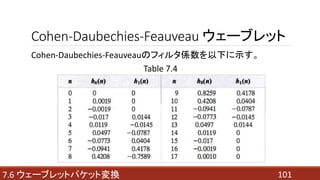
- 101. 1017.6 ウェーブレットパケット変換 Cohen-Daubechies-Feauveau ウェーブレット Cohen-Daubechies-Feauveauのフィルタ係数を以下に示す。 Table 7.4
- 102. 1027.6 ウェーブレットパケット変換 Cohen-Daubechies-Feauveau ウェーブレット Cohen-Daubechies-Feauveauの分解フィルタ係数および合成フィル タ係数を以下に示す。 Figure 7.39(a), (b) 分解フィルタ Figure 7.39(c), (d) 合成フィルタ
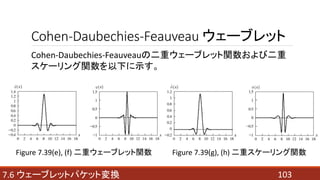
- 103. 1037.6 ウェーブレットパケット変換 Cohen-Daubechies-Feauveau ウェーブレット Cohen-Daubechies-Feauveauの二重ウェーブレット関数および二重 スケーリング関数を以下に示す。 Figure 7.39(e), (f) 二重ウェーブレット関数 Figure 7.39(g), (h) 二重スケーリング関数
- 104. 参考文献 ?Digital Image Processing: International Edition: Rafael C. Gonzalez, Richard E. Woods ?Wavelet Analysis for Image Processing: Tzu-Heng Henry Lee Graduate Institute of Communication Engineering, National Taiwan University, Taipei, Taiwan, ROC ?よくわかる信号処理 - フーリエ解析からウェーブレット変換まで: 和田成夫 ?フーリエ変換からウェーブレット変換へ やり直しのための通信数学: 三谷政昭 ?ウェーブレット変換の基礎と応用事例: 橘亮輔 ?画像処理のための複素数離散ウェーブレット変換の設計と応用に関する研究: 加藤毅 104