点群深層学習 Meta-study
23 likes10,801 views

cvpaper.challenge2019のMeta Study Groupでの発表スライド 点群深層学習についてのサーベイ ( /naoyachiba18/ss-120302579 )を経た上でのMeta Study













![Localisation Net: 幾何学変換を推定する
? 幾何学変換のパラメータθを出力
? あらゆるネットワーク構造を取りうる
(CNNでもMLPでも)
? ただし、パラメータθを得るために回帰出力層が必要
1. STN
[M. Jaderberg+, NIPS2015, arXiv:1506.02025, 2015-01-05] 担当: 戸田
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-22-320.jpg)
![1. STN
[M. Jaderberg+, NIPS2015, arXiv:1506.02025, 2015-01-05] 担当: 戸田
Grid Generator
? Transformer Netの出力θで座標系(Grid)を変換する
? 二次元アフィン変換であればθは6次元
Gridを変換
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-23-320.jpg)
![2. PointNet
[C. R. Qi+, CVPR2017, arXiv:1612.00593, 2016-12-02] 担当: 千葉
Symmetric Functionによって順不同な入力を扱う
? 三次元点群は順不同(irregular)なデータ形式
? 考えられるアプローチは3つ
? ソートする
? RNNの入力シーケンスとして扱う(全組み合わせで学習する)
? Symmetric Functionを使う → PointNetはこのアプローチ
? PointNetでは?? ? としてMax Poolingを用いる
点ごとに独立した変換
(Point-wise convolutionなど)
点の順序が影響しない関数
Max Poolingなど
Symmetric Function
(??の順序の影響を受けない)
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-24-320.jpg)
![2. PointNet
[C. R. Qi+, CVPR2017, arXiv:1612.00593, 2016-12-02] 担当: 千葉
ローカルな特徴はどうするか
→ グローバルな特徴と点ごとの特徴を結合して
最終的なポイントごとの特徴とする
T-net (STN) の導入
? 回転?並進の正規化するために入力点群を
T-Net (STN)で剛体変換
? 特徴量もFeature Alignment Networkで変換
? これもT-net (STN)
? 正規直交行列になるようロスを設計
(正規直交変換であれば情報を失わないため)
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-25-320.jpg)
![2. PointNet
[C. R. Qi+, CVPR2017, arXiv:1612.00593, 2016-12-02] 担当: 千葉
ネットワークの構造
T-Net = STN
Max Pooling
点ごとの特徴と
グローバルな特徴を結合
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-26-320.jpg)


![PIXOR(Vol.2収録予定)
[B. Yang+, CVPR2018, 2018-06-18] 担当: 千葉
LiDAR点群をBird’s Eye View (BEV)に変換して高速に
物体検出を行う手法 PIXORの提案
? ORiented 3D object detection from PIXel-wise neural
network predictions
? z方向(高さ)の情報は別のチャンネルとして2Dに変換
PIXORのワークフロー
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-30-320.jpg)
![25. Tangent Convolution
[M. Tatarchenko+, CVPR2018, arXiv:1807.02443, 2018-07-06] 担当: 千葉
Tangent Convolution
? 各点の接平面上で近傍点を畳み込む
? 処理の流れ
1. 一点半径内の点の分散共分散行列の
第3固有ベクトルで接平面法線の推定
2. 近傍の点を接平面上に投影
3. 接平面上の画像を補完
4. 畳み込み
三次元点の投影 Full Gaussian MixtureNearest Neighbor Top-3 Neighbors
Gaussian Mixture
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-31-320.jpg)
![25. Tangent Convolution
[M. Tatarchenko+, CVPR2018, arXiv:1807.02443, 2018-07-06] 担当: 千葉
Tangent Convolutionの効率的な計算
以下を事前計算
? 接平面上の各点??の入力点群での第??近傍点g?? ??
? 接平面上の各点??の第??近傍点に対する距離に応じた重み
??における出力特徴量
??の接平面上の点 畳み込みカーネル 入力点群中の??の
第??近傍点
→事前計算
g ?? の入力特徴量
カーネルに含まれる
第k近傍まで考える
第??近傍点に対する
距離に応じた重み
→事前計算
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-32-320.jpg)
![17. Pointwise CNN
[B.-S. Hua+, CVPR2018, arXiv:1712.05245, 2017-12-14] 担当: 千葉
点群上でのPointwise Convolutionを提案
? 点群の各点に適用する畳み込み演算
? 近傍点探索が一度で良いため計算が速い
? セグメンテーションとクラス分類ができた
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-33-320.jpg)
![17. Pointwise CNN
[B.-S. Hua+, CVPR2018, arXiv:1712.05245, 2017-12-14] 担当: 千葉
点数による正規化
カーネル内のボクセルごとに特徴量を点の数で正規化
してから畳み込み
第?層での
第??点の出力
カーネル内
ボクセルの
インデックス
カーネルでの
第??ボクセルの
重み 点????からみた
第??ボクセルの
点の集合
Ω?? ?? 内の各点 第?-1層での
第??点の出力
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-34-320.jpg)
![16. PointNet++
[C. R. Qi+, NIPS2017, arXiv:1706.02413, 2017-06-07] 担当: 千葉
PointNetを階層的に適用したネットワーク構造
? Sampling Layer: 重心位置を選択
? Grouping Layer: 近傍点群を抽出
? PointNet Layer: 局所特徴量を計算
? どうやって点群を分割するか
? 半径を変えつつ球で領域を切り出す
? Farthest Point Sampling (FPS)で点数が一定になるようサンプリング
? どうやって局所特徴を得るか
? 局所点群にPointNetを使う
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-35-320.jpg)
![16. PointNet++
[C. R. Qi+, NIPS2017, arXiv:1706.02413, 2017-06-07] 担当: 千葉
ネットワーク構造
? Sampling Layer: 重心位置を選択
? Grouping Layer: 近傍点群を抽出
? PointNet Layer: 局所特徴量を計算
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-36-320.jpg)
![21. Flex-convolution
[F. Groh+, ACCV2018, arXiv:1803.07289, 2018-03-20] 担当: 千葉
Flex-convolution
? 特徴
? 畳み込む点と畳み込まれる点の相対座標に応じて重みを付けて畳み込み
? このときの重みを,活性化関数を用いずに単にアフィン変換とする
? 処理の流れ
1. 畳み込む点周りで近傍点を選択
2. 相対位置をアフィン変換してカーネルの各要素に割り当てる
3. カーネルで畳み込み
二次元画像での畳み込み 三次元点群でのFlex-convolution
中心点との相対位置によって重みを変える
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-37-320.jpg)
![19. PointCNN
[Y. Li+, CVPR2018, arXiv:1801.07791, 2018-01-13] 担当: 千葉
X-Conv
? 点群から代表点群を選択,近傍の点の情報を畳み込み
集約していく
? クラス分類では代表点をランダムに選択
? セグメンテーションではFarthest Point Samplingを用いて
代表点を選択
二次元でのConvolution (+ Pooling) との比較
二次元画像でのCNNの例
X-Conv
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-38-320.jpg)
![20. DG-CNN
[Y. Wang+, arXiv:1801.07829, 2018-01-24] 担当: 千葉
グラフを各層の出力から逐次生成する
→ “Dynamic” Graph CNN
kNNで近傍点を結ぶ.このとき三次元空間だけではなく,
各層の出力特徴量空間での距離を使う
グラフ上での情報の集約方法: EdgeConv
1. エッジごとに特徴量を計算
? 本論文では
①中心ノードの特徴量と
②周辺ノードと中心ノードの差(局所特徴)
の二つを結合し,特徴量とした
2. ノードごとにエッジの特徴量を集約(Sum, Maxなど)
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-39-320.jpg)
![グラフ上での情報の集約方法: EdgeConv
1. エッジごとに特徴量を計算
2. ノードごとにエッジの特徴量を集約
2点の特徴量から,
それらを繋ぐエッジの
特徴量を計算
エッジの特徴量を集約
20. DG-CNN
[Y. Wang+, arXiv:1801.07829, 2018-01-24] 担当: 千葉
サーベイスライドより](https://image.slidesharecdn.com/pointclouddeeplearningmetastudy-190225042717/85/Meta-study-40-320.jpg)







点群深層学習 Meta-study
- 1. 点群深層学習 Meta-study 千葉 直也 東北大学大学院 情報科学研究科 橋本研究室 D1 1 http://xpaperchallenge.org/cv
- 2. 点群深層学習 2 ? 点群深層学習とは – (主に三次元の)点群を深層学習で扱う枠組み – その中でも ? 点群を直接入力/出力できる ? 直接ではないが,十分高解像度なまま三次元形状を 取り扱える ような手法が提案されつつある
- 3. 点群深層学習 3 ? 点群深層学習とは – (主に三次元の)点群を深層学習で扱う枠組み – その中でも ? 点群を直接入力/出力できる ? 直接ではないが,十分高解像度なまま三次元形状を 取り扱える ような手法が提案されつつある 今日の発表: 点群を直接入力する手法に関する紹介 元ネタのスライド: 千葉,戸田.叁次元点群を取り扱うニューラルネットワークのサーベイ /naoyachiba18/ss-120302579
- 4. 三次元点群の難しさ 4 ? 三次元点群を直接入力する難しさ 1. 順不同な入力 2. 2D画像のようには畳み込みができない 3. 剛体変換不変性が必要(タスクによる)
- 5. 三次元点群の難しさ 5 ? 三次元点群を直接入力する難しさ 1. 順不同な入力 2. 2D画像のようには畳み込みができない 3. 剛体変換不変性が必要(タスクによる)
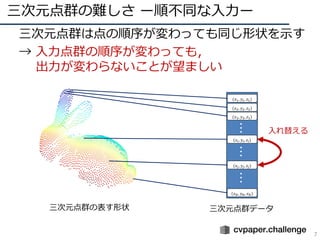
- 6. 三次元点群の難しさ ー順不同な入力ー 6 ? 三次元点群は点の順序が変わっても同じ形状を示す ? → 入力点群の順序が変わっても, 出力が変わらないことが望ましい 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ??????
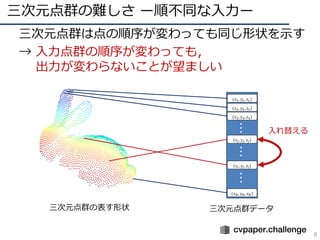
- 7. 三次元点群の難しさ ー順不同な入力ー 7 ? 三次元点群は点の順序が変わっても同じ形状を示す ? → 入力点群の順序が変わっても, 出力が変わらないことが望ましい 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? 入れ替える
- 8. 三次元点群の難しさ ー順不同な入力ー 8 ? 三次元点群は点の順序が変わっても同じ形状を示す ? → 入力点群の順序が変わっても, 出力が変わらないことが望ましい 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? 入れ替える
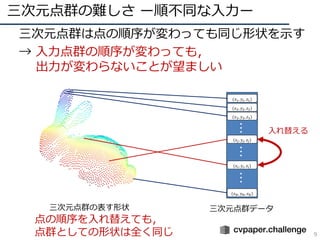
- 9. 三次元点群の難しさ ー順不同な入力ー 9 ? 三次元点群は点の順序が変わっても同じ形状を示す ? → 入力点群の順序が変わっても, 出力が変わらないことが望ましい 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? 入れ替える 点の順序を入れ替えても, 点群としての形状は全く同じ
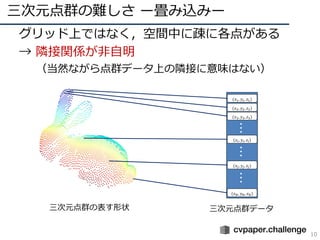
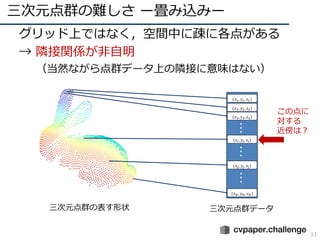
- 10. 三次元点群の難しさ ー畳み込みー 10 ? グリッド上ではなく,空間中に疎に各点がある ? → 隣接関係が非自明 (当然ながら点群データ上の隣接に意味はない) 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ??????
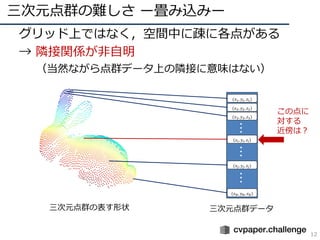
- 11. 三次元点群の難しさ ー畳み込みー 11 ? グリッド上ではなく,空間中に疎に各点がある ? → 隣接関係が非自明 (当然ながら点群データ上の隣接に意味はない) 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? この点に 対する 近傍は?
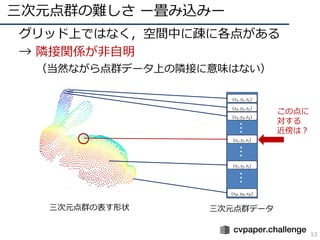
- 12. 三次元点群の難しさ ー畳み込みー 12 ? グリッド上ではなく,空間中に疎に各点がある ? → 隣接関係が非自明 (当然ながら点群データ上の隣接に意味はない) 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? この点に 対する 近傍は?
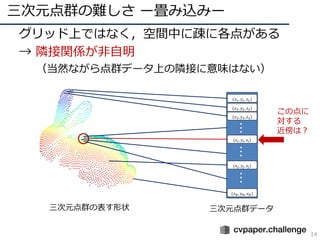
- 13. 三次元点群の難しさ ー畳み込みー 13 ? グリッド上ではなく,空間中に疎に各点がある ? → 隣接関係が非自明 (当然ながら点群データ上の隣接に意味はない) 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? この点に 対する 近傍は?
- 14. 三次元点群の難しさ ー畳み込みー 14 ? グリッド上ではなく,空間中に疎に各点がある ? → 隣接関係が非自明 (当然ながら点群データ上の隣接に意味はない) 三次元点群の表す形状 三次元点群データ (??1, ??1, ??1) (??2, ??2, ??2) (??3, ??3, ??3) (????, ????, ????) ??? (????, ????, ????) (????, ????, ????) ?????? この点に 対する 近傍は?
- 17. 三次元点群の難しさ ー剛体変換不変性ー 17 ? 剛体変換で変化する特性(相対姿勢など)と 変化しない特性(種類など)がある (基準) 種類: バニー (A) 種類: バニー 並進: あり 回転: なし (B) 種類: バニー 並進: あり 回転: あり (C) 種類: ブッダ 並進: あり 回転: あり
- 18. 三次元点群の難しさ ー剛体変換不変性ー 18 ? 剛体変換で変化する特性(相対姿勢など)と 変化しない特性(種類など)がある ? バニーをうまく回転させたらブッダになる,などはありえない (基準) 種類: バニー (A) 種類: バニー 並進: あり 回転: なし (B) 種類: バニー 並進: あり 回転: あり (C) 種類: ブッダ 並進: あり 回転: あり
- 19. 三次元点群の難しさ 19 ? 三次元点群を直接入力する難しさ 1. 順不同な入力 2. 2D画像のようには畳み込みができない 3. 剛体変換不変性が必要(タスクによる)
- 20. 三次元点群の難しさ 20 ? 三次元点群を直接入力する難しさ 1. 順不同な入力 → Symmetric Function (PointNetが利用) 2. 2D画像のようには畳み込みができない → PointNetが取り扱わなかったため, PointNet以降に様々な論文が発表されている 3. 剛体変換不変性が必要(タスクによる) → STN (PointNetが利用)
- 21. 論文の紹介 21 ? STN – Spatial Transformer Networks M. Jaderberg+ / NIPS2015 (arXiv:1506.02025) ? PointNet – PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation C. R. Qi+ / CVPR2017 (arXiv:1612.00593) スライドのフォーマットが サーベイスライドのままなのはお許し下さい..
- 22. Localisation Net: 幾何学変換を推定する ? 幾何学変換のパラメータθを出力 ? あらゆるネットワーク構造を取りうる (CNNでもMLPでも) ? ただし、パラメータθを得るために回帰出力層が必要 1. STN [M. Jaderberg+, NIPS2015, arXiv:1506.02025, 2015-01-05] 担当: 戸田 サーベイスライドより
- 23. 1. STN [M. Jaderberg+, NIPS2015, arXiv:1506.02025, 2015-01-05] 担当: 戸田 Grid Generator ? Transformer Netの出力θで座標系(Grid)を変換する ? 二次元アフィン変換であればθは6次元 Gridを変換 サーベイスライドより
- 24. 2. PointNet [C. R. Qi+, CVPR2017, arXiv:1612.00593, 2016-12-02] 担当: 千葉 Symmetric Functionによって順不同な入力を扱う ? 三次元点群は順不同(irregular)なデータ形式 ? 考えられるアプローチは3つ ? ソートする ? RNNの入力シーケンスとして扱う(全組み合わせで学習する) ? Symmetric Functionを使う → PointNetはこのアプローチ ? PointNetでは?? ? としてMax Poolingを用いる 点ごとに独立した変換 (Point-wise convolutionなど) 点の順序が影響しない関数 Max Poolingなど Symmetric Function (??の順序の影響を受けない) サーベイスライドより
- 25. 2. PointNet [C. R. Qi+, CVPR2017, arXiv:1612.00593, 2016-12-02] 担当: 千葉 ローカルな特徴はどうするか → グローバルな特徴と点ごとの特徴を結合して 最終的なポイントごとの特徴とする T-net (STN) の導入 ? 回転?並進の正規化するために入力点群を T-Net (STN)で剛体変換 ? 特徴量もFeature Alignment Networkで変換 ? これもT-net (STN) ? 正規直交行列になるようロスを設計 (正規直交変換であれば情報を失わないため) サーベイスライドより
- 26. 2. PointNet [C. R. Qi+, CVPR2017, arXiv:1612.00593, 2016-12-02] 担当: 千葉 ネットワークの構造 T-Net = STN Max Pooling 点ごとの特徴と グローバルな特徴を結合 サーベイスライドより
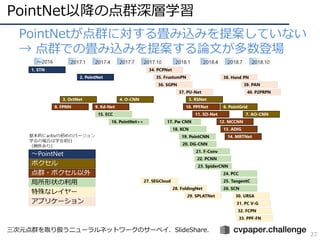
- 28. PointNet以降の点群深層学習 28 ? PointNetが点群に対する畳み込みを提案していない → 点群での畳み込みを提案する論文が多数登場 – 二次元の畳み込みに帰着 ? 地面方向(重力方向)は既知として2Dに変換 ? 接平面に投影 – 三次元座標を基準とした空間的畳み込み ? 世界座標系上のボクセルグリッド ? 点ごとのボクセルグリッド ? 点ごとの非ボクセルな固定形状のカーネル ? 点ごとにフレキシブルな形状のカーネル – 近傍点グラフを基準とした畳み込み ? 三次元空間での距離 ? 特徴空間での距離 – その他の表現を利用した近傍情報?局所形状の利用 Kd-Tree,自己組織化マップ,PPF,CRF,SDF,Octree,etc… 一部PointNet以前のものも ありますが???.
- 29. 論文の紹介 29 ? PIXOR – PIXOR: Real-Time 3D Object Detection From Point Clouds. B. Yang+ / CVPR2018 ? Tangent Convolutions – Tangent Convolutions for Dense Prediction in 3D. M. Tatarchenko+ / CVPR2018 (arXiv:1807.02443) ? Pointwise CNN – Pointwise Convolutional Neural Networks. B.-S. Hua+ / CVPR2018 (arXiv:1712.05245) ? PointNet++ – PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. C. R. Qi+ / NIPS2017 (arXiv:1706.02413) ? Flex-Convolution – Flex-Convolution (Million-Scale Point-Cloud Learning Beyond Grid-Worlds). F. Groh+ / ACCV2018 (arXiv:1803.07289) ? PointCNN – PointCNN. Y. Li+ / CVPR2018 (arXiv:1801.07791) ? DG-CNN – Dynamic Graph CNN for Learning on Point Clouds. Y. Wang+ / (arXiv:1801.07829) スライドのフォーマットが サーベイスライドのままなのはお許し下さい..
- 30. PIXOR(Vol.2収録予定) [B. Yang+, CVPR2018, 2018-06-18] 担当: 千葉 LiDAR点群をBird’s Eye View (BEV)に変換して高速に 物体検出を行う手法 PIXORの提案 ? ORiented 3D object detection from PIXel-wise neural network predictions ? z方向(高さ)の情報は別のチャンネルとして2Dに変換 PIXORのワークフロー サーベイスライドより
- 31. 25. Tangent Convolution [M. Tatarchenko+, CVPR2018, arXiv:1807.02443, 2018-07-06] 担当: 千葉 Tangent Convolution ? 各点の接平面上で近傍点を畳み込む ? 処理の流れ 1. 一点半径内の点の分散共分散行列の 第3固有ベクトルで接平面法線の推定 2. 近傍の点を接平面上に投影 3. 接平面上の画像を補完 4. 畳み込み 三次元点の投影 Full Gaussian MixtureNearest Neighbor Top-3 Neighbors Gaussian Mixture サーベイスライドより
- 32. 25. Tangent Convolution [M. Tatarchenko+, CVPR2018, arXiv:1807.02443, 2018-07-06] 担当: 千葉 Tangent Convolutionの効率的な計算 以下を事前計算 ? 接平面上の各点??の入力点群での第??近傍点g?? ?? ? 接平面上の各点??の第??近傍点に対する距離に応じた重み ??における出力特徴量 ??の接平面上の点 畳み込みカーネル 入力点群中の??の 第??近傍点 →事前計算 g ?? の入力特徴量 カーネルに含まれる 第k近傍まで考える 第??近傍点に対する 距離に応じた重み →事前計算 サーベイスライドより
- 33. 17. Pointwise CNN [B.-S. Hua+, CVPR2018, arXiv:1712.05245, 2017-12-14] 担当: 千葉 点群上でのPointwise Convolutionを提案 ? 点群の各点に適用する畳み込み演算 ? 近傍点探索が一度で良いため計算が速い ? セグメンテーションとクラス分類ができた サーベイスライドより
- 34. 17. Pointwise CNN [B.-S. Hua+, CVPR2018, arXiv:1712.05245, 2017-12-14] 担当: 千葉 点数による正規化 カーネル内のボクセルごとに特徴量を点の数で正規化 してから畳み込み 第?層での 第??点の出力 カーネル内 ボクセルの インデックス カーネルでの 第??ボクセルの 重み 点????からみた 第??ボクセルの 点の集合 Ω?? ?? 内の各点 第?-1層での 第??点の出力 サーベイスライドより
- 35. 16. PointNet++ [C. R. Qi+, NIPS2017, arXiv:1706.02413, 2017-06-07] 担当: 千葉 PointNetを階層的に適用したネットワーク構造 ? Sampling Layer: 重心位置を選択 ? Grouping Layer: 近傍点群を抽出 ? PointNet Layer: 局所特徴量を計算 ? どうやって点群を分割するか ? 半径を変えつつ球で領域を切り出す ? Farthest Point Sampling (FPS)で点数が一定になるようサンプリング ? どうやって局所特徴を得るか ? 局所点群にPointNetを使う サーベイスライドより
- 36. 16. PointNet++ [C. R. Qi+, NIPS2017, arXiv:1706.02413, 2017-06-07] 担当: 千葉 ネットワーク構造 ? Sampling Layer: 重心位置を選択 ? Grouping Layer: 近傍点群を抽出 ? PointNet Layer: 局所特徴量を計算 サーベイスライドより
- 37. 21. Flex-convolution [F. Groh+, ACCV2018, arXiv:1803.07289, 2018-03-20] 担当: 千葉 Flex-convolution ? 特徴 ? 畳み込む点と畳み込まれる点の相対座標に応じて重みを付けて畳み込み ? このときの重みを,活性化関数を用いずに単にアフィン変換とする ? 処理の流れ 1. 畳み込む点周りで近傍点を選択 2. 相対位置をアフィン変換してカーネルの各要素に割り当てる 3. カーネルで畳み込み 二次元画像での畳み込み 三次元点群でのFlex-convolution 中心点との相対位置によって重みを変える サーベイスライドより
- 38. 19. PointCNN [Y. Li+, CVPR2018, arXiv:1801.07791, 2018-01-13] 担当: 千葉 X-Conv ? 点群から代表点群を選択,近傍の点の情報を畳み込み 集約していく ? クラス分類では代表点をランダムに選択 ? セグメンテーションではFarthest Point Samplingを用いて 代表点を選択 二次元でのConvolution (+ Pooling) との比較 二次元画像でのCNNの例 X-Conv サーベイスライドより
- 39. 20. DG-CNN [Y. Wang+, arXiv:1801.07829, 2018-01-24] 担当: 千葉 グラフを各層の出力から逐次生成する → “Dynamic” Graph CNN kNNで近傍点を結ぶ.このとき三次元空間だけではなく, 各層の出力特徴量空間での距離を使う グラフ上での情報の集約方法: EdgeConv 1. エッジごとに特徴量を計算 ? 本論文では ①中心ノードの特徴量と ②周辺ノードと中心ノードの差(局所特徴) の二つを結合し,特徴量とした 2. ノードごとにエッジの特徴量を集約(Sum, Maxなど) サーベイスライドより
- 40. グラフ上での情報の集約方法: EdgeConv 1. エッジごとに特徴量を計算 2. ノードごとにエッジの特徴量を集約 2点の特徴量から, それらを繋ぐエッジの 特徴量を計算 エッジの特徴量を集約 20. DG-CNN [Y. Wang+, arXiv:1801.07829, 2018-01-24] 担当: 千葉 サーベイスライドより
- 41. PointNet以降の点群深層学習 41 ? PointNetが点群に対する畳み込みを提案していない → 点群での畳み込みを提案する論文が多数登場 – 二次元の畳み込みに帰着 ? 地面方向(重力方向)は既知として2Dに変換 ? 接平面に投影 – 三次元座標を基準とした空間的畳み込み ? 世界座標系上のボクセルグリッド ? 点ごとのボクセルグリッド ? 点ごとの非ボクセルな固定形状のカーネル ? 点ごとにフレキシブルな形状のカーネル – 近傍点グラフを基準とした畳み込み ? 三次元空間での距離 ? 特徴空間での距離 – その他の表現を利用した近傍情報?局所形状の利用 Kd-Tree,自己組織化マップ,PPF,CRF,SDF,Octree,etc… 一部PointNet以前のものも ありますが???. そろそろ落ち着いてきたような印象はある
- 42. メタな話 42 ? 反応のすばやさ ? 次に何を目指しているか ? 本当に点群深層学習は流行るか ? データセットは適切か ? グラフ系との関係 ? サンプリング方法について ? PointNetが本当のブレイクスルーだったのか ここからの話は話題提供としての側面が大きいので あまりまとまってはいません...
- 43. メタな話 43 ? 反応のすばやさ – PointNetが出てから関連研究を行って論文を 出すまで,どの研究グループも非常にはやい ? 次に何を目指しているか – 現状: ストレートに思いつきそうな畳み込みの アイデアがだいたい出尽くした → 2D?他分野でうまくいったアイデアを適用 AE,GAN,LSTM,RL,etc… → 構造の単純化?高速化 → アプリケーションに適用 ノイズ除去,手の認識,自動運転,産業用ロボット,etc…
- 44. 44 ? 本当に点群深層学習は流行るか – 正直微妙 ? 全周のデータがある場合にはMVCNNが強い ? 片面の観測であればRGB-Dとして2Dで扱えば良い ? メッシュも相当強い → 3D点群をそのまま扱えることの良さが 生きてくるタスク設定が必要 ? データセットは適切か – 現在の汎用的なデータセットが本当に使えるか, というと疑問が残る ? タスクに応じて作るべき? ? より大規模なデータセット? メタな話
- 45. メタな話 45 ? グラフ系との関係 – 近傍点をkNNで結べば(一応)グラフになる – 「グラフ上の信号」ではなく「グラフの構造」を 扱うネットワークであれば点群にも適用できる ? 適用例もある ? サンプリング方法について – 同じ点群を違う点群密度で扱いたいという設定 (プーリングなど)が多い – 一番よく使われているFPSは重い ? いくつか(サブ)サンプリング手法も提案されている ? グラフ関連での知見が生かせる,という話もある
- 46. 46 ? PointNetが本当にブレイクスルーだったのか PointNetのちょっと前にSymmetric Functionで 点群を扱う論文が出ている ? Deep Learning with Sets and Point Clouds – S. Ravanbakhsh, J. Schneider, B. Poczos. / ICLR2017-WS – 2016/11/14 (arxiv:1611.04500) ? PointNet – C. R. Qi, H. Su, K. Mo, L. J. Guibas. / CVPR2017 – 2016/12/02 (arxiv:1612.00593) ? Deep Sets – M. Zaheer, S. Kottur, S. Ravanbakhsh, B. Poczos, R. Salakhutdinov, A. Smola. / NIPS2017 – 2017/03/10 (arXiv:1703.06114) 有名になる要因はアイデアの新しさだけではない 考えられる他の要因例: 学会,完成度,評価,見せ方,タイトル,初期の被引用数??? メタな話
- 47. まとめ 47 ? 点群を直接入力として深層学習で扱うのは 難しかった – 順不同,畳み込み,剛体変換 ? PointNetの登場 – STN,Symmetric Function ? PointNetに続く研究事例 – 様々な畳み込み手法?局所形状の利用手法 ? メタな話 – サーベイを通して色々思うところからの話題提供