Swim_2013_02_19_jpn
Download as pptx, pdf1 like961 views

Paper introduction: "Linking and Building Ontologies of Linked Data" at SWIM seminar (2012/02/19).











![╠Į╦„ż╚ų”žūżĻŻ©1/3Ż®
? Restriction class ═¼╩┐ż╬ĮM║Žż╗żŪ╠Į╦„
[(pi1 = vij )(pk = vl2 )]
2
? ╔ŅżĄā׎╚╠Į╦„Ż¼╠Į╦„║“ča╩²: O(n2m2)
? n: īØŽ¾Ż▓źĮ®`ź╣żŪŻ¼źūźĒźčźŲźŻż¼ČÓżżĘĮż╬źūźĒźčźŲźŻūŅ┤¾╩²
? m: ╚╬ęŌż╬źūźĒźčźŲźŻż╬Ż¼ųžč}ż“│²żżż┐ūŅ┤¾źżź¾ź╣ź┐ź¾ź╣╩²
? ų”žūżĻŻ©╠Į╦„┐šķgż╬Ž„£pŻ®
? Ż▒Ż®ķōéÄżŪų”žūżĻ
? Ż▓Ż®├„żķż½ż╦░³║¼ķvéSż¼żóżļł÷║ŽżŽ╠Į╦„żĘż╩żż
? Ż│Ż®ųŲ╝sż“ŠÅżßżļųŲ╝sź»źķź╣ż╬ūĘ╝ėżŽąąż’ż╩żżŻ©╠Į╦„żĘż╩żżŻ®
? Ż┤Ż®Ż©Ż▓ź┌®`źĖßßżŪšh├„Ż®](https://image.slidesharecdn.com/swim20130219jpn-130221092003-phpapp02/85/Swim_2013_02_19_jpn-15-320.jpg)




![┐╝▓ņ
? ╠ß░Ė╩ųĘ©żŽ░Ą³aż╬ ?ķ]żĖż┐╩└Įń? ż“üóČ©ż╣żļ
? īgļHż╬ Linked Data ż¼ż╔ż”ż╩ż├żŲżżżļż╬ż½
? źżź¾ź╣ź┐ź¾ź╣ż¼ź¬ź¾ź╚źĒźĖż╚ż╔ż”īØÅĻżĘżŲżżżļż╬ż½Ż¼░č╬šżŪżŁż┐
? ?ķ]żĖż┐╩└Įń?Ż©źŪ®`ź┐ź╗ź├ź╚ż╬─┌é╚Ż®ż“└¹ė├ż╣żļż│ż╚żŪ╔Ž╩ųż»żżż├ż┐
? ?ķ_ż▒ż┐╩└Įń? żŪżõżĒż”ż╚żĘżŲżŌ
ŪĘōpżĘż┐źżź¾ź╣ź┐ź¾ź╣ż╬ź½źŲź┤źķźżź║żŽ└¦ļy
? Ż▒Ż®ż▐ż└╠Į╦„żŪżŁżŲżżż╩żżŻ¼
? Ż▓Ż®╠Į╦„żĄżņżŲżżżļż¼ęŌćĒżĄżņżŲźŪ®`ź┐ź╗ź├ź╚ż╦║¼ż▐żņżŲżżż╩żżŻ¼
? Ż│Ż®╠Į╦„żĄżņżŲżżżļż¼ź▀ź╣żŪźŪ®`ź┐ź╗ź├ź╚ż╦║¼ż▐żņżŲżżż╩żż
? ╩²ČÓż»ż╬▀Bą»Ż©Ą╚ü²Ż¼░³║¼Ż®ż“ęŖż─ż▒│÷ż╣ż│ż╚ż¼żŪżŁż┐
? īgźŪ®`ź┐ż“╗∙ż╦śŗ║BżĄżņżŲżżżļź¬ź¾ź╚źĒźĖż╬śŗ║BŻ¼Ė─╔Ųż╦žĢŽūż╣żļ](https://image.slidesharecdn.com/swim20130219jpn-130221092003-phpapp02/85/Swim_2013_02_19_jpn-25-320.jpg)
![ķv▀B蹊┐Ż©1/2Ż®
? Ontology Matching [12]
? terminologicalŻ©ągšZĄ─Ż®: linguistic and IR techniques [11]
? structuralŻ©śŗįņĄ─Ż®: graph matching [15]
? semanticŻ©ęŌ╬ČšōĄ─Ż®: model-based
? FCA-merge algorithm [18]
? Č■ż─ż╬ź¬ź¾ź╚źĒźĖż½żķźķźŲźŻź╣ż“ū„żĻŻ¼ź▐®`źĖ
? Ż©╠ß░Ė╩ųĘ©ż╚«Éż╩żĻŻ®ź▐®`źĖż╦żŽź©źŁź╣źč®`ź╚(źµ®`źČ)ż¼▒žę¬
? Duckham żķ [10]
? Ąž└Ē┐šķgź╔źßźżź¾ż╦īØż╣żļź¬ź¾ź╚źĒźĖż╬╚┌║Ž?▀Bą»╩ųĘ©
? Ż©╠ß░Ė╩ųĘ©ż╚«Éż╩żĻŻ®┤µį┌ż╣żļź»źķź╣żĘż½┐╝æ]żĘż╩żż
? ę╗ĘĮŻ¼ų°š▀żķżŽ ?type? ż╦Ž▐żķż╩żż](https://image.slidesharecdn.com/swim20130219jpn-130221092003-phpapp02/85/Swim_2013_02_19_jpn-26-320.jpg)
![ķv▀B蹊┐Ż©2/2Ż®
? GLUE system [9]
? instance-based similarity approach
? źżź¾ź╣ź┐ź¾ź╣ż¼│ųż─źķź┘źļ(źŲźŁź╣ź╚)ż“ź»źķź╣ĘųŅÉż╦ė├żżżļ
? ╦¹ż╬ź¬ź¾ź╚źĒźĖż╬Ė┼─Ņż╚▒╚▌^żĘżŲŻ¼╩¶ż╣żļż½┼ąČ©ż╣żļ
? Ż©╠ß░Ė╩ųĘ©żŪżŽŻ®Linked Data ż╬ Ī░┤ŪĘ╔▒¶:▓§▓╣│Š▒┤Ī▓§Ī▒ ż“└¹ė├ż╣żļ](https://image.slidesharecdn.com/swim20130219jpn-130221092003-phpapp02/85/Swim_2013_02_19_jpn-27-320.jpg)
![ķv▀B蹊┐Ż©Linked Dataķv▀BŻ®
? Brizerżķ [7]: źżź¾ź╣ź┐ź¾ź╣ź▐ź├ź┴ź¾ź░
? Raimondżķ [17]
? 궜SŻ©źó®`źŲźŻź╣ź╚Ż¼źņź│®`ź╔Ż¼ź╚źķź├ź»ż╩ż╔Ż®ż╦īØżĘżŲŻ¼
? ╬─ūų┴ąŻ¼ź░źķźšź▐ź├ź┴ź¾ź░ż“ė├żżżŲŻ¼Ż▓ż─ż╬DBķgż╬▀Bą»ż“╠Įż╣
? ż▐ż┐Ż¼Ż©╠ß░Ė╩ųĘ©ż╚«Éż╩żĻŻ®éĆ╚╦ż╬궜Sģ¦╝»Ūķł¾żŌ└¹ė├ż╣żļ
? Nikolovżķ [2]
? «Éż╩żļźĻźĮ®`ź╣ż“ ?owl:sameAs? ż╬═ŲęŲķ]░³żŪź»źķź╣ź┐ĘųĮŌ
? żóżļź»źķź╣ź┐─┌żŪżŽŻ¼╚½żŲż╬źżź¾ź╣ź┐ź¾ź╣ż¼Ą╚ü²ż╦ż╩żļżĶż”ż╦ż╣żļ
? żĮżņżŠżņż╬ź»źķź╣ź┐ż╬źżź¾ź╣ź┐ź¾ź╣ż“źĻźķź┘źļ
? ╣▓═©▓┐Ęų╝»║Žż╬źĄźżź║żŪĮ³╦ŲéÄż“ėŗ╦ѿʿŲŻ¼ź»źķź╣ż“Ą╚ü²ż╚ż╣żļ
? ź»źķź╣żžż╬į┘ĖŅĄ▒żŲź╣źŲź├źūż“└RżĻĘĄżĘŻ¼żĶżĻĄ╚ü²ż╩źĻź¾ź»ż“╔·│╔](https://image.slidesharecdn.com/swim20130219jpn-130221092003-phpapp02/85/Swim_2013_02_19_jpn-28-320.jpg)

Swim_2013_02_19_jpn
- 1. Linking and Building Ontologies on Linked Data Rahul Parundekar, Craig A. Knoblock, and Jose Luis Ambite. University of Southern California, Information Sciences Institute and Department of Computer Science. International Semantic Web Conference 2011 SWIM Seminar 2013/02/19. Hiroyuki Inoue.
- 3. ▒│Š░ ? Linked Data ż╬ Web ż╬│╔ķLż¼ų°żĘżż ? Ę∙Ä┌żżź╔źßźżź¾żŪ 316ā|ź╚źĻźūźļŻ©2011─Ļ9į┬Ż® ? š■Ė«Ż©42%Ż®Ż¼Ąž└ĒŻ©19.4%Ż®Ż¼╔·├³┐Ų覯©9.6%Ż®Ż¼ż╩ż╔ĪŁ ? Ī░┤ŪĘ╔▒¶:▓§▓╣│Š▒┤Ī▓§Ī▒ ? ═¼żĖęŌ╬Čż╬źĻźĮ®`ź╣═¼╩┐ż“ĮėŠAż╣żļźūźĒźčźŲźŻ ? ū┼īgż╦ēł╝ėżĘżŲżżżļŻ©LODź»źķź”ź╔ųąż╬10%Ż® ? żĘż½żĘź¬ź¾ź╚źĒźĖźņź┘źļżŪż╬ĮėŠAżŽżóż▐żĻēłż©żŲżżż╩żż ? 190źĮ®`ź╣ż╬ż”ż┴Ż¼15ż╬ż▀żŪ└¹ė├żĄżņżŲżżżļ
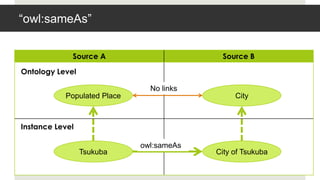
- 4. Ī░┤ŪĘ╔▒¶:▓§▓╣│Š▒┤Ī▓§Ī▒ Source A Source B Ontology Level No links Populated Place City Instance Level owl:sameAs Tsukuba City of Tsukuba
- 5. ─┐Ą─ż╚å¢Ņ} ?─┐Ą─: ź¬ź¾ź╚źĒźĖż╬▀Bą»ż“ęŖż─ż▒żļŻ¼ēłżõż╣ ? ▀Bą»: alignments ? ▀Bą»żŽŻ¼Semantic Web ż╦ż¬ż▒żļŽÓ╗ź▀\ė├ąįż╦ųžę¬ ? Ī░Semantic InteroperabilityĪ▒ ? ÖCąĄż¼═ŲšōŻ¼ų¬ūRż╬░kęŖŻ¼╦¹ż╬ÖCąĄż╚żõżĻ╚ĪżĻż╣żļż┐żßż╦▒žę¬ ?å¢Ņ}: ĮėŠAżĄżņżŲżżż╩żżź¬ź¾ź╚źĒźĖ ? 190ż╬źĮ®`ź╣ż╬ż”ż┴Ż¼15ż└ż▒ĮėŠAż¼żóżļ ? ╝╚┤µż╬ĮėŠAķvéSż¼░³└©Ą─ż╦£║ūŃżŪżŁżļżŌż╬żŪżŽż╩żżż└żĒż”
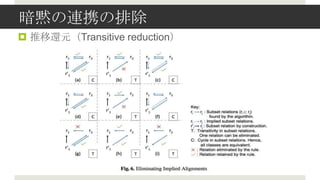
- 6. ų°š▀żķż╬źóźūźĒ®`ź┴ ?Linked Data ż½żķź¬ź¾ź╚źĒźĖż╬▀Bą»ż“ūįäė╔·│╔ ? LDż╦ż¬ż▒żļŻ¼źżź¾ź╣ź┐ź¾ź╣═¼╩┐ż╬Ą╚ü²ĮėŠA Ż©Ī▒owl:sameAsĪ▒Ż®ż“└¹ė├ ? ╝»║Žšōż“ė├żżżŲŻ¼Ė┼─Ņ═¼╩┐ż╬▀Bą»ż“ęŖż─ż▒żļ ?▀Bą»ż“ęŖż─ż▒│÷ż╣ż┐żßż╬ą┬żĘżżĖ┼─Ņż╬ī¦╚ļ ? ÆłÅłĖ┼─Ņż╬ī¦╚ļ ? Ī░rdf:typeĪ▒ ż└ż▒żŪĄ├żķżņżļź»źķź╣Ū°ĘųżŪżŽ▓─┴Žż¼ūŃżķż╩żż ? Restriction Classes
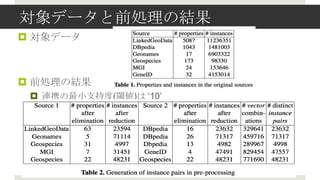
- 7. īØŽ¾ż╚ż╣żļźŪ®`ź┐źĮ®`ź╣Ż©1/2Ż® ? Linked Geo Data (http://linkedgeodata.org/) ? Open Street Map ż½żķ╔·│╔żĄżņż┐╝s20ā|ź╚źĻźūźļż╬Ąž└Ē┐šķgźŪ®`ź┐ ? ÖCąĄč¦┴Ģź┘®`ź╣ż╬źęźÕ®`źĻź╣źŲźŻź├ź»ż“ė├żżżŲŻ¼ą═Ūķł¾Ż¼ ┐šķgŠÓļxŻ¼Ąž├¹ż╩ż╔ż¼ DBpedia ż╦źĻź¾ź» ? GeoNamesŻ©http://geonames.org/Ż® ? ╝s800═“ż╬Ąž└ĒŪķł¾Ż«GeoNames Ontology ż╦żĶżļśŗįņ╗» ? Ī░FeatureĪ▒ź»źķź╣ż╬źżź¾ź╣ź┐ź¾ź╣żŪśŗ│╔żĄżņżļŻ¼żĮżņżŠżņ ? Ī░FeatureClassĪ▒Ż©ąąš■Ū°ė“Ż¼ėą├¹ż╩ł÷╦∙Ż¼ż╩ż╔Ż®ż╚Ż¼ ? Ī░FeatureCodeĪ▒Ż©FeatureClassż╬źĄźųź½źŲź┤źĻŻ®ż“│ųż─
- 8. īØŽ¾ż╚ż╣żļźŪ®`ź┐źĮ®`ź╣Ż©2/2Ż® ? DBpedia (http://dbpedia.org/) ? Wikipedia ż½żķśŗįņ╗»Ūķł¾ż“│ķ│÷żĘż┐┤ŪĢ°Ż¼150═“ź¬źųźĖź¦ź»ź╚ ? Linked Data ż╬ Web ż╬źŽźųż╚ż╩żļ ? Į±╗žżŽŻ¼Ī░rdf:typeĪ▒ ż╚ info-box ż╬Ūķł¾ż└ż▒└¹ė├ ? Linked Geo Data, GeoNames żŽ Ī░┤ŪĘ╔▒¶:▓§▓╣│Š▒┤Ī▓§Ī▒ żŪźĻź¾ź» ? GeospeciesŻ©http://lod.geospecies.org/Ż® ? ź»źķź╣ĘųŅÉż╬Ģß├┴żĄż“ĮŌøQż╣żļż┐żßż╬Ż¼╔·╬’覿╬ź┐źŁźĮź╬ź▀ ? DBpedia ż╚ Ī░skos:closeMatchĪ▒ żŪźĻź¾ź» ? MGIż╚GeneIDŻ©http://bio2rdf.blogspot.jp/) ? Mouse Genome Information ż╚▀zü╗ūėIDŻ©Gene IDŻ®DB ? MGI źżź¾ź╣ź┐ź¾ź╣ż½żķ GeneIDżž Ī░bio2RDF:xGeneIDĪ▒ żŪźĻź¾ź»
- 9. Ontology Alignment Using Linked Data
- 10. ╠ß░Ė╩ųĘ© ?Ė┼ę¬ ? źŪ®`ź┐Ęų╬÷ż╚ĮyėŗĄ─╩ųĘ©ż╬└¹ė├ ? Ī░Common Extension ComparisonĪ▒ źóźūźĒ®`ź┴ż╬ÆłÅł ? ╦Ųż┐ź»źķź╣ż╬źżź¾ź╣ź┐ź¾ź╣═¼╩┐żŪźżź¾ź┐®`ź╗ź»źĘźńź¾ż“źŲź╣ź╚ż╣żļ ? ź¬ź¾ź╚źĒźĖź▐ź├ź┴ź¾ź░ż╬ę╗╩ųĘ© ?╠žÅšŻ©Novel featuresŻ® ? Linked Data ż╬ Web ż╦ż¬ż▒żļĄ╚ü²ĮėŠAż“└¹ė├ż╣żļ ? ź»źķź╣Č©┴xż“ Ī░rdf:typeĪ▒ ż└ż▒żŪż╩ż»Ż¼╦¹ż╬Ūķł¾ż½żķżŌ╔·│╔ ? ╔·│╔żĘż┐ź»źķź╣ż╬╝»║Žż½żķŻ¼ź¬ź¾ź╚źĒźĖķgż╬▀Bą»ż“ęŖż─ż▒│÷ż╣
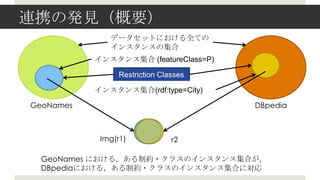
- 11. ┴¼ą»ż╬░k╝¹Ż©Ė┼꬯® źŪ®`ź┐ź╗ź├ź╚ż╦ż¬ż▒żļ╚½żŲż╬ źżź¾ź╣ź┐ź¾ź╣ż╬╝»║Ž źżź¾ź╣ź┐ź¾ź╣╝»║Ž (featureClass=P) źżź¾ź╣ź┐ź¾ź╣╝»║Ž(rdf:type=City) GeoNames DBpedia Img(r1) r2 GeoNames ż╦ż¬ż▒żļŻ¼żóżļųŲ╝s?ź»źķź╣ż╬źżź¾ź╣ź┐ź¾ź╣╝»║Žż¼Ż¼ DBpediaż╦ż¬ż▒żļŻ¼żóżļųŲ╝s?ź»źķź╣ż╬źżź¾ź╣ź┐ź¾ź╣╝»║Žż╦īØÅĻ
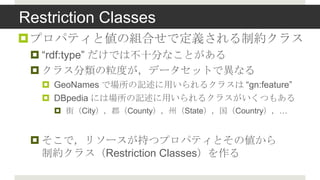
- 12. Restriction Classes ?źūźĒźčźŲźŻż╚éÄż╬ĮM║Žż╗żŪČ©┴xżĄżņżļųŲ╝sź»źķź╣ ? Ī░rdf:typeĪ▒ ż└ż▒żŪżŽ▓╗╩«Ęųż╩ż│ż╚ż¼żóżļ ? ź»źķź╣ĘųŅÉż╬┴ŻČ╚ż¼Ż¼źŪ®`ź┐ź╗ź├ź╚żŪ«Éż╩żļ ? GeoNames żŪł÷╦∙ż╬ėø╩÷ż╦ė├żżżķżņżļź»źķź╣żŽ Ī░gn:featureĪ▒ ? DBpedia ż╦żŽł÷╦∙ż╬ėø╩÷ż╦ė├żżżķżņżļź»źķź╣ż¼żżż»ż─żŌżóżļ ? ĮųŻ©CityŻ®Ż¼┐żŻ©CountyŻ®Ż¼ų▌Ż©StateŻ®Ż¼╣·Ż©CountryŻ®Ż¼ĪŁ ? żĮż│żŪŻ¼źĻźĮ®`ź╣ż¼│ųż─źūźĒźčźŲźŻż╚żĮż╬éÄż½żķ ųŲ╝sź»źķź╣Ż©Restriction ClassesŻ®ż“ū„żļ
- 13. Restriction Classes ż╬śŗ║B ?źūźĒźčźŲźŻż╚éÄż╬āń╝»║Žż½żķśŗ║BżĄżņżļ ? └²Ż®GeoNames ż╦ż¬ż▒żļ1źĻźĮ®`ź╣Ż©Saudi ArabiaŻ® ? rdf:type = geonames:FeatureŻ©ł÷╦∙ź»źķź╣Ż® independent political ? featureCode = geonames:A.PCLI Ż©Č└┴ó╣·╝꯮ entity ? featureClass = geonames:A Ż©╣·Ż¼ų▌Ż¼ŅIė“Ż® ĮM║Žż╗ż¼ųĖ╩²ķv╩²Ą─ż╦ēłż©żļż╬żŪŻ¼ ź¬ź¾ź╚źĒźĖķgż╬▀Bą»ż“╠Įż╣Ū░ż╦Ż¼ źŪ®`ź┐ż╦īØżĘżŲŪ░äI└ĒŻ¼╠Į╦„┐šķgż╬Ž„£pż“ąąż”
- 14. źŪ®`ź┐żžż╬Ū░äI└Ē ? Ż▒Ż®¼Fį┌īØŽ¾ż╚żĘżŲżżżļź»źķź╣ż╚ķvéSż╩żżżŌż╬ż“Ž„│² ? Ż▓Ż®▀Bą»ż╬╔·│╔ż╦ķvéS¤ożĄżĮż”ż╩źūźĒźčźŲźŻż“Ž„│² ? Ż│Ż®źżź¾ź╣ź┐ź¾ź╣źŪ®`ź┐żŽRDBż╦Ė±╝{ż╣żļ ? URIż“ų„źŁ®`ż╚żĘżŲŻ¼1źżź¾ź╣ź┐ź¾ź╣ż“ę╗ąążŪĖ±╝{ż╣żļŻ©?vector?Ż® ? ČÓéÄż╬źūźĒźčźŲźŻż╦ż─żżżŲżŽč}╩²ąąż╦Ęųż▒żŲĖ±╝{ż╣żļ ? DISTINCT żŪźūźĒźčźŲźŻéÄż“╚Īżļż╬żŪŻ¼č}╩²ąąż╦ĘųĖŅżĄżņżŲżŌå¢Ņ}ż╩żż ? Ą╚ü²źūźĒźčźŲźŻ(?owl:sameAs?)żŪJoinż╣żļż│ż╚żŪŻ¼ 2ż─ż╬ź¬ź¾ź╚źĒźĖż½żķ ?vector? ż╬ĮM║Žż╗ż“╚ĪĄ├ż╣żļż│ż╚ż¼żŪżŁ żļŻ©?instance pair?Ż®
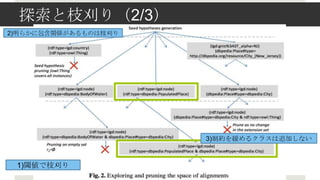
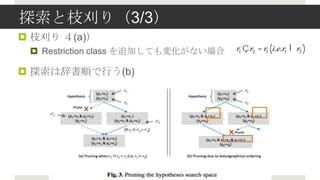
- 15. ╠Į╦„ż╚ų”žūżĻŻ©1/3Ż® ? Restriction class ═¼╩┐ż╬ĮM║Žż╗żŪ╠Į╦„ [(pi1 = vij )(pk = vl2 )] 2 ? ╔ŅżĄā׎╚╠Į╦„Ż¼╠Į╦„║“ča╩²: O(n2m2) ? n: īØŽ¾Ż▓źĮ®`ź╣żŪŻ¼źūźĒźčźŲźŻż¼ČÓżżĘĮż╬źūźĒźčźŲźŻūŅ┤¾╩² ? m: ╚╬ęŌż╬źūźĒźčźŲźŻż╬Ż¼ųžč}ż“│²żżż┐ūŅ┤¾źżź¾ź╣ź┐ź¾ź╣╩² ? ų”žūżĻŻ©╠Į╦„┐šķgż╬Ž„£pŻ® ? Ż▒Ż®ķōéÄżŪų”žūżĻ ? Ż▓Ż®├„żķż½ż╦░³║¼ķvéSż¼żóżļł÷║ŽżŽ╠Į╦„żĘż╩żż ? Ż│Ż®ųŲ╝sż“ŠÅżßżļųŲ╝sź»źķź╣ż╬ūĘ╝ėżŽąąż’ż╩żżŻ©╠Į╦„żĘż╩żżŻ® ? Ż┤Ż®Ż©Ż▓ź┌®`źĖßßżŪšh├„Ż®
- 16. ╠Į╦„ż╚ų”žūżĻŻ©2/3Ż® 2)├„żķż½ż╦░³║¼ķvéSż¼żóżļżŌż╬żŽų”žūżĻ 3)ųŲ╝sż“ŠÅżßżļź»źķź╣żŽūĘ╝ėżĘż╩żż 1)ķōéÄżŪų”žūżĻ
- 17. ╠Į╦„ż╚ų”žūżĻŻ©3/3Ż® ? ų”žūżĻ Ż┤(a)Ż® ? Restriction class ż“ūĘ╝ėżĘżŲżŌēõ╗»ż¼ż╩żżł÷║Ž r1 ?r2 = r1 (i.e.r1 ? r2 ) ? ╠Į╦„żŽ┤ŪĢ°ĒśżŪąąż”(b)
- 18. üóšhż╬įuü²Ż©ź╣ź│źóźĻź¾ź░Ż®Ż©1/2Ż® ? ┤_ą┼Č╚ż“ėŗ╦ѿʿŲŻ¼Ą├żķżņż┐üóšhż“įuü²ż╣żļ ? Ž± r1 ż“ėŗ╦ŃŻ©I(r1)Ż® ? źĮ®`ź╣Ż▓ż╦ż¬żżżŲŻ¼źĮ®`ź╣Ż▒ż╚ Ī░┤ŪĘ╔▒¶:▓§▓╣│Š▒┤Ī▓§Ī▒ źĻź¾ź»żŪ Ī░instance pairĪ▒ ż“śŗ│╔ż╣żļźżź¾ź╣ź┐ź¾ź╣╝»║Ž ? I(r1) ż¬żĶżė r2 ż“ė├żżżŲ P(recision), R(ecall) ż“ėŗ╦Ń ? š`▓Ņż“įS╚▌ż╣żļŻ¼ŠÅżßż╬Č©┴xż╚żĘżŲ R?,P? ż“ė├ęŌ I(r1 )? r2 I(r1 )? r2 P= R= r2 r1
- 19. üóšhż╬įuü²Ż©ź╣ź│źóźĻź¾ź░Ż®Ż©2/2Ż® ? ėŗ╦Ń└² ? Restriction class A(r1): Ī░lgd:gnis%3AST_alpha=NJĪ▒ ? Restriction class B(r2): ? Ī░dbpedia:Place#type=http://dbpedia.org/resource/City_(New_Jersey)Ī▒ ? I(r ) = 39, r2 = 40, 1 I(r1 )? r2 = 39, 39 39 P' = = 0.97 ? 0.90, R' = = 1.0 ? 0.90 40 39 żĶż├żŲŻ¼Aż╚Bż╬Restriction classżŽ equivalent ż╚čįż©żļ
- 22. īØŽ¾źŪ®`ź┐ż╚Ū░äI└Ēż╬ĮY╣¹ ? īØŽ¾źŪ®`ź┐ ? Ū░äI└Ēż╬ĮY╣¹ ? ▀Bą»ż╬ūŅąĪų¦│ųČ╚(ķōéÄ)żŽ ?10?
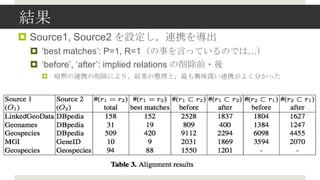
- 23. ĮY╣¹ ? Source1, Source2 ż“įOČ©żĘŻ¼▀Bą»ż“ī¦│÷ ? ?best matches?: P=1, R=1Ż©ż╬╩┬ż“čįż├żŲżżżļż╬żŪżŽĪŁŻ® ? ?before?, ?after?: implied relations ż╬Ž„│²Ū░?ßß ? ░Ą³aż╬▀Bą»ż╬Ž„│²ż╦żĶżĻŻ¼ĮY╣¹ż╬š¹└Ēż╚Ż¼ūŅżŌ┼d╬Č╔Ņżż▀Bą»ż¼żĶż»Ęųż½ż├ż┐
- 25. ┐╝▓ņ ? ╠ß░Ė╩ųĘ©żŽ░Ą³aż╬ ?ķ]żĖż┐╩└Įń? ż“üóČ©ż╣żļ ? īgļHż╬ Linked Data ż¼ż╔ż”ż╩ż├żŲżżżļż╬ż½ ? źżź¾ź╣ź┐ź¾ź╣ż¼ź¬ź¾ź╚źĒźĖż╚ż╔ż”īØÅĻżĘżŲżżżļż╬ż½Ż¼░č╬šżŪżŁż┐ ? ?ķ]żĖż┐╩└Įń?Ż©źŪ®`ź┐ź╗ź├ź╚ż╬─┌é╚Ż®ż“└¹ė├ż╣żļż│ż╚żŪ╔Ž╩ųż»żżż├ż┐ ? ?ķ_ż▒ż┐╩└Įń? żŪżõżĒż”ż╚żĘżŲżŌ ŪĘōpżĘż┐źżź¾ź╣ź┐ź¾ź╣ż╬ź½źŲź┤źķźżź║żŽ└¦ļy ? Ż▒Ż®ż▐ż└╠Į╦„żŪżŁżŲżżż╩żżŻ¼ ? Ż▓Ż®╠Į╦„żĄżņżŲżżżļż¼ęŌćĒżĄżņżŲźŪ®`ź┐ź╗ź├ź╚ż╦║¼ż▐żņżŲżżż╩żżŻ¼ ? Ż│Ż®╠Į╦„żĄżņżŲżżżļż¼ź▀ź╣żŪźŪ®`ź┐ź╗ź├ź╚ż╦║¼ż▐żņżŲżżż╩żż ? ╩²ČÓż»ż╬▀Bą»Ż©Ą╚ü²Ż¼░³║¼Ż®ż“ęŖż─ż▒│÷ż╣ż│ż╚ż¼żŪżŁż┐ ? īgźŪ®`ź┐ż“╗∙ż╦śŗ║BżĄżņżŲżżżļź¬ź¾ź╚źĒźĖż╬śŗ║BŻ¼Ė─╔Ųż╦žĢŽūż╣żļ
- 26. ķv▀B蹊┐Ż©1/2Ż® ? Ontology Matching [12] ? terminologicalŻ©ągšZĄ─Ż®: linguistic and IR techniques [11] ? structuralŻ©śŗįņĄ─Ż®: graph matching [15] ? semanticŻ©ęŌ╬ČšōĄ─Ż®: model-based ? FCA-merge algorithm [18] ? Č■ż─ż╬ź¬ź¾ź╚źĒźĖż½żķźķźŲźŻź╣ż“ū„żĻŻ¼ź▐®`źĖ ? Ż©╠ß░Ė╩ųĘ©ż╚«Éż╩żĻŻ®ź▐®`źĖż╦żŽź©źŁź╣źč®`ź╚(źµ®`źČ)ż¼▒žę¬ ? Duckham żķ [10] ? Ąž└Ē┐šķgź╔źßźżź¾ż╦īØż╣żļź¬ź¾ź╚źĒźĖż╬╚┌║Ž?▀Bą»╩ųĘ© ? Ż©╠ß░Ė╩ųĘ©ż╚«Éż╩żĻŻ®┤µį┌ż╣żļź»źķź╣żĘż½┐╝æ]żĘż╩żż ? ę╗ĘĮŻ¼ų°š▀żķżŽ ?type? ż╦Ž▐żķż╩żż
- 27. ķv▀B蹊┐Ż©2/2Ż® ? GLUE system [9] ? instance-based similarity approach ? źżź¾ź╣ź┐ź¾ź╣ż¼│ųż─źķź┘źļ(źŲźŁź╣ź╚)ż“ź»źķź╣ĘųŅÉż╦ė├żżżļ ? ╦¹ż╬ź¬ź¾ź╚źĒźĖż╬Ė┼─Ņż╚▒╚▌^żĘżŲŻ¼╩¶ż╣żļż½┼ąČ©ż╣żļ ? Ż©╠ß░Ė╩ųĘ©żŪżŽŻ®Linked Data ż╬ Ī░┤ŪĘ╔▒¶:▓§▓╣│Š▒┤Ī▓§Ī▒ ż“└¹ė├ż╣żļ
- 28. ķv▀B蹊┐Ż©Linked Dataķv▀BŻ® ? Brizerżķ [7]: źżź¾ź╣ź┐ź¾ź╣ź▐ź├ź┴ź¾ź░ ? Raimondżķ [17] ? 궜SŻ©źó®`źŲźŻź╣ź╚Ż¼źņź│®`ź╔Ż¼ź╚źķź├ź»ż╩ż╔Ż®ż╦īØżĘżŲŻ¼ ? ╬─ūų┴ąŻ¼ź░źķźšź▐ź├ź┴ź¾ź░ż“ė├żżżŲŻ¼Ż▓ż─ż╬DBķgż╬▀Bą»ż“╠Įż╣ ? ż▐ż┐Ż¼Ż©╠ß░Ė╩ųĘ©ż╚«Éż╩żĻŻ®éĆ╚╦ż╬궜Sģ¦╝»Ūķł¾żŌ└¹ė├ż╣żļ ? Nikolovżķ [2] ? «Éż╩żļźĻźĮ®`ź╣ż“ ?owl:sameAs? ż╬═ŲęŲķ]░³żŪź»źķź╣ź┐ĘųĮŌ ? żóżļź»źķź╣ź┐─┌żŪżŽŻ¼╚½żŲż╬źżź¾ź╣ź┐ź¾ź╣ż¼Ą╚ü²ż╦ż╩żļżĶż”ż╦ż╣żļ ? żĮżņżŠżņż╬ź»źķź╣ź┐ż╬źżź¾ź╣ź┐ź¾ź╣ż“źĻźķź┘źļ ? ╣▓═©▓┐Ęų╝»║Žż╬źĄźżź║żŪĮ³╦ŲéÄż“ėŗ╦ѿʿŲŻ¼ź»źķź╣ż“Ą╚ü²ż╚ż╣żļ ? ź»źķź╣żžż╬į┘ĖŅĄ▒żŲź╣źŲź├źūż“└RżĻĘĄżĘŻ¼żĶżĻĄ╚ü²ż╩źĻź¾ź»ż“╔·│╔
- 29. ż▐ż╚żßŻ¼Į±ßßż╬šnŅ} ? ź¬ź¾ź╚źĒźĖķgż╬░³║¼?Ą╚ü²▀Bą»ż“ęŖż─ż▒żļźóźļź┤źĻź║źÓż“╠ß░Ė ? ųŲ╝sź»źķź╣ż╬ī¦╚ļż╚Ż¼żĮżņżķż“ĮMż▀║Žż’ż╗żļ ? ▒ŠĖÕżŪżŽĄž└Ē┐šķgŻ¼äė╬’ż╬źŪ®`ź┐ż╦īØżĘżŲūįäėżŪ▀Bą»ż“░kęŖ ? żĘż½żĘŻ¼╦¹ż╬ę╗░ŃĄ─ż╩ Linked Data ż╦▀mė├┐╔─▄żŪżóżļ ? Į±ßßż╬šnŅ} ? ź╣ź▒®`źķźėźĻźŲźŻż╬Ė─╔Ų ? üóšhż╬▀Bą»ż“╠Į╦„ż╣żļźčźšź®®`ź▐ź¾ź╣ż“Ž“╔ŽżĄż╗ż┐żż ? Ū░ż╬蹊┐Ż©źĮ®`ź╣ż½żķż╬źŌźŪźļśŗ║BŻ®ż╚▀Bą»żĄż╗ż┐żż ? ź»źĒź╣ź╔źßźżź¾ż╩źŪ®`ź┐ź╗ź├ź╚ż╦īØżĘżŲ▀mė├żĘż┐żż ? ╠žż╦Ż¼╔·╬’ęĮ覿╩Linked Dataż╦īØżĘżŲ