The Web Conference 2019 参加報告会資料
Download as pptx, pdf2 likes220 views

The Web Conference 2019のフィードバック会の資料です。




![? BIG
?検索ランキング
“Machine Learning-Powered Search Ranking of Airbnb Experiences.”
? [Personalization] In ResearchTrack
?ユーザ側?アイテム側両方の情報を使った推薦
“Dual Neural Personalized Ranking”
?環境の変化に対応したバンディット
“Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests”
? W4A
?旅行先の推薦
“Location Embeddings for Next Trip Recommendation.”
?Webページの画像の代替テキストの評価
“Combining Semantic Tools for Automatic Evaluation of Alternative Texts”
紹介する研究](https://image.slidesharecdn.com/cs7kkiyxtlqyfwhql6vx-signature-dab55cf7f512baf0bc0f199491cf2d7e701d9bab04a1cc10db1ac0208468fa9e-poli-190628065430/85/The-Web-Conference-2019-8-320.jpg)
![? BIG
?検索ランキング
“Machine Learning-Powered Search Ranking of Airbnb Experiences.”
? [Personalization] In ResearchTrack
?ユーザ側?アイテム側両方の情報を使った推薦
“Dual Neural Personalized Ranking”
?環境の変化に対応したバンディット
“Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests”
? W4A
?旅行先の推薦
“Location Embeddings for Next Trip Recommendation.”
?Webページの画像の代替テキストの評価
“Combining Semantic Tools for Automatic Evaluation of Alternative Texts”
紹介する研究](https://image.slidesharecdn.com/cs7kkiyxtlqyfwhql6vx-signature-dab55cf7f512baf0bc0f199491cf2d7e701d9bab04a1cc10db1ac0208468fa9e-poli-190628065430/85/The-Web-Conference-2019-9-320.jpg)

























![? BIG
?検索ランキング
“Machine Learning-Powered Search Ranking of Airbnb Experiences.”
? [Personalization] In ResearchTrack
?ユーザ側?アイテム側両方の情報を使った推薦
“Dual Neural Personalized Ranking”
?環境の変化に対応したバンディット
“Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests”
? W4A
?旅行先の推薦
“Location Embeddings for Next Trip Recommendation.”
?Webページの画像の代替テキストの評価
“Combining Semantic Tools for Automatic Evaluation of Alternative Texts”
紹介する研究](https://image.slidesharecdn.com/cs7kkiyxtlqyfwhql6vx-signature-dab55cf7f512baf0bc0f199491cf2d7e701d9bab04a1cc10db1ac0208468fa9e-poli-190628065430/85/The-Web-Conference-2019-37-320.jpg)




![? BIG
?検索ランキング
“Machine Learning-Powered Search Ranking of Airbnb Experiences.”
? [Personalization] In ResearchTrack
?ユーザ側?アイテム側両方の情報を使った推薦
“Dual Neural Personalized Ranking”
?環境の変化に対応したバンディット
“Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests”
? W4A
?旅行先の推薦
“Location Embeddings for Next Trip Recommendation.”
?Webページの画像の代替テキストの評価
“Combining Semantic Tools for Automatic Evaluation of Alternative Texts”
紹介する研究](https://image.slidesharecdn.com/cs7kkiyxtlqyfwhql6vx-signature-dab55cf7f512baf0bc0f199491cf2d7e701d9bab04a1cc10db1ac0208468fa9e-poli-190628065430/85/The-Web-Conference-2019-52-320.jpg)









![? BIG
?検索ランキング
“Machine Learning-Powered Search Ranking of Airbnb Experiences.”
? [Personalization] In ResearchTrack
?ユーザ側?アイテム側両方の情報を使った推薦
“Dual Neural Personalized Ranking”
?環境の変化に対応したバンディット
“Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests”
? W4A
?旅行先の推薦
“Location Embeddings for Next Trip Recommendation.”
?Webページの画像の代替テキストの評価
“Combining Semantic Tools for Automatic Evaluation of Alternative Texts”
紹介する研究](https://image.slidesharecdn.com/cs7kkiyxtlqyfwhql6vx-signature-dab55cf7f512baf0bc0f199491cf2d7e701d9bab04a1cc10db1ac0208468fa9e-poli-190628065430/85/The-Web-Conference-2019-65-320.jpg)






![? BIG
?検索ランキング
“Machine Learning-Powered Search Ranking of Airbnb Experiences.”
? [Personalization] In ResearchTrack
?ユーザ側?アイテム側両方の情報を使った推薦
“Dual Neural Personalized Ranking”
?環境の変化に対応したバンディット
“Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests”
? W4A
?旅行先の推薦
“Location Embeddings for Next Trip Recommendation.”
?Webページの画像の代替テキストの評価
“Combining Semantic Tools for Automatic Evaluation of Alternative Texts”
紹介する研究](https://image.slidesharecdn.com/cs7kkiyxtlqyfwhql6vx-signature-dab55cf7f512baf0bc0f199491cf2d7e701d9bab04a1cc10db1ac0208468fa9e-poli-190628065430/85/The-Web-Conference-2019-75-320.jpg)














The Web Conference 2019 参加報告会資料
- 1. The Web Conference 2019 参加報告会 サイバーエージェント アドテクスタジオ 宮西 一徳
- 2. スケジュール 5/13, 14 Workshop → 9個くらい並列 W4A(Web for All) (テーマはPersonalisation(Security, Accessibility)) BIG ビッグデータ系の招待講演 5/15?17 Keynote ResearchTrack → 5個くらい並列 W3C Web of Health 健康?医療分野の発表 The Future of the Open Web Poster & Demo The Web Conference(旧WWW) 2019: 5/13?17
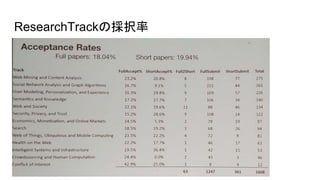
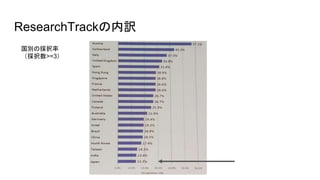
- 3. ResearchTrack ● Crowdsourcing and Human Computation ● Economics, Monetization, and Online Markets ● Health on the Web ● Intelligent Systems and Infrastructure ● Search ● Security, Privacy, and Trust ● Semantics and Knowledge ● Social Network Analysis and Graph Algorithms ● User Modeling, Personalization, and Experience ● Web and Society ● Web Mining and Content Analysis ● Web of Things, Ubiquitous, and Mobile Computing
- 7. 紹介する研究 5/13, 14 Workshop W4A(Web for All) BIG ビッグデータ系 5/15?17 Keynote ResearchTrack W3C Web of Health 健康?医療分野 The Future of the Open Web Poster & Demo ここから 5つの研究を紹介
- 8. ? BIG ?検索ランキング “Machine Learning-Powered Search Ranking of Airbnb Experiences.” ? [Personalization] In ResearchTrack ?ユーザ側?アイテム側両方の情報を使った推薦 “Dual Neural Personalized Ranking” ?環境の変化に対応したバンディット “Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests” ? W4A ?旅行先の推薦 “Location Embeddings for Next Trip Recommendation.” ?Webページの画像の代替テキストの評価 “Combining Semantic Tools for Automatic Evaluation of Alternative Texts” 紹介する研究
- 9. ? BIG ?検索ランキング “Machine Learning-Powered Search Ranking of Airbnb Experiences.” ? [Personalization] In ResearchTrack ?ユーザ側?アイテム側両方の情報を使った推薦 “Dual Neural Personalized Ranking” ?環境の変化に対応したバンディット “Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests” ? W4A ?旅行先の推薦 “Location Embeddings for Next Trip Recommendation.” ?Webページの画像の代替テキストの評価 “Combining Semantic Tools for Automatic Evaluation of Alternative Texts” 紹介する研究
- 10. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Airbnbの検索ランキングのアルゴリズムについての話 データが少ない段階からどう改善していくか? ?モデルの作り方 ?評価の仕方
- 11. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) ■ Airbnb Homes 民泊 → ホストはスペースを貸したい。ゲストは泊まる場所を見つけたい。 191カ国に600万件。毎晩200万人以上のゲストが利用。 ■ Airbnb Experiences アクティビティ → ホストは趣味?スキル?専門知識を共有したい。ゲストは旅行先でや ることを探したい。 1000都市で35000件。 アクティビティの種類はエディターが厳選したもので、90%以上が星5つ。 (コンサート、サーフィン、料理教室 などなど) Experiencesの検索ランキングについての発表 → ユーザごとにベストなランキングを作りたい 背景とゴール
- 12. 1. 予約したユーザについて検索履歴(クリック)を収集 2. 検索結果のアクティビティについて、離脱?予約でラベル付け 3. アクティビティ?ユーザ?検索クエリについて属性を作る ?値段、レビュー数、レーティング ?宿泊先の場所、旅行の日数、興味のあるジャンル?時間帯 ?検索した場所、ゲストの数、日数 Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) 学習に使うデータの作り方
- 13. Airbnb Engineering & Data Science より データが貯まるにつれて、ユーザやクエリの履歴情報が使えるようになってくる Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) アルゴリズムの開発ステップ
- 14. データ数少ない(アクティビティ: 500個、検索履歴: 5万) Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage1 (Offline ML Model) アクティビティの属性のみでGBDT学習 (予約するかしないかを予測するモデル) ユーザ属性、クエリ属性もまだ使えないので、 すべてのユーザに同じランキングを表示する。 日次でモデル更新するので、毎日ランキングは変わる A/Bテストで評価 (ルールベースのランダムランキングアルゴリズムと比較) 予約数で13%増
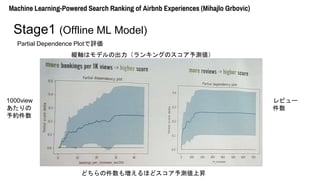
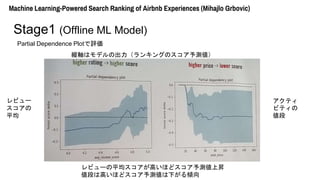
- 15. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage1 (Offline ML Model) Partial Dependence Plotで評価 → 特定の属性が予測にどう影響しているかを見る方法 評価対象とする属性以外のすべての属性を固定して、 対象属性の値を変化させて予測結果を見る
- 16. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage1 (Offline ML Model) Partial Dependence Plotで評価 縦軸はモデルの出力(ランキングのスコア予測値) 1000view あたりの 予約件数 レビュー 件数 どちらの件数も増えるほどスコア予測値上昇
- 17. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage1 (Offline ML Model) Partial Dependence Plotで評価 縦軸はモデルの出力(ランキングのスコア予測値) レビュー スコアの 平均 アクティ ビティの 値段 レビューの平均スコアが高いほどスコア予測値上昇 値段は高いほどスコア予測値は下がる傾向
- 18. データ数少し多め(アクティビティ: 4000個、検索履歴: 25万) Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) アクティビティ属性+ユーザ属性でGBDT学習 (予約するかしないかを予測するモデル) ユーザによってはランキングが変化する A/Bテストで評価 (Stage1のモデルと比較) 予約数で7.9%増
- 19. パーソナライズのためのユーザ属性 過去?現在のAirbnb Homeの予約 過去のAirbnb Experienceの予約 検索セッションの中での履歴(Airbnb Experienceでの過去のクリックと予約) Airbnb Homeの属性としては、 場所、日にち、期間、ゲスト人数、料金など Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model)
- 20. Partial dependency plot Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ← 横軸はHomeで宿泊している場所と アクティビティの場所の距離 宿泊してる場所に近いアクティビティの方が スコア予測値が高い(ランク上位) 傾向がある
- 21. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ここからわかること ?ユーザの短期的な特徴(直近30日) ?ユーザの長期的な特徴 検索セッションの中での履歴(Airbnb Experienceでの過去のクリックと予約) ユーザ属性のうち
- 22. ユーザの短期的な特徴 Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ?興味のあるカテゴリー ?暇な時間 ?希望の価格帯
- 23. ユーザの短期的な特徴(興味のあるカテゴリー) Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) 各アクティビティにはカテゴリーのタグ付けされてるので、 そのタグ(ハイキング、音楽、ヨガ、...)ごとに興味の指標を計算する。 興味の指標 ● Category Intensity カテゴリーごとのクリック数 ● Category Recency 最後にクリックしてからの経過日数
- 24. ユーザの短期的な特徴(興味のあるカテゴリー) Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) Partial dependency plot category intensity: クリック数が多いものはランク上位へ category recency: 最近クリックされていないものはランク下位へ
- 25. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ユーザの短期的な特徴(興味のあるカテゴリー) クリックではなく予約の履歴で見てみると、 最近予約したカテゴリーはランク下位へ → 旅行中に同じカテゴリーのアクティビティはもういい
- 26. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ユーザの長期的な特徴 ?過去に予約したカテゴリー ?プロフィールとして登録している趣味 ?Airbnb Homeの予約状況 → 短期間で変化しない特徴が見える
- 27. Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ユーザの長期的な特徴 例えば、ユーザの居住地と組み合わせると、 行き先が『パリ』の場合、 ? 出発地が『日本』 → ワークショップに参加する ? 出発地が『USA』 → 飲み食いする ? 出発地が『フランス』 → 歴史ツアーに参加する 短期?長期ともに、ユーザ属性として利用する。
- 28. オフラインで学習しておくメリット Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage2 (Personalized Offline ML Model) ● アクティブなユーザに絞ってランキングを計算しておく ● スコアはDBに入れて、検索時には参照するだけ ● 少ない投資でできる
- 29. データ数多い(アクティビティ: 16000個、検索履歴: 100万) Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage3 (Personalized Online ML Model) アクティビティ属性+ユーザ属性+クエリ属性でGBDT学習 (予約するかしないかを予測するモデル) すべてのユーザに異なるランキングを出せる A/Bテストで評価 (Stage2のモデルと比較) 予約数で5.1%増
- 30. クエリ属性 ?場所 ?ゲスト数 ?日数 ?ブラウザの言語 Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage3 (Personalized Online ML Model)
- 31. 検索に入力した場所と実際のアクティビティの場所との距離 Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage3 (Personalized Online ML Model) Partial dependency plot 離れてるほうがランキングは低めに出る
- 32. Stage3までは予約件数を上げることが目標 実際の運用では、他にも目標が存在している=Business Rules Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Stage4 (Business Rules) 検索結果の 多様性 検索結果の 質の向上 新しいアクティビティ ヒットしそうなのを出せ れば 高い稼働率
- 33. Apache Supersetを使って可視化 Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) モニタリング 特定のアクティビティや属性ごとの傾向が見えるようにしてる
- 34. ● Personalized Groupings 一通りではないランキングの表示方法 家族旅行→家族向けのアクティビティ、10日間の旅行→日帰りアクティビティ ● Different Labeling 二値ラベルではないユーザアクションに基づくラベル付与 (imp, click, booking) ● Adding more real-time signals クリック後すぐに反映 ● Impression discounting 上位表示されたけど無視されたやつのランクをリアルタイムに下げる Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) 現在進行系のタスク
- 35. ● ポジションバイアス ● GBDT以外のモデル ● 探索と活用 ● 事例レベルの属性(平日と週末の違いみたいな) Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) Future Work
- 36. ■ シンプルなベースラインから始めて、徐々に複雑にしていく → コントロールしやすくなる ?複数のアイデアを別々にテストしやすい ?何が良くて何が悪いかわかりやすい ■ チャンス:MLモデルがうまく働かないケースを見つける ■ 調査して新しいアプローチをテストする時間をとっておく ■ いいアイデアが必ずしもうまくいくとは限らない (だいたいの実験が変化なしか悪化したので、) ■ 悪い実験結果から分析して学びましょう Machine Learning-Powered Search Ranking of Airbnb Experiences (Mihajlo Grbovic) アドバイス
- 37. ? BIG ?検索ランキング “Machine Learning-Powered Search Ranking of Airbnb Experiences.” ? [Personalization] In ResearchTrack ?ユーザ側?アイテム側両方の情報を使った推薦 “Dual Neural Personalized Ranking” ?環境の変化に対応したバンディット “Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests” ? W4A ?旅行先の推薦 “Location Embeddings for Next Trip Recommendation.” ?Webページの画像の代替テキストの評価 “Combining Semantic Tools for Automatic Evaluation of Alternative Texts” 紹介する研究
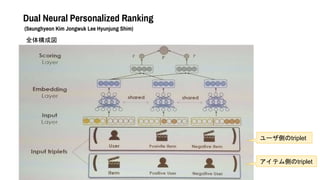
- 38. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) Implicit Feedbackなレコメンドモデルを提案 既存研究 ?Bayesian Personalized Ranking (BPR) 各ユーザについて、アイテムのペアワイズのランキング損失を最小化する ?Neural Personalized Ranking (NPR) ↑のDNN拡張 ユーザ側の三つ組(ユーザ?アイテムi?アイテムj)について、 iがjよりもランク上位になる確率を出力する。 問題点 ?アイテム側の三つ組を見ていない ?汎用的な設計ではない
- 39. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) そこで提案するのがDualNPR ?DualPairwise: ユーザ側からのtripletとアイテム側からのも使う ?一般的なDNNモデル ?動的ネガティブサンプリング戦略
- 40. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) 全体構成図 ユーザ側のtriplet アイテム側のtriplet
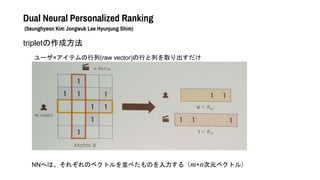
- 41. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) tripletの作成方法 ユーザ×アイテムの行列(raw vector)の行と列を取り出すだけ NNへは、それぞれのベクトルを並べたものを入力する(m+n次元ベクトル)
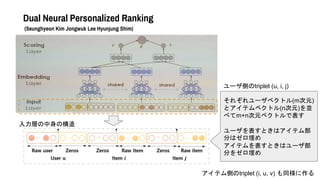
- 42. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) 入力層の中身の構造 それぞれユーザベクトル(m次元) とアイテムベクトル(n次元)を並 べてm+n次元ベクトルで表す ユーザを表すときはアイテム部 分はゼロ埋め アイテムを表すときはユーザ部 分をゼロ埋め ユーザ側のtriplet (u, i, j) アイテム側のtriplet (i, u, v) も同様に作る
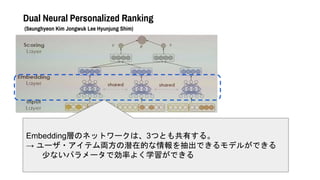
- 43. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) Embedding層のネットワークは、3つとも共有する。 → ユーザ?アイテム両方の潜在的な情報を抽出できるモデルができる 少ないパラメータで効率よく学習ができる
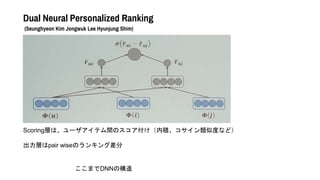
- 44. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) Scoring層は、ユーザアイテム間のスコア付け(内積、コサイン類似度など) 出力層はpair wiseのランキング差分 ここまでDNNの構造
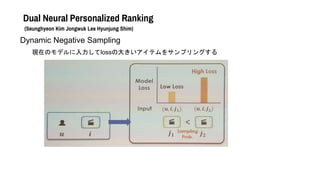
- 45. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) Dynamic Negative Sampling 現在のモデルに入力してlossの大きいアイテムをサンプリングする
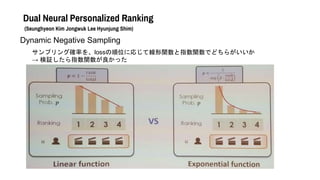
- 46. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) Dynamic Negative Sampling サンプリング確率を、lossの順位に応じて線形関数と指数関数でどちらがいいか → 検証したら指数関数が良かった
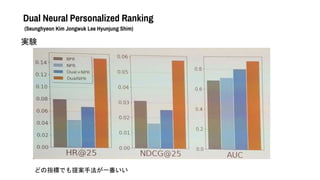
- 47. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) 実験 使ったデータセットは ?Amazon Music ?MovieLens Latest ?MovieLens 1M 比較対象は ?BPR ?NPR ?Dual+NPR: ユーザ側?アイテム側の表現を使ってNPRを拡張したもの → 違いはraw vectorを使っているところとdynamic negative sampling ?DualNPR(提案手法) 評価指標は ?HR@N : トップN個の中にあるかどうかで評価 ?NDCG@N : トップNでどれだけ高くランク付けされているか ?AUC
- 48. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) 実験 どの指標でも提案手法が一番いい
- 49. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) 実験(Dual Representation) ユーザ側とアイテム側のベクトルを使った方がいい 特に(a)と(b)のデータセットで顕著→ スパースなデータの場合に効いてる ユーザ側?アイテム側の両方を使った場合と使わない場合の比較
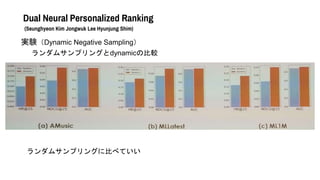
- 50. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) 実験(Dynamic Negative Sampling) ランダムサンプリングに比べていい ランダムサンプリングとdynamicの比較
- 51. Dual Neural Personalized Ranking (Seunghyeon Kim Jongwuk Lee Hyunjung Shim) まとめ ユーザ側とアイテム側の両方のベクトルを使ったことで精度改善した Dynamic Negative Samplingも効果的 future work 過学習を防ぐ方法 → 少しずつモデルの複雑度を上げていく みたいなのは必ずしも効果的 ではないので、、
- 52. ? BIG ?検索ランキング “Machine Learning-Powered Search Ranking of Airbnb Experiences.” ? [Personalization] In ResearchTrack ?ユーザ側?アイテム側両方の情報を使った推薦 “Dual Neural Personalized Ranking” ?環境の変化に対応したバンディット “Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests” ? W4A ?旅行先の推薦 “Location Embeddings for Next Trip Recommendation.” ?Webページの画像の代替テキストの評価 “Combining Semantic Tools for Automatic Evaluation of Alternative Texts” 紹介する研究
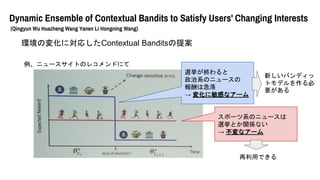
- 53. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 環境の変化に対応したContextual Banditsの提案 → ユーザの好みの変化など たいていの既存のcontextual banditアルゴリズムは 環境が定常であることを前提としている。
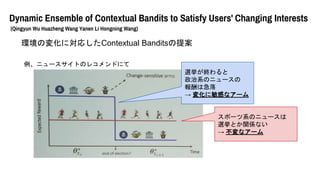
- 54. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 環境の変化に対応したContextual Banditsの提案 例、ニュースサイトのレコメンドにて 選挙が終わると 政治系のニュースの 報酬は急落 → 変化に敏感なアーム スポーツ系のニュースは 選挙とか関係ない → 不変なアーム
- 55. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 環境の変化に対応したContextual Banditsの提案 例、ニュースサイトのレコメンドにて 選挙が終わると 政治系のニュースの 報酬は急落 → 変化に敏感なアーム スポーツ系のニュースは 選挙とか関係ない → 不変なアーム 新しいバンディッ トモデルを作る必 要がある 再利用できる
- 56. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 問題は、 1. 変化をどう検知するか 2. 変化の影響を受けないアームをどう判別するか 3. 複数のバンディットモデルからどうアームを選択するか
- 57. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) ? Bandit Expert 期待報酬の高いアームを引き続ける人 Contextual Banditモデルそのもの 'Badness' Bandit Expertの悪さを定義 期待報酬と実際の報酬の差分 ? Bandit Auditor badnessの推定値を監視する役 ?信頼区間にあればOKとする ?大きな変化があると、信頼区間から外れるので、そのExpertの推定結果は使わない → 変化の影響を受けるアームは選択されなくなる 詳しくは→論文
- 58. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 変化の影響を受けないExpertは Badnessに変化がなくAuditorが許可する (例: スポーツ系のニュース記事) 変化の影響を受けるExpertは Badnessが信頼区間外に行ってしまうので Auditorが許可しない (例: 政治系のニュース記事) Dynamic Ensemble of Contextual Bandits
- 59. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) Dynamic Ensemble of Contextual Bandits 論文 より 時刻tで、これまでに作ったExpertの集合: Badnessが信頼区間に入ってるExpertのみ許可して 許可Expert集合に入れる→ 許可されたExpertが1つもないときは新たに作る。 両方の集合に追加しておく。
- 60. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) Dynamic Ensemble of Contextual Bandits アームの選び方 ExpertたちのUCBの平均を最大化 するアームを選ぶ Regret分析は難しいのでスキップして、、、
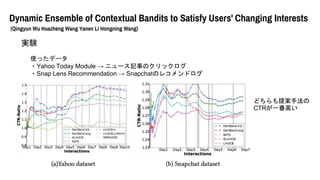
- 61. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 実験 比較対象 ?WMDUCB1 - non-contextualなbanditで、移動平均を使った変化点検知機能付き ?adTS - 適応的トンプソンサンプリング。CUMSUMテストで変化点検知 ?dLinUCB - 階層的な動的contextual bandit
- 62. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 実験 使ったデータ ?Yahoo Today Module → ニュース記事のクリックログ ?Snap Lens Recommendation → Snapchatのレコメンドログ どちらも提案手法の CTRが一番高い
- 63. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) 実験 使ったデータ ?Last FM Dataset 異なるユーザ群を途中で入れて環境の変化をシミュレートしてみた こちらも提案手法の CTRが一番高い
- 64. Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests (Qingyun Wu Huazheng Wang Yanen Li Hongning Wang) まとめ 非定常な環境でのバンディットの提案 - 環境の変化に対してコンテキスト依存な性質の活用 - Expert/Auditorによるアンサンブルなバンディット Future Work - ユーザたちの関心の変化の影響を考慮する - 変化し続ける環境、定期的な変動への対応 参考: BanditLib
- 65. ? BIG ?検索ランキング “Machine Learning-Powered Search Ranking of Airbnb Experiences.” ? [Personalization] In ResearchTrack ?ユーザ側?アイテム側両方の情報を使った推薦 “Dual Neural Personalized Ranking” ?環境の変化に対応したバンディット “Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests” ? W4A ?旅行先の推薦 “Location Embeddings for Next Trip Recommendation.” ?Webページの画像の代替テキストの評価 “Combining Semantic Tools for Automatic Evaluation of Alternative Texts” 紹介する研究
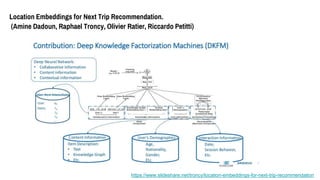
- 66. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) 旅行先をレコメンドする デモグラ?履歴?コンテキスト情報(いつどこに何人で旅行したかとか)を活用する Research Question ?何を推薦するか ?外部データを使って精度をあげられるか ?評価どうする
- 67. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) /troncy/location-embeddings-for-next-trip-recommendation
- 68. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) /troncy/location-embeddings-for-next-trip-recommendation 使うデータ ?旅行者のデモグラ (年齢、性別、国籍、...) ?旅行履歴情報 出発地、目的地、期間、... タイプ: 片道?往復?複数地点
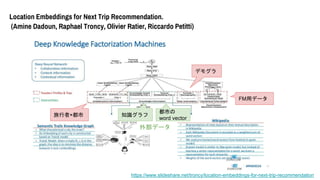
- 69. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) 前処理 ?データフィルタリング - 頻度の低いデータを除外(旅行回数の少ない人、訪問者が少ない場所) - レジャーの旅行のみ対象とする → 旅行者×旅行先 の行列がスパース ?データ強化 - 旅行先の都市名をwikipediaから引いてきて、 各単語のTF-IDFに対応するword vectorを作る - 知識グラフを使ってEmbedding 訪問履歴から知識抽出する的な?? 詳しくは → /troncy/location-embeddings-for-next-trip-recommendation
- 70. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) /troncy/location-embeddings-for-next-trip-recommendation 旅行者×都市 デモグラ FM用データ 知識グラフ 都市の word vector 外部データ
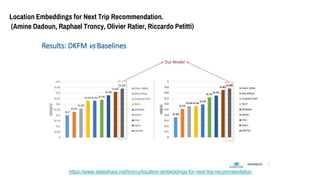
- 71. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) 評価方法は、leave-one-outで、 過去ログから各旅行者の最後の旅行を隠して学習し、最後の行き先を当てられるかどうか 予測結果はランキングで出して、上位K(実験ではK=10)に入ってるかどうかを見る 指標 ?Hitrate@K: 上位Kに入ってるかどうかの集計値。 ?MRR@K: 順位で重み付けする。上位でマッチするほど大きい値になる。
- 72. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) /troncy/location-embeddings-for-next-trip-recommendation
- 73. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) /troncy/location-embeddings-for-next-trip-recommendation
- 74. Location Embeddings for Next Trip Recommendation. (Amine Dadoun, Raphael Troncy, Olivier Ratier, Riccardo Petitti) 結論 ?様々な属性を組み合わせて精度向上できた ?他の手法と比べても性能がいい 今後 ?都市についてvisual embedding ?コサイン類似度のような類似度指標をDNNの中で使えないか
- 75. ? BIG ?検索ランキング “Machine Learning-Powered Search Ranking of Airbnb Experiences.” ? [Personalization] In ResearchTrack ?ユーザ側?アイテム側両方の情報を使った推薦 “Dual Neural Personalized Ranking” ?環境の変化に対応したバンディット “Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests” ? W4A ?旅行先の推薦 “Location Embeddings for Next Trip Recommendation.” ?Webページの画像の代替テキストの評価 “Combining Semantic Tools for Automatic Evaluation of Alternative Texts” 紹介する研究
- 76. 自動的にWebページのアクセシビリティを評価することは重要 Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) すぐに結果がわかるし、コスト削減もできて、ページの一貫性を保つことができる が、 コンテンツのセマンティックスは解釈できないので、その妥当性までは確認できない。 (例えば、画像のalt属性があってるかどうか) 研究の背景について
- 77. Simply Accessible 2015 reportによると Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) ● 66.36% → 有益な画像だが代替テキストがない ● 20.33% → 代替テキストが役立たず ● 10.35% → 代替テキスト付きの飾り付け画像 ● 2.96% → 代替テキストが他のコンテンツの使い回し Webページ中の画像と代替テキストにありがちな問題点
- 78. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) ● 情報伝達 → 代替テキストはその内容を記述するべき ● 飾り付け画像 → 情報はない。null。だから代替テキストもいらない。 ● 機能画像(ナビゲーション的な??) → 代替テキストはその行動を記述するべき(「詳細ページへ」的な??) Webページ中の画像の目的とは 代替テキストは、125文字未満の簡易な文言にすべし Webページの文脈を考慮して情報欠損しないように "image of"とか"graphic of"とか付けるな
- 79. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 画像と代替テキストの対応が大事で、 画像に対して代替テキストの質がどの程度のものか評価できるシステムが あれば嬉しい (目的が「情報伝達」である画像に限るが、、) 提案する内容
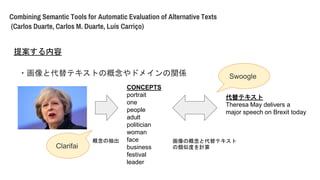
- 80. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 以下のような点について調べるアルゴリズムを提案 ?画像と代替テキストの概念やドメインの関係 ?画像のメタデータと代替テキストの関係 ?記述の長さ 提案する内容 具体的には、 画像から概念を抽出し、代替テキストとの類似度を計算する。 抽出した概念からドメイン(人物画像ならPerson)を判定して、代替テキストとの類似度計算
- 81. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 提案する内容 使ったツール ?Clarifai: 画像の概念とドメイン抽出 ?Swoogle: 概念と代替テキストのセマンティックな関連性 ?spaCy: 代替テキストから固有表現 ?Sematch: 固有表現と画像の概念を結びつける
- 82. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 提案する内容 ?画像と代替テキストの概念やドメインの関係 CONCEPTS portrait one people adult politician woman face business festival leader 代替テキスト Theresa May delivers a major speech on Brexit today 概念の抽出 画像の概念と代替テキスト の類似度を計算Clarifai Swoogle
- 83. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 提案する内容 ?画像と代替テキストの概念やドメインの関係 CONCEPTS portrait one people adult politician woman face business festival leader 代替テキスト Theresa May delivers a major speech on Brexit today 画像から抽出した概念 画像の概念と代替テキストのドメイン との類似度を計算 ドメイン Person
- 84. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 提案する内容 ?画像と代替テキストの概念やドメインの関係 CONCEPTS portrait one people adult politician woman face business festival leader 代替テキスト Theresa May delivers a major speech on Brexit today 画像から抽出した概念 画像の概念と代替テキストのドメイン との類似度を計算 ドメイン Person spaCy 固有表現の抽出
- 85. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 実験 訓練データ:収集した画像と代替テキスト45個 (代替テキストの質を “very bad”, “bad”, “good”, “very good”の4段階に分類) テストデータ:149個の画像と代替テキスト → badとgoodの二値分類したときの精度評価
- 86. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 実験 Accuracy: 0.832 Precision: 0.853 Recall: 0.795 F-measure: 0.823 なかなかいい → 提案したアルゴリズムで自動的に代替テキストの評価ができそう
- 87. Combining Semantic Tools for Automatic Evaluation of Alternative Texts (Carlos Duarte, Carlos M. Duarte, Luís Carri?o) 実験 できていない点 ?使ったセマンティックサービスの性能に依存する ?英語のみ対応 ?ページの文脈は使っていない ?画像の目的が情報伝達かそれ以外かは考慮していない 参考ページ マッシュアップなのでわかりやすいw