












Kaggle ®C Airbnb New User Bookings§Œ•¢•◊•Ì©`•¡§À§ƒ§§§∆(Kaggle Tokyo Meetup #1 20160305)
- 1. Kaggle ®C Airbnb New User Bookings§Œ•¢•◊•Ì©`•¡§À§ƒ§§§∆ Kaggle Tokyo Meetup #1 2016/03/05 id:@Keiku
- 2. ±æ»’§Œ•¢•∏•ß•Û•¿ ? Airbnb New User Bookings•≥•Û•⁄∏≈“™ ®C Dataset§À§ƒ§§§∆ ®C Metric§À§ƒ§§§∆ ? ±æ•≥•Û•⁄§À≤Œº”§∑§øÑ”ôC ? •¢•◊•Ì©`•¡§À§ƒ§§§∆ ®C Preprocessing ®C Stacked generalization ®C Modeling ®C Results ? Shakeup§À§ƒ§§§∆ ? §™§Ô§Í§À
- 3. Dataset§À§ƒ§§§∆(1) ? train_users.csv - the training set of users ? test_users.csv - the test set of users ®C id: user id ®C date_account_created: the date of account creation ®C timestamp_first_active: timestamp of the first activity, note that it can be earlier than date_account_created or date_first_booking because a user can search before signing up ®C date_first_booking: date of first booking ®C gender ®C age ®C signup_method ®C signup_flow: the page a user came to signup up from ®C language: international language preference ®C affiliate_channel: what kind of paid marketing ®C affiliate_provider: where the marketing is e.g. google, craigslist, other ®C first_affiliate_tracked: whats the first marketing the user interacted with before the signing up ®C signup_app ®C first_device_type ®C first_browser ®C country_destination: this is the target variable you are to predict
- 4. Dataset§À§ƒ§§§∆(2) ? sessions.csv - web sessions log for users ®C user_id: to be joined with the column 'id' in users table ®C action ®C action_type ®C action_detail ®C device_type ®C secs_elapsed ? countries.csv - summary statistics of destination countries in this dataset and their locations ? age_gender_bkts.csv - summary statistics of users' age group, gender, country of destination ? sample_submission.csv - correct format for submitting your predictions
- 5. Metric§À§ƒ§§§∆(1) ? The evaluation metric for this competition is NDCG (Normalized discounted cumulative gain) @k where k=5. NDCG is calculated as: ? where reli is the relevance of the result at position i. ? IDCGk is the maximum possible (ideal) DCG for a given set of queries. All NDCG calculations are relative values on the interval 0.0 to 1.0. ? For each new user, you are to make a maximum of 5 predictions on the country of the first booking. The ground truth country is marked with relevance = 1, while the rest have relevance = 0. ? For example, if for a particular user the destination is FR, then the predictions become:
- 6. ±æ•≥•Û•⁄§À≤Œº”§∑§øÑ”ôC ? ÷˜§ ¿Ì”… ®C Learning to rank(Metric§¨NDCG)§ŒÜñÓ}§À»°§ÍΩM§Û§«§þ§ø§´§√§ø ? þ^»•§À§œ°¢Personalize Expedia Hotel Searches - ICDM 2013 ®C Train dataset§Œ∆⁄Èg§¨2010/01?2014/06°¢Test dataset§Œ∆⁄Èg§¨2014/07 ?2014/09§«§¢§√§ø ? §≥§Œ•ø•§•◊§Œ•«©`•ø§ŒCross Validation§Àøý ÷“‚◊R§Œ§¢§Î ? þ^»••≥•Û•⁄£∫ ®C Rossmann Store Sales ®C Recuruit - Coupon Purchase Prediction ®C Avazu - Click-Through Rate Prediction ®C •«•‚•∞•È§¨∂ý§Ø°¢Ãÿè’¡ø§¨§ƒ§Ø§Í§‰§π§§ ? µ±ïr§Œ◊¥õr ®C •≥•Û•⁄∆⁄Èg§œ°¢2015/11/25?2016/02/11(78»’Èg)§«°¢First submission§œ 2016/01/25§«§¢§ÍΩK±P ®C ≤–§Í3þLÈg√„è䧌§ø§·§À≤Œº”
- 7. Preprocessing(1) ? Ãÿè’≥È≥ˆ ®C ageƒ⁄§À∫¨§Þ§Ï§Î…˙ƒÍ‘¬»’§Ú–Þ’˝§π§Î ®C date_first_booking§»date_account_created§Œlag§Ú”ãÀ„§∑°¢§Ω§Ï§Ú4•´•∆•¥•Í§À ºØºs§π§Î ®C date_first_booking§»timestamp_first_active§Œlag§Ú”ãÀ„§∑°¢§Ω§Ï§Ú3•´•∆•¥•Í§À ºØºs§π§Î ®C •´•∆•¥•Í•´•Î≠˝§ÚOne-Hot Encoding§π§Î ®C train_users.csv°¢test_users.csv§Àage_gender_bkts.csv§Újoin§π§Î ®C train_users.csv°¢test_users.csv§Àcountries.csv§Újoin§π§Î ®C sessions.csv§Ú(user_id°¢action)§Ú•≠©`§Àsecs_elapsed§»–– ˝§Ú•µ•Þ•Í°¢ train_users.csv°¢test_users.csv§Àjoin§π§Î£®action“‘Õ‚§Œâ‰ ˝§‚Õ¨ò ? Ãÿè’≥È≥ˆ§Ú§π§Î§À§¢§ø§Í ®C π§®§Î§‚§Œ§œ§π§Ÿ§∆ 𧶠®C sessions.csv§œ–Ú¡––‘§‚ó ”ë§∑§ø§¨Ñøπ˚§œ§ §´§√§ø°£Telstra Network Disruptions§Œ•«©`•ø§œ‘™§Œ–Ú¡––‘§¨Magic features§»§ §√§ø¿˝§‚§¢§Î
- 10. Stacked generalization ? “‘œ¬§Œ18•‚•«•Î§À§ƒ§§§∆Stacking 1. Model£∫XGBoost / Target£∫age / Train dataset£∫age∑««∑ìp 2. Model£∫XGBoost / Target£∫age_cln / Train dataset£∫age∑««∑ìp 3. Model£∫XGBoost / Target£∫age_cln2 / Train dataset£∫age∑««∑ìp 4. Model£∫glmnet / Target£∫age_cln / Train dataset£∫age∑««∑ìp 5. Model£∫glmnet / Target£∫age_cln2 / Train dataset£∫age∑««∑ìp 6. Model£∫XGBoost / Target£∫country_destination / Train dataset£∫Train»´∆⁄Èg 7. Model£∫XGBoost / Target£∫country_destination / Train dataset£∫÷±Ω¸12•ˆ‘¬ 8. Model£∫XGBoost / Target£∫country_destination / Train dataset£∫÷±Ω¸6•ˆ‘¬ 9. Model£∫XGBoost / Target£∫country_destination / Train dataset£∫»•ƒÍ§Œ7,8,9‘¬ 10. Model£∫XGBoost / Target£∫distance_km / Train dataset£∫distance_km∑««∑ìp 11. Model£∫XGBoost / Target£∫destination_km2 / Train dataset£∫destination_km2∑««∑ìp 12. Model£∫XGBoost / Target£∫gender / Train dataset£∫∑«-unknown- 13. Model£∫XGBoost / Target£∫dfb_dac_lag_flg / Train dataset£∫Train»´∆⁄Èg 14. Model£∫XGBoost / Target£∫dfb_tfa_lag_flg / Train dataset£∫Train»´∆⁄Èg 15. Model£∫XGBoost / Target£∫dfb_dac_lag / Train dataset£∫Train»´∆⁄Èg 16. Model£∫XGBoost / Target£∫dfb_tfa_lag / Train dataset£∫Train»´∆⁄Èg 17. Model£∫glmnet / Target£∫dfb_dac_lag / Train dataset£∫Train»´∆⁄Èg 18. Model£∫glmnet / Target£∫dfb_tfa_lag / Train dataset£∫Train»´∆⁄Èg
- 11. Modeling(1) ? XGBoost§Ú π§√§∆•‚•«•Í•Û•∞ ®C eval_metric§œNDCG@5 ? merror°¢mlogloss§œ◊ÓΩKµƒ§À π”√§∑§ §´§√§ø ? c4.8xlarge§«1 round§ŒCV§«1∑÷§€§…°£√Êµπ§¿§¨ƒÕ§®§Î ®C Drip Coffee10±≠∑÷§Ø§È§§œ˚ ß:-) ®C Techniques (Tricks) for Data Mining Competitions(@smly) ? BO°¢RSCV§ §…§À§Ë§Î•¡•Â©`•À•Û•∞§ŒÉûœ»∂»§œµÕ§´§√§ø ? Ãÿè’þxík ®C Ãÿ§À…˙§Œage§œæ´∂»§Ú¬‰§»§∑§ø ? Ãÿè’þxík§π§Î§≥§»§«æ´∂»§¨“ªöð§ÀœÚ…œ ®C 90%§Ú•È•Û•¿•ý§ÀÃÿè’þxík§∑§∆•‚•«•Î§Ú◊˜≥…
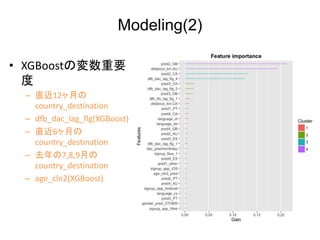
- 12. Modeling(2) ? XGBoost§Œâ‰ ˝÷ÿ“™ ∂» ®C ÷±Ω¸12•ˆ‘¬§Œ country_destination ®C dfb_dac_lag_flg(XGBoost) ®C ÷±Ω¸6•ˆ‘¬§Œ country_destination ®C »•ƒÍ§Œ7,8,9‘¬§Œ country_destination ®C age_cln2(XGBoost)
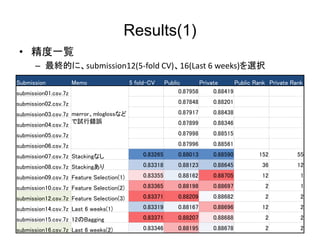
- 13. Results(1) ? æ´∂»“ª”E ®C ◊ÓΩKµƒ§À°¢submission12(5-fold CV)°¢16(Last 6 weeks)§Úþxík Submission Memo 5 fold-CV Public Private Public Rank Private Rank submission01.csv.7z merror°¢mlogloss§ §… §«‘á––Âe’` 0.87958 0.88419 submission02.csv.7z 0.87848 0.88201 submission03.csv.7z 0.87917 0.88438 submission04.csv.7z 0.87899 0.88346 submission05.csv.7z 0.87998 0.88515 submission06.csv.7z 0.87996 0.88561 submission07.csv.7z Stacking§ §∑ 0.83265 0.88013 0.88590 152 55 submission08.csv.7z Stacking§¢§Í 0.83318 0.88123 0.88645 36 12 submission09.csv.7z Feature Selection(1) 0.83355 0.88162 0.88705 12 1 submission10.csv.7z Feature Selection(2) 0.83365 0.88198 0.88697 2 1 submission12.csv.7z Feature Selection(3) 0.83371 0.88209 0.88682 2 2 submission14.csv.7z Last 6 weeks(1) 0.83319 0.88167 0.88696 12 2 submission15.csv.7z 12§ŒBagging 0.83371 0.88207 0.88688 2 2 submission16.csv.7z Last 6 weeks(2) 0.83346 0.88195 0.88678 2 2
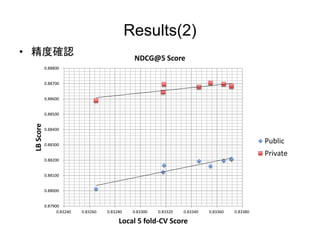
- 14. Results(2) ? æ´∂»¥_’J 0.87900 0.88000 0.88100 0.88200 0.88300 0.88400 0.88500 0.88600 0.88700 0.88800 0.83240 0.83260 0.83280 0.83300 0.83320 0.83340 0.83360 0.83380 LBScore Local 5 fold-CV Score NDCG@5 Score Public Private
- 15. Shakeup§À§ƒ§§§∆ ? Forum§À°∏Expected Leaderboard Shakeup°π§»§§§¶Topic§¨¡¢§ƒ§€§…Shakeup §¨ë“ƒÓ§µ§Ï§Î ? ÀΩ§Œøº≤Ï ®C 5-fold CV§»Public LB Score§ŒÈvþB§¨èä§Ø°¢ÖgºÉ§ÀÅI∑Ω§»§‚¡º§§•π•≥•¢§Œ•‚ •«•Î§Úþx§Ÿ§–¡º§´§√§ø ®C ◊ÓΩKSubmission§À2§ƒþx§Ÿ§Î§Œ§«°¢1§ƒ§œPublic LB§ŒScore§¨◊Ó§‚∏þ§§•‚ •«•Î°¢§‚§¶1§ƒ§œLast 6 weeks§ŒScore§¨◊Ó§‚∏þ§§•‚•«•Î§Úþxík§∑§ø ? Best Public LB£∫Public: 0.88209(2nd)/Private: 0.88682(2nd) ? Best Last 6 weeks Validation£∫Public: 0.88195(2nd)/Private: 0.88678(2nd) ®C Shakeup§Àèä§Ω§¶§ Gilberto Titericz Junior§µ§Û§Œ•≥•·•Û•» ? CV§Œ•π•≥•¢§¨Õ¨§∏§‚§Œ2§ƒ§¨§¢§Í°¢Public LB§¨¡º§§∑Ω§Úþx§Û§¿§¨°¢“ª ∑Ω§œ§‚§√§»¡º§§•π•≥•¢§«§¢§Í°¢Public: 0.88107(57th)/Private: 0.88675(3rd)§«§¢§√§ø ®C •∑•Û•◊•Î§ •‚•«•Îòã∫B§Ú–ƒ§¨§±§ø°£•¢•Û•µ•Û•÷•Î§œ§¢§Þ§ÍÑøπ˚§¨§ §§ ®C ◊˜≥…§∑§øÃÿè’¡ø§¨èä§Ø°¢Shakeup§∑§ø§‚§Œ§Œ…œŒª§«§»§…§Þ§√§ø
- 16. §™§Ô§Í§À ? •≥•Û•⁄’Ò§Í∑µ§Í ®C ≥£§À√„èä§π§Î§»§§§¶•π•ø•Û•π§«»°§ÍΩM§þ°¢Ãÿ§ÀÈ_ ºïr∆⁄§œ öð§À§∑§ §§ ®C •«©`•ø§Ú§ƒ§÷§µ§À“ä§∆°¢øº≤ϧπ§Î ? Train§À§∑§´§ §§date_first_booking§‚ π§®§Î§´ó ”ë§π§Î ®C Evaluation Metric§œ√Êµπ§«§‚∫œ§Ô§ª§Î ®C ª˘±æµƒ§À§œCross Validation§ŒΩYπ˚§¨¡º§§•‚•«•Î§Úþxík ®C Shakeup§Œë“ƒÓ§Œ§¢§Îàˆ∫œ°¢•∑•Û•◊•Î§ •‚•«•Îòã∫B§Ú–ƒ §¨§±°¢Æê§ §ÎValidation•—•ø©`•Û§Ú”√“‚§∑§∆§™§Ø ®C Results(2)§Œ§Ë§¶§ •∞•È•’§œ±ÿ§∫ﯧ±§Î§Ë§¶§À•·•‚§Ú»°§Î