





































































More Related Content
Similar to UNIT-1 Introduction to Distributed SystemPPT.ppt (20)
Recently uploaded (20)


















UNIT-1 Introduction to Distributed SystemPPT.ppt
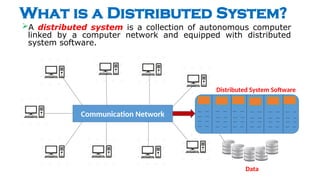
- 1. What is a Distributed System? ’āśA distributed system is a collection of autonomous computer linked by a computer network and equipped with distributed system software. Communication Network Distributed System Software Data
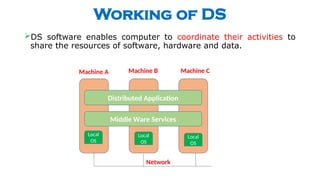
- 2. Working of DS ’āśDS software enables computer to coordinate their activities to share the resources of software, hardware and data. Distributed Application Middle Ware Services Local OS Local OS Local OS Network Machine A Machine B Machine C
- 3. ROLE OF DISTRIBUTED SYSTEM SOFTWARE ŌĆó The main roles and functions of distributed system software include: 1. Resource sharing 2. Communication 3. Scalability 4. Fault tolerance 5. Consistency and coordination 6. Load balancing 7. Security 8. Transparency 9. Performance monitoring 10.Synchronization and concurrency control
- 4. Characterization of Distributed systems ŌĆó Resource Sharing: It is the ability to use any Hardware, Software, or Data anywhere in the System. ŌĆó Openness: It is concerned with Extensions and improvements in the system (i.e., How openly the software is developed and shared with others). ŌĆó Concurrency: It is naturally present in Distributed Systems, that deal with the same activity or functionality that can be performed by separate users who are in remote locations. Every local system has its independent Operating Systems and Resources.
- 5. Characterization of Distributed systems ŌĆó Scalability: It increases the scale of the system as a number of processors communicate with more users by accommodating to improve the responsiveness of the system. ŌĆó Fault tolerance: It cares about the reliability of the system if there is a failure in Hardware or Software, the system continues to operate properly without degrading the performance the system. ŌĆó Transparency: It hides the complexity of the Distributed Systems to the Users and Application programs as there should be privacy in every system.
- 6. Characterization of Distributed systems ŌĆó Heterogeneity: Networks, computer hardware, operating systems, programming languages, and developer implementations can all vary and differ among dispersed system components.
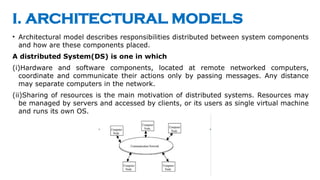
- 8. I. ARCHITECTURAL MODELS ŌĆó Architectural model describes responsibilities distributed between system components and how are these components placed. A distributed System(DS) is one in which (i)Hardware and software components, located at remote networked computers, coordinate and communicate their actions only by passing messages. Any distance may separate computers in the network. (ii)Sharing of resources is the main motivation of distributed systems. Resources may be managed by servers and accessed by clients, or its users as single virtual machine and runs its own OS.
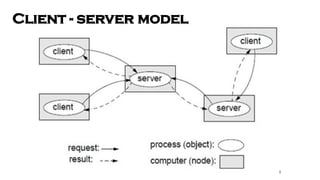
- 9. a) Client-server model ŌĆó The system is structured as a set of processes, called servers, that offer services to the users, called clients. ŌĆó The client-server model is usually based on a simple request/reply protocol implemented with send/receive primitives or using remote procedure calls (RPC) or remote method invocation (RMI): ŌĆó The client sends a request (invocation) message to the server asking for some service; ŌĆó The server does the work and returns a result (e.g. the data requested) or an error code if the work could not be performed.
- 10. Client - server model
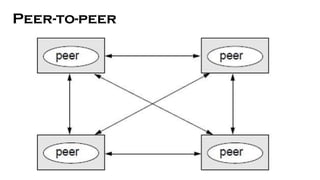
- 11. b) Peer-to-peer All processes (objects) play similar role. ŌĆóProcesses (objects) interact without particular distinction between clients and servers. ŌĆóThe pattern of communication depends on the particular application. ŌĆóA large number of data objects are shared; any individual computer holds only a small part of the application database. ŌĆóProcessing and communication loads for access to objects are distributed across many computers and access links. ŌĆóThis is the most general and flexible model. ŌĆóIt distributes shared resources widely -> share computing and communication loads.
- 12. Peer-to-peer
- 13. II. INTERACTION MODEL ŌĆó Interaction model are for handling time i. e. for process execution, message delivery, clock drifts etc. ŌĆó Synchronous distributed systems ŌĆó Main features: ŌĆó Lower and upper bounds on execution time of processes can be set. ŌĆó Transmitted messages are received within a known bounded time. ŌĆó Drift rates between local clocks have a known bound.
- 14. INTERACTION MODEL ŌĆó Main features: ŌĆó Lower and upper bounds on execution time of processes can be set. ŌĆó Transmitted messages are received within a known bounded time. ŌĆó Drift rates between local clocks have a known bound. ŌĆó Important consequences: 1.In a synchronous distributed system there is a notion of global physical time(with a known relative precision depending on the drift rate). 2.Only synchronous distributed systems have a predictable behavior in terms of timing. Only such systems can be used for hard real-time applications. 3.In a synchronous distributed system, it is possible and safe to use timeouts in order to detect failures of a process or communication link.
- 15. ŌĆó It is difficult and costly to implement synchronous distributed systems. ŌĆó Asynchronous distributed systems ŌĆó Many distributed systems (including those on the Internet) are asynchronous. ŌĆó No bound on process execution time (nothing can be assumed about speed, load, and reliability of computers). ŌĆó No bound on message transmission delays (nothing can be assumed about speed, load, and reliability of interconnections) ŌĆó No bounds on drift rates between local clocks. ŌĆó Important consequences: 1.In an asynchronous distributed system there is no global physical time. Reasoning can be only in terms of logical time (see lecture on time and state). 2.Asynchronous distributed systems are unpredictable in terms of timing. 3.No timeouts can be used. ŌĆó Asynchronous systems are widely and successfully used in practice.
- 16. iii. Fault Models 1.Node Failures: 1.Crash Failure: A node abruptly stops functioning and remains inactive. 2.Omission Failure: A node fails to send or receive messages. 2.Communication Failures: 1.Link Failure: The communication link between two nodes becomes unavailable. 2.Delayed Messages: Messages take longer than expected to reach their destination. 3.Duplicate Messages: A message is received multiple times due to network issues. 3.Clock Synchronization Issues: 1.Clock Drift: Local clocks of nodes run at different rates, leading to time inconsistencies. 2.Clock Skew: The time difference between clocks of different nodes. 4.Network Partition: 1.Network Partition: The network becomes divided into separate subnetworks, preventing communication between nodes on different sides of the partition.
- 17. iii. Fault Models 5. Software Failures: 1.Software Bug: A programming error leads to incorrect behavior or crashes. 2.Deadlock: A set of processes or nodes are waiting for resources that are never released. 6. Hardware Failures: 1.Disk Failure: A storage device becomes inaccessible or corrupted. 2.Memory Corruption: A portion of memory becomes corrupted, leading to data loss or system crashes. 7. Power Failures: 1.Power Outage: The entire system or specific components lose power abruptly. 8. External Failures: 1.Environmental Factors: Environmental conditions such as temperature, humidity, and electromagnetic interference can lead to failures.
- 18. iii. Fault Models ŌĆó Defining a fault model helps in designing fault-tolerant strategies to ensure that a distributed system continues to operate even in the presence of these failures. ŌĆó These strategies can include replication, redundancy, error detection and correction codes, consensus algorithms, and more. ŌĆó Different distributed systems might have varying fault tolerance requirements based on factors like criticality, scalability, performance, and cost.
- 20. REMOTE INVOCATION Request-Reply Communication: ’éĘ Most primitive; minor improvement over underlying IPC primitives. ’éĘ 2-way exchange of messages as in client-server computing. ’éĘ RPC, RMI: mechanisms enabling a client to invoke a procedure/method from the server via communication between client and server. Remote Procedure Call (RPC): ’éĘ Extension of conventional procedural programming model. ’éĘ Allow client programs to transparently call procedures in server programs running in separate processes, and in separate machines from the client. Remote Method Invocation (RMI): ’éĘ Extension of conventional object-oriented programming model ’éĘ Allows objects in different processes to communicate i.e. An object in one JVM is able to invoke methods in an object in another JVM. ’éĘ Extension of local method invocation: allows object in one process to invoke methods of an object living in another process.
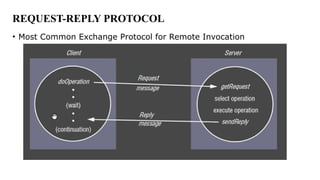
- 22. REQUEST-REPLY PROTOCOL ŌĆó Most Common Exchange Protocol for Remote Invocation
- 23. REQUEST-REPLY PROTOCOL Operations ’éĘdoOperation(): send request to remote object, and returns the reply received ’éĘgetRequest(): acquire client request at server port ’éĘsendReply(): sends reply message from server to client Design issues ’éĘTimeouts: what to do when a request times out? How many retries? ’éĘDuplicate messages: how to discard? ’éĘE.g., recognise successive messages with the same request id and filter them ’éĘLost replies: dependent on idempotency of server operations ’éĘHistory: do servers need to send replies without re-execution? then history needs to be maintained
- 24. Exchange protocols Different flavours of exchange protocols: ’éĘRequest (R): no value to be returned from remote operation o client needs no confirmation operation has been executed o e.g. sensor producing large amounts of data: may be acceptable for some loss ’éĘRequest-reply (RR): useful for most client-server exchanges. Reply regarded as acknowledgement of request o subsequent request can be considered acknowledgement of the previous reply ’éĘRequest-reply-acknowledge (RRA): acknowledgement of reply contains request id, allowing server to discard entry from history
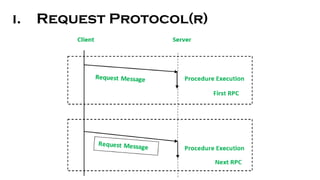
- 26. i. Request Protocol(r) ŌĆó The Request Protocol is also known as the R protocol. ŌĆó It is used in Remote Procedure Call (RPC) when a request is made from the calling procedure to the called procedure. After execution of the request, a called procedure has nothing to return and there is no confirmation required of the execution of a procedure. ŌĆó Because there is no acknowledgement or reply message, only one message is sent from client to server
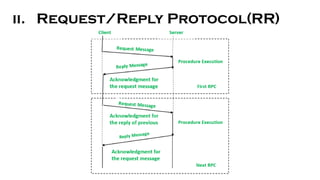
- 28. ii. Request/Reply Protocol(RR) It works well for systems that involve simple RPCs. ŌĆó This protocol has a concept base of using implicit acknowledgements instead of explicit acknowledgements. ŌĆó To deal with failure handling e.g., lost messages, the timeout transmission technique is used with RR protocol. ŌĆó If a client does not get a response message within the predetermined timeout period, it retransmits the request message. ŌĆó Exactly-once semantics is provided by servers as responses get held in reply cache that helps in filtering the duplicated request messages and reply messages are retransmitted without processing the request again. ŌĆó If there is no mechanism for filtering duplicate messages then at least-call semantics is used by RR protocol in combination with timeout transmission.
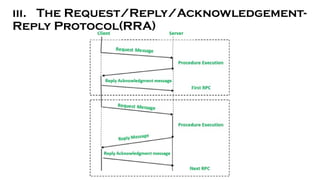
- 29. iii. The Request/Reply/Acknowledgement- Reply Protocol(RRA)
- 30. iii. The Request/Reply/Acknowledgement- Reply Protocol(RRA) ŌĆó This protocol is also known as the RRA protocol (request/reply/acknowledge-reply). ŌĆó Exactly-once semantics is provided by RR protocol which refers to the responses getting held in reply cache of servers resulting in loss of replies that have not been delivered. ŌĆó The RRA (Request/Reply/Acknowledgement-Reply) Protocol is used to get rid of the drawbacks of the RR (Request/Reply) Protocol. ŌĆó In this protocol, the client acknowledges the receiving of reply messages and when the server gets back the acknowledgement from the client then only deletes the information from its cache. ŌĆó Because the reply acknowledgement message may be lost at times, the RRA protocol requires unique ordered message identities. This keeps track of the acknowledgement series that has been sent.
- 31. REMOTE PROCEDURE CALL (RPC)
- 32. Remote Procedure Call ŌĆó Remote Procedure Call (RPC) is a communication technology that is used by one program to make a request to another program for utilizing its service on a network without even knowing the networkŌĆÖs details. ŌĆó A function call or a subroutine call are other terms for a procedure call. ŌĆó It is based on the client-server concept. ŌĆó The client is the program that makes the request, and the server is the program that gives the service. ŌĆó An RPC, like a local procedure call, is based on the synchronous operation that requires the requesting application to be stopped until the remote process returns its results.
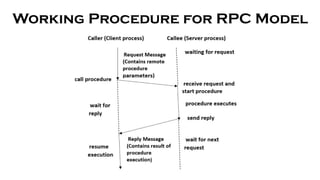
- 33. Working Procedure for RPC Model
- 34. Working Procedure for RPC Model ŌĆó The process arguments are placed in a precise location by the caller when the procedure needs to be called. ŌĆó Control at that point passed to the body of the method, which is having a series of instructions. ŌĆó The procedure body is run in a recently created execution environment that has duplicates of the calling instructionŌĆÖs arguments. ŌĆó At the end, after the completion of the operation, the calling point gets back the control, which returns a result.
- 35. Working Procedure for RPC Model ŌĆó The call to a procedure is possible only for those procedures that are not within the callerŌĆÖs address space because both processes (caller and callee) have distinct address space and the access is restricted to the callerŌĆÖs environmentŌĆÖs data and variables from the remote procedure. ŌĆó The caller and callee processes in the RPC communicate to exchange information via the message-passing scheme. ŌĆó The first task from the server-side is to extract the procedureŌĆÖs parameters when a request message arrives, then the result, send a reply message, and finally wait for the next call message. ŌĆó Only one process is enabled at a certain point in time. ŌĆó The caller is not always required to be blocked. ŌĆó The asynchronous mechanism could be employed in the RPC that permits the client to work even if the server has not responded yet. ŌĆó In order to handle incoming requests, the server might create a thread that frees the server for handling consequent requests.
- 36. Types of RPC ŌĆó Three types of RPC are: 1. Callback RPC 2. Broadcast RPC 3. Batch-mode RPC
- 37. 1. CALLBACK RPC ŌĆó A P2P (Peer-to-Peer)paradigm opts between participating processes. ŌĆó In this way, a process provides both client and server functions which are quite helpful. ŌĆó Callback RPCŌĆÖs features include: ŌĆó The problems encountered with interactive applications that are handled remotely. ŌĆó It provides a server for clients to use. ŌĆó Due to the callback mechanism, the client process is delayed. ŌĆó Deadlocks need to be managed in callbacks. ŌĆó It promotes a Peer-to-Peer (P2P) paradigm among the processes involved.
- 38. 2. BROADCAST RPC ŌĆó A clientŌĆÖs request that is broadcast all through the network and handled by all servers that possess the method for handling that request is known as a broadcast RPC. ŌĆó Broadcast RPCŌĆÖs features include: ŌĆó You have an option of selecting whether or not the clientŌĆÖs request message have to be broadcast. ŌĆó It also gives you the option of declaring broadcast ports. ŌĆó It helps in shrinking physical network load.
- 39. BATCH-MODE RPC ŌĆó Batch-mode RPC helps to queue, separate RPC requests, in a transmission buffer, on the client-side, and then send them on a network in one batch to the server. ŌĆó Batch-mode RPCŌĆÖs features include: ŌĆó It reduces the overhead of requesting the server by sending them all at once using the network. ŌĆó It is used for applications that require low call rates. ŌĆó It necessitates the use of a reliable transmission protocol.
- 40. ŌĆó Remote Procedure Calls have disjoint address space i.e. different address space, unlike Local Procedure Calls. ŌĆó Remote Procedure Calls are more prone to failures due to possible processor failure or communication issues of a network than Local Procedure Calls. ŌĆó Because of the communication network, remote procedure calls take longer than local procedure calls. Local Procedure Call Vs Remote Procedure Call
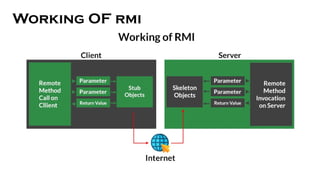
- 42. REMOTE METHOD INVOCATION ŌĆó The RMI (Remote Method Invocation) is an API that provides a mechanism to create distributed application in java. ŌĆó The RMI allows an object to invoke methods on an object running in another JVM. ŌĆó The RMI provides remote communication between the applications using two objects stub and skeleton.
- 43. stub ŌĆó The stub is an object, acts as a gateway for the client side. ŌĆó All the outgoing requests are routed through it. ŌĆó It resides at the client side and represents the remote object. ŌĆó When the caller invokes method on the stub object, it does the following tasks: 1. It initiates a connection with remote Virtual Machine (JVM), 2. It writes and transmits (marshals) the parameters to the remote Virtual Machine (JVM), 3. It waits for the result, 4. It reads (un-marshals) the return value or exception, and 5. It finally, returns the value to the caller.
- 44. SKELETON ŌĆó The skeleton is an object, acts as a gateway for the server side object. All the incoming requests are routed through it. ŌĆó When the skeleton receives the incoming request, it does the following tasks: 1. It reads the parameter for the remote method 2. It invokes the method on the actual remote object, and 3. It writes and transmits (marshals) the result to the caller.
- 45. Working OF rmi
- 46. The remote invocation process typically involves the following steps: 1.Client Program: The client program initiates the remote invocation. It contains the code that calls the remote procedure as if it were a local function call. 2.RPC Stub (Client Stub): The client program uses a local procedure called an RPC stub, or client stub. The stub is responsible for packaging the parameters of the procedure call into a message and sending it over the network to the remote server. 3.Network Communication: The message containing the procedure call information is transmitted over the network to the remote server. 4.Server Program: On the remote server, there is a corresponding server program that listens for incoming RPC requests.
- 47. 5.RPC Skeleton (Server Stub): The server program uses a local procedure called an RPC skeleton, or server stub. The skeleton unpacks the received message, extracts the procedure call details, and executes the procedure with the provided parameters. 6.Procedure Execution: The server executes the requested procedure using the provided parameters and generates a result. 7.Result Transmission: The server's result is sent back to the client over the network. 8.Client Processing: The client's RPC stub receives the result, extracts the returned value, and returns it to the client program, which continues its execution as if the remote procedure call had been a local function call.
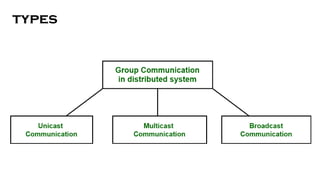
- 49. Group Communication ŌĆó Communication between two processes in a distributed system is required to exchange various data, such as code or a file, between the processes. ŌĆó When one source process tries to communicate with multiple processes at once, it is called Group Communication. ŌĆó A group is a collection of interconnected processes with abstraction. ŌĆó This abstraction is to hide the message passing so that the communication looks like a normal procedure call. ŌĆó Group communication also helps the processes from different hosts to work together and perform operations in a synchronized manner, therefore increases the overall performance of the system.
- 50. types
- 51. Unicast Communication ŌĆó When the host process tries to communicate with a single process in a distributed system at the same time. ŌĆó Although, same information may be passed to multiple processes. ŌĆó This works best for two processes communicating as only it has to treat a specific process only. ŌĆó However, it leads to overheads as it has to find exact process and then exchange information/data.
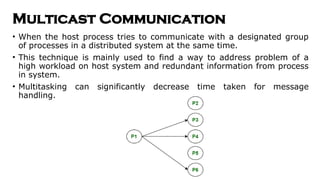
- 52. Multicast Communication ŌĆó When the host process tries to communicate with a designated group of processes in a distributed system at the same time. ŌĆó This technique is mainly used to find a way to address problem of a high workload on host system and redundant information from process in system. ŌĆó Multitasking can significantly decrease time taken for message handling.
- 53. Broadcast Communication ŌĆó When the host process tries to communicate with every process in a distributed system at same time. ŌĆó Broadcast communication comes in handy when a common stream of information is to be delivered to each and every process in most efficient manner possible. ŌĆó Since it does not require any processing whatsoever, communication is very fast in comparison to other modes of communication. ŌĆó However, it does not support a large number of processes and cannot treat a specific process individually.
- 54. Essential features ŌĆó Atomicity (all-or-nothing): when a message is sent to a group, it will either arrive correctly at all members of the group or at none of them. ŌĆó Ordering ŌĆó FIFO ordering: Messages originating from a given sender are delivered in the order they have been sent, to all members of the group. Px P4 P3 P2 P1 m4, m2, m3, m1 m2, m4, m1, m3 m2, m1, m4, m3 m4, m3, m2, m1 send m3; Py send m1; send m2; send m4;
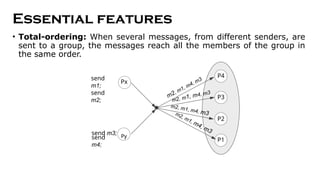
- 55. Essential features ŌĆó Total-ordering: When several messages, from different senders, are sent to a group, the messages reach all the members of the group in the same order. Px P4 P3 P2 P1 m2, m1, m4, m3 m2, m1, m4, m3 m2, m1, m4, m3 m2, m1, m4, m3 send m3; Py send m1; send m2; send m4;