









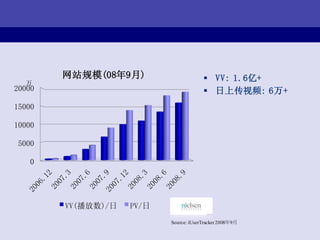



![ЧАЖЫПђМм
Browser : http://www..com/<module>/<method>/[params]
Front Framework:
hook(request)
{
module, method, params <-- request.url
response = module.php->method(params)
echo reponse
}
module1.php:
method1(params)
{
return ЁА<p>hello, world!</p>ЁБ
}](https://image.slidesharecdn.com/web-090918120623-phpapp01/85/Web-14-320.jpg)








































More Related Content
What's hot (15)
Similar to гХПс WebЭјеОМмЙЙАИР§ЗжЮі (20)













More from George Ang (20)




















гХПс WebЭјеОМмЙЙАИР§ЗжЮі
- 1. WebЭјеОМмЙЙАИР§ЗжЮі ДггХПсЭјЧГЬИДѓаЭЭјеОЕФМмЙЙКЭгХЛЏ ЧёЕЄ qiudan@gmail.com QCon 2009 ББОЉ
- 2. вщ ГЬ ? МмЙЙКЭЛЗОГ ? WebМмЙЙЕФ8ИіЬиад ? гХПсЭјАИР§ ? ЭјТчгХЛЏ
- 3. Part I МмЙЙКЭЛЗОГ ? ЪЪгІЬьЩЯЗЩЯшЃКФёгЕгаГсАђ ? ЪЪгІЫЎРяКєЮќЃКгугЕгаШњ
- 6. МмЙЙЕФНјЛЏКЭЭЫЛЏ ? НјЛЏдРэ - бАевзюЪЪКЯЕФ ? ЭЫЛЏдРэ - МђЛЏВЛБивЊЕФ
- 7. МмЙЙЪІЕФжАд№ ГѕЪМЛЗОГ while(true) { бАевЪЪгІЛЗОГЕФНсЙЙ; /*НјЛЏ*/ МђЛЏНсЙЙ; /*ЭЫЛЏ*/ ЛЗОГИФБф; }
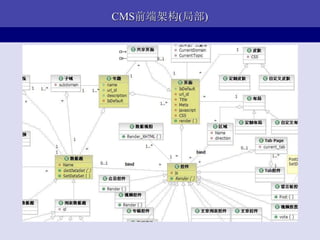
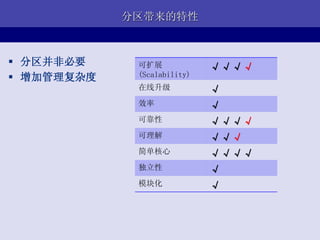
- 8. Part II WebЛЗОГЯТМмЙЙ8ИіЬиад ПЩРЉеЙ (Scalability) дкЯпЩ§МЖ аЇТЪ ПЩППад ПЩРэНт МђЕЅКЫаФ ЖРСЂад ФЃПщЛЏ
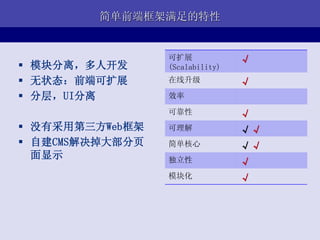
- 9. Part III ЭјеОМмЙЙАИР§ ЖдгкгХПсЭј(youku.com) - жаЙњДѓТНСьЯШЕФдкЯпЪгЦЕЭјеО
- 10. ЭјеОЙцФЃ(08Фъ9дТ) ? VV: 1.6вк+ Эђ 20000 ? ШеЩЯДЋЪгЦЕ: 6Эђ+ 15000 10000 5000 0 VV(ВЅЗХЪ§)/Ше PV/Ше Source: iUserTracker 2008Фъ9дТ
- 11. ЭјеОКЫаФвЕЮёДјРДЕФМмЙЙЬиад ПЩРЉеЙ (Scalability) дкЯпЩ§МЖ аЇТЪ ПЩППад ПЩРэНт ЁЬ МђЕЅКЫаФ ЁЬ ЖРСЂад ФЃПщЛЏ
- 12. ДДЪРМЭЃКЭјеОЕФГѕЪМЛЗОГ ? 2006ФъЯТАыФъ ? 500МвЪгЦЕЭјеОДцдкЃЌЕЋЙцФЃЖМВЛДѓ ? ВПЗжЛЅСЊЭјгУЛЇЙизЂ ? ОоДѓЕФгУЛЇЧБСІ
- 13. гЕБЇПЊдДЪРНч
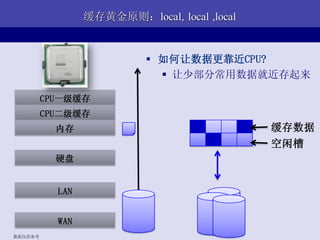
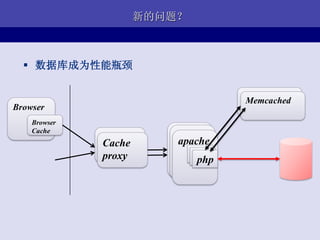
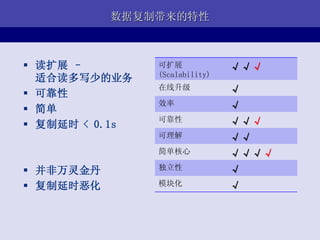
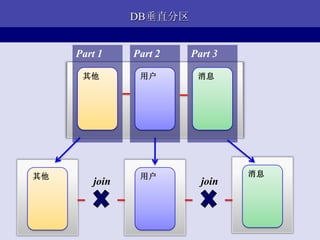
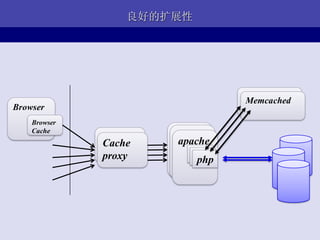
- 14. ЧАЖЫПђМм Browser : http://www..com/<module>/<method>/[params] Front Framework: hook(request) { module, method, params <-- request.url response = module.php->method(params) echo reponse } module1.php: method1(params) { return ЁА<p>hello, world!</p>ЁБ }
- 15. МђЕЅЧАЖЫПђМмТњзуЕФЬиад ПЩРЉеЙ ЁЬ ? ФЃПщЗжРыЃЌЖрШЫПЊЗЂ (Scalability) ? ЮозДЬЌЃКЧАЖЫПЩРЉеЙ дкЯпЩ§МЖ ЁЬ ? ЗжВуЃЌUIЗжРы аЇТЪ ПЩППад ЁЬ ? УЛгаВЩгУЕкШ§ЗНWebПђМм ПЩРэНт ЁЬЁЬ ? здНЈCMSНтОіЕєДѓВПЗжвГ МђЕЅКЫаФ ЁЬЁЬ УцЯдЪО ЖРСЂад ЁЬ ФЃПщЛЏ ЁЬ
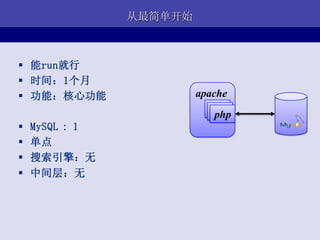
- 17. ДгзюМђЕЅПЊЪМ ? ФмrunОЭаа ? ЪБМфЃК1ИідТ ? ЙІФмЃККЫаФЙІФм apache php ? MySQL : 1 ? ЕЅЕу ? ЫбЫїв§ЧцЃКЮо ? жаМфВуЃКЮо
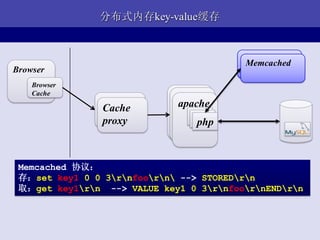
- 19. ЛКДцЛЦН№ддђЃКlocal, local ,local ? ШчКЮШУЪ§ОнИќППНќCPU? ? ШУЩйВПЗжГЃгУЪ§ОнОЭНќДцЦ№РД CPUвЛМЖЛКДц CPUЖўМЖЛКДц ФкДц ЛКДцЪ§Он ПеЯаВл гВХЬ LAN WAN Ъ§ОнНіЙЉВЮПМ
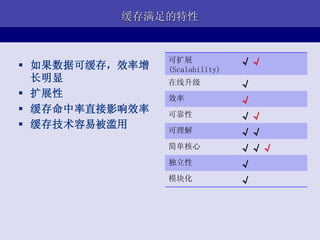
- 20. HTTPЛКДц ЈC Squid/Varnish Browser Browser Cache Cache apache apache HTTP apache proxy Reverse php php php Proxy HTTP Response: Cache-Control: max-age=3600, must-revalidate Expires: Fri, 28 Oct 2007 14:19:41 GMT Last-Modified: Mon, 27 Jun 2007 05:21:17 GMT
- 21. ЗжВМЪНФкДцАьБ№Вт-БЙВЙБєГмБ№ЛКДц Cache Memcached Browser proxy Browser Cache apache apache Cache Cache apache proxy php php proxy php Memcached авщЃК ДцЃКset key1 0 0 3rnfoorn --> STOREDrn ШЁЃКget key1rn --> VALUE key1 0 3rnfoornENDrn
- 22. ДѓЮФМўЛКДц(ФкВПЯюФП) ? SquidЮЪЬт ? write()ЃЌгУЛЇНјГЬПеМфЯћКФ ? lighttpd1.5/AIOЮЪЬт ? AIOЖСШЁЮФМўЕНгУЛЇФкДцЕМжТаЇТЪЕЭЯТ ? Sendfile() ? ZeroCopyжБНгЗЂЫЭЮФМўЕНЭјПЈНгПк ? ВЛгУФкДцзіЛКДц ? БмУтФкДцПНБД ? БмУтЫј
- 23. ЛКДцТњзуЕФЬиад ПЩРЉеЙ ЁЬЁЬ ? ШчЙћЪ§ОнПЩЛКДцЃЌаЇТЪді (Scalability) ГЄУїЯд дкЯпЩ§МЖ ЁЬ ? РЉеЙад аЇТЪ ЁЬ ? ЛКДцУќжаТЪжБНггАЯьаЇТЪ ПЩППад ЁЬЁЬ ? ЛКДцММЪѕШнвзБЛРФгУ ПЩРэНт ЁЬЁЬ МђЕЅКЫаФ ЁЬЁЬЁЬ ЖРСЂад ЁЬ ФЃПщЛЏ ЁЬ
- 24. аТЕФЮЪЬтЃП ? Ъ§ОнПтГЩЮЊадФмЦПОБ Cache Memcached Browser proxy Browser Cache Cache apache apache Cache apache proxy proxy php php php
- 25. РЉеЙжаМфВу or РЉеЙЪ§ОнПт VS
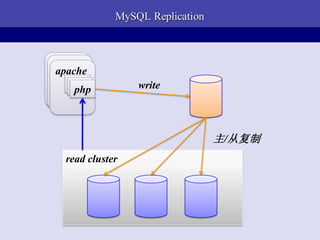
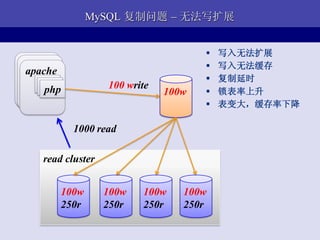
- 26. MySQL Replication apache apache apache php php write php жї/ДгИДжЦ read cluster
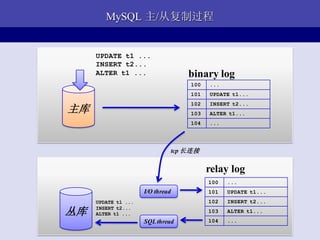
- 27. MySQL жї/ДгИДжЦЙ§ГЬ UPDATE t1 ... INSERT t2... ALTER t1 ... binary log 100 ... 101 UPDATE t1... 102 INSERT t2... жїПт 103 ALTER t1... 104 ... tcp ГЄСЌНг relay log 100 ... I/O thread 101 UPDATE t1... UPDATE t1 ... 102 INSERT t2... ДдПт INSERT t2... ALTER t1 ... 103 ALTER t1... SQL thread 104 ...
- 28. Ъ§ОнИДжЦДјРДЕФЬиад ? ЖСРЉеЙ ЈC ПЩРЉеЙ ЁЬЁЬЁЬ (Scalability) ЪЪКЯЖСЖраДЩйЕФвЕЮё дкЯпЩ§МЖ ЁЬ ? ПЩППад аЇТЪ ЁЬ ? МђЕЅ ПЩППад ЁЬЁЬЁЬ ? ИДжЦбгЪБ < 0.1s ПЩРэНт ЁЬЁЬ МђЕЅКЫаФ ЁЬЁЬЁЬЁЬ ? ВЂЗЧЭђСщН№ЕЄ ЖРСЂад ЁЬ ? ИДжЦбгЪБЖёЛЏ ФЃПщЛЏ ЁЬ
- 29. MySQL ИДжЦЮЪЬт ЈC ЮоЗЈаДРЉеЙ ? аДШыЮоЗЈРЉеЙ apache apache ? аДШыЮоЗЈЛКДц apache php ? ИДжЦбгЪБ php php 100 write 100w ? ЫјБэТЪЩЯЩ§ ? БэБфДѓЃЌЛКДцТЪЯТНЕ 1000 read read cluster 100w 100w 100w 100w 250r 250r 250r 250r
- 30. ЯждкИУШчКЮНјЛЏ? ? MySQL Proxy/HSCALE ? lighttpdЭЌвЛзїепЃЌНјЖШЪмЯоЁЃ luaжаМфВуЃЌадФм/ПЩЮЌЛЄад/ГЩЪьЖШЃП ? MySQL ЗжЧјММЪѕ ? ЮоЗЈНјааПчЗўЮёЦїЗжЧјЁЃ ? MySQLМЏШК(MySQL NDB Cluster) ? КёжиЕФШ№ЪПОќЕЖЃЌВуУцЙ§ЖрЃЌадФм/ИДдгЖШЃП ? УЛгавјЕЏЗНАИЁЃ ? ?
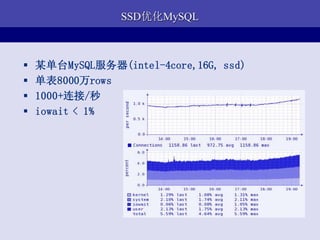
- 31. SSDгХЛЏMySQL ? ФГЕЅЬЈMySQLЗўЮёЦї(intel-4core,16G, ssd) ? ЕЅБэ8000Эђrows ? 1000+СЌНг/Уы ? iowait < 1%
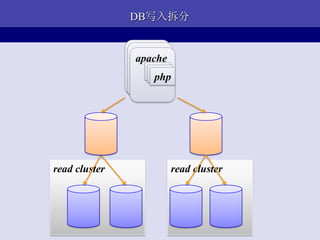
- 32. ЖйЕўаДШыВ№Зж apache apache apache php php php read cluster read cluster
- 33. ЖйЕўДЙжБЗжЧј Part 1 Part 2 Part 3 ЦфЫћ гУЛЇ ЯћЯЂ ЦфЫћ гУЛЇ ЯћЯЂ join join
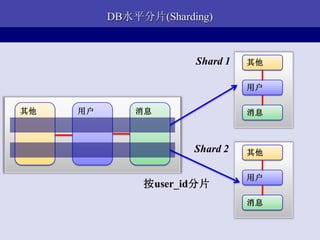
- 34. ЖйЕўЫЎЦНЗжЦЌ(ГЇГѓВЙАљЛхОБВдВЕ) Shard 1 ЦфЫћ гУЛЇ ЦфЫћ гУЛЇ ЯћЯЂ ЯћЯЂ Shard 2 ЦфЫћ гУЛЇ АДuser_idЗжЦЌ ЯћЯЂ
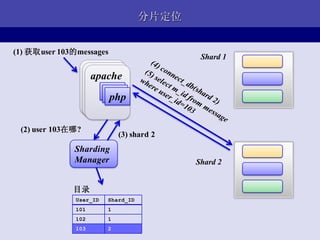
- 35. ЗжЦЌЖЈЮЛ (1) ЛёШЁuser 103ЕФmessages Shard 1 apache apache apache php php php (2) user 103дкФФ? (3) shard 2 Sharding Manager Shard 2 ФПТМ User_ID Shard_ID 101 1 102 1 103 2
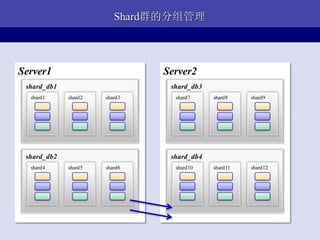
- 36. ShardШКЕФЗжзщЙмРэ Server1 Server2 shard_db1 shard_db3 shard1 shard2 shard3 shard7 shard8 shard9 shard_db2 shard_db4 shard4 shard5 shard6 shard10 shard11 shard12
- 37. ШчКЮДІРэПчshardЕФВщбЏ? ? ЩЯВпЃКВЛУцЖд ? жаВпЃКЖрЮЌЗжЦЌЫїв§ЁЂЗжВМЪНЫбЫїв§Чц ? ЯТВпЃКЗжВМЪНЪ§ОнПтВщбЏ
- 38. СМКУЕФРЉеЙад Cache Memcached Browser proxy Browser Cache Cache apache apache Cache apache proxy proxy php php php
- 39. ЗжЧјДјРДЕФЬиад ? ЗжЧјВЂЗЧБивЊ ПЩРЉеЙ ЁЬЁЬЁЬЁЬ ? діМгЙмРэИДдгЖШ (Scalability) дкЯпЩ§МЖ ЁЬ аЇТЪ ЁЬ ПЩППад ЁЬЁЬЁЬЁЬ ПЩРэНт ЁЬЁЬЁЬ МђЕЅКЫаФ ЁЬЁЬЁЬЁЬ ЖРСЂад ЁЬ ФЃПщЛЏ ЁЬ
- 40. Part IV ЭјТчЭЬЭТСПгХЛЏ ? ЭЬЭТСПЭЌЯьгІЫйЖШЕФВЛЭЌ ? НјГЬЧаЛЛПЊЯњ ? БЃГжЕБЧАcpuМФДцЦї(eax,ebx,esi,edi,...) ? ЛжИДаТНјГЬcpuМФДцЦї(eax,ebx,esi,edi,...) ? jmp new_eip ? fork/pthreadЮЪЬт ? ДѓСПНјГЬЧаЛЛПЊЯњ ? МФДцЦїдНЖраЇТЪдНЕЭ ? гУvmstatВщПДcs ? Apache preforkКЭMySQLЕФpthread ? ДѓСПНјГЬЧаЛЛПЊЯњЙ§Дѓ
- 41. ЪТМўЧ§ЖЏ ? select()ЮЪЬт ? 1024ЯожЦ ? ЮЛЩЈУш ? poll()ЮЪЬт ? ДгФкКЫЕНгУЛЇНјГЬПНБДУшЪіЗћЪ§зщ ? epoll(kernel 2.6+) ? ВЩгУmmap()БмУтФкКЫЕНгУЛЇНјГЬЕФПНБД ? libeventЗтзАepoll/kqueue ? epollЭЦЖЏЕБНёWeb ? memcached/lighttpd/nginx/squid/haproxy
- 42. АИР§ЃКMemcached СЌНгЮЪЬт ? PHPЖдmemcachedЕФtcpСЌ НгПЊЯњ ? ОВЬЌHashРЉеЙВЛЗНБу
- 43. БОЕиMemcached agent(ФкВПЯюФП) ? Лљгкlibevent(ЗтзАepoll) ? memcachedМцШнНгПк ? БОЕиunix domain socket ? ЖдMemcachedГЄСЌНг ? MemcachedЖЏЬЌШЮвтРЉеЙ(Consistent hashing) php php memcached unix domain socket agent memcached tcpСЌНгГи
- 44. Q&A
- 45. аЛаЛЃЁ