






















Frequency Pattern Mining
- 1. Frequency Pattern Mining Karubi Namuru Nov. 14, 2010
- 2. ūį╝║ĮBĮķ Ī± Karubi Namuru, Ph.D. Ī± Kauli ųĻ╩Į╗ß╔ń Ī± Twitter: @karubi Ī± Facebook: http://facebook.com/karubi Ī± │÷╔ĒŻ║Ä┌Źu , ŠėūĪŻ║¢|Š® , Seongnam
- 3. Frequency Pattern Mining Ī± Ņl│÷źčź┐®`ź¾ź▐źżź╦ź¾ź░ Ī± źŪ®`ź┐ż╬╝»║Žż½żķŻ¼│÷¼FŅlČ╚ż╬Ė▀żż╠žÅšĄ─ż╩źč ź┐®`ź¾ż“░kęŖż╣żļ Ī± Ī· ŲĄ│÷źčź┐®`ź¾ż╬│ķ│÷
- 4. ┤·▒ĒĄ─ż╩Ņl│÷źčź┐®`ź¾ź▐źżź╦ź¾ź░ Ī± ŽÓķvźļ®`źļ│ķ│÷ Ī± ż┐ż╚ż©żąŻ¼źŪ®`ź┐ź┘®`ź╣ż╦ąŅĘeżĘż┐┤¾┴┐ż╬źŪ®`ź┐ż½ żķŻ¼ŅlĘ▒ż╦Ż¼ż½ż─Ż¼═¼Ģrż╦Ż¼░k╔·ż╣żļ╩┬Ž¾ż“ęŖż─ż▒ żļż│ż╚Ż« Ī± ═¼Ģrż╦░k╔·ż╣żļ╩┬Ž¾ż“Ż¼ŽÓķvż╬ÅŖżżķvéSż╚żĘżŲźļ®` ź╚ż╚żĘżŲ│ķ│÷ Ī± źąź╣ź▒ź├ź╚Ęų╬÷ ©C POS źŪ®`ź┐żõ EC ż╩ż╔żŪ╚ĪĄ├żŪżŁżļź╚źķź¾źČź»źĘźńź¾ż½ żķ┘Å┘I┬─Üsż“Ęų╬÷
- 5. źąź╣ź▒ź├ź╚Ęų╬÷ Ī± ┘Å┘I┬─Üsż½żķĪĖę╗Šwż╦┘Iż’żņżļ╔╠ŲĘĪ╣ż╚żżż”╠žÅšĄ─ż╩ źčź┐®`ź¾ż“░kęŖż╣żļ Ī± üŃēė╔╠ŲĘż╬░kęŖ ©C źŪźĖź┐źļź½źßźķż╚ę║Š¦ż“▒Żūoż╣żļż┐żßż╬źĘ®`ź╚ ż“┘Å╚ļż╣żļŅÖ┐═żŽŻ¼źßźŌźĻź½®`ź╔żŌę╗Šwż╦┘Iż” Ī± ╔╠ŲĘĻÉ┴ąźņźżźóź”ź╚ ©C ż¬żÓż─ż“┘Iż”ŅÖ┐═żŽ═¼Ģrż╦źė®`źļżŌ┘Iż”ż╩żķüI ĘĮż╬╔╠▓─ż“Į³ż»ż╦ĻÉ┴ążĘżŲż¬ż»
- 7. ╗∙▒Šż╬╩ųĒś Ī± ╚½źóźżźŲźÓż½żķ╚½żŲż╬źļ®`źļż“Ž┤żż│÷ż╣ Ī± ╚½źóźżźŲźÓż½żķŻļéĆż“▀xżų Ī± ż│ż╬╚½═©żĻż╦ż─żżżŲŻ¼ęŌ╬Čż╬żóżļźļ®`źļż“ęŖż─ż▒żļ Ī± ż│ż╬źóźżźŲźÓż╬Ė„Ī®ż¼Ū░╠ßż╦ż»żļż½Ż¼ĮYšōż╦ż»żļż½ żŪĘųż▒ĘĮż¼ēõż’żļ Ī± ╚½źóźżźŲźÓż¼Ū░╠ßż╦╝»ż▐żļł÷║Žż╚Ż¼╚½źóźżźŲźÓż¼ĮY šōż╦╝»ż▐żļł÷║ŽżŽźļ®`źļż╦ż╩żķż╩żżż╬żŪ┼┼│²ż╣żļ
- 8. īgļHż╬ėŗ╦ŃĘĮĘ© Ī± m ĘNŅÉż╬źóźżźŲźÓż╦ż¬żżżŲ┤µį┌ż╣żļźļ®`źļż╬╩² Ī± ż┐ż╚ż©żą 10 ĘNŅÉż╬ł÷║ŽŻ¼źļ®`źļż╬Št╩²Ż║ 57000 ╚§ Ī± ü²éÄż╬żóżļźļ®`źļż╬╩²Ż║ż’ż║ż½ż╩╩² ĪŲ k=2 m ½ßa b½Ō½ß2 m ?2½Ō
- 9. źóźūźĻź¬źĻźóźļź┤źĻź║źÓ Ī± ┤_ą┼Č╚Ż¼źĄź▌®`ź╚ż╚żżż” 2 ż─ż╬ųĖś╦ż“ī¦╚ļż╣żļ Ī± żĮżņżŠżņŻ¼ūŅąĪ┤_ą┼Č╚ż╚Ż¼ūŅąĪźĄź▌®`ź╚ż╬żšż┐ż─ż“ėļż©żļ Ī± ┤_ą┼Č╚Ż¼źĄź▌®`ź╚ż╚żŌūŅąĪżĶżĻ┤¾żŁżżźļ®`źļż“░kęŖż╣żļĘĮĘ©
- 10. FPGrowth źóźļź┤źĻź║źÓ Ī± źóźūźĻź¬źĻźóźļź┤źĻź║źÓż╬ä┐┬╩ż“Ė─╔Ųż╣żļźóźļź┤źĻź║źÓ Ī± źóźūźĻź¬źĻźóźļź┤źĻź║źÓżŽŅl│÷źóźżźŲźÓź╗ź├ź╚ż“│ķ│÷ż╣żļ▒žę¬ ż¼żóż├ż┐ż¼Ż¼ FPGrowth żŽ FP-Tree ż╚żżż”─Šśŗįņż╦ź╚źķź¾źČ ź»źĘźńź¾ż“łR┐sżĘżŲŻ¼ FP-Tree ż½żķŅl│÷źóźżźŲźÓź╗ź├ź╚ż“│ķ│÷ ż╣żļŻ« Ī± FP-Growth żŽ║“čaźčź┐®`ź¾ż“╔·│╔żĘż╩żżż┐żßŻ¼źŪ®`ź┐ź╗ź├ź╚ ż╬ź╣źŁźŃź¾╗ž╩²ż“ęųż©żļż│ż╚ż¼żŪżŁżļŻ«ż─ż▐żĻŻ¼źóźūźĻź¬źĻżĶ żĻĖ▀╦┘ż╦Ņl│÷źóźżźŲźÓź╗ź├ź╚ż“│ķ│÷ż╣żļż│ż╚ż¼żŪżŁżļŻ«
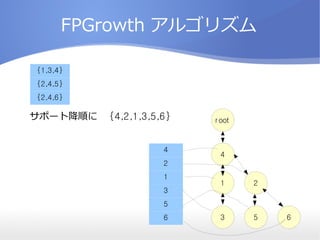
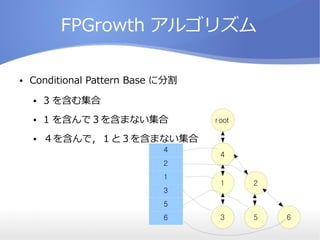
- 12. FPGrowth źóźļź┤źĻź║źÓ Ī± Conditional Pattern Base ż╦ĘųĖŅ Ī± 3 ż“║¼żÓ╝»║Ž Ī± 1 ż“║¼ż¾żŪŻ│ż“║¼ż▐ż╩żż╝»║Ž Ī± Ż┤ż“║¼ż¾żŪŻ¼Ż▒ż╚Ż│ż“║¼ż▐ż╩żż╝»║Ž 4 2 1 3 5 6 root 4 1 3 2 5 6
- 14. FPGrowth ż“äėż½ż╣ Ī± Mahout ż“äėż»ŁhŠ│ż“ż─ż»żļ Ī± Linux ż╬ł÷║Ž ©C Virtual Macine ż“ż─ż»żļŻ¼ż┐ż╚ż©żą CentOS ©C Java ż╬źżź¾ź╣ź╚®`źļŻ¼ż┐ż╚ż©żą OpenJDK ©C ŁhŠ│ēõ╩²ż“įOČ© ©C Mahout ż“ź└ź”ź¾źĒ®`ź╔żĘżŲŻ¼▀mĄ▒ż╩źŪźŻźņź»ź╚źĻż╦ų├ ż» ©C ŁhŠ│ēõ╩²ż“įOČ©
- 15. źŪ®`ź┐ź╗ź├ź╚ Ī± ź═ź├ź╚╔Žż╬¤o┴Žż╬┘Yį┤ż“└¹ė├ż╣żļ Ī± 覹gżŪ╩╣ż”żŌż╬ ©C ż└żżż┐żżźŪ®`ź┐ż╬ųą╔Ēż¼żĶż»ż’ż½żķż╩żż ©C ż╔ż”żżż”╩┬Ž¾ż“ėøÕhżĘż┐ż½ż╬ż▀šh├„ ©C éĆĪ®ż╬éÄż╦ż─żżżŲżŽŻ¼│ķŽ¾╗»żĄżņżŲż’ż½żķż╩żżŻ«Ż«Ż« Ī± ęŖżŲż’ż½żĻżõż╣żżźŪ®`ź┐ ©C MovieLens
- 16. ź═ź├ź╚╔Žż╬Ūķł¾į┤ Ī± ╣½ķ_żĄżņżŲżżżļ├„╩ŠĄ─ż╩Ūķł¾į┤Ż©ę╗▓┐Ż® Ī± The Netflix prize datasets ©C Netflix Ż║źóźßźĻź½ż╬ź¬ź¾źķźżź¾ DVD źņź¾ź┐źļźĄ®`źėź╣ ©C 1 ā|źņź│®`ź╔ęį╔Ž ©C 480,189 ╚╦ż¼ 17,770 ź┐źżź╚źļż╦ż─żżżŲįuü² Ī± Grouplens Research ©C ź▀ź═źĮź┐┤¾ż╬蹊┐ź┴®`źÓŻ¼ MovieLens źūźĒźĖź¦ź»ź╚ ©C 10 ═“Ż¼ 100 ═“Ż¼ 1000 ═“źņź│®`ź╔ż╬ 3 ż─ż╬źŪ®`ź┐ ©C 71,567 ╚╦ż¼ 10,681 ź┐źżź╚źļż╦ż─żżżŲįuü²Ż© 1000 ═“Ż®
- 18. Ī±
- 19. äI└Ē£gż▀źŪ®`ź┐ż╬─┌╚▌ Ī± źŪ®`ź┐ą╬╩Į Ī± Ż▒ąą─┐ Ī± 122,185,231,292,316,329,355,356,362,364,370,377 ,420,466,480,520,539,586,588,589,594,616 Ī± Ī· 1 ąą─┐ż╬źµ®`źČŻ║źµź╦®`ź» ID ĪĖŻ▒Ī╣Ę¼ż╬╚╦ Ī± Ī· 122,185,231,.... Ż║Ė▀żżįuü²ż“ėļż©ż┐ė│╗Ł
- 20. └²ż╬źµ®`źČ Ī± 122: Boomerang (1992), Comedy|Romance Ī± 185: Net, The (1995), Action|Crime|Thriller Ī± 231: Dumb & Dumber (1994), Comedy Ī± 292: Outbreak (1995), Action|Drama|Sci-Fi| Thriller Ī± 316: Stargate (1994), Action|Adventure|Sci-Fi Ī± 329: Star Trek: Generations (1994), Action| Adventure|Drama|Sci-Fi
- 21. Mahout FPGrowth Ī± ź│ź▐ź¾ź╔źķźżź¾żŪäėż½ż╗żļ 1.Mahout ż“ź└ź”ź¾źĒ®`ź╔żĘż┐źŪźŻźņź»ź╚źĻż╦ęŲäė 2.Bin źŪźŻźņź»ź╚źĻż╬ųąż╦ mahout źąźżź╩źĻż¼żóżļ 3.ź│ź▐ź¾ź╔ż“┤“ż─ ©C ./mahout fpg -i /home/you/dir/data.dat -o patterns -k 50 -method mapreduce Ī² ż└żżż┐żżż╬ęŌ╬Č ./mahout (FPGrowth ż“äėż½ż╣ ) -i ( ĮŌ╬÷īØŽ¾źšźĪźżźļż╬ ł÷╦∙ ) -o ( │÷┴”ż“ėøÕhż╣żļł÷╦∙Ż® -k Ż© TopK Ż® -method Ż© Hadoop MapReduce żŪäėż½ż╣Ż®
- 22. ėŗ╦Ńųąż╬╗Ł├µ Ī±
- 23. ĮY╣¹ż“ęŖżļĘĮĘ© Ī± ź└ź¾źč®`ż“└¹ė├ż╣żļ ./mahout seqdumper ©CseqFile patterns/fpgrowth/part-r-00000
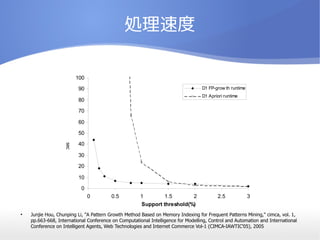
- 24. äI└Ē╦┘Č╚ Ī± Junjie Hou, Chunping Li, "A Pattern Growth Method Based on Memory Indexing for Frequent Patterns Mining," cimca, vol. 1, pp.663-668, International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce Vol-1 (CIMCA-IAWTIC'05), 2005 0 10 20 30 40 50 60 70 80 90 100 0 0.5 1 1.5 2 2.5 3 Support threshold(%) Run time(sec.) D1 FP-grow th runtime D1 Apriori runtime sec
- 26. Ī± Thank you