





![One Hot Encoded
bear = [1,0,0] cat = [0,1,0] frog = [0,0,1]
What is bear ^ cat?
Too may dimensions.
Data structure is sparse.
This is also called discrete or local representation
Ref : Constructing and Evaluating Word Embeddings - Marek Rei](https://image.slidesharecdn.com/wordvectors-180205071159/85/Word-vectors-8-320.jpg)

![What if we decide on dimensions?
bear = [0.9,0.85] cat = [0.85, 0.15]
What is bear ^ cat?
How many dimensions?
How do we know the dimensions for our vocabulary?
This is known as distributed representation.
Is it theoretically possible to come up with
limited set of features to exhaustively cover the
meaning space?
Ref : Constructing and Evaluating Word Embeddings - Marek Rei](https://image.slidesharecdn.com/wordvectors-180205071159/85/Word-vectors-10-320.jpg)





![Fill in the blanks
• I ________ at my desk
[read/study/sit]
• A _______ climbing a tree
[cat/bird/snake/man] [table/egg/car]
• ________ is the capital of ________.
Model context | word pair as [feature | label] pair and feed it to the
neural network.](https://image.slidesharecdn.com/wordvectors-180205071159/85/Word-vectors-17-320.jpg)




























![Outline of the approach
Text pre-processing
• Replace newline/ tabs/ multiple spaces
• Remove punctuations (brackets, comma, semicolon, slash)
• Sentence tokenizer [Spacy]
• Join back sentences separated by newline
Text processing outputs text document containing a sentence on a line.
This structure ignores paragraph placement.
Load pre-trained word vectors.
• This is trained on the corpus if it's sufficiently large ~ 5000+ documents or
5000000+ tokens
• Or use open source model like Google News word2vec](https://image.slidesharecdn.com/wordvectors-180205071159/85/Word-vectors-46-320.jpg)
![Outline of the approach
Document vector calculation
• Tokenize sentences into terms.
• Filter terms
• Remove terms occurring in less than <20> documents
• Remove terms occurring in more than <85%> of the documents
• Calculate counts of all terms
For each word (term) of the document…………………[1]
• not a stop word
• Has vector associated
• Has survived count calculation
• If term satisfies criteria 1, get vector for the term from pretrained model………………..[2]
• Calculate weight of the term as log of count of the term frequency in the document. …..[3]
• Weighted vector = weight * vector
• Finally, document vector = sum of all weighted term vectors / no of terms](https://image.slidesharecdn.com/wordvectors-180205071159/85/Word-vectors-47-320.jpg)
































More Related Content
Similar to Word vectors (20)
Recently uploaded (20)


















Word vectors
- 1. Word 2 Vec And other adventures July 12, 2017 A conceptual introduction and practical applications
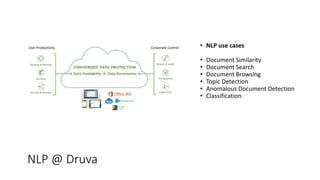
- 2. NLP @ Druva • NLP use cases • Document Similarity • Document Search • Document Browsing • Topic Detection • Anomalous Document Detection • Classification
- 3. Document Similarity Hurricane Gilbert swept toward the Dominican Republic Sunday , and the Civil Defence alerted its heavily populated south coast to prepare for high winds, heavy rains and high seas. The storm was approaching from the southeast with sustained winds of 75 mph gusting to 92 mph . “There is no need for alarm," Civil Defence Director Eugenio Cabral said in a television alert shortly before midnight Saturday . Cabral said residents of the province of Barahona should closely follow Gilbert 's movement . An estimated 100,000 people live in the province, including 70,000 in the city of Barahona , about 125 miles west of Santo Domingo . Tropical Storm Gilbert formed in the eastern Caribbean and strengthened into a hurricane Saturday night The National Hurricane Centre in Miami reported its position at 2a.m. Sunday at latitude 16.1 north , longitude 67.5 west, about 140 miles south of Ponce, Puerto Rico, and 200 miles southeast of Santo Domingo. The National Weather Service in San Juan , Puerto Rico , said Gilbert was moving westward at 15 mph with a "broad area of cloudiness and heavy weather" rotating around the centre of the storm. The weather service issued a flash flood watch for Puerto Rico and the Virgin Islands until at least 6p.m. Sunday. Strong winds associated with the Gilbert brought coastal flooding , strong southeast winds and up to 12 feet to Puerto Rico 's south coast. Ref: A text from DUC 2002 on “Hurricane Gilbert” 24 sentences
- 4. How to measure similarity? Document 1 • Gilbert: 3 • Hurricane: 2 • Rains: 1 • Storm: 2 • Winds: 2 Document 2 • Gilbert: 2 • Hurricane: 1 • Rains: 0 • Storm: 1 • Winds: 2 • To measure similarity of documents, we need some number. • To understand document similarity, we need to understand sentences and words. How similar are my words? How are they related? Sent1 : The problem likely will mean corrective changes before the shuttle fleet starts flying again. Sent2 : The issue needs to be solved before the spacecraft fleet is cleared to shoot again. Ref. Microsoft research corpus
- 5. Words can be similar or related in many ways… • They mean the same thing (synonyms) • They mean the opposite (antonyms) • They are used in the same way (red, green) • They are used in the same context (doctor, hospital, scalpel) • They are of same type (cat, dog -> mammal) • They occur in different times(swim, swimming)
- 6. How to measure the word similarity? • We need a number, preferably between (0,1) • We need to represent words in some numerical format as well. • We need word representation for computers to manipulate the representation in meaningful way. • Scaler or vector? Vector is better so that it can capture multiple levels dimension of similarity.
- 7. Representing words as vectors • Limitation on understanding meaning of the word (neurophysiological).Can we instead, have a computational model that is consistent with usage? • Let’s represent words as vectors. • We want to construct them so that similar words have similar vectors. • Similarity-is-Proximity : two similar things can be conceptualized as being near each other • Entities-are-Locations : in order for two things to be close to each other, they need to have a spatial location
- 8. One Hot Encoded bear = [1,0,0] cat = [0,1,0] frog = [0,0,1] What is bear ^ cat? Too may dimensions. Data structure is sparse. This is also called discrete or local representation Ref : Constructing and Evaluating Word Embeddings - Marek Rei
- 9. Hot Problems with One Hot… • Dimensions of vectors scales with size of vocabulary • Must pre-determine vocabulary size. • Cannot scale to large or infinite vocabularies (Zipf’s law!) • ‘Out-of-Vocabulary’ (OOV) problem. How would you handle unseen words in the test set? • No relationship between words.
- 10. What if we decide on dimensions? bear = [0.9,0.85] cat = [0.85, 0.15] What is bear ^ cat? How many dimensions? How do we know the dimensions for our vocabulary? This is known as distributed representation. Is it theoretically possible to come up with limited set of features to exhaustively cover the meaning space? Ref : Constructing and Evaluating Word Embeddings - Marek Rei
- 11. Measure of similarity cos(bear, cat) = 0.15 cos(bear, lion) = 0.9 We can infer some information, based only on the vector of the word. We don’t even need to know the labels on the vector elements. Ref : Constructing and Evaluating Word Embeddings - Marek Rei
- 12. Vector Space Creates a n-dimensional space. Represent each word in as a point in space, where it is represented by a vector of fixed number of dimensions (generally 100-500 dimensions). Information about a particular feature distributed among a set of (not necessarily mutually exclusive) dimensions. All the words with a very with some relation will be near to each other. Word vectors in distributed form are • Dense • Compressed (low dimension) • Smooth (discrete to continuous) Ref : Constructing and Evaluating Word Embeddings - Marek Rei
- 13. Story so far… • Document similarity is one of the fundamental task of NLP. • To infer document similarity, we need to express word similarity in numerical terms. • Words are similar in many ‘senses’ (loose definition). • Mapping words in common space (embedding) looks like possible solution to understand semantic relationships of the words. Often referred to as “word embeddings”, as we are embedding the words into a real-valued low-dimensional space
- 14. Obstacles? • It is almost impossible to come up with possible ‘meaning’ dimensions. • For our setup, we cannot make assumption about corpus. • When we don’t know the dimensions explicitly, can we still learn the word vectors? • We have large text collections, but very less labelled data. Ref : http://www.changingmindsonline.com/wp-content/uploads/2014/12/roadblock.jpg
- 15. Neural Nets Ref: https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-core-concepts/
- 16. Neural Nets for word vectors • Neural networks will automatically discover useful features in the data, given a specific task. • Let’s allocate a number of parameters for each word and allow the neural network to automatically learn what the useful values should be. • But neural nets are supervised. How do we discover a pair of feature and label?
- 17. Fill in the blanks • I ________ at my desk [read/study/sit] • A _______ climbing a tree [cat/bird/snake/man] [table/egg/car] • ________ is the capital of ________. Model context | word pair as [feature | label] pair and feed it to the neural network.
- 18. Any theoretical confirmation? “You shall know a word by the company it keeps” In simple words: Co-occurrence is a good indicator of meaning. Even simpler: Two words are considered close if they occur in similar context. Context is the surrounding words. (bug, insect) -> crawl, squash, small, wild, forest (doctor, surgeon) -> operate, scalpel, medicine the idea that children can figure out how to use words they've rarely encountered before by generalizing about their use from distributions of similar words. John Rupert Firth (1957) https://en.wikipedia.org/wiki/John_Rupert_Firth
- 19. Multiple contexts… 1. Can you cook some ________ for me? 2. _______ is so delicious. 3. _______ is not as healthy as fresh vegetables. 4. _______ was recently banned for some period of time. 5. _______ , Nestle brand is very popular with kids. Ref: https://www.ourncr.com/blog/wp-content/uploads/2016/06/top-maggi-points-in-delhi.jpg
- 20. Word2Vec • Simple neural nets can be used to obtain distributed representations of words (Hinton et al, 1986; Elman, 1991;) • The resulting representations have interesting structure – vectors can be obtained using shallow network (Mikolov, 2007) • Two target words are close and semantically related if they have many common strongly co-occurring words. • Efficient Estimation of Word Representations in Vector Space (Mikolov, Chen, Corrado and Dean,2013) • A popular tool for creating word embeddings. Available from Google https://code.google.com/archive/p/word2vec/
- 21. Demo time • word similarity • word analogy • odd man out problem • You can try it out online http://bionlp-www.utu.fi/wv_demo/ • Found anything interesting?
- 22. Some words to try out! Efficient Estimation of Word Representations in Vector Space (Mikolov, Chen, Corrado and Dean,2013)
- 23. Visualization of words in vector space https://www.tensorflow.org/images/linear-relationships.png
- 24. About this talk This is meant to be a short (2-3 hours), overview/summary style talk on word2vec. I have tried to make it interesting by demo and real world applications. Full reference list at the end. Comments/suggestions welcome: adwaitbhave@gmail.com ∫›∫›fl£s and Full Code: https://github.com/yantraguru/word2vec_talk
- 25. Demystifying the algorithm • How does a vector look? • How does the underlying networks look? • What are the vector properties? • What are the limitations on the learning? • What pre-processing is required? • How we can control or tune the vectors?
- 26. More on word2vec word2vec is not a single algorithm. It is a software package containing: Two distinct models • CBoW • Skip-Gram Various training methods • Negative sampling • Hierarchical softmax A rich processing pipeline • Dynamic Context Windows • Subsampling • Deleting Rare Words Plus bunch of tricks: weighting of distant words, down-sampling of frequent words…
- 28. Skip-gram model Predict the surrounding words, based on the current word “the dog saw a cat”, “the dog chased the cat”, “the cat climbed a tree” What are the context words? the dog chased the cat the dog chased the cat …. Efficient Estimation of Word Representations in Vector Space (Mikolov, Chen, Corrado and Dean,2013)
- 29. Continuous Bag-of-Words (CBOW) model Predict the current word, based on the surrounding words “the dog saw a cat”, “the dog chased the cat”, “the cat climbed a tree” What are the context words? the dog saw a cat Efficient Estimation of Word Representations in Vector Space (Mikolov, Chen, Corrado and Dean,2013)
- 30. Architecture
- 31. Word2vec network • Lets assume we have 3 sentences. “the dog saw a cat”, “the dog chased the cat”, “the cat climbed a tree” • 8 words. • Input and output is one hot encoded. • Weight matrices learnt by backpropagation Efficient Estimation of Word Representations in Vector Space (Mikolov, Chen, Corrado and Dean,2013)
- 32. Dynamic Context Windows Marco saw a furry little dog hiding in the tree. word2vec: 1 4 2 4 3 4 4 4 4 4 3 4 2 4 1 4 32 The probabilities that each specific context word will be included in the training data.
- 33. Negative Sampling • we are instead going to randomly select just a small number of “negative” words (let’s say 5) to update the weights for. (In this context, a “negative” word is one for which we want the network to output a 0 for). • Essentially, the probability for selecting a word as a negative sample is related to its frequency, with more frequent words being more likely to be selected as negative samples.
- 34. Subsampling and Delete Rare Words • There are two “problems” with common words like “the”: For each word we encounter in our training text, there is a chance that we will effectively delete it from the text. The probability that we cut the word is related to the word’s frequency. • Ignore words that are rare in the training corpus • Remove these tokens from the corpus before creating context windows
- 35. Word2vec Parameters • skip-gram or CBOW • window size (m) • number of dimensions • number of epochs • negative sampling or hierarchical softmax • negative samples (k) • sampling distribution for negative samples(s) • subsampling frequency
- 36. Demo and Code walkthrough • Create word embeddings from corpus • Examine the word similarities and other tasks
- 37. Word2Vec Key Ideas • Achieve better performance not by using a more complex model(i.e. with more layers), but by allowing a simpler (shallower) model to be trained on much larger amounts of data. • Meaning of new word can also be acquired just through reading (Miller and Charles, 1991) • Use neural network and hidden layer of neural network is a feature detector • Simple objective • Few linguistic assumptions • Implementation works without building / storing the actual matrix in memory. • is very fast to train, can use multiple threads. • can easily scale to huge data and very large word and context vocabularies.
- 38. DIY word2vec • Word2vec: https://code.google.com/p/word2vec/ • Gensim Python Library: • https://radimrehurek.com/gensim/index.html • Gensim Tutorials: • https://radimrehurek.com/gensim/tutorial.html • scikit-Learn TSNE: • http://scikit-learn.org/stable/modules/generated/ • sklearn.manifold.TSNE.html
- 39. Word2Vec Unanswered • How do you generate vectors for unknown words? (Out-of-vocabulary problem) • How do you generate vectors for infrequent words? • Non-uniform results • Hard to understand and visualize (as word dimensions are derived by using deep learning techniques)
- 40. Word2vec beats many algos
- 41. Competition and State of the art… • Pennington, Socher, and Manning (2014) GloVe: Global Vectors for Word Representation • Word embeddings can be composed from characters • Generate embeddings for unknown words • Similar spellings share similar embeddings • Kim, Jernite, Sontag, and Rush (2015) Character-Aware Neural Language Models • Dos Santos and Zadrozny (2014) Learning Character-level Representations for Part-of-Speech Tagging
- 42. More about word2vec • Word embeddings are one of the most exciting area of research in deep learning. • They provide a fresh perspective to ALL problems in NLP, and not just solve one problem. • much faster and way more accurate than previous neural net based solutions - speed up of training compared to prior state of art (from weeks to seconds) • Features derived from word2vec are used across all big IT companies in plenty of applications. • Very popular also in research community: simple way how to boost performance in many NLP tasks • Main reasons of success: very fast, open-source, easy to use the resulting features to boost many applications (even non-NLP) • Word2vec is successful because it is simple, but it cannot be applied everywhere
- 43. Pre-trained Vectors • Word2vec is often used for pretraining. It will help your models start from an informed position. Requires only plain text which we have a lot. • Already pretrained vectors also available (trained on 100B words) • However, for best performance it is important to continue training (fine-tuning). • Raw word2vec vectors are good for predicting the surrounding words, but not necessarily for your specific task. • Simply treat the embeddings the same as other parameters in your model and keep updating them during training. • Google News dataset (~100 billion words) • A common web platform with multiple datasets : http://www.wordvectors.org
- 44. Back to original Problem… • How to find document vector? • Summing it up? • BOW – Bag of words? • Clustering • Recurrent Networks • Convolutional Networks • Tree-Structured Networks • paragraph2Vec (2015)
- 45. Common sense approach • Demo 1 : Stack overflow questions clustering using word2vec • Demo 2 : Document clustering using pretrained word vectors. • Code Walkthrough
- 46. Outline of the approach Text pre-processing • Replace newline/ tabs/ multiple spaces • Remove punctuations (brackets, comma, semicolon, slash) • Sentence tokenizer [Spacy] • Join back sentences separated by newline Text processing outputs text document containing a sentence on a line. This structure ignores paragraph placement. Load pre-trained word vectors. • This is trained on the corpus if it's sufficiently large ~ 5000+ documents or 5000000+ tokens • Or use open source model like Google News word2vec
- 47. Outline of the approach Document vector calculation • Tokenize sentences into terms. • Filter terms • Remove terms occurring in less than <20> documents • Remove terms occurring in more than <85%> of the documents • Calculate counts of all terms For each word (term) of the document…………………[1] • not a stop word • Has vector associated • Has survived count calculation • If term satisfies criteria 1, get vector for the term from pretrained model………………..[2] • Calculate weight of the term as log of count of the term frequency in the document. …..[3] • Weighted vector = weight * vector • Finally, document vector = sum of all weighted term vectors / no of terms
- 48. Document Clusters Document Similarity : Cosine distance of document vectors Document Search : Query vector vs document vectors Document Browsing : Using semantic clusters Topic Detection : Cluster signifies a topic. Anomalous Document Detection: based on inter cluster distance. Classification : Supervised training based on document vectors
- 49. References • Mikolov (2012): Statistical Language Models Based on Neural Networks • Mikolov, Yih, Zweig (2013): Linguistic Regularities in Continuous Space Word Representations • Mikolov, Chen, Corrado, Dean (2013): Efficient estimation of word representations in vector space • Mikolov, Sutskever, Chen, Corrado, Dean (2013): Distributed representations of words and phrases and their compositionality • Baroni, Dinu, Kruszewski (2014): Don't count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors • Pennington, Socher, Manning (2014): Glove: Global Vectors for Word Representation • Levy, Goldberg, Dagan (2015): Improving distributional similarity with lessons learned from word embeddings
- 50. Thank You!
Editor's Notes
- #5: Possible measures of similarity might take into consideration: (a) The lengths of the documents (b) The number of terms in common (c) Whether the terms are common or unusual (d) How many times each term appears
- #16: Each layer can apply any function you want to the previous layer to produce an output (usually a linear transformation followed by a squashing nonlinearity). The hidden layer's job is to transform the inputs into something that the output layer can use. The output layer transforms the hidden layer activations into whatever scale you wanted your output to be on.
- #19: Firth‚Äôs Distributional Hypothesis is the basis forÃ˝statistical semantics. Although the Distributional Hypothesis originated in linguistics,Ã˝it is now receiving attention inÃ˝cognitive scienceÃ˝especially regarding the context of word use. In recent years, the distributional hypothesis has provided the basis for the theory ofÃ˝similarity-based generalizationÃ˝in language learning: