CAT development
4 likes1,425 views

Computerized Adaptive Testing (CAT) adalah metode pengujian yang disesuaikan dengan kemampuan peserta, di mana soal yang diberikan dipilih oleh komputer berdasarkan respon sebelumnya. Keunggulan CAT termasuk presisi skor yang lebih tinggi, efisiensi, dan hasil yang cepat, tetapi memerlukan bank soal yang terkalibrasi dan valid. Pengembangan CAT melibatkan pembuatan bank soal, perangkat lunak, dan perangkat keras, serta riset untuk memastikan validitas dan efektivitas tes.







































































































CAT development
- 1. COMPUTERIZED ADAPTIVE TESTING DISAMPAIKAN OLEH: JAHJA UMAR, Ph.D
- 2. APA ITU CAT? ï PENG-ADMINISTRASI-AN TES DENGAN KOMPUTER, DI MANA SOAL YANG DIBERIKAN DISESUAIKAN DENGAN TINGKAT KEMAMPUAN/ TRAIT DARI ORANG YANG DI TES ï SOAL YANG SESUAI DIPILIH DAN DISAJIKAN OLEH KOMPUTER ï KOMPUTER MENCATAT JAWABAN (RESPONSE) YANG DIBERIKAN, DAN MENGANALISISNYA SEHINGGA DIPEROLEH âESTIMATE â TINGKAT KEMAMPUAN/ TRAIT ORANG YANG DI TES ï KOMPUTER MEMILIH SOAL BERIKUTNYA SESUAI DENGAN HASIL ESTIMASI TERSEBUT, KEMUDIAN RESPONSE DIANALISIS LAGI DAN DIPEROLEH ESTIMATE YANG BARU ï PROSES DI ATAS DIULANG TERUS SAMPAI DIPEROLEH ESTIMATE DENGAN TINGKAT PRESISI YANG DIINGINKAN
- 3. APA ITU CAT? ï HARUS TERSEDIA BANK SOAL YANG ITEM NYA SUDAH DIVALIDASI DAN DIKALIBRASI SKALANYA ï VALIDASI DAN KALIBRASI SOAL MENGGUNAKAN ITEM RESPONSE THEORY (IRT) ATAU CONFIRMATORY FACTOR ANALYSIS (CFA) ï KARAKTERISTIK SOAL YANG DIHASILKAN BERSIFAT âINVARIANCEâ ï MEMILIH ITEM YANG AKAN DISAJIKAN DENGAN PERHITUNGAN IRT (SOAL DENGAN INFORMASI TERTINGGI) ï MENG-ESTIMASI KEMAMPUAN/ TRAIT (SCORING) JUGA DENGAN IRT
- 4. APA ITU CAT? ï ORANG YANG BERBEDA MENEMPUH HIMPUNAN SOAL BERBEDA (MUNGKIN ADA SEBAGIAN YANG SAMA TAPI MUNGKIN JUGA TAK ADA YANG SAMA), JUGA DENGAN JUMLAH SOAL YANG BERBEDA ï MESKIPUN SOAL YANG DITEMPUH BERBEDA TETAPI HASIL UKURAN MEMILIKI SKALA YANG SAMA (KOMPARABEL) ï PEMILIHAN SOAL YANG AKAN DISAJIKAN BERIKUTNYA BERSIFAT ADAPTIVE, BERGANTUNG KEPADA HASIL ESTIMASI (SKORING) BERDASARKAN JAWABAN TERHADAP SOAL YANG SEBELUMNYA ï SETIAP KALI SKOR DIPEROLEH, TERSEDIA PULA INFORMASI (TINGKAT PRESISI/ STANDAR ERROR) DARI SKOR TERSEBUT ï PENYAJIAN SOAL DIHENTIKAN JIKA SKOR YANG DIPEROLEH SESEORANG TELAH MENCAPAI TINGKAT PRESISI TERTENTU ï PIONIR PEMIKIRAN CAT: F.M. LORD, DAN D.J. WEISS, SEDANGKAN PIONIR DARI APLIKASI CAT MODERN: J.R. McBRIDE, H. WAINER, W.J. van der LINDEN, DAN C.A.W. GLAS
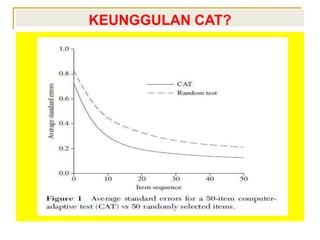
- 5. KEUNGGULAN CAT? ï TINGKAT PRESISI SKOR YANG DIPEROLEH LEBIH TINGGI KARENA SOAL YANG DITEMPUH SELALU SESUAI DENGAN TINGKAT KEMAMPUAN/ TRAIT ORANG YANG DI TES (ADAPTIVE) ï SOAL YANG DITEMPUH SETIAP ORANG UMUMNYA LEBIH SEDIKIT ï TIAP ORANG MENEMPUH HIMPUNAN SOAL BERBEDA JADI TAK BISA SALING MENYONTEK ï LEBIH EFISIEN DAN HASIL SEGERA DIKETAHUI ï SKOR TES YANG DIHASILKAN KOMPARABEL KARENA SUDAH TERKALIBRASI PADA SKALA YANG SAMA
- 7. TAHAPAN PENGEMBANGAN CAT: ï PENGEMBANGAN BANK SOAL YANG TERKALIBRASI ï PENGEMBANGAN SOFTWARE CAT ï PENGADAAN HARDWARES DENGAN SPESIKASI TERTENTU ï INSTALASI/ PEMASANGAN HARDWARES ï PELATIHAN PERSONIL ï RISET/ PERCOBAAN â PERCOBAAN SEBELUM IMPLEMENTASI ï IMPLEMENTASI
- 8. CONTOH: TAHAPAN PENGEMBANGAN ASVAB CAT ï RISET PENDAHULUAN: 1976 - 1990 âĒ APA MENGELUARKAN Guidelines for Computer-Based Tests and Interpretations PADA TAHUN 1985 ï CAT-ASVAB MULAI PERTAMA BEROPERASI PADA SEPTEMBER 1990 ï DEPARTEMEN PERTAHANAN AMERIKA MENGELUARKAN SURAT KEPUTUSAN UNTUK MENERAPKAN CAT-ASVAB SECARA NASIONAL ï IMPLEMENTASI PERTAMA OKTOBER 1996 DI DENVER, LALU DI CHICAGO 1997, DAN BEROPRERASI LENGKAP SECARA NASIONAL PADA APRIL 1997 (di 65 Military entrance processing stations /MEPSs).
- 9. DESKRIPSI ASVAB SEBELUM CAT:
- 10. APA ITU BANK SOAL TERKALIBRASI ? âĒ HIMPUNAN SOAL YANG TELAH DIVALIDASI (UJI VALIDITAS KONSTRUK) DENGAN ANALISIS FAKTOR KONFIRMATORIK (CFA) ATAU DENGAN ITEM RESPONSE THEORY (IRT), âĒ SOAL YANG TERBUKTI VALID, DIKALIBRASI SKALA TINGKAT KESUKARAN (THRESHOLD) NYA DENGAN IRT, âĒ SOAL DAN KARAKTERISTIK PSIKOMETRIK NYA DISIMPAN SERTA DIKELOLA DENGAN KOMPUTER, âĒ DAPAT DIGUNAKAN UNTUK PERAKITAN TES ATAU UNTUK CAT, âĒ SKOR YANG DIHASILKAN OLEH TES YG BERBEDA (TIDAK PARALEL) NAMUN TETAP KOMPARABEL PADA SKALA YANG SAMA
- 11. PENGEMBANGAN BANK SOAL TERKALIBRASI ï MENETAPKAN JENIS KEMAMPUAN/ APTITUDES/ TRAITS DSB YANG HENDAK DIUKUR ï PENGADAAN SOAL (ITEM WRITING) PADA MASING-MASING JENIS TERSEBUT ï UJI-COBA SKALA BESAR DALAM RANGKA VALIDASI (IRT DAN CFA) ï SOAL-SOAL YANG VALID DIKALIBRASI KE DALAM SKALA YANG SAMA (IRT) YANG TELAH ADA DI MASING-MASING BANK SOAL ï KETIGA KEGIATAN INI BERKELANJUTAN SECARA RUTIN (SISTEMIK)
- 12. PENGEMBANGAN SOFTWARE CAT: ï DAPAT MENYIMPAN SOAL DENGAN BERBAGAI INFORMASI TENTANG SOAL TERSEBUT (TERMASUK DATA PSIKOMETRIKNYA) ï DAPAT MENAMPILKAN SOAL DENGAN SEGERA TERMASUK SOAL YANG BERISI RUMUS, GAMBAR, FOTO, DAN ATRIBUT LAINNYA ï BERSIFAT INTERAKTIF DAN MUDAH DIGUNAKAN OLEH ORANG YANG DI TES ï TERDAPAT ALGORITMA IRT YANG MAMPU MELAKUKAN PERHITUNGAN DALAM RANGKA PEMILIHAN SOAL YANG AKAN DITAMPILKAN DENGAN MENGGUNAKAN DATA PSIKOMETRIK DARI SETIAP SOAL ï TERDAPAT ALGORITMA IRT YANG MAMPU MELAKUKAN PERHITUNGAN DALAM RANGKA ESTIMASI âTRUE SCOREâ DENGAN MENGGUNAKAN DATA RESPONS TERHADAP SETIAP SOAL ï MEMILIKI FUNGSI EDITING DALAM RANGKA PENYUSUNAN LAPORAN HASIL TES DALAM BERBAGAI FORMAT YANG DIINGINKAN
- 13. FOKUS WORKSHOP INI: âĒ CARA UJI VALIDITAS KONSTRUK SOAL DENGAN CFA âĒ CARA UJI VALIDITAS SOAL DENGAN IRT âĒ KALIBRASI TINGKAT KESUKARAN SOAL DENGAN IRT âĒ PENGGUNAAN IRT DALAM CAT: (1) MEMILIH SOAL YANG AKAN DITAMPILKAN, (2) ESTIMASI TRUE SCORE DAN STANDAR ERROR NYA
- 15. PENYUSUNAN SOAL: CONTENT VALIDITY LATENT VARIABEL ï OPERATIONAL DEFINITION ï INDICATORS ï KISI-KISI ï TEST ITEMS (STIMULUS) ï PAKET TES ATAU ITEM POOL
- 16. PENYUSUNAN SOAL âĒ PENGUASAAN MATERI, PENGUASAAN KAEDAH, SENI/ BAKAT âĒ PERLU DISELEKSI DAN DILATIH âĒ PADA LEMBAGA PENGEMBANG TES BESAR DI USA, INGGRIS,AUSTRALIA, PENYUSUN SOAL OLEH SEHIMPUNAN ORANG YANG TETAP âĒ TIDAK SECARA ADHOC TETAPI BERKESINAMBUNGAN
- 17. Perkembangan dalam metode penulisan soal: âĒ Tidaklah terlalu pesat, dan selama puluhan tahun terakhir relatif tak berubah. âĒ Bentuk-bentuk soal yang dapat dipilih masih relatif sama, âĒ Kalaupun ada perkembangan baru, terutama adalah karena pengaruh teknologi komputer âĒ Soal dapat di âgenerateâ secara otomatis menggunakan kriteria yang sangat spesifik.
- 18. Penulisan Soal âComputerizedâ: âĒ Hal ini terutama jika populasi soal yang hendak ditulis bersifat âfiniteâ. âĒ Misalnya, soal untuk mengukur kemampuan arithmatika seperti âperkalian dua bilangan yang hasilnya kurang dari seratusâ. âĒ Soal untuk beberapa kemampuan kognitif maupun persepsi, sikap, bahkan traits (menggunakan kepustakaan âadjectivesâ tertentu) dapat di âgenerateâ dengan bantuan komputer.
- 19. âĒ TEORI TES KLASIK âĒ ITEM RESPONSE THEORY âĒ CONFIRMATORY FACTOR ANALYSIS METODE VALIDASI SOAL
- 20. TEORI DAN METODA VALIDASI TES âĒ Mengalami perubahan dan kemajuan yang pesat, namun pada dasarnya hanya ada dua jenis teori tes, yaitu : âĒ (1) Teori yang berbasis âraw scoresâ (skor total, atau skor komposit), dan disebut âteori tes klasikâ atau âteori tes tradisionalâ, âĒ (2) Teori yang berbasis âitemâ (soal): Dapat menghasilkan âtrue-scoresâ bagi setiap orang dan disebut âteori tes modernâ.
- 21. TEORI DAN METODA VALIDASI TES âĒ Teori berbasis items ada dua jenis: âĒ Berdasarkan pola jawaban (response patterns) âĒ Berdasarkan struktur matriks korelasi antar item.
- 22. DASAR TEORI TES KLASIK âĒ Skor tes diperoleh dengan menjumlahkan skor masing-masing soal (disebut X) âĒ Diteorikan bahwa X = T + E, âĒ dimana T adalah âtrue scoreâ dan E adalah âmeasurement errorâ. âĒ Konsep validitas umumnya dirumuskan sebagai korelasi antara skor tes (X) dengan âtrue scoresâ T.
- 23. METODE VALIDASI TEORI TES KLASIK âĒ Karena true-scores tidak ada datanya, maka skor dari tes lain yang sudah dianggap valid digunakan sebagai kriteria untuk menilai valid tidaknya tes tersebut. âĒ Ketika hal inipun tak tersedia, maka skor dari tes yang sedang diteliti itu sendiri lalu dianggap sudah valid dan dijadikan kriteria sementara.
- 24. METODE VALIDASI TEORI TES KLASIK âĒ Korelasi antara setiap item dengan skor tes tersebut dihitung, âĒ Item yang berkorelasi positif dan tinggi dianggap valid, sedangkan item yang berkorelasi rendah, apalagi jika negatif, dinilai tidak valid. âĒ Setelah semua item yang dianggap âtidak validâ di drop, maka skor tes yang diperoleh dianggap valid.
- 25. METODE VALIDASI TEORI TES KLASIK âĒ Sangat lemah karena skor tes yang dijadikan kriteria itu sendiri adalah belum diuji validitasnya. âĒ Ketika kriteria eksternal (skor tes lain yang dianggap sudah valid) tersedia, sebenarnya pun masih cukup lemah karena validitas skor tes lain itupun dapat dipertanyakan.
- 26. METODE VALIDASI TEORI TES KLASIK âĒ Cara yang lebih ilmiah ialah dengan metode âmulti-traits multi-methodsâ (MTMM) âĒ Membandingkan pola (pattern) korelasi antar âtraitsâ dan âantar metodeâ, apakah sesuai dengan landasan teori psikologi yang digunakan. âĒ Namun cara ini jarang dilakukan karena seringkali sulit diimplementasikan secara empiris.
- 27. METODE VALIDASI TEORI TES KLASIK âĒ Metode lain ialah dengan pendekatan analisis faktor, namun dengan teknik tradisional (misalnya seperti pada SPSS) âĒ Hanya bersifat eksploratorik dan bukan merupakan inferensi statistik, âĒ Tidak ilmiah karena tak ada kriteria yg pasti untuk menentukan banyaknya faktor maupun dalam merotasi faktor. âĒ Ringkasnya, semua indeks validitas pada teori klasik adalah bermasalah.
- 28. TEORI TES MODERN âĒ Teori tes modern dan teori tes klasik sebenarnya tidaklah berbeda karena teori tes modern merupakan penyempurnaan dari teori tes klasik. âĒ Yang tak dapat diperoleh pada teori tes klasik seperti âtrue-scoreâ yang berskala interval, adalah hal yang dapat dihasilkan pada teori tes modern.
- 29. TEORI TES MODERN âĒ Indeks-indeks validitas dan reliabilitas dapat diperoleh dengan lebih baik, dan âĒ Asumsi-asumsi yang mendasari proses pengukuran dapat diuji kebenarannya. âĒ Namun menuntut pemahaman matematika dan statistika yang lebih rumit, âĒ Penggunaan teori klasik tetap dominan terutama di negara yang belum tergolong maju. âĒ Di kalangan komunitas psikologi di Indonesia, tampak bahwa bahkan teori tes klasik pun masih belum dipahami dengan memadai.
- 30. TUMBUHNYA TEORI TES MODERN âĒ Berkembangnya teori statistika dan matematika khususnya di bidang âstatistical modelingâ âĒ Disertai dengan berbagai teori dan metode estimasi yang canggih untuk parameternya, âĒ Berbarengan pula dengan pesatnya perkembangan teknologi komputer, âĒ Semua ini mendorong pesatnya perkembangan teori tes di bidang psikologi dan pendidikan.
- 31. TUMBUHNYA TEORI TES MODERN âĒ Konsep pengukuran psikologis yang dahulunya mungkin sudah pernah dibahas namun terpaksa ditinggalkan atau mengendap karena tidak mungkin dilakukan perhitungan matematis pada jamannya, âĒ Kini dimunculkan kembali dan bahkan menjadi teori yang dianggap baru dengan sebutan teori tes modern.
- 32. CIRI UTAMA TEORI TES MODERN âĒ Tidak berbasis skor tes tetapi berbasis skor item, âĒ Dapat diperoleh âtrue scoreâ untuk setiap orang lengkap dengan standar error nya masing- masing sehingga tidak diperlukan lagi indeks reliabilitas âĒ Hasil tes yang tak bergantung kepada sampel (invariance) sehingga dapat dibuat komparabel antar waktu, tempat, dan tingkatan âĒ Asumsi-asumsi penting dapat diuji secara empiris,
- 33. CIRI UTAMA TEORI TES MODERN âĒ True score yang dihasilkan berskala interval, âĒ Dapat diterapkan pada berbagai jenis tes baik untuk kemampuan, sikap, maupun personality âĒ Pada level yang canggih dapat dibuat âcomputer adaptive testingâ yang bahkan berbasis online, âĒ Pengaruh berbagai sumber bias (termasuk âsocial desirabilityâ) dapat dikontrol secara matematis
- 34. DUA JENIS TEORI TES MODERN âĒ Teori yang berbasis model probabilitas dari pola respons (pola jawaban terhadap sehimpunan items), dikenal dengan nama âItem Response Theoryâ (IRT), dan âĒ Teori yang berbasis analisis terhadap struktur korelasi antar items (âConfirmatory Factor Analysisâ atau CFA). âĒ Dari sisi teori statistika atau psikometrika, sebenarnya kedua pendekatan tersebut sudah menyatu menjadi model statistika yang generik dan canggih, yaitu: âlatent variable modelingâ
- 35. DUA JENIS TEORI TES MODERN âĒ Aplikasinya tidak lagi terbatas pada bidang psikologi tapi pada hampir semua bidang seperti ekonomi, kesehatan, ilmu pengetahuan alam, ilmu-ilmu sosial, bahasa, dan bahkan antropologi. âĒ Salah satu program komputer canggih dan komprehensif dalam hal âlatent variable statistical analysisâ pada saat ini adalah MPLUS versi 7.4 (Muthen and Muthen, 2015). âĒ Hampir semua jenis model statistika yang telah dikembangkan orang hingga saat ini, dapat diselesaikan dengan menggunakan software ini, terutama sekali jika menyangkut variabel laten.
- 36. ITEM RESPONSE THEORY (IRT) âĒ Mulai berkembang pesat di tahun 1980an âĒ Ide dasarnya telah dimunculkan oleh F.M. Lord di tahun 1940 tetapi baru menjadi topik hangat di tahun 1970an âĒ Namun yang dianggap sebagai ârevolusi dalam teori testingâ ialah model pengukuran kemampuan yang dikembangkan oleh Georg Rasch, pakar matematika asal Denmark âĒ Menjadi cikal bakal IRT dan dikenal dengan nama âRasch Measurement Modelâ
- 37. ITEM RESPONSE THEORY (IRT) âĒ Sampai kini âaliranâ Rasch Model terus berkembang pesat menjadi makin canggih, dan sangat dominan di Eropa dan Australia âĒ Di Amerika, pengaruh Rasch Model ini juga cukup besar dengan pusat perkembangannya di Universitas Chicago âĒ Mengklaim bahwa dari semua model IRT yang ada, Rasch Model adalah satu-satunya âmeasurement modelâ, sedang yang lainnya hanyalah âstatistical modelsâ âĒ Sebaliknya, mereka yang mengembangkan âIRT sebagai model statistikaâ hanya memandang Rasch Model sebagai âspecial caseâ saja dari IRT dan mereka memberinya label âIRT model satu parameterâ
- 38. ITEM RESPONSE THEORY (IRT) âĒ Metode pengujian validitas dalam IRT secara konsep cukup sederhana namun perhitungan matematis cukup kompleks. âĒ Sebagai ilustrasi, misalkan sebuah tes kemampuan yang itemnya berbentuk pilihan ganda: respons yang diperoleh hanya dua macam yaitu (a) jawaban benar dengan kode angka 1, dan (b) jawaban salah dengan kode angka 0.
- 39. ITEM RESPONSE THEORY (IRT) âĒ Dalam hal ini, teori IRT berbunyi sebagai berikut: âĒ âJika ada banyak orang yang bervariasi kemampuannya menempuh sebuah soal, maka orang yang lebih tinggi kemampuannya akan memiliki âpeluangâ lebih tinggi untuk menjawab benar pada soal tersebut dibandingkan dengan orang yang kemampuannya lebih rendahâ.
- 40. ITEM RESPONSE THEORY (IRT) âĒ Makin tinggi kemampuan seseorang akan makin tinggi probabilitas (peluang) orang tersebut menjawab benar, dan sebaliknya. âĒ Jika tingkat kemampuan orang diberi simbol (theta) dan tingkat kesukaran soal diberi simbol , serta digunakan distribusi probabilitas dengan fungsi âlogisticâ, maka peluang seorang untuk menjawab benar pada sebuah item dapat dituliskan dengan rumus berikut: âĒ di mana y adalah jawaban seorang terhadap suatu butir soal ïą ïĪ
- 41. ITEM RESPONSE THEORY (IRT) âĒ Karena nilai probabilitas hanya antara nol dan satu sedangkan dan adalah bilangan riel (variabel kontinum), maka untuk suatu nilai yang konstan dan yang bervariasi (artinya, ada banyak orang menempuh satu butir soal), persamaan di atas akan menghasilkan sebuah kurva yang makin ke kanan makin menanjak (âmonotonic increasingâ) namun bersifat asimptotik (tidak pernah menyentuh nol ataupun satu karena sifat yang probabilistik) ïą ïą ïĪ ïĪ
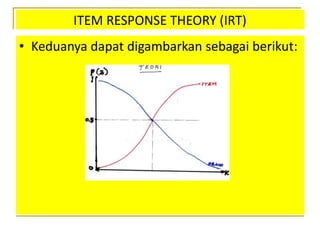
- 42. ITEM RESPONSE THEORY (IRT) âĒ Kurva ini disebut kurva karakteristik soal (âitem characteristic curveâ, atau ICC) âĒ Sebaliknya, untuk suatu nilai yang konstan dengan yang bervariasi (ada satu orang menempuh banyak soal), maka yang dihasilkan adalah kurva yang makin ke kanan makin menurun (âmonotonic decreasingâ) dan disebut sebagai kurva karakteristik orang (PCC) ïą ïĪ
- 43. ITEM RESPONSE THEORY (IRT) âĒ Keduanya dapat digambarkan sebagai berikut:
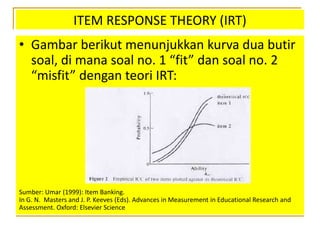
- 44. ITEM RESPONSE THEORY (IRT) âĒ Dengan menggunakan kurva di atas, orang dapat menguji secara empirik validitas data tes baik untuk instrumen (item tes) maupun untuk orang âĒ Jika sebuah soal secara empirik terbukti menghasilkan kurva soal yang sesuai dengan teori IRT (monotonic increasing) maka soal tersebut dianggap valid, dan sebaliknya. âĒ Begitu pula dengan orang yang dites, jika respons nya menghasilkan kurva orang yang sesuai dengan teori IRT (monotonic decreasing) maka berarti jawabannya tidak ângawurâ atau palsu, dan boleh digunakan untuk diskor
- 45. ITEM RESPONSE THEORY (IRT) âĒ Gambar berikut menunjukkan kurva dua butir soal, di mana soal no. 1 âfitâ dan soal no. 2 âmisfitâ dengan teori IRT: Sumber: Umar (1999): Item Banking. In G. N. Masters and J. P. Keeves (Eds). Advances in Measurement in Educational Research and Assessment. Oxford: Elsevier Science
- 46. ITEM RESPONSE THEORY (IRT) âĒ Pada contoh di atas, item nomor 1 valid, sedangkan item 2 tidak valid dan harus di drop. âĒ Jika seluruh item pada sebuah tes terbukti valid, maka berarti tes tersebut valid dan dapat digunakan.
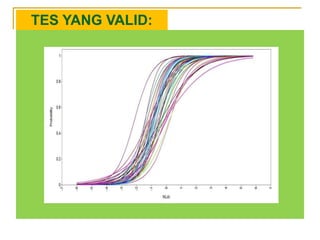
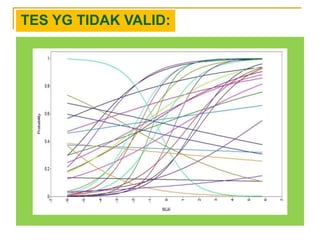
- 47. TES YANG VALID:
- 48. TES YG TIDAK VALID:
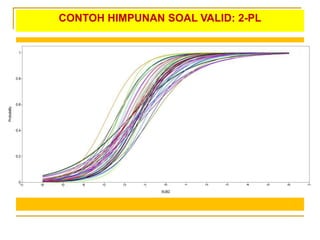
- 49. CONTOH HIMPUNAN SOAL VALID: 2-PL
- 50. ITEM RESPONSE THEORY (IRT) âĒ Seperti telah disebutkan, meskipun konsep dasar IRT terlihat sederhana namun perhitungan matematis yang diperlukan amatlah rumit dan hanya dapat dilakukan dengan komputer berkecepatan tinggi.
- 51. ITEM RESPONSE THEORY (IRT) âĒ Sebagai ilustrasi, jika dalam rangka validasi tes yang terdiri dari 40 soal diuji-cobakan kepada 400 subyek, maka orang harus menyelesaikan sebanyak 16000 persamaan secara simultan (simultaneous equations) Apalagi mengingat persamaannya yang bersifat ânon-linearâ jadi tak terdapat âclosed formulasâ dan harus diselesaikan dengan metode âiterativeâ yang memerlukan hitungan âcalculusâ dengan sangat intensif
- 52. ASUMSI ITEM RESPONSE THEORY (IRT) âĒ Seperti semua model pengukuran, pada IRT pun diperlukan asumsi âunidimensionalâ âĒ Bahwa seluruh item dalam suatu tes hanya mengukur satu dimensi saja, yaitu konstruk yang telah didefinisikan dan diniati untuk diukur. âĒ Masalahnya ialah, jika sehimpunan soal sudah memenuhi syarat kurva ICC yang menanjak, ternyata tidaklah merupakan jaminan bahwa seluruh soal tersebut hanya mengukur satu konstruk saja
- 53. ASUMSI ITEM RESPONSE THEORY (IRT) âĒ Asumsi lain adalah bahwa setiap respons bersifat independen satu sama lain, yang terkadang tak dapat terpenuhi âĒ Juga ada asumsi bahwa âmeasurement errorâ pada suatu item tidak berkorelasi satu sama lain (asumsi âlocal-independenceâ) âĒ Inipun sukar terpenuhi karena beberapa item mungkin memiliki berbagai aspek kontekstual yang sama
- 54. ASUMSI ITEM RESPONSE THEORY (IRT) âĒ Semua asumsi di atas tak dapat diuji dalam IRT dan harus diuji secara terpisah dengan metode statistika lain (software lain) yang terpisah. âĒ Kelemahan IRT ini dapat tertutupi pada model teori tes modern yang lain, yaitu yang berbasis struktur korelasi antar item, âĒ Model ini dikenal dengan nama âConfirmatory Factor Analysis for Categorical dataâ ( CFA)
- 55. CFA CATEGORICAL DATA âĒ Teori tes modern yang berbasis struktur korelasi antar item, pada dasarnya terdiri dari tiga langkah: 1. Mengestimasi korelasi âpolychoricâ antar setiap pasangan item dengan memperhitungkan nilai âthresholdâ pada masing-masing item (yang juga harus diestimasi dari data) 2. Menguji hipotesis bahwa seluruh item mengukur hanya satu atribut atau dimensi yang ditetapkan (unidimensional), 3. Jika model unidimensional terbukti âfitâ dengan data maka dapat diuji apakah setiap item âsignifikanâ dalam mengukur dimensi yang hendak diukur. Dalam hal ini, item yang tidak signifikan atau item yang koefisiennya negatif harus di drop karena tidak valid dalam mengukur apa yang hendak diukur.
- 56. CFA CATEGORICAL DATA âĒ Langkah pertama merupakan ranah tersendiri dalam metode statistika untuk data kategorikal, sedangkan langkah kedua dan ketiga adalah dikenal dengan sebutan metode âConfirmatory Factor Analysisâ (CFA) âĒ Jika ketiganya diintegrasikan, disebut: âConfirmatory Factor Analysis of Categorical Dataâ âĒ Pada model ini, IRT dan CFA melebur menjadi satu dan seluruh asumsi IRT dapat sekaligus diuji apakah telah terpenuhi
- 57. CFA CATEGORICAL DATA âĒ Berbeda dengan IRT, meskipun asumsi tak terpenuhi, tetap dapat diperoleh true-score yang valid, yaitu dengan memperhitungkan aspek asumsi yang tak terpenuhi tersebut âĒ Pada saat ini, software yang dapat digunakan untuk problem di mana IRT dan CFA terintegrasi adalah MPLUS (Muthen and Muthen 2015)
- 58. CFA CATEGORICAL DATA âĒ Dari segi matematis, perhitungannya termasuk sangat rumit. âĒ Sekedar ilustrasi, misalkan menghitung korelasi polychoric âĒ Paling sederhana adalah korelasi tetrachoric yaitu antara dua variabel dichotomis, misalnya jawaban terhadap dua item pilihan ganda:
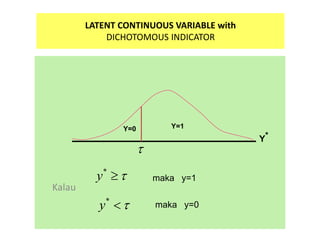
- 59. CFA CATEGORICAL DATA âĒ Pertama adalah menghitung âthresholdâ (dalam hal ini dapat disebut sebagai âtingkat kesukaran soalâ). âĒ Andaikan adalah threshold item x, artinya: jika tingkat kemampuan orang yang menjawab item x lebih tinggi dari maka jawabannya akan benar (x=1), dan jika kemampuan < maka jawabannya salah (x=0). ïī ïī ïī
- 60. LATENT CONTINUOUS VARIABLE with DICHOTOMOUS INDICATOR Kalau Y* Y=0 Y=1 ïī * y ïīïģ * y ïīïž maka y=1 maka y=0
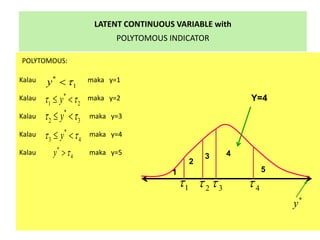
- 61. LATENT CONTINUOUS VARIABLE with POLYTOMOUS INDICATOR POLYTOMOUS: Kalau maka y=1 Kalau maka y=2 Kalau maka y=3 Kalau maka y=4 Kalau maka y=5 * 1y ïīïž * 2 3yïī ïīïĢ ïž * 1 2yïī ïīïĢ ïž * 3 4yïī ïīïĢ ïž * 4y ïīïū 1 2 3 4 5 1ïī 2ïī 3ïī 4ïī * y Y=4
- 62. MENGHITUNG KORELASI POLYCHORIC: âĒ Dengan asumsi bahwa kemampuan yang diukur mengikuti kurva normal, nilai dapat dihitung dengan rumus: âĒ Jika ada item y dengan threshold , maka korelasi tetrachoric antara item x dan y dapat diperoleh dengan mencari nilai r dari persamaan berikut (Divgi, 1979): di mana adalah probability ïī 2 1 ( ) exp( ) 22 x F x ïī ïī ï° ïĨ ï― ï ïķïē ïŦ 2 2 22 1 2 ( , , ) exp( ) 2(1 )2 1 x y rxy L r x y rr ïŦ ïī ïī ïŦ ï° ïĨ ïĨ ïŦ ï ï― ï ïķ ïķ ïï ïē ïē ( , , )L rïī ïŦ ( , )x yïī ïŦf f
- 63. CFA CATEGORICAL DATA âĒ Bayangkan jika tiap item kategorinya lebih dari dua, misalnya skala Likert dengan 4 pilihan, dimana ada tiga thresholds untuk setiap item. âĒ Jika sebuah tes terdiri dari 40 item, maka harus dihitung sebanyak (40 X 41)/2 = 820 korelasi polychoric. âĒ Nah, matriks korelasi polychoric inilah yang akan dijadikan data untuk analisis CFA pada langkah berikutnya.
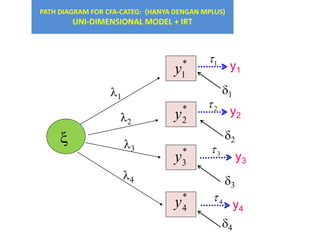
- 64. PATH DIAGRAM FOR CFA-CATEG: (HANYA DENGAN MPLUS) UNI-DIMENSIONAL MODEL + IRT ïĪ1 x l1 l2 l3 l4 * 1y * 2y * 3y * 4y ïĪ2 ïĪ3 ïĪ4 1ïī 2ïī 3ïī 4ïī y1 y2 y3 y4
- 65. CFA CATEGORICAL DATA UNTUK SETIAP ITEM (x) PERSAMAANNYA ADALAH: y = Îŧ Îū + Îī DIMANA: y = VECTOR OF OBSERVED VARIABLES (ITEMS), Îū = VECTOR OF FACTORS (CONSTRUCTS, OR LATENT VARIABLES) TO BE MEASURED VIA y , IN WHICH Îŧ IS THE COEFFICIENTS OF FACTOR LOADINGS, Îī = VECTOR OF RESIDUALS (ERRORS OF MEASUREMENT).
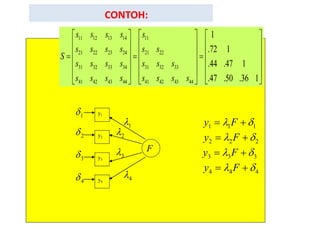
- 66. CFA CATEGORICAL DATA âĒ Perhitungan dalam analisis CFA (jauh lebih rumit dari perhitungan korelasi polychoric), menggunakan rumus: Dimana: = matrik korelasi polychoric antar items Y , = matrik koefisien muatan faktor setiap item = matrik korelasi antar faktor = matrik kovarians antar kesalahan pengukuran pada setiap item Setiap elemen dari ÎĢ dinyatakan dalam Îŧ, Ï, AND Îļ. Misalnya: pada model unidimensionaal: Ï21 = Îŧ1Îŧ2 ïĒï ï― ïïï ïŦ ï ï ï ï ï
- 67. CONTOH: 11 12 13 14 11 21 22 23 24 21 22 31 32 33 34 31 32 33 41 42 43 44 41 42 43 44 1 .72 1 .44 .47 1 .47 .50 .36 1 s s s s s s s s s s s S s s s s s s s s s s s s s s s ïĐ ïđ ïĐ ïđ ïĐ ïđ ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïšï― ï― ï― ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïš ïŦ ïŧïŦ ïŧ ïŦ ïŧ y1 y2 y3 y4 1l 2l 3l 4l F 1ïĪ 2ïĪ 3ïĪ 4ïĪ 2 2 2y Fl ïĪï― ïŦ 1 1 1y Fl ïĪï― ïŦ 3 3 3y Fl ïĪï― ïŦ 4 4 4y Fl ïĪï― ïŦ
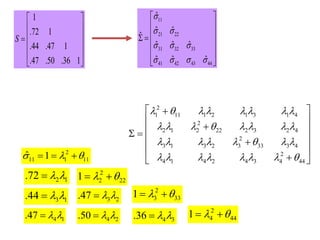
- 68. ï ï 1 11 2 22 1 2 3 4 333 444 2 1 11 1 2 1 3 1 4 2 2 1 2 22 2 3 2 4 2 3 1 3 2 3 33 3 4 2 4 1 4 2 4 3 4 44 0 0 0 0 0 0 0 0 0 0 0 0 l ïą l ïą l l l l ïąl ïąl l ïą l l l l l l l l l ïą l l l l l l l l l ïą l l l l l l l l l ïą ïĐ ïđ ïĐ ïđ ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïšï ï― ïī ïŦ ïŠ ïš ïŠ ïš ïŠ ïš ïŠ ïš ïŦ ïŧïŦ ïŧ ïĐ ïđïŦ ïŠ ïš ïŦïŠ ïšï― ïŠ ïšïŦ ïŠ ïš ïŦïŦ ïŧ PERSAMAAN UNTUK CFA: ÎĢ = ÎÎĶÎÎ + Îļ
- 69. UJI HIPOTESIS: MODEL TEORI âĒ OBSERVED SAMPLE CORRELATION MATRIX OF Y VARIABLES, i.e., S, IS USED AS AN âESTIMATEâ OF ÎĢ (EACH ELEMENT OF ÎĢ IS EQUATED WITH ITS RESPECTIVE ELEMENT IN S) âĒ THE NULL HYPOTHESIS TO BE TESTED IS: S = ÎĢ, OR, (S - ÎĢ = 0). IF NOT REJECTED (NON SIGNIFICANT) MEANS THE THEORETICAL MODEL IS SUPPORTED BY DATA, HENCE, ITS USES IS JUSTIFIED. âĒ THIS MODEL TESTING IS REFERRED TO AS: âTEST OF GOODNESS OF FITâ.
- 70. 11 21 22 31 32 33 41 42 43 44 Ë Ë Ë Ë Ë Ë Ë Ë Ë Ë ïģ ïģ ïģ ïģ ïģ ïģ ïģ ïģ ïģ ïģ ïĐ ïđ ïŠ ïš ïŠ ïšï ï― ïŠ ïš ïŠ ïš ïŦ ïŧ 2 11 1 11 Ë 1ïģ l ïąï― ï― ïŦ 2 1.72 l lï― 3 1.44 l lï― 2 2 221 l ïąï― ïŦ 2 3 331 l ïąï― ïŦ 2 4 441 l ïąï― ïŦ 3 2.47 l lï― 4 1.47 l lï― 4 2.50 l lï― 4 3.36 l lï― 1 .72 1 .44 .47 1 .47 .50 .36 1 S ïĐ ïđ ïŠ ïš ïŠ ïšï― ïŠ ïš ïŠ ïš ïŦ ïŧ 2 1 11 1 2 1 3 1 4 2 2 1 2 22 2 3 2 4 2 3 1 3 2 3 33 3 4 2 4 1 4 2 4 3 4 44 l ïą l l l l l l l l l ïą l l l l l l l l l ïą l l l l l l l l l ïą ïĐ ïđïŦ ïŠ ïš ïŦïŠ ïšï ï― ïŠ ïšïŦ ïŠ ïš ïŦïŦ ïŧ
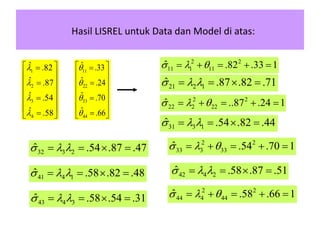
- 71. Hasil LISREL untuk Data dan Model di atas: 11 22 33 44 Ë .33 Ë .24 Ë .70 Ë .66 ïą ïą ïą ïą ïĐ ïđï― ïŠ ïš ï―ïŠ ïš ïŠ ïš ï―ïŠ ïš ïŠ ïš ï―ïŦ ïŧ 1 2 3 4 Ë .82 Ë .87 Ë .54 Ë .58 l l l l ïĐ ïđï― ïŠ ïš ï―ïŠ ïš ïŠ ïš ï―ïŠ ïš ïŠ ïš ï―ïŦ ïŧ 2 2 11 1 11 Ë .82 .33 1ïģ l ïąï― ïŦ ï― ïŦ ï― 21 2 1 Ë .87 .82 .71ïģ l lï― ï― ïī ï― 31 3 1 Ë .54 .82 .44ïģ l lï― ï― ïī ï― 2 2 33 3 33 Ë .54 .70 1ïģ l ïąï― ïŦ ï― ïŦ ï― 2 2 22 2 22 Ë ..87 .24 1ïģ l ïąï― ïŦ ï― ïŦ ï― 32 3 2 Ë .54 .87 .47ïģ l lï― ï― ïī ï― 41 4 1 Ë .58 .82 .48ïģ l lï― ï― ïī ï― 42 4 2 Ë .58 .87 .51ïģ l lï― ï― ïī ï― 43 4 3 Ë .58 .54 .31ïģ l lï― ï― ïī ï― 2 2 44 4 44 Ë .58 .66 1ïģ l ïąï― ïŦ ï― ïŦ ï―
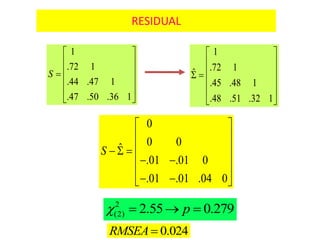
- 72. RESIDUAL 1 .72 1 .44 .47 1 .47 .50 .36 1 S ïĐ ïđ ïŠ ïš ïŠ ïšï― ïŠ ïš ïŠ ïš ïŦ ïŧ 1 .72 1Ë .45 .48 1 .48 .51 .32 1 ïĐ ïđ ïŠ ïš ïŠ ïšï ï― ïŠ ïš ïŠ ïš ïŦ ïŧ 0 0 0Ë .01 .01 0 .01 .01 .04 0 S ïĐ ïđ ïŠ ïš ïŠ ïšï ï ï― ï ïïŠ ïš ïŠ ïš ï ïïŦ ïŧ 2 (2) 2.55 0.279pïĢ ï― ïŪ ï― 0.024RMSEAï―
- 73. UJI HIPOTESIS: Îŧ âĒ ONLY WHEN THE MODEL IS âFITâ, THEN THE NULL HYPOTHESES Îŧ = 0, WORTH TO BE TESTED. âĒ WHEN A NULL HYPOTHESIS REGARDING AN Îŧ IS REJECTED (SIGNIFICANT), THE RESPECTIVE Y IS CONSIDERED AS A VALID INDICATOR (MEASURE) OF THE Îū (FACTOR).
- 74. CATATAN UNTUK UJI VALIDITAS DENGAN CFA: âĒ KALAU MENGGUNAKAN SOFTWARE SEPERTI LISREL, DILAKUKAN DENGAN DUA TAHAP: PERITUNGAN KORELASI POLYCHORIC DENGAN SOFTWARE âPRELISâ KEMUDIAN DILANJUTKAN DENGAN CFA MENGGUNAKAN LISREL âĒ JIKA MENGGUNAKAN SOFTWARE MPLUS, KEDUANYA TERINTEGRASI DAN DILAKUKAN SECARA SIMULTAN
- 76. KALIBRASI SOAL DENGAN IRT: âĒ JIKA TELAH DIPEROLEH SEHIMPUNAN ITEM YANG TELAH TERBUKTI VALID, MAKA TINGKAT KESUKARANNYA DAPAT DIKALIBRASI KE DALAM SKALA LOGIT YANG SAMA DENGAN IRT âĒ SOFTWARE YANG DAPAT DIGUNAKAN ANTARA LAIN: WINSTEP (UNTUK RASCH MODEL), BILOG NG (UNTUK MODEL 2PL ATAU 3PL), ATAU MPLUS (BISA UNTUK SEMUA MODEL).
- 77. KALIBRASI SOAL DENGAN IRT: âĒ KALIBRASI = MENYAMAKAN SKALA UKURAN DENGAN MENYESUAIKAN TITIK NOL DAN SATUAN UKURAN (SCALING UNIT) âĒ BIASANYA NILAI RATA-RATA TINGKAT KESUKARAN SEHIMPUNAN YANG PERTAMA KALI DI VALIDASI, DIJADIKAN TITIK NOL DAN SETIAP ITEM YANG KEMUDIAN DITAMBAHKAN KE DALAM BANK SOAL DISESUAIKAN KE SKALA INI
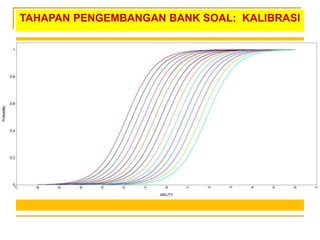
- 78. TAHAPAN PENGEMBANGAN BANK SOAL: KALIBRASI
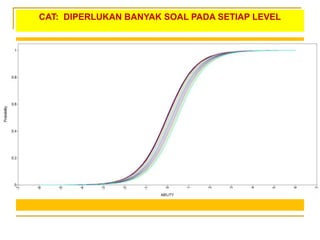
- 79. CAT: DIPERLUKAN BANYAK SOAL PADA SETIAP LEVEL
- 80. KALIBRASI SOAL BARU: âĒ SETIAP KALI ADA SOAL BARU YANG SUDAH DIVALIDASI DAN AKAN DITAMBAHKAN KE BANK SOAL, ADA DUA MASALAH YANG PERLU DIPERHATIKAN: âĒ DISAIN UJI COBA SOAL, APAKAH AKAN MENGGUNAKAN MODEL âCOMMON ITEMSâ, ATAUKAH DENGAN âCOMMON PERSONSâ âĒ METODE KALIBRASI APAKAH SIMULTAN ATAUKAH SATU PER SATU PAKET TES âĒ YANG PALING SEDERHANA ADALAH JIKA MENGGUNAKAN RASCH MODEL, KARENA SKALA KESUKARAN SOAL HANYA BERBEDA LOKASI TITIK NOL NYA SAJA, SEDANGKAN UNIT SKALANYA SUDAH SAMA
- 81. CONTOH DISAIN LINKING 5 PAKET TES:
- 82. PENYAJIAN SOAL DENGAN CAT ïïïïïïïïï
- 83. METODE PENGADMINISTRASIAN TES âĒ Perkembangan metode penyajian tes tidak mengalami perubahan besar kecuali adanya pengaruh teknologi komputer dan internet. âĒ Tes yang sebelumnya disajikan dengan metode âpaper and pencilâ kini dapat disajikan secara âcomputerizedâ. âĒ Ada dua jenis penyajian tes dengan bantuan komputer yaitu: (1) âComputer Assisted Testingâ dan (2) âComputer Adapted Testingâ
- 84. METODE PENGADMINISTRASIAN TES âĒ Pada Computer Assisted Testing ada dua metode: âĒ (a) beberapa paket tes (forms) disimpan dalam komputer, lalu salah satu diantaranya digunakan ketika ada orang yang akan di tes, dan âĒ (b) tersedia âitem poolâ lalu dilakukan pemilihan item secara âcomputerizedâ sesuai kisi-kisi untuk langsung disajikan kepada orang yang di tes.
- 85. METODE PENGADMINISTRASIAN TES âĒ Sedangkan âComputerized Adaptive Testingâ adalah bentuk yang paling advance dari pengadministrasian tes. âĒ Penggunaannya tanpa kisi-kisi tertentu, sangat fleksibel namun hasilnya sangat akurat dan komparabel. âĒ SEPERTI TELAH DISEBUTKAN SEBELUMNYA, TERDIRI DARI DUA LANGKAH YANG DI ULANG- ULANG YAITU: MEMILIH SOAL YANG AKAN DITAMPILKAN DAN ESTIMASI KEMAMPUAN (SCORING).
- 86. METODE PENGADMINISTRASIAN TES âĒ Dimungkinkan karena tingkat kesukaran yang diperoleh melalui IRT bersifat âinvarianceâ, yaitu âĒ Tidak berubah meskipun dihitung pada sampel berbeda âĒ Skala tingkat kesukaran seluruh soal yang disimpan di komputer telah disamakan (dikalibrasi) âĒ Meskipun setiap orang menempuh himpunan soal yang berbeda namun hasilnya dapat diperbandingkan/ komparabel pada skala ukuran yang sama.
- 87. METODE PENGADMINISTRASIAN TES âĒ Hasilnya lebih akurat karena soal yang disajikan selalu disesuaikan dengan kemampuan orang yang menempuhnya. âĒ Setiap kali soal disajikan, jika jawabannya benar maka komputer akan mencari dan menyajikan soal yang sedikit lebih sukar dan jika jawabannya salah maka akan disajikan soal yang sedikit lebih mudah.
- 88. METODE PENGADMINISTRASIAN TES âĒ Setiap kali terjadi jawaban benar atau salah, komputer menghitung âtrue-scoreâ lengkap dengan âstandard errorânya âĒ Hanya jika tingkat akurasi tertentu telah dicapai (standard error lebih kecil dari kriteria tertentu), barulah penyajian tes dihentikan. âĒ Setiap orang menempuh jumlah item yang berbeda namun hasilnya komparabel pada skala ukuran yang sama.
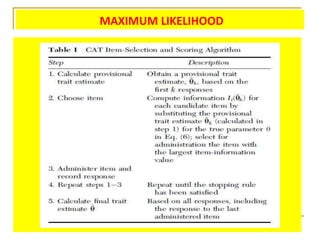
- 89. MENENTUKAN SOAL YANG AKAN DITAMPILKAN âĒ MENGGUNAKAN IRT, PROSEDURNYA SAMA DENGAN SAAT VALIDASI (MENGESTIMASI PARAMETER SOAL) HANYA SAJA DALAM HAL INI NILAI PARAMETER SOAL SUDAH DIMILIKI âĒ ADA DUA PILIHAN YAITU DENGAN METODE MAXIMUM LIKELIHOOD ATAU METODE BAYESIAN
- 90. KRITERIA SOAL YANG AKAN DITAMPILKAN âĒ MENGGUNAKAN IRT, PROSEDURNYA SAMA DENGAN SAAT VALIDASI (MENGESTIMASI PARAMETER SOAL) HANYA SAJA DALAM HAL INI NILAI PARAMETER SOAL SUDAH DIMILIKI âĒ ADA DUA PILIHAN YAITU DENGAN METODE MAXIMUM LIKELIHOOD ATAU METODE BAYESIAN
- 96. BAYESIAN CAT
- 97. BAYESIAN CAT
- 99. METODE SKORING: CARA TRADISIONAL ï SKOR BUTIR DIJUMLAHKAN MENJADI SKOR TOTAL TANPA PEMBOBOTAN ï JIKA TERDIRI DARI BEBERAPA SUBTES, SKOR SUBTES DISTANDARDISASI LALU DIJUMLAHKAN ï SKOR BUTIR ORDINAL SEPERTI PADA SKALA RATING ATAU LIKERT, DIANGGAP SKALA INTERVAL ï UMUMNYA TANPA DIDAHULUI UJI VALIDITAS KONSTRUK ï HASIL PENGUKURAN YANG DILAPORKAN BUKAN DALAM BENTUK âTRUE-SCOREâ.
- 100. ASUMSI: ï ï SELURUH BUTIR TES MENGUKUR SATU KONSTRUK YANG SAMA (UNIDIMENSIONAL) ï SELURUH BUTIR SOAL MERUPAKAN TES PARALEL ï SKOR BUTIR ORDINAL SEPERTI PADA SKALA RATING ATAU LIKERT, DIANGGAP SKALA INTERVAL ï HASIL PENGUKURAN YANG DILAPORKAN BUKAN DALAM BENTUK âTRUE-SCOREâ.
- 101. MASALAH PADA SKOR TRADISIONAL ï SEMUA BUTIR DIANGGAP SAMA (PARALEL), BAIK TINGKAT KESUKARAN MAUPUN DAYA PEMBEDANYA, SEHINGGA PENGGUNAAN SKOR TOTAL TANPA PEMBOBOTAN DAPAT MENYESATKAN BAIK KETIKA DIBUAT RANKING MAUPUN DALAM ANALISIS STATISTIK ï ï PADA SKALA RATING ATAU LIKERT HASILNYA AKAN LEBIH MENYESATKAN LAGI KARENA HASIL RATING DIANGGAP SKALA INTERVAL ï ï DAPAT TERJADI PENCEMARAN SKOR AKIBAT ADANYA BUTIR YANG TIDAK VALID (KARENA MENGUKUR KONSTRUK LAIN) ï ï TIDAK DIGUNAKANNYA âTRUE-SCOREâ DAPAT MENGAKIBATKAN HASIL ANALISIS YANG SALAH BAIK DALAM PENGAMBILAN KEPUTUSAN MAUPUN DALAM ANALISIS DATA UNTUK RISET
- 102. CARA BARU: MENGGUNAKAN TRUE-SCORE ï SETIAP BUTIR TES DIUJI VALIDITAS KONSTRUKNYA ï ï SETIAP BUTIR TES DIKALIBRASI TINGKAT KESUKARANNYA ï ï KADAR VALIDITAS DAN TINGKAT KESUKARAN BUTIR DIPERHITUNGKAN DALAM PENSKORAN ï ï DIBUAT SKALA UKURAN UNTUK TRUE-SCORE YANG BERBASIS BUTIR, BUKAN TES ï ï ORANG YANG MENEMPUH PAKET TES YANG BERBEDA (BAHKAN YANG JUMLAH BUTIRNYA BERBEDA) DAPAT DIUKUR PADA SKALA YANG SAMA
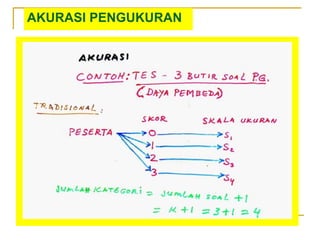
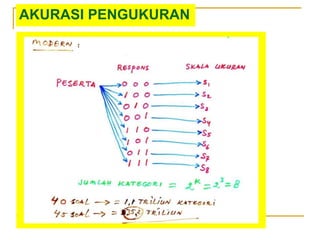
- 103. AKURASI PENGUKURAN
- 104. AKURASI PENGUKURAN
- 105. SIMULASI METODE SKORING âĒ Untuk sekedar ilustrasi tentang resiko menggunakan skor total tes, bahkan ketika asumsi unidimensionalitas telah terpenuhi, berikut penulis sajikan hasil sementara dari studi simulasi yang saat ini tengah penulis lakukan: âĒ Data simulasi dibuat memenuhi asas unidimensionalitas âĒ True scores 400 subyek ditetapkan âĒ Dibuat empat kondisi yang berbeda:
- 106. EMPAT KONDISI TES YANG DISIMULASI: 1. Strictly parallel (SP): seluruh item sama daya pembeda, sama tingkat kesukaran, dan sama varians dari âmeasurement errorâ nya. 2. Parallel (P): sama daya pembeda, sama tingkat kesukaran, tapi berbeda measurement error nya. 3. Semi-parallel (MP): yang sama hanya tingkat kesukaran nya, daya pembeda serta error variance nya berbeda. 4. Non-parallel (NP): semua karakteristik item dibuat berbeda.
- 107. SIMULASI METODE SKORING: âĒ Sebagai kondisi tambahan, ditetapkan sebuah variabel independen yang memiliki koefisien regresi sebesar 0.8 terhadap true score. âĒ Berdasarkan true score yang telah ditetapkan dan segala spesifikasi diatas, lalu dibuat data untuk 400 subyek dengan 10 item. âĒ Masing-masing kondisi (mulai dari strictly parallel sampai dengan non-parallel) dilakukan 50 replikasi . âĒ Keseluruhannya ada sebanyak 200 simulasi.
- 108. SIMULASI METODE SKORING: âĒ Pada setiap simulasi, penulis mengitung: âĒ (1) korelasi antara hasil tiga cara skoring dengan true score, dan âĒ (2) koefisien regresi dari variabel independen yang telah ditetapkan terhadap skor yang dihasilkan dengan ke tiga cara skoring tersebut. âĒ Adapun tiga cara skoring ialah: âĒ (1) skor mentah hasil menjumlahkan skor item (RAW), âĒ (2) true score hasil CFA dengan metode maximum likelihood (CFA-True), dan âĒ (3) true score hasil metode IRT (IRT-True).
- 109. SIMULASI METODE SKORING: Kriteria: âĒ Makin tinggi korelasi dengan true score yang telah ditetapkan waktu menciptakan data, berarti makin baik metode skoring tersebut âĒ Koefisien regresi yang makin mendekati nilai 0.8 (nilai aslinya), berarti makin baik metode skoring yang digunakan.
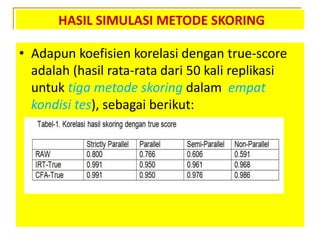
- 110. HASIL SIMULASI METODE SKORING âĒ Adapun koefisien korelasi dengan true-score adalah (hasil rata-rata dari 50 kali replikasi untuk tiga metode skoring dalam empat kondisi tes), sebagai berikut:
- 111. HASIL SIMULASI METODE SKORING: âĒ Koefisien regresi IV yang ditetapkan (hasil rata-rata dari 50 kali replikasi), sebagai berikut (nilai true-value nya adalah 0.80):
- 112. HASIL SIMULASI METODE SKORING âĒ Sangat jelas terlihat bahwa validitas dan reliabilitas raw score (cara tradisional) sangat terpengaruh jika asumsi paralel tak terpenuhi, sedangkan hasil estimasi true score baik dari IRT maupun CFA tetap memiliki validitas yang tinggi meskipun item tidak paralel. âĒ Hal ini berlaku baik ditinjau dari kriteria korelasi dengan true score asli, maupun dari sisi koefisien regresi pada suatu variabel independen.
- 113. HASIL SIMULASI METODE SKORING âĒ Hal yang menarik adalah pada hasil IRT dan CFA, baik korelasi maupun regresi, pada kondisi yang makin tidak paralel justru makin tinggi âĒ Ini menunjukkan bahwa pada IRT dan CFA, jika kondisinya tidak benar-benar paralel, sebaiknya true score dihitung dengan memperhitungkan semua karakteristik soal. âĒ Penjelasan untuk fenomena ini memerlukan analisis lebih lanjut.
- 115. METODE PENAFSIRAN SKOR TES âĒ Perkembangan metode penafsiran skor boleh dikatakan dari dahulu sampai sekarang hanya ada dua, yaitu âĒ (1) norm-referenced, dan âĒ (2) domain-referenced.
- 116. METODE PENAFSIRAN SKOR TES âĒ Kebanyakan penafsiran hasil tes psikologis pada saat ini masih menggunakan cara norm- referenced, yaitu bahwa setelah suatu tes terbukti valid, lalu dicobakan pada berbagai populasi, kemudian disusun norma statistik bagi setiap populasi tersebut âĒ Jika ada seorang di tes, maka skor yang diperoleh ditransformasikan ke dalam skor baku (dengan satuan standar deviasi), untuk kemudian ditentukan di mana kedudukan skor orang tersebut dalam norma yang sesuai untuknya.
- 117. METODE PENAFSIRAN SKOR TES âĒ Permasalahan di sini adalah bahwa orang diukur dalam kedudukan relatifnya terhadap orang lain sesuai norma yang digunakan. âĒ Jadi skor tes sama sekali tak memberikan informasi deskriptif mengenai orang diukur. âĒ Tak ada informasi tentang apa yang ia mampu atau tak mampu lakukan
- 118. METODE PENAFSIRAN SKOR TES âĒ Bisa terjadi misalnya, orang dinilai tinggi karena kebanyakan orang lain pada norma yang digunakan memiliki nilai lebih rendah dari pada dirinya, padahal sebenarnya kemampuan orang tersebut rendah âĒ Oleh sebab itu, penafsiran skor tes yang lebih baik ialah dengan pendekatan âdomain- referencedâ
- 119. PENAFSIRAN SKOR TES (CARA BARU): DOMAIN-REFERENCED (BUKAN NORMA) ï PADA SKALA UKURAN DIBUAT BAND-SCALE ï PADA SETIAP BAND-SCALE DI IDENTIFIKASI BUTIR-BUTIR YANG TINGKAT KESUKARANNYA MEWAKILI BAND-SCALE TERSEBUT ï AHLI SUBSTANSI BUTIR (CONTENT SPECIALIST) DAN PSIKOLOG YANG BERPENGALAMAN DIMINTA MEMBUAT DESKRIPSI TENTANG KEMAMPUAN YANG DIWAKILI OLEH HIMPUNAN BUTIR PADA SETIAP BAND-SCALE ï SELANJUTNYA, SETIAP ORANG YANG DITES DAPAT DIDESKRIPSIKAN KEMAMPUANNYA DENGAN MERUJUK KEPADA BAND-SCALE TERSEBUT
- 120. SYARAT UNTUK DAPAT DILAKUKAN PENAFSIRAN DOMAIN-REFERENCED ï SETIAP BUTIR TES HARUS DIVALIDASI DAN DIKALIBRASI DENGAN METODA âCFAâ DAN / ATAU âIRTâ OLEH PENGEMBANG TES ï UNTUK PENGUKURAN DENGAN AKURASI TINGGI, PENGGUNA TES HARUS MENSKOR DENGAN MENGGUNAKAN PERANGKAT LUNAK SEPERTI BILOG (HANYA IRT) ATAU MPLUS (CFA DAN IRT) ï ESTIMASI TRUE SCORE LEBIH UNGGUL IALAH DENGAN METODE âPLAUSIBLE VALUESâ, NAMUN SAAT INI HANYA TERSEDIA PADA: MPLUS
- 121. CONTOH INTERPRETASI SKOR TES SECARA DOMAIN-REFERENCED
- 122. _THANK YOU