РһРұлаСҮРҪСӢРө СӮРөС…РҪРҫР»РҫРіРёРё Рё СҖРөСҲРөРҪРёР№ ANSYS. РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё ANSYS HPC
Download as PPTX, PDF0 likes213 views

РһРұлаСҮРҪСӢРө СӮРөС…РҪРҫР»РҫРіРёРё Рё СҖРөСҲРөРҪРёР№ ANSYS. РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё ANSYS HPC
























































More Related Content
Similar to РһРұлаСҮРҪСӢРө СӮРөС…РҪРҫР»РҫРіРёРё Рё СҖРөСҲРөРҪРёР№ ANSYS. РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё ANSYS HPC (20)
More from Yury Novozhilov (20)


















РһРұлаСҮРҪСӢРө СӮРөС…РҪРҫР»РҫРіРёРё Рё СҖРөСҲРөРҪРёР№ ANSYS. РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё ANSYS HPC
- 1. РһРұлаСҮРҪСӢРө СӮРөС…РҪРҫР»РҫРіРёРё Рё СҖРөСҲРөРҪРёР№ ANSYS РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё ANSYS HPC РқРҫРІРҫжилРҫРІ Р®СҖРёР№ ВлаРҙРёСҒлавРҫРІРёСҮ Р СғРәРҫРІРҫРҙРёСӮРөР»СҢ РҪР°РҝСҖавлРөРҪРёСҸ HPC yury.novozhilov@cadfem-cis.ru
- 2. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 3. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 4. 4 РҡлаСҒСҒРёСҮРөСҒРәРёР№ DMP РҝРҫРҙС…РҫРҙ: - РәажРҙРҫРјСғ СҒРІРҫР№ РәСғСҒРҫСҮРөРә СҒРөСӮРәРё РқРҫРІСӢР№ DMP РҝРҫРҙС…РҫРҙ: - РәажРҙРҫРјСғ СҒРІРҫСҸ РҝРҫР»РҫСҒР° СҮР°СҒСӮРҫСӮ (FREQ) - РәажРҙРҫРјСғ СҒРІРҫСҸ РіР°СҖРјРҫРҪРёРәР° (CYCHI) XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 РқРҫРІСӢРө СӮРёРҝСӢ РҙРҫРјРөРҪРҪРҫР№ РҙРөРәРҫРјРҝРҫР·РёСҶРёРё РІ R18 Р’СӢСҮРёСҒлиСӮРөР»СҢ 1 Р’СӢСҮРёСҒлиСӮРөР»СҢ 4 Р’СӢСҮРёСҒлиСӮРөР»СҢ 3 Р’СӢСҮРёСҒлиСӮРөР»СҢ 2 50 150100 250200 300 350 400 0 ЧаСҒСӮРҫСӮР°, Р“СҶ Р’СӢСҮРёСҒлиСӮРөР»СҢ 1 Р’СӢСҮРёСҒлиСӮРөР»СҢ 2 Р’СӢСҮРёСҒлиСӮРөР»СҢ 3 Р’СӢСҮРёСҒлиСӮРөР»СҢ 4
- 5. 5XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 РқРҫРІСӢРө СӮРёРҝСӢ РҙРҫРјРөРҪРҪРҫР№ РҙРөРәРҫРјРҝРҫР·РёСҶРёРё РІ R18 0 20 40 60 80 100 120 140 160 8 16 32 64 128 256 РҡРҫлиСҮРөСҒСӮРІРҫРІР°СҖРёР°РҪСӮРҫРІРІСҒСғСӮРәРё РҡРҫлиСҮРөСҒСӮРІРҫ CPU СҸРҙРөСҖ РҹРҫР»РҪСӢР№ РіР°СҖРјРҫРҪРёСҮРөСҒРәРёР№ Р°РҪализ R18.0 (MESH) R18.0 (FREQ) Linear Scaling 0 20 40 60 80 100 0 16 32 48 64 РҡРҫлиСҮРөСҒСӮРІРҫРІР°СҖРёР°РҪСӮРҫРІРІСҒСғСӮРәРё РҡРҫлиСҮРөСҒСӮРІРҫ CPU СҸРҙРөСҖ РҹРҫРёСҒРә СҒРҫРұСҒСӮРІРөРҪРҪСӢС… СҮР°СҒСӮРҫСӮ Рё С„РҫСҖРј R16.2 (MESH) R17.0 (MESH) R18.0 (MESH) R18.0 (CYCHI) Linear ScalingРҳРҙРөалСҢРҪРҫ РҳРҙРөалСҢРҪРҫ x2.7 x2.6
- 6. 6 РЎСӮР°СӮРёСҮРөСҒРәР°СҸ Р·Р°РҙР°СҮР° РјРөС…Р°РҪРёРәРё РқРөлиРҪРөР№РҪР°СҸ РҝРҫСҒСӮР°РҪРҫРІРәР° РЈСҮРөСӮ РҝРҫлзСғСҮРөСҒСӮРё 6 миллиРҫРҪРҫРІ СғСҖавРҪРөРҪРёР№ РҹСҖСҸРјРҫР№ СҖРөСҲР°СӮРөР»СҢ XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 Mechanical 18.2 вҖ“ РөСүРө РұРҫР»СҢСҲРө СҸРҙРөСҖ 0 50 100 150 200 250 300 350 128 256 512 1024 2048 4096 РҡРҫлиСҮРөСҒСӮРІРҫРІР°СҖРёР°РҪСӮРҫРІРІСҒСғСӮРәРё РҡРҫлиСҮРөСҒСӮРІРҫ РҝСҖРҫСҶРөСҒСҒРҫСҖРҪСӢС… СҸРҙРөСҖ R18.1 R18.2 вҖў 16 million DOF; sparse solver вҖў Nonlinear transient analysis вҖў Linux cluster; each compute node contains 2 Intel Xeon Gold 6148 processors, 192GB RAM, SSD, RHEL 7.3 вҖў Intel Omnipath interconnect РЁР°СҖРёРәРҫРІСӢРө РәРҫРҪСӮР°РәСӮСӢ РЈРҝР°РәРҫРІРәР° СҮРёРҝР° PCB
- 7. 7 Nonlinear Adaptivity (NLAD) СӮРөРҝРөСҖСҢ РҝРҫРҙРҙРөСҖживаРөСӮСҒСҸ СҖР°СҒРҝСҖРөРҙРөлёРҪРҪСӢРј (DMP) СҖРөСҲР°СӮРөР»РөРј вҖ“ СғСҒРәРҫСҖРөРҪРёРө СҖР°СҒСҮРөСӮР° РІ СҖазСӢ XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 Р Р°СҒРҝСҖРөРҙРөлёРҪРҪСӢР№ СҖРөСҲР°СӮРөР»СҢ R18 РҙР»СҸ РҪРөлиРҪРөР№РҪСӢС… Р·Р°РҙР°СҮ 0 1 2 3 4 5 6 2 4 8 16 32 РЈСҒРәРҫСҖРөРҪРёРөСҖР°СҒСҮРөСӮР° РҡРҫлиСҮРөСҒСӮРІРҫ СҸРҙРөСҖ CPU Р РөР·РёРҪРҫРІСӢР№ СғРҝР»РҫСӮРҪРёСӮРөР»СҢ SMP DMP 0 1 2 3 4 5 6 2 4 8 16 32 РЈСҒРәРҫСҖРөРҪРёРөСҖР°СҒСҮРөСӮР° РҡРҫлиСҮРөСҒСӮРІРҫ СҸРҙРөСҖ CPU РҹСҖРҫРәР°СӮРәР° РјРөСӮала SMP DMP x3.2 x3.2
- 8. 8 РЎРөСҖРІРөСҖ: 2x Intel Xeon E5-2698v3 2.3 ГГСҶ 16 СҸРҙРөСҖ 256 Р“Рұ RAM 4x NVIDIA Tesla P100 x4 ANSYS HPC Pack x2 XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 ANSYS Fluent Рё NVIDIA Pascal 0 0.5 1 1.5 2 2.5 3 3.5 4 32 CPU СҸРҙСҖР° 28 CPU СҸРҙРөСҖ + 4 Tesla P100 РЈСҒРәРҫСҖРөРҪРёРө,СҖаз С…3.75
- 9. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 10. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 11. 11 РҳСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө CentOS РҪРө лиСҲР°РөСӮ СӮРөС…РҪРёСҮРөСҒРәРҫР№ РҝРҫРҙРҙРөСҖР¶РәРё XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 РҹРҫРҙРҙРөСҖР¶РәР° CentOS РҹРӣРҗРўРӨРһР РңРҗ 18.0 18.1 18.2 19.0 CentOS 7.2 РҙР° РҙР°** CentOS 7.3 РҙР°** РҙР° РҙР° (**) РқРө РҙР»СҸ РІСҒРөС… РҝСҖРҫРҙСғРәСӮРҫРІ ANSYS
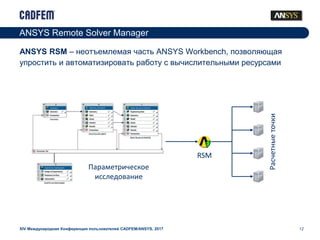
- 12. 12 ANSYS RSM вҖ“ РҪРөРҫСӮСҠРөРјР»РөРјР°СҸ СҮР°СҒСӮСҢ ANSYS Workbench, РҝРҫР·РІРҫР»СҸСҺСүР°СҸ СғРҝСҖРҫСҒСӮРёСӮСҢ Рё авСӮРҫРјР°СӮРёР·РёСҖРҫРІР°СӮСҢ СҖР°РұРҫСӮСғ СҒ РІСӢСҮРёСҒлиСӮРөР»СҢРҪСӢРјРё СҖРөСҒСғСҖСҒами XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 ANSYS Remote Solver Manager RSM РҹР°СҖамРөСӮСҖРёСҮРөСҒРәРҫРө РёСҒСҒР»РөРҙРҫРІР°РҪРёРө Р Р°СҒСҮРөСӮРҪСӢРөСӮРҫСҮРәРё
- 13. 13 Р’ СҒРҫСҒСӮавРө ANSYS СӮРөРҝРөСҖСҢ РөСҒСӮСҢ СҒРҫРұСҒСӮРІРөРҪРҪСӢР№ РұРөСҒРҝлаСӮРҪСӢР№ РҝлаРҪРёСҖРҫРІСүРёРә РҫСҮРөСҖРөРҙРё Р·Р°РҙР°СҮ РҙР»СҸ РәлаСҒСӮРөСҖР° РҝРҫРҙ Windows Рё Linux RSM вҖ“ РёРҪСӮРөСҖС„РөР№СҒ Рә ARC XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 ANSYS RSM Cluster (ARC)
- 14. 14 ANSYS RSM СғРјРөРөСӮ РёРҪСӮРөРіСҖРёСҖРҫРІР°СӮСҢСҒСҸ РІ РәлаСҒСӮРөСҖСӢ вҖў Windows HPC, PBS, UGE, Toque with MOAB, ARC ANSYS RSM РёРјРөРөСӮ РҪРҫРІСӢР№ РёРҪСӮРөСҖС„РөР№СҒ вҖў Р’СҒСӮСҖРҫРөРҪРҪРҫРө РҝСҖРёР»РҫР¶РөРҪРёРө РІ Workbench, Mechanical Рё EKM вҖў РңРөРҪСҢСҲРө РҪР°СҒСӮСҖРҫРөРә Рё СӮСҖСғРҙРҪРҫСҒСӮРөР№ СҒ РҝСҖавами РҝРҫР»СҢР·РҫРІР°СӮРөР»СҸ РҹСҖРёР»РҫР¶РөРҪРёСҸ ANSYS РҝРҫРҙРҙРөСҖживаСҺСӮ RSM вҖў CFX, Fluent, Icepak, Mechanical/APDL, Explicit STR, Rigid Body Dynamics, Polyflow, WB LS-DYNA (beta) ANSYS Electromagnetics Suite СғРјРөРөСӮ СҖР°РұРҫСӮР°СӮСҢ СҒ ARC вҖў Р—Р°РҝСғСҒРә СҖР°СҒСҮРөСӮР° СӮРҫР»СҢРәРҫ СҮРөСҖРөР· EKM XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 Р§СӮРҫ СғРјРөРөСӮ ANSYS RSM Рё ARC
- 15. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 16. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 17. 17 CFD Enterprise/Solver Рё CFD Premium/Solve 4 РұРөСҒРҝлаСӮРҪСӢС… СҸРҙСҖР° CPU XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 ANSYS CFD
- 18. 18XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 РЎСҶРөРҪР°СҖРёРё РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёСҸ + ANSYS CFD Enterprise/Premium 4-С… СҸРҙРөСҖРҪР°СҸ СҖР°РұРҫСҮР°СҸ СҒСӮР°РҪСҶРёСҸ 8-С… СҸРҙРөСҖРҪР°СҸ СҖР°РұРҫСҮР°СҸ СҒСӮР°РҪСҶРёСҸ + ANSYS CFD Enterprise/Premium + ANSYS HPC x4 20-СӮРё СҸРҙРөСҖРҪСӢР№ СҒРөСҖРІРөСҖ + ANSYS CFD Enterprise/Premium + ANSYS HPC Workgroup 16
- 19. 19 РҹРөСҖРІСӢР№ ANSYS HPC Pack РҙР°РөСӮ 10 СҸРҙРөСҖ РҪР° СҖР°СҒСҮРөСӮ XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 ANSYS HPC Pack 1x ANSYS HPC Pack = 10 HPC РҝРҫСӮРҫРәРҫРІ 8 CPU СҸРҙРөСҖ + 2 GPU СҮРёРҝР° 6 CPU СҸРҙРөСҖ + 4 GPU СҮРёРҝР° 24 CPU СҸРҙСҖР° + 8 GPU СҮРёРҝРҫРІ (2-С… СғР·Р»РҫРІРҫР№ РәлаСҒСӮРөСҖ) 2x ANSYS HPC Pack = 32 HPC РҝРҫСӮРҫРәР°
- 20. РЈР»СғСҮСҲРөРҪРёСҸ РІ СҖР°РұРҫСӮРө СҖРөСҲР°СӮРөР»РөР№ РқРҫРІСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝлаСӮС„РҫСҖРјСӢ РӣРёСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° HPC R18
- 22. 22XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 Р’СҒСӮСҖРҫРөРҪРҪСӢРө РІРҫР·РјРҫР¶РҪРҫСҒСӮРё РҝРҫ СҖР°СҒРҝР°СҖаллРөливаРҪРёСҺ 1 вҖ“ 2 2 4 1 4 4 1 1 4 R17 R18 R19
- 23. ANSYS HPC ANSYS HPC Workgroup ANSYS HPC Pack 23XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 ANSYS HPC Pack (EM) R17 R18 R19 ANSYS Electronics HPC ANSYS Electronics HPC Workgroup ANSYS Electronics HPC Pack ANSYS HPC ANSYS HPC Workgroup ANSYS HPC Pack
- 24. 24XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 РЈРҪифиРәР°СҶРёСҸ лиСҶРөРҪР·РёРҫРҪРҪРҫР№ РҝРҫлиСӮРёРәРё 4 + 2 HPC = 4 + 2 = 6 + HPC Workgroup 16 = 4 + 16 = 20 + 1 HPC Pack = 4 + 8 = 12 + 2 HPC Pack = 4 + 32 = 36 РўР°Рә РұСғРҙРөСӮ РҙР»СҸ Р»СҺРұРҫРіРҫ СҖРөСҲР°СӮРөР»СҸ ANSYS
- 26. РһРұРҪРҫРІР»РөРҪРҪСӢР№ СҖРөСҲР°СӮРөР»СҢ Mechanical РҝР°СҖаллРөлиСӮСҒСҸ РұРҫР»РөРө СҮРөРј РҪР° 3000 СҸРҙРөСҖ ANSYS ARC вҖ“ РҝРҫР»РҪРҫСҶРөРҪРҪСӢР№ РәлаСҒСӮРөСҖРҪСӢР№ РҝлаРҪРёСҖРҫРІСүРёРә РҫСҮРөСҖРөРҙРё Р·Р°РҙР°СҮ 4 СҸРҙСҖР° РҙР»СҸ CFD СҒРөР№СҮР°СҒ Рё РҪРҫРІР°СҸ лиСҶРөРҪР·РёРҫРҪРҪР°СҸ РҝРҫлиСӮРёРәР° РҙР»СҸ R19
- 27. 27XIV РңРөР¶РҙСғРҪР°СҖРҫРҙРҪР°СҸ РҡРҫРҪС„РөСҖРөРҪСҶРёСҸ РҝРҫР»СҢР·РҫРІР°СӮРөР»РөР№ CADFEM/ANSYS, 2017 Р‘РҫР»РөРө РҝРҫРҙСҖРҫРұРҪР°СҸ РҙРҫРәСғРјРөРҪСӮР°СҶРёСҸ https://www.cadfem-cis.ru/products/ansys/hpc/
- 28. РЎРҝР°СҒРёРұРҫ Р·Р° РІРҪРёРјР°РҪРёРө! РқРҫРІРҫжилРҫРІ Р®СҖРёР№ ВлаРҙРёСҒлавРҫРІРёСҮ Р СғРәРҫРІРҫРҙРёСӮРөР»СҢ РҪР°РҝСҖавлРөРҪРёСҸ HPC yury.novozhilov@cadfem-cis.ru
Editor's Notes
- #7: This slide demonstrates the improved scaling of Distributed ANSYS in R18.2 compared to R18.0. This is a ball grid array (BGA) benchmark from MicroConsult in Germany involving a nonlinear transient analysis with creep material properties (no contact). The sparse solver is used to solve the 4 million equations. There is 1 load step with 12 substeps and a total of 25 iterations to reach convergence in the nonlinear analysis. This model was solved on the Intel Endeavor cluster. Each compute node contains 2 Intel Xeon Gold 6148 (Skylake) processors, 192 GB of RAM, local SSD storage, and RHEL7.3. These runs were performed with the Intel Omnipath interconnect. Here we are timing the вҖңElapsed time spent computing solutionвҖқ. So this measures the entire solution (forming elements, solving the equations, computing stresses/strains, etc..), but does not include items such as resuming the database or combining files at the end of the solution. One can easily see that with R18.0 the scaling stops at approximately 1000 cores. However, with R18.2 the scaling continues to at least 3072 cores.