








![12 / 88 KYOTO UNIVERSITY
KL •ņ•§•–©`•ł•ß•ů•Ļ§Ō“™ňō§őĺŗŽx§ÚŅľĎ]§«§≠§ §§
™ę
ö›ő¬§Ú•Į•ť•Ļ∑÷Óź§ň§Ť§Í”Ťúy§Ļ§ŽÜĖÓ}§ÚŅľ§®§Ž
™ę
KL •ņ•§•–©`•ł•ß•ů•Ļ§Ú”√§§§Ž§»°Ę“™ňō§ī§»§őļÕ§»§ §Ž§ő§«°Ę
«ŗ?≥ŗ§őĺŗŽx§»«ŗ?ĺv§őĺŗŽx§ŌÕ¨§ł
21
22
23
24
25
26
27
28
29
21
22
23
24
25
26
27
28
29
=](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-12-320.jpg)
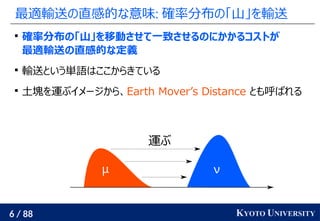
![13 / 88 KYOTO UNIVERSITY
◊ÓŖm›ĒňÕ§Ō“™ňō§…§¶§∑§őĺŗŽx§ÚŅľĎ]§«§≠§Ž
™ę
◊ÓŖm›ĒňÕ§Ú”√§§§Ž§»°Ę«ŗ?≥ŗ§ő∑ŧ¨›ĒňÕ§ň§ę§ę§Ž•≥•Ļ•»§¨…Ŕ§ §§§ő§«
ĺŗŽx§¨–°§Ķ§§§»Ň–∂®§Ķ§ž§Ž
™ę
22 ∂»§Ú 23 ∂»§»ťgŖ`§®§∆§§§Ž§ņ§Ī§ §ő§«°Ę22 ∂»§Ú 28 ∂»§»
ťgŖ`§®§Ž§Ť§ÍĺŗŽx§¨–°§Ķ§§§»Ň–∂®§Ķ§ž§Ž§ő§Ō÷Īł–§ňŖmļŌ§∑§∆§§§Ž
21
22
23
24
25
26
27
28
29
21
22
23
24
25
26
27
28
29
<](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-13-320.jpg)

















![31 / 88 KYOTO UNIVERSITY
POT §ő Ļ”√ņż: ļÜÖg§ň Ļ§®§ř§Ļ
™ę
żāéņż: ∂Ģ§ń§ő’ż“é∑÷≤ľ§ę§ť§őĶ„»ļ§őĪ»›^
import numpy as np
import matplotlib.pyplot as plt
import ot # POT •ť•§•÷•ť•Í
n = 100 # Ķ„»ļ•Ķ•§•ļ
mu = np.random.randn(n, 2) # »ŽŃ¶∑÷≤ľ 1
nu = np.random.randn(n, 2) + 1 # »ŽŃ¶∑÷≤ľ 2
a = np.ones(n) / n # Ŕ|ŃŅ•“•Ļ•»•į•ť•ŗ (1/n, ..., 1/n)
b = np.ones(n) / n # Ŕ|ŃŅ•“•Ļ•»•į•ť•ŗ (1/n, ..., 1/n)
C = np.linalg.norm(nu[np.newaxis] - mu[:, np.newaxis], axis=2) # •≥•Ļ•»––Ń–
P = ot.emd(a, b, C) # ◊ÓŖm›ĒňÕĺŗŽx§ő”čň„
plt.scatter(mu[:, 0], mu[:, 1]) # mu §ő…Ę≤ľáŪ√Ť–ī
plt.scatter(nu[:, 0], nu[:, 1]) # nu §ő…Ę≤ľáŪ√Ť–ī
for i in range(n):
j = P[i].argmax() # i §őĆĚŹÍŌŗ ÷: ◊Ó§‚§Ņ§Į§Ķ§ů›ĒňÕ§∑§∆§§§ŽŌ»
plt.plot([mu[i, 0], nu[j, 0]], [mu[i, 1], nu[j, 1]], c='grey', zorder=-1)
°Ł •≥•‘•ŕ§«‘᧼§ř§Ļ](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-31-320.jpg)












![44 / 88 KYOTO UNIVERSITY
•∑•ů•Į•Ř©`•ůČš ż§ę§ť‘™§őČš ż§ō§őĎݧ∑∑Ĺ
™ę
•∑•ů•Į•Ř©`•ů§ň§Ť§Í (u, v) §¨«ů§ř§Ž§»°ĘČš żČšďQ§ő ŧŤ§Í‘™§ő
ňęĆĚČš ż§Ō
™ę
÷ųÜĖÓ}§őČš ż§ŌňęĆĚ◊ÓŖmĹ‚§»÷ų◊ÓŖmĹ‚§őĆĚŹÍťvāS§Ť§Í
f, g §¨ÕÍŤĶ§ňÖß Ý§∑§ §§Ōř§Í°Ę«ů§Š§Ņ Pij
§ŌÖó√‹§ň§ŌĆg––Ņ…ń‹§»§Ō
Ōř§ť§ §§§≥§»§ň◊Ę“‚£®Ćg”√…Ō§Ō∂ŗ…Ŕ§ő’`≤Ó§ŌÜĖÓ}§ §§§≥§»§‚∂ŗ§§£©
™ę §≥§ő Pij
§ę§ťŖ`∑ī∑÷§Ú§§§§ł–§ł§ň∑÷Ňš§∑§∆Ćg––Ņ…ń‹Ĺ‚§Ú”čň„§Ļ§Ž
•Ę•Ž•ī•Í•ļ•ŗ§‚ŐŠįł§Ķ§ž§∆§§§Ž [Altschuler+ 2017]
Jason Altschuler, Jonathan Weed, Philippe Rigollet. Near-linear time approximation algorithms for optimal transport
via Sinkhorn iteration. NeurIPS 2017.](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-44-320.jpg)

![46 / 88 KYOTO UNIVERSITY
•∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ: ņż
import numpy as np
import matplotlib.pyplot as plt
n, m = 4, 4
C = np.array([
[0, 2, 2, 2],
[2, 0, 1, 2],
[2, 1, 0, 2],
[2, 2, 2, 0]])
a = np.array([0.2, 0.5, 0.2, 0.1])
b = np.array([0.3, 0.3, 0.4, 0.0])
eps = 0.2 # īů§≠§§§»łŖňŔ§ň°Ę–°§Ķ§§§»Öó√‹§ň
K = np.exp(- C / eps) # •ģ•÷•Ļ•ę©`•Õ•Ž§ő”čň„
u = np.ones(n) # §Ļ§Ŕ§∆ 1 §«≥ű∆ŕĽĮ
for i in range(100):
v = b / (K.T @ u) # •Ļ•∆•√•◊ (2)
u = a / (K @ v) # •Ļ•∆•√•◊ (3)
f = eps * np.log(u + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ
g = eps * np.log(v + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ
P = u.reshape(n, 1) * K * v.reshape(1, m) # ÷ųĹ‚
plt.pcolor(P, cmap=plt.cm.Blues) # Ĺ‚§őŅ…“ēĽĮ
°Ż •≥•‘•ŕ§«‘᧼§ř§Ļ
•Š•§•ů•Ū•ł•√•Į§Ō§Ô§ļ§ę 3 ––
°Ł •®•ů•»•Ū•‘©`§ §∑§őĹ‚§»§Ř§‹“Ľ÷¬
£®◊ůŌ¬§¨ (1, 1) §«§Ę§Ž§≥§»§ň◊Ę“‚£©
Õ‚≤Ņ•ť•§•÷•ť•Í§ňÓm§ť§ §§](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-46-320.jpg)










![57 / 88 KYOTO UNIVERSITY
•Ĺ©`•Ļ•≥©`•…»ę√≤
import matplotlib.pyplot as plt
import torch
import torch.optim
import torch.nn
# •«©`•Ņ…ķ≥…
torch.manual_seed(0)
x = torch.rand(20, 2)
y = torch.rand(20, 2) +
torch.FloatTensor([0, 2])
z = torch.rand(20, 2) +
torch.FloatTensor([1, 1])
mu = torch.cat([x, y, z])
nu = torch.rand(12, 2) * 2
nu = torch.nn.parameter.Parameter(nu)
n, m = len(mu), len(nu)
a = torch.ones(n) / n
b = torch.ones(m) / m
optimizer = torch.optim.SGD([nu], lr=1.0)
for it in range(100):
eps = 0.1
D = torch.linalg.norm(mu.reshape(n, 1, 2) -
nu.reshape(1, m, 2), axis=2)
K = torch.exp(- D / eps) # •ģ•÷•Ļ•ę©`•Õ•Ž§ő”čň„
u = torch.ones(n) # §Ļ§Ŕ§∆ 1 §«≥ű∆ŕĽĮ
for i in range(100):
v = b / (K.T @ u) # •Ļ•∆•√•◊ (2)
u = a / (K @ v) # •Ļ•∆•√•◊ (3)
f = eps * torch.log(u + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ
g = eps * torch.log(v + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ
P = u.reshape(n, 1) * K * v.reshape(1, m) # ÷ųĹ‚
loss = (P * D).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.clf()
plt.scatter(mu[:, 0], mu[:, 1])
plt.scatter(nu.data[:, 0], nu.data[:, 1])
plt.show()
•≥•‘•ŕ§«‘᧼§ř§Ļ](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-57-320.jpg)
![58 / 88 KYOTO UNIVERSITY
◊Ó–¬§ő ÷∑®§«§‚Ļę∆Ĺ”ŤúyÜĖÓ}§ň•∑•ů•Į•Ř©`•ů§¨ Ļ§Ô§ž§Ž
™ę
ňŻ§ň§‚°Ę∂Ģ§ń§őľĮļŌ§őĺŗŽx§ÚĹŁ§Ň§Ī§Ž§Ņ§Š§őőĘ∑÷Ņ…•Ū•Ļ§»§∑§∆ Ļ§Ô§ž§Ž
™ę
ņż§®§–°ĘĻę∆Ĺ–‘§őĶ£Ī£§ő§Ņ§Š°Ęń––‘§ň§ń§§§∆§ő”Ťúy§»Ňģ–‘§ň§ń§§§∆§ő
”Ťúy∑÷≤ľ§¨Õ¨§ł§Ť§¶§ň§∑§Ņ§§
™ę
”Ťúy’`≤Ó + ≥ŗ§»«ŗ§ő◊ÓŖm›ĒňÕĺŗŽx§Ú◊Ó–°ĽĮ [Oneto+ NeurIPS 2020]
Luca Oneto, Michele Donini, Giulia Luise, Carlo Ciliberto, Andreas Maurer, Massimiliano Pontil. Exploiting
MMD and Sinkhorn Divergences for Fair and Transferable Representation Learning. NeurIPS 2020.
•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į
»ŽŃ¶
d īő‘™•Ŕ•Į•»•Ž§¨
≥Ų§∆§Į§Ž
Rd
”Ťúy∆ų
≥ŲѶ
łųÕŤ§Ōłų•Ķ•ů•◊•Ž§ő
¬Ů§Šřz§Ŗ
≥ŗ: Ňģ–‘•Ķ•ů•◊•Ž
«ŗ: ń––‘•Ķ•ů•◊•Ž](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-58-320.jpg)











![70 / 88 KYOTO UNIVERSITY
•—•ť•Š©`•Ņ§őāé§ÚüoņŪ§š§Í÷∆Ōř§∑§∆•Í•◊•∑•√•ń–‘§Ú’n§Ļ
™ę
Ĺ‚õQ≤Ŗ 1: weight clipping [Arjovsky+ 2017]
™ę
”Ėĺö§őŽH•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őłų•—•ť•Š©`•Ņ§őĹ~ĆĚā駨
∂® ż ¶√ > 0 §Ú‘ŧ®§Ž§Ņ§”§ňĹ~ĆĚāé ¶√ §ň•Į•Í•√•◊§Ļ§Ž£®¶√:•Ō•§•—•ť£©
™ę
§≥§¶§Ļ§Ž§»°Ę•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į f §őĪŪ¨F§«§≠§Žťv ż§Ō÷∆Ōř§Ķ§ž
ľĪľ§§ ČšĽĮ§Ú§Ļ§Žťv ż§ŌĪŪ§Ľ§ §Į§ §Ž
™ę
¶√ §ő‘O∂®īőĶ৫°Ęļő§ť§ę§ő k > 0 §ň§ń§§§∆ k-•Í•◊•∑•√•ń§«§Ę§Ž§≥§»§¨
Ī£‘^§«§≠§Ž
™ę
k-•Í•◊•∑•√•ń§ ťv ż»ę§∆§ÚĪŪ¨F§«§≠§Ž‘U§«§Ō§ §§§¨°Ę•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`
•Į§ő»Š‹õ–‘§Ť§Í§Ĺ§ž§ §Í§ňōNłĽ§ ťv ż§¨ĪŪ¨F§«§≠§Ž§≥§»§¨∆ŕīż§«§≠§Ž
Martin Arjovsky, Soumith Chintala, L®¶on Bottou. Wasserstein GAN. ICML 2017](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-70-320.jpg)
![71 / 88 KYOTO UNIVERSITY
łųĶ„§«§őĻīŇš§¨ 1 §ę§ťŽx§ž§Ž§»•ŕ• •Ž•∆•£
™ę
Ĺ‚õQ≤Ŗ 2: gradient penalty [Gulrajani+ 2017]
™ę
f §¨őĘ∑÷Ņ…§ő§»§≠łųĶ„§«§őĻīŇš§ő•ő•Ž•ŗ§¨ 1 “‘Ō¬ ? 1-•Í•◊•∑•√•ń
™ę
…ę§ů§ Ķ„§«ĻīŇš§Ú‘uĀż§∑§∆ 1 §ę§ťŽx§ž§∆§§§Ņ§ť•ŕ• •Ž•∆•£§Ú’n§Ļ
§Ú•Ū•Ļ§»§∑§∆◊ÓŖmĽĮ
Ishaan Gulrajani, Faruk Ahmed, Mart®™n Arjovsky, Vincent Dumoulin, Aaron C. Courville.. Improved
Training of Wasserstein GANs. NeurIPS 2017
•Ō•§•—•ť’żĄtĽĮāS ż
ĻīŇš§Ú 1 §ňĹŁ§Ň§Ī§Ž](https://image.slidesharecdn.com/ibis2021tutorialot-220311073419/85/-71-320.jpg)















































More Related Content
What's hot (20)
Similar to ◊Ó šňÕ»Ž√Ň (20)
![[DL›Ü’iĽŠ]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=560&fit=bounds)
![[’iĽŠ]Logistic regression models for aggregated data](https://cdn.slidesharecdn.com/ss_thumbnails/logisticregressionmodelsforaggregateddata-211229094148-thumbnail.jpg?width=560&fit=bounds)
















More from joisino (10)










◊Ó šňÕ»Ž√Ň
- 1. 1 KYOTO UNIVERSITY KYOTO UNIVERSITY ◊Ó šňÕ»Ž√Ň ◊ŰŐŔłoŮR @IBIS 2021 •Ń•Ś©`•»•Í•Ę•Ž
- 2. 2 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§Ōī_¬ ∑÷≤ľ§ÚĪ»›^§Ļ§Ž•ń©`•Ž ™ę §≥§ő•Ń•Ś©`•»•Í•Ę•Ž§ő•»•‘•√•Į: ◊ÓŖm›ĒňÕ ™ę Óźň∆•ń©`•Ž: KL•ņ•§•–©`•ł•ß•ů•Ļ, MMD ™ę §≥§ő•Ń•Ś©`•»•Í•Ę•Ž§«§Ō ™ę KL •ņ•§•–©`•ł•ß•ů•Ļ§ňĪ»§Ŕ§Ņ◊ÓŖm›ĒňÕ§őÉ짞§ŅĶ„§Ú÷™§Ž ™ę ◊ÓŖm›ĒňÕ§ő•Ę•Ž•ī•Í•ļ•ŗ§Ú÷™§Ž §Ú§Š§∂§∑§ř§Ļ ◊ÓŖm›ĒňÕ§Ōī_¬ ∑÷≤ľ§»ī_¬ ∑÷≤ľ§ÚĪ»›^§Ļ§Ž§ő§ň Ļ§®§Ž•ń©`•Ž take home message
- 3. 3 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§ő÷Īł–Ķń§ Ćß»Ž§»•Š•Í•√•»
- 4. 4 / 88 KYOTO UNIVERSITY ∑÷≤ľĪ»›^§őņż: •ę•∆•ī•Í”Ťúy ™ę ī_¬ ∑÷≤ľ§őĪ»›^§ŌôC–Ķ—ßŃē§ő§Ę§ť§ś§ŽąŲ√ś§«Ķ«ąŲ§Ļ§Ž ™ę ņż1: •ę•∆•ī•Í”Ťúy§ő•Ū•Ļťv ż ™ę •Į•Ū•Ļ•®•ů•»•Ū•‘©`£®KL •ņ•§•–©`•ł•ß•ů•Ļ£©§¨”–√Ż dog cat lion bird dog cat lion bird ”Ťúy∑÷≤ľ ’żĹ‚•ť•Ŕ•Ž ĺŗŽx = •Ū•Ļ
- 5. 5 / 88 KYOTO UNIVERSITY ∑÷≤ľĪ»›^§őņż: …ķ≥…•‚•«•Ž ™ę ī_¬ ∑÷≤ľ§őĪ»›^§ŌôC–Ķ—ßŃē§ő§Ę§ť§ś§ŽąŲ√ś§«Ķ«ąŲ§Ļ§Ž ™ę ņż2: …ķ≥…•‚•«•Ž§ő•Ū•Ļťv ż …ķ≥…•Ķ•ů•◊•Ž§őĹUÚY∑÷≤ľ ”Ėĺö•Ķ•ů•◊•Ž§őĹUÚY∑÷≤ľ ĺŗŽx = •Ū•Ļ Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICLR 2018. https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- 6. 6 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§ő÷Īł–Ķń§ “‚ő∂: ī_¬ ∑÷≤ľ§ő°ł…Ĺ°Ļ§Ú›ĒňÕ ™ę ī_¬ ∑÷≤ľ§ő°ł…Ĺ°Ļ§Ú“∆Ą”§Ķ§Ľ§∆“Ľ÷¬§Ķ§Ľ§Ž§ő§ň§ę§ę§Ž•≥•Ļ•»§¨ ◊ÓŖm›ĒňÕ§ő÷Īł–Ķń§ ∂®Ńx ™ę ›ĒňÕ§»§§§¶Ög’Z§Ō§≥§≥§ę§ť§≠§∆§§§Ž ™ę ÕŃČK§ÚŖ\§÷•§•Š©`•ł§ę§ť°ĘEarth Mover°Įs Distance §»§‚ļۧ–§ž§Ž ¶Ő ¶Õ Ŗ\§÷
- 7. 7 / 88 KYOTO UNIVERSITY •“•Ļ•»•į•ť•ŗĪ»›^§őąŲļŌ§őņż ™ę •Į•ť•Ļī_¬ £®•“•Ļ•»•į•ť•ŗ£©Ī»›^§őąŲļŌ ™ę łų•Į•ť•Ļ§ę§ťňŻ§ő•Į•ť•Ļ§ō…ŧړ∆Ą”§Ķ§Ľ§Ž•≥•Ļ•»§Ú»ň ÷§«∂®§Š§Ž cat °ķ lion §Ō cat °ķ bird §Ť§Í§‚ĶÕ•≥•Ļ•»§»§§§¶÷™◊R§Úřz§Š§∆§‚§Ť§§ ™ę ¶Ő §ő…ŧړ∆Ą”§Ķ§Ľ§∆ ¶Õ §ň“Ľ÷¬§Ķ§Ľ§Ž•≥•Ļ•»§¨◊ÓŖm›ĒňÕĺŗŽx £®¶Õ §ő…ŧړ∆Ą”§Ķ§Ľ§∆ ¶Ő §ő…ŧň“∆Ą”§Ķ§Ľ§Ž§»§∑§∆§‚•≥•Ļ•»§ŌÕ¨§ł£© dog cat lion bird dog cat lion bird ¶Ő ¶Õ ≤ĽĄ” ≤ĽĄ” ≤ĽĄ” dog §ō lion §ō
- 8. 8 / 88 KYOTO UNIVERSITY Ķ„»ļĪ»›^§őąŲļŌ§őņż ™ę ŖBĺA∑÷≤ľ§őĹUÚY∑÷≤ľ£®Ķ„»ļ£©Ī»›^§őąŲļŌ ™ę łųĶ„§ňŔ|ŃŅ 1/n §ő…į…ŧ¨§Ę§Ž§»Ņľ§®§Ĺ§ő›ĒňÕĺŗŽx§ÚŅľ§®§Ž
- 9. 9 / 88 KYOTO UNIVERSITY ◊ÓŖm§ ›ĒňÕ§ň§ń§§§∆§ő•≥•Ļ•»§Ú”√§§§∆ĺŗŽx§Ú∂®Ńx§Ļ§Ž ™ę ›ĒňÕ§ő ň∑ŧŌ—} żÕ®§Í§Ę§Ž§¨°Ę◊Ó§‚•≥•Ļ•»§¨…Ŕ§ §§›ĒňÕ∑Ĺ∑®§ÚŖx§÷ •“•Ļ•»•į•ť•ŗ§őąŲļŌ§‚Õ¨ėĒ ™ę °ł◊ÓŖm°Ļ§»§§§¶—‘»~§Ō§≥§≥§ę§ť§≠§∆§§§Ž ◊ÓŖm§«§Ō§ §§›ĒňÕ§őņż
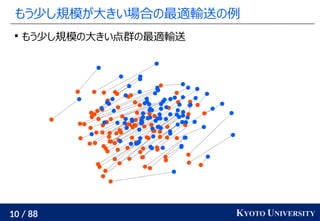
- 10. 10 / 88 KYOTO UNIVERSITY §‚§¶…Ŕ§∑“éń£§¨īů§≠§§ąŲļŌ§ő◊ÓŖm›ĒňÕ§őņż ™ę §‚§¶…Ŕ§∑“éń£§őīů§≠§§Ķ„»ļ§ő◊ÓŖm›ĒňÕ
- 11. 11 / 88 KYOTO UNIVERSITY KL •ņ•§•–©`•ł•ß•ů•Ļ§Ō“™ňō§ī§»§őŪó§őļÕ ™ę KL •ņ•§•–©`•ł•ß•ů•Ļ§»§őĪ»›^§ÚÕ®§∑§∆◊ÓŖm›ĒňÕ§őņŻĶ„§Úī_’J§Ļ§Ž ™ę Žx…Ę∑÷≤ľ§Ō n īő‘™§ő•Ŕ•Į•»•Ž p §«ĪŪ¨F§«§≠§Ž pi §Ō i ∑¨ńŅ§ő“™ňō§őī_¬ āé ™ę KL •ņ•§•–©`•ł•ß•ů•Ļ: ™ę “™ňō§ī§»§ň∂ņŃʧňŪó§Ú◊„§∑ļŌ§Ô§Ľ§∆§§§Ž§ő§¨•›•§•ů•»
- 12. 12 / 88 KYOTO UNIVERSITY KL •ņ•§•–©`•ł•ß•ů•Ļ§Ō“™ňō§őĺŗŽx§ÚŅľĎ]§«§≠§ §§ ™ę ö›ő¬§Ú•Į•ť•Ļ∑÷Óź§ň§Ť§Í”Ťúy§Ļ§ŽÜĖÓ}§ÚŅľ§®§Ž ™ę KL •ņ•§•–©`•ł•ß•ů•Ļ§Ú”√§§§Ž§»°Ę“™ňō§ī§»§őļÕ§»§ §Ž§ő§«°Ę «ŗ?≥ŗ§őĺŗŽx§»«ŗ?ĺv§őĺŗŽx§ŌÕ¨§ł 21 22 23 24 25 26 27 28 29 21 22 23 24 25 26 27 28 29 =
- 13. 13 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§Ō“™ňō§…§¶§∑§őĺŗŽx§ÚŅľĎ]§«§≠§Ž ™ę ◊ÓŖm›ĒňÕ§Ú”√§§§Ž§»°Ę«ŗ?≥ŗ§ő∑ŧ¨›ĒňÕ§ň§ę§ę§Ž•≥•Ļ•»§¨…Ŕ§ §§§ő§« ĺŗŽx§¨–°§Ķ§§§»Ň–∂®§Ķ§ž§Ž ™ę 22 ∂»§Ú 23 ∂»§»ťgŖ`§®§∆§§§Ž§ņ§Ī§ §ő§«°Ę22 ∂»§Ú 28 ∂»§» ťgŖ`§®§Ž§Ť§ÍĺŗŽx§¨–°§Ķ§§§»Ň–∂®§Ķ§ž§Ž§ő§Ō÷Īł–§ňŖmļŌ§∑§∆§§§Ž 21 22 23 24 25 26 27 28 29 21 22 23 24 25 26 27 28 29 <
- 14. 14 / 88 KYOTO UNIVERSITY KL §Ō•Ķ•›©`•»§¨ĪĽ§√§∆§§§ §§§» Ļ§®§ §§ ™ę ŖBĺA∑÷≤ľ§őĹUÚY∑÷≤ľ£®Ķ„»ļ£©Ī»›^§ÚŅľ§®§Ž ™ę KL §Ō•Ķ•›©`•»§¨ĪĽ§√§∆§§§ §§§»ĺŗŽx§¨ °ř §»Ň–∂Ō§Ķ§ž§Ž °ķ ŖBĺA∑÷≤ľ§őĹUÚY∑÷≤ľ§őĪ»›^§¨§«§≠§ §§ ĹUÚY∑÷≤ľ§ň§™§§§∆§Ō°Ę§Ń§Á§¶§…§≥§őĶ„§ň§™§Ī§Ž «ŗ§őī_¬ §Ō•ľ•Ū§»Ň–∂Ō§Ķ§ž§Ž °ķ - log 0 §őŪó§¨Ķ«ąŲ§∑§∆ KL = °ř ī_¬ ā駨’ż§Ú»°§ŽĶ„ľĮļŌ
- 15. 15 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§Ō•Ķ•›©`•»§¨ĪĽ§√§∆§§§ §Į§∆§‚ Ļ§®§Ž ™ę ◊ÓŖm›ĒňÕ§Ō›ĒňÕ§»§§§¶łŇńÓ§ő§™§ę§≤§«•Ķ•›©`•»§¨ĪĽ§√§∆§§§ §§§»§≠§ň§‚ ņŻ”√§«§≠§Ž
- 16. 16 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§Ō∑÷≤ľ§őĆĚŹÍťvāS§ÚĶ√§Ž§≥§»§¨§«§≠§Ž ™ę ◊ÓŖm›ĒňÕ§ŌłĪģbőÔ§»§∑§∆°Ę∑÷≤ľ§őĆĚŹÍťvāS§ÚĶ√§Ž§≥§»§¨§«§≠§Ž ™ę ’ż“é∑÷≤ľ§őĆĚŹÍťvāS: ∑÷≤ľ§¨§ļ§ž§∆§§§∆§‚°Ę§ļ§ž§Ú–ř’ż§Ļ§Ž§Ť§¶§ ĆĚŹÍťvāS§¨Ķ√§ť§ž§Ž
- 17. 17 / 88 KYOTO UNIVERSITY ŹÍ”√: ◊ÓŖm›ĒňÕ§Ō…ęŌŗČšďQ§ň§‚ņŻ”√§«§≠§Ž ™ę »ŽŃ¶: …ęŌŗ§őģź§ §Ž∂Ģ§ń§őĽ≠ŌŮ ™ę •‘•Į•Ľ•Ž§Ú RGB Ņ’ťgńŕ§ň§™§≠°ĘĽ≠ŌŮ§Ú RGB Ņ’ťgńŕ§őĶ„»ļ§»§Ŗ§Ž °ķ ∂Ģ§ń§őĶ„»ļ§ő◊ÓŖm›ĒňÕ§Ú”čň„ °ķ Ķ√§ť§ž§ŅĆĚŹÍťvāS§Ú§‚§»§ň°Ę•‘•Į•Ľ•Ž§ő…ę§Ú÷√ďQ§Ļ§Ž ™ę ≥ŲѶ: …ęŌŗ§Ú»Ž§žŐś§®§Ņ∂Ģ§ń§őĽ≠ŌŮ Gabriel Peyr®¶. Optimal Transport in Imaging Sciences. 2012. /gpeyre/optimal-transport-in-imaging-sciences
- 18. 18 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§Ō KL §őŌřĹÁ§ÚŅň∑Ģ§«§≠§Ž ™ę ◊ÓŖm›ĒňÕ§ř§»§Š: ™ę ◊ÓŖm›ĒňÕ§ŌĺŗŽxėč‘ž§ÚņŻ”√§«§≠§Ž £®? KL §Ō§«§≠§ §§£© ™ę ◊ÓŖm›ĒňÕ§Ō•Ķ•›©`•»§¨ĪĽ§√§∆§§§ §§§»§≠§ň§‚ņŻ”√§«§≠§Ž £®? KL §Ō§«§≠§ §§£© ™ę ◊ÓŖm›ĒňÕ§Ō∑÷≤ľ§őĆĚŹÍťvāS§ÚĶ√§Ž§≥§»§¨§«§≠§Ž £®? KL §Ō§«§≠§ §§£© ™ę Ķ„§…§¶§∑§ň◊‘»Ľ§ ĺŗŽx§ÚĆß»Ž§«§≠§Ž§»§≠§ň§Ō◊ÓŖm›ĒňÕ•Ń•„•ů•Ļ °ł√®°Ļ §» °ł•ť•§•™•ů°Ļ §Ō °ł√®°Ļ §» °łÝB°Ļ §Ť§ÍĹŁ§§£®•Į•ť•Ļ∑÷Óź£© ő¬∂»§ő§Ť§¶§ Ūė–Ú≥Ŗ∂» •ś©`•Į•Í•√•…Ņ’ťg…Ō§őĶ„»ļ
- 19. 19 / 88 KYOTO UNIVERSITY KL §Ú◊ÓŖm›ĒňÕ§ň÷√§≠ďQ§®§Ž§≥§»§ÚŐŠįł§Ļ§Ž’ďőń§Ņ§Ń ™ę ĆgŽH°ĘKL §Ú◊ÓŖm›ĒňÕ§ň÷√§≠ďQ§®§ŽŐŠįł§¨§Ķ§ř§∂§ř§ őń√}§« § §Ķ§ž§∆§§§Ž ™ę Arjovsky et al. Wasserstein GAN. ICML 2017. GAN §ő•Ū•Ļ§Ú JS •ņ•§•–©`•ł•ß•ů•Ļ§ę§ť◊ÓŖm›ĒňÕĺŗŽx§ň ™ę Frogner et al. Learning with Wasserstein Loss. NeurIPS 2015. •ř•Ž•Ń•Į•ť•Ļ∑÷Óź§ő•Ū•Ļ§Ú•Į•Ū•Ļ•®•ů•»•Ū•‘©`§ę§ť◊ÓŖm›ĒňÕĺŗŽx§ň ™ę Liu et al. Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training. AAAI 2020. •Ľ•į•Š•ů•∆©`•∑•Á•ů§ő•Ū•Ļ§Ú•Į•Ū•Ļ•®•ů•»•Ū•‘©`§ę§ť◊ÓŖm›ĒňÕĺŗŽx§ň
- 20. 20 / 88 KYOTO UNIVERSITY KL §¨¨F§ž§Ņ§ť◊ÓŖm›ĒňÕ§ň÷√§≠ďQ§®§ť§ž§ §§§ęŅľ§®§∆§Ŗ§Ž ™ę …Ŕ§∑•ļ•Ž§§§«§Ļ§¨: ◊š’ď§ő•∆©`•ř§¨ňľ§§ł°§ę§–§ §§§»§≠°ĘKL §Ú Ļ§√§∆§§§Ž ÷∑®§ÚŐŧ∑§∆ ◊ÓŖm›ĒňÕ§ň÷√§≠ďQ§®§Ž§ņ§Ī§«’ďőń§ň§ §Í§ř§Ļ°£ ™ę §Ņ§ņ§∑: •Ņ•Ļ•Į§ň§Ť§√§∆◊ÓŖm›ĒňÕ§»§őŌŗ–‘§Ę§Í°£ ĺŗŽxėč‘ž§ő∂®Ńx§ő ň∑ŧŌĻ§∑Ú§ő§Ŗ§Ľ§…§≥§Ū°£ §Ť§§•Ņ•Ļ•Į?ĺŗŽxėč‘ž§Ú§¶§ř§ĮŖx§Ŕ§Ž§»∑«≥£§ň§Ť§§—–ĺŅ§ň§ §Í§ř§Ļ°£ …ŧا…§Ę§Í§ř§Ļ ◊ÓŖm›ĒňÕ§Ō KL §ő«∑Ķ„§ÚŅň∑Ģ§«§≠§Ž°£ ÷∑®÷–§ň KL §¨¨F§ž§Ņ§ť◊ÓŖm›ĒňÕ§ÚŅľ§®§∆§Ŗ§ř§∑§Á§¶°£ take home message
- 21. 21 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§ő∂®Ńx§»«ů§Š∑Ĺ
- 22. 22 / 88 KYOTO UNIVERSITY •“•Ļ•»•į•ť•ŗ§ő◊ÓŖm›ĒňÕĺŗŽx§ő∂® ĹĽĮ: ĺÄ–ő”čĽ≠ ™ę »ŽŃ¶: Ī»›^§Ļ§Ž•“•Ļ•»•į•ť•ŗ łųĶ„§őĺŗŽx§ÚĪŪ§Ļ––Ń– ™ę ≥ŲѶ: •“•Ļ•»•į•ť•ŗ§őĺŗŽx ™ę ◊ÓŖm›ĒňÕĺŗŽx§Ú“‘Ō¬§ő◊ÓŖmĽĮÜĖÓ}§ő◊ÓŖmā駻∂®Ńx§Ļ§Ž ? ĺt•≥•Ļ•» ? ›ĒňÕŃŅ§Ō∑«ōď ? ”ŗ§Í§ §∑ ? ≤Ľ◊„§ §∑ õQ∂®Čš ż Pij §Ō Ķ„ i §ę§ťĶ„ j §ň ›ĒňÕ§Ļ§ŽŃŅ§Ú ĪŪ§Ļ §≥§ž§ŌĺÄ–ő”čĽ≠
- 23. 23 / 88 KYOTO UNIVERSITY •“•Ļ•»•į•ť•ŗĪ»›^§őņż ™ę »ŽŃ¶: dog, cat, lion, bird dog, cat, lion, bird dog, cat, lion, bird °Ł cat §» lion §ő•Ŗ•Ļ§Ō•≥•Ļ•»§¨ĶÕ§§ cat §ę§ť lion §ō 0.2 §ő›ĒňÕ dog cat lion bird dog cat lion bird ≤ĽĄ” ≤ĽĄ” ≤ĽĄ” lion §ō ™ę ≥ŲѶ:
- 24. 24 / 88 KYOTO UNIVERSITY Ķ„»ļ§ő◊ÓŖm›ĒňÕĺŗŽx§ő∂® ĹĽĮ: ĺÄ–ő”čĽ≠ ™ę »ŽŃ¶: Ī»›^§Ļ§ŽĶ„»ļ łųĶ„§őĺŗŽx§ÚĪŪ§Ļťv ż ™ę ≥ŲѶ: Ķ„»ļ§őĺŗŽx ™ę ◊ÓŖm›ĒňÕĺŗŽx§Ú“‘Ō¬§ő◊ÓŖmĽĮÜĖÓ}§ő◊ÓŖmā駻∂®Ńx§Ļ§Ž ? ĺt•≥•Ļ•» ? ›ĒňÕŃŅ§Ō∑«ōď ? ”ŗ§Í§ §∑ ? ≤Ľ◊„§ §∑ õQ∂®Čš ż Pij §Ō Ķ„ i §ę§ťĶ„ j §ň ›ĒňÕ§Ļ§ŽŃŅ§Ú ĪŪ§Ļ §≥§ž§ŌĺÄ–ő”čĽ≠
- 25. 25 / 88 KYOTO UNIVERSITY ŖBĺA∑÷≤ľĪ»›^§őąŲļŌ§ő◊ÓŖm›ĒňÕĺŗŽx§ő∂® ĹĽĮ ™ę »ŽŃ¶: Ī»›^§Ļ§Žī_¬ ∑÷≤ľ łųĶ„§őĺŗŽx§ÚĪŪ§Ļťv ż ™ę ≥ŲѶ: ∑÷≤ľ§őĺŗŽx ™ę ◊ÓŖm›ĒňÕĺŗŽx§Ú“‘Ō¬§ő◊ÓŖmĽĮÜĖÓ}§ő◊ÓŖmā駻∂®Ńx§Ļ§Ž ? ĺt•≥•Ļ•» ? ›ĒňÕŃŅ§Ō∑«ōď ? ”ŗ§Í§ §∑ ? ≤Ľ◊„§ §∑ §∂§√§Į§Í—‘§¶§» ļÕ§Ú∑e∑÷§ň§∑§∆ ŖBĺA§ň§∑§∆§§§Ž
- 26. 26 / 88 KYOTO UNIVERSITY Žx…Ę◊ÓŖm›ĒňÕ§ŌĺÄ–ő”čĽ≠°ĘŖBĺA§őąŲļŌ§ŌĻ§∑Ú§¨Īō“™ ™ę •“•Ļ•»•į•ť•ŗ§őąŲļŌ§»Ķ„»ļ§őąŲļŌ§Ō§Ř§»§ů§…Õ¨§łĺÄ–ő”čĽ≠ •Ę•Ž•ī•Í•ļ•ŗ§ÚŅľ§®§Ž…Ō§«§Ō§≥§ž§ť§ŌÕ¨§łÜĖÓ}§»§Ŗ§ §Ķ§ž§Ž§≥§»§¨∂ŗ§§ ™ę ĺÄ–ő”čĽ≠§ §ő§«°Ęľ»īś§ő•Ĺ•Ž•–§Ú”√§§§∆Ĺ‚§Į§≥§»§¨§«§≠§Ž ™ę ŖBĺA∑÷≤ľ§…§¶§∑§ő◊ÓŖm›ĒňÕ§ŌŖBĺA∑÷≤ľ§ő◊ÓŖmĽĮÜĖÓ}§ň§ §Ž§ő§« Ĺ‚§Į§ő§¨Žy§∑§§ 1. ŖBĺA∑÷≤ľ§ę§ť•Ķ•ů•◊•Í•ů•į§Ú––§§Ķ„»ļĪ»›^§ňéĘ◊ҧĻ§Ž°Ę§ř§Ņ§Ō 2. §≥§ő•Ń•Ś©`•»•Í•Ę•Ž§őŠŠįŽ§«ĹBĹť§Ļ§ŽňęĆĚ§Ú Ļ§√§Ņ•Ę•◊•Ū©`•Ń§« ÷ĪŔł§Į ™ę “‘Ō¬°Ę÷ų§ňŽx…Ę◊ÓŖm›ĒňÕ§ÚŅľ§®§Ž
- 27. 27 / 88 KYOTO UNIVERSITY •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§Ō◊ÓŖm›ĒňÕ§őŐō ‚•Ī©`•Ļ ™ę ◊ÓŖm›ĒňÕĺŗŽx§Ō•≥•Ļ•»––Ń–§ő‘O∂®īőĶ৫ĺŗŽxĻęņŪ§Ōúļ§Ņ§Ķ§ §§ §Ļ§Ŕ§∆•≥•Ļ•»§¨ 0 §ő§»§≠°Ę§Ļ§Ŕ§∆§ő∑÷≤ľ§őĺŗŽx§Ō•ľ•Ū§ň§ §√§∆§∑§ř§¶ ™ę •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§ŌĺŗŽxĻęņŪ§Úúļ§Ņ§Ļ◊ÓŖm›ĒňÕ§őŐō ‚•Ī©`•Ļ ™ę ∂®Ńx: •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx …Ō§őĺŗŽxťv ż §»Ćg ż §Ú”√§§§∆•≥•Ļ•»––Ń–§Ú §»∂®Ńx§Ļ§Ž°£ §Ú p-•Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§»§§§¶°£ ™ę •ś©`•Į•Í•√•…ĺŗŽx§ő 1-•Ô•√•Ķ©`•Ļ•Ņ•§•ů §š 2-•Ô•√•Ķ©`•Ļ•Ņ•§•ů §¨§Ť§Į”√§§§ť§ž§Ž
- 28. 28 / 88 KYOTO UNIVERSITY •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§ŌĺŗŽxĻęņŪ§Úúļ§Ņ§Ļ ™ę ∂®ņŪ: •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§ŌĺŗŽxĻęņŪ§Úúļ§Ņ§Ļ ‘^√ų§ŌŌ¬”õőńŌ◊§ §…≤ő’’ ™ę §Ļ§ §Ô§Ń°ĘĶ„§őĺŗŽx§»§∑§∆ĺŗŽxĻęņŪ§Úúļ§Ņ§Ļ§‚§ő§Ú Ļ§®§–°Ę ∑÷≤ľ§őĺŗŽx§»§∑§∆◊‘Ą”Ķń§ňĺŗŽxĻęņŪ§¨úļ§Ņ§Ķ§ž§Ž§Ť§¶§ň§ §Ž ™ę cf. KL §ŌĺŗŽx§őĻęņŪ§Úúļ§Ņ§Ķ§ §§ Gabriel Peyr®¶, Marco Cuturi. Computational Optimal Transport. 2019.
- 29. 29 / 88 KYOTO UNIVERSITY •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§őņż ™ę §ň§ń§§§∆°Ę , §¨ī_¬ 1 §«≥Ų§∆§Į§Žī_¬ ∑÷≤ľ , §ő•Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§Ō ™ę “Ľ∑Ĺ°ĘKL •ņ•§•–©`•ł•ß•ů•Ļ§Ō ™ę •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§ő∑ŧ¨§Ť§Íľö§ę§Į“ä∑÷§Ī§∆§§§Ž§»§§§®§Ž
- 30. 30 / 88 KYOTO UNIVERSITY •Ĺ•Ž•–§őĹBĹť: POT §¨•™•Ļ•Ļ•Š ™ę ◊ÓŖm›ĒňÕ§ÚĆgŽH§ň Ļ§¶ŽH§ň§ŌėĒ°©§ •Ĺ•Ž•–§¨ņŻ”√§«§≠§Ž ™ę Python Optimal Transport (POT): •™•Ļ•Ļ•Š pip install pot §«•§•ů•Ļ•»©`•Ž§«§≠§Ž a: numpy array (n,) b: numpy array (m,) C: numpy array (n, m) ot.emd(a, b, C) §Úļۧ”≥Ų§Ľ§–◊ÓŖm›ĒňÕ––Ń– P* §¨∑Ķ§Ž ™ę Scipy: scipy.optimize.linear_sum_assignment °ķ 1 ĆĚ 1 Ć̏ͧőąŲļŌ§ő§Ŗ scipy.optimize.linprog °ķ “Ľį„§őĺÄ–ő”čĽ≠
- 31. 31 / 88 KYOTO UNIVERSITY POT §ő Ļ”√ņż: ļÜÖg§ň Ļ§®§ř§Ļ ™ę żāéņż: ∂Ģ§ń§ő’ż“é∑÷≤ľ§ę§ť§őĶ„»ļ§őĪ»›^ import numpy as np import matplotlib.pyplot as plt import ot # POT •ť•§•÷•ť•Í n = 100 # Ķ„»ļ•Ķ•§•ļ mu = np.random.randn(n, 2) # »ŽŃ¶∑÷≤ľ 1 nu = np.random.randn(n, 2) + 1 # »ŽŃ¶∑÷≤ľ 2 a = np.ones(n) / n # Ŕ|ŃŅ•“•Ļ•»•į•ť•ŗ (1/n, ..., 1/n) b = np.ones(n) / n # Ŕ|ŃŅ•“•Ļ•»•į•ť•ŗ (1/n, ..., 1/n) C = np.linalg.norm(nu[np.newaxis] - mu[:, np.newaxis], axis=2) # •≥•Ļ•»––Ń– P = ot.emd(a, b, C) # ◊ÓŖm›ĒňÕĺŗŽx§ő”čň„ plt.scatter(mu[:, 0], mu[:, 1]) # mu §ő…Ę≤ľáŪ√Ť–ī plt.scatter(nu[:, 0], nu[:, 1]) # nu §ő…Ę≤ľáŪ√Ť–ī for i in range(n): j = P[i].argmax() # i §őĆĚŹÍŌŗ ÷: ◊Ó§‚§Ņ§Į§Ķ§ů›ĒňÕ§∑§∆§§§ŽŌ» plt.plot([mu[i, 0], nu[j, 0]], [mu[i, 1], nu[j, 1]], c='grey', zorder=-1) °Ł •≥•‘•ŕ§«‘᧼§ř§Ļ
- 32. 32 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§ŌĺÄ–ő”čĽ≠°£•Ĺ•Ž•–§«ļÜÖg§ňĹ‚§Ī§Ž°£ ◊ÓŖm›ĒňÕĺŗŽx§ŌĺÄ–ő”čĽ≠§»§∑§∆∂® ĹĽĮ§Ķ§ž§Ž •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§ŌĺŗŽxĻęņŪ§Úúļ§Ņ§ĻŐō ‚•Ī©`•Ļ •Ĺ•Ž•–§ÚņŻ”√§Ļ§Ž§»ļÜÖg§ň◊ÓŖm›ĒňÕ§Ú”čň„§«§≠§Ž take home message
- 33. 33 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ
- 34. 34 / 88 KYOTO UNIVERSITY łŖňŔ§«•Ř•Ô•§•»•‹•√•Į•Ļ§ •Ę•Ž•ī•Í•ļ•ŗ§¨”Ż§∑§§ ™ę «į’¬§«§ő◊h’ď: ◊ÓŖm›ĒňÕ§ŌĺÄ–ő”čĽ≠ °ķ ĺÄ–ő”čĽ≠•Ĺ•Ž•–§ňÕ∂§≤§Ž§»Ĺ‚§Ī§Ž ™ę «∑Ķ„: öÝ”√•Ĺ•Ž•–?Öó√‹•Ĺ•Ž•–§ŌŖW§§ •÷•ť•√•Į•‹•√•Į•Ļ§ §ő§«°Ę◊‘∑÷§ő ÷∑®§ň”–ôCĶń§ňĹMřz§Ŗ§Ň§ť§§ ™ę §≥§ž§ę§ťĹBĹť§Ļ§Ž•∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ: łŖňŔ •∑•ů•◊•Ž °ķ §Ķ§ř§∂§ř§ ÷∑®§»ĹM§ŖļŌ§Ô§Ľ§š§Ļ§§ §Ņ§ņ§∑°ĘÖó√‹§ ◊ÓŖm›ĒňÕ§Ō«ů§ř§ť§ §§
- 35. 35 / 88 KYOTO UNIVERSITY •®•ů•»•Ū•‘©`’żĄtĽĮ§ń§≠◊ÓŖm›ĒňÕÜĖÓ}§ÚŅľ§®§Ž ™ę “‘Ō¬§ő•®•ů•»•Ū•‘©`’żĄtĽĮ§ń§≠◊ÓŖm›ĒňÕÜĖÓ}§ÚŅľ§®§Ž ™ę ¶Ň > 0 §Ō’żĄtĽĮāS ż£®•Ō•§•—©`•—•ť•Š©`•Ņ£© •™•Í•ł• •Ž§ő◊ÓŖm›ĒňÕ§»§ŌĄeÜĖÓ}°£§Ņ§ņ§∑ ¶Ň °ķ 0 §«‘™ÜĖÓ}§ň°£ •®•ů•»•Ū•‘©`Ūó = H(P)
- 36. 36 / 88 KYOTO UNIVERSITY •®•ů•»•Ū•‘©`’żĄtĽĮ§ń§≠ÜĖÓ}§ŌŹäÕĻ ™ę ś“§∑§Ķ : •®•ů•»•Ū•‘©`’żĄtĽĮ§ń§≠ÜĖÓ}§őńŅĶńťv ż§ŌŹäÕĻ ™ę ÷∆ľs§¨ĺÄ–ő÷∆ľs§ņ§Ī§»§§§¶§≥§»§ŌĆg––Ņ…ń‹ÓI”Ú§ŌÕĻ§ §ő§« Ćg––Ņ…ń‹ÓI”ÚÕĻ + ńŅĶńťv żŹäÕĻ °ķ ◊ÓŖmĹ‚§Ō“Ľ“‚§ň∂®§ř§Ž ? ĺÄ–ő”čĽ≠§Ō√ś»ęŐŚ§«◊ÓŖm§Ú§»§Ž§≥§»§¨§Ę§Í°Ę“Ľ“‚§ň∂®§ř§ť§ §§ ĺÄ–ő •®•ů•»•Ū•‘©`§ŌŹäįľ °ķ »ęŐŚ§«ŹäÕĻ °ķ ◊ÓŖmĽĮ§∑§š§Ļ§§ Gabriel Peyr®¶, Marco Cuturi. Computational Optimal Transport. 2019.
- 37. 37 / 88 KYOTO UNIVERSITY ňęĆĚÜĖÓ}§Ō÷∆ľs§ §∑◊ÓīůĽĮÜĖÓ} ™ę •®•ů•»•Ū•‘©`’żĄtĽĮ§ń§≠◊ÓŖm›ĒňÕ§ő£®ÕĻ”čĽ≠§»§∑§∆§ő£©ňęĆĚÜĖÓ}§Ō °ķ ÷∆ľs§ §∑◊ÓīůĽĮÜĖÓ} ™ę ňęĆĚÜĖÓ}§ÚĹ‚§Į§≥§»§Ú§Š§∂§Ļ ™ę ňęĆĚÜĖÓ}§őĆß≥Ų§ŌŌ¬”õőńŌ◊§ §…§Ú≤ő’’ Gabriel Peyr®¶, Marco Cuturi. Computational Optimal Transport. 2019. ◊Ó šňÕ§őĹ‚§≠∑Ĺ /joisino/ss-249394573
- 38. 38 / 88 KYOTO UNIVERSITY ňęĆĚÜĖÓ}§őńŅĶńťv ż§őĻīŇš§Ō f ńŕ g ń৫Ĺj§Ŗ§ §∑ ™ę ňęĆĚÜĖÓ}§őńŅĶńťv ż§Ú D §Ú§™§Į ™ę D §ő f §» g §ň§ń§§§∆§őĻīŇš§Ō“‘Ō¬§őÕ®§Í ™ę fi §őĻīŇš§ő÷–§ň fk (k °Ŕ i), gj §őĻīŇš§ő÷–§ň gk (k °Ŕ j) §Ō ≥Ų§∆§≥§ §§£®Ĺj§Ŗ§ §∑£©
- 39. 39 / 88 KYOTO UNIVERSITY f §ī§»°Ęg §ī§»§ň◊ÓŖmā駨Öó√‹§ň«ů§ř§Ž ™ę •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ§őĽýĪĺĶń§ Ņľ§®§Ō◊ýėňŌÚ…Ō∑® ™ę f §ÚĻŐ∂®§∑§Ņ§»§≠§ő g §ő◊ÓŖmāé§ŌĻīŇš•§•≥©`•Ž•ľ•Ū§»§™§§§∆ g §ÚĻŐ∂®§∑§Ņ§»§≠§ő f §ő◊ÓŖmā駂ըėĒ§ň ™ę •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ§Ō f ĻŐ∂®§«§ő g §őÖó√‹◊ÓŖmĽĮ °ķ g ĻŐ∂®§«§ő f §őÖó√‹◊ÓŖmĽĮ§ÚĹĽĽ•§ňņR§Í∑Ķ§Ļ
- 40. 40 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ§Ō f §» g §ÚĹĽĽ•§ň◊ÓŖmĽĮ§Ļ§Ž ™ę ĆĚ żÓI”Ú§«§ő•∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ ™ę •Ļ•∆•√•◊ 1: f(1) §ÚŖmĶĪ§ň≥ű∆ŕĽĮ£®ņż§®§–•ľ•Ū•Ŕ•Į•»•Ž), t = 1 §ň ™ę •Ļ•∆•√•◊ 2: ™ę •Ļ•∆•√•◊ 3: ™ę •Ļ•∆•√•◊ 4: f §» g §¨Öß Ý§Ļ§Ž§ř§« t °Ż t + 1 §«•Ļ•∆•√•◊ 2 §ō ™ę ńŅĶńťv ż§¨őĘ∑÷Ņ…ń‹§«łų•Ļ•∆•√•◊ő®“ĽĹ‚§ §ő§«īů”Ú◊ÓŖm§ňÖß Ý
- 41. 41 / 88 KYOTO UNIVERSITY ÷ł żťv ż§Ú Ļ§√§∆Čš żČšďQ§Ļ§Ž§»•∑•ů•◊•Ž§ňēݧĪ§Ž ™ę Ō»≥Ő§ő•§•∆•ž©`•∑•Á•ů§«§Ō log §š exp §¨§Ņ§Į§Ķ§ů≥Ų§∆§Į§Ž ™ę §»Čš żČšďQ§Ļ§Ž§»•∑•ů•◊•Ž§ň
- 42. 42 / 88 KYOTO UNIVERSITY •ģ•÷•Ļ•ę©`•Õ•Ž§ő∂®Ńx ™ę §Ķ§ť§ň K ° Rn°Ńm §Ú“‘Ō¬§«∂®§Š§Ž ™ę K §Ú•ģ•÷•Ļ (Gibbs) •ę©`•Õ•Ž§»§§§¶ ™ę i §» j §őÓźň∆∂»§ÚĪŪ§∑§∆§§§Ž ™ę ņż§®§– C §¨•ś©`•Į•Í•√•…ĺŗŽx§ő◊‘Ā\£®2-•Ô•√•Ķ©`•Ļ•Ņ•§•ů£© §ő§»§≠•¨•¶•Ļ•ę©`•Õ•Ž§ň§ §Ž •≥•Ļ•»§ňōďļŇ °ķ Óźň∆∂» exp §ŌÖg’{
- 43. 43 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ů§ő•§•∆•ž©`•∑•Á•ů§Ō––Ń–∑e§«§ę§Ī§Ž ™ę •ģ•÷•Ļ•ę©`•Õ•Ž––Ń–§Ú Ļ§¶§»§Ķ§ť§ň•∑•ů•◊•Ž§ň ™ę §Ņ§ņ§∑ KT §Ō‹ě÷√––Ń–°ĘłÓ§Íň„§Ō“™ňō§ī§»°Ę∑÷ńł§Ō––Ń–•Ŕ•Į•»•Ž∑e ™ę ∑«≥£§ňÖgľÉ§ňĆg◊į§«§≠§Ž ™ę ––Ń–•Ŕ•Į•»•Ž∑e§¨•Š•§•ů§ §ő§« GPU §«łŖňŔ”čň„Ņ…ń‹ §’§ń§¶•∑•ů•Į•Ř©`•ů§»§§§¶§» §≥§ő–ő§őłŁ–¬•Ę•Ž•ī•Í•ļ•ŗ§Ú÷ł§Ļ
- 44. 44 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ůČš ż§ę§ť‘™§őČš ż§ō§őĎݧ∑∑Ĺ ™ę •∑•ů•Į•Ř©`•ů§ň§Ť§Í (u, v) §¨«ů§ř§Ž§»°ĘČš żČšďQ§ő ŧŤ§Í‘™§ő ňęĆĚČš ż§Ō ™ę ÷ųÜĖÓ}§őČš ż§ŌňęĆĚ◊ÓŖmĹ‚§»÷ų◊ÓŖmĹ‚§őĆĚŹÍťvāS§Ť§Í f, g §¨ÕÍŤĶ§ňÖß Ý§∑§ §§Ōř§Í°Ę«ů§Š§Ņ Pij §ŌÖó√‹§ň§ŌĆg––Ņ…ń‹§»§Ō Ōř§ť§ §§§≥§»§ň◊Ę“‚£®Ćg”√…Ō§Ō∂ŗ…Ŕ§ő’`≤Ó§ŌÜĖÓ}§ §§§≥§»§‚∂ŗ§§£© ™ę §≥§ő Pij §ę§ťŖ`∑ī∑÷§Ú§§§§ł–§ł§ň∑÷Ňš§∑§∆Ćg––Ņ…ń‹Ĺ‚§Ú”čň„§Ļ§Ž •Ę•Ž•ī•Í•ļ•ŗ§‚ŐŠįł§Ķ§ž§∆§§§Ž [Altschuler+ 2017] Jason Altschuler, Jonathan Weed, Philippe Rigollet. Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. NeurIPS 2017.
- 45. 45 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ: ņż ™ę ņż£®“‘«į Ļ§√§Ņ§‚§ő£©: dog, cat, lion, bird dog, cat, lion, bird dog, cat, lion, bird °Ł cat §» lion §ő•Ŗ•Ļ§Ō•≥•Ļ•»§¨ĶÕ§§ ™ę •®•ů•»•Ū•‘©`’żĄtĽĮ§ §∑§őąŲļŌ§ő≥ŲѶ: dog cat lion bird dog cat lion bird ≤ĽĄ” ≤ĽĄ” ≤ĽĄ” lion §ō
- 46. 46 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ: ņż import numpy as np import matplotlib.pyplot as plt n, m = 4, 4 C = np.array([ [0, 2, 2, 2], [2, 0, 1, 2], [2, 1, 0, 2], [2, 2, 2, 0]]) a = np.array([0.2, 0.5, 0.2, 0.1]) b = np.array([0.3, 0.3, 0.4, 0.0]) eps = 0.2 # īů§≠§§§»łŖňŔ§ň°Ę–°§Ķ§§§»Öó√‹§ň K = np.exp(- C / eps) # •ģ•÷•Ļ•ę©`•Õ•Ž§ő”čň„ u = np.ones(n) # §Ļ§Ŕ§∆ 1 §«≥ű∆ŕĽĮ for i in range(100): v = b / (K.T @ u) # •Ļ•∆•√•◊ (2) u = a / (K @ v) # •Ļ•∆•√•◊ (3) f = eps * np.log(u + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ g = eps * np.log(v + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ P = u.reshape(n, 1) * K * v.reshape(1, m) # ÷ųĹ‚ plt.pcolor(P, cmap=plt.cm.Blues) # Ĺ‚§őŅ…“ēĽĮ °Ż •≥•‘•ŕ§«‘᧼§ř§Ļ •Š•§•ů•Ū•ł•√•Į§Ō§Ô§ļ§ę 3 –– °Ł •®•ů•»•Ū•‘©`§ §∑§őĹ‚§»§Ř§‹“Ľ÷¬ £®◊ůŌ¬§¨ (1, 1) §«§Ę§Ž§≥§»§ň◊Ę“‚£© Õ‚≤Ņ•ť•§•÷•ť•Í§ňÓm§ť§ §§
- 47. 47 / 88 KYOTO UNIVERSITY •∑•ů•Į•Ř©`•ů§Ō◊‘Ą”őĘ∑÷§«§≠§Ž ™ę ”čň„§¨––Ń–—›ň„§ņ§Ī§ę§ť§ §Ž§ő§«°Ę◊‘Ą”őĘ∑÷•ť•§•÷•ť•Í§ň§Ť§Í őĘ∑÷§¨«ů§ř§Ž ™ę §Ņ§»§®§–“‘Ō¬§ő§Ť§¶§ň numpy §őīķ§Ô§Í§ň torch §»§Ļ§Ž import torch K = torch.exp(- C / eps) # •ģ•÷•Ļ•ę©`•Õ•Ž§ő”čň„ u = torch.ones(n) # §Ļ§Ŕ§∆ 1 §«≥ű∆ŕĽĮ for i in range(100): v = b / (K.T @ u) # •Ļ•∆•√•◊ (2) u = a / (K @ v) # •Ļ•∆•√•◊ (3) f = eps * torch.log(u + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ g = eps * torch.log(v + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ P = u.reshape(n, 1) * K * v.reshape(1, m) # ÷ųĹ‚ loss = (P * C).sum() loss.backward()
- 48. 48 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę ņż: “‘Ō¬§őĶ„»ļ§ÚŅľ§®§Ž°£≥ŗ§ŌĻŐ∂®°Ę«ŗ§őőĽ÷√§¨•—•ť•Š©`•Ņ°£ Sinkhorn §ň§Ť§Í”čň„§Ķ§ž§Ņāé§Ú•Ū•Ļ§»§∑§∆ĻīŇš∑®§«◊ÓŖmĽĮ°£
- 49. 49 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 50. 50 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 51. 51 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 52. 52 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 53. 53 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 54. 54 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 55. 55 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę Sinkhorn §ň§Ť§Í«ů§ř§√§Ņ›ĒňÕ––Ń–§Ú≤őŅľ§ň”õ§∑§∆§§§Ž
- 56. 56 / 88 KYOTO UNIVERSITY ◊‘Ą”őĘ∑÷§őņż ™ę ›ĒňÕĺŗŽx§ő–°§Ķ§§«ŗ§őŇš÷√§¨«ů§ř§√§Ņ
- 57. 57 / 88 KYOTO UNIVERSITY •Ĺ©`•Ļ•≥©`•…»ę√≤ import matplotlib.pyplot as plt import torch import torch.optim import torch.nn # •«©`•Ņ…ķ≥… torch.manual_seed(0) x = torch.rand(20, 2) y = torch.rand(20, 2) + torch.FloatTensor([0, 2]) z = torch.rand(20, 2) + torch.FloatTensor([1, 1]) mu = torch.cat([x, y, z]) nu = torch.rand(12, 2) * 2 nu = torch.nn.parameter.Parameter(nu) n, m = len(mu), len(nu) a = torch.ones(n) / n b = torch.ones(m) / m optimizer = torch.optim.SGD([nu], lr=1.0) for it in range(100): eps = 0.1 D = torch.linalg.norm(mu.reshape(n, 1, 2) - nu.reshape(1, m, 2), axis=2) K = torch.exp(- D / eps) # •ģ•÷•Ļ•ę©`•Õ•Ž§ő”čň„ u = torch.ones(n) # §Ļ§Ŕ§∆ 1 §«≥ű∆ŕĽĮ for i in range(100): v = b / (K.T @ u) # •Ļ•∆•√•◊ (2) u = a / (K @ v) # •Ļ•∆•√•◊ (3) f = eps * torch.log(u + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ g = eps * torch.log(v + 1e-9) # ĆĚ żÓI”Ú§ňĎݧĻ P = u.reshape(n, 1) * K * v.reshape(1, m) # ÷ųĹ‚ loss = (P * D).sum() optimizer.zero_grad() loss.backward() optimizer.step() plt.clf() plt.scatter(mu[:, 0], mu[:, 1]) plt.scatter(nu.data[:, 0], nu.data[:, 1]) plt.show() •≥•‘•ŕ§«‘᧼§ř§Ļ
- 58. 58 / 88 KYOTO UNIVERSITY ◊Ó–¬§ő ÷∑®§«§‚Ļę∆Ĺ”ŤúyÜĖÓ}§ň•∑•ů•Į•Ř©`•ů§¨ Ļ§Ô§ž§Ž ™ę ňŻ§ň§‚°Ę∂Ģ§ń§őľĮļŌ§őĺŗŽx§ÚĹŁ§Ň§Ī§Ž§Ņ§Š§őőĘ∑÷Ņ…•Ū•Ļ§»§∑§∆ Ļ§Ô§ž§Ž ™ę ņż§®§–°ĘĻę∆Ĺ–‘§őĶ£Ī£§ő§Ņ§Š°Ęń––‘§ň§ń§§§∆§ő”Ťúy§»Ňģ–‘§ň§ń§§§∆§ő ”Ťúy∑÷≤ľ§¨Õ¨§ł§Ť§¶§ň§∑§Ņ§§ ™ę ”Ťúy’`≤Ó + ≥ŗ§»«ŗ§ő◊ÓŖm›ĒňÕĺŗŽx§Ú◊Ó–°ĽĮ [Oneto+ NeurIPS 2020] Luca Oneto, Michele Donini, Giulia Luise, Carlo Ciliberto, Andreas Maurer, Massimiliano Pontil. Exploiting MMD and Sinkhorn Divergences for Fair and Transferable Representation Learning. NeurIPS 2020. •ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į »ŽŃ¶ d īő‘™•Ŕ•Į•»•Ž§¨ ≥Ų§∆§Į§Ž Rd ”Ťúy∆ų ≥ŲѶ łųÕŤ§Ōłų•Ķ•ů•◊•Ž§ő ¬Ů§Šřz§Ŗ ≥ŗ: Ňģ–‘•Ķ•ů•◊•Ž «ŗ: ń––‘•Ķ•ů•◊•Ž
- 59. 59 / 88 KYOTO UNIVERSITY §ř§»§Š: •∑•ů•Į•Ř©`•ů§Ō•∑•ů•◊•Ž§ę§ńłŖ§§»Š‹õ–‘§Ú’F§Ž •®•ů•»•Ū•‘©`§ÚĆß»Ž§Ļ§Ž§»◊ÓŖmĽĮ§¨ļÜÖg§ň •∑•ů•Į•Ř©`•ů§Ō––Ń–—›ň„§ņ§Ī§«§«§≠§Ž•∑•ů•◊•Ž◊ÓŖmĽĮ∑® ļÜÖg§ň•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ňĹM§Ŗřz§ŗ§≥§»§¨§«§≠§Ž take home message
- 60. 60 / 88 KYOTO UNIVERSITY Wasserstein GAN £®ŖBĺA∑÷≤ľ§ň§ń§§§∆§ő◊ÓŖm›ĒňÕ£©
- 61. 61 / 88 KYOTO UNIVERSITY ŖBĺA∑÷≤ľ§ő◊ÓŖm›ĒňÕ§Ú÷ĪŔł§Į•Ę•◊•Ū©`•Ń§ÚŅľ§®§Ž ™ę ŖBĺA∑÷≤ľ§ň§ń§§§∆§ő◊ÓŖm›ĒňÕ§ÚŅľ§®§Ž ? ĺt•≥•Ļ•» ? ›ĒňÕŃŅ§Ō∑«ōď ? ”ŗ§Í§ §∑ ? ≤Ľ◊„§ §∑
- 62. 62 / 88 KYOTO UNIVERSITY ňęḈڻ°§Ž§» 2 §ń§őťv ż§ő◊ÓŖmĽĮ§ň -> Žy§∑§§ ™ę ňęḈڧ»§Ž§» §≥§őÜĖÓ}§ő◊ÓŖmāé = ◊ÓŖm›ĒňÕĺŗŽx£®ŹäňęĆĚ–‘£© ňęḈőĆß≥Ų§ŌŌ¬”õőńŌ◊§ §…§Ú≤ő’’ ™ę ŖBĺAťv ż f, g §Ú◊ÓŖmĽĮ§Ļ§ŽÜĖÓ} °ķ “ņ»ĽŽy§∑§§ ◊Ó šňÕ§őĹ‚§≠∑Ĺ /joisino/ss-249394573
- 63. 63 / 88 KYOTO UNIVERSITY 1-•Ô•√•Ķ©`•Ļ•Ņ•§•ů§ő§»§≠§ň§Ō 1 §ń§őťv ż§ő◊ÓŖmĽĮ§ň ™ę √ŁÓ}: •≥•Ļ•»ťv ż C §¨ĺŗŽxťv ż§ő§»§≠£®1-•Ô•√•Ķ©`•Ļ•Ņ•§•ů£©°Ę ◊ÓŖmĹ‚§ň§™§§§∆ f = g ‘^√ų§ŌŌ¬”õőńŌ◊§ §…≤ő’’ ™ę “‘ĹĶ 1-•Ô•√•Ķ©`•Ļ•Ņ•§•ů§ő§Ŗ§ÚŅľ§®§Ž°£§≥§ž§ň§Ť§ÍČš ż g §ÚŌų≥ż§«§≠§Ž ™ę ŖBĺAťv ż f §Ú◊ÓŖmĽĮ§Ļ§ŽÜĖÓ} ◊Ó šňÕ§őĹ‚§≠∑Ĺ /joisino/ss-249394573
- 64. 64 / 88 KYOTO UNIVERSITY 1-•Ô•√•Ķ©`•Ļ•Ņ•§•ů§őňęḈőŐűľĢ§Ō•Í•◊•∑•√•ń§»Ķ»Āż C §¨ĺŗŽxťv ż§ő§»§≠°Ę §≥§ž§Ō f §¨ 1-•Í•◊•∑•√•ń§»§§§¶§≥§»
- 65. 65 / 88 KYOTO UNIVERSITY “‘ĹĶ°Ę•Í•◊•∑•√•ńŖBĺAťv ż§Ú◊ÓŖmĽĮ§Ļ§ŽÜĖÓ}§ÚŅľ§®§Ž ™ę •Í•◊•∑•√•ń–‘§Ōĺ÷ňýĶń§ ŐűľĢ£®łųĶ„§«§őĻīŇš£©§«ĪŪ§Ľ§Ž§ő§«ś“§∑§§ ™ę ňęḈš f = g §ő◊h’ď§Ōřz§Ŗ»Ž§√§∆§§§Ž§ő§«°Ę∂Őērťg§«§Ō‘Ēľö§ř§« ◊∑§®§ř§Ľ§ů§«§∑§Ņ°£ö›§ň§ §Ž»ň§ŌŌ¬”õőńŌ◊§Ú§Ę§»§«≤ő’’§∑§∆§Į§ņ§Ķ§§°£ ™ę “‘ĹĶ§Ō°Ę…Ō”õ§őÜĖÓ}§Ķ§®Ĺ‚§Ī§ž§–◊ÓŖm›ĒňÕ§¨Ĺ‚§Ī§Ž§»§§§¶§≥§»§Ú «įŐŠ§ň°Ę…Ō”õ§őÜĖÓ}§ÚĹ‚§Į§≥§»§ňľĮ÷–§∑§ř§Ļ°£ ◊Ó šňÕ§őĹ‚§≠∑Ĺ /joisino/ss-249394573
- 66. 66 / 88 KYOTO UNIVERSITY ¶Ő §ő•Ķ•ů•◊•Ž§Ú…Ō§≤°Ę¶Õ §ő•Ķ•ů•◊•Ž§ÚŌ¬§≤§Ž§ő§¨ńŅĶń ™ę f §Ō ¶Ő §ę§ť§ő•Ķ•ů•◊•Ž…Ō§«īů§≠§Ī§ž§–īů§≠§§§Ř§… ¶Õ §ę§ť§ő•Ķ•ů•◊•Ž…Ō§«–°§Ķ§Ī§ž§––°§Ķ§§§Ř§…§Ť§§ ™ę §Ņ§ņ§∑°Ęf §Ō°łĽ¨§ť§ę°Ļ£®•Í•◊•∑•√•ńŖBĺA£©§«§ §Ī§ž§–§ §ť§ §§
- 67. 67 / 88 KYOTO UNIVERSITY ťv ż◊ÓŖmĽĮ§ő•§•Š©`•ł ™ę ņż: ≥ŗĶ„§Ō ¶Ő §ę§ť§ő•Ķ•ů•◊•Ž°Ę«ŗĶ„§Ō ¶Õ §ę§ť§ő•Ķ•ů•◊•Ž§ňĆĚŹÍ Ī≥ĺį§¨≥ŗ§§§Ř§… f §őā駨īů§≠§§ Ī≥ĺį§¨«ŗ§§§Ř§… f §őā駨–°§Ķ§§ ťv ż§őČšĽĮ§ŌĽ¨§ť§ę
- 68. 68 / 88 KYOTO UNIVERSITY ňęĆĚÜĖÓ}§Ō 2 •Į•ť•Ļ∑÷ÓźÜĖÓ}§»“䧎§≥§»§¨§«§≠§Ž ™ę §≥§ő§Ť§¶§ň“䧎§»°Ę¶Ő §ę§ť§ő•Ķ•ů•◊•Ž§Ú’żņż°Ę¶Õ §ę§ť§ő•Ķ•ů•◊•Ž§Ú ōďņż§»§∑§Ņ§»§≠§ő 2 •Į•ť•Ļ∑÷ÓźÜĖÓ}§»“䧎§≥§»§¨§«§≠§Ž ™ę ľ§§∑§ĮČšĽĮ§Ļ§Ž∑÷Óź∆ų§Ō÷∆ľsŖ`∑ī °ł’żĄtĽĮ°Ļ§»§∑§∆•Í•◊•∑•√•ńťv ż§őŐűľĢ
- 69. 69 / 88 KYOTO UNIVERSITY ∑÷ÓźÜĖÓ}§Ú•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ň»ő§Ľ§Ž ™ę °ł∑÷Óź∆ų°Ļ f §Ú•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§«•‚•«•Í•ů•į§Ļ§Ž§≥§»§ÚŅľ§®§Ž ™ę •Ū•Ļťv ż§Ō•∑•ů•◊•Ž§ň ™ę §≥§ž§ÚĹUÚY’`≤Ó◊Ó–°ĽĮ ™ę f §¨ 1-•Í•◊•∑•√•ńŖBĺA§«§Ę§Ž§≥§»§Ú’n§Ļ§ő§ŌŽy§∑§§ ™ę §≥§≥§«§Ōňō∆”§ Ĺ‚õQ≤Ŗ§Ú 2 §ńĹBĹť
- 70. 70 / 88 KYOTO UNIVERSITY •—•ť•Š©`•Ņ§őāé§ÚüoņŪ§š§Í÷∆Ōř§∑§∆•Í•◊•∑•√•ń–‘§Ú’n§Ļ ™ę Ĺ‚õQ≤Ŗ 1: weight clipping [Arjovsky+ 2017] ™ę ”Ėĺö§őŽH•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őłų•—•ť•Š©`•Ņ§őĹ~ĆĚā駨 ∂® ż ¶√ > 0 §Ú‘ŧ®§Ž§Ņ§”§ňĹ~ĆĚāé ¶√ §ň•Į•Í•√•◊§Ļ§Ž£®¶√:•Ō•§•—•ť£© ™ę §≥§¶§Ļ§Ž§»°Ę•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į f §őĪŪ¨F§«§≠§Žťv ż§Ō÷∆Ōř§Ķ§ž ľĪľ§§ ČšĽĮ§Ú§Ļ§Žťv ż§ŌĪŪ§Ľ§ §Į§ §Ž ™ę ¶√ §ő‘O∂®īőĶ৫°Ęļő§ť§ę§ő k > 0 §ň§ń§§§∆ k-•Í•◊•∑•√•ń§«§Ę§Ž§≥§»§¨ Ī£‘^§«§≠§Ž ™ę k-•Í•◊•∑•√•ń§ ťv ż»ę§∆§ÚĪŪ¨F§«§≠§Ž‘U§«§Ō§ §§§¨°Ę•ň•Ś©`•ť•Ž•Õ•√•»•Ô©` •Į§ő»Š‹õ–‘§Ť§Í§Ĺ§ž§ §Í§ňōNłĽ§ ťv ż§¨ĪŪ¨F§«§≠§Ž§≥§»§¨∆ŕīż§«§≠§Ž Martin Arjovsky, Soumith Chintala, L®¶on Bottou. Wasserstein GAN. ICML 2017
- 71. 71 / 88 KYOTO UNIVERSITY łųĶ„§«§őĻīŇš§¨ 1 §ę§ťŽx§ž§Ž§»•ŕ• •Ž•∆•£ ™ę Ĺ‚õQ≤Ŗ 2: gradient penalty [Gulrajani+ 2017] ™ę f §¨őĘ∑÷Ņ…§ő§»§≠łųĶ„§«§őĻīŇš§ő•ő•Ž•ŗ§¨ 1 “‘Ō¬ ? 1-•Í•◊•∑•√•ń ™ę …ę§ů§ Ķ„§«ĻīŇš§Ú‘uĀż§∑§∆ 1 §ę§ťŽx§ž§∆§§§Ņ§ť•ŕ• •Ž•∆•£§Ú’n§Ļ §Ú•Ū•Ļ§»§∑§∆◊ÓŖmĽĮ Ishaan Gulrajani, Faruk Ahmed, Mart®™n Arjovsky, Vincent Dumoulin, Aaron C. Courville.. Improved Training of Wasserstein GANs. NeurIPS 2017 •Ō•§•—•ť’żĄtĽĮāS ż ĻīŇš§Ú 1 §ňĹŁ§Ň§Ī§Ž
- 72. 72 / 88 KYOTO UNIVERSITY •ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ő∂® ĹĽĮ§Ō GAN §ň”√§§§ť§ž§Ž ™ę f §Ú•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§«ĪŪ§Ļ§» f(x) §Ō x §ň§ń§§§∆őĘ∑÷Ņ…ń‹ °ķ ◊ÓŖm›ĒňÕ•≥•Ļ•»§ÚŌ¬§≤§Ž§ň§Ō x §Ú§…§¶Ą”§ę§Ľ§–§Ť§§§ę§¨∑÷§ę§Ž ™ę •ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ň§Ť§Ž∂® ĹĽĮ§Ō GAN£®…ķ≥…•‚•«•Ž£©§ő ”Ėĺö§ň§Ť§Į”√§§§ť§ž§Ž: Wasserstein GAN ™ę ◊‘»Ľ•Ķ•ů•◊•Ž§őľĮļŌ§Ú X ? Rd §»§Ļ§Ž°£ņż§®§–Ľ≠Ō٧őľĮļŌ ™ę GAN §ň§Ť§Í°ĘX §ňň∆§Ņ•Ķ•ů•◊•ŽľĮļŌ§Ú…ķ≥…§∑§Ņ§§ ™ę GAN §ň§Ť§Í…ķ≥…§∑§Ņ•Ķ•ů•◊•Ž§őľĮļŌ§Ú Y ? Rd §»§∑°ĘX §» Y §őĺŗŽx§Ú ◊ÓŖm›ĒňÕ•≥•Ļ•»§«úy§Ž ™ę §≥§ž§Ú◊Ó–°ĽĮ§Ļ§Ž§Ť§¶§ň GAN §Ú”Ėĺö§Ļ§Ž
- 73. 73 / 88 KYOTO UNIVERSITY •ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őÕ∆∂®§Ōīů“éń£•«©`•Ņ§»Ōŗ–‘§Ť§∑ ™ę Ķš–ÕĶń§ X §Ō∑«≥£§ňīů§≠§§£® żįŔÕÚ√∂§őĽ≠Ō٧ §…£© ™ę …ķ≥…•‚•«•Ž§ő…ķ≥…ĹYĻŻ Y §őļÚ—a§ŌüoŌř§ň§Ę§Ž ™ę •∑•ů•Į•Ř©`•ů•Ę•Ž•ī•Í•ļ•ŗ§«§Ō»ę§∆§őḈړĽ∂»§ňĹ‚§ę§ §Ī§ž§– § §ť§ļ°Ę∑«≥£§ňīů§≠§§•«©`•Ņ§ň§ŌŖm§∑§∆§§§ §§ ™ę °ł∑÷Óź∆ų°Ļ f §Ú∑÷Óź§Ļ§Ž§»§§§¶Ņľ§®∑ŧňŃʧ∆§–°Ę X §» Y §ę§ť“Ľ≤Ņ§ő•«©`•Ņ§Ú•Ŗ•ň•–•√•Ń§»§∑§∆»°§Í≥Ų§∑ f §Ú–ž°©§ň ”Ėĺö§∑§∆§§§Ī§–§Ť§§ °ķ •ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ň§Ť§ŽÕ∆∂®§Ōīů“éń££®or üoŌř£©§ő•«©`•Ņ §ň§ń§§§∆Ĺ‚§Į§ő§»Ōŗ–‘§¨§Ť§§
- 74. 74 / 88 KYOTO UNIVERSITY Wasserstein GAN: …ķ≥…•‚•«•Ž §» f §őĹĽĽ•”Ėĺö ™ę 1. …ķ≥…•‚•«•Ž G: Rr °ķ Rd §Ú•ť•ů•ņ•ŗ§ň≥ű∆ŕĽĮ §≥§ž§Ō•ő•§•ļ z ° Rr §Ú ‹§Ī»°§ÍĽ≠ŌŮ G(z) ° Rd §Ú∑Ķ§Ļ ◊ÓŖm›ĒňÕÜĖÓ}§ÚĹ‚§Į•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į f §Ú•ť•ů•ņ•ŗ§ň≥ű∆ŕĽĮ ™ę 2. G §Ú Ļ§√§∆Ľ≠ŌŮ Y = {G(z1 ), G(z2 ), ..., G(zm )} §Ú…ķ≥… ™ę 3. f §¨ X §» Y §Ú∑÷Óź§«§≠§Ž§Ť§¶§ň•Ŗ•ň•–•√•Ń§«”Ėĺö§∑§∆ X §» Y §ő£®•Ŗ•ň•–•√•Ń§ő£©◊ÓŖm›ĒňÕ•≥•Ļ•»§Ú”čň„ ™ę 4. f §Ú Ļ§√§Ņ◊ÓŖm›ĒňÕ•≥•Ļ•»§¨–°§Ķ§Į§ §Ž§Ť§¶§ň G §Ú•Ę•√•◊•«©`•» ™ę 5. 2 §ōĎݧŽ°£§≥§ő§»§≠ Y §ŌČšĽĮ§Ļ§Ž§¨ f §Ú“Ľ§ę§ť”Ėĺö§Ļ§Ž§ő§«§Ō§ §Į°Ę …Ŕ§∑ G §¨Čš§Ô§√§Ņ§Į§ť§§§«§Ō◊ÓŖm§ f §‚§Ř§‹Õ¨§ł§ §ő§« “‘«į§ő•—•ť•Š©`•Ņ§ę§ť”Ėĺö§Ú•Ļ•Ņ©`•»§Ļ§Ž£®•¶•©©`•ŗ•Ļ•Ņ©`•»£©
- 75. 75 / 88 KYOTO UNIVERSITY …ÓĆ”ģí§Ŗřz§Ŗ•Õ•√•»•Ô©`•Į§Ú Ļ§¶§≥§»§«•Í•Ę•Ž§ Ľ≠ŌŮ…ķ≥… ™ę Wasserstein GAN §ő’ďőń§šŠŠĺA§ő’ďőń§«§Ō G §š f §»§∑§∆ …ÓĆ”ģí§Ŗřz§Ŗ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§Ú Ļ§¶ ™ę …Ō§Ō X §ÚÓÜ–ī’śľĮļŌ§»§∑§∆”Ėĺö§∑§Ņ§∆§«§≠§Ņ…ķ≥…Ľ≠ŌŮ ∑«≥£§ň•Í•Ę•Ž§ ÓÜ–ī’ś§¨…ķ≥…§«§≠§∆§§§Ž …Ō§őĽ≠Ō٧Ō∂őŽAĶń—ßŃē§ §…Ąe§ő•∆•Į•ň•√•Į§‚Ůl Ļ§∑§∆”Ėĺö§Ķ§ž§∆§§§Ž Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICLR 2018.
- 76. 76 / 88 KYOTO UNIVERSITY ŖBĺA∑÷≤ľ§ő◊ÓŖm›ĒňÕ§Ō∑÷ÓźÜĖÓ}§»§∑§∆Ĺ‚§Ī§Ž ŖBĺA∑÷≤ľ§ő◊ÓŖm›ĒňÕ§őňęĆĚÜĖÓ}§Ō∑÷ÓźÜĖÓ}§»§Ŗ§ §Ľ§Ž °ł∑÷Óź∆ų°Ļ f §Ú•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§«•‚•«•Í•ů•į WGAN §Ō◊ÓŖm›ĒňÕĺŗŽx§¨–°§Ķ§Į§ §Ž§Ť§¶§ň•Ķ•ů•◊•Ž§ÚĄ”§ę§Ļ take home message
- 77. 77 / 88 KYOTO UNIVERSITY §ř§»§Š
- 78. 78 / 88 KYOTO UNIVERSITY •∆•§•Į•Ř©`•ŗ•Š•√•Ľ©`•ł 1 ◊ÓŖm›ĒňÕ§Ōī_¬ ∑÷≤ľ§»ī_¬ ∑÷≤ľ§ÚĪ»›^§Ļ§Ž§ő§ň Ļ§®§Ž•ń©`•Ž take home message
- 79. 79 / 88 KYOTO UNIVERSITY •∆•§•Į•Ř©`•ŗ•Š•√•Ľ©`•ł 2 take home message ◊ÓŖm›ĒňÕ§Ō KL §ő«∑Ķ„§ÚŅň∑Ģ§«§≠§Ž°£ ÷∑®÷–§ň KL §¨¨F§ž§Ņ§ť◊ÓŖm›ĒňÕ§ÚŅľ§®§∆§Ŗ§ř§∑§Á§¶°£
- 80. 80 / 88 KYOTO UNIVERSITY •∆•§•Į•Ř©`•ŗ•Š•√•Ľ©`•ł 3 ◊ÓŖm›ĒňÕĺŗŽx§ŌĺÄ–ő”čĽ≠§»§∑§∆∂® ĹĽĮ§Ķ§ž§Ž •Ô•√•Ķ©`•Ļ•Ņ•§•ůĺŗŽx§ŌĺŗŽxĻęņŪ§Úúļ§Ņ§ĻŐō ‚•Ī©`•Ļ •Ĺ•Ž•–§ÚņŻ”√§Ļ§Ž§»ļÜÖg§ň◊ÓŖm›ĒňÕ§Ú”čň„§«§≠§Ž take home message
- 81. 81 / 88 KYOTO UNIVERSITY •∆•§•Į•Ř©`•ŗ•Š•√•Ľ©`•ł 4 take home message •®•ů•»•Ū•‘©`§ÚĆß»Ž§Ļ§Ž§»◊ÓŖmĽĮ§¨ļÜÖg§ň •∑•ů•Į•Ř©`•ů§Ō––Ń–—›ň„§ņ§Ī§«§«§≠§Ž•∑•ů•◊•Ž◊ÓŖmĽĮ∑® ļÜÖg§ň•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ňĹM§Ŗřz§ŗ§≥§»§¨§«§≠§Ž
- 82. 82 / 88 KYOTO UNIVERSITY •∆•§•Į•Ř©`•ŗ•Š•√•Ľ©`•ł 5 take home message ŖBĺA∑÷≤ľ§ő◊ÓŖm›ĒňÕ§őňęĆĚÜĖÓ}§Ō∑÷ÓźÜĖÓ}§»§Ŗ§ §Ľ§Ž °ł∑÷Óź∆ų°Ļ f §Ú•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§«•‚•«•Í•ů•į WGAN §Ō◊ÓŖm›ĒňÕĺŗŽx§¨–°§Ķ§Į§ §Ž§Ť§¶§ň•Ķ•ů•◊•Ž§ÚĄ”§ę§Ļ
- 83. 83 / 88 KYOTO UNIVERSITY •Ę•Ž•ī•Í•ļ•ŗ§Ú√„Źä§∑§Ņ§§∑ŧň§™§Ļ§Ļ§Š§őŔYŃŌ ™ę ◊ÓŖm›ĒňÕ§ő•Ę•Ž•ī•Í•ļ•ŗ√ś§ň§ń§§§∆§‚§√§»‘Ē§∑§Į÷™§Í§Ņ§§∑ŧŌ: ™ę •Ę•Ž•ī•Í•ļ•ŗ√ś§ň§ń§§§∆“‘«į––§√§Ņ•Ľ•Ŗ• ©`§őŔYŃŌ§¨ņŻ”√§«§≠§Ž§ő§« §ľ§“§ī”E§Į§ņ§Ķ§§ ™ę ◊Ó šňÕ§őĹ‚§≠∑Ĺ /joisino/ss-249394573
- 84. 84 / 88 KYOTO UNIVERSITY §Ķ§ť§ň√„Źä§∑§Ņ§§∑ŧň§™§Ļ§Ļ§Š§őĪĺ ™ę ◊ÓŖm›ĒňÕ»ęį„§ň§ń§§§∆§‚§√§»‘Ē§∑§Į÷™§Í§Ņ§§∑ŧŌ: ™ę Gabriel Peyr®¶ and Macro Cuturi. Computational Optimal Transport with Applications to Data Science. ™ę arXiv §«Žä◊”įś§¨Ļęť_§Ķ§ž§∆§§§ř§Ļ https://arxiv.org/abs/1803.00567
- 85. 85 / 88 KYOTO UNIVERSITY ◊ÓŖm›ĒňÕ§ő—ßŃē§ň§¶§√§∆§ń§Ī§őĪĺ£®–ŻĀĽ£© ™ę ôC–Ķ—ßŃē•◊•Ū•’•ß•√•∑•Á• •Ž•∑•Í©`•ļ§Ť§Í◊ÓŖm›ĒňÕĪ姨ŅĮ––”Ť∂®§«§Ļ £®ņīńÍń©§ī§Ū”Ť∂®£© ™ę įkČ”§Ķ§ž§Ņēö§ň§Ō§ľ§“§ī”E§Į§ņ§Ķ§§
- 86. 86 / 88 KYOTO UNIVERSITY ≤őŅľőńŌ◊“Ľ”E
- 87. 87 / 88 KYOTO UNIVERSITY ≤őŅľőńŌ◊“Ľ”E ™ę Jason Altschuler, Jonathan Weed, Philippe Rigollet. Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. NeurIPS 2017. ™ę Martin Arjovsky, Soumith Chintala, L®¶on Bottou. Wasserstein GAN. ICML 2017. ™ę Charlie Frogner, Chiyuan Zhang, Hossein Mobahi, Mauricio Araya-Polo, Tomaso A. Poggio. Learning with a Wasserstein Loss. NIPS 2015. ™ę Ishaan Gulrajani, Faruk Ahmed, Mart®™n Arjovsky, Vincent Dumoulin, Aaron C. Courville.. Improved Training of Wasserstein GANs. NeurIPS 2017. ™ę Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICLR 2018.
- 88. 88 / 88 KYOTO UNIVERSITY ≤őŅľőńŌ◊“Ľ”E ™ę Xiaofeng Liu, Yuzhuo Han, Song Bai, Yi Ge, Tianxing Wang, Xu Han, Site Li, Jane You, Jun Lu. Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training. AAAI 2020. ™ę Luca Oneto, Michele Donini, Giulia Luise, Carlo Ciliberto, Andreas Maurer, Massimiliano Pontil. Exploiting MMD and Sinkhorn Divergences for Fair and Transferable Representation Learning. NeurIPS 2020. ™ę Gabriel Peyr®¶. Optimal Transport in Imaging Sciences. 2012. ™ę /gpeyre/optimal-transport-in-imaging- sciences ™ę Gabriel Peyr®¶, Marco Cuturi. Computational Optimal Transport. 2019. ™ę ◊ŰŐŔłoŮR. ◊Ó šňÕ§őĹ‚§≠∑Ĺ. /joisino/ss- 249394573