























最近の碍补驳驳濒别に学ぶテーブルデータの特徴量エンジニアリング
- 1. 最近のKaggleに学ぶ テーブルデータの特徴量エンジニアリング 能見大河 2019/03/27 MACHINE LEARNING Meetup KANSAI #4 ※発表内容は個人の見解に基づくものであり、所属する組織の公式見解ではありません。
- 2. 自己紹介 株式会社キーエンス(2011~) Original Author of tiny-dnn Kaggle Master (@nyanpn) PLAsTiCC Astronomical Classification Challenge: 3rd/1094 (team) Home Credit Default Risk: 27th /7198 (solo)
- 5. アジェンダ 1. Kaggleコンペティションについて 2. 最近のKaggleコンペティションの傾向 3. 上位入賞者に学ぶ特徴量エンジニアリング (本題)
- 6. アジェンダ 1. Kaggleコンペティションについて 2. 最近のKaggleコンペティションの傾向 3. 上位入賞者に学ぶ特徴量エンジニアリング (本題)
- 7. Kaggleコンペティション 与えられたデータセットに対する予測モデルの精度を競う。 開催期間は1~3か月程度。上位にはメダルや賞金が与えられる。 Train Set Test Set (Public) Test Set (Private) 1. 訓練データには正解ラベ ルが与えられており、これ を使ってモデリング。 参加者には、テストデータのどの行がPrivateなのかは公開されない =LB以外にも通用するモデルの作成が求められる 2. テストデータに対する予 測値を提出すると、順位が Public Leaderboard (LB)に 反映される。 3. 最終的な順位は、Publicと は別のデータで決定される。
- 9. アジェンダ 1. Kaggleについて 2. 最近のKaggleコンペティションの傾向 3. 上位入賞者に学ぶ特徴量エンジニアリング (本題)
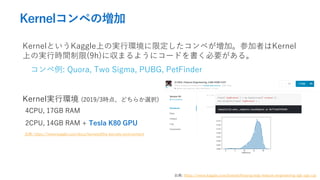
- 10. Kernelコンペの増加 KernelというKaggle上の実行環境に限定したコンペが増加。参加者はKernel 上の実行時間制限(9h)に収まるようにコードを書く必要がある。 コンペ例: Quora, Two Sigma, PUBG, PetFinder 4CPU, 17GB RAM 2CPU, 14GB RAM + Tesla K80 GPU 出典: https://www.kaggle.com/docs/kernels#the-kernels-environment Kernel実行環境 (2019/3時点、どちらか選択) 出典: https://www.kaggle.com/kamalchhirang/eda-feature-engineering-lgb-xgb-cat
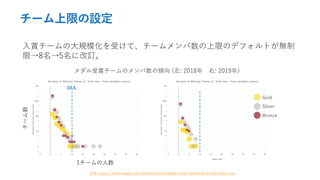
- 11. チーム上限の設定 入賞チームの大規模化を受けて、チームメンバ数の上限のデフォルトが無制 限→8名→5名に改訂。 出典: https://www.kaggle.com/gpreda/meta-kaggle-what-happened-to-the-team-size メダル受賞チームのメンバ数の傾向 (左: 2018年 右: 2019年) チーム数 1チームの人数 Gold Silver Bronze 10人
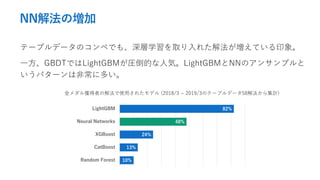
- 12. NN解法の増加 テーブルデータのコンペでも、深層学習を取り入れた解法が増えている印象。 一方、GBDTではLightGBMが圧倒的な人気。LightGBMとNNのアンサンブルと いうパターンは非常に多い。 金メダル獲得者の解法で使用されたモデル (2018/3 ~ 2019/3のテーブルデータ58解法から集計) 82% 48% 24% 13% 10% LightGBM Neural Networks XGBoost CatBoost Random Forest
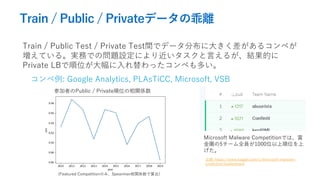
- 13. Train / Public / Privateデータの乖離 Train / Public Test / Private Test間でデータ分布に大きく差があるコンペが 増えている。実務での問題設定により近いタスクと言えるが、結果的に Private LBで順位が大幅に入れ替わったコンペも多い。 コンペ例: Google Analytics, PLAsTiCC, Microsoft, VSB 参加者のPublic / Private順位の相関係数 (Featured Competitionのみ、Spearman相関係数で算出) Microsoft Malware Competitionでは、賞 金圏の5チーム全員が1000位以上順位を上 げた。 出典: https://www.kaggle.com/c/microsoft-malware- prediction/leaderboard
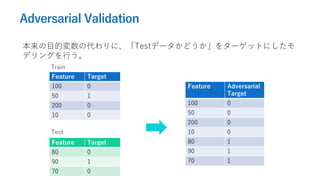
- 14. Adversarial Validation 本来の目的変数の代わりに、「Testデータかどうか」をターゲットにしたモ デリングを行う。 Feature Target 100 0 50 1 200 0 10 0 Feature Target 80 0 90 1 70 0 Train Test Feature Adversarial Target 100 0 50 0 200 0 10 0 80 1 90 1 70 1
- 15. Adversarial Validation Train/Test間の差異を扱うための道具として、2018年頃のコンペから積極的に 活用されるようになってきた。 1) Adversarial ModelのAUCから過学習のリスクを見積もる 2) Adversarial Modelの予測値がテスト寄りの訓練データを使ってLocal Validationを行う →誤分類したデータ=よりTestデータに近いとみなす 3) Adversarial Modelが誤分類したデータを重視してEnsemble Weightを決める ※あくまで本来の問題とは違う問題を解いた結果なので、Adversarial ValidationのAUCが高いからといって即座 に過学習に繋がる訳でも、AUCが○○以下なら安心…という訳でもないのが難しい所です。Train/Testの違いに 対して保守的な戦略を取る場合の一指標ですが、過信は禁物だと思います
- 16. Adversarial Validation 例)Microsoft Malware Prediction マルウェア検出の有無をマシン単位で予測するコンペ。Train / Testだけでな く、Public Test / Private Test間の差も大きいことがコンペ中に指摘されて いた。 ある特徴量をタイムスタンプに変 換してプロットを見ると、Test データに2種類の分布がある。LB を使った実験により、後半が Private Testに使われることが判 明。 出典: https://www.kaggle.com/rquintino/2-months-train-1-month-public-1-day-private Public Private
- 17. Adversarial Validation 元データでAdversarial Validationを行うとAUC=0.98程度が出ていたのに対 して、6th 入賞者はTrain / Test間で頻度が近いカテゴリ変数のラベルをまと める前処理を行うことで、AUCを0.7以下に抑えた。 PublicのTop-10が(我々の チーム含めて)全員過学習で 脱落する中、ほぼ唯一 Public/Privateで一貫して上 位をキープしていた。 出典: https://www.kaggle.com/c/microsoft-malware-prediction/leaderboard
- 18. アジェンダ 1. Kaggleについて 2. 最近のKaggleコンペティションの傾向 3. 上位入賞者に学ぶ特徴量エンジニアリング (本題)
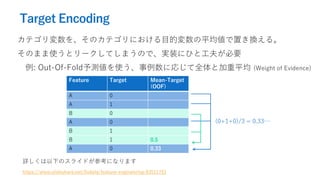
- 19. Target Encoding カテゴリ変数を、そのカテゴリにおける目的変数の平均値で置き換える。 そのまま使うとリークしてしまうので、実装にひと工夫が必要 例: Out-Of-Fold予測値を使う、事例数に応じて全体と加重平均 (Weight of Evidence) Feature Target Mean-Target (OOF) A 0 A 1 B 0 A 0 B 1 B 1 0.5 A 0 0.33 詳しくは以下のスライドが参考になります /0xdata/feature-engineering-83511751 (0+1+0)/3 = 0.33…
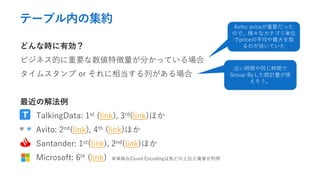
- 20. Target Encoding どんな時に有効? カテゴリ変数の水準数がそれなりに多い場合 Train/Test間であまり分布に差が無いと期待できる場合 …とはいえ、大抵やってみないと分からない 最近の解法例 TalkingData: 3rd(link), 4th(link), 6th(link)ほか Avito: 1st(link),11th(link)ほか Elo: 5th (link), 18th(link)ほか カテゴリ変数をTargetの期待値に変 換しているので、期待値がドリフト する問題設定では素朴なTarget Encodingは有害なはず (例: Microsoft Malware Prediction)
- 21. テーブル間の集約 テーブルが複数ある場合に、様々な集約関 数(min, max, sum, mean, std…)を使って情報 を目的変数がいるテーブルに集める。 これ自体は基本的だが、集約する際に色々 な条件を組み合わせると多数のバリエー ションを生成することができる。 マーケティング系だと実務でも良くあるはず 出典: Ilya Kastov, “Introduction to Algorithmic Marketing” (link) SQLでいうWhere句を 色々使う
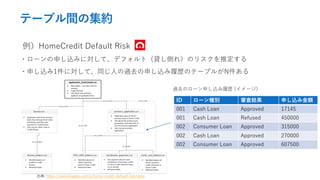
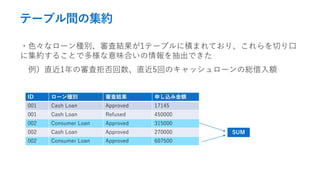
- 22. テーブル間の集約 例)HomeCredit Default Risk ?ローンの申し込みに対して、デフォルト(貸し倒れ)のリスクを推定する ?申し込み1件に対して、同じ人の過去の申し込み履歴のテーブルがN件ある ID ローン種別 審査結果 申し込み金額 001 Cash Loan Approved 17145 001 Cash Loan Refused 450000 002 Consumer Loan Approved 315000 002 Cash Loan Approved 270000 002 Consumer Loan Approved 607500 過去のローン申し込み履歴 (イメージ) 出典: https://www.kaggle.com/c/home-credit-default-risk/data
- 23. テーブル間の集約 ?色々なローン種別、審査結果が1テーブルに積まれており、これらを切り口 に集約することで多様な意味合いの情報を抽出できた 例)直近1年の審査拒否回数、直近5回のキャッシュローンの総借入額 ID ローン種別 審査結果 申し込み金額 001 Cash Loan Approved 17145 001 Cash Loan Refused 450000 002 Consumer Loan Approved 315000 002 Cash Loan Approved 270000 002 Consumer Loan Approved 607500 SUM
- 24. テーブル間の集約 どんな時に有効? トランザクション側の情報が多い場合 特にカテゴリ変数やタイムスタンプを含む場合 最近の解法例 HomeCredit: 1st (link), 2nd(link)ほか Elo: 7th(link), 18th(link)ほか ※両コンペとも単純な集約は事実上必須のため、条件に工夫を入れているSolutionのみ記載
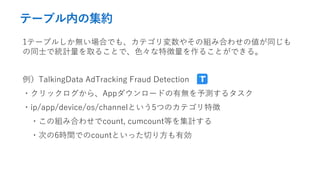
- 25. テーブル内の集約 1テーブルしか無い場合でも、カテゴリ変数やその組み合わせの値が同じも の同士で統計量を取ることで、色々な特徴量を作ることができる。 例)TalkingData AdTracking Fraud Detection ?クリックログから、Appダウンロードの有無を予測するタスク ?ip/app/device/os/channelという5つのカテゴリ特徴 ?この組み合わせでcount, cumcount等を集計する ?次の6時間でのcountといった切り方も有効
- 26. テーブル内の集約 どんな時に有効? ビジネス的に重要な数値特徴量が分かっている場合 タイムスタンプ or それに相当する列がある場合 最近の解法例 TalkingData: 1st (link), 3rd(link)ほか Avito: 2nd(link), 4th (link)ほか Santander: 1st(link), 2nd(link)ほか Microsoft: 6th (link) ※単純なCount Encodingは殆どの上位入賞者が利用 Avito: priceが重要だった ので、様々なカテゴリ単位 でpriceの平均や最大を取 るのが効いていた 近い時間や同じ時間で Group-Byした統計量が使 えそう。
- 29. 四則演算 例)Avito Demand Prediction オンライン商品広告の需要予測。商品名、商品 写真、分類名、価格、説明文等が与えられた Multimodalタスク 「同一カテゴリ内の平均価格と自分の価格との 差/比」を色々なカテゴリ(商品分類、地域な ど)で算出するのが効果的だった。 出典: https://medium.com/@chrisstevens1/approaching-a-competition-on- kaggle-avito-demand-prediction-challenge-part-1-9bc4e6299ba4 たとえば「iPhoneの中で は安い」といった特徴を表 現しているイメージ
- 30. 四則演算 例)Avito Demand Prediction さらに4位解法(link)によれば、「商品名の中の 名詞」でグループ化した価格平均を使った特徴 量が劇的に効いた。 Avitoのサイトから名詞をキーワードに検索を かけ、価格順にソートして上から見るような ユーザーの振る舞いをReverse Engineeringし ている意味合いになる、という考察がなされて いた。 商品名 出典: https://medium.com/@chrisstevens1/approaching-a-competition-on- kaggle-avito-demand-prediction-challenge-part-1-9bc4e6299ba4
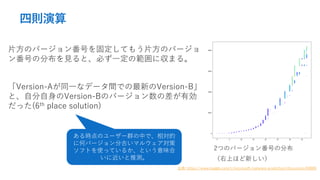
- 32. 四則演算 2つのバージョン番号の分布 (右上ほど新しい) 片方のバージョン番号を固定してもう片方のバージョ ン番号の分布を見ると、必ず一定の範囲に収まる。 「Version-Aが同一なデータ間での最新のVersion-B」 と、自分自身のVersion-Bのバージョン数の差が有効 だった(6th place solution) 出典: https://www.kaggle.com/c/microsoft-malware-prediction/discussion/84069 ある時点のユーザー群の中で、相対的 に何バージョン分古いマルウェア対策 ソフトを使っているか、という意味合 いに近いと推測。
- 33. 四則演算 どんな時に有効? (特にコンペを選ばない印象だが、強いて挙げるなら) 物理量や意味が明確な数値列が多数ある場合 最近の解法例 Avito: 4th (link)ほか HomeCredit: 1st(link)ほか Elo: 7th (link)ほか Microsoft: 6th (link) 差や割り算が効くのは、同一単 位系の量同士のことが多い 出典: https://seaborn.pydata.org/generated/seaborn.pairplot.html 個人的には、とりあえずpairplot 等で散布図を見て、比例に近そ うな量的変数間で比を取る…み たいなアプローチをとることも あります
- 35. Sub-Modelによる特徴量 1) 重要な特徴量の予測 例)Home Credit Default Risk 過去のローン履歴では各ローンの利率を算出できるが、予測対象のローンで は(列が足りず)算出できない。利率は銀行から見た申込者に対する一種の リスク評価値とみなすことができ、重要な特徴量だと考えられた。 →そこで、過去の履歴情報を使って、今回のローン申し込みの利率を予測 するモデルを作成。予測値を特徴量に加えた。 (2nd place, 5th place他) ID 申し込み金額 1回の返済額 支払い回数 001 450000 34000 12 001 315000 21400 18 002 637500 101400 6 過去のローン申し込み履歴 ID 申し込み金額 1回の返済額 001 510000 38000 002 656000 25240 003 897000 100000 今回のローン申し込み(予測対象) この3列があれば、利率を算出できる。
- 36. Sub-Modelによる特徴量 1) 重要な特徴量の予測 例)Avito Demand Prediction ラベル付きデータの他に、同じ期間の広告のラベル無しデータが主催者から 提供。→ラベル無しデータを使うことで、価格予測モデルを作成できた。 価格予測モデルが算出した予測値と実際の価格の差を算出することで、一種 の「お得度合い」のような特徴量を作ることができた。(1st place) → Sub-Model + 差の組み合わせ 先ほどの「カテゴリ内平均と の差」と、考え方は非常に近 い。推定値をMLベースで求め るか、単純な統計量で求める かの違い。
- 37. Sub-Modelによる特徴量 1) 重要な特徴量の予測 例)PLAsTiCC Astronomical Classification 天体望遠鏡が観測した変光(Variables)から、その正体を分類するタスク。 時系列観測データと、距離や方角などのメタデータが与えられた。 メタデータに天体までの距離情報が2種類含まれ、これが非常に重要だった。 距離A: 精度が低い。全データに値が入っている。 距離B: 精度が高いが、大半のテストデータで値が欠損。 →距離Bを予測するモデルを作成し、直接特徴量に加えたり、見かけの明る さと距離から光度を計算したりした(2nd, 3rd, 4th place solution)
- 38. Sub-Modelによる特徴量 1) 重要な特徴量の予測 どんな時に有効? 重要な特徴量の一部または全部が欠損しているとき 大量のラベル無しデータが利用できるとき 最近の解法例 Avito: 1st(link)ほか HomeCredit: 2nd(link)ほか PLAsTiCC: 3rd(link)ほか Elo: 18th(link)
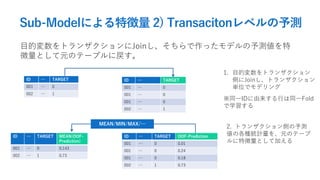
- 39. Sub-Modelによる特徴量 2) Transacitonレベルの予測 目的変数をトランザクションにJoinし、そちらで作ったモデルの予測値を特 徴量として元のテーブルに戻す。 ID … TARGET 001 … 0 002 … 1 ID … TARGET 001 … 0 001 … 0 001 … 0 002 … 1 1. 目的変数をトランザクション 側にJoinし、トランザクション 単位でモデリング ※同一IDに由来する行は同一Fold で学習する ID … TARGET MEAN(OOF- Prediction) 001 … 0 0.143 002 … 1 0.73 ID … TARGET OOF-Prediction 001 … 0 0.01 001 … 0 0.24 001 … 0 0.18 002 … 1 0.73 MEAN/MIN/MAX/… 2. トランザクション側の予測 値の各種統計量を、元のテーブ ルに特徴量として加える
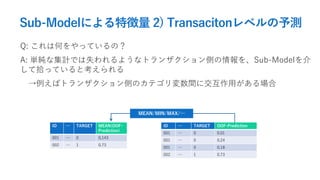
- 40. Sub-Modelによる特徴量 2) Transacitonレベルの予測 Q: これは何をやっているの? A: 単純な集計では失われるようなトランザクション側の情報を、Sub-Modelを介 して拾っていると考えられる →例えばトランザクション側のカテゴリ変数間に交互作用がある場合 ID … TARGET MEAN(OOF- Prediction) 001 … 0 0.143 002 … 1 0.73 ID … TARGET OOF-Prediction 001 … 0 0.01 001 … 0 0.24 001 … 0 0.18 002 … 1 0.73 MEAN/MIN/MAX/…
- 41. Sub-Modelによる特徴量 2) Transacitonレベルの予測 どんな時に有効? トランザクション側に多数の列があるとき 最近の解法例 HomeCredit: 2nd(link), 3rd(link)ほか Elo: 1st(link), 7th(link)
- 42. その他の特徴量 他にも、コンペによって色々な特徴量が使われている。 ?行内でのヒストグラム特徴量 (Santander 1st) ?Gaussian Processでのフィッティング+各種統計量 (PLAsTiCC 1st) ?カテゴリ間の共起行列からのLDA (TalkingData 1st) ?特徴量が似た近傍500点での目的変数の平均値 (HomeCredit 1st) 実際に参加した上で上位者の解法を読むと、ぐっと理解が深まる。 実務に近い問題設定のコンペに参加してみると、仕事にも役立つかも。