Google Colaboratory§Œ π§§∑Ω
5 likes7,545 views

Google Colaboratory§Œ π§§∑Ω§À§ƒ§§§∆°¢ ⁄òI§« π§¶πÝáϧ«±ÿ“™§ §≥§»§Ú’h√˜§∑§∆§þ§Þ§∑§ø°£












































More Related Content
What's hot (20)
Similar to Google Colaboratory§Œ π§§∑Ω (20)


















More from Katsuhiro Morishita (20)




















Google Colaboratory§Œ π§§∑Ω
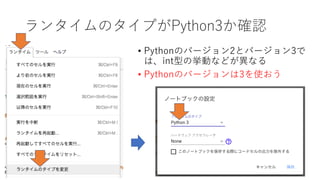
- 2. Colaboratory§»§œ ? •÷•È•¶•∂…œ§«Python§Œ•◊•Ì•∞•È•ý§Úåg––§«§≠§Î≠hæ≥ ? jupyter notebook≠hæ≥§ÚGoogle§¨•Õ•√•»…œ§À÷π©§∑§ø§‚§Œ ? •Õ•√•»§»PC§¨§¢§Ï§–’l§«§‚•◊•Ì•∞•È•ý§Úﯧ±§Î ? ◊Ó≥ı§´§È ˝Çé”ãÀ„§‰ôC–µ—ߡ琉•È•§•÷•È•Í§¨»Î§√§∆§Î ? •Œ©`•»•÷•√•Ø§ÚÈ_§Ø∂»§À–¬§∑§§Å¢œÎ≠hæ≥§¨Ã·π©§µ§Ï§Î§Œ§«°¢∞≤–ƒ ? ◊„§Í§ §§•È•§•÷•È•Í§œ◊∑º”§«•§•Û•π•»©`•Î§«§≠§Î ? Google•¢•´•¶•Û•»§¨±ÿ“™ 2
- 3. º§·∑Ω ? œ¬”õ§ŒURL§À•¢•Ø•ª•π ? https://colab.research.google.com/?hl=ja ? Google§À•Ì•∞•§•Û§∑§∆§§§ §§§ §È•Ì•∞•§•Û 3
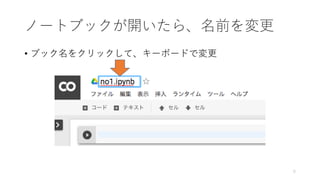
- 4. §Þ§∫§œ•Œ©`•»•÷•√•Ø§Œ◊˜≥… ? •·•À•Â©`§Œ°∏•’•°•§•Î°π§´§È°∏Python 3 §Œ–¬§∑§§•Œ©`•»•÷•√•Ø°π§Úþxík 4
- 7. •Œ©`•»•÷•√•Ø§Œ±£¥ÊàˆÀ˘ ? •Œ©`•»•÷•√•Ø§œ°¢òÀú §«§œGoogle•…•È•§•÷§Œ•Þ•§•…•È•§•÷ƒ⁄§Œ Colab Notebooks§»§§§¶•’•©•Î•¿§À±£¥Ê§µ§Ï§Î ? §ø§¿§∑°¢»Œ“‚§ŒàˆÀ˘§À•Œ©`•»•÷•√•Ø§Ú“∆Ñ”§µ§ª§ø§Í°¢◊˜≥…§«§≠§Î ? ”“•Ø•Í•√•Ø°˙§Ω§ŒÀ˚°˙Colaboratory 7
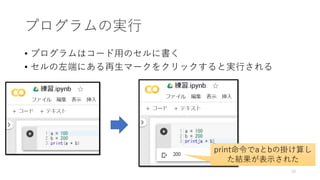
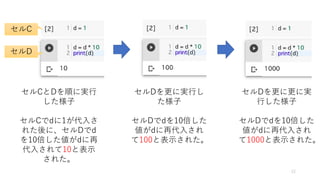
- 11. •ª•Î§Œåg––§Œ§µ§Ï∑Ω ? •ª•ÎA§Úåg––§∑§∆§‚°¢B§œåg––§µ§Ï§ §§ ? •ª•ÎÖgŒª§«åg––§µ§Ï§Î ? Python§«§œ°¢±Ì 槜print()Èv ˝§Ú 𧶠? jupyter notebook§«§œ°¢•ª•Î§Œ◊Ó··§Àﯧ§ §øÑI¿Ì§Œ∑µ§ÍÇ駜±Ì 槵§Ï§Î ? åg––§π§Î§»°¢â‰ ˝§ §…§ŒÑI¿Ìƒ⁄»ð§œ•·•‚•Í ƒ⁄§À±£¥Ê§µ§Ï§Î ? •ª•ÎA§Úåg––§π§Î§»°¢â‰ ˝a§»b§¨±£≥÷§µ§Ï§Î ? ±£≥÷§µ§Ï§ø≠˝§œÀ˚§Œ•ª•Î§«§‚≤Œ’’§«§≠§Î 11 •ª•ÎA •ª•ÎB
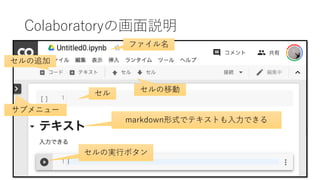
- 13. Colaboratory (jupyter noteboook)¿˚”√…œ§Œ◊¢“‚ ? ÈL§§—}Îj§ ÑI¿Ì§ÚΩYπ˚§Ú¥_’J§∑§ §¨§È–°∑÷§±§Àﯧ±§Î ? §π§¥§Ø±„¿˚§¿§¨°¢ ? •ª•Î§Ú…œ§´§ÈÌò§Àåg––§∑§ §Ø§∆§‚Ñ”§Ø°£Ñ”§§§∆§∑§Þ§¶°£ ? ÑI¿ÌΩYπ˚§¨À˚§Œ•ª•Î§À“¿¥Ê§∑§‰§π§§§∑°¢â‰ ˝√˚§¨Õ¨§∏§¿§»÷–…̧¨ …œï¯§≠§µ§Ï§∆“‚áÌÕ®§Í§ÀÑ”§´§ §§§≥§»§¨§¢§Î ? ª˘±æµƒ§À°¢1§ƒ§Œ•Œ©`•»•÷•√•Ø§À§œ°¢1§ƒ§Œ•∆©`•Þ§»§∑§ø∑Ω§¨¡º§§ ? ◊˜§√§ø•◊•Ì•∞•È•ý§Ú•Ì©`•´•Î…œ§«Ñ”§´§π∑Ω∑®§‚§¢§Î§¨°¢ °¬‘ ? ◊‰—–µ»§«±ÿ“™§ §Èœý’ѧ∑§∆§Ø§¿§µ§§ 13
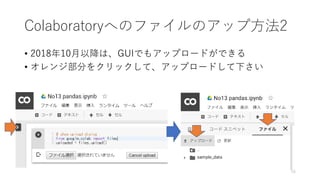
- 14. Colaboratory§ÿ§Œ•’•°•§•Î§Œ•¢•√•◊∑Ω∑®1 ? •’•°•§•Î§ÚColaboratory§«íQ§¶§À§œ°¢•¢•√•◊•Ì©`•…§¨±ÿ“™ ? œ¬”õ§Œ•≥©`•…§Ú•ª•Î§Àﯧ≠Þz§Û§«°¢åg––§ª§Ë ? ±Ì 槵§Ï§ø°∏•’•°•§•Îþxík°π§Ú•Ø•Í•√•Ø§∑§∆•¢•√•◊•Ì©`•… 14 # show upload dialog from google.colab import files uploaded = files.upload() •’•°•§•Î§Ú•¢•√•◊•Ì©`•…§«§≠§Î§Ë§¶§À§ §Í§Þ§π
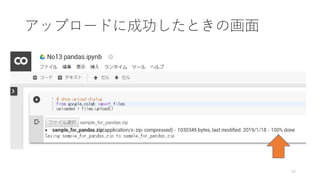
- 17. •¢•√•◊§∑§øzip•’•°•§•Î§ÚΩ‚Éˆ§π§Î§À§œ£ø ? ––Ó^§À!•Þ©`•Ø§Ú 𧶧»°¢Linuxœµ§Œ•≥•Þ•Û•…§¨ π§®§Î ? •ª•Î§Ú◊∑º”§∑°¢“‘œ¬§Œ¿˝§Œòî§Àunzip•≥•Þ•Û•…§Úåg–– ? sample_for_pandas.zip§œ°¢Ω‚Ɉ§∑§ø§§•’•°•§•Î√˚§À’i§þÃʧ® 17 ! ls ! unzip sample_for_pandas.zip ! ls ◊¢£∫—} ˝ªÿåg––§π§Î§»°¢•’•°•§•Î§Ú…œï¯§≠§π§Î§´£®replace£©¬Ñ§´§Ï§Î * ls§œ•’•°•§•Î§Ú±Ì 槵§ª§Î•≥•Þ•Û•… ** unzip§œzip•’•°•§•Î§ÚΩ‚Éˆ§π§Î•≥•Þ•Û•…
- 18. Ω‚Éˆ§À≥…π¶§∑§ø§»§≠§Œª≠√Ê ? sample_for_pandas§»§§§¶°¢•«•£•Ï •Ø•»•Í?§¨◊˜≥…§µ§Ï§Î ? •«©`•ø§œsample_for_pandas§Œ÷–§À ±£¥Ê§µ§Ï§∆§§§Î ? ls ./sample_for_pandas -all§«•’•© •Î•¿ƒ⁄§Œ•’•°•§•Î“ª”E§Ú¥_’J§«§≠§Î 18 ?Linuxœµ§«§œ°¢•’•©•Î•¿§Œ§≥§»§Ú•«•£•Ï•Ø•»•Í§»—‘§§§Þ§π°£
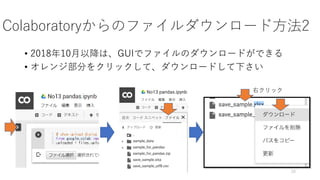
- 19. ? Colaboratory§«±£¥Ê§∑§ø•’•°•§•Î§œGoogle§Œ•µ©`•–©`ƒ⁄§À§¢§Î ? ±£¥Ê§∑§ø•’•°•§•Î§Ú◊‘∑÷§ŒPC§« 𧶧À§œ°¢•¿•¶•Û•Ì©`•…§¨±ÿ“™ ? œ¬”õ§Œ•≥©`•…§Úåg––§∑§∆•’•°•§•Î§Ú•¿•¶•Û•Ì©`•…§∑§Ë§¶ ? ‘Sø…§Ú“™«Û§µ§Ï§ø§È°¢°∏‘Sø…°π§Ú•Ø•Í•√•Ø 19 from google.colab import files files.download('save_sample.xlsx') files.download('save_sample_utf8.csv') Colaboratory§´§È§Œ•’•°•§•Î•¿•¶•Û•Ì©`•…∑Ω∑®1
- 21. ∏∂Âh 21
- 22. ≤ŒøºŒƒœ◊ ? Google Colab§Œ π§§∑Ω§Þ§»§· ? https://qiita.com/shoji9x9/items/0ff0f6f603df18d631ab ? ôC–µ—ß¡ï§Ú§‰§Î§À§œ≤Œøº§À§ §Î ? §Ω§¶§«§ §Ø§»§‚°¢◊‘∑÷§ŒGoogle•…•È•§•÷§Ú•’•°•§•Î÷√§≠àˆ§À π§¶∑Ω∑® §¨§Ô§´§Í“◊§§ 22